Ich habe anscheinend die Angewohnheit, über
leistungsstarke Maschinen zu schreiben, bei denen viele Kerne aufgrund falscher Sperren im
Leerlauf sind. Also ... ja. Nochmals dazu.
Diese Geschichte ist besonders beeindruckend. Wie oft dreht sich ein Thread einige Sekunden lang in einem Zyklus von sieben Befehlen und hält eine Sperre, die die Arbeit von 63 anderen Prozessoren stoppt? Es ist einfach unglaublich, in einem schrecklichen Sinne.
Entgegen der landläufigen Meinung habe ich tatsächlich keine Maschine mit 64 logischen Prozessoren, und ich habe dieses spezielle Problem nie gesehen. Aber mein Freund ist
darauf gestoßen ,
dieser Nerd hat mich süchtig gemacht, er hat um Hilfe gebeten, und ich habe festgestellt, dass das Problem ziemlich interessant ist. Er schickte eine
ETW-Spur mit genügend Informationen, damit der kollektive Verstand auf Twitter das Problem schnell löste.
Die Beschwerde des Freundes war recht einfach: Er sammelte den Build mit
Ninja . In der Regel erhöht Ninja die Last hervorragend und unterstützt ständig n + 2 Prozesse, um Ausfallzeiten zu vermeiden. Aber hier sah die CPU-Auslastung in den ersten 17 Sekunden der Assembly folgendermaßen aus:

Wenn Sie genauer hinschauen (ein Witz), sehen Sie eine dünne Linie, in der die gesamte CPU-Auslastung innerhalb weniger Sekunden von 100% auf 0% sinkt. In nur einer halben Sekunde reduziert sich die Last von 64 auf zwei oder drei Fäden. Hier ist ein vergrößertes Fragment eines dieser Stürze - Sekunden sind entlang der horizontalen Achse markiert:
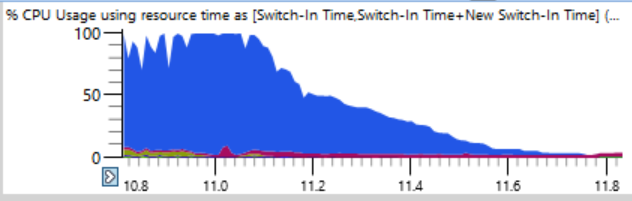
Der erste Gedanke war, dass Ninja nicht schnell Prozesse erstellen kann. Ich habe dies oft gesehen, normalerweise aufgrund des Eingreifens von Antivirensoftware. Aber als ich die Diagramme nach der Endzeit sortierte, stellte ich fest, dass während solcher Abstürze keine Prozesse abgeschlossen wurden, so dass Ninja nicht schuld ist.
Die Tabelle zur
CPU-Auslastung (präzise) ist ideal, um die Ursache für Ausfallzeiten zu ermitteln. Dort werden die Protokolle aller Kontextwechsel gespeichert, einschließlich genauer Aufzeichnungen über jeden Start des Streams, einschließlich Ort und Zeitüberschreitung.
Der Trick ist, dass Ausfallzeiten nichts auszusetzen haben. Das Problem tritt auf, wenn wir wirklich wollen, dass der Thread die Arbeit erledigt, aber stattdessen ist er inaktiv. Daher müssen Sie bestimmte Ausfallzeiten auswählen.
Bei der Analyse ist es wichtig zu verstehen, dass die Kontextumschaltung erfolgt, wenn ein Thread den Betrieb wieder aufnimmt. Wenn wir uns diese Stellen ansehen, an denen die Prozessorlast zu sinken beginnt, werden wir nichts finden. Konzentrieren Sie sich stattdessen darauf, wann das System wieder funktioniert. Diese Spurenphase ist noch dramatischer. Während der CPU-Lastabfall eine halbe Sekunde dauert, dauert der umgekehrte Vorgang von einem verwendeten Thread zu einer vollen Last nur zwölf Millisekunden! Die folgende Grafik ist ziemlich stark vergrößert, und dennoch ist der Übergang vom Leerlauf zur Last fast eine vertikale Linie:

Ich habe auf zwölf Millisekunden gezoomt und 500 Kontextwechsel gefunden. Hier ist eine sorgfältige Analyse erforderlich.
Die Kontextwechsel-Tabelle enthält viele Spalten, die ich hier
dokumentiert habe . Wenn ein Prozess einfriert, um den Grund zu finden, gruppiere ich nach neuen Prozessen, neuen Threads, neuen Thread-Stapeln usw. (
hier beschrieben ), aber dies funktioniert nicht bei Hunderten von gestoppten Prozessen. Wenn ich einen falschen Prozess untersucht habe, ist es klar, dass er durch den vorherigen Prozess vorbereitet wurde, der durch den vorherigen vorbereitet wurde, und ich würde eine lange Kette scannen, um das erste Glied zu finden, das (vermutlich) lange Zeit ein wichtiges Schloss enthält.
Also habe ich ein anderes Spaltenlayout im Programm ausprobiert:
- Einschaltzeit (bei Kontextumschaltung)
- Vorbereitungsprozess (der die Sperre nach dem Warten freigegeben hat)
- Neuer Prozess (wer hat angefangen zu arbeiten)
- Zeit seit dem letzten (wie lange hat der neue Prozess gewartet)
Dies gibt eine zeitlich geordnete Liste von Kontextwechseln mit einer Notiz darüber, wer wen vorbereitet hat und wie lange die Prozesse betriebsbereit waren.
Es stellte sich heraus, dass dies genug ist. Die folgende Tabelle spricht für sich, wenn Sie wissen, wie man sie liest. Die ersten paar Kontextwechsel sind nicht von Interesse, da die Wartezeit für einen neuen Prozess (Time Since Last) recht gering ist, aber in der hervorgehobenen Zeile (# 4) beginnt eine interessante Sache:
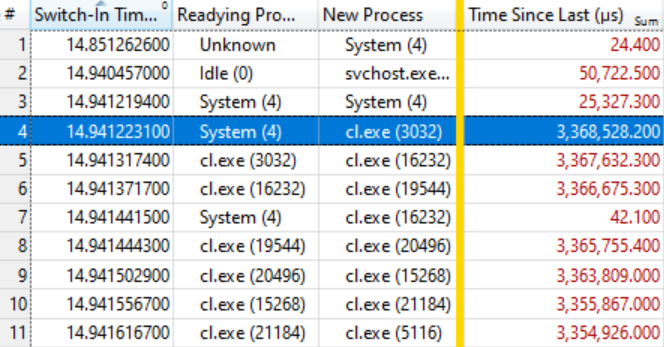
Diese Zeile besagt, dass
System (4) Cl. Exe (3032) vorbereitet hat, das 3,368 Sekunden gewartet hat. Die nächste Zeile besagt, dass
Cl . Exe (3032) in weniger als 0,1 ms
cl.exe (16232) vorbereitet
hat , das 3,367 Sekunden gewartet hat. Usw.
Einige Kontextwechsel, wie in Zeile 7, sind nicht in der Wartekette enthalten, sondern spiegeln einfach andere Arbeiten im System wider, aber im Allgemeinen ist die Kette auf viele zehn Elemente ausgedehnt.
Dies bedeutet, dass alle diese Prozesse auf die Freigabe derselben Sperre warten. Wenn der
System (4) -Prozess die Sperre aufhebt (nach 3.368 Sekunden Halten!), Erfassen die wartenden Prozesse diese wiederum, erledigen ihre kleine Arbeit und geben die Sperre weiter. Die Warteschlange hat ungefähr hundert Prozesse, was den Grad des Einflusses einer einzelnen Sperre anzeigt.
Eine kleine Studie mit
Ready Thread Stacks hat gezeigt, dass die meisten Erwartungen von
KernelBase.dllWriteFile stammen . Ich habe WPA gebeten, die Aufrufer dieser Funktion mit Gruppierung anzuzeigen. Dort können Sie sehen, dass in 12 Millisekunden dieser Katharsis 174 Threads aus dem
WriteFile- Warten
verschwinden und durchschnittlich 1.184 Sekunden gewartet haben:
 174 Threads warten auf WriteFile, durchschnittliche Wartezeit 1.184 Sekunden
174 Threads warten auf WriteFile, durchschnittliche Wartezeit 1.184 SekundenDies ist eine erstaunliche Verzögerung und in der Tat nicht einmal das gesamte Ausmaß des Problems, da viele Threads von anderen Funktionen, wie z. B.
KernelBase.dll! GetQueuedCompletionStatus, die Freigabe derselben Sperre erwarten.
Was macht das System? (4)
Zu diesem Zeitpunkt wusste ich, dass der Build-Fortschritt gestoppt wurde, da alle Compiler-Prozesse und andere
WriteFile erwarteten, da
System (4) die Sperre hielt. Eine weitere Spalte mit der
Ready-Thread-ID zeigte, dass der Thread 3276 die Sperre im Systemprozess aufgehoben hat.
Während aller "Hänge" der Baugruppe war der Thread 3276 zu 100% geladen, sodass klar ist, dass er beim Halten der Sperre einige Arbeiten an der CPU ausgeführt hat. Um herauszufinden, wo die Prozessorzeit verbracht wird, schauen wir uns das
Diagramm zur CPU-Auslastung
(abgetastet) für Stream 3276 an. Die Daten zur CPU-Auslastung erwiesen sich als überraschend klar. Fast die ganze Zeit dauert die Arbeit einer Funktion
ntoskrnl.exe! RtlFindNextForwardRunClear (die Anzahl der Proben ist in der Spalte mit den Zahlen angegeben):
 Der Aufrufstapel führt zu ntoskrnl.exe! RtlFindNextForwardRunClear
Der Aufrufstapel führt zu ntoskrnl.exe! RtlFindNextForwardRunClearAnzeigen des Thread-Stapels Das
Bereitstellen der Thread-ID bestätigte, dass
NtfsCheckpointVolume die Sperre nach 3.368 s
aufgehoben hat:
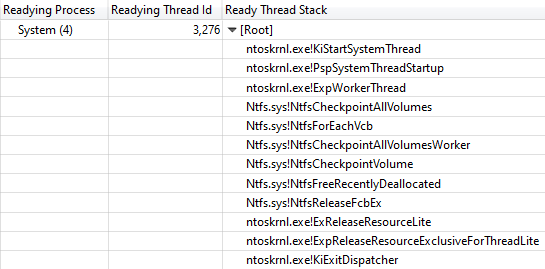 Rufen Sie Stack von NtfsCheckpointVolume zu ExReleaseResourceLite auf
Rufen Sie Stack von NtfsCheckpointVolume zu ExReleaseResourceLite aufIn diesem Moment schien es mir an der Zeit, das reiche Wissen meiner Follower auf Twitter zu nutzen, also stellte ich
diese Frage und zeigte einen vollständigen Anrufstapel. Tweets mit solchen Fragen können sehr effektiv sein, wenn Sie genügend Informationen bereitstellen.
In diesem Fall kam die
richtige Antwort von
Caitlin Gadd sehr schnell, zusammen mit vielen anderen großartigen Vorschlägen. Sie schaltete die Systemwiederherstellungsfunktion aus - und plötzlich ging der Build zwei- bis dreimal schneller!
Aber warte, weiter ist noch besser
Das Blockieren der Ausführung im gesamten System für mehr als 3 Sekunden ist beeindruckend. Die Situation ist jedoch noch beeindruckender, wenn Sie die Spalte
Adresse zur Tabelle
CPU-Auslastung (Stichproben) hinzufügen und danach sortieren. Es zeigt, wo genau in
RtlFindNextForwardRunClear- Samples - und 99% davon fallen auf eine Anweisung!

Ich nahm die
Dateien ntoskrnl.exe und
ntkrnlmp.pdb (dieselbe Version wie mein Freund) und führte
dumpbin /disasm , um die Funktion
dumpbin /disasm , die für Assembler von Interesse ist. Die ersten Ziffern der Adressen sind unterschiedlich, da sich der Code beim Booten bewegt, die letzten vier Hex-Werte jedoch gleich sind (sie ändern sich nach ASLR nicht):
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx
140064652: 73 0F jae 0000000140064663
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663
140064659: 49 83 C0 04 r8.4 hinzufügen
14006465D: 41 83 C1 20 addiere r9d, 20h
140064661: EB EC jmp 000000014006464F
...
Wir sehen, dass die Anweisung zu ... 4657 in einem Zyklus von sieben Anweisungen enthalten ist, die in anderen Beispielen enthalten sind. Die Anzahl solcher Proben ist rechts angegeben:
RtlFindNextForwardRunClear:
...
14006464F: 4C 3B C3 cmp r8, rbx 4
140064652: 73 0F jae 0000000140064663 41
140064654: 41 39 28 cmp dword ptr [r8], ebp
140064657: 75 0A jne 0000000140064663 7498
140064659: 49 83 C0 04 addiere r8.4 2
14006465D: 41 83 C1 20 addiere r9d, 20h 1
140064661: EB EC jmp 000000014006464F 1
...
Lassen Sie uns als Übung für den Leser die Interpretation der Anzahl der Samples auf einem superskalaren Prozessor mit außergewöhnlicher Ausführung von Anweisungen belassen, obwohl einige gute Ideen in
diesem Artikel zu finden sind . In diesem Fall haben wir einen 32-Kern AMD Ryzen Threadripper 2990WX. Offensichtlich ermöglicht die Prozessorfunktion von Micro-Up Fusion mit der Ausführung von fünf Befehlen gleichzeitig tatsächlich, dass jeder Zyklus auf jne abgeschlossen wird, da der Befehl nach dem teuersten Befehl in die Mehrzahl der Unterbrechungen in der Auswahl fällt.
Es stellt sich also heraus, dass ein Computer mit 64 logischen Prozessoren in einem Zyklus von sieben Befehlen im Systemprozess stoppt, während eine wichtige NTFS-Sperre beibehalten wird, die durch Deaktivieren der Systemwiederherstellung behoben wird.
Coda
Es ist nicht klar, warum sich dieser Code auf diesem bestimmten Computer schlecht verhalten hat. Ich nehme an, das hängt irgendwie mit der Verteilung von Daten auf einer fast leeren 2-TB-Festplatte zusammen. Wenn die Systemwiederherstellung wieder aktiviert wurde, trat das Problem ebenfalls auf, jedoch nicht so schwerwiegend. Vielleicht gibt es eine Art Pathologie für Festplatten mit riesigen Fragmenten des leeren Raums?
Ein anderer Follower auf Twitter erwähnte den Volume Shadow Copy-Fehler von Windows 7, der die
Ausführung während O (n ^ 2) ermöglicht . Dieser Fehler wurde angeblich in Windows 8 behoben, wurde aber möglicherweise in irgendeiner Form beibehalten. Meine Stack-Traces zeigen deutlich, dass
VspUpperFindNextForwardRunClearLimited (Suchen eines verwendeten Bits in diesem 16-Megabyte-Bereich)
VspUpperFindNextForwardRunClear aufruft (nach dem nächsten verwendeten Bit sucht, es jedoch nicht
zurückgibt , wenn es außerhalb des angegebenen Bereichs liegt). Dies verursacht natürlich ein gewisses Gefühl von Deja Vu. Wie ich
kürzlich sagte , ist O (n ^ 2) eine Schwachstelle schlecht skalierbarer Algorithmen. Zwei Faktoren stimmen hier überein: Ein solcher Code ist schnell genug, um in die Produktion zu gelangen, aber langsam genug, um diese Produktion einzustellen.
Es gab Berichte, dass ein ähnliches Problem bei einem
massiven Löschen von Dateien auftritt, aber unsere Ablaufverfolgung zeigt nicht viele Löschungen an, so dass das Problem anscheinend nicht das ist.
Abschließend werde ich den systemweiten CPU-Ladeplan ab dem Anfang des Artikels duplizieren, diesmal jedoch die CPU-Auslastung durch den
Systemproblemprozess angeben (unten in grün). In einem solchen Bild ist das Problem völlig offensichtlich. Der Systemprozess ist im oberen Diagramm technisch sichtbar, in dieser Größenordnung jedoch leicht zu übersehen.
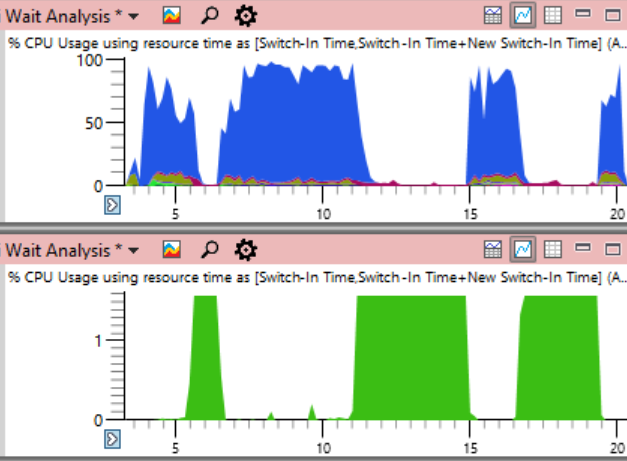
Obwohl das Problem in der Grafik deutlich sichtbar ist, beweist es tatsächlich nichts. Korrelation ist,
wie sie sagen , kein Kausalzusammenhang. Nur eine Analyse von Kontextwechselereignissen zeigt, dass es dieser Stream ist, der die kritische Sperre hält - und dann können Sie sicher sein, dass wir die tatsächliche Ursache gefunden haben und nicht nur eine zufällige Korrelation.
Anfragen
Wie üblich schließe ich diese Untersuchung mit einem
Aufruf ab, die Threads besser zu benennen . Der Systemprozess hat Dutzende von Threads, von denen viele einen speziellen Zweck haben und keiner einen Namen hat. Der am stärksten frequentierte Systemthread in diesem Trace war
MiZeroPageThread . Ich stürzte mich wiederholt in seinen Stapel und jedes Mal erinnerte ich mich, dass es nicht von Interesse war. Der VC ++ - Compiler benennt auch seine Threads nicht. Das Umbenennen der Streams nimmt nicht viel Zeit in Anspruch und ist sehr nützlich. Gib einfach den Namen.
Es ist einfach . Chromium enthält sogar ein Tool zum
Auflisten von Streamnamen in einem Prozess .
Wenn jemand aus dem NTFS-Team von Microsoft über dieses Thema sprechen möchte, lassen Sie es mich wissen, und ich kann Sie mit dem Autor des Originalberichts verbinden und eine ETW-Ablaufverfolgung bereitstellen.
Referenzen