Habr-Konferenz - die Geschichte ist kein Debüt. Früher haben wir ziemlich große Toaster-Veranstaltungen für 300 bis 400 Personen abgehalten, aber jetzt haben wir beschlossen, dass kleine thematische Besprechungen relevant sind, deren Richtung Sie auch festlegen können - zum Beispiel in den Kommentaren. Die erste Konferenz dieses Formats fand im Juli statt und war der Backend-Entwicklung gewidmet. Die Teilnehmer hörten sich Berichte über die Funktionen des Übergangs vom Backend zu ML und zum Quadrupel-Dienstgerät im State Services-Portal an und nahmen an einem runden Tisch teil, der sich mit Serverless befasste. Für diejenigen, die nicht persönlich an der Veranstaltung teilnehmen konnten, erzählen wir in diesem Beitrag das Interessanteste.

Von der Backend-Entwicklung bis zum maschinellen Lernen
Was machen ML-Dateningenieure? Was sind die Ähnlichkeiten und Unterschiede zwischen den Aufgaben des Backend-Entwicklers und des ML-Ingenieurs? Welchen Weg müssen Sie gehen, um den ersten Beruf in den zweiten zu verwandeln? Dies erzählte Alexander Parinov, der nach 10 Jahren Backend in das maschinelle Lernen einstieg.
 Alexander Parinov
Alexander ParinovHeute arbeitet Alexander als Architekt für Computer-Vision-Systeme bei der X5 Retail Group und trägt zu Open-Source-Projekten im Zusammenhang mit Computer-Vision und Deep Learning bei (github.com/creafz). Seine Fähigkeiten werden durch seine Teilnahme an den Top 100 der Weltrangliste Kaggle Master (kaggle.com/creafz) bestätigt - der beliebtesten Plattform, auf der Wettbewerbe für maschinelles Lernen stattfinden.
Warum auf maschinelles Lernen umsteigen?
Vor anderthalb Jahren beschrieb Jeff Dean, Leiter von Google Brain, Googles eingehender Studie zu Googles Forschungsprojekt zur künstlichen Intelligenz, wie eine halbe Million Codezeilen in Google Translate durch ein neuronales Netzwerk mit Tensor Flow ersetzt wurden, das aus nur 500 Zeilen besteht. Nach dem Training des Netzwerks ist die Datenqualität gestiegen und die Infrastruktur wurde vereinfacht. Es scheint, dass hier unsere glänzende Zukunft liegt: Wir müssen keinen Code mehr schreiben, sondern nur Neuronen erstellen und sie mit Daten werfen. In der Praxis ist jedoch alles viel komplizierter.
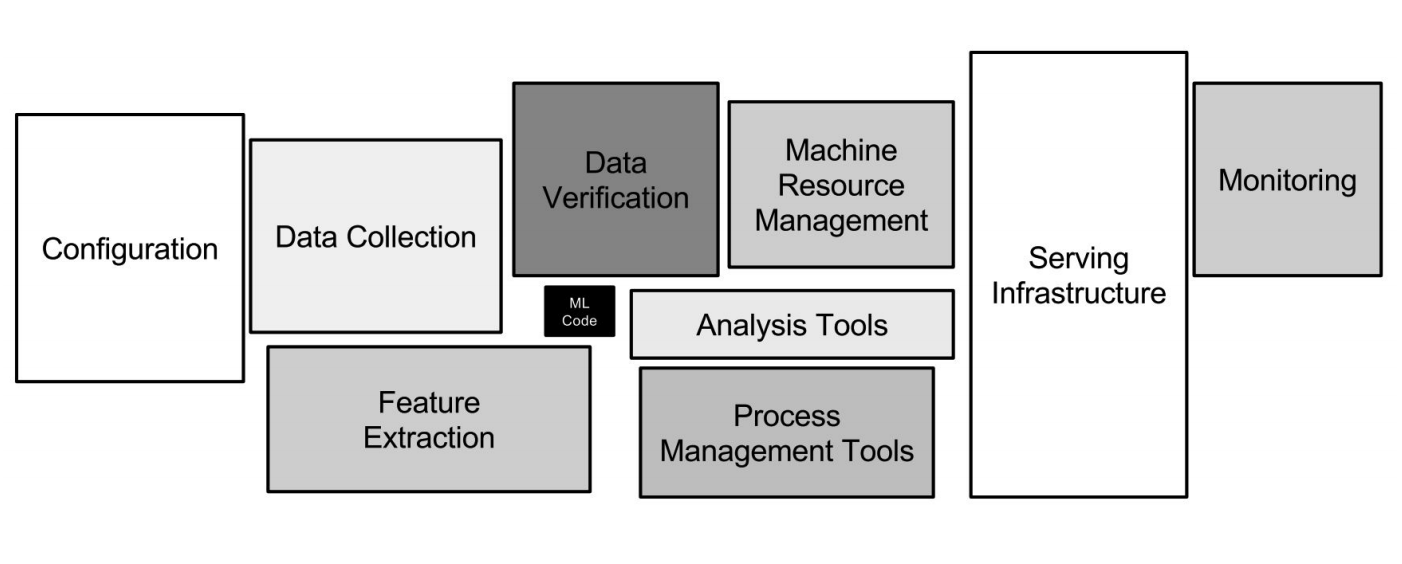 Google ML-Infrastruktur
Google ML-InfrastrukturNeuronale Netze sind nur ein kleiner Teil der Infrastruktur (eine kleine Blackbox im Bild oben). Es sind viel mehr Hilfssysteme erforderlich, um Daten zu empfangen, zu verarbeiten, zu speichern, die Qualität zu überprüfen usw. Wir benötigen die Infrastruktur für Schulungen, die Bereitstellung von Code für maschinelles Lernen in der Produktion und das Testen dieses Codes. All diese Aufgaben entsprechen genau den Aufgaben der Backend-Entwickler.
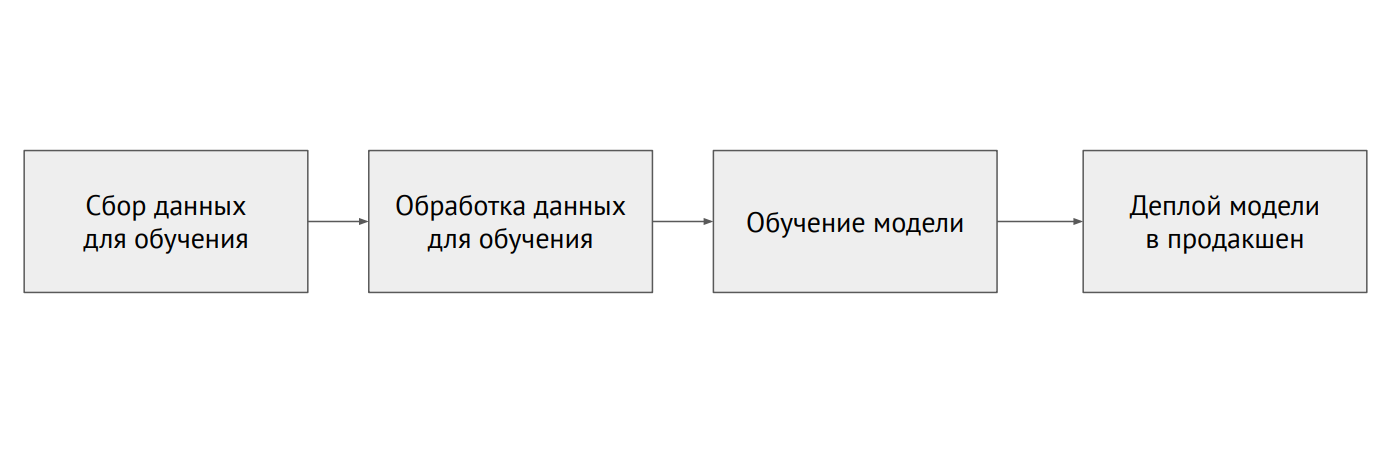 Maschineller Lernprozess
Maschineller LernprozessWas ist der Unterschied zwischen ML und Backend?
In der klassischen Programmierung schreiben wir Code, und dies bestimmt das Verhalten des Programms. In ML haben wir einen kleinen Modellcode und viele Daten, mit denen wir das Modell löschen. Daten in ML sind sehr wichtig: Das gleiche Modell, das mit unterschiedlichen Daten trainiert wurde, kann völlig unterschiedliche Ergebnisse zeigen. Das Problem ist, dass fast immer die Daten fragmentiert sind und in verschiedenen Systemen liegen (relationale Datenbanken, NoSQL-Datenbanken, Protokolle, Dateien).
 Datenversionierung
DatenversionierungML erfordert nicht nur die Versionierung des Codes, wie in der klassischen Entwicklung, sondern auch der Daten: Es ist notwendig, klar zu verstehen, worauf das Modell trainiert wurde. Hierfür können Sie die beliebte Data Science-Versionskontrollbibliothek (dvc.org) verwenden.
 Datenmarkup
DatenmarkupDie nächste Aufgabe ist das Datenmarkup. Markieren Sie beispielsweise alle Objekte im Bild oder sagen Sie, zu welcher Klasse sie gehört. Dies geschieht durch spezielle Dienste wie Yandex.Tolki, mit denen die Verfügbarkeit der API erheblich vereinfacht wird. Schwierigkeiten ergeben sich aus dem „menschlichen Faktor“: Es ist möglich, die Datenqualität zu verbessern und Fehler zu minimieren, indem dieselbe Aufgabe mehreren Darstellern anvertraut wird.
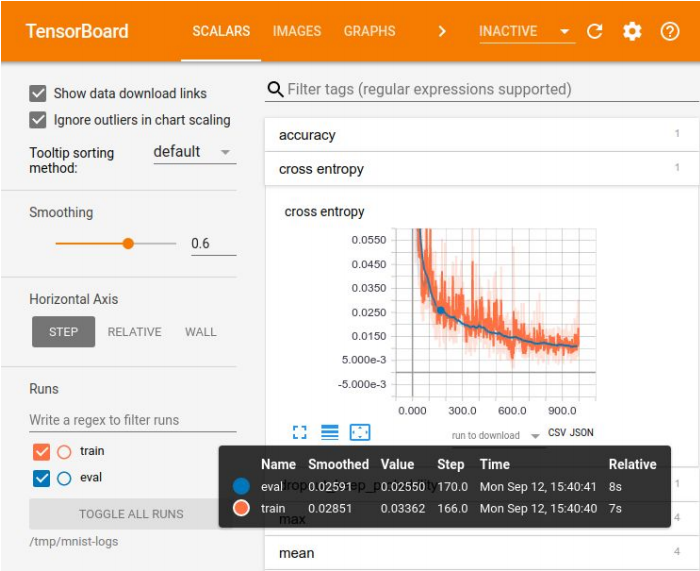 Visualisierung in Tensor Board
Visualisierung in Tensor BoardDie Protokollierung von Experimenten ist erforderlich, um die Ergebnisse zu vergleichen und das beste Modell für einige Metriken auszuwählen. Zur Visualisierung gibt es eine Vielzahl von Werkzeugen - zum Beispiel Tensor Board. Es gibt jedoch keine idealen Methoden zum Speichern von Experimenten. In kleinen Unternehmen kommen sie oft mit einer Excel-Platte aus, in großen Unternehmen verwenden sie spezielle Plattformen, um Ergebnisse in der Datenbank zu speichern.
 Es gibt viele Plattformen für maschinelles Lernen, aber keine davon deckt sogar 70% des Bedarfs ab
Es gibt viele Plattformen für maschinelles Lernen, aber keine davon deckt sogar 70% des Bedarfs abDas erste Problem, mit dem Sie sich befassen müssen, wenn Sie ein geschultes Modell in die Produktion bringen, hängt mit Ihrem bevorzugten Datenwissenschaftler-Tool zusammen - Jupyter Notebook. Es gibt keine Modularität, das heißt, die Ausgabe ist ein solcher "Fußabfall" von Code, der nicht in logische Teile zerlegt wird - Module. Alles ist durcheinander: Klassen, Funktionen, Konfigurationen usw. Dieser Code ist schwer zu versionieren und zu testen.
Wie gehe ich damit um? Sie können sich mit Netflix abfinden und eine eigene Plattform erstellen, auf der Sie diese Laptops direkt in der Produktion ausführen, Daten an sie übertragen und das Ergebnis erhalten können. Sie können Entwickler, die das Modell in die Produktion rollen, dazu zwingen, den Code normal umzuschreiben und in Module aufzuteilen. Bei diesem Ansatz ist es jedoch leicht, einen Fehler zu machen, und das Modell funktioniert nicht wie beabsichtigt. Daher ist die ideale Option, die Verwendung von Jupyter Notebook für Modellcode zu verbieten. Wenn Data Scientists dem natürlich zustimmen.
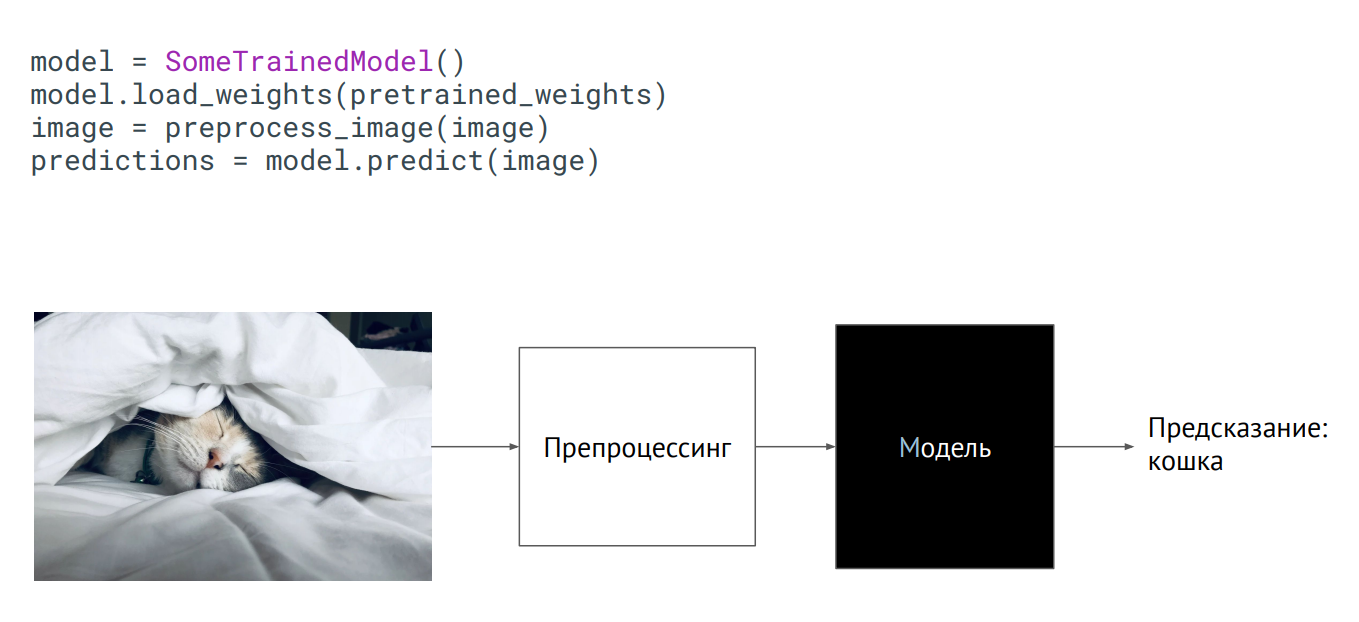 Modell als Black Box
Modell als Black BoxDer einfachste Weg, ein Modell in Produktion zu bringen, besteht darin, es als Black Box zu verwenden. Sie haben eine Klasse des Modells, die Gewichte des Modells (Parameter der Neuronen des trainierten Netzwerks) wurden an Sie übergeben, und wenn Sie diese Klasse initialisieren (die Vorhersagemethode aufrufen, ein Bild darauf setzen), erhält die Ausgabe eine Art Vorhersage. Was drinnen passiert, spielt keine Rolle.
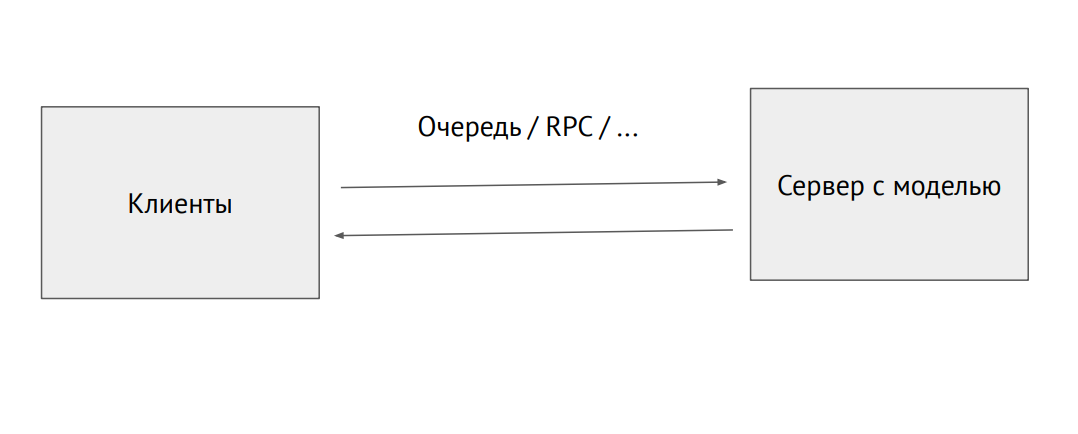 Separater Serverprozess mit einem Modell
Separater Serverprozess mit einem ModellSie können auch einen separaten Prozess abrufen und über die RPC-Warteschlange senden (mit Bildern oder anderen Quelldaten. Am Ausgang erhalten wir Vorhersagen.
Ein Beispiel für die Verwendung des Modells in Flask:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
Das Problem bei diesem Ansatz ist die Leistungsbeschränkung. Angenommen, wir haben einen Phyton-Code, der von Datenwissenschaftlern geschrieben wurde und langsamer wird, und wir möchten die maximale Leistung einschränken. Zu diesem Zweck können Sie Tools verwenden, die den Code in native oder in ein anderes Framework konvertieren, das für die Produktion geschärft wurde. Es gibt solche Tools für jedes Framework, aber es gibt keine idealen Tools. Sie müssen es selbst fertigstellen.
Die Infrastruktur in ML ist dieselbe wie in einem regulären Backend. Es gibt Docker und Kubernetes. Nur für Docker müssen Sie die NVIDIA-Laufzeit festlegen, damit die Prozesse im Container auf die Grafikkarten im Host zugreifen können. Kubernetes benötigt ein Plugin, um Server mit Grafikkarten verwalten zu können.
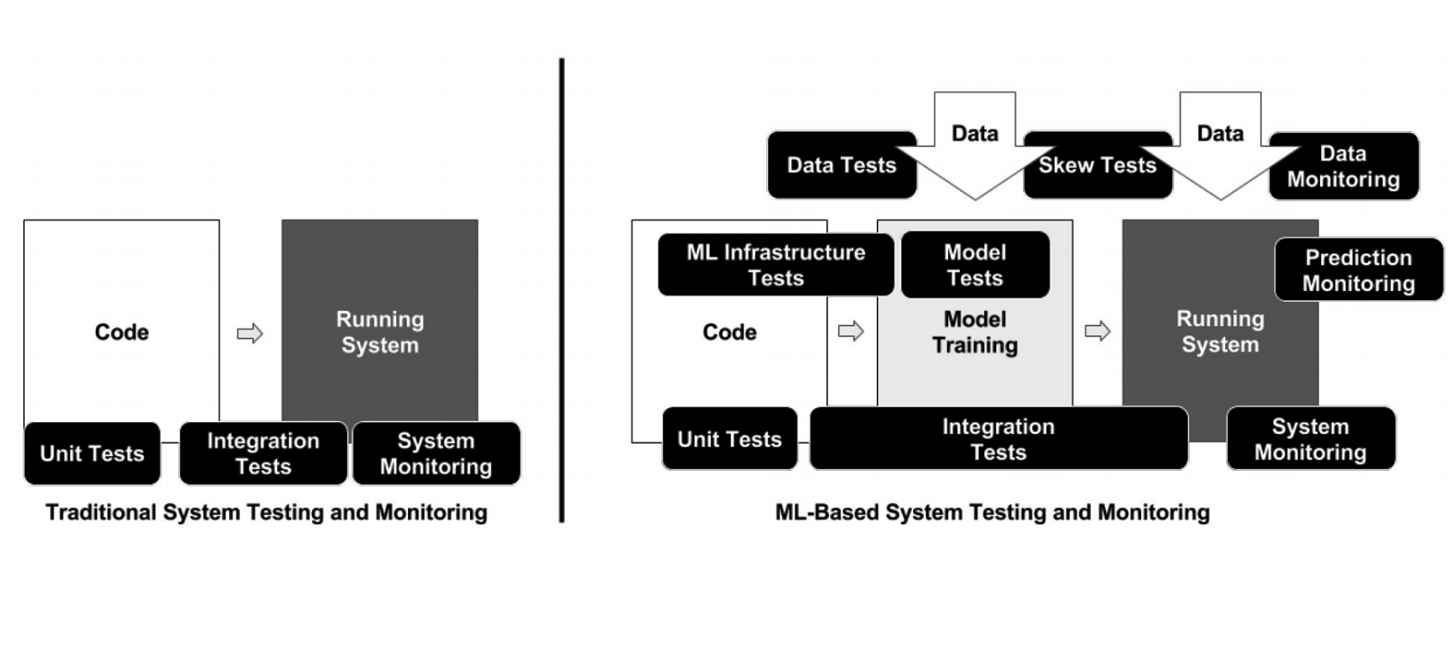
Im Gegensatz zur klassischen Programmierung weist die Infrastruktur im Fall von ML viele verschiedene bewegliche Elemente auf, die überprüft und getestet werden müssen - beispielsweise Datenverarbeitungscode, Modellschulungspipeline und Produktion (siehe Abbildung oben). Es ist wichtig, den Code zu testen, der verschiedene Pipelines verbindet: Es gibt viele Teile, und an den Grenzen von Modulen treten sehr häufig Probleme auf.
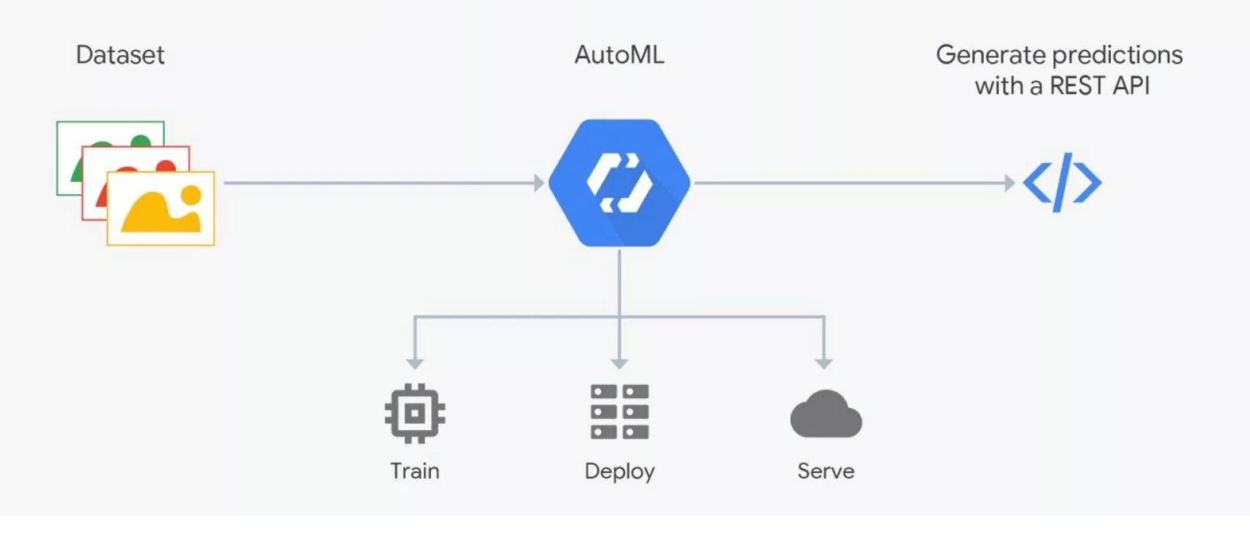 Wie AutoML funktioniert
Wie AutoML funktioniertAutoML-Services versprechen, das beste Modell für Ihre Ziele auszuwählen und zu trainieren. Aber Sie müssen verstehen: In ML sind Daten sehr wichtig, das Ergebnis hängt von ihrer Vorbereitung ab. Die Leute markieren, was mit Fehlern behaftet ist. Ohne strenge Kontrolle kann sich Müll herausstellen, aber die Automatisierung funktioniert noch nicht. Überprüfung durch Experten - Datenwissenschaftler sind erforderlich. Hier „bricht“ AutoML. Dies kann jedoch bei der Auswahl der Architektur hilfreich sein - wenn Sie die Daten bereits vorbereitet haben und eine Reihe von Experimenten durchführen möchten, um das beste Modell zu finden.
Wie man in maschinelles Lernen einsteigt
Der Einstieg in ML ist am einfachsten, wenn Sie in Python entwickeln, das in allen Deep-Learning-Frameworks (und regulären Frameworks) verwendet wird. Diese Sprache ist für dieses Tätigkeitsfeld praktisch erforderlich. C ++ wird für einige Aufgaben mit Computer Vision verwendet - beispielsweise in Steuerungssystemen unbemannter Fahrzeuge. JavaScript und Shell - zur Visualisierung und für so seltsame Dinge wie das Starten eines Neurons in einem Browser. Java und Scala werden bei der Arbeit mit Big Data und beim maschinellen Lernen verwendet. R und Julia werden von Leuten geliebt, die Statistiken machen.
Bei Kaggle ist es am bequemsten, zunächst praktische Erfahrungen zu sammeln. Die Teilnahme an einem der Wettbewerbe der Plattform bietet mehr als ein Jahr Zeit, um die Theorie zu studieren. Auf dieser Plattform können Sie den angelegten und kommentierten Code einer anderen Person verwenden und versuchen, ihn zu verbessern und für Ihre Ziele zu optimieren. Der Bonusrang bei Kaggle wirkt sich auf Ihr Gehalt aus.
Eine weitere Möglichkeit besteht darin, als Backend-Entwickler zum ML-Team zu wechseln. Mittlerweile gibt es viele Startups im Bereich maschinelles Lernen, bei denen Sie Erfahrungen sammeln, indem Sie Kollegen bei der Lösung ihrer Probleme helfen. Schließlich können Sie einer der Data Scientist-Communities beitreten - Open Data Science (ods.ai) und anderen.
Der Redner platzierte zusätzliche Informationen zum Thema unter https://bit.ly/backend-to-ml
"Quadrupel" - der Dienst für gezielte Benachrichtigungen des Portals "State Services"

Evgeny Smirnov
Der nächste Redner war Jewgeni Smirnow, Leiter der Abteilung für E-Government-Infrastrukturentwicklung, der über das Quadrupel sprach. Dies ist ein gezielter Benachrichtigungsdienst des Gosuslugi-Portals (gosuslugi.ru), der meistbesuchten staatlichen Ressource im russischen Internet. Das tägliche Publikum beträgt 2,6 Millionen, insgesamt sind 90 Millionen Benutzer auf der Website registriert, von denen 60 Millionen bestätigt werden. Die Last auf der Portal-API beträgt 30.000 RPS.
 Im Gosuslug-Backend verwendete Technologien
Im Gosuslug-Backend verwendete Technologien"Vierfach" ist ein Adressbenachrichtigungsdienst, mit dessen Hilfe der Benutzer zum für ihn am besten geeigneten Zeitpunkt ein Serviceangebot erhält, indem er spezielle Informationsregeln einrichtet. Die Hauptanforderungen bei der Entwicklung des Dienstes waren flexible Einstellungen und eine angemessene Zeit für den Versand.
Wie funktioniert das Vierfache?

Das obige Diagramm zeigt eine der Regeln des „Vierfachen“ am Beispiel einer Situation, in der ein Führerschein ersetzt werden muss. Zunächst sucht der Dienst nach Benutzern, deren Ablaufdatum in einem Monat abläuft. Sie stellen ein Banner mit einem Angebot auf, den entsprechenden Service zu erhalten und eine E-Mail-Nachricht zu senden. Für Benutzer, die bereits abgelaufen sind, ändern sich das Banner und die E-Mail-Adresse. Nach einem erfolgreichen Austausch von Rechten erhält der Benutzer weitere Benachrichtigungen - mit dem Vorschlag, die Daten im Zertifikat zu aktualisieren.
Aus technischer Sicht sind dies groovige Skripte, in die Code geschrieben ist. An den Eingangsdaten, am Ausgang - wahr / falsch, übereinstimmend / nicht übereinstimmend. Insgesamt mehr als 50 Regeln - von der Bestimmung des Geburtstages des Benutzers (das aktuelle Datum entspricht dem Geburtstag des Benutzers) bis hin zu schwierigen Situationen. Jeden Tag werden nach diesen Regeln etwa eine Million Spiele ermittelt - Personen, die benachrichtigt werden müssen.
 Vierfache Benachrichtigungskanäle
Vierfache BenachrichtigungskanäleUnter der Haube des Quadrupel befindet sich eine Datenbank, in der Benutzerdaten gespeichert sind, und drei Anwendungen:
- Worker dient zum Aktualisieren von Daten.
- Die Rest-API nimmt die Banner selbst auf und gibt sie an das Portal und an die mobile Anwendung weiter.
- Scheduler startet Banner-Nachzählungen oder Massenversand.
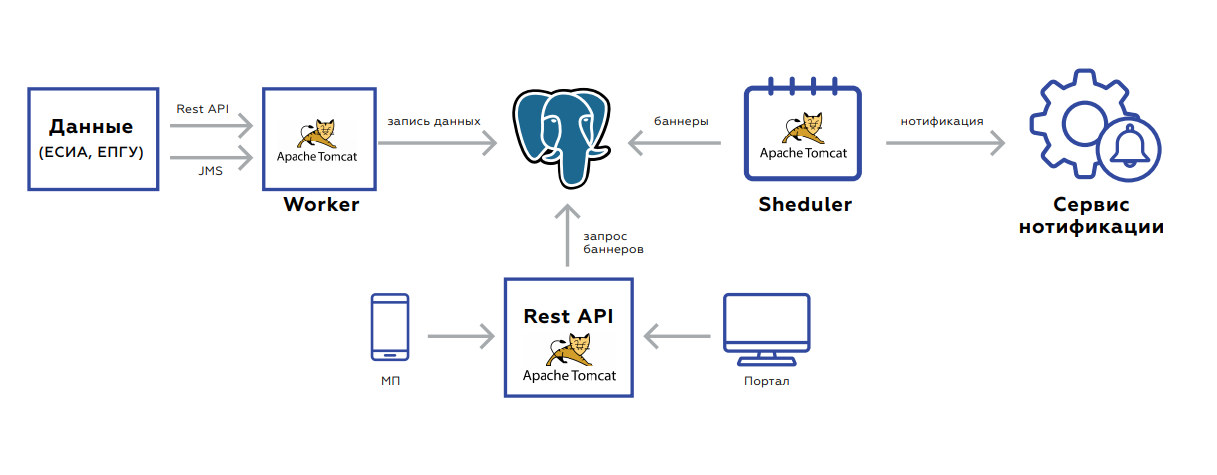
Das Backend ist ereignisorientiert zum Aktualisieren von Daten. Zwei Schnittstellen - Rest oder JMS. Es gibt viele Ereignisse, bevor sie gespeichert und verarbeitet werden. Sie werden aggregiert, um keine unnötigen Anforderungen zu stellen. Die Datenbank selbst, die Platte, auf der die Daten gespeichert sind, sieht aus wie die Speicherung von Schlüsselwerten - der Schlüssel des Benutzers und der Wert selbst: Flags, die das Vorhandensein oder Fehlen relevanter Dokumente, deren Gültigkeitsdauer, aggregierte Statistiken über die Reihenfolge der Dienste dieses Benutzers usw. anzeigen.

Nach dem Speichern der Daten wird die Aufgabe in JMS so eingestellt, dass die Banner sofort nachgezählt werden - dies muss sofort im Web angezeigt werden. Das System startet nachts: In JMS werden Aufgaben in Benutzerintervallen ausgelöst, nach denen Sie die Regeln nachzählen müssen. Dies wird von Nachzählern aufgegriffen. Ferner fallen die Verarbeitungsergebnisse in die nächste Warteschlange, die entweder die Banner in der Datenbank speichert oder Aufgaben an den Benutzer sendet, um den Benutzer zu benachrichtigen. Der Prozess dauert 5-7 Stunden und ist leicht skalierbar, da Sie mit neuen Prozessoren jederzeit entweder Prozessoren löschen oder Instanzen auslösen können.

Der Service funktioniert ganz gut. Die Datenmenge wächst jedoch mit zunehmender Anzahl von Benutzern. Dies führt zu einer Erhöhung der Datenbanklast - selbst unter Berücksichtigung der Tatsache, dass die Rest-API das Replikat betrachtet. Der zweite Punkt ist JMS, das, wie sich herausstellte, aufgrund des hohen Speicherverbrauchs nicht sehr geeignet ist. Bei JMS-Absturz und Verarbeitungsstopp besteht ein hohes Risiko eines Warteschlangenüberlaufs. Es ist unmöglich, das JMS danach anzuheben, ohne die Protokolle zu bereinigen.
Es ist geplant, Probleme mithilfe von Splittern zu lösen, um die Last auf der Basis auszugleichen. Es ist auch geplant, das Datenspeicherschema zu ändern und das JMS in Kafka zu ändern - eine fehlertolerantere Lösung, die Speicherprobleme löst.
Backend-as-a-Service Vs. Serverlos
 Von links nach rechts: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara Israelyan
Von links nach rechts: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara IsraelyanBackend als Service oder serverlose Lösung? Folgende Personen nahmen an der Diskussion dieses dringenden Themas am Runden Tisch teil:
- Ara Israelyan, CTO CTO und Gründer von Scorocode.
- Nikolay Markov, Senior Data Engineer bei der Aligned Research Group.
- Andrey Tomilenko, Leiter der Entwicklungsabteilung RUVDS.
Das Gespräch wurde von Senior-Entwickler Alexander Borgart moderiert. Wir präsentieren die Debatte, an der das Publikum teilgenommen hat, in einer gekürzten Fassung.
- Was ist Serverless nach Ihrem Verständnis?
Andrei : Dies ist ein Rechenmodell - eine Lambda-Funktion, die Daten verarbeiten soll, damit das Ergebnis nur von den Daten abhängt. Der Begriff stammt von Google oder von Amazon und seinem AWS Lambda-Dienst. Für den Anbieter ist es einfacher, eine solche Funktion zu verarbeiten, indem er hierfür einen Kapazitätspool zuweist. Verschiedene Benutzer können unabhängig voneinander auf denselben Servern berücksichtigt werden.
Nikolay : Wenn es einfach ist, übertragen wir einen Teil unserer IT-Infrastruktur, die Geschäftslogik, in die Cloud, um sie auszulagern.
Ara : Seitens der Entwickler - ein guter Versuch, Ressourcen zu sparen, seitens der Vermarkter - um mehr Geld zu verdienen.
- Serverlos - das gleiche wie Microservices?
Nikolai : Nein, Serverless ist eher eine Organisation der Architektur. Microservice ist eine atomare Einheit einer bestimmten Logik. Serverless ist ein Ansatz, keine „separate Entität“.
Ara : Die Serverless-Funktion kann in einen Microservice gepackt werden, aber ab diesem Zeitpunkt ist sie nicht mehr serverlos, sondern keine Lambda-Funktion mehr. In Serverless wird eine Funktion nur gestartet, wenn sie angefordert wird.
Andrew : Sie unterscheiden sich in der Lebenszeit. Wir haben die Lambda-Funktion gestartet und vergessen. Es hat einige Sekunden lang funktioniert, und der nächste Client kann seine Anforderung auf einem anderen physischen Computer verarbeiten.
- Welche Waage ist besser?
Ara : Bei horizontaler Skalierung verhalten sich Lambda-Funktionen genauso wie Microservices.
Nikolai : Wie viele Replikate Sie fragen - es werden so viele sein, dass es keine Probleme mit der serverlosen Skalierung gibt. Kubernetes hat ein Replikatset erstellt, 20 Instanzen "irgendwo" gestartet und 20 anonymisierte Links an Sie zurückgegeben. Mach weiter!
- Ist es möglich, ein Backend auf Serverless zu schreiben?
Andrew : Theoretisch, aber das hat keinen Sinn. Lambda-Funktionen ruhen auf einem einzigen Repository - wir müssen eine Garantie geben. Wenn der Benutzer beispielsweise eine bestimmte Transaktion durchgeführt hat, sollte das nächste Mal, wenn er Folgendes sehen sollte: Die Transaktion wurde abgeschlossen, das Geld gutgeschrieben. Alle Lambda-Funktionen werden bei diesem Aufruf blockiert. Tatsächlich wird aus einer Reihe von Serverless-Funktionen ein einziger Dienst mit einem engen Zugriffspunkt auf die Datenbank.
- In welchen Situationen ist es sinnvoll, eine Architektur ohne Server zu verwenden?
Andrew : Aufgaben, bei denen kein gemeinsamer Speicher erforderlich ist - dasselbe Mining, dieselbe Blockchain. Wo Sie viel zählen müssen. Wenn Sie über viel Rechenleistung verfügen, können Sie eine Funktion wie "Berechnen Sie den Hash von etwas dort ..." definieren. Sie können das Problem der Datenspeicherung jedoch lösen, indem Sie beispielsweise Amazon- und Lambda-Funktionen sowie deren verteilten Speicher verwenden. Und es stellt sich heraus, dass Sie einen regulären Dienst schreiben. Lambda-Funktionen greifen auf das Repository zu und geben dem Benutzer eine Antwort.
Nikolai : Container, die unter Serverless ausgeführt werden, sind äußerst ressourcenbeschränkt. Es gibt wenig Gedächtnis und alles andere. Wenn Sie jedoch die gesamte Infrastruktur vollständig in einer Cloud bereitgestellt haben - Google, Amazon - und einen dauerhaften Vertrag mit ihnen haben, gibt es ein Budget für all dies. Für einige Aufgaben können Sie Serverless-Container verwenden. Es ist notwendig, genau innerhalb dieser Infrastruktur zu sein, da alles auf die Verwendung in einer bestimmten Umgebung zugeschnitten ist. Das heißt, wenn Sie bereit sind, alles an die Cloud-Infrastruktur zu binden, können Sie experimentieren. Das Plus ist, dass Sie diese Infrastruktur nicht verwalten müssen.
Ara : Dass Serverless nicht erfordert, dass Sie Kubernetes, Docker, Kafka usw. verwalten, ist Selbsttäuschung. Das gleiche Amazon und Google sind der Manager und sie sagen es. Eine andere Sache ist, dass Sie eine SLA haben. Mit dem gleichen Erfolg können Sie alles auslagern und nicht selbst programmieren.
Andrew : Serverless selbst ist kostengünstig, aber für den Rest der Amazon-Dienste muss man viel bezahlen - zum Beispiel für eine Datenbank. Die Leute haben sie bereits verklagt, weil sie verrücktes Geld für das API-Gate zerrissen haben.
Ara : Wenn wir über Geld sprechen, müssen Sie diesen Punkt berücksichtigen: Sie müssen die gesamte Entwicklungsmethode im Unternehmen um 180 Grad bereitstellen, um den gesamten Code auf Serverless zu übertragen. Es wird viel Zeit und Geld kosten.
- Gibt es vernünftige Alternativen zu bezahlten serverlosen Amazon und Google?
Nikolay : In Kubernetes beginnt man eine Art Job, der erfüllt und stirbt - dies ist aus architektonischer Sicht ziemlich serverlos. Wenn Sie eine wirklich interessante Geschäftslogik mit Warteschlangen und Basen erstellen möchten, müssen Sie etwas mehr darüber nachdenken. Dies ist alles gelöst, ohne Kubernetes zu verlassen. Ich würde nicht anfangen, zusätzliche Implementierung zu ziehen.
- Wie wichtig ist es zu überwachen, was in Serverless passiert?
Ara : Abhängig von der Systemarchitektur und den Geschäftsanforderungen. Tatsächlich sollte der Anbieter Berichte bereitstellen, die dem Entwickler helfen, mögliche Probleme herauszufinden.
Nikolai : In Amazon gibt es CloudWatch, wo alle Protokolle gestreamt werden, auch mit Lambda. Integrieren Sie die Protokollweiterleitung und verwenden Sie ein separates Tool zum Anzeigen, Warnen usw. In den Containern, die Sie starten, können Sie Agenten stopfen.
 - Fassen wir zusammen.
- Fassen wir zusammen.
Andrew : Über Lambda-Funktionen nachzudenken ist nützlich. Wenn Sie einen Dienst auf dem Knie erstellen - keinen Mikrodienst, sondern einen, der eine Anforderung schreibt, auf die Datenbank zugreift und eine Antwort sendet - löst die Lambda-Funktion eine Reihe von Problemen: Multithreading, Skalierbarkeit und mehr. Wenn Ihre Logik auf diese Weise aufgebaut ist, können Sie diese Lambda in Zukunft auf Microservices übertragen oder Dienste von Drittanbietern wie Amazon nutzen. Die Technologie ist nützlich, eine interessante Idee. Inwieweit dies für das Geschäft gerechtfertigt ist, ist noch offen.
Nikolai: Serverless ist besser für Betriebsaufgaben zu verwenden, als eine Art Geschäftslogik zu berechnen. Ich nehme das immer als Ereignisverarbeitung. Wenn Sie es in Amazon haben, wenn Sie in Kubernetes sind - ja. Andernfalls müssen Sie viele Anstrengungen unternehmen, um Serverless selbst zu erhöhen. Sie müssen einen bestimmten Geschäftsfall beobachten. Zum Beispiel habe ich jetzt eine der Aufgaben: Wenn Dateien in einem bestimmten Format auf einer Festplatte angezeigt werden, müssen Sie sie auf Kafka hochladen. Ich kann diesen WatchDog oder Lambda verwenden. Logischerweise sind beide geeignet, aber Serverless ist schwieriger zu implementieren, und ich bevorzuge den einfacheren Weg ohne Lambda.
Ara : Serverless - eine interessante, anwendbare, sehr technisch schöne Idee. Früher oder später wird die Technologie den Punkt erreichen, an dem jede Funktion in weniger als 100 Millisekunden ansteigt. Dann steht im Prinzip außer Frage, ob die Wartezeit für den Benutzer kritisch ist. Gleichzeitig hängt die Anwendbarkeit von Serverless, wie Kollegen bereits gesagt haben, vollständig von der Geschäftsaufgabe ab.
Wir danken unseren Sponsoren, die uns sehr geholfen haben:
- Der Raum der IT-Konferenzen " Frühling " hinter der Plattform für die Konferenz.
- Kalender der IT-Veranstaltungen Runet-ID und die Publikation " Internet in Zahlen " für Informationsunterstützung und Neuigkeiten.
- Akronis für Geschenke.
- Avito für die Mitgestaltung.
- "Association of Electronic Communications" RAEC für Engagement und Erfahrung.
- Der Hauptsponsor von RUVDS - für alles!
