Pavel Selivanov, Southbridge Solution Architect und Slurm Lecturer, hielt auf der DevOpsConf 2019 einen Vortrag. Dieser Bericht ist Teil des ausführlichen Slur Mega-Kurses von Kubernetes.
Slurm Basic: Eine Einführung in Kubernetes findet vom 18. bis 20. November in Moskau statt.
Slurm Mega: Wir schauen unter die Haube von Kubernetes - Moskau, 22.-24. November.
Slurm Online: Beide Kubernetes-Kurse sind immer verfügbar.
Unter dem Schnittprotokoll des Berichts.
Guten Tag, Kollegen und Sympathisanten. Heute werde ich über Sicherheit sprechen.
Ich sehe, dass heute viele Sicherheitskräfte in der Halle sind. Ich entschuldige mich im Voraus bei Ihnen, wenn ich die Begriffe aus der Sicherheitswelt nicht so verwende, wie Sie es akzeptiert haben.
So kam es, dass ich vor ungefähr sechs Monaten in die Hände eines öffentlichen Kubernetes-Clusters geriet. Öffentlich - bedeutet, dass es eine n-te Anzahl von Namespaces gibt. In diesem Namespace befinden sich Benutzer, die in ihrem Namespace isoliert sind. Alle diese Benutzer gehören verschiedenen Unternehmen an. Nun, es wurde angenommen, dass dieser Cluster als CDN verwendet werden sollte. Das heißt, sie geben Ihnen einen Cluster, sie geben dem Benutzer dort, Sie gehen in Ihrem Namespace dorthin und stellen Ihre Fronten bereit.
Sie haben versucht, einen solchen Service an meine vorherige Firma zu verkaufen. Und ich wurde gebeten, einen Cluster zu diesem Thema zu erstellen - ist diese Lösung geeignet oder nicht?
Ich bin zu diesem Cluster gekommen. Ich erhielt begrenzte Rechte, begrenzten Namespace. Dort verstanden die Jungs, was Sicherheit ist. Sie haben gelesen, was Kubernetes über eine rollenbasierte Zugriffskontrolle (RBAC) verfügt - und sie haben sie verdreht, damit ich Pods nicht getrennt von der Bereitstellung ausführen kann. Ich erinnere mich nicht an die Aufgabe, die ich lösen wollte, indem ich ohne Bereitstellung ausgeführt wurde, aber ich wollte wirklich nur unter ausführen. Ich habe mich für viel Glück entschieden, um zu sehen, welche Rechte ich im Cluster habe, was ich kann, was ich nicht kann, was sie dort vermasselt haben. Gleichzeitig werde ich Ihnen mitteilen, was sie im RBAC falsch konfiguriert haben.
So kam es, dass ich zwei Minuten später einen Administrator für ihren Cluster bekam, mir alle benachbarten Namespaces ansah, die Produktionsfronten von Unternehmen sah, die den Service bereits gekauft hatten und dort feststeckten. Ich hielt mich kaum auf, um nicht zu jemandem in der Front zu kommen und kein obszönes Wort auf die Hauptseite zu setzen.
Ich werde Ihnen anhand von Beispielen erzählen, wie ich das gemacht habe und wie ich mich davor schützen kann.
Aber stell mich zuerst vor. Ich heiße Pavel Selivanov. Ich bin Architekt bei Southbridge. Ich verstehe Kubernetes, DevOps und alle möglichen ausgefallenen Sachen. Die Ingenieure von Southbridge und ich bauen das alles und ich rate.
Zusätzlich zu unserem Kerngeschäft haben wir kürzlich Projekte namens Slory gestartet. Wir versuchen, unsere Fähigkeit, mit Kubernetes zu arbeiten, der Masse nahe zu bringen und anderen Menschen beizubringen, wie man auch mit K8s arbeitet.
Worüber ich heute sprechen werde. Das Thema des Berichts liegt auf der Hand - über die Sicherheit des Kubernetes-Clusters. Aber ich möchte sofort sagen, dass dieses Thema sehr groß ist - und deshalb möchte ich sofort festlegen, worüber ich nicht sicher erzählen werde. Ich werde nicht über abgedroschene Begriffe sprechen, die im Internet bereits hundertmal überstrapaziert sind. Alle RBAC und Zertifikate.
Ich werde darüber sprechen, wie es mir und meinen Kollegen aus Sicherheitsgründen im Kubernetes-Cluster weh tut. Wir sehen diese Probleme sowohl bei Anbietern, die Kubernetes-Cluster bereitstellen, als auch bei Kunden, die zu uns kommen. Und selbst bei Kunden, die von anderen Beratungsunternehmen zu uns kommen. Das heißt, das Ausmaß der Tragödie ist in der Tat sehr groß.
Buchstäblich drei Punkte, über die ich heute sprechen werde:
- Benutzerrechte gegen Pod-Rechte. Benutzer- und Herdrechte sind nicht dasselbe.
- Sammlung von Clusterinformationen. Ich werde zeigen, dass Sie im Cluster alle Informationen sammeln können, die Sie benötigen, ohne über besondere Rechte in diesem Cluster zu verfügen.
- DoS-Angriff auf den Cluster. Wenn wir keine Informationen sammeln können, können wir den Cluster auf jeden Fall platzieren. Ich werde über DoS-Angriffe auf Cluster-Steuerelemente sprechen.
Eine andere häufige Sache, die ich erwähnen werde, ist, wo ich alles getestet habe, und ich kann definitiv sagen, dass alles funktioniert.
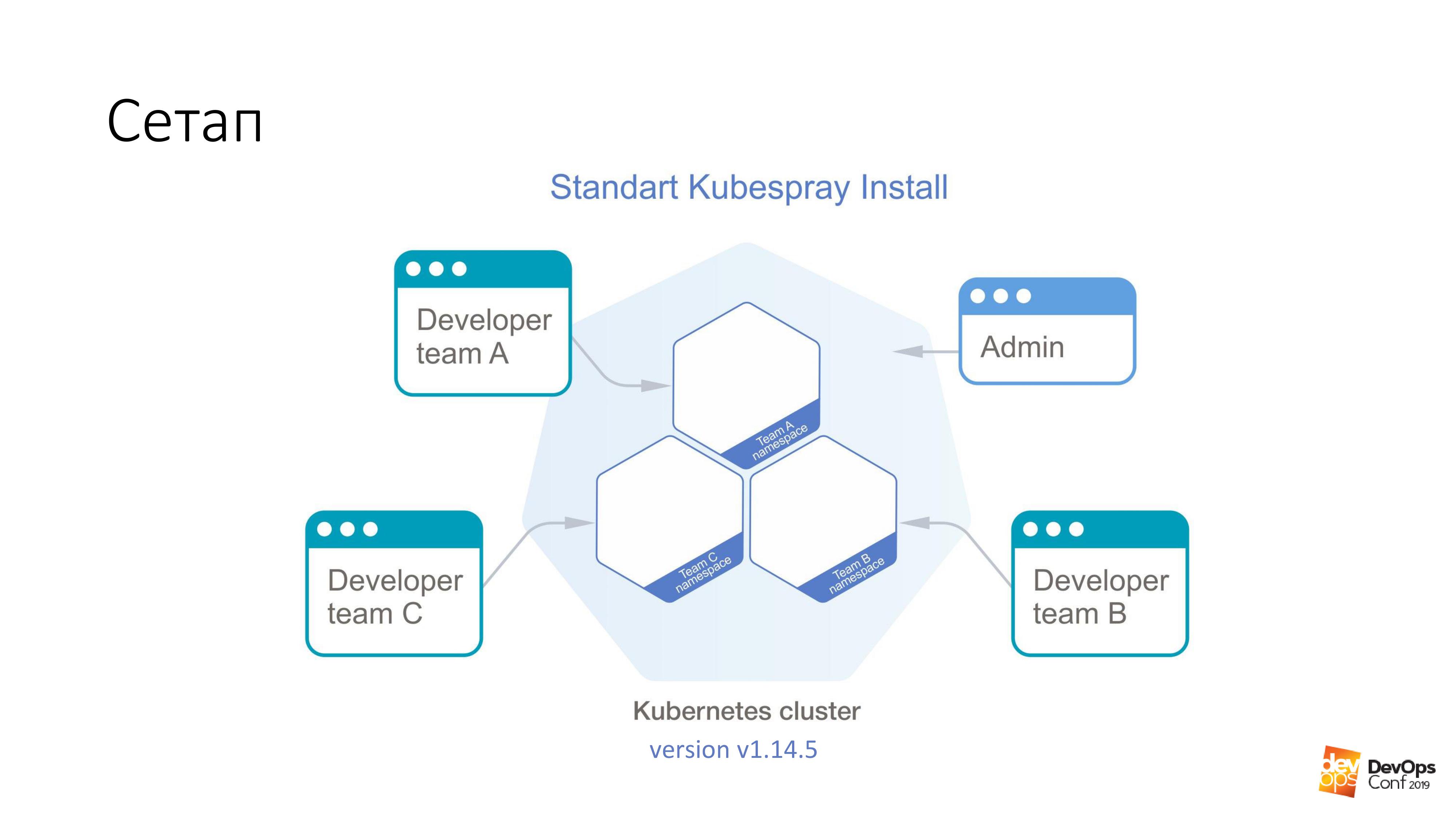
Als Basis nehmen wir die Installation eines Kubernetes-Clusters mit Kubespray. Wenn jemand es nicht weiß, ist dies tatsächlich eine Reihe von Rollen für Ansible. Wir verwenden es ständig in unserer Arbeit. Das Gute ist, dass Sie überall rollen können - Sie können auf den Drüsen und irgendwo in der Wolke rollen. Eine Installationsmethode ist grundsätzlich für alles geeignet.
In diesem Cluster werde ich Kubernetes v1.14.5 haben. Der gesamte Cluster Kubas, den wir betrachten werden, ist in Namespaces unterteilt. Jeder Namespace gehört zu einem separaten Team. Mitglieder dieses Teams haben Zugriff auf jeden Namespace. Sie können nicht zu verschiedenen Namespaces gehen, sondern nur zu ihren eigenen. Es gibt jedoch ein Administratorkonto, das Rechte für den gesamten Cluster hat.
Ich habe versprochen, dass wir als erstes Administratorrechte für den Cluster erhalten werden. Wir brauchen einen speziell vorbereiteten Pod, der den Kubernetes-Cluster zerstört. Wir müssen es nur auf den Kubernetes-Cluster anwenden.
kubectl apply -f pod.yaml
Dieser Pod wird bei einem der Master des Kubernetes-Clusters ankommen. Danach gibt der Cluster gerne eine Datei mit dem Namen admin.conf an uns zurück. In Kuba werden alle Administratorzertifikate in dieser Datei gespeichert und gleichzeitig die Cluster-API konfiguriert. Auf diese Weise können Sie, glaube ich, Administratorzugriff auf 98% der Kubernetes-Cluster erhalten.
Ich wiederhole, dieser Pod wurde von einem Entwickler in Ihrem Cluster erstellt, der Zugriff auf die Bereitstellung seiner Vorschläge in einem kleinen Namespace hat. Er wird vollständig von RBAC geklemmt. Er hatte keine Rechte. Trotzdem ist das Zertifikat zurückgekehrt.
Und nun zum speziell vorbereiteten Herd. Auf einem beliebigen Bild ausführen. Nehmen Sie zum Beispiel debian: jessie.
Wir haben so etwas:
tolerations: - effect: NoSchedule operator: Exists nodeSelector: node-role.kubernetes.io/master: ""
Was ist Toleranz? Die Meister im Kubernetes-Cluster sind normalerweise mit einem so genannten Taint ("Infektion" auf Englisch) gekennzeichnet. Und die Essenz dieser "Infektion" - sie sagt, dass Pods nicht Master-Knoten zugewiesen werden können. Aber niemand stört sich daran, in irgendeiner Weise anzuzeigen, dass er gegenüber der "Infektion" tolerant ist. Der Abschnitt Toleranz sagt nur, dass wenn NoSchedule auf einem Knoten ist, unsere unter einer solchen Infektion tolerant ist - und keine Probleme.
Weiter sagen wir, dass unser Unter nicht nur tolerant ist, sondern auch gezielt auf den Meister fallen will. Weil die Meister die leckersten sind, die wir brauchen - alle Zertifikate. Daher sagen wir nodeSelector - und wir haben eine Standardbezeichnung auf den Assistenten, mit der wir genau die Knoten auswählen können, die Assistenten aus allen Knoten des Clusters sind.
Mit solchen zwei Abschnitten wird er definitiv zum Meister kommen. Und er darf dort leben.
Aber nur zum Meister zu kommen, reicht uns nicht. Es wird uns nichts geben. Daher haben wir weiter diese zwei Dinge:
hostNetwork: true hostPID: true
Wir geben an, dass unser under, das wir starten, im Kernel-Namespace, im Netzwerk-Namespace und im PID-Namespace leben wird. Sobald der Assistent gestartet wird, kann er alle realen Live-Schnittstellen dieses Knotens anzeigen, den gesamten Datenverkehr abhören und die PID aller Prozesse anzeigen.
Als nächstes ist es klein. Nehmen Sie etcd und lesen Sie, was Sie wollen.
Am interessantesten ist diese Kubernetes-Funktion, die dort standardmäßig vorhanden ist.
volumeMounts: - mountPath: /host name: host volumes: - hostPath: path: / type: Directory name: host
Und das Wesentliche ist, dass wir sagen können, dass wir in dem von uns ausgeführten Pod ein Volume vom Typ hostPath erstellen möchten, auch ohne die Rechte an diesem Cluster. Es bedeutet, den Pfad von dem Host zu nehmen, auf dem wir beginnen werden - und ihn als Volume zu nehmen. Und dann nenne es Name: Host. All diesen HostPath montieren wir im Kamin. In diesem Beispiel in das Verzeichnis / host.
Ich wiederhole noch einmal. Wir haben dem Pod gesagt, er soll zum Master kommen, dort hostNetwork und hostPID holen - und die gesamte Wurzel des Masters in diesen Pod einbinden.
Sie verstehen, dass in Debian Bash ausgeführt wird und dieser Bash unter unserer Wurzel funktioniert. Das heißt, wir haben gerade die Wurzel für den Master erhalten, ohne Rechte im Kubernetes-Cluster zu haben.
Dann besteht die ganze Aufgabe darin, in das Verzeichnis unter / host / etc / kubernetes / pki zu wechseln. Wenn ich mich nicht irre, alle Master-Zertifikate des Clusters dort abzurufen und dementsprechend der Cluster-Administrator zu werden.
Wenn Sie so aussehen, sind dies einige der gefährlichsten Rechte in Pods - trotz der Benutzerrechte:

Wenn ich Rechte habe, unter denen ich in einem Cluster-Namespace ausgeführt werden kann, verfügt dieses Sub standardmäßig über diese Rechte. Ich kann privilegierte Pods ausführen, und dies sind im Allgemeinen alle Rechte, praktisch root auf dem Knoten.
Mein Favorit ist Root. Und Kubernetes hat eine solche Option Als Nicht-Root ausführen. Dies ist eine Art Hackerschutz. Wissen Sie, was das "Moldauische Virus" ist? Wenn Sie ein Hacker sind und zu meinem Kubernetes-Cluster kommen, fragen wir, arme Administratoren: „Bitte geben Sie in Ihren Pods an, mit welchen Sie meinen Cluster hacken und als Nicht-Root ausführen. Und es kommt einfach so vor, dass Sie den Prozess in Ihrem Herd unter der Wurzel starten und es für Sie sehr einfach sein wird, mich zu hacken. Bitte schütze dich vor dir. “
Host-Pfad-Volume - meiner Meinung nach der schnellste Weg, um das gewünschte Ergebnis aus dem Kubernetes-Cluster zu erhalten.
Aber was tun mit all dem?
Gedanken, die jedem normalen Administrator einfallen sollten, der auf Kubernetes trifft: „Ja, ich habe dir gesagt, Kubernetes funktioniert nicht. Es gibt Löcher darin. Und der ganze Würfel ist Schwachsinn. " Tatsächlich gibt es so etwas wie Dokumentation, und wenn Sie dort nachsehen, gibt es einen Abschnitt mit Pod-Sicherheitsrichtlinien .
Dies ist ein solches Yaml-Objekt - wir können es im Kubernetes-Cluster erstellen -, das die Sicherheitsaspekte in der Beschreibung der Herde steuert. Das heißt, es steuert tatsächlich diese Rechte zur Verwendung aller Arten von hostNetwork, hostPID und bestimmten Datenträgertypen, die sich beim Start in den Pods befinden. Mit der Pod-Sicherheitsrichtlinie kann all dies beschrieben werden.
Das Interessanteste an der Pod-Sicherheitsrichtlinie ist, dass im Kubernetes-Cluster nicht alle PSP-Installationsprogramme in irgendeiner Weise beschrieben, sondern standardmäßig deaktiviert werden. Die Pod-Sicherheitsrichtlinie wird über das Zulassungs-Plugin aktiviert.
Okay, lassen Sie uns in einer Cluster-Pod-Sicherheitsrichtlinie landen. Nehmen wir an, wir haben eine Art Service-Pods im Namespace, auf die nur Administratoren Zugriff haben. Nehmen wir an, in allen anderen Pods haben sie eingeschränkte Rechte. Da Entwickler höchstwahrscheinlich keine privilegierten Pods in Ihrem Cluster ausführen müssen.
Und bei uns scheint alles in Ordnung zu sein. Und unser Kubernetes-Cluster kann nicht in zwei Minuten gehackt werden.
Es gibt ein Problem. Wenn Sie einen Kubernetes-Cluster haben, wird höchstwahrscheinlich die Überwachung in Ihrem Cluster installiert. Ich gehe sogar davon aus, dass Prometheus als Überwachung bezeichnet wird, wenn in Ihrem Cluster eine Überwachung stattfindet.
Was ich Ihnen jetzt sagen werde, gilt sowohl für den Prometheus-Betreiber als auch für den Prometheus, der in seiner reinen Form geliefert wird. Die Frage ist, dass ich mehr suchen muss, wenn ich den Administrator nicht so schnell in den Cluster einbinden kann. Und ich kann mit Ihrer Überwachung suchen.
Wahrscheinlich lesen alle die gleichen Artikel über Habré, und die Überwachung ist in der Überwachung. Die Helmkarte wird für alle ungefähr gleich genannt. Ich gehe davon aus, dass Sie ungefähr die gleichen Namen erhalten, wenn Sie Stable / Prometheus installieren. Und selbst höchstwahrscheinlich muss ich den DNS-Namen in Ihrem Cluster nicht erraten. Weil es Standard ist.
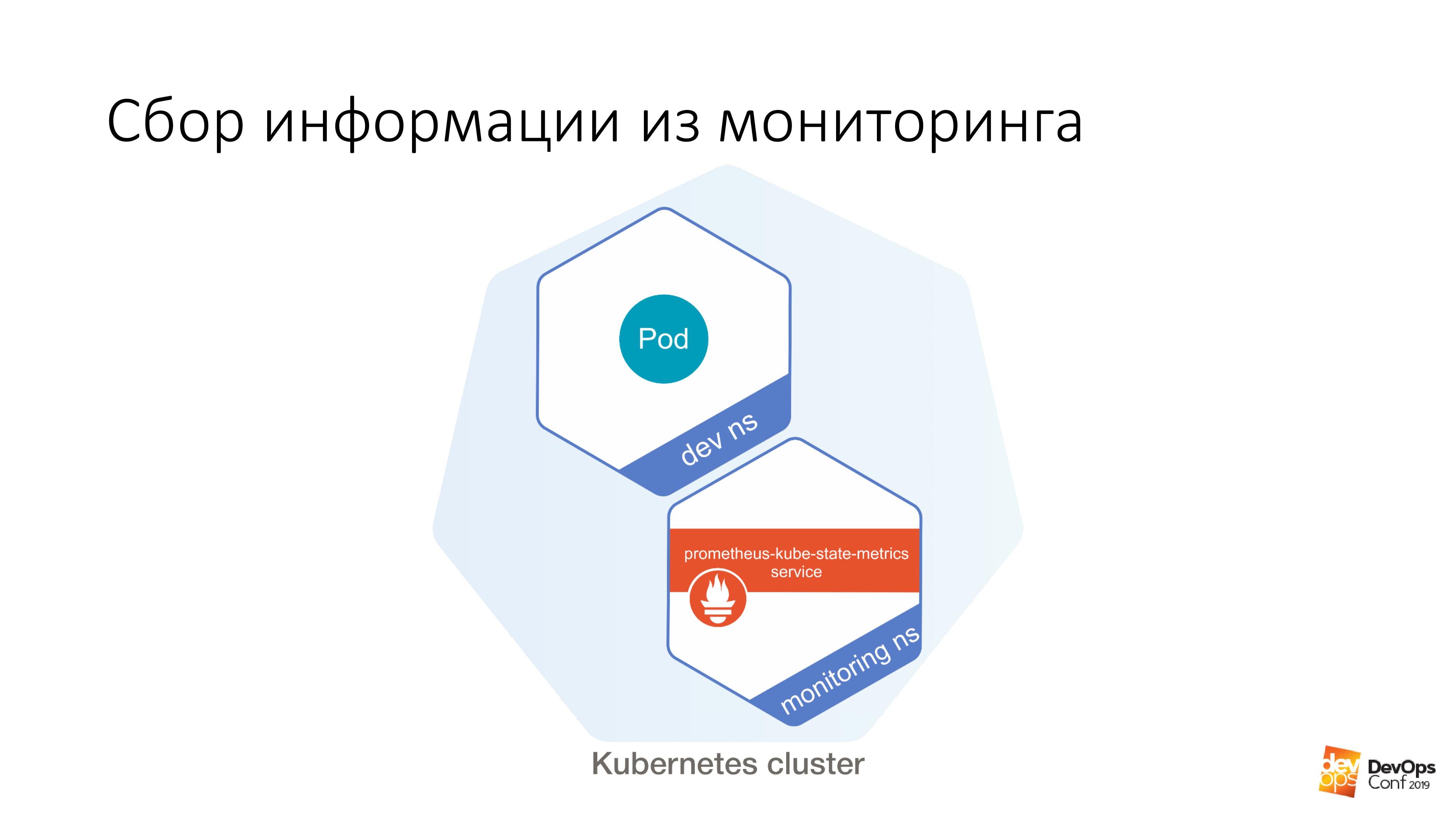
Weiter haben wir eine bestimmte Entwicklung, in der es möglich ist, eine bestimmte Unter zu starten. Und weiter von diesem Herd entfernt ist es sehr einfach, dies zu tun:
$ curl http://prometheus-kube-state-metrics.monitoring
prometheus-kube-state -metrics ist einer der prometheus-Exporteure, der Metriken aus der Kubernetes-API sammelt. In Ihrem Cluster werden viele Daten ausgeführt, was es ist, welche Probleme Sie damit haben.
Als einfaches Beispiel:
kube_pod_container_info {namespace = "kube-system", pod = "kube-apiserver-k8s-1", container = "kube-apiserver", image =
"gcr.io/google-containers/kube-apiserver:v1.14.5"
, Image_id = "Docker-ziehbar: //gcr.io/google-containers/kube- apiserver @ sha256: e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989", container_id = "Docker: // 7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b"} 1
Nachdem Sie eine einfache Curl-Anfrage aus einer nicht privilegierten Datei gestellt haben, können Sie solche Informationen erhalten. Wenn Sie nicht wissen, in welcher Version von Kubernetes Sie ausgeführt werden, können Sie dies leicht feststellen.
Und das Interessanteste ist, dass Sie sich neben der Tatsache, dass Sie sich den Kubikzustandsmetriken zuwenden, genauso direkt auf Prometheus selbst anwenden können. Von dort aus können Sie Metriken sammeln. Von dort aus können Sie sogar Metriken erstellen. Selbst theoretisch können Sie eine solche Anforderung aus einem Cluster in Prometheus erstellen, wodurch sie einfach deaktiviert wird. Und Ihre Überwachung funktioniert im Allgemeinen nicht mehr im Cluster.
Und hier stellt sich bereits die Frage, ob eine externe Überwachung Ihre Überwachung überwacht. Ich hatte gerade die Gelegenheit, im Kubernetes-Cluster ohne Konsequenzen für mich selbst zu agieren. Sie werden nicht einmal wissen, dass ich dort agiere, da es keine Überwachung mehr gibt.
Genau wie bei PSP scheint das Problem zu sein, dass all diese trendigen Technologien - Kubernetes, Prometheus - einfach nicht funktionieren und voller Löcher sind. Nicht wirklich.
Es gibt so etwas - Netzwerkrichtlinien .
Wenn Sie ein normaler Administrator sind, wissen Sie höchstwahrscheinlich über die Netzwerkrichtlinie, dass dies ein weiteres Yaml ist, das im Cluster bereits dofig ist. Und einige Netzwerkrichtlinien werden definitiv nicht benötigt. Und selbst wenn Sie lesen, was Netzwerkrichtlinie ist, was die Kubernetes-Yaml-Firewall ist, können Sie damit die Zugriffsrechte zwischen Namespaces und Pods einschränken. Dann haben Sie sicher entschieden, dass die Yaml-Firewall in Kubernetes in den nächsten Abstraktionen enthalten ist ... Nein, nicht . Dies ist definitiv nicht notwendig.
Selbst wenn Ihren Sicherheitsspezialisten nicht mitgeteilt wurde, dass Sie mit Ihren Kubernetes sehr einfach und unkompliziert eine Firewall erstellen können, ist diese sehr detailliert. Wenn sie dies immer noch nicht wissen und Sie nicht ziehen: "Nun, geben, geben ..." In jedem Fall benötigen Sie eine Netzwerkrichtlinie, um den Zugriff auf einige offizielle Orte zu blockieren, die Sie ohne Genehmigung aus Ihrem Cluster abrufen können.
Wie in dem von mir zitierten Beispiel können Sie die Kube-Statusmetriken aus einem beliebigen Namespace im Kubernetes-Cluster abrufen, ohne Rechte dafür zu haben. Netzwerkrichtlinien schlossen den Zugriff aller anderen Namespaces auf die Namespace-Überwachung und sozusagen auf alles: kein Zugriff, keine Probleme. In allen vorhandenen Diagrammen, sowohl im Standard-Prometeus als auch im Prometeus im Operator, gibt es in den Steuerwerten lediglich eine Option, um einfach Netzwerkrichtlinien für sie zu aktivieren. Sie müssen es nur einschalten und sie werden funktionieren.
Hier gibt es wirklich ein Problem. Als normaler bärtiger Administrator haben Sie höchstwahrscheinlich entschieden, dass Netzwerkrichtlinien nicht benötigt werden. Und nachdem Sie alle Arten von Artikeln über Ressourcen wie Habr gelesen haben, haben Sie entschieden, dass Flanell, insbesondere im Host-Gateway-Modus, das Beste ist, was Sie auswählen können.
Was zu tun ist?
Sie können versuchen, die Netzwerklösung in Ihrem Kubernetes-Cluster erneut bereitzustellen und durch eine funktionalere zu ersetzen. Zum Beispiel auf demselben Calico. Aber sofort möchte ich sagen, dass die Aufgabe, die Netzwerklösung im Kubernetes-Arbeitscluster zu ändern, nicht trivial ist. Ich habe es zweimal gelöst (beide Male jedoch theoretisch), aber wir haben sogar gezeigt, wie man das auf den Slurms macht. Für unsere Schüler haben wir gezeigt, wie die Netzwerklösung im Kubernetes-Cluster geändert werden kann. Im Prinzip können Sie versuchen, sicherzustellen, dass im Produktionscluster keine Ausfallzeiten auftreten. Aber Sie werden wahrscheinlich keinen Erfolg haben.
Und das Problem ist eigentlich sehr einfach gelöst. Der Cluster enthält Zertifikate, und Sie wissen, dass Ihre Zertifikate in einem Jahr fehlerhaft sein werden. Nun, und normalerweise eine normale Lösung mit Zertifikaten im Cluster - warum werden wir dämpfen, wir werden einen neuen Cluster daneben erstellen, ihn im alten faulen lassen und alles wiederholen. Es stimmt, wenn es schlecht wird, wird sich in unserer Zeit alles hinlegen, aber dann ein neuer Cluster.
Wenn Sie einen neuen Cluster erstellen, fügen Sie gleichzeitig Calico anstelle von Flanell ein.
Was tun, wenn Sie seit hundert Jahren Zertifikate ausgestellt haben und den Cluster nicht erneut gruppieren? Es gibt so etwas wie Kube-RBAC-Proxy. Dies ist eine sehr coole Entwicklung, mit der Sie sich als Beiwagencontainer in jeden Herd im Kubernetes-Cluster einbetten können. Und sie fügt diesem Pod tatsächlich eine Autorisierung durch Kubernetes RBAC hinzu.
Es gibt ein Problem. Zuvor war Kube-RBAC-Proxy in den Prometheus des Betreibers eingebaut. Aber dann war er weg. Moderne Versionen basieren jetzt auf der Tatsache, dass Sie über eine Netzwerkrichtlinie verfügen und diese nicht mehr verwenden. Und so müssen Sie das Diagramm ein wenig umschreiben. Wenn Sie zu diesem Repository gehen , gibt es Beispiele für die Verwendung als Beiwagen, und Sie müssen die Diagramme minimal neu schreiben.
Es gibt noch ein kleines Problem. Nicht nur Prometheus gibt seine Metriken an jeden weiter, der sie erhält. Wir haben auch alle Komponenten des Kubernetes-Clusters, sie können ihre Metriken angeben.
Aber wie gesagt, wenn Sie keinen Zugriff auf den Cluster erhalten und keine Informationen sammeln können, können Sie zumindest Schaden anrichten.
Ich zeige Ihnen also schnell zwei Möglichkeiten, wie Sie Ihren Kubernetes-Cluster verderben können.
Sie werden lachen, wenn ich Ihnen sage, dies sind zwei Fälle aus dem wirklichen Leben.
Der erste Weg. Die Ressourcen gehen zur Neige.
Wir starten ein weiteres Special unter. Er wird einen solchen Abschnitt haben.
resources: requests: cpu: 4 memory: 4Gi
Wie Sie wissen, sind Anforderungen die Menge an CPU und Speicher, die auf dem Host für bestimmte Pods mit Anforderungen reserviert ist. Wenn wir einen Vier-Kern-Host im Kubernetes-Cluster haben und vier CPUs mit Anforderungen dorthin kommen, bedeutet dies, dass keine Pods mit Anforderungen an diesen Host mehr kommen können.
Wenn ich dies unter ausführe, mache ich einen Befehl:
$ kubectl scale special-pod --replicas=...
Dann kann niemand anderes im Kubernetes-Cluster bereitstellen. Denn in allen Knoten enden die Anfragen. Und so stoppe ich Ihren Kubernetes-Cluster. Wenn ich dies abends mache, kann ich den Einsatz für einige Zeit einstellen.
Wenn wir uns die Kubernetes-Dokumentation noch einmal ansehen, werden wir so etwas wie den Grenzbereich sehen. Es legt Ressourcen für Clusterobjekte fest. Sie können ein Limit Range-Objekt in yaml schreiben, es auf bestimmte Namespaces anwenden - und weiter in diesem Namespace können Sie sagen, dass Sie über die Ressourcen für die Standard-, Maximum- und Minimum-Pods verfügen.
Mit Hilfe eines solchen Dokuments können wir Benutzer in bestimmten Produkt-Namespaces von Teams auf die Möglichkeit beschränken, böse Dinge auf ihren Pods anzuzeigen. Aber selbst wenn Sie dem Benutzer mitteilen, dass es unmöglich ist, Pods mit Anforderungen von mehr als einer CPU auszuführen, gibt es leider einen so wunderbaren Skalierungsbefehl, oder über das Dashboard können sie skalieren.
Und von hier kommt die Methode Nummer zwei. Wir starten 11 111 111 111 111 Herde. Das sind elf Milliarden. Das liegt nicht daran, dass ich eine solche Nummer gefunden habe, sondern daran, dass ich sie selbst gesehen habe.
Die wahre Geschichte. Am späten Abend wollte ich gerade das Büro verlassen. Ich sehe, eine Gruppe von Entwicklern sitzt in der Ecke und macht hektisch etwas mit Laptops. Ich gehe zu den Jungs und frage: "Was ist mit dir passiert?"
Etwas früher, um neun Uhr abends, ging einer der Entwickler nach Hause. Und er entschied: "Ich überspringe meine Bewerbung jetzt bis zu einer." Ich klickte ein wenig und das Internet ein wenig langweilig. Er klickte erneut auf das Gerät, drückte auf das Gerät und klickte auf die Eingabetaste. Stocherte in allem, was er konnte. Dann wurde das Internet lebendig - und alles begann bis zu diesem Datum zu skalieren.
Diese Geschichte kam zwar nicht auf Kubernetes vor, damals war es Nomad. Es endete mit der Tatsache, dass Nomad nach einer Stunde unserer Versuche, Nomad von hartnäckigen Versuchen abzuhalten, zusammenzuhalten, antwortete, dass er nicht aufhören würde zu kleben und nichts anderes tun würde. "Ich bin müde, ich gehe." Und zusammengerollt.
Ich habe natürlich versucht, dasselbe bei Kubernetes zu tun. Die elf Milliarden Schoten von Kubernetes waren nicht erfreut, sagte er: "Ich kann nicht. Übertrifft die inneren Mundschützer. " Aber 1.000.000.000 Herde könnten.
Als Antwort auf eine Milliarde ging der Würfel nicht hinein. Er begann wirklich zu skalieren. Je weiter der Prozess ging, desto mehr Zeit brauchte er, um neue Herde zu schaffen. Trotzdem ging der Prozess weiter. Das einzige Problem ist, dass ich, wenn ich Pods unbegrenzt in meinem Namespace ausführen kann, auch ohne Anforderungen und Einschränkungen eine solche Anzahl von Pods mit einigen Aufgaben starten kann, dass sich bei diesen Aufgaben die Knoten aus dem Speicher und aus der CPU addieren. Wenn ich so viele Herde betreibe, sollten die Informationen von ihnen in das Repository gehen, d. H. Usw. Und wenn dort zu viele Informationen eintreffen, beginnt das Lagerhaus zu langsam zu verschenken - und bei Kubernetes beginnen langweilige Dinge.
Und noch ein Problem ... Wie Sie wissen, sind die Steuerelemente von Kubernetes nicht nur eine zentrale Sache, sondern mehrere Komponenten. Dort gibt es insbesondere einen Controller-Manager, einen Scheduler usw. Alle diese Leute werden gleichzeitig unnötig dumme Arbeit verrichten, was im Laufe der Zeit immer mehr Zeit in Anspruch nehmen wird. Der Controller-Manager erstellt neue Pods. Der Scheduler versucht, einen neuen Knoten zu finden. Neue Knoten in Ihrem Cluster werden höchstwahrscheinlich bald enden. Der Kubernetes-Cluster beginnt langsamer und langsamer zu arbeiten.
Aber ich beschloss, noch weiter zu gehen. Wie Sie wissen, gibt es in Kubernetes so etwas wie Service. Nun, und standardmäßig in Ihren Clustern funktioniert der Dienst höchstwahrscheinlich mithilfe von IP-Tabellen.
Wenn Sie beispielsweise eine Milliarde Herde betreiben und dann mithilfe von Skripten Kubernetis zwingen, neue Dienste zu erstellen:
for i in {1..1111111}; do kubectl expose deployment test --port 80 \ --overrides="{\"apiVersion\": \"v1\", \"metadata\": {\"name\": \"nginx$i\"}}"; done
Auf allen Knoten des Clusters werden ungefähr gleichzeitig ungefähr neue iptables-Regeln generiert. Darüber hinaus werden für jeden Dienst eine Milliarde Iptables-Regeln generiert.
Ich habe das Ganze an mehreren tausend, bis zu einem Dutzend, überprüft. Und das Problem ist, dass bereits bei dieser Schwelle ssh auf dem Knoten ziemlich problematisch zu tun ist. Weil sich die Pakete, die eine solche Anzahl von Ketten passieren, nicht sehr gut anfühlen.
Und all dies wird auch mit Hilfe von Kubernetes gelöst. Es gibt ein solches Ressourcenkontingentobjekt. Legt die Anzahl der verfügbaren Ressourcen und Objekte für einen Namespace in einem Cluster fest. Wir können in jedem Namespace des Kubernetes-Clusters ein yaml-Objekt erstellen. Mit diesem Objekt können wir sagen, dass wir eine bestimmte Anzahl von Anforderungen und Grenzwerten für diesen Namespace zugewiesen haben, und dann können wir sagen, dass es möglich ist, 10 Dienste und 10 Pods in diesem Namespace zu erstellen. Und ein einzelner Entwickler kann sich zumindest abends quetschen. Kubernetes wird zu ihm sagen: "Sie können Ihre Pods nicht auf einen solchen Betrag bringen, weil er die Ressourcenquote überschreitet." Alles, das Problem ist gelöst. Die Dokumentation finden Sie hier .
Ein problematischer Punkt ergibt sich im Zusammenhang damit. Sie spüren, wie schwierig es wird, in Kubernetes einen Namespace zu erstellen. Um es zu schaffen, müssen wir eine Reihe von Dingen berücksichtigen.
Ressourcenkontingent + Grenzbereich + RBAC
• Erstellen Sie einen Namespace
• Erstellen Sie einen inneren Grenzbereich
• Innerhalb des Ressourcenkontingents erstellen
• Erstellen Sie ein Servicekonto für CI
• Erstellen Sie eine Rollenbindung für CI und Benutzer
• Führen Sie optional die erforderlichen Service-Pods aus
Bei dieser Gelegenheit möchte ich daher meine Entwicklungen mitteilen. Es gibt so etwas, den SDK-Operator. Dies ist eine Möglichkeit im Kubernetes-Cluster, Operatoren dafür zu schreiben. Sie können Anweisungen mit Ansible schreiben.
Zuerst wurde es in Ansible geschrieben, und dann habe ich nach einem SDK-Operator gesucht und die Ansible-Rolle im Operator neu geschrieben. Mit diesem Operator können Sie ein Objekt im Kubernetes-Cluster erstellen, das als Team bezeichnet wird. yaml . , - .
.
. ?
. Pod Security Policy — . , , - .
Network Policy — - . , .
LimitRange/ResourceQuota — . , , . , .
, , , . .
. , warlocks , .
, , . , ResourceQuota, Pod Security Policy . .
.