Fliegender Wagen, Afu ChanIch arbeite bei
Mail.ru Cloud Solutons als Architekt und Entwickler, einschließlich meiner Cloud. Es ist bekannt, dass eine verteilte Cloud-Infrastruktur einen produktiven Blockspeicher benötigt, von dem der Betrieb der mit ihnen erstellten PaaS-Dienste und -Lösungen abhängt.
Anfangs haben wir bei der Bereitstellung einer solchen Infrastruktur nur Ceph verwendet, aber nach und nach hat sich der Blockspeicher weiterentwickelt. Wir wollten, dass
unsere Datenbanken , der Dateispeicher und verschiedene Dienste mit maximaler Leistung funktionieren. Deshalb haben wir lokalisierte Speicher hinzugefügt und die erweiterte Ceph-Überwachung eingerichtet.
Ich werde Ihnen sagen, wie es war - vielleicht ist diese Geschichte, die Probleme, auf die wir gestoßen sind, und unsere Lösungen für diejenigen nützlich, die auch Ceph verwenden.
Hier ist übrigens
eine Videoversion dieses Berichts.
Von DevOps-Prozessen zu Ihrer eigenen Cloud
DevOps-Praktiken zielen darauf ab, das Produkt so schnell wie möglich einzuführen:
- Automatisierung von Prozessen - der gesamte Lebenszyklus: Montage, Prüfung, Lieferung an den Test und produktiv. Automatisieren Sie Prozesse schrittweise, beginnend mit kleinen Schritten.
- Infrastruktur als Code ist ein Modell, wenn der Infrastrukturkonfigurationsprozess dem Softwareprogrammierungsprozess ähnlich ist. Zuerst testen sie das Produkt, das Produkt hat bestimmte Anforderungen an die Infrastruktur und die Infrastruktur muss getestet werden. In diesem Stadium, wenn Wünsche für sie auftauchen, möchte ich die Infrastruktur „optimieren“ - zuerst in der Testumgebung, dann im Lebensmittelgeschäft. In der ersten Phase kann dies manuell erfolgen, dann geht es jedoch zur Automatisierung über - zum Modell „Infrastruktur als Code“.
- Virtualisierung und Container - erscheinen im Unternehmen, wenn klar ist, dass Sie Prozesse auf eine industrielle Spur bringen müssen, um neue Funktionen schneller und mit minimalem manuellen Eingriff einzuführen.
 Die Architektur aller virtuellen Umgebungen ist ähnlich: Gastcomputer mit Containern, Anwendungen, öffentlichen und privaten Netzwerken, Speicher.
Die Architektur aller virtuellen Umgebungen ist ähnlich: Gastcomputer mit Containern, Anwendungen, öffentlichen und privaten Netzwerken, Speicher.Allmählich werden immer mehr Dienste in der virtuellen Infrastruktur bereitgestellt, die in und um DevOps-Prozesse aufgebaut ist, und die virtuelle Umgebung wird nicht nur zu einem Test (der für Entwicklung und Test verwendet wird), sondern auch produktiv.
In der Regel werden sie in der Anfangsphase von den einfachsten grundlegenden Automatisierungstools umgangen. Da jedoch neue Tools angezogen werden, muss früher oder später eine vollwertige Cloud-Plattform bereitgestellt werden, um die fortschrittlichsten Tools wie Terraform verwenden zu können.
In dieser Phase verwandelt sich die virtuelle Infrastruktur aus „Hypervisoren, Netzwerken und Speicher“ in eine vollwertige Cloud-Infrastruktur mit entwickelten Tools und Komponenten für die Orchestrierung von Prozessen. Dann erscheint eine eigene Cloud, in der die Prozesse zum Testen und automatisierten Bereitstellen von Updates für vorhandene Dienste sowie zum Bereitstellen neuer Dienste stattfinden.
Der zweite Weg zu Ihrer eigenen Cloud ist die Notwendigkeit, nicht von externen Ressourcen und externen Dienstanbietern abhängig zu sein, dh eine gewisse technische Unabhängigkeit für Ihre eigenen Dienste zu gewährleisten.
 Die erste Cloud sieht fast wie eine virtuelle Infrastruktur aus - ein Hypervisor (eine oder mehrere), virtuelle Maschinen mit Containern, gemeinsam genutzter Speicher: Wenn Sie die Cloud nicht auf proprietären Lösungen aufbauen, handelt es sich normalerweise um Ceph oder DRBD.
Die erste Cloud sieht fast wie eine virtuelle Infrastruktur aus - ein Hypervisor (eine oder mehrere), virtuelle Maschinen mit Containern, gemeinsam genutzter Speicher: Wenn Sie die Cloud nicht auf proprietären Lösungen aufbauen, handelt es sich normalerweise um Ceph oder DRBD.Ausfallsicherheit und Leistung der Private Cloud
Die Cloud wächst, das Geschäft hängt immer mehr davon ab, das Unternehmen fordert zunehmend mehr Zuverlässigkeit.
Hier wird die verteilte Cloud der verteilten Cloud-Infrastruktur hinzugefügt: zusätzliche Punkte, an denen sich die Geräte befinden. Die Cloud verwaltet zwei, drei oder mehr Installationen, die eine fehlertolerante Lösung bieten.
Gleichzeitig werden Daten von allen Standorten benötigt, und es gibt ein Problem: Innerhalb eines Standorts treten keine großen Verzögerungen bei der Datenübertragung auf, aber zwischen Standorten werden die Daten langsamer übertragen.
 Installationsorte und gemeinsamer Speicher. Rote Rechtecke sind Engpässe auf Netzwerkebene.
Installationsorte und gemeinsamer Speicher. Rote Rechtecke sind Engpässe auf Netzwerkebene.Der externe Teil der Infrastruktur ist aus Sicht des Verwaltungsnetzwerks oder des öffentlichen Netzwerks nicht so ausgelastet, aber im internen Netzwerk sind die übertragenen Datenmengen viel größer. Und in verteilten Systemen beginnen Probleme, die sich in einer langen Servicezeit äußern. Wenn der Client zu einer Gruppe von Speicherknoten kommt, müssen die Daten sofort in die zweite Gruppe repliziert werden, damit die Änderungen nicht verloren gehen.
Für einige Prozesse ist die Datenreplikationslatenz akzeptabel, aber in Fällen wie der Transaktionsverarbeitung können Transaktionen nicht verloren gehen. Wenn die asynchrone Replikation verwendet wird, tritt eine Zeitverzögerung auf, die zum Verlust eines Teils der Daten führen kann, wenn einer der „Schwänze“ des Speichersystems (Datenspeichersystem) ausfällt. Wenn die synchrone Replikation verwendet wird, erhöht sich die Servicezeit.
Es ist auch ganz natürlich, dass mit zunehmender Verarbeitungszeit (Latenz) des Speichers die Datenbanken langsamer werden und negative Auswirkungen bekämpft werden müssen.
In unserer Cloud suchen wir nach ausgewogenen Lösungen, um Zuverlässigkeit und Leistung zu gewährleisten. Die einfachste Technik besteht darin, die Daten zu lokalisieren - und dann haben wir zusätzliche lokalisierte Ceph-Cluster hinzugefügt.
 Die grüne Farbe zeigt zusätzliche lokalisierte Ceph-Cluster an.
Die grüne Farbe zeigt zusätzliche lokalisierte Ceph-Cluster an.Der Vorteil einer solch komplexen Architektur besteht darin, dass diejenigen, die eine schnelle Dateneingabe / -ausgabe benötigen, lokalisierte Speicher verwenden können. Daten, für die die vollständige Verfügbarkeit an zwei Standorten von entscheidender Bedeutung ist, befinden sich in einem verteilten Cluster. Es funktioniert langsamer - aber die darin enthaltenen Daten werden auf beide Sites repliziert. Wenn die Leistung nicht ausreicht, können Sie lokalisierte Ceph-Cluster verwenden.
Die meisten öffentlichen und privaten Clouds erreichen schließlich ungefähr das gleiche Arbeitsmuster, wenn die Last je nach Anforderungen in verschiedenen Arten von Speichern (verschiedenen Arten von Festplatten) bereitgestellt wird.
Ceph-Diagnose: Aufbau einer Überwachung
Bei der Bereitstellung und dem Start der Infrastruktur war es an der Zeit, deren Funktion sicherzustellen und Zeit und Anzahl der Ausfälle zu minimieren. Daher war der nächste Schritt bei der Entwicklung der Infrastruktur der Aufbau von Diagnose und Überwachung.
Betrachten Sie die Überwachungsaufgabe durchgehend - wir haben einen Stapel von Anwendungen in einer virtuellen Cloud-Umgebung: eine Anwendung, ein Gastbetriebssystem, ein Blockgerät, die Treiber dieses Blockgeräts auf einem Hypervisor, ein Speichernetzwerk und das eigentliche Speichersystem (Speichersystem). Und all dies wurde noch nicht durch Überwachung abgedeckt.
 Elemente, die nicht überwacht werden.
Elemente, die nicht überwacht werden.Die Überwachung erfolgt in mehreren Schritten, wir beginnen mit Festplatten. Wir erhalten die Anzahl der Lese- / Schreibvorgänge, eine gewisse Genauigkeit, die Servicezeit (Megabyte pro Sekunde), die Warteschlangentiefe und andere Merkmale und erfassen SMART über den Status der Festplatten.
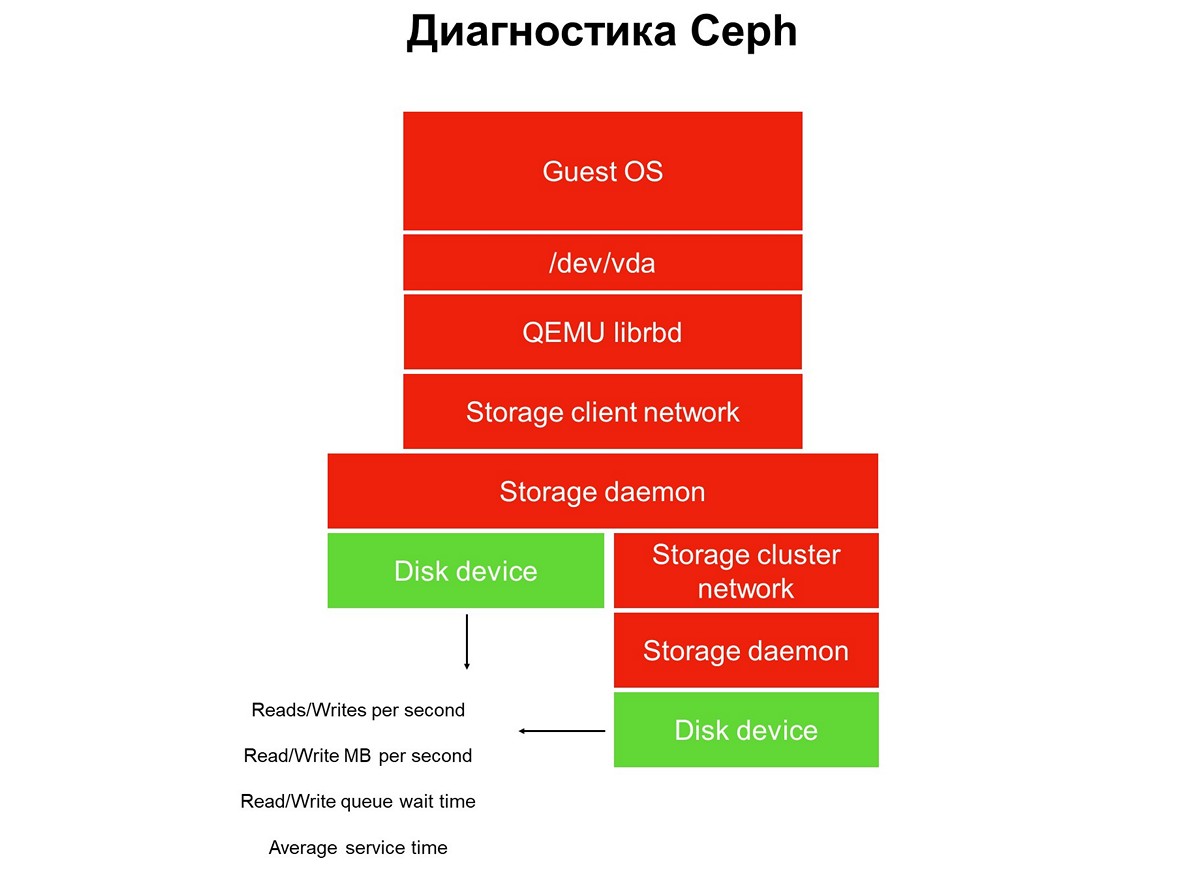 Die erste Phase: Wir behandeln Überwachungsdisketten.
Die erste Phase: Wir behandeln Überwachungsdisketten.Die Festplattenüberwachung reicht nicht aus, um ein vollständiges Bild der Vorgänge im System zu erhalten. Daher überwachen wir ein kritisches Element der Infrastruktur - das Netzwerk des Speichersystems. Es gibt tatsächlich zwei davon - den internen Cluster und den Client, die Speichercluster mit Hypervisoren verbinden. Hier erhalten wir die Datenpaketübertragungsraten (Megabyte pro Sekunde, Pakete pro Sekunde), die Größe der Netzwerkwarteschlangen, Puffer und möglicherweise Datenpfade.
 Zweite Stufe: Netzwerküberwachung.
Zweite Stufe: Netzwerküberwachung.Sie hören oft damit auf, aber dies ist nicht möglich, da der größte Teil der Infrastruktur noch nicht durch Überwachung geschlossen wurde.
Der gesamte verteilte Speicher, der in öffentlichen und privaten Clouds verwendet wird, ist SDS, softwaredefinierter Speicher. Sie können auf den Lösungen eines bestimmten Anbieters, Open Source-Lösungen, implementiert werden. Sie können mithilfe eines Stapels bekannter Technologien selbst etwas tun. Es handelt sich jedoch immer um Sicherheitsdatenblätter, und die Arbeit dieser Softwareteile muss überwacht werden.
 Dritter Schritt: Überwachung des Speicherdämons.
Dritter Schritt: Überwachung des Speicherdämons.Die meisten Ceph-Betreiber verwenden Daten, die von Ceph-Überwachungs- und Kontrolldämonen (Monitor und Manager, auch bekannt als mgr) erfasst wurden. Anfangs gingen wir den gleichen Weg, stellten jedoch sehr schnell fest, dass diese Informationen nicht ausreichten - Warnungen vor hängenden Anfragen erscheinen zu spät: Die Anfrage hing 30 Sekunden lang, erst dann sahen wir sie. Solange es um die Überwachung geht, während die Überwachung den Alarm auslöst, vergehen mindestens drei Minuten. Im besten Fall bedeutet dies, dass ein Teil des Speichers und der Anwendungen drei Minuten lang inaktiv ist.
Natürlich haben wir uns entschlossen, die Überwachung zu erweitern und sind zum Hauptelement von Ceph übergegangen - dem OSD-Daemon. Durch die Überwachung des Object Storage-Daemons erhalten wir die ungefähre Betriebszeit, wie sie vom OSD angezeigt wird, sowie Statistiken zu blockierten Anforderungen - wer, wann, in welchem PG, wie lange.
Warum nur Ceph nicht genug ist und was man dagegen tun kann
Ceph allein reicht aus mehreren Gründen nicht aus. Zum Beispiel haben wir einen Client mit einem Datenbankprofil. Er stellte alle Datenbanken im All-Flash-Cluster bereit, die Latenz der dort ausgegebenen Vorgänge passte zu ihm, es gab jedoch Beschwerden über Ausfallzeiten.
Mit dem Überwachungssystem können Sie nicht sehen, was in den Clients der virtuellen Umgebung geschieht. Um das Problem zu identifizieren, haben wir daher die erweiterte Analyse verwendet, die mit dem Dienstprogramm blktrace von seiner virtuellen Maschine angefordert wurde.
 Das Ergebnis einer erweiterten Analyse.
Das Ergebnis einer erweiterten Analyse.Die Analyseergebnisse enthalten Operationen, die mit den Flags W und WS gekennzeichnet sind. Das W-Flag ist ein Datensatz, das WS-Flag ist ein synchroner Datensatz, der darauf wartet, dass das Gerät den Vorgang abschließt. Wenn wir mit Datenbanken arbeiten, haben fast alle SQL-Datenbanken einen Engpass - WAL (Write-Ahead-Protokoll).
Die Datenbank schreibt immer zuerst Daten in das Protokoll, erhält eine Bestätigung von der Festplatte mit leeren Puffern und schreibt dann die Daten in die Datenbank selbst. Wenn sie keine Bestätigung eines Puffer-Resets erhalten hat, glaubt sie, dass ein Power-Reset eine vom Client bestätigte Transaktion löschen kann. Dies ist für die Datenbank nicht akzeptabel, daher wird "SYNC / FLUSH schreiben" angezeigt und anschließend die Daten geschrieben. Wenn die Protokolle voll sind, erfolgt ihr Wechsel, und alles, was in den Seitencache gelangt ist, wird ebenfalls zwangsweise geflasht.
Hinzugefügt: Es gibt kein Zurücksetzen im Bild selbst, dh Operationen mit dem Pre-Flush-Flag. Sie sehen aus wie FWS - Pre-Flush + Write + Sync oder FWSF - Pre-Flush + Write + Sync + FUAWenn ein Client viele kleine Transaktionen hat, werden praktisch alle E / A zu einer sequentiellen Kette: Schreiben - Spülen - Schreiben - Spülen. Da Sie mit der Datenbank nichts anfangen können, beginnen wir mit dem Speichersystem zu arbeiten. In diesem Moment verstehen wir, dass die Fähigkeiten von Ceph nicht ausreichen.
Zu diesem Zeitpunkt bestand die beste Lösung für uns darin, kleine und schnelle lokale Repositorys hinzuzufügen, die nicht mit Ceph-Tools implementiert wurden (wir haben die Funktionen im Grunde erschöpft). Und wir verwandeln Cloud-Speicher in etwas mehr als Ceph. In unserem Fall haben wir viele lokale Storys hinzugefügt (lokal in Bezug auf das Rechenzentrum, nicht den Hypervisor).
 Zusätzliche lokalisierte Repositorys Ziel A und B.
Zusätzliche lokalisierte Repositorys Ziel A und B.Die Servicezeit eines solchen lokalen Speichers beträgt ungefähr 0,3 ms pro Stream. Wenn es in einem anderen Rechenzentrum liegt, arbeitet es langsamer - mit einer Leistung von ca. 0,7 ms. Dies ist ein signifikanter Anstieg im Vergleich zu Ceph, das 1,2 ms produziert und über Rechenzentren verteilt ist - 2 ms. Die Leistung solcher kleinen Fabriken, von denen wir mehr als ein Dutzend haben, beträgt ungefähr 100.000 pro Modul, 100.000 IOPS pro Datensatz.
Nach einer solchen Änderung der Infrastruktur drückt unsere Cloud weniger als eine Million IOPS zum Schreiben oder etwa zwei bis drei Millionen IOPS zum Lesen für alle Kunden aus:

Es ist wichtig zu beachten, dass diese Art von Speicher nicht die Haupterweiterungsmethode ist. Wir setzen die Hauptwette auf Ceph und das Vorhandensein von schnellem Speicher ist nur für Dienste wichtig, die eine Antwortzeit auf die Festplatte erfordern.
Neue Iterationen: Code- und Infrastrukturverbesserungen
Alle unsere Geschichten sind gemeinsame Ressourcen. Für eine solche Infrastruktur müssen wir
eine Service-Level-Richtlinie implementieren : Wir müssen ein bestimmtes
Service-Level bereitstellen und dürfen nicht zulassen, dass ein Client versehentlich oder absichtlich durch Deaktivieren des Speichers in einen anderen Client eingreift.
Dazu mussten wir die Finalisierung und den nicht trivialen Roll-out durchführen - die iterative Lieferung an das Produktive.
Dieser Roll-out unterschied sich von den üblichen DevOps-Praktiken, bei denen alle Prozesse: Montage, Test, Code-Roll-out, Neustart des Service, falls erforderlich, mit einem Klick auf eine Schaltfläche beginnen und dann alles funktioniert. Wenn Sie DevOps-Praktiken in der Infrastruktur implementieren, bleibt diese bis zum ersten Fehler bestehen.
Aus diesem Grund hat sich die „Vollautomatisierung“ im Infrastruktur-Team nicht besonders etabliert. Natürlich gibt es einen bestimmten Ansatz für die Test- und Bereitstellungsautomatisierung - dieser wird jedoch immer kontrolliert und die Bereitstellung wird von den SRE-Ingenieuren des Cloud-Teams initiiert.
Wir haben Änderungen in mehreren Diensten eingeführt: im Cinder-Backend, im Cinder-Frontend (Cinder-Client) und im Nova-Dienst. Änderungen wurden in mehreren Iterationen angewendet - jeweils eine Iteration. Nach der dritten Iteration wurden die entsprechenden Änderungen auf die Gastcomputer der Clients angewendet: Jemand migrierte, jemand selbst startete die VM neu (Hard Reboot) oder geplante Migration, um die Hypervisoren zu bedienen.
Das nächste Problem, das auftrat, waren die
Sprünge in der Schreibgeschwindigkeit . Wenn wir mit Netzwerkspeicher arbeiten, betrachtet der Standardhypervisor das Netzwerk als langsam und speichert daher alle Daten zwischen. Er schreibt schnell, bis zu mehreren zehn Megabyte, und beginnt dann, den Cache zu leeren. Es gab viele unangenehme Momente wegen solcher Sprünge.
Wir haben festgestellt, dass beim Einschalten des Caches die Leistung der SSD um 15% und beim Ausschalten des Caches die Leistung der Festplatte um 35% sinkt. Es bedurfte einer weiteren Entwicklung, der Einführung der verwalteten Cache-Verwaltung, wenn das Caching explizit für jeden Festplattentyp zugewiesen wurde. Dies ermöglichte es uns, SSD ohne Cache und HDD zu betreiben - mit einem Cache konnten wir daher die Leistung nicht mehr verlieren.
Die Praxis, einem Produkt eine Entwicklung zu liefern, ist ähnlich - Iterationen. Wir haben den Code eingeführt, den Dämon neu gestartet und dann bei Bedarf virtuelle Gastmaschinen neu gestartet oder migriert, die Änderungen unterliegen sollten. Die Client-VM wurde von der Festplatte migriert, der Cache wurde aktiviert - alles funktioniert, oder im Gegenteil, der Client wurde mit der SSD migriert, der Cache wurde deaktiviert - alles funktioniert.
Das dritte Problem ist der
fehlerhafte Betrieb von virtuellen Maschinen, die von GOLD-Images auf der Festplatte bereitgestellt werden .
Es gibt viele solcher Clients, und die Besonderheit der Situation besteht darin, dass die Arbeit der VM von selbst angepasst wurde: Das Problem trat garantiert während der Bereitstellung auf, wurde jedoch behoben, während der Client den technischen Support erreichte. Zuerst haben wir die Kunden gebeten, eine halbe Stunde zu warten, bis sich die VM stabilisiert hat, aber dann haben wir begonnen, an der Qualität des Dienstes zu arbeiten.
Im Verlauf der Forschung haben wir festgestellt, dass die Fähigkeiten unserer Überwachungsinfrastruktur immer noch nicht ausreichen.
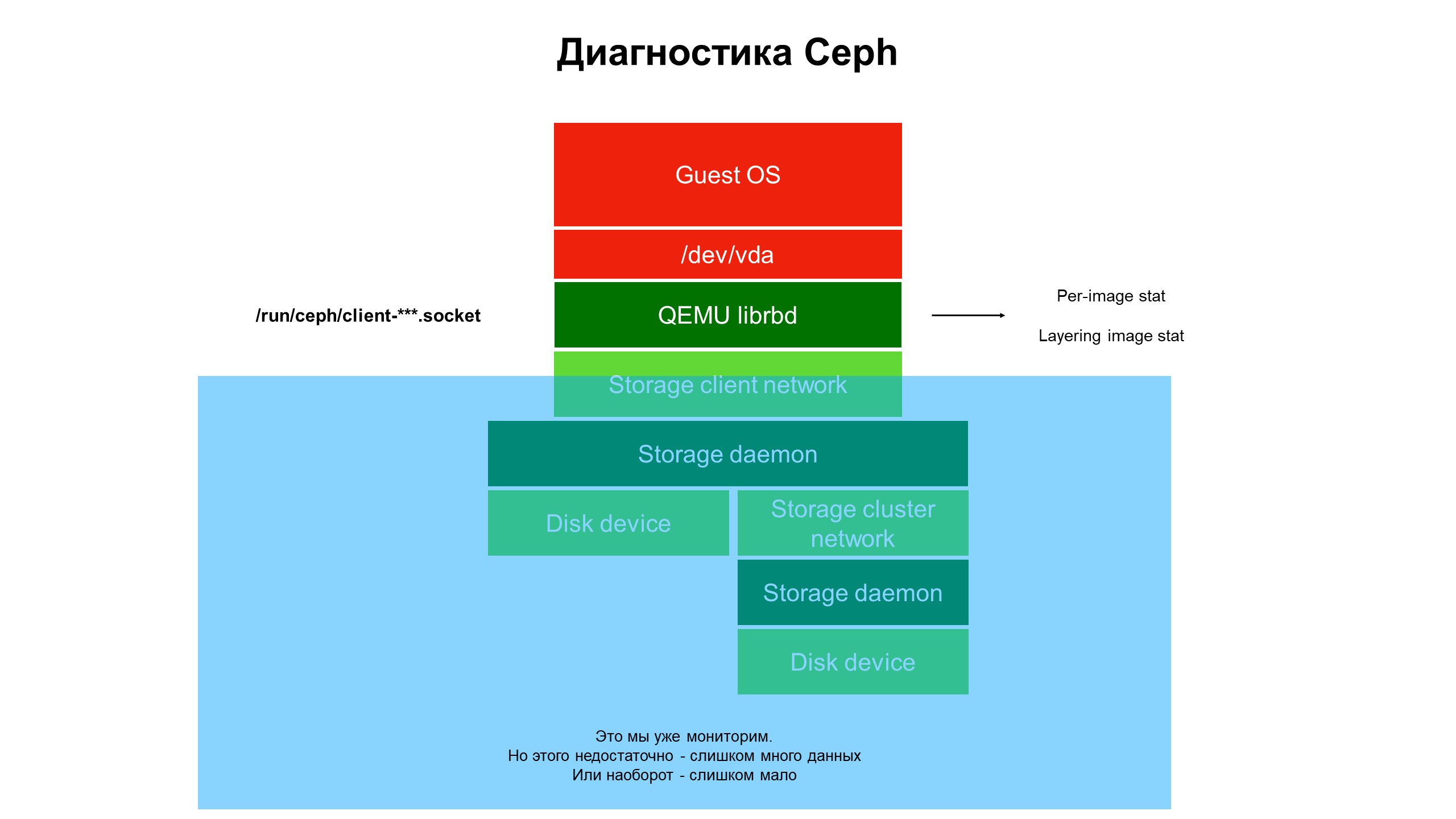 Die Überwachung schloss den blauen Teil, und das Problem befand sich ganz oben in der Infrastruktur und wurde nicht von der Überwachung abgedeckt.
Die Überwachung schloss den blauen Teil, und das Problem befand sich ganz oben in der Infrastruktur und wurde nicht von der Überwachung abgedeckt.Wir haben begonnen, uns mit dem zu befassen, was in dem Teil der Infrastruktur geschieht, der nicht überwacht wurde. Zu diesem Zweck verwendeten wir die erweiterte Ceph-Diagnostik (oder besser gesagt eine der Varianten des Ceph-Clients - librbd). Mithilfe von Automatisierungstools haben wir Änderungen an der Ceph-Client-Konfiguration vorgenommen, um über den Unix-Domain-Socket auf interne Datenstrukturen zuzugreifen, und haben begonnen, Statistiken von Ceph-Clients auf dem Hypervisor zu erstellen.
Was haben wir gesehen? Es wurden keine Statistiken zum Ceph-Cluster / OSD / Cluster angezeigt, sondern Statistiken zu jeder Festplatte der virtuellen Client-Maschine, deren Festplatten sich in Ceph befanden - dh Statistiken, die dem Gerät zugeordnet sind.
 Erweiterte Ergebnisse der Überwachungsstatistik.
Erweiterte Ergebnisse der Überwachungsstatistik.Es war die erweiterte Statistik, die deutlich machte, dass das Problem nur auf Datenträgern auftritt, die von anderen Datenträgern geklont wurden.
Als nächstes haben wir uns Statistiken über Operationen angesehen, insbesondere Lese- / Schreiboperationen. Es stellte sich heraus, dass die Belastung der Bilder der oberen Ebene relativ gering ist, und bei den ersten Bildern, von denen der Klon stammt, ist sie groß, aber nicht ausgeglichen: eine große Menge an Lesevorgängen ohne Aufzeichnung.
Das Problem ist lokalisiert, jetzt wird eine Lösung benötigt - Code oder Infrastruktur?
Mit dem Ceph-Code kann nichts gemacht werden, er ist „schwer“. Darüber hinaus hängt die Sicherheit der Kundendaten davon ab. Aber es gibt ein Problem, das gelöst werden muss, und wir haben die Architektur des Repositorys geändert. Der HDD-Cluster wurde zu einem Hybrid-Cluster. Der Festplatte wurde eine bestimmte Menge SSD hinzugefügt. Anschließend wurden die Prioritäten der OSD-Dämonen geändert, sodass die SSD immer Vorrang hatte und zum primären OSD innerhalb der Platzierungsgruppe (PG) wurde.
Wenn der Client die virtuelle Maschine von der geklonten Festplatte bereitstellt, werden die Lesevorgänge auf die SSD übertragen. Infolgedessen wurde die Wiederherstellung von der Festplatte schnell und nur andere Clientdaten als das Original-Image werden auf die Festplatte geschrieben. Wir haben eine Verdreifachung der Produktivität fast kostenlos erhalten (im Vergleich zu den anfänglichen Kosten der Infrastruktur).
Warum Infrastrukturüberwachung wichtig ist
- Die Überwachungsinfrastruktur muss maximal im gesamten Stapel enthalten sein, beginnend mit der virtuellen Maschine und endend mit der Festplatte. Während ein Client, der eine private oder öffentliche Cloud verwendet, zu seiner Infrastruktur gelangt und die erforderlichen Informationen bereitstellt, ändert sich das Problem oder wird an einen anderen Ort verschoben.
- Die Überwachung des gesamten Hypervisors, der virtuellen Maschine oder des Containers "in seiner Gesamtheit" ergibt fast nichts. Wir haben versucht, aus dem Netzwerkverkehr zu verstehen, was mit Ceph passiert - es ist nutzlos, die Daten fliegen mit hoher Geschwindigkeit (ab 500 Megabyte pro Sekunde), es ist äußerst schwierig, die erforderlichen auszuwählen. Es wird eine ungeheure Menge an Festplatten erfordern, um solche Statistiken zu speichern, und viel Zeit, um sie zu analysieren.
- , - . : , , — , .
- — . , . — , . , . — , , .
- MCS Cloud Solutions — , . .