Wir bereiten gerade die nächste Hauptversion von Tokio vor, eine asynchrone Laufzeitumgebung für Rust. Am 13. Oktober wurde eine
Poolanforderung mit einem vollständig neu geschriebenen Taskplaner zum Zusammenführen in eine Zweigstelle ausgegeben. Das Ergebnis sind enorme Leistungsverbesserungen und eine verringerte Latenz. Einige Tests haben eine zehnfache Beschleunigung festgestellt! Wie üblich spiegeln synthetische Tests nicht den tatsächlichen Nutzen in der Realität wider. Daher haben wir auch überprüft, wie sich Änderungen im Scheduler auf reale Aufgaben wie
Hyper und
Tonic auswirken (Spoiler: Das Ergebnis ist wunderbar).
Ich bereitete mich auf die Arbeit an einem neuen Planer vor und suchte nach thematischen Ressourcen. Abgesehen von den tatsächlichen Implementierungen wurde nichts Besonderes gefunden. Ich fand auch, dass der Quellcode für vorhandene Implementierungen schwer zu navigieren ist. Um dies zu beheben, haben wir versucht, den Tokio-Sheduler so sauber wie möglich zu schreiben. Ich hoffe, dieser ausführliche Artikel über die Implementierung des Schedulers hilft denjenigen, die sich in derselben Position befinden und erfolglos nach Informationen zu diesem Thema suchen.
Der Artikel beginnt mit einer allgemeinen Überprüfung des Designs, einschließlich der Richtlinien zur Auftragserfassung. Tauchen Sie dann im neuen Tokio-Scheduler in die Details spezifischer Optimierungen ein.
Berücksichtigte Optimierungen:
Wie Sie sehen können, lautet das Hauptthema „Reduktion“. Der schnellste Code ist schließlich sein Mangel!
Wir werden auch über das
Testen des neuen Schedulers sprechen. Es ist sehr schwierig, den richtigen parallelen Code ohne Sperren zu schreiben. Es ist besser, langsam, aber korrekt als schnell zu arbeiten, aber mit Störungen, insbesondere wenn die Fehler die Speichersicherheit betreffen. Die beste Option sollte jedoch schnell und fehlerfrei funktionieren. Deshalb haben wir
loom geschrieben , ein Tool zum Testen der Parallelität.
Bevor ich mich mit dem Thema befasse, möchte ich mich bedanken bei:
- @withoutboats und andere, die an der
async / await Funktion in Rust gearbeitet haben. Du hast einen tollen Job gemacht. Dies ist eine Killer-Funktion.
- @cramertj und andere, die
std::task . Dies ist eine enorme Verbesserung gegenüber dem, was es vorher war. Und toller Code.
- Buoyant , der Schöpfer von Linkerd und vor allem mein Arbeitgeber. Vielen Dank, dass ich so viel Zeit mit diesem Job verbringen durfte. Wenn sich jemand für das Service-Mesh interessiert, schauen Sie sich Linkerd an. In Kürze werden alle in diesem Artikel beschriebenen Vorteile enthalten sein.
- Entscheiden Sie sich für eine so gute Planerimplementierung.
Nehmen Sie eine Tasse Kaffee und lehnen Sie sich zurück. Dies wird ein langer Artikel sein.
Wie arbeiten Planer?
Die Aufgabe des Schuppers ist es, die Arbeit zu planen. Die Anwendung ist in Arbeitseinheiten unterteilt, die wir
Aufgaben nennen
werden . Eine Aufgabe gilt als ausführbar, wenn sie in ihrer Ausführung voranschreiten kann, aber nicht mehr ausgeführt wird, oder wenn sie für eine externe Ressource gesperrt ist. Aufgaben sind insofern unabhängig, als beliebig viele Aufgaben gleichzeitig ausgeführt werden können. Der Scheduler ist dafür verantwortlich, Aufgaben in einem laufenden Zustand auszuführen, bis sie in den Standby-Modus zurückkehren. Bei der Ausführung von Aufgaben wird der Aufgabe Prozessorzeit zugewiesen - eine globale Ressource.
Der Artikel beschreibt User Space Scheduler, dh das Arbeiten auf Betriebssystem-Threads (die wiederum von einem Sheduler auf Kernel-Ebene gesteuert werden). Der Tokio-Scheduler führt Rust-Futures aus, die als "asynchrone grüne Threads" betrachtet werden können. Dies ist ein
gemischtes M: N-Streaming- Muster, bei dem viele Benutzeroberflächenaufgaben auf mehrere Threads des Betriebssystems gemultiplext werden.
Es gibt viele verschiedene Möglichkeiten, einen Sheduler zu simulieren, jede mit ihren eigenen Vor- und Nachteilen. Auf der einfachsten Ebene kann der Scheduler als
Ausführungswarteschlange und als
Prozessor modelliert werden, der ihn auseinander zieht. Ein Prozessor ist ein Code, der in einem Thread ausgeführt wird. Im Pseudocode wird Folgendes ausgeführt:
while let Some(task) = self.queue.pop() { task.run(); }
Wenn eine Aufgabe realisierbar wird, wird sie in die Ausführungswarteschlange eingefügt.
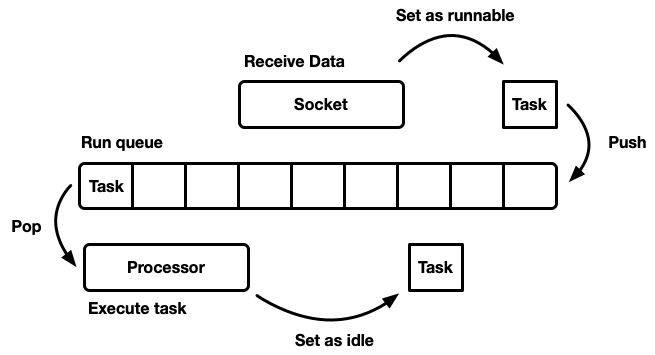
Obwohl Sie ein System entwerfen können, in dem Ressourcen, Aufgaben und ein Prozessor im selben Thread vorhanden sind, bevorzugt Tokio die Verwendung mehrerer Threads. Wir leben in einer Welt, in der ein Computer viele Prozessoren hat. Die Entwicklung eines Single-Threaded-Schedulers führt zu einer unzureichenden Eisenbeladung. Wir wollen alle CPUs nutzen. Es gibt verschiedene Möglichkeiten, dies zu tun:
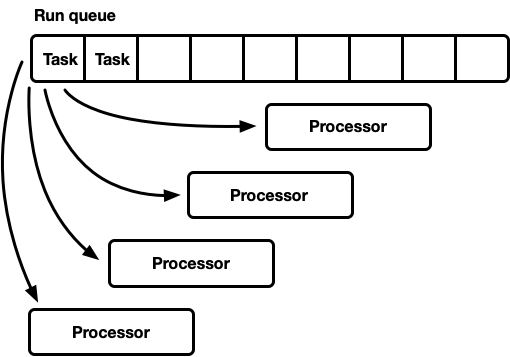
- Eine globale Ausführungswarteschlange, viele Prozessoren.
- Viele Prozessoren mit jeweils eigener Ausführungswarteschlange.
Eine Runde, viele Prozessoren
Dieses Modell verfügt über eine globale Ausführungswarteschlange. Wenn die Aufgaben abgeschlossen sind, werden sie am Ende der Warteschlange platziert. Es gibt mehrere Prozessoren, die sich jeweils in einem separaten Thread befinden. Jeder Prozessor übernimmt eine Aufgabe vom Kopf der Warteschlange oder blockiert den Thread, wenn keine Aufgaben verfügbar sind.
Die Ausführungslinie muss von vielen Herstellern und Verbrauchern unterstützt werden. Normalerweise wird eine
aufdringliche Liste verwendet, in der die Struktur jeder Aufgabe einen Zeiger auf die nächste Aufgabe in der Warteschlange enthält (anstatt die Aufgaben in eine verknüpfte Liste zu packen). Somit kann eine Speicherzuweisung für Push- und Pop-Operationen vermieden werden. Sie können
die Push-Operation ohne Sperren verwenden , aber um die Verbraucher zu koordinieren, ist der Mutex für die Pop-Operation erforderlich (es ist technisch möglich, eine Mehrbenutzer-Warteschlange ohne Sperren zu implementieren).
In der Praxis ist der Aufwand für einen ordnungsgemäßen Schutz vor Schlössern jedoch mehr als nur die Verwendung eines Mutex.
Dieser Ansatz wird häufig für einen allgemeinen Thread-Pool verwendet, da er mehrere Vorteile bietet:
- Aufgaben sind ziemlich geplant.
- Relativ einfache Implementierung. Eine mehr oder weniger Standardwarteschlange ist mit dem oben beschriebenen Prozessorzyklus verbunden.
Ein kurzer Hinweis zur fairen (gerechten) Planung. Das bedeutet, dass die Aufgaben ehrlich ausgeführt werden: Wer früher kam, ist derjenige, der früher gegangen ist. Allzweckplaner versuchen fair zu sein, aber es gibt Ausnahmen wie die Parallelisierung über Fork-Join, bei denen die Geschwindigkeit der Ergebnisberechnung und nicht die Gerechtigkeit für jede einzelne Teilaufgabe ein wichtiger Faktor ist.
Dieses Modell hat einen Nachteil. Alle Prozessoren beantragen Aufgaben vom Kopf der Warteschlange aus. Für Allzweck-Threads ist dies normalerweise kein Problem. Die Zeit zum Ausführen einer Aufgabe überschreitet bei weitem die Zeit zum Abrufen aus der Warteschlange. Wenn Aufgaben über einen längeren Zeitraum ausgeführt werden, wird der Wettbewerb in der Warteschlange verringert. Es wird jedoch erwartet, dass asynchrone Rust-Aufgaben sehr schnell abgeschlossen werden. In diesem Fall erhöhen sich die Gemeinkosten für den Kampf in der Warteschlange erheblich.
Parallelität und mechanische Sympathie
Um maximale Leistung zu erzielen, müssen wir die Hardwarefunktionen optimal nutzen. Der Begriff „mechanische Sympathie“ für Software wurde zuerst von
Martin Thompson verwendet (dessen Blog nicht mehr aktualisiert, aber immer noch sehr informativ ist).
Eine ausführliche Erörterung der Implementierung von Parallelität in modernen Geräten würde den Rahmen dieses Artikels sprengen. Im Allgemeinen erhöht Eisen die Produktivität nicht aufgrund von Beschleunigung, sondern aufgrund der Einführung einer größeren Anzahl von CPU-Kernen (sogar mein Laptop hat sechs!). Jeder Kern kann in winzigen Zeitintervallen große Rechenmengen ausführen. Aktionen wie der Zugriff auf den Cache und den Speicher benötigen
im Vergleich zur Ausführungszeit auf der CPU
viel mehr Zeit . Um Anwendungen zu beschleunigen, müssen Sie daher die Anzahl der CPU-Anweisungen für jeden Speicherzugriff maximieren. Obwohl der Compiler sehr hilfreich ist, müssen wir noch über Dinge wie Ausrichtung und Speicherzugriffsmuster nachdenken.
Separate Threads funktionieren separat sehr ähnlich wie ein einzelner isolierter Thread,
bis mehrere Threads gleichzeitig dieselbe Cache-Zeile ändern (gleichzeitige Mutationen) oder eine
konsistente Konsistenz erforderlich ist. In diesem Fall wird das
CPU-Cache-Kohärenzprotokoll aktiviert. Es garantiert die Relevanz des Caches jeder CPU.
Die Schlussfolgerung liegt auf der Hand: Vermeiden Sie nach Möglichkeit die Synchronisation zwischen Threads, da diese langsam ist.
Viele Prozessoren mit jeweils eigener Ausführungswarteschlange
Ein weiteres Modell sind mehrere Single-Threaded-Scheduler. Jeder Prozessor erhält eine eigene Ausführungswarteschlange, und Aufgaben werden auf einem bestimmten Prozessor festgelegt. Dies vermeidet das Synchronisationsproblem vollständig. Da das Rust-Aufgabenmodell die Fähigkeit erfordert, eine Aufgabe von einem beliebigen Thread in die Warteschlange zu stellen, sollte es dennoch eine thread-sichere Möglichkeit geben, Aufgaben in den Scheduler einzugeben. Entweder unterstützt die Ausführungswarteschlange jedes Prozessors die thread-sichere Push-Operation (MPSC), oder jeder Prozessor verfügt über
zwei Ausführungswarteschlangen: unsynchronisiert und thread-sicher.
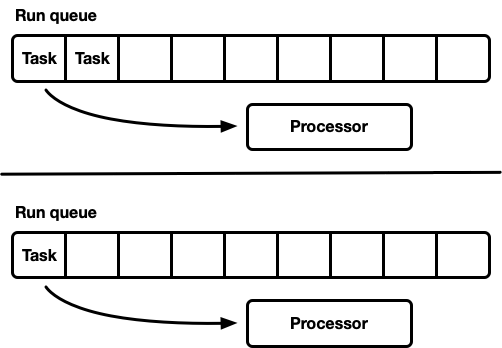
Diese Strategie verwendet
Seastar . Da wir die Synchronisation fast vollständig vermeiden, bietet diese Strategie eine sehr gute Geschwindigkeit. Aber sie löst nicht alle Probleme. Wenn die Arbeitslast nicht vollständig homogen ist, sind einige Prozessoren unter Last, während andere im Leerlauf sind, was zu einer nicht optimalen Ressourcennutzung führt. Dies liegt daran, dass Aufgaben auf einem bestimmten Prozessor festgelegt sind. Wenn eine Gruppe von Aufgaben in einem Paket auf einem Prozessor geplant ist, erfüllt sie im Alleingang die Spitzenlast, auch wenn andere im Leerlauf sind.
Die meisten „realen“ Workloads sind nicht homogen. Daher meiden Allzweckplaner dieses Modell normalerweise.
Job Capture Scheduler
Der Scheduler mit Work-Stealing-Schedulern basiert auf dem Sharded-Scheduler-Modell und löst das Problem des unvollständigen Ladens von Hardwareressourcen. Jeder Prozessor unterstützt seine eigene Ausführungswarteschlange. Aufgaben, die ausgeführt werden, werden in die Ausführungswarteschlange des aktuellen Prozessors gestellt und funktionieren darauf. Wenn der Prozessor jedoch inaktiv ist, überprüft er die Warteschlangen des Schwesterprozessors und versucht, etwas von dort abzurufen. Der Prozessor wechselt erst in den Ruhemodus, nachdem er keine Arbeit in Peer-to-Peer-Ausführungswarteschlangen gefunden hat.

Auf Modellebene ist dies der Ansatz „Das Beste aus zwei Welten“. Unter Last arbeiten Prozessoren unabhängig voneinander und vermeiden Overhead-Synchronisation. In Fällen, in denen die Last zwischen den Prozessoren ungleichmäßig verteilt ist, kann der Scheduler sie neu verteilen. Aus diesem Grund werden solche Scheduler in
Go ,
Erlang ,
Java und anderen Sprachen verwendet.
Der Nachteil ist, dass dieser Ansatz viel komplizierter ist. Der Warteschlangenalgorithmus muss die Auftragserfassung unterstützen. Für eine reibungslose Ausführung ist eine
gewisse Synchronisierung zwischen den Prozessoren erforderlich. Wenn es nicht korrekt implementiert ist, kann der Overhead für die Erfassung größer sein als die Verstärkung.
Stellen Sie sich folgende Situation vor: Prozessor A führt derzeit eine Aufgabe aus und hat eine leere Ausführungswarteschlange. Prozessor B ist inaktiv; Er versucht, eine Aufgabe zu erfassen, schlägt jedoch fehl und wechselt in den Schlafmodus. Dann werden 20 Aufgaben aus der Aufgabe von Prozessor A erzeugt. Im Idealfall sollte Prozessor B aufwachen und einige davon greifen. Zu diesem Zweck müssen bestimmte Heuristiken im Scheduler implementiert werden, wobei die Prozessoren den schlafenden Peer-Prozessoren signalisieren, dass neue Aufgaben in ihrer Warteschlange erscheinen. Dies erfordert natürlich eine zusätzliche Synchronisation, so dass solche Operationen am besten minimiert werden.
Zusammenfassend:
- Je weniger Synchronisation, desto besser.
- Die Auftragserfassung ist der optimale Algorithmus für Allzweckplaner.
- Jeder Prozessor arbeitet unabhängig von den anderen, es ist jedoch eine gewisse Synchronisierung erforderlich, um die Arbeit zu erfassen.
Tokio 0.1 Scheduler
Der erste Arbeitsplaner für Tokio wurde im März 2018 veröffentlicht. Dies war der erste Versuch, der auf einigen Annahmen beruhte, die sich als falsch herausstellten.
Erstens schlug der Tokio 0.1-Scheduler vor, Prozessorthreads zu schließen, wenn sie für eine bestimmte Zeit inaktiv waren. Der Scheduler wurde ursprünglich als "Allzweck" -System für den Rust-Thread-Pool erstellt. Zu diesem Zeitpunkt befand sich die Tokio-Laufzeit noch in einem frühen Entwicklungsstadium. Dann ging das Modell davon aus, dass E / A-Aufgaben auf demselben Thread wie der E / A-Selektor ausgeführt werden (epoll, kqueue, iocp ...). Weitere Rechenaufgaben könnten an den Thread-Pool gerichtet werden. In diesem Zusammenhang wird eine flexible Konfiguration der Anzahl der aktiven Threads angenommen, sodass es sinnvoller ist, inaktive Threads zu deaktivieren. Im Scheduler mit Joberfassung wurde das Modell jedoch auf die Ausführung
aller asynchronen Aufgaben umgestellt. In diesem Fall ist es sinnvoll, immer eine kleine Anzahl von Threads im aktiven Zustand zu halten.
Zweitens wurde dort eine Zweiwege-
Querträgerlinie implementiert. Diese Implementierung basiert auf der
bidirektionalen Chase-Lev-Linie und ist aus den unten beschriebenen Gründen nicht für die Planung unabhängiger asynchroner Aufgaben geeignet.
Drittens erwies sich die Implementierung als zu kompliziert. Dies liegt zum Teil daran, dass dies mein erster Taskplaner war. Außerdem war ich zu ungeduldig, wenn ich Atomics in Zweigen verwendete, in denen der Mutex gut funktioniert hätte. Eine wichtige Lektion ist, dass sehr oft Mutexe am besten funktionieren.
Schließlich gab es viele kleinere Mängel bei der anfänglichen Implementierung. In den Anfangsjahren haben sich die Implementierungsdetails des asynchronen Rust-Modells erheblich weiterentwickelt, aber die Bibliotheken haben die API jederzeit stabil gehalten. Dies führte zu einer Anhäufung technischer Schulden.
Jetzt nähert sich Tokio der ersten Hauptversion - und wir können all diese Schulden bezahlen und aus den Erfahrungen lernen, die wir in den Jahren der Entwicklung gesammelt haben. Dies ist eine aufregende Zeit!
Tokio Scheduler der nächsten Generation
Jetzt ist es Zeit, sich genauer anzusehen, was sich im neuen Scheduler geändert hat.
Neues Aufgabensystem
Zunächst ist es wichtig hervorzuheben, was
nicht Teil von Tokio ist, aber für die Verbesserung der Effizienz von entscheidender Bedeutung ist: Dies ist ein
neues Aufgabensystem in
std , das ursprünglich von
Taylor Kramer entwickelt wurde . Dieses System bietet die Hooks, die der Scheduler implementieren muss, um asynchrone Rust-Aufgaben auszuführen, und das System ist wirklich hervorragend entworfen und implementiert. Es ist viel leichter und flexibler als die vorherige Iteration.
Die
Waker Struktur aus den Ressourcen signalisiert, dass eine
realisierbare Aufgabe in die Scheduler-Warteschlange gestellt werden sollte. Im neuen Aufgabensystem ist dies eine Zwei-Zeiger-Struktur, während sie zuvor viel größer war. Das Reduzieren der Größe ist wichtig, um den Aufwand für das Kopieren des
Waker Werts an verschiedenen Stellen zu minimieren.
Waker nimmt es weniger Platz in den Strukturen ein, sodass Sie wichtigere Daten in die Cache-Zeile drücken können. Das
vtable- Design hat eine Reihe von Optimierungen vorgenommen, die wir später diskutieren werden.
Auswahl des besten Warteschlangenalgorithmus
Die Ausführungswarteschlange befindet sich in der Mitte des Schedulers. Daher ist dies die wichtigste zu behebende Komponente. Der ursprüngliche Tokio-Scheduler verwendete eine Zwei-Wege-
Crossbeam-Warteschlange : eine Single-Source-Implementierung (Produzent) und viele Konsumenten. Eine Aufgabe wird an einem Ende platziert und Werte werden vom anderen abgerufen. Meistens "pusht" der Thread die Werte vom Ende der Warteschlange, aber manchmal fangen andere Threads die Arbeit ab und führen dieselbe Operation aus. Die Zwei-Wege-Warteschlange wird von einem Array und einer Reihe von Indizes unterstützt, die Kopf und Schwanz verfolgen. Wenn die Warteschlange voll ist, führt die Einführung zu einer Erhöhung des Speicherplatzes. Ein neues, größeres Array wird zugewiesen und die Werte werden in den neuen Speicher verschoben.
Die Fähigkeit zu wachsen wird durch Komplexität und Overhead erreicht. Push / Pop-Operationen sollten dieses Wachstum berücksichtigen. Darüber hinaus ist das Freigeben des ursprünglichen Arrays mit zusätzlichen Schwierigkeiten verbunden. In einer Garbage Collection (GC) -Sprache verlässt das alte Array den Gültigkeitsbereich und wird schließlich vom GC gelöscht. Rust wird jedoch ohne GC geliefert. Dies bedeutet, dass wir selbst für die Freigabe des Arrays verantwortlich sind, Threads jedoch gleichzeitig versuchen können, auf den Speicher zuzugreifen. Um dieses Problem zu lösen, verwendet Crossbeam eine epochenbasierte Rekultivierungsstrategie. Obwohl es nicht viele Ressourcen erfordert, fügt es dem Hauptpfad (Hot Path) nicht trivialen Overhead hinzu. Jede Operation sollte nun atomare RMW-Operationen (Lesen-Ändern-Schreiben) am Ein- und Ausgang kritischer Abschnitte ausführen, um anderen Threads zu signalisieren, dass der Speicher verwendet wird und nicht gelöscht werden kann.
Aufgrund des Overheads für das Wachstum der Ausführungswarteschlange ist es sinnvoll zu denken: Ist die Unterstützung für dieses Wachstum wirklich notwendig? Diese Frage veranlasste mich schließlich, den Planer neu zu schreiben. Die neue Strategie besteht darin, für jeden Prozess eine feste Warteschlangengröße zu haben. Wenn die Warteschlange voll ist, wird die Aufgabe nicht mit der lokalen Warteschlange vergrößert, sondern mit mehreren Verbrauchern und mehreren Produzenten in die globale Warteschlange verschoben. Prozessoren überprüfen diese globale Warteschlange regelmäßig, jedoch mit einer viel geringeren Häufigkeit als die lokale.
Im Rahmen eines der ersten Experimente haben wir den Querträger durch
mpmc ersetzt . Dies führte aufgrund des Umfangs der Synchronisation für Push und Pop nicht zu einer signifikanten Verbesserung. Der Schlüssel zur Erfassung der Arbeit besteht darin, dass in den Warteschlangen unter Last fast keine Konkurrenz besteht, da jeder Prozessor nur auf seine eigene Warteschlange zugreift.
Zu diesem Zeitpunkt habe ich mich entschlossen, die Go-Quellen sorgfältig zu untersuchen - und festgestellt, dass sie eine feste Warteschlangengröße mit einem Hersteller und mehreren Verbrauchern bei minimaler Synchronisation verwenden, was sehr beeindruckend ist. Um den Algorithmus an den Tokio-Scheduler anzupassen, habe ich einige Änderungen vorgenommen. Es ist bemerkenswert, dass die Go-Implementierung sequentielle atomare Operationen verwendet (so wie ich es verstehe). Die Tokio-Version reduziert auch die Anzahl einiger Kopiervorgänge in selteneren Codezweigen.
Eine Warteschlangenimplementierung ist ein Ringpuffer, der Werte in einem Array speichert. Der Kopf und das Ende der Warteschlange werden durch atomare Operationen mit ganzzahligen Werten verfolgt.
struct Queue {
Die Warteschlange wird von einem einzelnen Thread ausgeführt:
loop { let head = self.head.load(Acquire);
Beachten Sie, dass in dieser
push Funktion die einzigen atomaren Operationen das Laden mit
Acquire Ordering und das Speichern mit
Release Ordering sind. Es gibt keine RMW-Operationen (
compare_and_swap ,
fetch_and ...) oder sequentielle Reihenfolge wie zuvor. Dies ist wichtig, da auf x86-Chips alle Downloads / Speicherungen bereits "atomar" sind. Auf CPU-Ebene wird
diese Funktion daher nicht synchronisiert . Atomic-Operationen verhindern bestimmte Optimierungen im Compiler, aber das ist alles. Höchstwahrscheinlich könnte der erste
Relaxed mit einer
Relaxed Bestellung sicher durchgeführt werden, aber der Austausch bringt keinen merklichen Aufwand mit sich.
Wenn die Warteschlange voll ist, wird
push_overflow .
Diese Funktion verschiebt die Hälfte der Aufgaben von der lokalen in die globale Warteschlange. Die globale Warteschlange ist eine aufdringliche Liste, die durch einen Mutex geschützt ist. Beim Verschieben in die globale Warteschlange werden Aufgaben zuerst miteinander verknüpft, dann wird ein Mutex erstellt und alle Aufgaben werden durch Aktualisieren des Zeigers auf das Ende der globalen Warteschlange eingefügt. Dies spart eine kleine kritische Abschnittsgröße.Wenn Sie mit den Details der Reihenfolge des Atomspeichers vertraut sind, stellen Sie möglicherweise ein potenzielles „Problem“ mit der oben gezeigten Funktion fest push. Die atomare loadOrdnungsoperation ist Acquireziemlich schwach. Es kann veraltete Werte zurückgeben, d. H. Eine parallele Erfassungsoperation kann den Wert bereits erhöhen self.head, jedoch im Stream-CachepushDer alte Wert bleibt erhalten, sodass der Erfassungsvorgang nicht bemerkt wird. Dies ist kein Problem mit der Richtigkeit des Algorithmus. Im Wesentlichen (schnell) pushkümmern wir uns nur darum, ob die lokale Warteschlange voll ist oder nicht. Da nur der aktuelle Thread die Warteschlange verschieben kann, lässt eine veraltete Operation loaddie Warteschlange einfach voller aussehen, als sie tatsächlich ist. Möglicherweise wird fälschlicherweise festgestellt, dass die Warteschlange voll ist, und push_overflowdies führt zu einer stärkeren atomaren Operation. Wenn push_overflowfestgestellt wird, dass die Warteschlange tatsächlich nicht voll ist, wird w / zurückgegeben Errund der Vorgang pusherneut gestartet. Dies ist ein weiterer Grund warumpush_overflowVerschiebt die Hälfte der Ausführungswarteschlange in die globale Warteschlange. Nach dieser Bewegung treten solche Fehlalarme viel seltener auf.Local pop(vom Prozessor, zu dem die Warteschlange gehört) wird ebenfalls einfach implementiert: loop { let head = self.head.load(Acquire);
In dieser Funktion sind ein Atom loadund ein compare_and_swaps Release. Der Hauptaufwand kommt von compare_and_swap.Die Funktion stealist ähnlich pop, aber die self.tailAtomlast muss von übertragen werden. In ähnlicher Weise push_overflowversucht die Operation steal, so zu tun, als wäre sie die halbe Warteschlange anstelle einer einzelnen Aufgabe. Dies hat einen guten Einfluss auf die Leistung, auf die wir später noch eingehen werden.Der letzte fehlende Teil ist die Analyse der globalen Warteschlange, die Aufgaben empfängt, die lokale Warteschlangen überlaufen, sowie das Übertragen von Aufgaben von Nicht-Prozessor-Threads an den Scheduler. Wenn der Prozessor unter Last ist, dh sich Aufgaben in der lokalen Warteschlange befinden, versucht der Prozessor, die Aufgaben nach etwa 60 Aufgaben in der lokalen Warteschlange aus der globalen Warteschlange zu ziehen. Es überprüft auch die globale Warteschlange, wenn sie sich im unten beschriebenen Status "Suchen" befindet.Optimieren Sie Nachrichtenvorlagen
Tokio-Anwendungen bestehen normalerweise aus vielen kleinen unabhängigen Aufgaben. Sie interagieren miteinander durch Nachrichten. Eine solche Vorlage ähnelt anderen Sprachen wie Go und Erlang. Angesichts der Häufigkeit der Vorlage ist es für den Planer sinnvoll, sie zu optimieren.Angenommen, die Aufgaben A und B sind gegeben. Aufgabe A wird jetzt ausgeführt und sendet eine Nachricht über den Übertragungskanal an Aufgabe B. Ein Kanal ist eine Ressource, für die Task B derzeit gesperrt ist. Durch das Senden einer Nachricht wird Task B in einen ausführbaren Status versetzt und in die Ausführungswarteschlange des aktuellen Prozessors gestellt. Dann leitet der Prozessor die nächste Aufgabe aus der Ausführungswarteschlange ab, führt sie aus und wiederholt diesen Zyklus, bis er Aufgabe B erreicht.Das Problem besteht darin, dass zwischen dem Senden einer Nachricht und dem Abschließen von Aufgabe B eine erhebliche Verzögerung auftreten kann. Darüber hinaus werden heiße Daten, z. B. eine Nachricht, im CPU-Cache gespeichert. Wenn die Aufgabe abgeschlossen ist, werden die entsprechenden Caches wahrscheinlich gelöscht.Um dieses Problem zu lösen, implementiert der neue Tokio-Scheduler die Optimierung (wie bei den Go- und Kotlin-Schedulern). Wenn eine Aufgabe in einen ausführbaren Zustand versetzt wird, wird sie nicht am Ende der Warteschlange platziert, sondern in einem speziellen Steckplatz für die nächste Aufgabe gespeichert. Der Prozessor überprüft diesen Steckplatz immer, bevor er die Warteschlange überprüft. Wenn beim Einfügen in den Steckplatz bereits eine alte Aufgabe vorhanden ist, wird diese aus dem Steckplatz gelöscht und an das Ende der Warteschlange verschoben. Somit wird die Aufgabe des Sendens einer Nachricht praktisch ohne Verzögerung abgeschlossen.
Drosselklappenerfassung
Wenn in einem Joberfassungsplaner die Prozessorausführungswarteschlange leer ist, versucht der Prozessor, Aufgaben von Peer-CPUs zu erfassen. Zuerst wird eine zufällige Peer-CPU ausgewählt. Wenn keine Aufgaben dafür gefunden werden, wird die nächste durchsucht usw., bis Aufgaben gefunden werden.In der Praxis beenden mehrere Prozessoren häufig die Verarbeitung der Ausführungswarteschlange ungefähr zur gleichen Zeit. Dies geschieht, wenn ein Jobpaket eintrifft (z. B. wennepollauf Bereitschaft der Steckdose abgefragt). Prozessoren wachen auf, empfangen Aufgaben, starten sie und erledigen sie. Dies führt dazu, dass alle Prozessoren gleichzeitig versuchen, die Aufgaben anderer Personen zu erfassen, dh viele Threads versuchen, auf dieselben Warteschlangen zuzugreifen. Es gibt einen Konflikt. Eine zufällige Auswahl des Startpunkts trägt zur Reduzierung des Wettbewerbs bei, aber die Situation ist immer noch nicht sehr gut.Um dieses Problem zu umgehen, begrenzt der neue Scheduler die Anzahl der parallelen Prozessoren, die Erfassungsvorgänge ausführen. Wir nennen den Status des Prozessors, in dem er versucht, die Aufgaben anderer Personen zu erfassen, "Jobsuche" oder kurz "Suche" (dazu später mehr). Eine solche Optimierung wird unter Verwendung eines Atomwerts durchgeführtint, die der Prozessor vor dem Starten der Suche erhöht und beim Verlassen des Suchstatus verringert. Maximal die Hälfte der Gesamtzahl der Prozessoren kann sich im Suchstatus befinden. Das heißt, die ungefähre Grenze ist festgelegt, und dies ist normal. Wir brauchen keine feste Begrenzung für die Anzahl der CPUs in der Suche, sondern nur eine Drosselung. Wir opfern die Genauigkeit, um die Effizienz des Algorithmus zu verbessern.Nach dem Eintritt in den Suchstatus versucht der Prozessor, die Arbeit von Peer-CPUs zu erfassen, und überprüft die globale Warteschlange.Verringern Sie die Synchronisation zwischen Threads
Ein weiterer wichtiger Teil des Schedulers ist die Benachrichtigung von Peer-CPUs über neue Aufgaben. Wenn der "Bruder" schläft, wacht er auf und erfasst Aufgaben. Benachrichtigungen spielen eine weitere wichtige Rolle. Denken Sie daran, dass der Warteschlangenalgorithmus eine schwache atomare Ordnung ( Acquire/ Release) verwendet. Aufgrund der atomaren Speicherzuweisung kann nicht garantiert werden, dass ein Peer-Prozessor jemals Aufgaben in der Warteschlange ohne zusätzliche Synchronisierung sieht. Daher sind auch Benachrichtigungen dafür verantwortlich. Aus diesem Grund werden Benachrichtigungen teuer. Das Ziel ist es, ihre Anzahl zu minimieren, um keine CPU-Ressourcen zu verwenden, dh der Prozessor hat Aufgaben und der Bruder kann sie nicht stehlen. Eine übermäßige Anzahl von Benachrichtigungen führt zu einem Problem mit der Donnerherde .Der ursprüngliche Tokio-Planer verfolgte einen naiven Ansatz bei Benachrichtigungen. Immer wenn eine neue Aufgabe in die Ausführungswarteschlange gestellt wurde, erhielt der Prozessor eine Benachrichtigung. Immer wenn die CPU benachrichtigt wurde und die Aufgabe nach dem Aufwachen sah, benachrichtigte sie eine andere CPU. Diese Logik führte sehr schnell dazu, dass alle Prozessoren aufwachten und nach Arbeit suchten (was zu einem Konflikt führte). Oft fanden die meisten Prozessoren keine Arbeit und schliefen wieder ein.Der neue Scheduler hat dieses Muster erheblich verbessert, ähnlich wie der Go-Scheduler. Benachrichtigungen werden wie zuvor gesendet, jedoch nur, wenn sich keine CPU im Suchstatus befindet (siehe vorherigen Abschnitt). Wenn der Prozessor eine Benachrichtigung erhält, wechselt er sofort in den Suchstatus. Wenn der Prozessor im Suchstatus neue Aufgaben findet, verlässt er zuerst den Suchstatus und benachrichtigt dann den anderen Prozessor.Diese Logik begrenzt die Geschwindigkeit, mit der Prozessoren aufwachen. Wenn ein ganzes Aufgabenpaket sofort geplant ist (zum Beispiel wannepollabgefragt auf Bereitschaft des Sockets), dann führt die erste Aufgabe zu einer Benachrichtigung an den Prozessor. Er ist jetzt in einem Suchzustand. Die verbleibenden geplanten Aufgaben im Paket benachrichtigen den Prozessor nicht, da sich mindestens eine CPU im Suchstatus befindet. Dieser benachrichtigte Prozessor erfasst die Hälfte der Aufgaben im Stapel und benachrichtigt wiederum den anderen Prozessor. Ein dritter Prozessor wacht auf, findet die Aufgaben eines der ersten beiden Prozessoren und erfasst die Hälfte davon. Dies führt zu einem reibungslosen Anstieg der Anzahl der funktionierenden CPUs sowie zu einem schnellen Lastausgleich.Speicherzuordnung reduzieren
Der neue Tokio-Scheduler benötigt nur eine Speicherzuordnung für jede erzeugte Aufgabe, während der alte zwei benötigt. Bisher sah die Aufgabenstruktur ungefähr so aus: struct Task {
Die Struktur Taskwird auch in hervorgehoben Box. Ich wollte dieses Gelenk schon sehr lange reparieren (ich habe es 2014 zum ersten Mal versucht). Zwei Dinge haben sich seit dem alten Tokio-Planer geändert. Erstens stabilisiert std::alloc. Zweitens hat das zukünftige Aufgabensystem auf eine explizite vtable-Strategie umgestellt . Es waren diese beiden Dinge, die schließlich fehlten, um die ineffiziente doppelte Speicherzuweisung für jede Aufgabe zu beseitigen.Nun wird die Struktur Taskin der folgenden Form dargestellt: struct Task<T> { header: Header, future: T, trailer: Trailer, }
Für Aufgaben notwendig und Headerund Trailer, aber sie sind zwischen dem „heißen“ Daten (Kopf) und „kalten“ (Schwanz), m. E. etwa zwischen Daten häufig zugegriffen wird und solche unterteilt , die selten verwendet werden. "Heiße" Daten werden am Kopf der Struktur platziert und so wenig wie möglich gespeichert. Wenn der Prozessor den Taskzeiger dereferenziert, lädt er sofort die Cache-Zeile (von 64 bis 128 Byte). Wir möchten, dass diese Daten so relevant wie möglich sind.Reduzierte Anzahl atomarer Verbindungen
Die letzte Optimierung, die wir in diesem Artikel diskutieren, besteht darin, die Anzahl der atomaren Verknüpfungen zu reduzieren. Es gibt viele Verweise auf die Struktur der Aufgabe, auch vom Scheduler und von jedem Waker. Die allgemeine Strategie zur Verwaltung dieses Speichers ist das Zählen atomarer Verbindungen . Diese Strategie erfordert jedes Mal, wenn ein Link geklont und ein Link gelöscht wird, eine atomare Operation. Wenn der letzte Link den Gültigkeitsbereich verlässt, wird der Speicher freigegeben.Im alten Tokio-Scheduler enthielten sowohl der Scheduler als auch alle Waker einen Link zu einem Task-Deskriptor, ungefähr: struct Waker { task: Arc<Task>, } impl Waker { fn wake(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Wenn die Aufgabe aktiviert wird, wird die Verbindung geklont (ein atomares Inkrement tritt auf). Dann wird der Link in die Ausführungswarteschlange gestellt. Wenn der Prozessor die Aufgabe empfängt und ihre Ausführung abschließt, verwirft er die Verknüpfung, was zu einer atomaren Reduktion führt. Diese atomaren Operationen (Inkrementieren und Verringern) summieren sich.Dieses Problem wurde zuvor von den Entwicklern des Task-Systems identifiziert std::future. Sie bemerkten, dass beim Anrufen der Waker::wakeursprüngliche Link zu wakerhäufig nicht mehr benötigt wird. Auf diese Weise können Sie den Atomic Link-Zähler wiederverwenden, wenn Sie eine Aufgabe in die Ausführungswarteschlange verschieben. Das Task-System enthält std::futurejetzt zwei API-Aufrufe zum „Aufwachen“:Eine solche API-Konstruktion lässt uns sie beim Aufrufen verwenden wake, um atomare Inkremente zu vermeiden. Die Implementierung sieht folgendermaßen aus: impl Waker { fn wake(self) { task.scheduler.schedule(self.task); } fn wake_by_ref(&self) { let task = self.task.clone(); task.scheduler.schedule(task); } }
Dies vermeidet den Aufwand für zusätzliche Verbindungszählungen nur, wenn Sie die Verantwortung für das Aufwachen übernehmen können. Nach meiner Erfahrung ist es stattdessen fast immer ratsam, mit aufzuwachen &self. Das Erwachen selfverhindert die Wiederverwendung von Waker (nützlich in Fällen, in denen die Ressource viele Werte sendet, d. H. Kanäle, Sockets, ...). Auch für den Fall, dass es selfschwieriger ist, ein thread-sicheres Aufwachen zu implementieren (wir werden die Details für einen anderen Artikel belassen).Der neue Planer löst das Problem des "Aufwachens self", indem er das atomare Inkrement vermeidet wake_by_ref, was es so effektiv wie machtwake(self). Zu diesem Zweck verwaltet der Scheduler eine Liste aller Aufgaben, die derzeit aktiv sind (noch nicht abgeschlossen). Die Liste stellt den Referenzzähler dar, der zum Senden der Aufgabe an die Ausführungswarteschlange erforderlich ist.Die Komplexität dieser Optimierung liegt in der Tatsache, dass der Scheduler Aufgaben erst dann aus seiner Liste entfernt, wenn er die Garantie erhält, dass die Aufgabe erneut in die Ausführungswarteschlange gestellt wird. Details zur Implementierung dieses Schemas gehen über den Rahmen dieses Artikels hinaus. Ich empfehle jedoch dringend, dass Sie sich die Quelle ansehen.Fettgedruckte (unsichere) Parallelität mit Loom
Es ist sehr schwierig, den richtigen parallelen Code ohne Sperren zu schreiben. Es ist besser, langsam, aber korrekt als schnell zu arbeiten, aber mit Störungen, insbesondere wenn die Fehler die Speichersicherheit betreffen. Die beste Option sollte jedoch schnell und fehlerfrei funktionieren. Der neue Scheduler hat einige ziemlich aggressive Optimierungen vorgenommen und vermeidet die meisten Typen stdaus Gründen der Spezialisierung. Im Allgemeinen enthält es ziemlich viel unsicheren Code unsafe.Es gibt verschiedene Möglichkeiten, parallelen Code zu testen. Eine davon ist, dass Benutzer anstelle von Ihnen testen und debuggen können (eine attraktive Option, das ist sicher). Eine andere Möglichkeit besteht darin, Komponententests zu schreiben, die in einer Schleife ausgeführt werden und einen Fehler abfangen können. Vielleicht sogar TSAN verwenden. Wenn er einen Fehler findet, kann er natürlich nicht einfach reproduziert werden, ohne den Testzyklus neu zu starten. Wie lange dauert dieser Zyklus? Zehn Sekunden? Zehn Minuten? Zehn Tage? Zuvor mussten Sie parallelen Code in Rust testen.Wir fanden diese Situation inakzeptabel. Wenn wir den Code freigeben, möchten wir uns (so weit wie möglich) sicher fühlen, insbesondere bei parallelem Code ohne Sperren. Tokio-Benutzer benötigen Zuverlässigkeit.Aus diesem Grund haben wir Loom entwickelt : ein Tool zum Testen der Permutation von parallelem Code. Tests werden wie gewohnt geschrieben, aberloomSie werden viele Male ausgeführt und alle möglichen Optionen für die Ausführung und das Verhalten neu angeordnet, auf die der Test in einer Streaming-Umgebung stoßen kann. Außerdem wird überprüft, ob der Speicherzugriff korrekt ist, Speicher freigegeben usw.Hier ist als Beispiel der Webmaschinentest für den neuen Scheduler: #[test] fn multi_spawn() { loom::model(|| { let pool = ThreadPool::new(); let c1 = Arc::new(AtomicUsize::new(0)); let (tx, rx) = oneshot::channel(); let tx1 = Arc::new(Mutex::new(Some(tx)));
Es sieht ziemlich normal aus, aber ein Teil des Codes in einem Block wird loom::modelviele tausend Mal (möglicherweise Millionen) ausgeführt, jedes Mal mit einer geringfügigen Änderung des Verhaltens. Jeder Lauf ändert die genaue Reihenfolge der Threads. Darüber hinaus versucht loom für jede atomare Operation alle unterschiedlichen Verhaltensweisen, die im C ++ 11-Speichermodell zulässig sind. Denken Sie daran, dass die Atomlast mit Acquireeher schwach war und veraltete Werte zurückgeben konnte. Der Test loomversucht alle möglichen Werte, die geladen werden können.loomwurde ein unschätzbares Werkzeug bei der Entwicklung eines neuen Planers. Er hat mehr als zehn Fehler entdeckt, die alle Unit-Tests, manuellen Tests und Lasttests bestanden haben.Ein anspruchsvoller Leser kann bezweifeln, dass der Webstuhl „alle möglichen Permutationen“ überprüft, und er wird Recht haben. Naive Permutationen führen zu einer kombinatorischen Explosion. Jeder nicht triviale Test wird niemals enden. Dieses Problem wurde viele Jahre lang untersucht und eine Reihe von Algorithmen entwickelt, um eine kombinatorische Explosion zu verhindern. Webstuhl grundlegender Algorithmus basierend auf dynamische Reduktion mit teilweise Ordnung (dynamic Teil Ordnung reduction). Dieser Algorithmus eliminiert Permutationen, die zum gleichen Ergebnis führen. Der Zustandsraum kann jedoch immer noch so groß werden, dass er nicht in angemessener Zeit (mehrere Minuten) verarbeitet wird. Mit Loom können Sie die dynamische Reduzierung durch Teilbestellung weiter einschränken.Im Allgemeinen bin ich dank umfangreicher Tests mit Loom jetzt viel sicherer in der Richtigkeit des Schedulers.Ergebnisse
Wir haben uns also angesehen, was Scheduler sind und wie der neue Tokio-Scheduler einen enormen Leistungsschub erzielt hat ... aber welche Art von Wachstum? Da der neue Scheduler nur entwickelt wurde, wurde er in der realen Welt noch nicht vollständig getestet. Folgendes wissen wir.Erstens ist der neue Scheduler bei Mikro-Benchmarks viel schneller:Alter Planer
Test chained_spawn ... Bank: 2.019.796 ns / iter (+/- 302.168)
Test ping_pong ... Bank: 1.279.948 ns / iter (+/- 154.365)
test spawn_many ... Bench: 10.283.608 ns / iter (+/- 1.284.275)
Test Yield_many ... Bench: 21.450.748 ns / iter (+/- 1.201.337)
Neuer Planer
Test chained_spawn ... Bank: 168.854 ns / iter (+/- 8.339)
Test ping_pong ... Bank: 562.659 ns / iter (+/- 34.410)
test spawn_many ... Bench: 7.320.737 ns / iter (+/- 264.620)
Test Yield_many ... Bench: 14.638.563 ns / iter (+/- 1.573.678)
Diese Benchmark umfasst Folgendes:chained_spawn rekursiv neue Aufgaben erzeugen, d. h. eine Aufgabe erzeugen, die eine andere Aufgabe erzeugt, die auch eine Aufgabe erzeugt, usw.
ping_pongwählt einen Kanal aus oneshotund erzeugt eine Aufgabe, die eine Nachricht auf diesem Kanal sendet. Die ursprüngliche Aufgabe wartet auf eine Nachricht. Dies ist der Test, der der „realen Welt“ am nächsten kommt.
spawn_many Überprüft die Implementierung von Aufgaben im Scheduler, d. H. Erzeugt Aufgaben von außerhalb seines Kontexts.
yield_many prüft auf unabhängiges Aufwecken von Aufgaben.
Der Unterschied bei den Benchmarks ist sehr beeindruckend. Aber wie wird sich das in der "realen Welt" widerspiegeln? Es ist schwer zu sagen, aber ich habe versucht, die Hyper- Benchmarks auszuführen .Hier ist der einfachste Hyper-Server, dessen Leistung gemessen wird mit wrk -t1 -c50 -d10:Alter Planer
Ausführen von 10s test @ http://127.0.0.1 {000
1 Gewinde und 50 Verbindungen
Thread-Statistiken Durchschn. Stdev Max +/- Stdev
Latenz 371,53us 99,05us 1,97 ms 60,53%
Req / Sec 114.61k 8.45k 133.85k 67.00%
1139307 Anfragen in 10.00s, 95.61MB gelesen
Anfragen / Sek.: 113923.19
Übertragung / Sek.: 9,56 MB Neuer Planer
Ausführen von 10s test @ http://127.0.0.1 {000
1 Gewinde und 50 Verbindungen
Thread-Statistiken Durchschn. Stdev Max +/- Stdev
Latenz 275.05us 69.81us 1.09ms 73.57%
Req / Sec 153.17k 10.68k 171.51k 71.00%
1522671 Anfragen in 10.00s, 127.79MB gelesen
Anfragen / Sek.: 152258.70
Übertragung / Sek.: 12,78 MB Wir sehen einen Anstieg der Anfragen pro Sekunde um 34% unmittelbar nach dem Planerwechsel! Als ich das zum ersten Mal sah, war ich sehr glücklich, weil ich eine Steigerung von maximal 5-10% erwartet hatte. Aber dann war ich traurig, denn dieses Ergebnis zeigte auch, dass der alte Tokio-Scheduler nicht so gut ist. Dann erinnerte ich mich, dass Hyper bereits führend bei TechEmpower- Bewertungen ist . Es ist interessant zu sehen, wie sich der neue Planer auf die Bewertungen auswirkt.Tonic , der gRPC-Client und -Server mit dem neuen Scheduler, hat sich um etwa 10% beschleunigt, was ziemlich beeindruckend ist, wenn man bedenkt, dass Tonic noch nicht vollständig optimiert ist.Fazit
Ich freue mich sehr, dieses Projekt nach einigen Monaten Arbeit endlich abschließen zu können. Dies ist eine wesentliche Verbesserung der asynchronen E / A von Rust. Ich bin sehr zufrieden mit den Verbesserungen. In Tokio-Code gibt es noch viel Raum für Optimierungen, sodass wir mit der Leistungsverbesserung noch nicht fertig sind.Ich hoffe, dass das Material im Artikel für Kollegen nützlich ist, die versuchen, ihren Aufgabenplaner zu schreiben.