Flash-Zuverlässigkeit: erwartet und unerwartet. Teil 1. XIV. Konferenz der USENIX Association. DateispeichertechnologienFlash-Zuverlässigkeit: erwartet und unerwartet. Teil 2. XIV. Konferenz der USENIX Association. Dateispeichertechnologien5.5. Nicht behebbare Fehler und Lithografie
Interessanterweise ist die Auswirkung der Lithographie auf nicht korrigierbare Fehler weniger klar als im Fall von RBER, wo eine kleinere Lithographie erwartungsgemäß zu einer höheren RBER führt. Zum Beispiel zeigt 6, dass das SLC-B-Modell eine schnellere Fehlerkorrekturrate als das SLC-A-Modell aufweist, obwohl das SLC-B eine größere Lithographie aufweist (50 nm im Vergleich zu 34 nm für das SLC-A-Modell). Darüber hinaus weisen Modelle der MLC-Serie mit einer kleineren Arbeitsgröße (MLC-B-Modell) in der Regel keine höheren schwerwiegenden Fehlerraten auf als andere Modelle.
Tatsächlich hat dieses Modell während des ersten Drittels seiner Lebensdauer (Anzahl der PE-Zyklen von 0 bis 1000) und im letzten Drittel seiner Lebensdauer (> 2200 PE-Zyklen) eine niedrigere UE-Frequenz als beispielsweise das MLC-D-Modell. Denken Sie daran, dass alle MLC- und SLC-Laufwerke denselben ECC-Mechanismus verwenden, sodass diese Konsequenzen nicht auf Unterschiede in der ECC zurückzuführen sind.
Im Allgemeinen stellen wir fest, dass die Lithographie einen geringeren Effekt als erwartet und einen geringeren Effekt auf nicht korrigierbare Fehler hat als das, was wir bei der Untersuchung des Effekts von RBER beobachtet haben.
5.6. Die Auswirkungen anderer Fehlertypen im Vergleich zu nicht korrigierbaren Fehlern
Überlegen Sie, ob das Vorhandensein anderer Fehler die Wahrscheinlichkeit nicht korrigierbarer Fehler erhöht.
Abbildung 7 zeigt die Wahrscheinlichkeit eines schwerwiegenden Fehlers in einem bestimmten Monat des Festplattenbetriebs, abhängig davon, ob zu einem bestimmten Zeitpunkt im vorherigen Betriebszeitraum (gelbe Farbe der Streifen) oder im vorherigen Monat (grüne Farbe der Streifen) verschiedene Arten von Fehlern auf der Festplatte aufgetreten sind, und einen Vergleich Diese Wahrscheinlichkeit mit der Wahrscheinlichkeit des Auftretens eines nicht korrigierbaren Fehlers (rote Balken) im nächsten Monat.
Wir sehen, dass alle Arten von Fehlern die Wahrscheinlichkeit von nicht korrigierbaren Fehlern erhöhen. In diesem Fall tritt der maximale Anstieg auf, wenn der vorherige Fehler vor relativ kurzer Zeit festgestellt wurde (d. H. Im vorherigen Monat - grüne Balken im Diagramm sind höher als gelb) oder wenn der vorherige Fehler ebenfalls ein nicht korrigierbarer Fehler war. Beispielsweise beträgt die Wahrscheinlichkeit, dass ein schwerwiegender Fehler einen Monat nach einem weiteren schwerwiegenden Fehler auftritt, fast 30%, verglichen mit der Wahrscheinlichkeit von 2%, dass in einem anderen Monat ein schwerwiegender Fehler auftritt. Endgültige Schreibfehler, Metafehler und Löschfehler erhöhen jedoch auch die Wahrscheinlichkeit von UEs um mehr als das Fünffache.
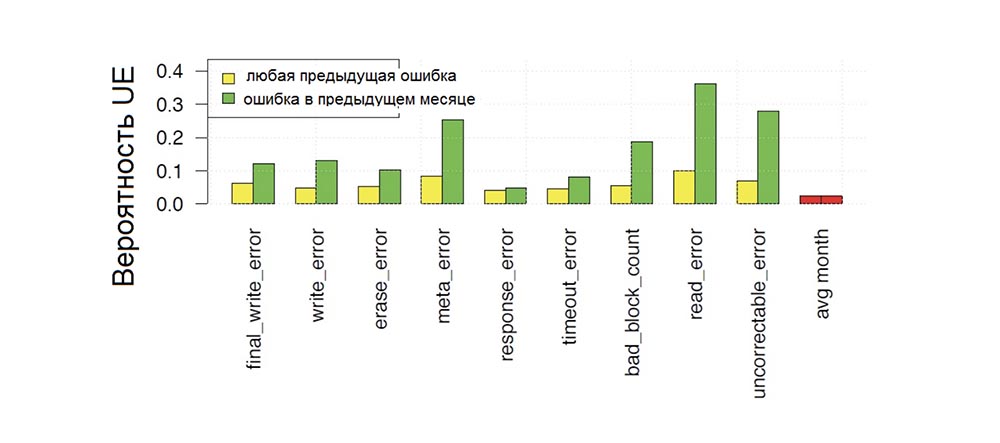 Abb. 7. Die monatliche Wahrscheinlichkeit des Auftretens nicht korrigierbarer Antriebsfehler in Abhängigkeit von der Abhängigkeit vom Vorhandensein früherer Fehler verschiedener Typen.
Abb. 7. Die monatliche Wahrscheinlichkeit des Auftretens nicht korrigierbarer Antriebsfehler in Abhängigkeit von der Abhängigkeit vom Vorhandensein früherer Fehler verschiedener Typen.Somit erhöhen frühere Fehler, insbesondere frühere nicht korrigierbare Fehler, die Wahrscheinlichkeit des nachfolgenden Auftretens nicht korrigierbarer Fehler um mehr als eine Größenordnung.
6. Hardwarefehler
6.1. Beschädigte Blöcke
Ein Block ist ein Speicherabschnitt, in dem Löschvorgänge ausgeführt werden. In unserer Studie unterscheiden wir zwischen Einheiten, die vor Ort beschädigt wurden, und solchen, die bereits Fabrikschäden hatten, als die Laufwerke an Benutzer ausgeliefert wurden.
In unserer Studie haben die Laufwerke den Block nach dem letzten Fehler beim Lesen, Schreiben oder Löschen für beschädigt erklärt und ihn entsprechend neu zugewiesen (dh der Block wurde von der weiteren Verwendung ausgeschlossen und alle Daten, die in diesem Block platziert wurden und wiederhergestellt werden konnten, wurden in einen anderen Block umgeleitet). .
 Tab. 4. Statistiken über das Vorhandensein beschädigter Blöcke, die während der Betriebsbedingungen vor Ort auftreten, und über das Vorhandensein beschädigter Blöcke, die während des Herstellungsprozesses einer Platte in einer Fabrik auftreten.
Tab. 4. Statistiken über das Vorhandensein beschädigter Blöcke, die während der Betriebsbedingungen vor Ort auftreten, und über das Vorhandensein beschädigter Blöcke, die während des Herstellungsprozesses einer Platte in einer Fabrik auftreten.Die obere Hälfte von Tabelle 4 enthält Statistiken zu beschädigten Einheiten in praxiserprobten Laufwerken. Die obere Zeile zeigt den Anteil der Laufwerke mit beschädigten Blöcken für jedes der 10 Laufwerksmodelle. Der Durchschnitt zeigt die durchschnittliche Anzahl der beschädigten Blöcke für die Laufwerke, die beschädigte Blöcke enthalten. Die untere Zeile zeigt die durchschnittliche Anzahl der beschädigten Blöcke unter den Festplatten mit beschädigten Blöcken.
Wir haben nur Laufwerke betrachtet, die vor mindestens vier Jahren in Produktion gegangen sind, und nur die beschädigten Blöcke, die während der ersten vier Jahre der Feldtests entstanden sind. Die untere Hälfte der Tabelle enthält Statistiken zu Laufwerken, bei denen während der Werksherstellung beschädigte Blöcke aufgetreten sind.
6.1.1. Das Auftreten beschädigter Einheiten im Feld
Wir sind zu dem Schluss gekommen, dass beschädigte Blöcke häufig vorkommen: Im Feld sind sie je nach Modell in 30-80% der Festplatten zu finden. Die Untersuchung der kumulativen Verteilungsfunktion (CDF) für die Anzahl der beschädigten Laufwerksblöcke ergab, dass die meisten Festplatten mit beschädigten Blöcken nur eine geringe Anzahl solcher Blöcke aufweisen: Die mittlere Anzahl fehlerhafter Blöcke für Festplatten mit beschädigten Blöcken liegt je nach Modell zwischen 2 und 4. Wenn jedoch die Anzahl der beschädigten Blöcke des Laufwerks sind mehr als der Medianwert, dann ist es normalerweise viel mehr. Dieses Phänomen ist in Abbildung 8 dargestellt.
 Abb. 8. Abbildung zeigt eine Zunahme der Anzahl beschädigter Blöcke in Abhängigkeit von der Anzahl der ursprünglich beschädigten Blöcke.
Abb. 8. Abbildung zeigt eine Zunahme der Anzahl beschädigter Blöcke in Abhängigkeit von der Anzahl der ursprünglich beschädigten Blöcke.Abbildung 8 zeigt, wie sich die mittlere Anzahl beschädigter Antriebsblöcke mit zunehmender Anzahl bereits beschädigter Blöcke entwickelt. Die blaue Linie entspricht den MLC-Modellen, die roten gestrichelten Linien entsprechen den SLC-Modellen. Insbesondere bei MLC-Laufwerken beobachten wir einen starken Anstieg der Anzahl beschädigter Blöcke nach dem zweiten erkannten beschädigten Block, während die mittlere Anzahl auf 200 springt, dh 50% der Festplatten mit 2 beschädigten Blöcken werden erkannt, und im Laufe der Zeit erscheinen 200 oder mehr beschädigte Blöcke.
Solange wir keinen Zugriff auf die Fehlerzählung auf Chipebene haben, werden die beschädigten Blöcke als Hunderte angesehen, wahrscheinlich aufgrund von Ausfällen des Chips selbst. Abbildung 8 zeigt also, dass nach dem Auftreten mehrerer beschädigter Blöcke eine hohe Wahrscheinlichkeit besteht, dass ein ganzer Chip ausfällt. Dieses Ergebnis kann als potenzielle Möglichkeit zur Vorhersage von Chipfehlern dienen, wenn Sie sich auf frühere Berechnungen fehlerhafter Blöcke verlassen und andere Faktoren wie Alter, Arbeitsbelastung und PE-Zyklen berücksichtigen.
Neben der Bestimmung der Häufigkeit des Auftretens fehlerhafter Blöcke möchten wir auch herausfinden, wie beschädigte Blöcke erkannt werden - während Schreib- oder Löschvorgängen, wenn ein Blockfehler für den Benutzer unsichtbar ist oder wenn ein endgültiger Lesefehler auftritt, der für den Benutzer sichtbar ist und das Risiko eines Datenverlusts birgt. Obwohl wir keine Daten zu einzelnen Blockfehlern und deren Erkennung haben, können wir uns auf die beobachteten Häufigkeiten verschiedener Fehlertypen beziehen, die auf einen Blockfehler hinweisen. Zurück zu Tabelle 2 sehen wir, dass bei allen Modellen die Häufigkeit von Lösch- und Schreibfehlern geringer ist als bei endgültigen Lesefehlern, dh die meisten beschädigten Blöcke werden als Ergebnis des Auftretens undurchsichtiger Fehler erkannt, und zwar während Lesevorgängen.
6.1.2. Beschädigte Einheiten im Werk
Oben haben wir die Dynamik des Auftretens fehlerhafter Blöcke im Feld untersucht. Hier stellen wir fest, dass fast alle Festplatten (> 99% für die meisten Modelle) Fabrikfehler in Form beschädigter Blöcke enthielten und ihre Anzahl zwischen den Modellen stark variiert, beginnend mit der mittleren Anzahl von weniger als 100 für 2 SLC-Modelle und endend mit einem typischeren Wert von mehr als 800 für andere Modelle. Die Verteilung der werkseitig beschädigten Blöcke entspricht der Normalverteilung, während der Durchschnitts- und der Medianwert nahe beieinander liegen. Interessanterweise sagt die Anzahl der werkseitig beschädigten Einheiten in gewissem Maße das Auftreten anderer Antriebsprobleme vor Ort voraus. Beispielsweise haben wir festgestellt, dass 95% der Laufwerke mit werkseitig fehlerhaften Blöcken mit Ausnahme eines Laufwerksmodells einen höheren Anteil an neuen beschädigten Blöcken im Feld und einen höheren Anteil an endgültigen Schreibfehlern aufweisen als die durchschnittliche Festplatte derselben Modelle. Sie haben auch einen höheren Anteil an der Entwicklung bestimmter Arten von Lesefehlern (entweder endgültig oder nicht endgültig). Festplatten im 5% -Perzentil weisen einen Anteil von Timeout-Fehlern auf, der unter dem Durchschnitt liegt. Daher kamen wir zu den folgenden Schlussfolgerungen in Bezug auf fehlerhafte Blöcke: Blockschäden treten häufig bei 30-80% der Laufwerke mit mindestens einem solchen Block auf. Gleichzeitig besteht eine starke Abhängigkeit: Wenn die Festplatte mindestens 2-4 beschädigte Blöcke enthält, besteht eine 50% ige Wahrscheinlichkeit, dass Hunderte beschädigter Blöcke folgen. Fast alle Festplatten werden mit werkseitig beschädigten Blöcken geliefert, was Anlass gibt, ihre Entwicklung vor Ort sowie die Entwicklung einiger anderer Arten von Fehlern vorherzusagen.
6.2. Beschädigte Speicherchips
In unserer Studie wird angenommen, dass der Plattenchip ausgefallen ist, wenn mehr als 5% der Blöcke ausgefallen sind oder wenn die Anzahl der Plattenfehler während des letzten Zeitintervalls den Grenzwert überschritten hat. Einige werkseitige Flash-Laufwerke enthalten einen Ersatzchip. Wenn also ein Chip ausfällt, verwendet das Laufwerk den zweiten. In unserer Studie hatten Antriebe die gleiche Funktion. Anstatt an einem Ersatzchip zu arbeiten, wurden beschädigte Speicherchips von der weiteren Verwendung ausgeschlossen, und das Laufwerk arbeitete weiterhin mit reduzierter Leistung auf den verbleibenden Chips.
Die erste Zeile von Tabelle 5 zeigt die Prävalenz beschädigter Chips. Wir sehen, dass 2-7% der Festplatten in den ersten vier Betriebsjahren Chip-Fehlfunktionen aufweisen. Laufwerke ohne Mechanismus zum Zuordnen beschädigter Chips müssen repariert und an den Hersteller zurückgesandt werden.
 Tab. 5. Der Anteil verschiedener Modelle von Festplatten mit fehlerhaften Chips, die während der ersten 4 Jahre der Feldversuche repariert und ersetzt werden müssen.
Tab. 5. Der Anteil verschiedener Modelle von Festplatten mit fehlerhaften Chips, die während der ersten 4 Jahre der Feldversuche repariert und ersetzt werden müssen.Wir haben auch die Symptome untersucht, die dazu führen, dass der Chip als defekt markiert wird: Bei allen Modellen werden etwa zwei Drittel der Chips als beschädigt markiert, nachdem 5% der beschädigten Blöcke gebildet wurden, und ein Drittel der Chips wird als fehlerhaft markiert, nachdem die Anzahl der Tage mit Fehlern erreicht wurde.
Wir haben festgestellt, dass die Lieferanten aller Flash-Speicherchips für diese Laufwerke garantiert haben, dass die Anzahl der beschädigten Blöcke pro Chip 2% nicht überschreitet, bis die Grenze der PE-Zyklen erreicht ist. Daher erfüllen zwei Drittel der fehlerhaften Chips, bei denen mehr als 5% der Blöcke versagten, nicht die Herstellergarantie.
6.3. Reparatur und Austausch von Laufwerken
Der Antrieb muss ausgetauscht oder repariert werden, wenn Probleme auftreten, die das Eingreifen von technischem Personal erfordern. Die zweite Zeile in Tabelle 5 zeigt den Prozentsatz der Festplatten, die zu einem bestimmten Zeitpunkt während der ersten 4 Betriebsjahre repariert werden mussten. Wir beobachten signifikante Unterschiede im Reparaturbedarf von Scheiben verschiedener Modelle. Während für die meisten Modelle zu einem bestimmten Zeitpunkt nur 6–9% repariert werden müssen, müssen einige Antriebsmodelle wie SLC-B und SLC-C in 30% bzw. 26% der Fälle repariert werden. Betrachtet man die relative Häufigkeit von Reparaturen, dh das Verhältnis der Betriebstage des Antriebs zur Anzahl der Reparaturfälle (dritte Zeile in Tabelle 5), so ergibt sich ein Bereich von einigen tausend Tagen zwischen Reparaturereignissen für die schlechtesten Modelle bis zu 15.000 Tagen zwischen Reparaturen für die besten Modelle.
Wir haben auch die Häufigkeit wiederholter Reparaturen untersucht: Während der gesamten Betriebsdauer werden 96% der Festplatten nur einmal repariert. Eine Studie der Flotte von Betriebsplatten ergab, dass ungefähr 5% der Laufwerke innerhalb von 4 Jahren ab dem Datum der Inbetriebnahme (vierte Zeile in Tabelle 5) ständig ausgetauscht wurden, während sie zu den schlechtesten Modellen (MLC-B und SLC-B) gehörten 10% der Laufwerke. Von den ausgetauschten Festplatten ging etwa die Hälfte zur Reparatur, und es wurde davon ausgegangen, dass mindestens die Hälfte aller Reparaturen erfolgreich sein würde.
7. Vergleich von MLC-, eMLC- und SLC-Laufwerken
Aktoren wie eMLC und SLC ziehen den Verbrauchermarkt zu einem höheren Preis an. Neben der Tatsache, dass sie sich durch die höchste Lebensdauer, dh eine hohe Anzahl von Umschreibungszyklen, auszeichnen, sind Kunden der Ansicht, dass solche Produkte des höchsten Segments der SSD durch allgemeine Zuverlässigkeit und Langlebigkeit gekennzeichnet sind. In diesem Abschnitt des Artikels haben wir versucht, die Fairness dieser Meinung zu bewerten.
Zurück zu Tabelle 3 sehen wir, dass diese Meinung in Bezug auf SLC-Festplatten relativ zu RBER zutrifft, da dieser Koeffizient eine Größenordnung niedriger ist als der von MLC- und eMLC-Laufwerken. Die Tabellen 2 und 5 zeigen jedoch, dass SLC-Festplatten nicht die beste Zuverlässigkeit aufweisen: Die Häufigkeit ihres Austauschs und ihrer Reparatur sowie die Häufigkeit undurchsichtiger Fehler sind nicht geringer als bei ähnlichen Indikatoren für Laufwerke, die mit anderen Technologien hergestellt wurden.
EMLC-Laufwerke weisen höhere RBERs als MLCs auf, selbst wenn man bedenkt, dass die unteren RBER-Grenzwerte für MLC-Laufwerke im schlimmsten Fall bis zu 16-mal höher sein können. Es ist jedoch möglich, dass diese Unterschiede aufgrund einer geringeren Lithographie als andere technologische Unterschiede auftreten. Basierend auf den obigen Beobachtungen schließen wir, dass SLC-Laufwerke normalerweise nicht zuverlässiger sind als MLC-Laufwerke.
8. Vergleich mit der Festplatte
Die offensichtliche Frage ist, wie die Zuverlässigkeit von Flash-Laufwerken mit der Zuverlässigkeit ihrer Hauptkonkurrenten - Festplatten - verglichen wird.
Wir stellen fest, dass Flash-Laufwerke gewinnen, wenn es um die Häufigkeit des Austauschs von Festplatten geht. Laut früheren Studien aus dem Jahr 2007 werden jährlich etwa 2 bis 9% der Gesamtzahl der Festplatten ausgetauscht, was deutlich mehr als 4 bis 10% der 4 Jahre nach Inbetriebnahme ausgetauschten SSDs entspricht. Flash-Laufwerke sind jedoch weniger attraktiv, wenn es um Fehlerraten geht. Mehr als 20% der Flash-Laufwerke entwickeln während 4 Betriebsjahren nicht behebbare Fehler, beschädigte Blöcke treten bei 30-80% auf und Chips fallen bei 2-7% aus. Daten aus einem der Forschungsarbeiten von 2007 zeigen, dass in nur 3,5% der Festplatten innerhalb von 32 Monaten beschädigte Sektoren auftreten. Dies ist eine relativ niedrige Zahl, aber da die Gesamtzahl der HDD-Sektoren um eine Größenordnung größer ist als die Anzahl der Blöcke oder Chips von SSDs und diese Sektoren kleiner als die Blöcke sind, scheinen die schlechtesten Eigenschaften von SSDs nicht so schwerwiegend zu sein.
Im Allgemeinen kamen wir zu dem Schluss, dass Flash-Laufwerke innerhalb der normalen Lebensdauer viel seltener ausgetauscht werden müssen als Festplatten. Andererseits weisen SSDs im Vergleich zu Festplatten mehr nicht korrigierbare Fehler auf.
9. Andere Studien in diesem Bereich
Es gibt eine große Menge an Forschung zur Zuverlässigkeit von Flash-Chips, die auf kontrollierten Laborexperimenten mit einer kleinen Anzahl von Chips basiert und sich auf die Identifizierung von Fehlertrends und deren Ursachen konzentriert. Beispielsweise untersuchten einige der frühen Arbeiten von 2002 bis 2006 die Erhaltung, Programmierung und Verletzung der Lesevorgänge von Flash-Chips, und in einigen neueren Arbeiten werden Trends beim Auftreten von Fehlern in den neuesten MLC-Chips untersucht. Wir waren am Verhalten von Flash-Laufwerken im Feld interessiert, daher unterscheiden sich die Ergebnisse unserer Beobachtungen manchmal von den Ergebnissen zuvor veröffentlichter Studien. Zum Beispiel glauben wir, dass RBER kein verlässlicher Indikator für die Wahrscheinlichkeit des Auftretens nicht korrigierbarer Fehler ist und dass RBER eher linear als exponentiell mit PE-Zyklen wächst.
Es gibt nur eine kürzlich veröffentlichte Feldstudie zu Flash-Speicherfehlern, die auf auf Facebook gesammelten Daten basiert - "Großstudie zu Flash-Speicherfehlern im Feld" (MEZA, J., WU, Q., KUMAR, S., MUTLU, O. „Eine groß angelegte Studie über Flash-Speicherfehler vor Ort.“ In Proceedings of the 2015 ACM SIGMETRICS Internationale Konferenz über Messung und Modellierung von Computersystemen, New York, 2015, SIGMETRICS '15, ACM, S. 177–190 ) Dies und unsere Forschung ergänzen sich, da sie sich nur sehr wenig überschneiden.
Die Facebook-Umfragedaten bestehen aus einem kurzen Blick auf die Flotte von Flash-Medien, die aus sehr jungen (in Bezug auf ihre Verwendung im Vergleich zur Grenze der PE-Zykluswerte) Festplatten besteht und nur Informationen über nicht korrigierbare Fehler enthält, während unsere Studie auf basiert Zeitintervalle, die den gesamten Lebenszyklus von Festplatten abdecken und detaillierte Informationen zu verschiedenen Arten von Fehlern enthalten, einschließlich korrigierbarer, verschiedener Arten von Hardwarefehlern sowie Laufwerken verschiedener Technologien (MLC, eMLC, SLC). Infolgedessen deckt unsere Studie ein breiteres Spektrum von Fehler- und Fehlermodi ab, einschließlich der Auswirkung von Verschleiß auf den gesamten Lebenszyklus.
Andererseits berücksichtigt die Facebook-Studie die Rolle einiger Faktoren (Temperatur, Busstromverbrauch, Verwendung des DRAM-Puffers), die wir nicht berücksichtigt haben.
Unsere Studien überschneiden sich nur in zwei kleinen Punkten, und in beiden Fällen kommen wir zu leicht unterschiedlichen Schlussfolgerungen:
- In einer Facebook-Studie wurde das Auftreten nicht korrigierbarer Fehler untersucht. Diese Fehler werden als Funktion der Festplattennutzung untersucht. Die Autoren der Studie beobachten eine signifikante „Kindersterblichkeit“ der Antriebe, die sie als „Früherkennung“ und „Frühversagen“ bezeichnen, während wir dies nicht tun. Die Unterschiede in den Ergebnissen lassen sich sowohl durch das Testen der Laufwerke in den beiden Unternehmen, die das Bild der „Kindersterblichkeit“ beeinflussen könnten, als auch durch die Tatsache erklären, dass sich die Facebook-Forschung mehr auf das frühe Stadium der Festplattenlebensdauer konzentriert (ohne Berücksichtigung von Schlüsselpunkten nach ein paar hundert PE-Zyklen für Festplatten, deren Die PE-Grenze wird in Zehntausenden gemessen. Unsere Studie ist makroskopischer Natur und deckt die gesamte Lebensdauer des Laufwerks ab.
- Eine Facebook-Studie kommt zu dem Schluss, dass Leseverletzungsfehler keine signifikanten Auswirkungen haben. Unsere Sicht auf Fehler dieses Typs ist differenzierter und zeigt, dass Leseverletzungen keine nicht korrigierbaren Fehler verursachen und dass Leseverletzungsfehler mit einer Häufigkeit auftreten, die hoch genug ist, um die RBER im Feld zu beeinflussen.
10. Schlussfolgerungen
Dieser Artikel enthält eine Reihe interessanter Erkenntnisse zur Zuverlässigkeit des Flash-Speichers im Feld. Einige von ihnen stimmen mit allgemein anerkannten Annahmen und Erwartungen überein, während die meisten Schlussfolgerungen unerwartet sind. Nachfolgend präsentieren wir Schlussfolgerungen basierend auf den Ergebnissen unserer Studie.
- Bei 20 bis 63% der Festplatten tritt in den ersten vier Betriebsjahren mindestens ein nicht behebbarer Fehler auf, und die häufigsten nicht behebbaren nicht behebbaren Fehler sind zwei bis 6 von 1000 Betriebstagen.
- In den meisten Tagen des Festplattenbetriebs tritt mindestens ein korrigierbarer Fehler auf, aber andere Arten von transparenten Fehlern, dh Fehler, die für den Benutzer unsichtbar sind, sind im Vergleich zu undurchsichtigen Fehlern selten.
- Wir stellen fest, dass die Standard-RBER-Metrik als Indikator für die Festplattenzuverlässigkeit nicht gut genug ist, um in der Praxis auftretende Fehler vorherzusagen. Insbesondere führt eine höhere RBER nicht notwendigerweise zu einer hohen Häufigkeit nicht korrigierbarer Fehler.
- Wir glauben, dass die Standardmetrik zur Messung schwerwiegender UBER-Fehler nicht objektiv genug ist, da wir die Beziehung zwischen dem UE und der Anzahl der Messwerte nicht gesehen haben. Aus diesem Grund erhöht die Normalisierung nicht korrigierbarer Fehler durch die Anzahl der Lesebits die Fehlerrate für Platten mit einer geringen Anzahl von Leseoperationen künstlich.
- Sowohl RBER als auch die Anzahl der nicht korrigierbaren Fehler nehmen mit dem Wachstum der PE-Zyklen zu, aber Wachstumsraten, die niedriger als erwartet sind, treten linear und nicht exponentiell auf, während es keine scharfen Sprünge gibt, wenn die Scheibe die vom Hersteller für die Betriebsbedingungen festgelegte Grenze der Anzahl der PE-Zyklen überschreitet.
- Während der Verschleiß während des Festplattenbetriebs häufig im Mittelpunkt der Aufmerksamkeit steht, sollte beachtet werden, dass unabhängig vom Alter des Laufwerks die im Feld verbrachte Zeit die Zuverlässigkeit der Festplatte beeinträchtigt.
- SLC-Laufwerke, die auf den Unternehmensmarkt abzielen und zum höheren Produktsegment gehören, sind nicht zuverlässiger als MLC-Laufwerke, die zum unteren Segment der SSDs gehören.
- , RBER, , , .
- , SSD , HDD, , , , .
- . , .
- : , 30-80% 2-7% . () , .
- , , , , , (, , ). , , .
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf einem einzigartigen analogen Einstiegsserver, den wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s ab 20 $ oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden! Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?