
Hallo habr Wir veröffentlichen weiterhin Rezensionen zu wissenschaftlichen Artikeln von Mitgliedern der Open Data Science-Community über den Kanal #article_essense. Wenn Sie sie vor allen anderen erhalten möchten, treten Sie der Community bei !
Artikel für heute:
- Schichtrotation: ein überraschend starker Indikator für die Verallgemeinerung in tiefen Netzwerken? (Université catholique de Louvain, Belgien, 2018)
- Parametereffizientes Transferlernen für NLP (Google Research, Jagiellonian University, 2019)
- RoBERTa: Ein robust optimierter BERT-Pretraining-Ansatz (University of Washington, Facebook AI, 2019)
- EfficientNet: Überdenken der Modellskalierung für Faltungs-Neuronale Netze (Google Research, 2019)
- Wie das Gehirn von der bewussten zur unterschwelligen Wahrnehmung übergeht (USA, Argentinien, Spanien, 2019)
- Große Speicherschichten mit Produktschlüsseln (Facebook AI Research, 2019)
- Machen wir wirklich große Fortschritte? Eine besorgniserregende Analyse der jüngsten neuronalen Empfehlungsansätze (Politecnico di Milano, Universität Klagenfurt, 2019)
- Omni-Scale Feature Learning zur erneuten Identifizierung von Personen (Universität von Surrey, Queen Mary University, Samsung AI, 2019)
- Neuronale Reparametrisierung verbessert die Strukturoptimierung (Google Research, 2019)
Links zu früheren Sammlungen der Serie: 1. Schichtrotation: Ein überraschend starker Indikator für die Verallgemeinerung in tiefen Netzwerken?
Autoren: Simon Carbonnelle, Christophe De Vleeschouwer (Université catholique de Louvain, Belgien, 2018)
→ Originalartikel
Rezensionsautor: Svyatoslav Skoblov (in slack error_derivative)

In diesem Artikel machten die Autoren auf eine recht einfache Beobachtung aufmerksam: den Kosinusabstand zwischen den Schichtgewichten während der Initialisierung und nach dem Training (der Vorgang des Erhöhens des Abstands während des Trainings wird als Schichtrotation bezeichnet). Die Herren sagen, dass in den meisten Experimenten Netzwerke, die in allen Schichten einen Abstand von 1 erreicht haben, anderen Konfigurationen durchweg überlegen sind. In diesem Artikel wird auch der Layca- Algorithmus (Controlled Amount of Weight Rotation auf Gewichtsebene) vorgestellt, mit dem diese schichtweise Lernrate zur Steuerung derselben Schichtrotation verwendet werden kann. Tatsächlich unterscheidet es sich vom üblichen SGD-Algorithmus durch das Vorhandensein einer orthogonalen Projektion und Normalisierung. Eine detaillierte Auflistung des Algorithmus zusammen mit dem Trainingsschema finden Sie im Artikel.
Die Hauptidee, auf die die Autoren schließen, ist: Je größer die Schichtrotationen sind, desto besser ist die Generalisierungsleistung . Der größte Teil des Artikels ist eine Aufzeichnung von Experimenten, bei denen verschiedene Trainingsszenarien untersucht wurden: MNIST, CIFAR-10 / CIFAR-100, winziges ImageNet mit unterschiedlichen Architekturen, von einem einschichtigen Netzwerk bis zur ResNet-Familie.
Eine Reihe von Experimenten wurde in mehrere Phasen unterteilt:
- Vanilla SGD Es stellte sich heraus, dass das Verhalten der Skalen insgesamt mit der Hypothese übereinstimmt (große Änderungen im Abstand entsprachen den besten metrischen Werten), es wurden jedoch auch Probleme festgestellt: Die Schichtrotation wurde lange vor den gewünschten Werten gestoppt; Es wurde auch eine Instabilität beim Ändern der Entfernung festgestellt.
- SGD + Gewichtsabfall Durch Verringern der Gewichtsnorm wurde das Trainingsbild erheblich verbessert: Die meisten Schichten erreichten die maximale Entfernung, und die Testleistung ähnelt der vorgeschlagenen Layca. Der zweifelsfreie Vorteil der Methode des Autors ist das Fehlen eines zusätzlichen Hyperparameters.
- LR-Aufwärmübungen Es stellte sich heraus, dass das Aufwärmen SGD hilft, das Problem der instabilen Schichtrotation zu überwinden, jedoch keine Auswirkungen auf Layca hat.
- Adaptive Gradientenmethoden Zusätzlich zu der bekannten Wahrheit (dass es mit diesen Methoden schwieriger ist, den Grad der Verallgemeinerung zu erreichen, den SGD + Gewichtsabfall ergeben kann), stellte sich heraus, dass die Auswirkungen der Schichtrotation sehr unterschiedlich sind: Die erste Erhöhung der Rotation in den letzten Schichten, während SGD in den Anfangsschichten . Die Autoren weisen darauf hin, dass dies die Gemeinheit adaptiver Methoden sein könnte. Und sie schlagen vor, Layca in Verbindung mit ihnen zu verwenden (Verbesserung der Fähigkeit zur Verallgemeinerung adaptiver Methoden und Beschleunigung des Lernens bei SGD).
Der Artikel schließt mit einem Versuch, das Phänomen zu interpretieren. Zu diesem Zweck trainierten die Autoren ein Netzwerk mit einer verborgenen Schicht auf einer abgespeckten Version von MNIST. Anschließend visualisierten sie zufällige Neuronen und kamen zu einer logischen Schlussfolgerung: Ein höherer Grad an Schichtrotation entspricht einem geringeren Effekt der Initialisierung und einer besseren Untersuchung der Merkmale, was zu einer verbesserten Generalisierung beiträgt.
Der Code des implementierten Algorithmus (tf / keras) und der Code zur Reproduktion von Experimenten werden hochgeladen .
2. Parametereffizientes Transferlernen für NLP
Autoren des Artikels: Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly (Google Research, Jagiellonen-Universität, 2019)
→ Originalartikel
Rezensionsautor: Alexey Karnachev (in lockerem zhirzemli)
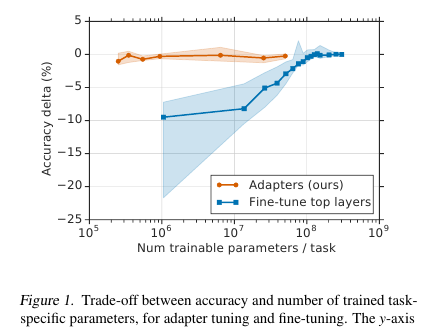
Hier bieten die Herren eine einfache, aber effektive Feinabstimmungstechnik für NLP-Modelle (in diesem Fall BERT) an. Die Idee ist, Lernschichten (Adapter) direkt in das Netzwerk einzubetten. Jede solche Schicht ist ein Netzwerk mit einem Engpass, das die latenten Zustände des ursprünglichen Modells an eine bestimmte nachgelagerte Aufgabe anpasst. Die Gewichte des Originalmodells bleiben wiederum eingefroren.
Motivation
Unter den Bedingungen des Streaming-Trainings (oder des Near-Online-Trainings), bei denen es viele Downstream-Aufgaben gibt, möchte ich nicht wirklich das gesamte Modell einreichen. Erstens ist es für eine lange Zeit schwierig, und zweitens ist es schwierig, und drittens muss das Modell, selbst wenn es eng ist, irgendwie gespeichert werden: um es zu sichern oder im Speicher zu behalten. Und wir werden dieses Modell nicht für die folgende Aufgabe wiederverwenden können: Jedes Mal müssen wir auf eine neue Weise abstimmen. Infolgedessen können wir versuchen, die verborgenen Netzwerkzustände an das aktuelle Problem anzupassen. Darüber hinaus bleibt das ursprüngliche Modell unberührt, und die Adapter selbst sind viel umfangreicher als das Hauptmodell (~ 4% der Gesamtzahl der Parameter).
Implementierung
Das Problem wird auf unglaublich einfache Weise gelöst: Wir fügen jeder Ebene des Modells 2 Adapter hinzu. Vor der Schichtnormalisierung in transformatorbasierten Modellen erfolgt eine Sprungverbindung: Der transformierte Eingang (aktueller verborgener Zustand) wird zum ursprünglichen Eingang hinzugefügt.
In jeder Transformatorschicht befinden sich zwei solcher Abschnitte: einer nach Mehrkopfaufmerksamkeit, der zweite nach Vorwärtskopplung. Somit werden die verborgenen Zustände dieser Abschnitte zusätzlich durch den Adapter geleitet: ein flaches Netzwerk mit einer verborgenen Schicht mit einem Engpass und einer Ausgabe mit derselben Dimension wie die Eingabe. Nichtlinearität wird auf den Engpasszustand angewendet, und Eingabe (Sprungverbindung) wird zur Ausgabe hinzugefügt. Es stellt sich heraus, dass die Gesamtzahl der trainierten Parameter 2 md + m + d beträgt, wobei d die Dimension des verborgenen Zustands des Originalmodells und m die Größe des Engpasses des Adapters ist. Es stellt sich heraus, dass für das BERT-Basismodell (12 Schichten, 110 Millionen Parameter) und für die Größe des Adapter-Bottlneck'a 128 4,3% der Gesamtzahl der Parameter erhalten werden
Ergebnisse
Der Vergleich wurde mit der vollständigen Modellabstimmung durchgeführt. Bei allen Aufgaben zeigte dieser Ansatz einen geringen Verlust an Metriken (im Durchschnitt weniger als 1 Punkt), wobei die Anzahl der trainierten Gewichte 3% der Gesamtzahl betrug. Ich werde die Aufgaben selbst nicht auflisten, es gibt viele davon, es gibt ein Tablet im Artikel.
Feinabstimmung
In diesem Modell ist nur der Adapterteil abgestimmt (+ der Ausgabeklassifikator selbst). Für Adapterskalen schlagen sie eine identitätsnahe Initialisierung vor. Somit wird ein nicht trainiertes Modell die verborgenen Netzwerkzustände in keiner Weise ändern, und dies wird es bereits während des Trainings des Modells ermöglichen, zu entscheiden, welche Zustände für die Aufgabe angepasst und welche unverändert bleiben sollen.
Die Lernrate empfiehlt mehr als bei der Standard-BERT-Feinabstimmung. Persönlich hat 1e-04 lr bei meiner Aufgabe gut funktioniert. Außerdem explodiert das Modell (bereits persönlich meine Beobachtung) während des Abstimmungsprozesses fast immer Gradienten, sodass Sie daran denken müssen, Clipping durchzuführen. Optimierer - Adam mit Aufwärmen 10%
Code
Der Code in ihrem Artikel ist beigefügt. Implementierung auf Tensorflow .
Für Torch gab der Autor der Rezension Pytorch-Transformatoren ab und fügte eine Adapterschicht hinzu (am Anfang der Datei README.md befindet sich ein kleines Starthandbuch).
3. RoBERTa: Ein robust optimierter BERT-Pretraining-Ansatz
Artikelautoren: Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov (Universität Washington, Facebook AI, 2019)
→ Originalartikel
Rezensionsautor: Artem Rodichev (in Slack Fuckai)
Die Qualität der BERT-Modelle wurde dramatisch gesteigert, der erste Platz in der GLUE-Rangliste und SOTA bei vielen NLP-Aufgaben. Sie schlugen eine Reihe von Möglichkeiten vor, um das BERT-Modell so gut wie möglich zu trainieren, ohne die Modellarchitektur selbst zu ändern.
Hauptunterschiede zum Original-BERT:
- Der Zugbau wurde um das Zehnfache von 16 GB Rohtext auf 160 GB erhöht
- Dynamische Maskierung für jede Probe
- Die Verwendung der Vorhersage des Verlusts im nächsten Satz wurde entfernt
- Die Größe der Mini-Charge wurde von 256 Proben auf 8 KB erhöht
- Verbesserte BPE-Codierung durch Übersetzung der Datenbank von Unicode in Bytes.
Das beste endgültige Modell wurde 5 Tage lang auf 1024 Nvidia V100-Karten (128 DGX-1-Server) trainiert.
Das Wesentliche des Ansatzes:
Daten. Zusätzlich zu den Wiki-Shells und BookCorpus (insgesamt 16 GB), in denen das ursprüngliche BERT unterrichtet wurde, wurden drei weitere größere Shells hinzugefügt, alle in englischer Sprache:
- SS-News 63 Millionen Nachrichten in 2,5 Jahren auf 76 GB
- OpenWebText ist das Framework, auf dem OpenAI das GPT2-Modell beigebracht wurde. Dies sind gecrawlte Artikel, zu denen Links in Posts auf einem Reddit mit mindestens drei Updates gegeben wurden. 38 GB Daten
- Geschichten - 31 GB CommonCrawl Story Case
Dynamische Maskierung. Im ursprünglichen BERT sind 15% der Token in jeder Probe maskiert, und diese Token werden unter Verwendung des nicht maskierten Teils der Sequenz vorhergesagt. Während der Vorverarbeitung wird für jede Probe einmal eine Maske generiert, die sich nicht ändert. Gleichzeitig kann dieselbe Probe im Zug je nach Anzahl der Epochen im Körper mehrmals auftreten. Die Idee der dynamischen Maskierung besteht darin, jedes Mal eine neue Maske für die Sequenz zu erstellen, anstatt bei der Vorverarbeitung eine feste zu verwenden.
Ziel der nächsten Satzvorhersage. Lassen Sie uns einfach dieses Objektiv abschneiden und sehen, ob es schlimmer wurde? Ist es besser geworden oder ist es auch geblieben - bei SQuAD-, MNLI-, SST- und RACE-Aufgaben?
Erhöhen Sie die Größe der Mini-Charge. An vielen Stellen, insbesondere in der maschinellen Übersetzung, wurde gezeigt, dass die Endergebnisse des Zuges umso besser sind, je größer die Mini-Charge ist. Sie zeigten, dass, wenn Sie den Minibatch von 256 Proben wie im ursprünglichen BERT auf 2k und dann auf 8k erhöhen, die Ratlosigkeit bei der Validierung abnimmt und die Metriken für MNLI und SST-2 zunehmen.
BPE Die BPE aus der ursprünglichen BERT-Implementierung verwendet Unicode-Zeichen als Basis für Unterworteinheiten. Dies führt dazu, dass in großen und unterschiedlichen Fällen ein erheblicher Teil des Wörterbuchs von einzelnen Unicode-Zeichen belegt wird. OpenAI in GPT2 schlug vor, nicht Unicode-Zeichen, sondern Bytes als Basis für Unterwörter zu verwenden. Wenn wir ein 50k BPE-Wörterbuch verwenden, haben wir keine unbekannten Token. Im Vergleich zum ursprünglichen BERT ist die Modellgröße für das Basismodell um 15 Millionen Parameter und für große Modelle um 20 Millionen gewachsen, dh um 5-10% mehr.
Ergebnisse:
BERT-Large und XLNet-Large werden als Vergleichsmodelle verwendet. RoBERTa selbst hat die gleichen Parameter wie BERT-large. Damit haben sie den ersten Platz im GLUE-Benchmark gewonnen. Im Gegensatz zu vielen anderen Ansätzen des GLUE-Benchmarks, die die Optimierung von Dateien für mehrere Aufgaben durchführen, haben wir die Optimierung von Dateien für einzelne Aufgaben verwendet. Bei den Mädchen in GLUE werden einzelne Modellergebnisse verglichen, sie erhielten SOTA für alle 9 Aufgaben. Auf dem Testset wird das Ensemble von Modellen verglichen, SOTA für 4 von 9 Aufgaben und die endgültige Klebegeschwindigkeit. Auf zwei Versionen von SQuAD im SOTA-Entwicklungsnetzwerk, auf dem Testset auf XLNet-Ebene. Darüber hinaus werden sie im Gegensatz zu XLNet nicht von zusätzlichen QS-Paketen erfasst, bevor sie SQuAD lösen.

SOTA on RACE-Aufgabe, in der ein Textstück gegeben wird, eine Frage zu diesem Text und 4 Antwortoptionen, bei denen Sie die richtige auswählen müssen. Um diese Aufgabe zu lösen, verketten sie den Text, stellen Fragen und Antworten, durchlaufen BERT, erhalten eine Darstellung vom CLF-Token, wenden sie auf eine vollständig verbundene Ebene an und sagen voraus, ob die Antwort korrekt ist. Dies geschieht viermal - für jede der Antwortoptionen.
Wir haben den Code und den Pretrain des RoBERTa-Modells in Fairseq-Rübe veröffentlicht . Sie können es verwenden, alles sieht ordentlich und einfach aus.
4. EfficientNet: Modellskalierung für Faltungs-Neuronale Netze überdenken
Autoren: Mingxing Tan, Quoc V. Le (Google Research, 2019)
→ Originalartikel
Rezensionsautor: Alexander Denisenko (in lockerem Alexander Denisenko)

Sie untersuchen die Skalierung (Skalierung) von Modellen und das Gleichgewicht zwischen Tiefe und Breite (Anzahl der Kanäle) des Netzwerks sowie die Auflösung von Bildern im Raster. Sie bieten eine neue Skalierungsmethode, mit der Tiefe / Breite / Auflösung gleichmäßig skaliert werden können. Zeigen Sie seine Wirksamkeit auf MobileNet und ResNet.
Sie verwenden auch die Suche nach neuronaler Architektur, um ein neues Netz zu erstellen und es zu skalieren, wodurch eine Klasse neuer Modelle erhalten wird - EfficientNets. Sie sind besser und wirtschaftlicher als frühere Netze. In ImageNet erreicht EfficientNet-B7 eine Genauigkeit von 84,4% Top-1 und 97,1% Top-5 auf dem neuesten Stand der Technik, während es 8,4-mal weniger und 6,1-mal schneller bei Inferenz ist als das derzeit beste ConvNet seiner Klasse. Es lässt sich gut auf andere Datensätze übertragen - sie haben SOTA für 5 der 8 beliebtesten Datensätze erhalten.
Zusammengesetzte Modellskalierung
Die Skalierung erfolgt, wenn Operationen innerhalb des Gitters festgelegt sind und nur die Tiefe (Anzahl der Wiederholungen derselben Module) d, die Breite (Anzahl der Kanäle in Faltung) w und die Auflösung r geändert werden. Im Pager wird die Skalierung als Optimierungsproblem formuliert - wir wollen maximale Genauigkeit (Net (d, w, r)), obwohl wir im Speicher und in FLOPS nicht aus dem Rahmen kriechen.
Wir haben Experimente durchgeführt und sichergestellt, dass es auch beim Skalieren in der Breite wirklich hilft, die Tiefe und Auflösung zu skalieren. Mit den gleichen FLOPS erzielen wir mit ImageNet ein deutlich besseres Ergebnis (siehe Bild oben). Im Allgemeinen ist dies vernünftig, da es den Anschein hat, dass mit zunehmender Auflösung des Netzwerkbildes mehr Schichten in der Tiefe benötigt werden, um das Empfangsfeld zu vergrößern, und mehr Kanäle, um alle Muster im Bild mit einer höheren Auflösung zu erfassen.
Die Essenz der zusammengesetzten Skalierung: Wir nehmen den zusammengesetzten Koeffizienten phi, der d, w und r mit diesem Koeffizienten gleichmäßig skaliert: wo - Konstanten, die aus einer kleinen Gitteransicht im Quellgitter erhalten wurden. - Koeffizient, der die Menge der verfügbaren Rechenressourcen kennzeichnet.
Effizientes Netz
Um das Raster zu erstellen, haben wir die Suche nach neuronalen Architekturen mit mehreren Objektiven, die optimierte Genauigkeit und FLOPS mit dem Parameter verwendet, der für den Kompromiss zwischen ihnen verantwortlich ist. Eine solche Suche ergab EfficientNet-B0. Kurz gesagt - Conv, gefolgt von mehreren MBConv am Ende von Conv1x1, Pool, FC.
Führen Sie dann die Skalierung in zwei Schritten durch:
- Zunächst reparieren wir Führen Sie eine Rastersuche für die Suche durch .
- Skalieren Sie das Raster mit den Formeln für d, w und r. Erhielt EffiientNet-B1. Ebenso steigend , erhalten EfficientNet-B2, ... B7.
Für verschiedene ResNet- und MobileNet-Modelle skaliert, wurden überall signifikante Verbesserungen gegenüber ImageNet erzielt. Die zusammengesetzte Skalierung führte zu einer signifikanten Steigerung im Vergleich zur Skalierung in nur einer Dimension. Wir haben auch Experimente mit EfficientNet an acht populäreren Datensätzen durchgeführt, überall dort, wo wir SOTA oder ein Ergebnis in der Nähe mit einer signifikant geringeren Anzahl von Parametern erhalten haben.
Code
5. Wie das Gehirn von der bewussten zur unterschwelligen Wahrnehmung übergeht
Autoren des Artikels: Francesca Arese Lucini, Gino Del Ferraro, Mariano Sigman, Hernan A. Makse (USA, Argentinien, Spanien, 2019)
→ Originalartikel
Rezensionsautor: Svyatoslav Skoblov (in slack error_derivative)
Dieser Artikel ist eine Fortsetzung und ein Umdenken der Arbeit von Dehaene, S, Naccache, L, Cohen, L, Le Bihan, D, Mangin, JF, Poline, JB und Rivie`re, D. Zerebrale Mechanismen der Wortmaskierung und der unbewussten Wiederholungsgrundierung in die Autoren versuchten, die Modi der bewussten und unbewussten Gehirnfunktion zu berücksichtigen.
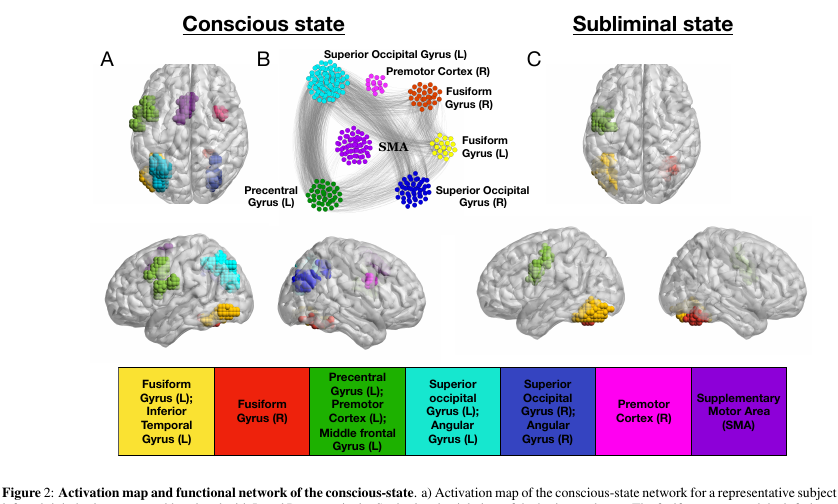
Experiment:
Freiwilligen werden Bilder gezeigt (Wörter mit 4 Buchstaben oder ein leerer Bildschirm oder Kritzeleien). Jeder von ihnen wird 30 ms lang angezeigt. Im Allgemeinen dauert die gesamte Aktion 5 Minuten.
- Im "bewussten" Modus des Experiments wechselt ein leerer Bildschirm mit Wörtern ab, wodurch eine Person den Text bewusst wahrnehmen kann.
- Im „unbewussten“ Modus wechseln sich Wörter mit Kritzeleien ab, was die Wahrnehmung des Textes auf bewusster Ebene sehr effektiv beeinträchtigt.
Daten:
Während dieser Präsentation wurden die Gehirne unserer Primaten mit fMRI gescannt. Insgesamt hatten die Forscher 15 Freiwillige, die das Experiment jeweils fünfmal wiederholten, insgesamt 75 fMRI-Ströme. Es ist erwähnenswert, dass der Voxel-Scan ziemlich groß war (sehr vereinfacht: Voxel ist ein 3D-Würfel, der eine ziemlich große Anzahl von Zellen enthält) - 4 x 4 x 4 mm.
Magie:
Rufen wir den Node Active Voxel aus unserem Stream auf. Da das Gehirn ein modularer Waschlappen ist, führen wir zwei Arten von Verbindungen ein: externe und interne (entsprechend der räumlichen Anordnung der Knoten). Verbindungen werden auf interessante Weise zusammengesetzt: Wir erstellen eine Kreuzkorrelationsmatrix zwischen Knoten und verbinden die Knoten mit einer Verbindung, wenn die Korrelation größer als ein adaptiver Parameter Lambda ist. Dieser Parameter wirkt sich auf die Entladung unseres Netzwerks aus.
Die Parametereinstellung erfolgt nach dem "Filter" -Verfahren. Wenn wir unser Lambda ein wenig beeinflussen, werden scharfe Übergänge zwischen den endgültigen Dimensionen des Netzwerks bemerkbar (d. H. Eine ausreichend kleine Parameteränderung entspricht einem großen Größenzuwachs).
Also: Interne Verbindungen werden durch den Lambda-1-Wert aktiviert, der dem Lambda-Wert unmittelbar vor einem scharfen Übergang entspricht. Extern - Lambda-2-Wert, der dem Lambda-Wert unmittelbar nach einem scharfen Übergang entspricht.
Magie 2:
K-Core-Filterung. Das k-Core-Konzept beschreibt die Netzwerkkonnektivität und ist ganz einfach formuliert: das maximale Subnetz, dessen Knoten alle mindestens k Nachbarn haben. Ein solches Subnetz kann durch iteratives Entfernen von Knoten mit weniger als k Nachbarn erhalten werden. Da die verbleibenden Knoten Nachbarn verlieren, wird der Vorgang fortgesetzt, bis nichts mehr zu löschen ist. Was bleibt, ist das k-Core-Netzwerk.
Ergebnisse:
Wenn Sie diese Artillerie auf unser Gehirn anwenden, können Sie eine Reihe sehr interessanter Merkmale erkennen.
- Die Anzahl der Knoten im k-Kern mit kleinem / sehr großem k ist extrem groß. Für Medium k ist es im Gegenteil nicht genug. Auf dem Bild sieht es aus wie eine U-Form, dh eine solche Netzwerkkonfiguration bietet die größte Stabilität des Systems (Beständigkeit gegen lokale und globale Fehler).
- und die wichtigsten Knoten, die zum k-Kern mit kleinem k gehören, können in fast jedem Zustand des Netzwerks gesehen werden. Ein k-Kern mit sehr großem k ist jedoch nur für diejenigen Teile des Gehirns charakteristisch, die im unbewussten Zustand Fusiform Gyrus & Left Precentral Gyrus aktiv sind . .
, rewiring, ( , ). k. , U shape , , .
Schlussfolgerungen:
, , , . , , , - ( , , , ).
, , , , , , , - . , , qualia.
6. Large Memory Layers with Product Keys
: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→
: ( belerafon)

, key-value , .
- attention. q, k v. q, k, , value . , . , . , , . - q (, -10). . .
— q k . , "Product Keys". , q , . -10 , , O(N) "" , (sqrt(N)).
key-value . , ( , ). , BERT 28 . , , . : 12- 2 , 24- , perplexity .
( self-attention). , - . , multy-head attention. Das heißt, query , value, . -.
, , , , BERT . .
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→
: ( netcitizen)

DL , , .
DL top-n. DL KDD, SIGIR, TheWebConf (WWW) RecSys :
- -
- 7/18 (39%)
- “” train/test, ., , , .
- (Variational Autoencoders for Collaborative Filtering (Mult-VAE) ± ) KNN, SVD, PR.
DL, CV, NLP , .
8. Omni-Scale Feature Learning for Person Re-Identification
: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→
: ( graviton)
Person Re-Identification, Face Recognition, , . (Kaiyang Zhou) deep-person-reid , (OSNet), Person Re-Identification. .
Person Re-Identification:

:
- conv1x1 deepwise conv3x3 conv3x3 (figure 3).
- , . ResNeXt , Inception (figure 4).
- “aggregation gate” . , Inception .

OSNet , .. , : ( , ) .
ReID-Testergebnisse für OSNet (ca. 2 Millionen Parameter) zeigen den Vorteil dieser Architektur gegenüber anderen Lichtmodellen (Markt: R1 93,6%, mAP 81,0% für OSNet und R1 87,0%, mAP 69,5% für MobileNetV2) und das Fehlen eines signifikanten Unterschieds in der Genauigkeit mit schwere Modelle von ResNet und DenseNet (Markt: R1 94,8%, mAP 84,9% für OSNet und R1 94,8%, mAP 86,0% für ResNet).
Eine weitere Herausforderung ist die Domänenanpassung : Modelle, die auf einem Datensatz trainiert wurden, weisen auf einem anderen eine schlechte Qualität auf. OSNet zeigt auch in diesem Segment gute Ergebnisse ohne die Verwendung einer „unbeaufsichtigten Domänenanpassung“ (Verwendung von Testdaten in nicht zugeordneter Form, um die Verteilung von Daten auszugleichen).
Die Architektur wurde auch in ImageNet getestet, wo sie mit MobileNetV2 eine ähnliche Genauigkeit mit weniger Parametern, aber mehr Operationen erreichte.
9. Neuronale Reparametrisierung verbessert die Strukturoptimierung
Autoren: Stephan Hoyer, Jascha Sohl-Dickstein, Sam Greydanus (Google Research, 2019)
→ Originalartikel
Rezensionsautor: Alexey (in Arech locker)
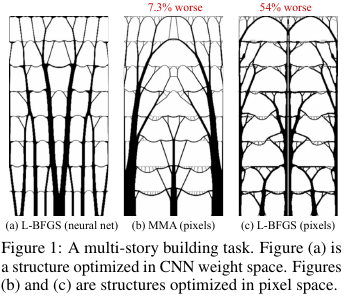
In der Konstruktion und anderen Technologien gibt es Aufgaben zur Optimierung der Struktur / Topologie einer Lösung. Grob gesagt ist dies eine Computerantwort auf eine Frage wie zum Beispiel, wie eine Brücke / ein Gebäude / ein Flügel eines Flugzeugs / einer Turbinenschaufel / einer Blablabla so konstruiert werden soll, dass bestimmte Einschränkungen erfüllt werden und die Struktur stark genug ist. Es gibt eine Reihe von "Standard" -Lösungsmethoden - es funktioniert, aber dort ist nicht immer alles reibungslos.
Was haben sich diese Leute von Google ausgedacht? Sie sagten: Lassen Sie uns eine Lösung durch ein neuronales Netzwerk (den Upsampling-Teil von UNet) generieren und dann unter Verwendung eines differenzierbaren physikalischen Modells, das das Verhalten einer Lösung unter dem Einfluss aller Kräfte und der Schwerkraft berechnet, die Zielfunktion - Stärke (genauer gesagt die Umkehrung davon - Compliance) berechnen. ) Designs. Da dann alles automatisch differenzierbar ist, erhalten wir den Gradienten der Zielfunktion, der durch die gesamte Struktur zurück zu den Gewichten und der Eingabe des neuronalen Netzwerks geschoben wird. Wir ändern Gewichte und Eingabe und setzen den Zyklus bis zur Konvergenz zu einer stabilen Lösung fort.
Es stellte sich heraus, dass die Ergebnisse kleine (in Bezug auf die Größe des Raums möglicher Lösungen) Probleme betrafen, die mit herkömmlichen Methoden zur Optimierung von Topologien vergleichbar sind, und dass große Probleme deutlich besser sind als herkömmliche (Übergewicht bei 99 gegenüber 66 von 116 Problemen). Darüber hinaus sind die resultierenden Lösungen oft wesentlich technologischer und optimaler als die Entscheidungen von Baselines.
Das heißt, Tatsächlich verwendeten sie den NS als eine schwierige Methode zur Parametrisierung des physikalischen Modells der Struktur, die implizit (dank der Architektur des NS) einige nützliche Einschränkungen für Parameterwerte auferlegen kann (gesteuert durch Entfernen des NS aus der Methode und direkte Optimierung der Pixelwerte).
Quellcode.
Eine detailliertere Übersicht über diesen Artikel auf habr.