Das Problem der automatischen Suche nach Text in Bildern besteht zumindest seit Beginn der neunziger Jahre des letzten Jahrhunderts seit langem. Oldtimer konnten sich an die weit verbreitete Verbreitung von ABBYY FineReader erinnern, der Dokumentenscans in ihre bearbeitbaren Versionen übersetzen kann.
An PCs angeschlossene Scanner funktionieren in Unternehmen hervorragend, aber der Fortschritt steht nicht still, und mobile Geräte haben die Welt erobert. Der Aufgabenbereich für die Arbeit mit Text hat sich ebenfalls geändert. Jetzt müssen Sie den Text nicht auf perfekt geraden A4-Blättern mit schwarzem Text auf weißem Hintergrund suchen, sondern auf verschiedenen Visitenkarten, farbenfrohen Menüs, Ladenschildern und vielem mehr darüber, was eine Person im Dschungel einer modernen Stadt treffen kann.
 Ein echtes Beispiel für die Arbeit unseres neuronalen Netzwerks. Das Bild ist anklickbar.
Ein echtes Beispiel für die Arbeit unseres neuronalen Netzwerks. Das Bild ist anklickbar.Grundlegende Anforderungen und Einschränkungen
Mit solch einer Vielzahl von Bedingungen für die Darstellung von Text können handgeschriebene Algorithmen nicht mehr fertig werden. Hier kommen neuronale Netze mit ihrer Fähigkeit zur Verallgemeinerung zur Rettung. In diesem Beitrag werden wir über unseren Ansatz zur Erstellung einer neuronalen Netzwerkarchitektur sprechen, die Text auf komplexen Bildern mit guter Qualität und hoher Geschwindigkeit erkennt.
Mobile Geräte beschränken die Wahl des Ansatzes zusätzlich:
- Aufgrund des teuren Roaming-Verkehrs oder Datenschutzproblemen haben Benutzer nicht immer die Möglichkeit, über ein Mobilfunknetz mit dem Server zu kommunizieren. Lösungen wie Google Lens helfen hier also nicht weiter.
- Da wir uns auf die lokale Datenverarbeitung konzentrieren, wäre es schön für unsere Lösung:
- Es nahm wenig Gedächtnis in Anspruch;
- Mit den technischen Funktionen des Smartphones funktionierte es schnell.
- Der Text kann gedreht werden und sich auf einem zufälligen Hintergrund befinden.
- Wörter können sehr lang sein. In neuronalen Faltungsnetzen deckt der Umfang des Faltungskerns normalerweise nicht das verlängerte Wort als Ganzes ab, so dass es eines Tricks bedarf, um diese Einschränkung zu umgehen.

- Die Textgrößen auf einem Foto können unterschiedlich sein:

Lösung
Die einfachste Lösung für das Problem der Textsuche besteht darin, das beste Netzwerk aus den
ICDAR- Wettbewerben (Internationale Konferenz für Dokumentenanalyse und -erkennung) zu entnehmen, die auf diese Aufgabe und dieses Geschäft spezialisiert sind! Leider erreichen solche Netzwerke aufgrund ihrer Sperrigkeit und Rechenkomplexität Qualität und eignen sich nur als Cloud-Lösung, die die Absätze 1 und 2 unserer Anforderungen nicht erfüllt. Aber was ist, wenn wir ein großes Netzwerk verwenden, das in den Szenarien, die wir abdecken müssen, gut funktioniert, und versuchen, es zu reduzieren? Dieser Ansatz ist bereits interessanter.
Baoguang Shi et al.
Schlugen SegLink [1] in ihrem neuronalen Netzwerk Folgendes vor:
- Nicht ganze Wörter auf einmal finden (grüne Bereiche im Bild a ), sondern ihre Teile, Segmente genannt, mit der Vorhersage ihrer Drehung, Neigung und Verschiebung. Lassen Sie uns diese Idee ausleihen.
- Sie müssen nach Wortsegmenten auf mehreren Skalen gleichzeitig suchen, um die Anforderung 5 zu erfüllen. Die Segmente werden in Bild b durch grüne Rechtecke angezeigt.
- Um zu verhindern, dass eine Person erfindet, wie diese Segmente kombiniert werden, lassen wir das neuronale Netzwerk einfach Verbindungen (Verknüpfungen) zwischen Segmenten vorhersagen, die sich auf dasselbe Wort beziehen
a. innerhalb des gleichen Maßstabs (rote Linien in Bild c )
b. und zwischen Skalen (rote Linien in Bild d ), um das Problem von Abschnitt 4 der Anforderungen zu lösen.
Die blauen Quadrate im Bild unten zeigen die Sichtbarkeitsbereiche der Pixel der Ausgabeschichten des neuronalen Netzwerks mit verschiedenen Maßstäben, die zumindest einen Teil des Wortes "sehen".
 Segment- und Linkbeispiele
Segment- und LinkbeispieleSegLink verwendet die bekannte VGG-16-Architektur als Grundlage. Die Vorhersage von Segmenten und Verknüpfungen erfolgt auf 6 Skalen. Als erstes Experiment haben wir mit der Implementierung der ursprünglichen Architektur begonnen. Es stellte sich heraus, dass das Netzwerk 23 Millionen Parameter (Gewichte) enthält, die in einer Datei mit einer Größe von 88 Megabyte gespeichert werden müssen. Wenn Sie eine auf VGG basierende Anwendung erstellen, ist sie einer der ersten Kandidaten für die Entfernung, wenn nicht genügend Speicherplatz vorhanden ist, und die Textsuche selbst funktioniert sehr langsam, sodass das Netzwerk dringend abnehmen muss.
 SegLink-Netzwerkarchitektur
SegLink-NetzwerkarchitekturDas Geheimnis unserer Ernährung
Sie können die Größe des Netzwerks reduzieren, indem Sie einfach die Anzahl der Schichten und Kanäle darin oder die Faltung selbst und die Verbindungen zwischen ihnen ändern. Mark Sandler und seine Mitarbeiter haben die Architektur in ihrem
MobileNetV2- Netzwerk [2] gerade noch rechtzeitig aufgegriffen, damit sie auf Mobilgeräten schnell funktioniert, wenig Platz beansprucht und die Arbeitsqualität derselben VGG immer noch nicht beeinträchtigt. Das Geheimnis der Geschwindigkeit und Reduzierung des Speicherverbrauchs liegt in drei Hauptschritten:
- Die Anzahl der Kanäle mit Feature-Maps am Eingang des Blocks wird durch Punktfaltung auf die gesamte Tiefe (den sogenannten Engpass) ohne Aktivierungsfunktion reduziert.
- Die klassische Faltung wird durch eine pro Kanal trennbare Faltung ersetzt. Eine solche Faltung erfordert weniger Gewicht und weniger Berechnung.
- Zeichenkarten nach dem Engpass werden zur Summierung ohne zusätzliche Windungen an den Eingang des nächsten Blocks weitergeleitet.
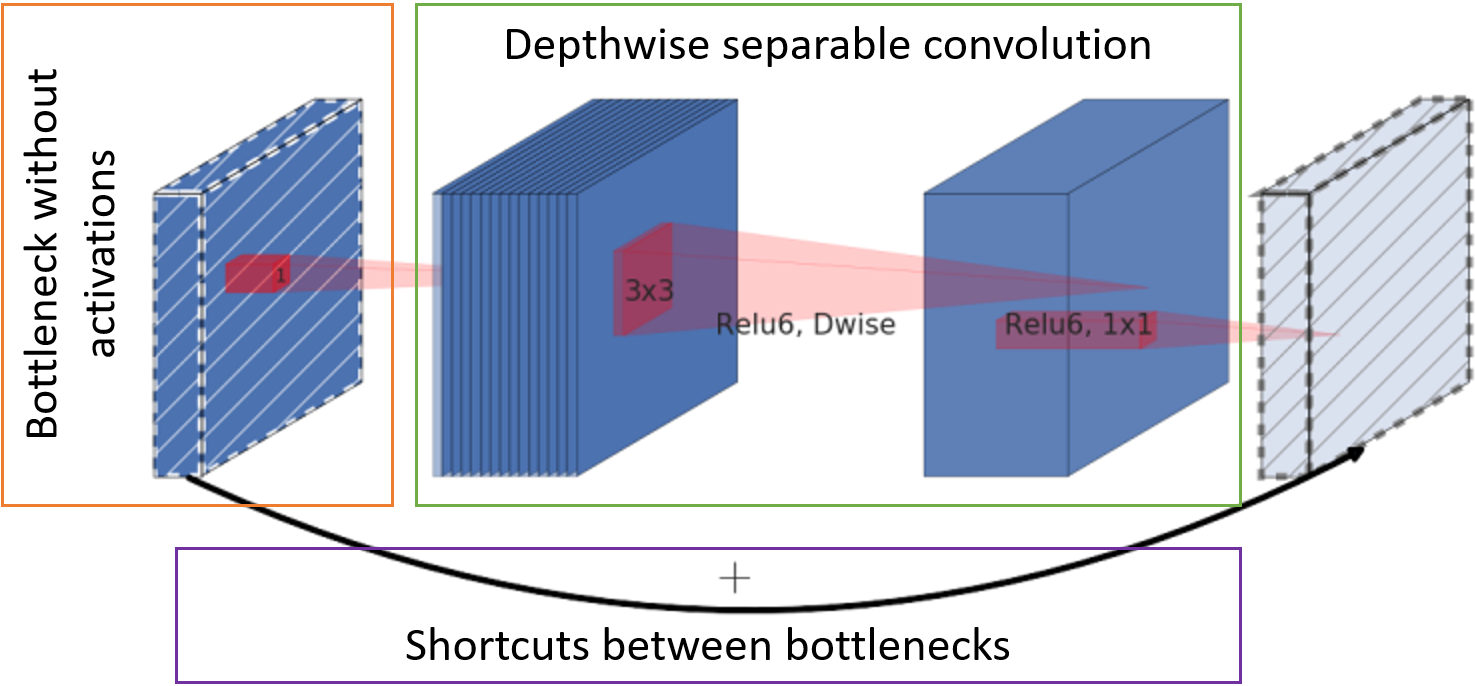 MobileNetV2-Basiseinheit
MobileNetV2-Basiseinheit
Resultierendes neuronales Netzwerk
Mit den oben genannten Ansätzen kamen wir zu folgender Netzwerkstruktur:
- Wir verwenden Segmente und Links von SegLink
- Ersetzen Sie VGG durch ein weniger gefräßiges MobileNetV2
- Reduzieren Sie die Anzahl der Textsuchskalen aus Gründen der Geschwindigkeit von 6 auf 5
 Textsuchzusammenfassungsnetzwerk
Textsuchzusammenfassungsnetzwerk
Entschlüsselung von Werten in Netzwerkarchitekturblöcken
Der Schrittschritt und die Basisanzahl der Kanäle in den Kanälen werden als s <Schritt> c <Kanäle> angegeben. Zum Beispiel bedeutet s2c32 32 Kanäle mit einer Verschiebung von 2. Die tatsächliche Anzahl von Kanälen in den Faltungsschichten wird erhalten, indem ihre Basiszahl mit einem Skalierungsfaktor α multipliziert wird, wodurch Sie schnell unterschiedliche „Dicken“ des Netzwerks simulieren können. Unten finden Sie eine Tabelle mit der Anzahl der Parameter im Netzwerk in Abhängigkeit von α.

Blocktyp:
- Conv2D - eine vollwertige Faltungsoperation;
- D-weise Konv - trennbare Faltung pro Kanal;
- Blöcke - eine Gruppe von MobileNetV2-Blöcken;
- Ausgabe - Faltung, um die Ausgabeschicht zu erhalten. Numerische Werte vom Typ NxN geben die Größe des Empfangsfeldes des Pixels an.
Als Aktivierungsfunktion verwenden die Bausteine ReLU6.

Die Ausgangsschicht hat 31 Kanäle:
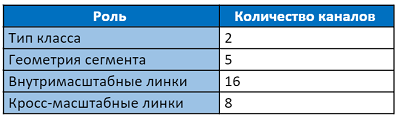
Die ersten beiden Kanäle der Ausgabeebene stimmen dafür, dass das Pixel zum Text und nicht zum Text gehört. Die folgenden fünf Kanäle enthalten Informationen zur genauen Rekonstruktion der Segmentgeometrie: vertikale und horizontale Verschiebungen relativ zur Position des Pixels, Faktoren für Breite und Höhe (da das Segment normalerweise nicht quadratisch ist) und den Drehwinkel. 16 Werte von Intra-Channel-Links geben an, ob eine Verbindung zwischen acht benachbarten Pixeln auf derselben Skala besteht. Die letzten 8 Kanäle geben Auskunft über das Vorhandensein von Links zu vier Pixeln der vorherigen Skala (die vorherige Skala ist immer zweimal größer). Alle 2 Werte von Segmenten, Intra- und Cross-Scale-Links werden durch die Softmax-Funktion normalisiert. Der Zugriff auf die allererste Skala verfügt nicht über skalierungsübergreifende Links.
Wortassemblierung
Das Netzwerk sagt voraus, ob ein bestimmtes Segment und seine Nachbarn zum Text gehören. Es bleibt, sie in Worte zu fassen.
Kombinieren Sie zunächst alle Segmente, die durch Links verbunden sind. Zu diesem Zweck erstellen wir ein Diagramm, in dem die Scheitelpunkte alle Segmente in allen Maßstäben und die Kanten Verknüpfungen sind. Dann finden wir die verbundenen Komponenten des Graphen. Für jede Komponente ist es jetzt möglich, das umschließende Rechteck des Wortes wie folgt zu berechnen:
- Wir berechnen den Drehwinkel des Wortes θ
- Oder als Durchschnittswert der Vorhersagen des Drehwinkels der Segmente, wenn es viele davon gibt,
- Oder als Drehwinkel der Linie, der durch Regression an den Punkten der Mittelpunkte der Segmente erhalten wird, wenn nur wenige Segmente vorhanden sind.
- Der Mittelpunkt des Wortes wird als Schwerpunkt der Mittelpunkte der Segmente ausgewählt.
- Erweitern Sie alle Segmente um -θ, um sie horizontal anzuordnen. Finde die Grenzen des Wortes.
- Die linken und rechten Grenzen des Wortes werden als Grenzen der Segmente ganz links bzw. ganz rechts ausgewählt.
- Um die obere Wortgrenze zu erhalten, werden die Segmente nach der Höhe der oberen Kante sortiert, 20% der höchsten werden abgeschnitten und der Wert des ersten Segments aus der Liste, der nach dem Filtern verbleibt, wird ausgewählt.
- Die untere Grenze ergibt sich aus den untersten Segmenten mit einem Grenzwert von 20% der niedrigsten in Analogie zur oberen Grenze.
- Drehen Sie das resultierende Rechteck zurück auf θ.
Die endgültige Lösung heißt
FaSTExt : Fast and Small Text Extractor [3]
Experimentierzeit!
Trainingsdetails
Das Netzwerk selbst und seine Parameter wurden für eine gute Arbeit an einer großen internen Stichprobe ausgewählt, die das Hauptszenario der Verwendung der Anwendung auf dem Telefon widerspiegelt. Er richtete die Kamera auf ein Objekt mit Text und machte ein Foto. Es stellte sich heraus, dass ein großes Netzwerk mit α = 1 in der Qualität die Version mit α = 0,5 nur um 2% umgeht. Dieses Beispiel ist nicht gemeinfrei. Aus Gründen der Übersichtlichkeit musste ich das Netzwerk auf das öffentliche Beispiel
ICDAR2013 trainieren , bei dem die Aufnahmebedingungen unseren ähnlich sind. Die Stichprobe ist sehr klein, daher wurde das Netzwerk zuvor auf eine große Menge synthetischer Daten aus
SynthText im Wild- Datensatz
trainiert . Der Vorschulungsprozess dauerte für jedes Experiment mit der GTX 1080 Ti etwa 20 Tage. Daher wurde der Netzwerkbetrieb mit öffentlichen Daten nur auf die Optionen α = 0,75, 1 und 2 überprüft.
Als Optimierer wurde die
AMSGrad- Version von Adam verwendet.
Fehlerfunktionen:
- Kreuzentropie zur Klassifizierung von Segmenten und Verbindungen;
- Huber-Verlustfunktion für Segmentgeometrie.
Ergebnisse
In Bezug auf die Qualität der Netzwerkleistung im Zielszenario können wir sagen, dass es in Bezug auf die Qualität nicht weit hinter den Wettbewerbern zurückbleibt und sogar einige überholt. MS ist ein starkes Multiskalen-Netzwerk von Wettbewerbern.
 * In dem Artikel über EAST gab es keine Ergebnisse für die von uns benötigte Probe, daher haben wir das Experiment selbst durchgeführt.
* In dem Artikel über EAST gab es keine Ergebnisse für die von uns benötigte Probe, daher haben wir das Experiment selbst durchgeführt.Das folgende Bild zeigt ein Beispiel dafür, wie FaSTExt mit Bildern von ICDAR2013 funktioniert. Die erste Zeile zeigt, dass die beleuchteten Buchstaben des Wortes ESPMOTO nicht markiert waren, das Netzwerk sie jedoch finden konnte. Die weniger geräumige Version mit α = 0,75 kam mit kleinem Text schlechter zurecht als die "dickeren" Versionen. In der unteren Zeile werden erneut Markup-Fehler im Beispiel mit verlorenem Text in der Reflexion angezeigt. FaSTExt sieht gleichzeitig einen solchen Text.

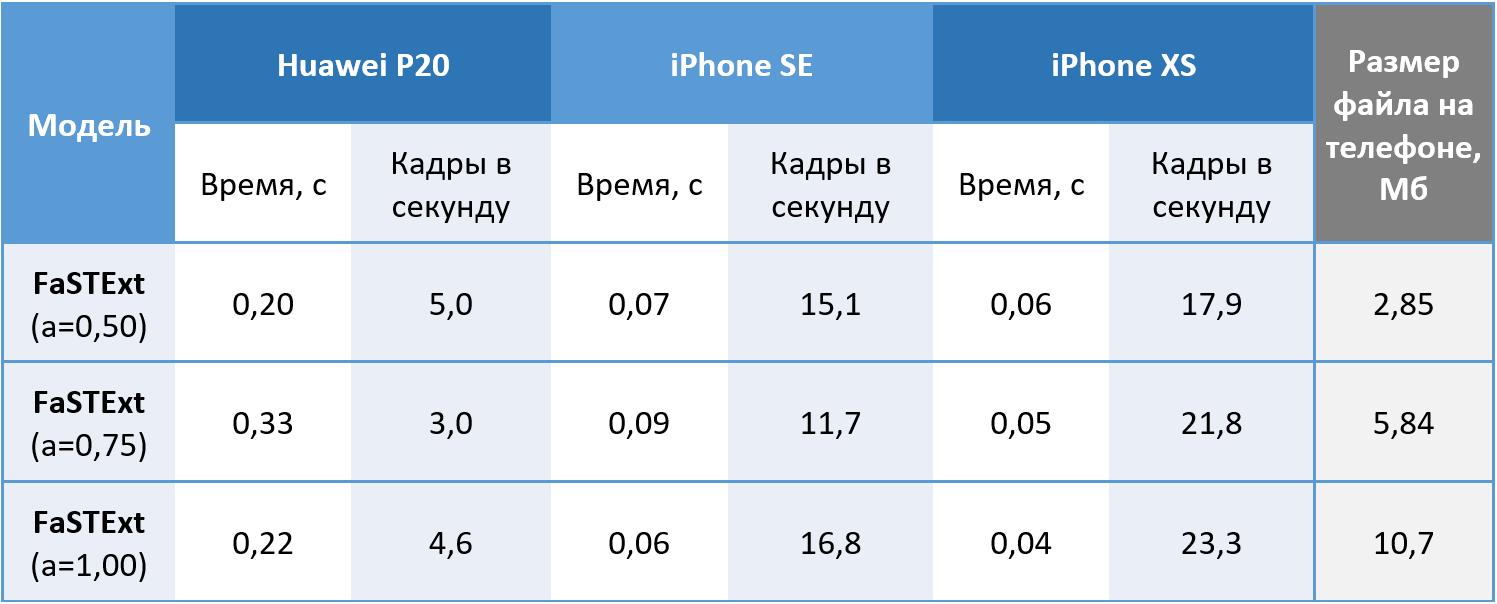
Das Netzwerk führt also seine Aufgaben aus. Es bleibt zu prüfen, ob es tatsächlich auf Telefonen verwendet werden kann? Die Modelle wurden auf 512 x 512 Farbbildern auf dem Huawei P20 mit der CPU und auf dem iPhone SE und iPhone XS mit der GPU gestartet, da Sie mit unserem maschinellen Lernsystem die GPU weiterhin nur unter iOS verwenden können. Werte, die durch Mittelung von 100 Starts erhalten werden. Unter Android haben wir eine Geschwindigkeit von 5 Bildern pro Sekunde erreicht, die für unsere Aufgabe akzeptabel ist. Das iPhone XS zeigte einen interessanten Effekt mit einer Verringerung der durchschnittlichen Zeit, die für Berechnungen benötigt wird, während das Netzwerk kompliziert wird. Ein modernes iPhone erkennt Text mit minimaler Verzögerung, was als Sieg bezeichnet werden kann.
Referenzliste
[1] B. Shi, X. Bai und S. Belongie, „Erkennen von orientiertem Text in natürlichen Bildern durch Verknüpfen von Segmenten“, Hawaii, 2017.
Link[2] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov und L.-C. Chen, „MobileNetV2: Invertierte Residuen und lineare Engpässe“, Salt Lake City, 2018.
Link[3] A. Filonenko, K. Gudkov, A. Lebedev, N. Orlov und I. Zagaynov, „FaSTExt: Schneller und kleiner Textextraktor“, im 8. Internationalen Workshop über kamerabasierte Dokumentenanalyse und -erkennung, Sydney, 2019
Link[4] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu und X. Bai, „Multiorientierte Texterkennung mit vollständig gefalteten Netzwerken“, Las Vegas, 2016.
Link[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He und J. Liang, „EAST: Ein effizienter und genauer Szenentextdetektor“, auf der IEEE-Konferenz 2017 über Computer Vision und Muster, Honolulu, 2017.
Link[6] M. Liao, Z. Zhu, B. Shi, G.-s. Xia und X. Bai, „Rotationsempfindliche Regression für die Texterkennung orientierter Szenen“, auf der IEEE / CVF-Konferenz 2018 über Computer Vision und Muster, Salt Lake City, 2018.
Link[7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao und J. Yan, „Fots: Schnelle Texterkennung mit einem einheitlichen Netzwerk“, auf der IEEE / CVF-Konferenz 2018 über Computer Vision und Muster, Salt Lake City, 2018.
LinkComputer Vision Gruppe