Alexey Lizunov, Leiter des Kompetenzzentrums für Remote-Service-Kanäle der Direktion für Informationstechnologien des ICD
Als Alternative zum ELK-Stack (ElasticSearch, Logstash, Kibana) untersuchen wir die Verwendung der ClickHouse-Datenbank als Data Warehouse für Protokolle.
In diesem Artikel möchten wir über unsere Erfahrungen mit der ClickHouse-Datenbank und über vorläufige Ergebnisse des Pilotbetriebs sprechen. Es sollte sofort angemerkt werden, dass die Ergebnisse beeindruckend waren.
Als nächstes werden wir detaillierter beschreiben, wie unser System konfiguriert ist und aus welchen Komponenten es besteht. Aber jetzt möchte ich ein wenig über diese Datenbank als Ganzes sprechen und warum Sie darauf achten sollten. Die ClickHouse-Datenbank ist eine leistungsstarke analytische Spaltendatenbank von Yandex. Es wird in Yandex-Diensten verwendet und ist zunächst das Haupt-Data-Warehouse für Yandex.Metrica. Das Open-Source-System ist kostenlos. Aus Sicht des Entwicklers war ich immer daran interessiert, wie sie es implementiert haben, weil es fantastisch große Datenmengen gibt. Und die metrische Benutzeroberfläche selbst ist sehr flexibel und schnell. Bei der ersten Bekanntschaft mit dieser Datenbank der Eindruck: „Nun, endlich! Gemacht "für Menschen"! Beginnend mit dem Installationsprozess und endend mit dem Senden von Anforderungen. "
Diese Datenbank hat eine sehr niedrige Eintragsschwelle. Selbst ein durchschnittlicher erfahrener Entwickler kann diese Datenbank in wenigen Minuten installieren und verwenden. Alles funktioniert klar. Selbst Linux-Neulinge können die Installation schnell durchführen und einfache Vorgänge ausführen. Früher, als das Wort Big Data, Hadoop, Google BigTable, HDFS, der übliche Entwickler die Idee hatte, dass es sich um Terabyte, Petabyte handelte, dass einige Übermenschen an den Einstellungen und der Entwicklung für diese Systeme beteiligt waren, kamen wir mit dem Aufkommen der ClickHouse-Datenbank Ein einfaches, verständliches Werkzeug, mit dem Sie den bisher unerreichbaren Aufgabenbereich lösen können. Nur ein ziemlich durchschnittliches Auto und fünf Minuten zu installieren. Das heißt, wir haben eine Datenbank wie zum Beispiel MySql, aber nur zum Speichern von Milliarden von Datensätzen! Eine Art SQL-Supervisor. Es ist, als würden Menschen Waffen von Außerirdischen gegeben.
Über unser Protokollsammelsystem
Zum Sammeln von Informationen werden IIS-Protokolldateien von Webanwendungen eines Standardformats verwendet (wir analysieren auch Anwendungsprotokolle, aber das Hauptziel in der Phase des Pilotbetriebs mit uns ist das Sammeln von IIS-Protokollen).
Aus verschiedenen Gründen konnten wir den ELK-Stack nicht vollständig aufgeben und verwenden weiterhin die Komponenten LogStash und Filebeat, die sich bewährt haben und recht zuverlässig und vorhersehbar funktionieren.
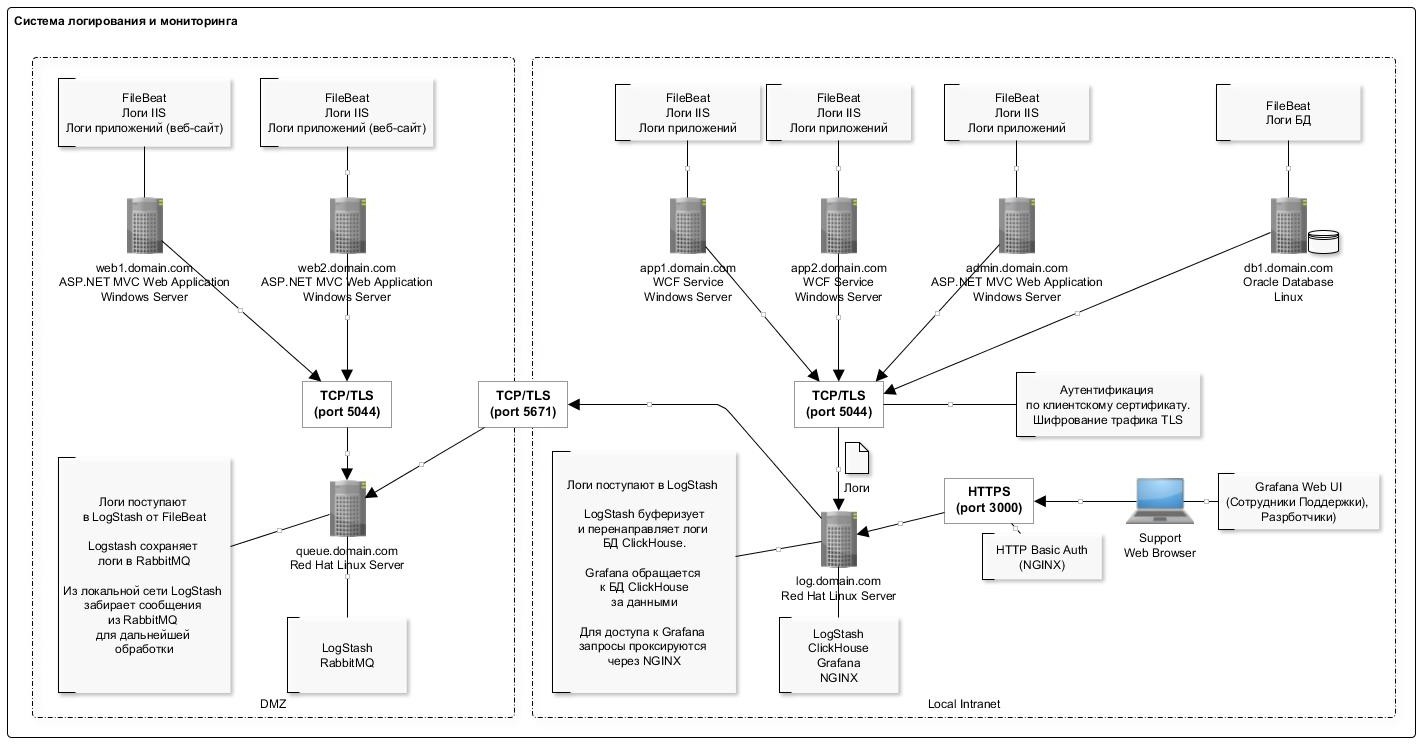
Das allgemeine Protokollierungsschema ist in der folgenden Abbildung dargestellt:
Eine Funktion zum Schreiben von Daten in die ClickHouse-Datenbank ist das seltene (einmal pro Sekunde) Einfügen von Datensätzen in großen Stapeln. Dies ist anscheinend der „problematischste“ Teil, auf den Sie stoßen, wenn Sie zum ersten Mal mit der ClickHouse-Datenbank arbeiten: Das Schema ist etwas kompliziert.
Das LogStash-Plugin hat hier sehr geholfen, da es Daten direkt in ClickHouse einfügt. Diese Komponente wird auf demselben Server wie die Datenbank selbst bereitgestellt. Im Allgemeinen wird daher nicht empfohlen, dies zu tun, sondern aus praktischer Sicht, um keine separaten Server zu erstellen, während diese auf demselben Server bereitgestellt werden. Wir haben keine Fehler oder Ressourcenkonflikte mit der Datenbank festgestellt. Zusätzlich sollte beachtet werden, dass das Plugin im Fehlerfall einen Retray-Mechanismus hat. Und im Fehlerfall schreibt das Plugin ein Datenpaket auf die Festplatte, das nicht eingefügt werden konnte (das Dateiformat ist praktisch: Nach der Bearbeitung können Sie das korrigierte Paket einfach mit dem Clickhouse-Client einfügen).
Die vollständige Liste der im Schema verwendeten Software ist in der Tabelle dargestellt:
Liste der verwendeten Software Die Serverkonfiguration mit der ClickHouse-Datenbank ist in der folgenden Tabelle dargestellt:
Wie Sie sehen können, ist dies eine normale Workstation.
Die Tabelle zum Speichern von Protokollen ist wie folgt aufgebaut:
log_web.sqlCREATE TABLE log_web ( logdate Date, logdatetime DateTime CODEC(Delta, LZ4HC), fld_log_file_name LowCardinality( String ), fld_server_name LowCardinality( String ), fld_app_name LowCardinality( String ), fld_app_module LowCardinality( String ), fld_website_name LowCardinality( String ), serverIP LowCardinality( String ), method LowCardinality( String ), uriStem String, uriQuery String, port UInt32, username LowCardinality( String ), clientIP String, clientRealIP String, userAgent String, referer String, response String, subresponse String, win32response String, timetaken UInt64 , uriQuery__utm_medium String , uriQuery__utm_source String , uriQuery__utm_campaign String , uriQuery__utm_term String , uriQuery__utm_content String , uriQuery__yclid String , uriQuery__region String ) Engine = MergeTree() PARTITION BY toYYYYMM(logdate) ORDER BY (fld_app_name, fld_app_module, logdatetime) SETTINGS index_granularity = 8192;
Wir verwenden Standardwerte für die Partitionierung (nach Monaten) und die Granularität des Index. Alle Felder entsprechen praktisch IIS-Protokolleinträgen zum Registrieren von http-Anforderungen. Separate separate Felder zum Speichern von utm-Tags (sie werden beim Einfügen in die Tabelle aus dem Feld für die Abfragezeichenfolge analysiert).
Außerdem werden in der Tabelle mehrere Systemfelder zum Speichern von Informationen zu Systemen, Komponenten und Servern hinzugefügt. In der folgenden Tabelle finden Sie eine Beschreibung dieser Felder. In einer Tabelle speichern wir Protokolle für mehrere Systeme.
Auf diese Weise können Sie Grafiken in Grafana effektiv erstellen. Zeigen Sie beispielsweise Anforderungen vom Frontend eines bestimmten Systems an. Dies ähnelt dem Site-Zähler in Yandex.Metrica.
Hier finden Sie einige Statistiken zur Nutzung der Datenbank für zwei Monate.
Anzahl der Datensätze nach System und Komponente SELECT fld_app_name, fld_app_module, count(fld_app_name) AS rows_count FROM log_web GROUP BY fld_app_name, fld_app_module WITH TOTALS ORDER BY fld_app_name ASC, rows_count DESC ┌─fld_app_name─────┬─fld_app_module─┬─rows_count─┐ │ site1.domain.ru │ web │ 131441 │ │ site2.domain.ru │ web │ 1751081 │ │ site3.domain.ru │ web │ 106887543 │ │ site3.domain.ru │ svc │ 44908603 │ │ site3.domain.ru │ intgr │ 9813911 │ │ site4.domain.ru │ web │ 772095 │ │ site5.domain.ru │ web │ 17037221 │ │ site5.domain.ru │ intgr │ 838559 │ │ site5.domain.ru │ bo │ 7404 │ │ site6.domain.ru │ web │ 595877 │ │ site7.domain.ru │ web │ 27778858 │ └──────────────────┴────────────────┴────────────┘ Totals: ┌─fld_app_name─┬─fld_app_module─┬─rows_count─┐ │ │ │ 210522593 │ └──────────────┴────────────────┴────────────┘ 11 rows in set. Elapsed: 4.874 sec. Processed 210.52 million rows, 421.67 MB (43.19 million rows/s., 86.51 MB/s.)
Die Datenmenge auf der Festplatte SELECT formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed, formatReadableSize(sum(data_compressed_bytes)) AS compressed, sum(rows) AS total_rows FROM system.parts WHERE table = 'log_web' ┌─uncompressed─┬─compressed─┬─total_rows─┐ │ 54.50 GiB │ 4.86 GiB │ 211427094 │ └──────────────┴────────────┴────────────┘ 1 rows in set. Elapsed: 0.035 sec.
Der Grad der Datenkomprimierung in Spalten SELECT name, formatReadableSize(data_uncompressed_bytes) AS uncompressed, formatReadableSize(data_compressed_bytes) AS compressed, data_uncompressed_bytes / data_compressed_bytes AS compress_ratio FROM system.columns WHERE table = 'log_web' ┌─name───────────────────┬─uncompressed─┬─compressed─┬─────compress_ratio─┐ │ logdate │ 401.53 MiB │ 1.80 MiB │ 223.16665968777315 │ │ logdatetime │ 803.06 MiB │ 35.91 MiB │ 22.363966401202305 │ │ fld_log_file_name │ 220.66 MiB │ 2.60 MiB │ 84.99905736932571 │ │ fld_server_name │ 201.54 MiB │ 50.63 MiB │ 3.980924816977078 │ │ fld_app_name │ 201.17 MiB │ 969.17 KiB │ 212.55518183686877 │ │ fld_app_module │ 201.17 MiB │ 968.60 KiB │ 212.67805817411906 │ │ fld_website_name │ 201.54 MiB │ 1.24 MiB │ 162.7204926761546 │ │ serverIP │ 201.54 MiB │ 50.25 MiB │ 4.010824061219731 │ │ method │ 201.53 MiB │ 43.64 MiB │ 4.617721053304486 │ │ uriStem │ 5.13 GiB │ 832.51 MiB │ 6.311522291936919 │ │ uriQuery │ 2.58 GiB │ 501.06 MiB │ 5.269731450124478 │ │ port │ 803.06 MiB │ 3.98 MiB │ 201.91673864241824 │ │ username │ 318.08 MiB │ 26.93 MiB │ 11.812513794583598 │ │ clientIP │ 2.35 GiB │ 82.59 MiB │ 29.132328640073343 │ │ clientRealIP │ 2.49 GiB │ 465.05 MiB │ 5.478382297052563 │ │ userAgent │ 18.34 GiB │ 764.08 MiB │ 24.57905114484208 │ │ referer │ 14.71 GiB │ 1.37 GiB │ 10.736792723669906 │ │ response │ 803.06 MiB │ 83.81 MiB │ 9.582334090987247 │ │ subresponse │ 399.87 MiB │ 1.83 MiB │ 218.4831068635027 │ │ win32response │ 407.86 MiB │ 7.41 MiB │ 55.050315514606815 │ │ timetaken │ 1.57 GiB │ 402.06 MiB │ 3.9947395692010637 │ │ uriQuery__utm_medium │ 208.17 MiB │ 12.29 MiB │ 16.936148912472955 │ │ uriQuery__utm_source │ 215.18 MiB │ 13.00 MiB │ 16.548367623199912 │ │ uriQuery__utm_campaign │ 381.46 MiB │ 37.94 MiB │ 10.055156353418509 │ │ uriQuery__utm_term │ 231.82 MiB │ 10.78 MiB │ 21.502540454070672 │ │ uriQuery__utm_content │ 441.34 MiB │ 87.60 MiB │ 5.038260760449327 │ │ uriQuery__yclid │ 216.88 MiB │ 16.58 MiB │ 13.07721335008116 │ │ uriQuery__region │ 204.35 MiB │ 9.49 MiB │ 21.52661903446796 │ └────────────────────────┴──────────────┴────────────┴────────────────────┘ 28 rows in set. Elapsed: 0.005 sec.
Beschreibung der verwendeten Komponenten
FileBeat. Datei Protokollübertragung
Diese Komponente überwacht Änderungen in den Protokolldateien auf der Festplatte und überträgt Informationen an LogStash. Es wird auf allen Servern installiert, auf denen Protokolldateien geschrieben werden (normalerweise IIS). Es funktioniert im Endmodus (d. H. Überträgt nur hinzugefügte Datensätze in eine Datei). Sie können jedoch separat die gesamte Dateiübertragung konfigurieren. Dies ist nützlich, wenn Sie Daten aus früheren Monaten herunterladen müssen. Legen Sie einfach die Protokolldatei in einen Ordner und er wird sie vollständig lesen.
Wenn der Dienst beendet wird, werden die Daten nicht mehr weiter in den Speicher übertragen.
Eine Beispielkonfiguration lautet wie folgt:
filebeat.yml filebeat.inputs: - type: log enabled: true paths: - C:/inetpub/logs/LogFiles/W3SVC1
LogStash Protokollsammler
Diese Komponente dient zum Empfangen von Protokolleinträgen von FileBeat (oder über die RabbitMQ-Warteschlange), zum Parsen und Einfügen von Bundles in die ClickHouse-Datenbank.
Zum Einfügen in ClickHouse wird das Plugin Logstash-output-clickhouse verwendet. Das Logstash-Plugin verfügt über einen Mechanismus zum Abrufen von Anforderungen. Bei einem regelmäßigen Herunterfahren ist es jedoch besser, den Dienst selbst zu stoppen. Wenn Sie anhalten, sammeln sich Nachrichten in der RabbitMQ-Warteschlange an. Wenn Sie also längere Zeit anhalten, ist es besser, Filebeats auf Servern zu stoppen. In einem Schema, in dem RabbitMQ nicht verwendet wird (im lokalen Netzwerk sendet Filebeat Protokolle direkt an Logstash), funktionieren Filebeats recht akzeptabel und sicher, sodass für sie die Unzugänglichkeit der Ausgabe keine Konsequenzen hat.
Eine Beispielkonfiguration lautet wie folgt:
log_web__filebeat_clickhouse.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/logstash/certs/ca.cer", "/etc/logstash/certs/ca-issuing.cer"] ssl_certificate => "/etc/logstash/certs/server.cer" ssl_key => "/etc/logstash/certs/server-pkcs8.key" ssl_verify_mode => "peer" add_field => { "fld_server_name" => "%{[fields][fld_server_name]}" "fld_app_name" => "%{[fields][fld_app_name]}" "fld_app_module" => "%{[fields][fld_app_module]}" "fld_website_name" => "%{[fields][fld_website_name]}" "fld_log_file_name" => "%{source}" "fld_logformat" => "%{[fields][fld_logformat]}" } } rabbitmq { host => "queue.domain.com" port => 5671 user => "q-reader" password => "password" queue => "web_log" heartbeat => 30 durable => true ssl => true
ClickHouse. Protokollspeicher
Protokolle für alle Systeme werden in einer Tabelle gespeichert (siehe Anfang des Artikels). Es dient zum Speichern von Informationen zu Anforderungen: Alle Parameter sind für verschiedene Formate ähnlich, z. B. IIS-Protokolle, Apache- und Nginx-Protokolle. Für Anwendungsprotokolle, in denen beispielsweise Fehler, Informationsmeldungen und Warnungen aufgezeichnet werden, wird eine separate Tabelle mit der entsprechenden Struktur bereitgestellt (jetzt in der Entwurfsphase).
Beim Entwerfen einer Tabelle ist es sehr wichtig, den Primärschlüssel zu bestimmen (nach dem die Daten während der Speicherung sortiert werden). Der Grad der Datenkomprimierung und die Abfragegeschwindigkeit hängen davon ab. In unserem Beispiel ist der Schlüssel
ORDER BY (fld_app_name, fld_app_module, logdatetime)
Das heißt, durch den Namen des Systems, den Namen der Systemkomponente und das Datum des Ereignisses. Das ursprüngliche Datum der Veranstaltung stand an erster Stelle. Nachdem es an den letzten Ort verschoben wurde, begannen die Abfragen etwa zweimal schneller zu arbeiten. Zum Ändern des Primärschlüssels müssen Sie die Tabelle neu erstellen und die Daten neu laden, damit ClickHouse die Daten auf der Festplatte neu sortiert. Dies ist eine schwierige Operation, daher ist es ratsam, im Voraus zu überlegen, was im Sortierschlüssel enthalten sein soll.
Es sollte auch beachtet werden, dass relativ in neueren Versionen der Datentyp LowCardinality aufgetreten ist. Bei Verwendung wird die Größe der komprimierten Daten für Felder mit geringer Kardinalität (wenige Optionen) stark reduziert.
Jetzt wird Version 19.6 verwendet, und wir planen, die Version auf den neuesten Stand zu bringen. Dazu gehörten beispielsweise wunderbare Funktionen wie Adaptive Granularity, Überspringen von Indizes und der DoubleDelta-Codec.
Standardmäßig wird die Protokollstufe der Ablaufverfolgung während der Konfiguration festgelegt. Protokolle werden gedreht und archiviert, aber auf ein Gigabyte erweitert. Wenn dies nicht erforderlich ist, können Sie die Warnstufe festlegen. Die Größe des Protokolls nimmt dann stark ab. Die Protokollierungseinstellungen werden in der Datei config.xml festgelegt:
<level>warning</level>
Einige nützliche Befehle Debian, Linux Altinity. : https://www.altinity.com/blog/2017/12/18/logstash-with-clickhouse sudo yum search clickhouse-server sudo yum install clickhouse-server.noarch 1. sudo systemctl status clickhouse-server 2. sudo systemctl stop clickhouse-server 3. sudo systemctl start clickhouse-server ( ";") clickhouse-client
LogStash FileBeat-Protokollrouter zur RabbitMQ-Warteschlange
Diese Komponente wird verwendet, um von FileBeat kommende Protokolle an die RabbitMQ-Warteschlange weiterzuleiten. Es gibt zwei Punkte:
- Leider verfügt FileBeat nicht über ein Ausgabe-Plugin zum direkten Schreiben in RabbitMQ. Und eine solche Funktionalität ist nach dem ish auf ihrem Github nicht für die Implementierung geplant. Es gibt ein Plugin für Kafka, aber aus irgendeinem Grund können wir es zu Hause nicht verwenden.
- Es gibt Anforderungen für das Sammeln von Protokollen in der DMZ. Basierend darauf müssen die Protokolle zuerst zur Warteschlange hinzugefügt werden, und dann liest LogStash von außen die Einträge aus der Warteschlange.
Daher müssen Sie genau für den Fall des Serverstandorts in der DMZ ein derart etwas kompliziertes Schema verwenden. Eine Beispielkonfiguration lautet wie folgt:
iis_w3c_logs__filebeat_rabbitmq.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/pki/tls/certs/app/ca.pem", "/etc/pki/tls/certs/app/ca-issuing.pem"] ssl_certificate => "/etc/pki/tls/certs/app/queue.domain.com.cer" ssl_key => "/etc/pki/tls/certs/app/queue.domain.com-pkcs8.key" ssl_verify_mode => "peer" } } output {
RabbitMQ. Nachrichtenwarteschlange
Diese Komponente wird verwendet, um Protokolleinträge in der DMZ zu puffern. Die Aufnahme erfolgt über eine Reihe von Filebeat → LogStash. Das Lesen erfolgt von außerhalb der DMZ über LogStash. Beim Betrieb über RabboitMQ werden ungefähr 4.000 Nachrichten pro Sekunde verarbeitet.
Das Nachrichtenrouting wird gemäß dem Namen des Systems konfiguriert, d. H. Basierend auf FileBeat-Konfigurationsdaten. Alle Nachrichten fallen in eine Warteschlange. Wenn der Warteschlangendienst aus irgendeinem Grund gestoppt wird, führt dies nicht zum Verlust von Nachrichten: FileBeats empfängt Verbindungsfehler und setzt das temporäre Senden aus. Und LogStash, das aus der Warteschlange liest, empfängt auch Netzwerkfehler und wartet, bis die Verbindung wieder aufgenommen wird. Die Daten werden in diesem Fall natürlich nicht mehr in die Datenbank geschrieben.
Die folgenden Anweisungen werden zum Erstellen und Konfigurieren von Warteschlangen verwendet:
sudo /usr/local/bin/rabbitmqadmin/rabbitmqadmin declare exchange
Grafana Dashboards
Diese Komponente wird zur Visualisierung von Überwachungsdaten verwendet. In diesem Fall müssen Sie die ClickHouse-Datenquelle für das Grafana 4.6+ Plugin installieren. Wir mussten es ein wenig optimieren, um die Effizienz der Verarbeitung von SQL-Filtern in einem Dashboard zu erhöhen.
Zum Beispiel verwenden wir Variablen, und wenn sie nicht im Filterfeld festgelegt sind, möchten wir, dass keine Bedingung in der WHERE-Form generiert wird (uriStem = `` AND uriStem! = ''). In diesem Fall liest ClickHouse die uriStem-Spalte. Im Allgemeinen haben wir verschiedene Optionen ausprobiert und schließlich das Plugin (Makro $ valueIfEmpty) so korrigiert, dass bei einem leeren Wert 1 zurückgegeben wird, ohne die Spalte selbst zu erwähnen.
Und jetzt können Sie diese Abfrage für das Diagramm verwenden
$columns(response, count(*) c) from $table where $adhoc and $valueIfEmpty($fld_app_name, 1, fld_app_name = '$fld_app_name') and $valueIfEmpty($fld_app_module, 1, fld_app_module = '$fld_app_module') and $valueIfEmpty($fld_server_name, 1, fld_server_name = '$fld_server_name') and $valueIfEmpty($uriStem, 1, uriStem like '%$uriStem%') and $valueIfEmpty($clientRealIP, 1, clientRealIP = '$clientRealIP')
Dies wird in eine solche SQL konvertiert (beachten Sie, dass leere uriStem-Felder in nur 1 konvertiert wurden).
SELECT t, groupArray((response, c)) AS groupArr FROM ( SELECT (intDiv(toUInt32(logdatetime), 60) * 60) * 1000 AS t, response, count(*) AS c FROM default.log_web WHERE (logdate >= toDate(1565061982)) AND (logdatetime >= toDateTime(1565061982)) AND 1 AND (fld_app_name = 'site1.domain.ru') AND (fld_app_module = 'web') AND 1 AND 1 AND 1 GROUP BY t, response ORDER BY t ASC, response ASC ) GROUP BY t ORDER BY t ASC
Fazit
Das Erscheinen der ClickHouse-Datenbank ist zu einem Meilenstein auf dem Markt geworden. Es war kaum vorstellbar, dass wir sofort kostenlos mit einem leistungsstarken und praktischen Tool für die Arbeit mit Big Data ausgestattet waren. Mit zunehmenden Anforderungen (z. B. Sharding und Replikation auf mehrere Server) wird das Schema natürlich komplexer. Aber auf den ersten Blick ist die Arbeit mit dieser Datenbank sehr schön. Es ist ersichtlich, dass das Produkt "für Menschen" hergestellt wird.
Im Vergleich zu ElasticSearch reduzieren sich die Kosten für das Speichern und Verarbeiten von Protokollen nach vorläufigen Schätzungen von fünf auf das Zehnfache. Mit anderen Worten, wenn wir für die aktuelle Datenmenge einen Cluster aus mehreren Computern konfigurieren müssten, benötigen wir bei Verwendung von ClickHouse nur einen Computer mit geringem Stromverbrauch. Ja, ElasticSearch verfügt natürlich auch über Mechanismen zum Komprimieren von Daten auf der Festplatte und andere Funktionen, die den Ressourcenverbrauch erheblich reduzieren können. Im Vergleich zu ClickHouse ist dies jedoch kostspielig.
Ohne spezielle Optimierungen funktioniert das Laden von Daten und das Abrufen von Daten aus der Datenbank in den Standardeinstellungen mit erstaunlicher Geschwindigkeit. Bisher haben wir ein paar Daten (ungefähr 200 Millionen Datensätze), aber der Server selbst ist schwach. In Zukunft können wir dieses Tool für andere Zwecke verwenden, die nicht mit der Speicherung von Protokollen zusammenhängen. Zum Beispiel für End-to-End-Analysen im Bereich Sicherheit, maschinelles Lernen.
Am Ende ein wenig über die Vor- und Nachteile.
Nachteile
- Herunterladen von Datensätzen in großen Paketen. Dies ist einerseits eine Funktion, aber Sie müssen immer noch zusätzliche Komponenten verwenden, um Datensätze zu puffern. Diese Aufgabe ist nicht immer einfach, aber dennoch lösbar. Und ich möchte das Schema vereinfachen.
- Einige exotische Funktionen oder neue Funktionen werden häufig in neuen Versionen verwendet. Dies wirft Bedenken auf und verringert den Wunsch nach einem Upgrade auf eine neue Version. Beispielsweise ist die Kafka-Tabellen-Engine eine sehr nützliche Funktion, mit der Sie Ereignisse aus Kafka direkt lesen können, ohne dass Verbraucher implementiert werden müssen. Gemessen an der Anzahl der Probleme auf dem Github sind wir jedoch immer noch vorsichtig, diesen Motor in der Produktion einzusetzen. Wenn Sie jedoch keine scharfen Bewegungen zur Seite ausführen und die Grundfunktionalität verwenden, funktioniert dies stabil.
Vorteile
- Es verlangsamt sich nicht.
- Niedrige Eintrittsschwelle.
- Open Source
- Es ist kostenlos.
- Skaliert gut (Out-of-Box-Sharding / Replikation)
- Es ist in dem vom Ministerium für Kommunikation empfohlenen Register russischer Software enthalten.
- Das Vorhandensein offizieller Unterstützung von Yandex.