
Kubernetes ist bereits zu einem De-facto-Standard für die Ausführung zustandsloser Anwendungen geworden, vor allem, weil dadurch die Markteinführungszeit für neue Funktionen verkürzt werden kann. Das Starten von Stateful-Anwendungen wie Datenbanken oder Stateful-Microservices ist immer noch eine komplexe Aufgabe, aber Unternehmen müssen sich der Konkurrenz stellen und eine hohe Bereitstellungsrate aufrechterhalten. Sie schaffen also eine Nachfrage nach solchen Lösungen.
Wir möchten unsere Lösung für den Start von Stateful
Tarantool Cartridge- Clustern
vorstellen :
Tarantool Kubernetes Operator , mehr unter dem
Strich .
- Anstelle von tausend Worten
- Was der Bediener tatsächlich tut
- Ein wenig über die Details
- Wie der Bediener arbeitet
- Was der Operator erstellt
- Zusammenfassung
Tarantool ist ein Open-Source-DBMS und ein Anwendungsserver in einem. Als Datenbank weist sie viele einzigartige Merkmale auf: hohe Effizienz der Hardwareauslastung, flexibles Datenschema, Unterstützung für In-Memory- und Festplattenspeicher sowie die Möglichkeit der Erweiterung mithilfe der Lua-Sprache. Als Anwendungsserver können Sie den Anwendungscode mit minimaler Antwortzeit und maximalem Durchsatz so nah wie möglich an die Daten verschieben. Darüber hinaus verfügt Tarantool über ein
umfangreiches Ökosystem, das gebrauchsfertige Module zur Lösung von Anwendungsproblemen bietet:
Sharding ,
Warteschlange , Module für die einfache Entwicklung (
Cartridge ,
Luatest ), Lösungen für den Betrieb (
Metrics ,
Ansible ), um nur einige zu nennen.
Trotz aller Vorzüge sind die Funktionen einer einzelnen Tarantool-Instanz immer begrenzt. Sie müssten Dutzende und Hunderte von Instanzen erstellen, um Terabyte an Daten zu speichern und Millionen von Anforderungen zu verarbeiten, was bereits ein verteiltes System mit all seinen typischen Problemen impliziert. Um sie zu lösen, haben wir
Tarantool Cartridge , ein Framework, das alle möglichen Schwierigkeiten beim Schreiben verteilter Anwendungen verbirgt. Entwickler können sich auf den Geschäftswert der Anwendung konzentrieren. Cartridge bietet einen robusten Satz von Komponenten für die automatische Cluster-Orchestrierung, die automatische Datenverteilung, die WebUI für den Betrieb und Entwicklertools.
Bei Tarantool geht es nicht nur um Technologien, sondern auch um ein Team von Ingenieuren, die an der Entwicklung schlüsselfertiger Unternehmenssysteme, sofort einsatzbereiter Lösungen und der Unterstützung von Open-Source-Komponenten arbeiten.
Weltweit lassen sich alle unsere Aufgaben in zwei Bereiche unterteilen: die Entwicklung neuer Systeme und die Verbesserung bestehender Lösungen. Zum Beispiel gibt es eine umfangreiche Datenbank von einem bekannten Anbieter. Um es für das Lesen zu skalieren, wird ein Tarantool-basierter, eventuell konsistenter Cache dahinter platziert. Oder umgekehrt: Um das Schreiben zu skalieren, wird Tarantool in der Hot / Cold-Konfiguration installiert: Während die Daten "abkühlen", werden sie in den Kühlspeicher und gleichzeitig in die Analysewarteschlange gestellt. Oder es wird eine Light-Version eines vorhandenen Systems geschrieben (funktionale Sicherung), um die "heißen" Daten mithilfe der Datenreplikation vom Hauptsystem zu sichern. Weitere
Informationen finden Sie in den Konferenzberichten zu T + 2019 .
Alle diese Systeme haben eines gemeinsam: Sie sind etwas schwierig zu bedienen. Nun, es gibt viele aufregende Dinge: schnell einen Cluster von über 100 Instanzen zu erstellen, die in 3 Rechenzentren gesichert werden; Aktualisieren der Anwendung, in der Daten ohne Ausfallzeiten oder Wartungsprobleme gespeichert werden; ein Backup und eine Wiederherstellung zu erstellen, um sich auf einen möglichen Unfall oder menschliche Fehler vorzubereiten; um ein Failover versteckter Komponenten sicherzustellen; Konfigurationsmanagement organisieren ...
Die Tarantool-Kassette , die buchstäblich gerade in Open Source veröffentlicht wurde, vereinfacht die Entwicklung verteilter Systeme erheblich: Sie unterstützt das Clustering von Komponenten, die Diensterkennung, das Konfigurationsmanagement, die Erkennung von Instanzfehlern und das automatische Failover, das Management der Replikationstopologie und das Sharding von Komponenten.
Es wäre großartig, wenn wir all dies so schnell wie möglich betreiben könnten. Kubernetes macht es möglich, aber ein spezialisierter Bediener würde das Leben noch komfortabler machen.
Heute stellen wir die Alpha-Version von Tarantool Kubernetes Operator vor.
Anstelle von tausend Worten
Wir haben ein kleines Beispiel basierend auf Tarantool Cartridge vorbereitet und werden damit arbeiten. Es ist eine einfache Anwendung, die als verteilter Schlüsselwertspeicher mit HTTP-Schnittstelle bezeichnet wird. Nach dem Start haben wir Folgendes:
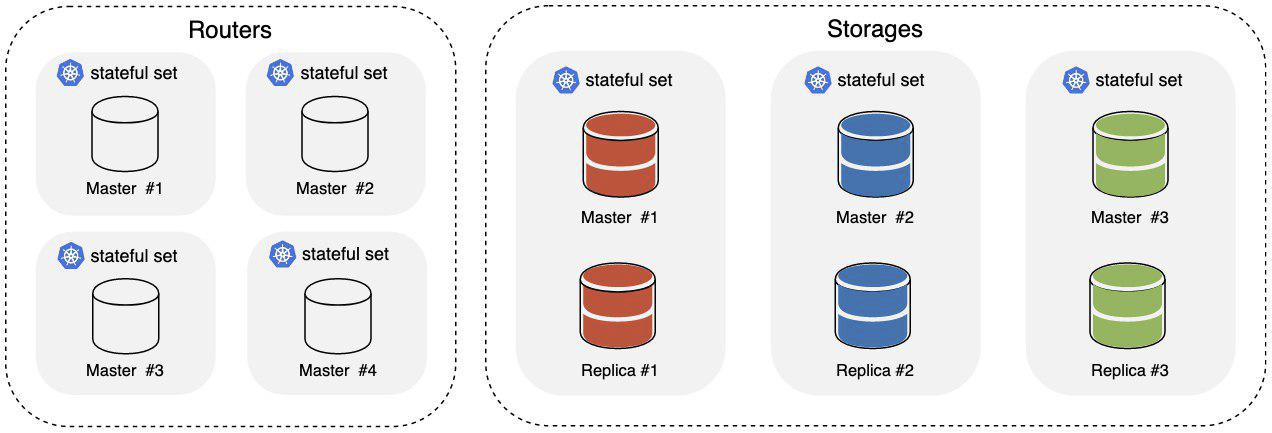
Wo
- Router sind Teil des Clusters, der für das Akzeptieren und Verarbeiten eingehender HTTP-Anforderungen verantwortlich ist.
- Speicher sind Teil des Clusters, der für das Speichern und Verarbeiten von Daten verantwortlich ist. Es werden sofort drei Shards installiert, von denen jeder einen Master und eine Replik hat.
Um den eingehenden HTTP-Verkehr auf den Routern auszugleichen, wird ein Kubernetes Ingress verwendet. Die Daten werden im Speicher auf der Ebene von Tarantool selbst mithilfe der
vshard-Komponente verteilt .
Wir brauchen Kubernetes 1.14+, aber
Minikube wird es tun. Es ist auch schön,
Kubectl zu haben. Erstellen Sie zum Starten des Operators ein ServiceAccount, eine Rolle und eine Rollenbindung:
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/deploy/service_account.yaml $ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/deploy/role.yaml $ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/deploy/role_binding.yaml
Tarantool Operator erweitert die Kubernetes-API mit ihren Ressourcendefinitionen. Erstellen wir sie also:
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/deploy/crds/tarantool_v1alpha1_cluster_crd.yaml $ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/deploy/crds/tarantool_v1alpha1_role_crd.yaml $ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/deploy/crds/tarantool_v1alpha1_replicasettemplate_crd.yaml
Alles ist bereit, um den Bediener zu starten.
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/deploy/operator.yaml
Wir warten auf den Start des Bedieners und können dann mit dem Starten der Anwendung fortfahren:
$ kubectl create -f https://raw.githubusercontent.com/tarantool/tarantool-operator/0.0.1/examples/kv/deployment.yaml
Ein Ingress wird auf der Web-Benutzeroberfläche in der YAML-Datei mit dem Beispiel deklariert. Es ist in
cluster_ip/admin/cluster verfügbar. Wenn mindestens ein Ingress Pod bereit ist und ausgeführt wird, können Sie dort beobachten, wie neue Instanzen zum Cluster hinzugefügt werden und wie sich seine Topologie ändert.
Wir warten auf die Verwendung des Clusters:
$ kubectl describe clusters.tarantool.io examples-kv-cluster
Wir warten auf folgenden Clusterstatus:
… Status: State: Ready …
Das ist alles und die Anwendung ist einsatzbereit!
Benötigen Sie mehr Speicherplatz? Dann fügen wir einige Scherben hinzu:
$ kubectl scale roles.tarantool.io storage --replicas=3
Wenn Shards die Last nicht verarbeiten können, erhöhen wir die Anzahl der Instanzen im Shard, indem wir die Replikatsatzvorlage bearbeiten:
$ kubectl edit replicasettemplates.tarantool.io storage-template
Setzen wir den Wert
.spec.replicas auf zwei, um die Anzahl der Instanzen in jedem Replikatsatz auf zwei zu erhöhen.
Wenn ein Cluster nicht mehr benötigt wird, löschen Sie ihn einfach zusammen mit allen Ressourcen:
$ kubectl delete clusters.tarantool.io examples-kv-cluster
Ist etwas schief gelaufen?
Erstellen Sie ein Ticket , und wir werden schnell daran arbeiten.
Was der Bediener tatsächlich tut
Beim Starten und Betreiben des Tarantool Cartridge-Clusters werden bestimmte Aktionen in einer bestimmten Reihenfolge zu einem bestimmten Zeitpunkt ausgeführt.
Der Cluster selbst wird hauptsächlich über die Admin-API verwaltet: GraphQL über HTTP. Sie können zweifellos eine Stufe tiefer gehen und Befehle direkt über die Konsole erteilen, aber dies kommt nicht sehr oft vor.
So startet der Cluster beispielsweise:
- Wir stellen die erforderliche Anzahl von Tarantool-Instanzen bereit, z. B. mit systemd.
- Dann verbinden wir die Instanzen zu einer Mitgliedschaft:
mutation { probe_instance: probe_server(uri: "storage:3301") }
- Anschließend weisen wir den Instanzen die Rollen zu und geben die IDs der Instanz und des Replikatsatzes an. Zu diesem Zweck wird die GraphQL-API verwendet:
mutation { join_server( uri:"storage:3301", instance_uuid: "cccccccc-cccc-4000-b000-000000000001", replicaset_uuid: "cccccccc-0000-4000-b000-000000000000", roles: ["storage"], timeout: 5 ) }
- Schließlich booten wir die Komponente, die für das Sharding verantwortlich ist, mithilfe der API:
mutation { bootstrap_vshard cluster { failover(enabled:true) } }
Einfach, oder?
Bei der Clustererweiterung ist alles interessanter. Die Rolle "Router" aus dem Beispiel lässt sich leicht skalieren: Erstellen Sie weitere Instanzen, verbinden Sie sie mit einem vorhandenen Cluster, und fertig! Die Rolle der Speicher ist etwas schwieriger. Der Speicher ist gespalten. Wenn Sie also Instanzen hinzufügen oder entfernen, müssen Sie die Daten neu ausgleichen, indem Sie sie zu / von den neuen / gelöschten Instanzen verschieben. Andernfalls würden entweder unterlastete Instanzen oder Daten verloren gehen. Was ist, wenn es nicht nur einen, sondern ein Dutzend Cluster mit unterschiedlichen Topologien gibt?
Im Allgemeinen ist dies alles, was Tarantool Operator erledigt. Der Benutzer beschreibt den erforderlichen Status des Tarantool-Cartridge-Clusters und übersetzt ihn in eine Reihe von Aktionen, die auf die K8-Ressourcen angewendet werden, sowie in bestimmte Aufrufe der Tarantool-Cluster-Administrator-API in einer bestimmten Reihenfolge zu einem bestimmten Zeitpunkt. Es wird auch versucht, alle Details vor dem Benutzer zu verbergen.
Ein wenig über die Details
Bei der Arbeit mit der Tarantool Cartridge-Clusteradministrator-API sind sowohl die Reihenfolge der Anrufe als auch ihr Ziel von entscheidender Bedeutung. Warum ist das so?
Tarantool Cartridge enthält den Topologiespeicher, die Service Discovery-Komponente und die Konfigurationskomponente. Jede Instanz des Clusters speichert eine Kopie der Topologie und Konfiguration in einer YAML-Datei.
servers: d8a9ce19-a880-5757-9ae0-6a0959525842: uri: storage-2-0.examples-kv-cluster:3301 replicaset_uuid: 8cf044f2-cae0-519b-8d08-00a2f1173fcb 497762e2-02a1-583e-8f51-5610375ebae9: uri: storage-0-0.examples-kv-cluster:3301 replicaset_uuid: 05e42b64-fa81-59e6-beb2-95d84c22a435 … vshard: bucket_count: 30000 ...
Aktualisierungen werden konsistent mithilfe des
Zwei-Phasen- Festschreibungsmechanismus angewendet. Für ein erfolgreiches Update ist ein Quorum von 100% erforderlich: Jede Instanz muss antworten. Andernfalls rollt es zurück. Was bedeutet das für den Betrieb? In Bezug auf die Zuverlässigkeit sollten alle Anforderungen an die Administrator-API, die den Clusterstatus ändern, an eine einzelne Instanz oder den Leader gesendet werden, da sonst die Gefahr besteht, dass unterschiedliche Konfigurationen für unterschiedliche Instanzen vorliegen. Tarantool Cartridge weiß (noch nicht) nicht, wie man eine Führungswahl durchführt, aber Tarantool Operator kann und für Sie ist dies nur eine lustige Tatsache, da der Operator alles tut.
Jede Instanz sollte auch eine feste Identität haben, d. H. Eine Menge von
instance_uuid und
replicaset_uuid sowie
advertise_uri . Wenn plötzlich ein Speicher neu gestartet wird und sich einer dieser Parameter ändert, besteht die Gefahr, dass das Quorum verletzt wird, und der Bediener ist dafür verantwortlich.
Wie der Bediener arbeitet
Der Zweck des Bedieners besteht darin, das System in den benutzerdefinierten Zustand zu versetzen und das System in diesem Zustand zu halten, bis neue Anweisungen gegeben werden. Damit der Bediener arbeiten kann, benötigt er:
- Die Beschreibung des Systemstatus.
- Der Code, der das System in diesen Zustand bringen würde.
- Ein Mechanismus zum Integrieren dieses Codes in k8s (zum Beispiel zum Empfangen von Statusänderungsbenachrichtigungen).
Der Tarantool Cartridge-Cluster wird in k8s unter Verwendung einer
benutzerdefinierten Ressourcendefinition (CRD) beschrieben . Der Betreiber würde drei benutzerdefinierte Ressourcen benötigen, die unter der Gruppe tarantool.io/v1alpha zusammengefasst sind:
- Cluster ist eine Ressource der obersten Ebene, die einem einzelnen Tarantool Cartridge-Cluster entspricht.
- Rolle ist eine Benutzerrolle in Bezug auf Tarantool Cartridge.
- Replicaset Template ist eine Vorlage zum Erstellen von StatefulSets (ich werde Ihnen etwas später erklären, warum sie StatefulSets sind; nicht zu verwechseln mit K8s ReplicaSet).
Alle diese Ressourcen spiegeln direkt das Tarantool Cartridge-Cluster-Beschreibungsmodell wider. Ein gemeinsames Wörterbuch erleichtert die Kommunikation mit den Entwicklern und das Verständnis dessen, was sie in der Produktion sehen möchten.
Der Code, der das System in den angegebenen Zustand bringt, ist der Controller in Bezug auf K8s. Im Fall von Tarantool Operator gibt es mehrere Controller:
- Der Cluster Controller ist für die Interaktion mit dem Tarantool Cartridge-Cluster verantwortlich. Es verbindet Instanzen mit dem Cluster und trennt Instanzen vom Cluster.
- Der Rollencontroller ist der Benutzerrollencontroller, der für die Erstellung von StatefulSets aus der Vorlage und die Verwaltung der vordefinierten Anzahl verantwortlich ist.
Wie ist ein Controller? Es ist eine Reihe von Codes, die die Welt um sich herum allmählich in Ordnung bringen. Ein Cluster-Controller würde schematisch wie folgt aussehen:
Ein Einstiegspunkt ist ein Test, um festzustellen, ob für ein Ereignis eine entsprechende Clusterressource vorhanden ist. Existiert es? "Nein" bedeutet beenden. "Ja" bedeutet, zum nächsten Block überzugehen und die Benutzerrollen zu übernehmen. Wenn das Eigentum an einer Rolle übernommen wird, wird sie beendet und beim zweiten Mal ausgeführt. Es geht weiter und weiter, bis es das Eigentum an allen Rollen übernimmt. Wenn das Eigentum übernommen wurde, ist es Zeit, zum nächsten Betriebsblock überzugehen. Und der Prozess geht bis zum letzten Block weiter. Danach können wir davon ausgehen, dass sich das gesteuerte System im definierten Zustand befindet.
Im Allgemeinen ist alles ganz einfach. Es ist jedoch wichtig, die Erfolgskriterien für das Bestehen jeder Stufe zu bestimmen. Beispielsweise wird die Cluster-Join-Operation nicht als erfolgreich angesehen, wenn sie den hypothetischen Erfolg = true zurückgibt, sondern wenn ein Fehler wie "bereits verbunden" zurückgegeben wird.
Und der letzte Teil dieses Mechanismus ist die Integration des Controllers in K8s. Aus der Vogelperspektive besteht der gesamte K8 aus einer Reihe von Controllern, die Ereignisse generieren und darauf reagieren. Diese Ereignisse sind in Warteschlangen organisiert, die wir abonnieren können. Es würde schematisch aussehen wie:

Der Benutzer ruft
kubectl create -f tarantool_cluster.yaml und die entsprechende
kubectl create -f tarantool_cluster.yaml wird erstellt. Der Cluster-Controller wird über die Erstellung der Cluster-Ressourcen benachrichtigt. Als erstes wird versucht, alle Rollenressourcen zu finden, die Teil dieses Clusters sein sollten. Wenn dies der Fall ist, wird der Cluster als Eigentümer für die Rolle zugewiesen und die Rollenressource aktualisiert. Der Rollencontroller erhält eine Benachrichtigung über die Rollenaktualisierung, versteht, dass die Ressource ihren Eigentümer hat, und beginnt mit der Erstellung von StatefulSets. So funktioniert es: Das erste Ereignis löst das zweite aus, das zweite Ereignis löst das dritte aus und so weiter, bis eines von ihnen stoppt. Sie können auch alle 5 Sekunden einen Zeitauslöser einstellen.
So ist der Operator organisiert: Wir erstellen eine benutzerdefinierte Ressource und schreiben den Code, der auf die Ereignisse im Zusammenhang mit den Ressourcen reagiert.
Was der Operator erstellt
Die Bedieneraktionen führen letztendlich zur Erstellung von K8-Pods und -Containern. In dem auf K8s bereitgestellten Tarantool Cartridge-Cluster sind alle Pods mit StatefulSets verbunden.
Warum StatefulSet? Wie bereits erwähnt, behält jede Tarantool-Cluster-Instanz eine Kopie der Cluster-Topologie und -Konfiguration bei. Und hin und wieder verfügt ein Anwendungsserver über Speicherplatz, der beispielsweise für Warteschlangen oder Referenzdaten reserviert ist, und dies ist bereits ein vollständiger Status. StatefulSet garantiert auch, dass die Pod-Identitäten erhalten bleiben. Dies ist wichtig, wenn Instanzen geclustert werden: Instanzen sollten feste Identitäten haben, da sonst das Quorum beim Neustart verloren gehen kann.
Wenn alle Clusterressourcen bereit und im gewünschten Zustand sind, spiegeln sie die folgende Hierarchie wider:
Die Pfeile geben die inhaberabhängige Beziehung zwischen Ressourcen an. Der
Garbage Collector muss beispielsweise nach dem Entfernen des Clusters bereinigt werden.
Zusätzlich zu StatefulSets erstellt Tarantool Operator einen Headless-Service für die Leader-Wahl, und die Instanzen kommunizieren über diesen Service miteinander.
Tarantool Operator basiert auf dem
Operator Framework , und der Operatorcode ist in Golang geschrieben, daher gibt es hier nichts Besonderes.
Zusammenfassung
Das ist so ziemlich alles. Wir warten auf Ihr Feedback und Ihre Tickets. Wir können nicht ohne sie auskommen - es ist schließlich die Alpha-Version. Was kommt als nächstes? Der nächste Schritt ist viel Polieren:
- Einheit, E2E-Tests;
- Chaos Monkey Tests;
- Stresstests;
- sichern / wiederherstellen;
- externer Topologieanbieter.
Jedes dieser Themen ist für sich genommen umfassend und verdient einen eigenen Artikel. Warten Sie also bitte auf Aktualisierungen!