
Guten Tag, ich möchte Ihnen meine Erfahrungen bei der Konfiguration und Verwendung des AWS EKS-Dienstes (Elastic Kubernetes Service) für Windows-Container oder vielmehr die Unmöglichkeit der Verwendung und einen Fehler im AWS-Systemcontainer für diejenigen mitteilen, die an diesem Dienst für Windows-Container interessiert sind unter Katze.
Ich weiß, dass Windows-Container kein beliebtes Thema sind und nur wenige Leute sie verwenden, aber ich habe mich dennoch entschlossen, diesen Artikel zu schreiben, da es auf Habré einige Artikel über Kubernetes und Windows gab und es immer noch solche Leute gibt.
Starten Sie
Alles begann mit der Tatsache, dass die Dienste in unserem Unternehmen beschlossen wurden, auf Kubernetes zu migrieren, es sind 70% Windows und 30% Linux. Hierzu wurde der AWS EKS Cloud Service als eine der möglichen Optionen angesehen. Bis zum 8. Oktober 2019 war AWS EKS Windows in der öffentlichen Vorschau. Ich habe damit begonnen. Die Version von kubernetes verwendete die alte Version 1.11. Ich habe mich jedoch entschlossen, sie trotzdem zu überprüfen und festzustellen, in welchem Stadium dieser Cloud-Dienst funktioniert. Wenn sich herausstellte, dass sie überhaupt funktioniert, war dies nicht der Fall Ein Fehler beim Hinzufügen von Herden, während die alten nicht mehr über die interne IP aus demselben Subnetz wie der Windows Worker-Knoten reagierten.
Aus diesem Grund wurde beschlossen, die Verwendung von AWS EKS zugunsten eines eigenen Clusters auf Kubernetes auf demselben EC2 aufzugeben. Nur der gesamte Ausgleich und die HA müssten von mir über CloudFormation beschrieben werden.
Amazon EKS Windows Container-Unterstützung jetzt allgemein verfügbar
von Martin Beeby | am 08. Oktober 2019Ich hatte keine Zeit, CloudFormation eine Vorlage für meinen eigenen Cluster hinzuzufügen, da ich diese Neuigkeiten sah.
Amazon EKS Windows Container Support jetzt allgemein verfügbarNatürlich habe ich alle meine Entwicklungen verschoben und angefangen zu untersuchen, was sie für GA getan haben und wie sich alles gegenüber der öffentlichen Vorschau geändert hat. Ja, AWS-Kollegen haben die Images für den Windows Worker-Knoten auf Version 1.14 sowie die Cluster-Version 1.14 in EKS aktualisiert und unterstützen jetzt Windows-Knoten. Sie schlossen das Public Preview-Projekt auf dem
Github und sagten, verwenden Sie jetzt die offizielle Dokumentation hier:
EKS Windows SupportIntegration eines EKS-Clusters in die aktuelle VPC und Subnetze
In allen Quellen wurde unter dem Link über der Ankündigung und auch in der Dokumentation vorgeschlagen, den Cluster entweder über das proprietäre Dienstprogramm eksctl oder über CloudFormation + kubectl danach bereitzustellen, nur öffentliche Subnetze in Amazon zu verwenden und eine separate VPC für einen neuen Cluster zu erstellen.
Diese Option ist für viele nicht geeignet. Erstens ist eine separate VPC die zusätzlichen Kosten für die Kosten + Peering-Verkehr zu Ihrer aktuellen VPC. Was tun für diejenigen, die bereits über eine vorgefertigte Infrastruktur in AWS mit mehreren AWS-Konten, VPC, Subnetzen, Routentabellen, Transit-Gateway usw. verfügen? Natürlich möchte ich nicht alles aufschlüsseln oder wiederholen, und ich muss den neuen EKS-Cluster unter Verwendung der vorhandenen VPC in die aktuelle Netzwerkinfrastruktur integrieren und, um das Maximum aufzuteilen, neue Subnetze für den Cluster erstellen.
In meinem Fall wurde dieser Pfad gewählt, ich habe die vorhandene VPC verwendet, nur 2 öffentliche Subnetze und 2 private Subnetze für einen neuen Cluster hinzugefügt. Natürlich wurden alle Regeln gemäß der Dokumentation zum
Erstellen Ihrer Amazon EKS-Cluster-VPC berücksichtigt .
Es gab auch eine Bedingung für keinen Arbeitsknoten in öffentlichen Subnetzen, die EIP verwenden.eksctl vs CloudFormation
Ich werde sofort reservieren, dass ich beide Methoden der Clusterbereitstellung ausprobiert habe. In beiden Fällen war das Bild das gleiche.
Ich werde ein Beispiel nur mit der Verwendung von eksctl zeigen, da der Code hier kürzer ist. Verwenden von eksctl cluster in drei Schritten bereitstellen:
1.Erstellen Sie den Cluster selbst + den Linux-Worker-Knoten, auf dem sich später die Systemcontainer und der sehr unglückliche VPC-Controller befinden.
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
Um auf einer vorhandenen VPC bereitzustellen, geben Sie einfach die ID Ihrer Subnetze an, und eksctl bestimmt die VPC selbst.
Damit Ihr Worker-Knoten nur im privaten Subnetz bereitgestellt werden kann, müssen Sie --node-private-network für die Knotengruppe angeben.
2. Installieren Sie den vpc-controller in unserem Cluster, der dann unsere Arbeitsknoten verarbeitet, indem er die Anzahl der freien IP-Adressen sowie die Anzahl der ENI auf der Instanz zählt und diese hinzufügt und entfernt.
eksctl utils install-vpc-controllers --name yyy --approve
3. Nachdem Ihre Systemcontainer erfolgreich auf Ihrem Linux-Worker-Knoten einschließlich VPC-Controller gestartet wurden, müssen Sie nur noch eine andere Knotengruppe mit Windows-Workern erstellen.
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
Nachdem Ihr Knoten erfolgreich mit Ihrem Cluster verbunden wurde und alles in Ordnung zu sein scheint, befindet er sich im Status Bereit, aber nein.
Fehler im VPC-Controller
Wenn wir versuchen, Pods auf dem Windows Worker-Knoten auszuführen, wird folgende Fehlermeldung angezeigt:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
Wenn wir genauer hinschauen, sehen wir, dass unsere AWS-Instanz folgendermaßen aussieht:

Und es sollte so sein:

Daraus ergibt sich, dass der VPC-Controller aus irgendeinem Grund seinen Teil nicht funktioniert hat und der Instanz keine neuen IP-Adressen hinzufügen konnte, damit Pods sie verwenden konnten.
Wir klettern, um uns die VPC-Controller-Pod-Protokolle anzusehen, und das sehen wir:
kubectl log <vpc-controller-deployment> -n kube-system I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
Die Google-Suche führte zu nichts, da anscheinend noch niemand einen solchen Fehler entdeckt oder ein Problem darauf gepostet hatte. Ich musste zunächst selbst über die Optionen nachdenken. Das erste, was mir in den Sinn kam, war, dass der VPC-Controller ip-10-xxx.ap-xxx.compute.internal möglicherweise nicht nüchtern machen und es erreichen kann, und daher fallen die Fehler.
Ja, in der Tat verwenden wir benutzerdefinierte DNS-Server in VPC und keine Amazon-Server. Daher wurde in dieser Domäne ap-xxx.compute.internal nicht einmal die Weiterleitung konfiguriert. Ich habe diese Option aktiviert und sie hat keine Ergebnisse gebracht. Vielleicht war der Test nicht sauber. Daher bin ich bei der Kommunikation mit dem technischen Support ihrer Idee erlegen.
Da es keine Ideen gab, wurden alle Sicherheitsgruppen von eksctl selbst erstellt, sodass kein Zweifel daran bestand, dass sie funktionierten. Die Routentabellen waren ebenfalls korrekt, nat, dns, es gab auch einen Internetzugang mit Arbeiterknoten.
Wenn Sie den Worker-Knoten im öffentlichen Subnetz bereitstellen, ohne --node-private-network zu verwenden, wurde dieser Knoten sofort vom vpc-controller aktualisiert und alles funktionierte wie eine Uhr.
Es gab zwei Möglichkeiten:
- Hämmern Sie und warten Sie, bis jemand diesen Fehler in AWS beschreibt und ihn behebt. Dann können Sie AWS EKS Windows sicher verwenden, da er gerade in GA eingestiegen ist (es hat zum Zeitpunkt des Schreibens 8 Tage gedauert). Wahrscheinlich werden viele den gleichen Weg wie ich gehen .
- Schreiben Sie an den AWS-Support und erklären Sie ihm die Essenz des Problems mit der ganzen Reihe von Protokollen von überall und beweisen Sie ihnen, dass ihr Service bei Verwendung ihrer VPC und Subnetze nicht funktioniert. Es war nicht umsonst, dass wir Business-Support hatten, wir müssen ihn mindestens einmal verwenden :-)
Kommunikation mit AWS-Ingenieuren
Nachdem ich ein Ticket auf dem Portal erstellt hatte, habe ich mich fälschlicherweise entschieden, mir per Web-E-Mail oder Support-Center zu antworten. Über diese Option können sie Ihnen nach einigen Tagen überhaupt antworten, obwohl mein Ticket den Schweregrad des Systems beeinträchtigt hatte, was eine Antwort innerhalb von <12 implizierte Stunden, und da der Business-Support-Plan rund um die Uhr Support bietet, hatte ich auf das Beste gehofft, aber es stellte sich wie immer heraus.
Mein Ticket landete von Freitag bis Montag in Unassigned, dann entschied ich mich, es erneut zu schreiben und wählte die Option Chat-Antwort. Nach einer kurzen Wartezeit wurde Harshad Madhav zu mir ernannt, und dann begann es ...
Wir haben 3 Stunden hintereinander online mit ihm diskutiert, Protokolle übertragen, denselben Cluster im AWS-Labor bereitgestellt, um das Problem zu emulieren, den Cluster meinerseits neu zu erstellen usw. Wir haben nur festgestellt, dass die Protokolle zeigten, dass die Lösung nicht funktionierte Interne AWS-Domainnamen, wie ich oben geschrieben habe, und Harshad Madhav haben mich gebeten, eine Weiterleitung zu erstellen. Angeblich verwenden wir benutzerdefinierte DNS, und dies kann ein Problem sein.
Weiterleitung
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
Was getan wurde, war der Tag vorbei. Harshad Madhav hat diesen Scheck abgemeldet und es sollte funktionieren, aber nein, die Lösung hat nicht geholfen.
Dann gab es ein Gespräch mit zwei weiteren Ingenieuren, einer fiel gerade aus dem Chat, anscheinend aus Angst vor einem schwierigen Fall, der zweite verbrachte meinen Tag wieder mit einem vollständigen Debug-Zyklus, schickte Protokolle, erstellte Cluster auf beiden Seiten, am Ende sagte er nur gut, es funktioniert für mich, also ich offizielle Dokumentation Ich mache alles Schritt für Schritt und du und du wirst Erfolg haben.
Zu dem ich ihn höflich gebeten habe zu gehen und meinem Ticket ein anderes zuzuweisen, wenn Sie nicht wissen, wo Sie nach dem Problem suchen sollen.
Finale
Am dritten Tag wurde ein neuer Ingenieur Arun B. zu mir ernannt, und von Beginn der Kommunikation mit ihm an war sofort klar, dass es sich nicht um drei frühere Ingenieure handelte. Er las die ganze Geschichte und bat sofort, die Protokolle mit seinem eigenen Skript auf ps1 zu sammeln, das auf seinem Github lag. Dann folgten wieder alle Iterationen des Erstellens von Clustern, der Ausgabe der Ergebnisse von Teams und des Sammelns von Protokollen, aber Arun B. bewegte sich in die richtige Richtung, gemessen an den mir gestellten Fragen.
Als wir -stderrthreshold = debug in ihren vpc-controller aufnehmen mussten und was geschah als nächstes? es funktioniert sicherlich nicht) pod startet einfach nicht mit dieser Option, nur -stderrthreshold = info funktioniert.
Hier endeten wir und Arun B. sagte, er würde versuchen, meine Schritte zu reproduzieren, um den gleichen Fehler zu erhalten. Am nächsten Tag erhalte ich eine Antwort von Arun B. Er hat diesen Fall nicht fallen lassen, sondern den Überprüfungscode ihres VPC-Controllers übernommen und den gleichen Ort gefunden, an dem er funktioniert und warum er nicht funktioniert:
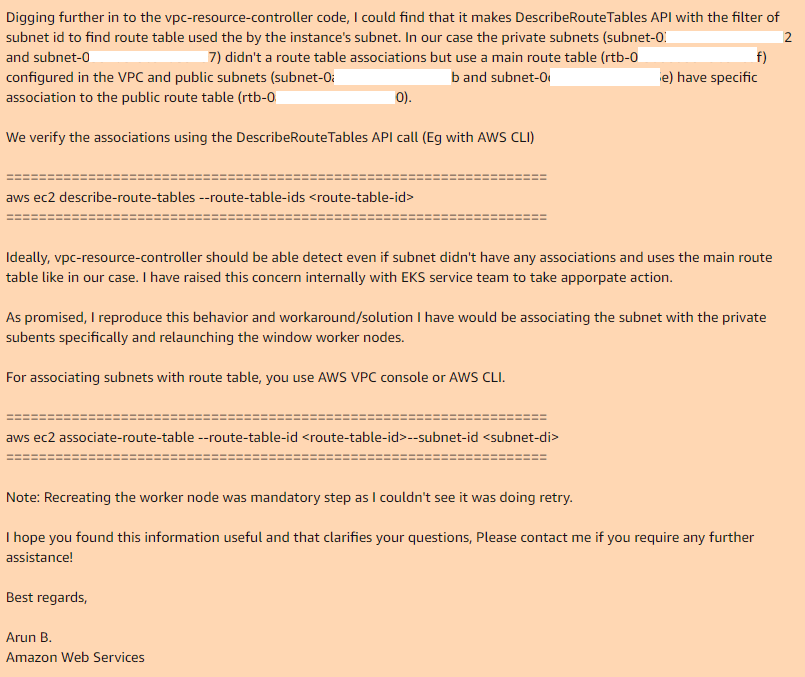
Wenn Sie also die Hauptroutentabelle in Ihrer VPC verwenden, hat sie standardmäßig keine Zuordnungen zu den erforderlichen Subnetzen. Daher verfügt der erforderliche VPC-Controller im Fall des öffentlichen Subnetzes über eine benutzerdefinierte Routentabelle mit einer Zuordnung.
Durch manuelles Hinzufügen von Zuordnungen für die Hauptroutentabelle zu den gewünschten Subnetzen und erneutes Erstellen der Knotengruppe funktioniert alles einwandfrei.
Ich hoffe, dass Arun B. diesen Fehler tatsächlich den EKS-Entwicklern melden wird und wir eine neue Version von vpc-controller sehen werden, bei der alles sofort funktioniert. Derzeit die neueste Version: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
hat dieses Problem.
Vielen Dank an alle, die bis zum Ende gelesen haben. Testen Sie vor der Implementierung alles, was Sie in der Produktion verwenden werden.
Update: Neuer Bug # 2
Nachdem wir eine Lösung für das erste Problem gefunden hatten, bereiteten wir diesen Service weiter auf unsere Bedürfnisse vor und fanden jetzt in der letzten Phase einen weiteren Fehler, der nicht mit dem Leben vereinbar war.
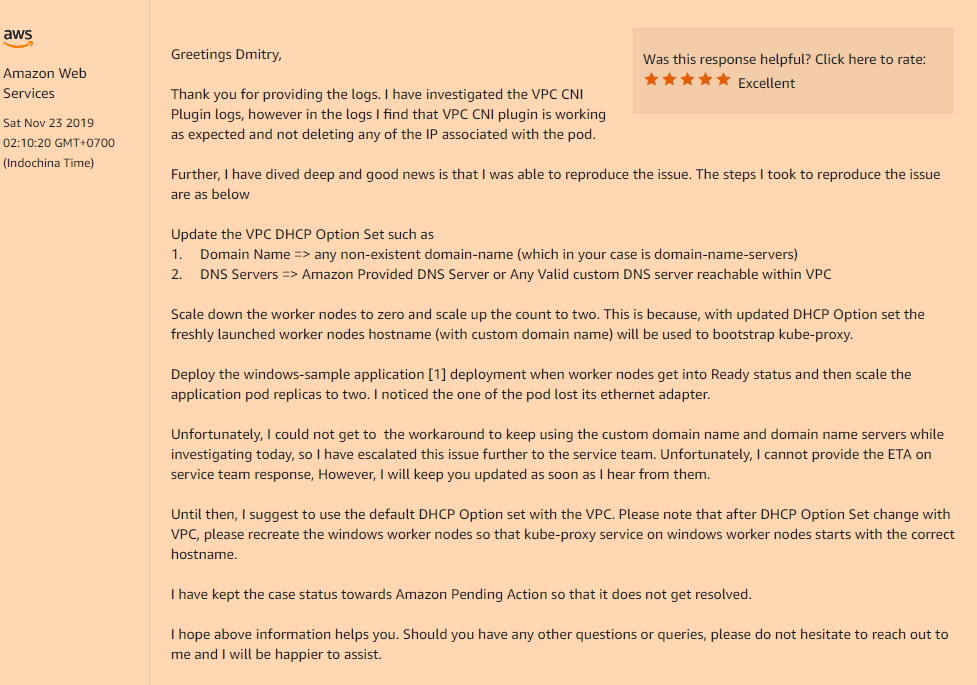
Problem:Stellen Sie die Anwendung auf den Kubernetes bereit, legen Sie Ihre Bereitstellung fest, Replikate> 1, und sehen Sie sich das folgende Bild an. Der neue Pod startet normal und funktioniert, während der alte Pod seine Netzwerkschnittstelle verliert. Ja, ja, der alte Pod ist komplett ohne Netzwerk, obwohl er weiterhin im laufenden Zustand hängt. Reduzieren oder erhöhen Sie Replikate, löschen Sie Pods, damit Sie nicht immer nur den Pod ausführen, dessen letzter Status aktiviert ist, der Rest funktioniert nicht. Unabhängig davon beginnen Pods oder andere auf demselben Knoten.
Lösung:Ja, das Problem stellte sich erneut in der benutzerdefinierten Konfiguration unserer VPC heraus, nämlich wenn Sie Ihren DHCP-Optionssatz verwenden, der den benutzerdefinierten Wert des Felds für den Domänennamen angibt, oder vollständig leer sind (wie in meinem Fall habe ich nur Domänennamenserver geändert). Den Rest brauchte ich nicht.) Sie werden ein so unverständliches Problem mit dem Verschwinden der Netzwerkschnittstellen in Ihren Pods nach dem Start bekommen.
Sie müssen es in Ihrem DHCP-Optionssatz registrieren:
domain-name = <aws-region-name>.compute.internal;
Danach müssen alle Worker-Knoten neu installiert werden, damit alle Komponenten während des Bootstraps die richtigen Einstellungen registrieren.
Nachfolgend finden Sie Details dazu, wie sich diese Domainnamenoption auf Ihre Arbeitsknoten auswirkt:
Dieses Mal bat ich sie, mindestens Dokumentation zu AWS EKS für Windows hinzuzufügen, diese "Funktionen" ihres Dienstes.