
Hallo habr Ich leite die Entwicklung der
Vision- Plattform - dies ist unsere öffentliche Plattform, die Zugriff auf Computer-Vision-Modelle bietet und es Ihnen ermöglicht, Aufgaben wie das Erkennen von Gesichtern, Zahlen, Objekten und ganzen Szenen zu lösen. Und heute möchte ich am Beispiel von Vision erläutern, wie ein schneller, hoch geladener Dienst mithilfe von Grafikkarten implementiert und bereitgestellt und betrieben werden kann.
Was ist Vision?
Dies ist im Wesentlichen eine REST-API. Der Benutzer generiert eine HTTP-Anfrage mit einem Foto und sendet es an den Server.
Angenommen, Sie müssen ein Gesicht in einem Bild erkennen. Das System findet es, schneidet es, extrahiert einige Eigenschaften aus dem Gesicht, speichert es in der Datenbank und weist eine bedingte Nummer zu. Zum Beispiel person42. Der Benutzer lädt dann das nächste Foto hoch, das dieselbe Person hat. Das System extrahiert Eigenschaften aus seinem Gesicht, durchsucht die Datenbank und gibt die bedingte Nummer zurück, die der Person ursprünglich zugewiesen wurde, d. H. person42.
Heute sind die Hauptnutzer von Vision verschiedene Projekte der Mail.ru Group. Die meisten Anfragen kommen von Mail und Cloud.
In der Cloud haben Benutzer Ordner, in die Fotos hochgeladen werden. Die Cloud führt Dateien über Vision aus und gruppiert sie in Kategorien. Danach kann der Benutzer bequem durch seine Fotos blättern. Wenn Sie beispielsweise Freunden oder Familienmitgliedern Fotos zeigen möchten, können Sie schnell die Fotos finden, die Sie benötigen.
Sowohl Mail als auch Cloud sind sehr große Dienste mit Millionen von Menschen, sodass Vision Hunderttausende von Anfragen pro Minute verarbeitet. Das heißt, es ist ein klassischer hoch geladener Dienst, aber mit einer Wendung: Er verfügt über Nginx, einen Webserver, eine Datenbank und Warteschlangen, aber auf der untersten Ebene dieses Dienstes befindet sich die Inferenz - das Ausführen von Bildern über neuronale Netze. Es ist der Lauf neuronaler Netze, der die meiste Zeit in Anspruch nimmt und Ressourcen benötigt. Computernetzwerke bestehen aus einer Folge von Matrixoperationen, die auf der CPU normalerweise lange dauern, auf der GPU jedoch perfekt parallelisiert sind. Um Netzwerke effektiv zu betreiben, verwenden wir einen Cluster von Servern mit Grafikkarten.
In diesem Artikel möchte ich eine Reihe von Tipps veröffentlichen, die beim Erstellen eines solchen Dienstes hilfreich sein können.
Service-Entwicklung
Bearbeitungszeit für eine Anfrage
Für ein System mit hoher Last sind die Verarbeitungszeit einer Anforderung und der Durchsatz des Systems wichtig. Eine hohe Geschwindigkeit der Abfrageverarbeitung wird vor allem durch die richtige Auswahl der neuronalen Netzwerkarchitektur erreicht. In ML können wie in jeder anderen Programmieraufgabe dieselben Aufgaben auf unterschiedliche Weise gelöst werden. Nehmen wir die Gesichtserkennung: Um dieses Problem zu lösen, haben wir zuerst neuronale Netze mit R-FCN-Architektur verwendet. Sie zeigen eine ziemlich hohe Qualität, dauerten jedoch etwa 40 ms bei einem Bild, was nicht zu uns passte. Dann wandten wir uns der MTCNN-Architektur zu und erzielten eine zweifache Geschwindigkeitssteigerung bei leichtem Qualitätsverlust.
Manchmal kann es zur Optimierung der Rechenzeit neuronaler Netze vorteilhaft sein, Inferenz in einem anderen Rahmen zu implementieren, nicht in dem, der gelehrt wurde. Manchmal ist es beispielsweise sinnvoll, Ihr Modell auf NVIDIA TensorRT umzustellen. Es wendet eine Reihe von Optimierungen an und eignet sich besonders für recht komplexe Modelle. Zum Beispiel kann es einige Ebenen irgendwie neu anordnen, zusammenführen und sogar wegwerfen. Das Ergebnis ändert sich nicht und die Geschwindigkeit der Inferenzberechnung erhöht sich. Mit TensorRT können Sie den Speicher auch besser verwalten und nach einigen Tricks auf die Berechnung von Zahlen mit geringerer Genauigkeit reduzieren, wodurch sich auch die Geschwindigkeit der Inferenzberechnung erhöht.
Grafikkarte herunterladen
Die Netzwerkinferenz wird auf der GPU ausgeführt. Die Grafikkarte ist der teuerste Teil des Servers. Daher ist es wichtig, sie so effizient wie möglich zu nutzen. Wie können wir verstehen, haben wir die GPU vollständig geladen oder können wir die Last erhöhen? Diese Frage kann beispielsweise mit dem Parameter GPU Utilization im Dienstprogramm nvidia-smi aus dem Standardvideotreiberpaket beantwortet werden. Diese Abbildung zeigt natürlich nicht, wie viele CUDA-Kerne direkt auf die Grafikkarte geladen sind, sondern wie viele sich im Leerlauf befinden, aber Sie können das Laden der GPU irgendwie bewerten. Aus Erfahrung können wir sagen, dass eine Beladung von 80-90% gut ist. Wenn es zu 10-20% geladen ist, ist dies schlecht und es besteht immer noch Potenzial.
Eine wichtige Konsequenz dieser Beobachtung: Sie müssen versuchen, das System so zu organisieren, dass das Laden von Grafikkarten maximiert wird. Wenn Sie 10 Grafikkarten haben, von denen jede zu 10 bis 20% geladen ist, können höchstwahrscheinlich zwei Grafikkarten mit hoher Last das gleiche Problem lösen.
Systemdurchsatz
Wenn Sie ein Bild an den Eingang eines neuronalen Netzwerks senden, wird die Bildverarbeitung auf eine Vielzahl von Matrixoperationen reduziert. Die Grafikkarte ist ein Mehrkernsystem, und die Eingabebilder, die wir normalerweise einreichen, sind klein. Angenommen, unsere Grafikkarte enthält 1.000 Kerne, und das Bild enthält 250 x 250 Pixel. Alleine können sie aufgrund ihrer bescheidenen Größe nicht alle Kerne laden. Und wenn wir solche Bilder einzeln an das Modell senden, wird das Laden der Grafikkarte 25% nicht überschreiten.
Daher müssen Sie mehrere Bilder hochladen, um daraus zu schließen, und daraus einen Stapel bilden.
In diesem Fall steigt die Grafikkartenlast auf 95%, und die Berechnung der Inferenz dauert wie bei einem einzelnen Bild.
Aber was ist, wenn sich keine 10 Bilder in der Warteschlange befinden, damit wir sie zu einem Stapel kombinieren können? Sie können beispielsweise 50-100 ms warten, in der Hoffnung, dass Anfragen kommen. Diese Strategie wird als Fix-Latenz-Strategie bezeichnet. Sie können Anforderungen von Clients in einem internen Puffer kombinieren. Infolgedessen erhöhen wir unsere Verzögerung um einen festen Betrag, erhöhen jedoch den Systemdurchsatz erheblich.
Inferenz starten
Wir trainieren Modelle mit Bildern eines festen Formats und einer festen Größe (z. B. 200 x 200 Pixel), aber der Dienst muss die Möglichkeit unterstützen, verschiedene Bilder hochzuladen. Daher müssen Sie alle Bilder vor dem Senden an die Inferenz ordnungsgemäß vorbereiten (Größe ändern, zentrieren, normalisieren, in Float übersetzen usw.). Wenn alle diese Operationen in einem Prozess ausgeführt werden, der die Inferenz startet, sieht der Arbeitszyklus ungefähr so aus:
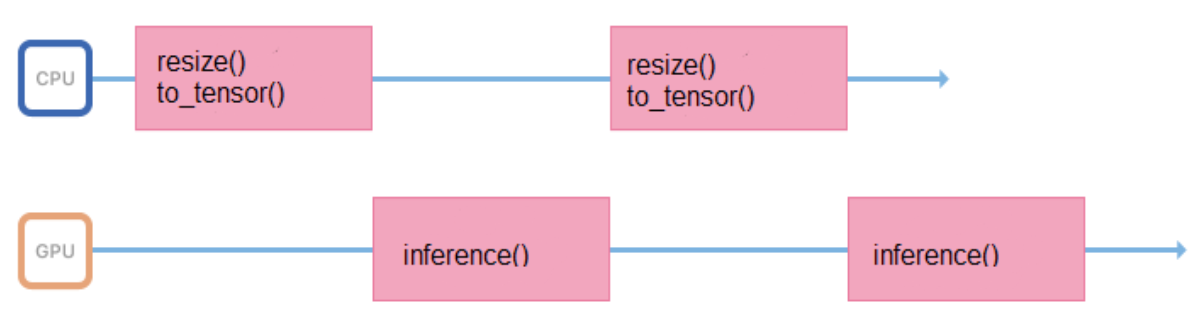
Er verbringt einige Zeit im Prozessor, bereitet die Eingabedaten vor und wartet einige Zeit auf eine Antwort von der GPU. Es ist besser, die Intervalle zwischen den Schlussfolgerungen zu minimieren, damit die GPU weniger inaktiv ist.
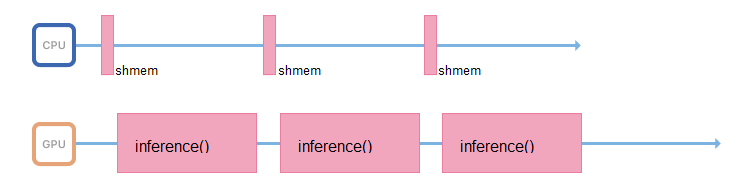
Zu diesem Zweck können Sie einen anderen Stream starten oder die Vorbereitung von Bildern auf andere Server übertragen, ohne Grafikkarten, aber mit leistungsstarken Prozessoren.
Wenn möglich, sollte sich der für die Inferenz verantwortliche Prozess nur damit befassen: Zugriff auf den gemeinsam genutzten Speicher, Sammeln der Eingabedaten, sofortiges Kopieren in den Speicher der Grafikkarte und Ausführen der Inferenz.
Turbo-Boost
Das Starten neuronaler Netze ist eine Operation, die nicht nur Ressourcen der GPU, sondern auch des Prozessors verbraucht. Selbst wenn alles in Bezug auf die Bandbreite korrekt organisiert ist und der Thread, der die Inferenz durchführt, bereits auf neue Daten wartet, haben Sie auf einem schwachen Prozessor einfach keine Zeit, diesen Stream mit neuen Daten zu sättigen.
Viele Prozessoren unterstützen die Turbo Boost-Technologie. Sie können die Frequenz des Prozessors erhöhen, dies ist jedoch nicht immer standardmäßig aktiviert. Es lohnt sich, es sich anzusehen. Zu diesem
$ cpupower frequency-info -m verfügt Linux über das Dienstprogramm CPU Power:
$ cpupower frequency-info -m .
Die Prozessoren verfügen auch über einen Stromverbrauchsmodus, der von einem solchen CPU Power:
performance Befehl erkannt werden kann.
Im Powersave-Modus kann der Prozessor seine Frequenz drosseln und langsamer laufen. Sie sollten in das BIOS gehen und den Leistungsmodus auswählen. Dann arbeitet der Prozessor immer mit maximaler Frequenz.
Anwendungsbereitstellung
Docker eignet sich hervorragend für die Bereitstellung der Anwendung. Sie können Anwendungen auf der GPU im Container ausführen. Um auf die Grafikkarten zuzugreifen, müssen Sie zuerst die Treiber für die Grafikkarte auf dem Hostsystem installieren - einem physischen Server. Um den Container zu starten, müssen Sie viel Handarbeit leisten: Werfen Sie die Grafikkarten mit den richtigen Parametern korrekt in den Container. Nach dem Starten des Containers müssen weiterhin Videotreiber installiert werden. Und erst danach können Sie Ihre Anwendung verwenden.

Dieser Ansatz hat eine Einschränkung. Server können aus dem Cluster verschwinden und hinzugefügt werden. Es ist möglich, dass verschiedene Server unterschiedliche Treiberversionen haben und sich von der im Container installierten Version unterscheiden. In diesem Fall wird ein einfacher Docker unterbrochen: Die Anwendung erhält beim Versuch, auf die Grafikkarte zuzugreifen, einen Fehler bei der Nichtübereinstimmung der Treiberversion.

Wie gehe ich damit um? Es gibt eine Version von Docker von NVIDIA, mit der die Verwendung des Containers einfacher und angenehmer wird. Laut NVIDIA selbst und nach praktischen Beobachtungen beträgt der Aufwand für die Verwendung von nvidia-docker etwa 1%.
In diesem Fall müssen die Treiber nur auf dem Hostcomputer installiert werden. Wenn Sie den Container starten, müssen Sie nichts hineinwerfen, und die Anwendung hat sofort Zugriff auf die Grafikkarten.

Die "Unabhängigkeit" von nvidia-docker von Treibern ermöglicht es Ihnen, einen Container mit demselben Image auf verschiedenen Computern auszuführen, auf denen verschiedene Versionen von Treibern installiert sind. Wie wird das umgesetzt? Docker hat ein Konzept namens Docker-Runtime: Es handelt sich um eine Reihe von Standards, die beschreiben, wie ein Container mit dem Host-Kernel kommunizieren soll, wie er gestartet und gestoppt werden soll, wie mit dem Kernel und dem Treiber interagiert werden soll. Ab einer bestimmten Version von Docker kann diese Laufzeit ersetzt werden. Dies hat NVIDIA getan: Sie ersetzen die Laufzeit, fangen die Anrufe an den darin enthaltenen Videotreiber ab und konvertieren die richtige Version in die Anrufe an den Videotreiber.
Orchestrierung
Wir haben Kubernetes als Orchester gewählt. Es unterstützt viele sehr schöne Funktionen, die für jedes stark ausgelastete System nützlich sind. Durch die automatische Erkennung können Dienste beispielsweise innerhalb eines Clusters ohne komplexe Routing-Regeln aufeinander zugreifen. Oder Fehlertoleranz - Wenn Kubernetes immer mehrere Container bereit hält und Ihnen etwas passiert ist, startet Kubernetes sofort einen neuen Container.
Wenn Sie bereits einen Kubernetes-Cluster konfiguriert haben, benötigen Sie nicht so viel, um Grafikkarten im Cluster zu verwenden:
- relativ frische Fahrer
- installierte nvidia-docker version 2
- Docker-Laufzeit standardmäßig auf "nvidia" in /etc/docker/daemon.json festgelegt:
"default-runtime": "nvidia"
- Installiertes Plugin
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
Nachdem Sie Ihren Cluster konfiguriert und das Geräte-Plugin installiert haben, können Sie eine Grafikkarte als Ressource angeben.
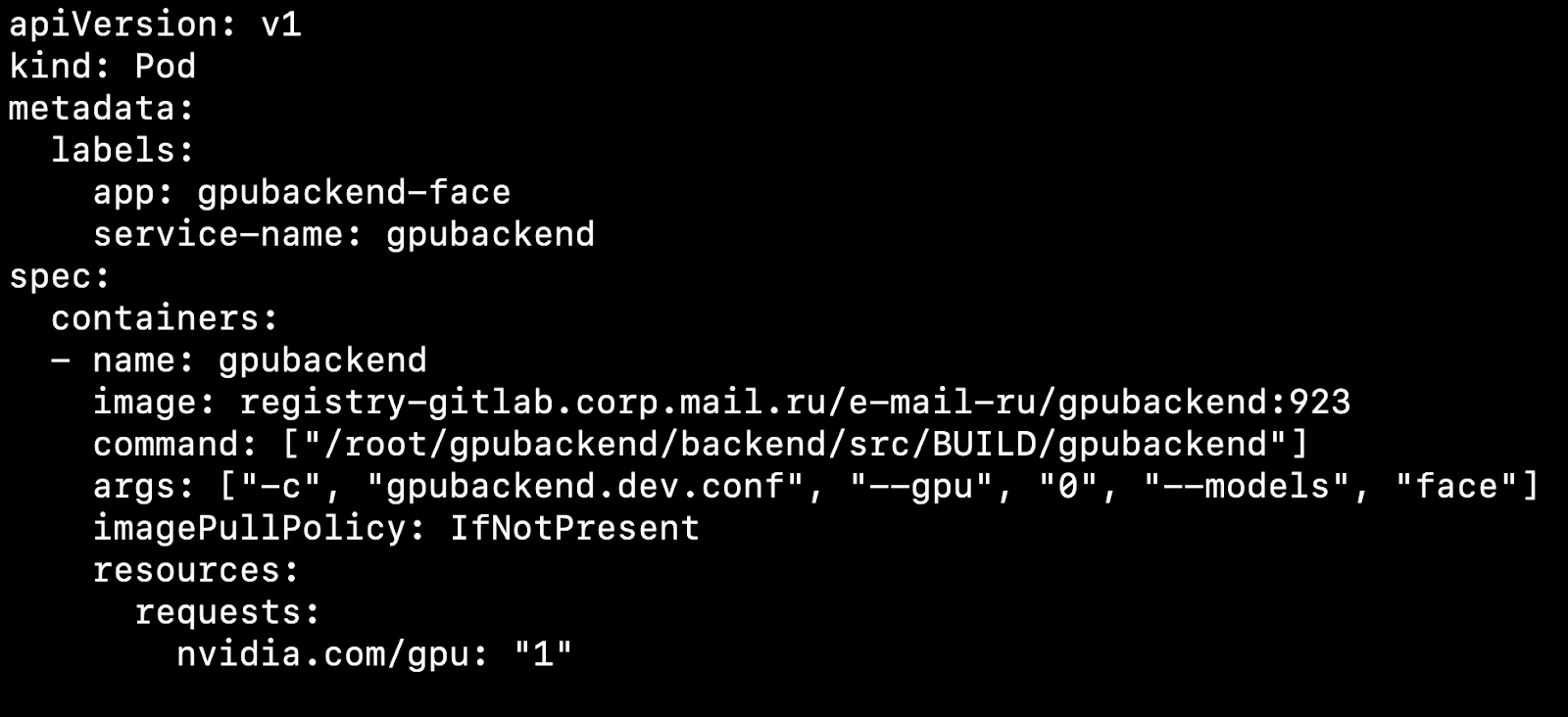
Was betrifft das? Nehmen wir an, wir haben zwei Knoten, physische Maschinen. Auf der einen befindet sich eine Grafikkarte, auf der anderen nicht. Kubernetes erkennt eine Maschine mit einer Grafikkarte und nimmt unseren Pod darauf auf.
Es ist wichtig zu beachten, dass Kubernetes nicht weiß, wie man eine Grafikkarte kompetent zwischen Pods fummelt. Wenn Sie 4 Grafikkarten haben und 1 GPU zum Starten des Containers benötigen, können Sie nicht mehr als 4 Pods in Ihrem Cluster erstellen.
Wir nehmen in der Regel 1 Pod = 1 Modell = 1 GPU.
Es gibt eine Option, um mehr Instanzen auf 4 Grafikkarten auszuführen, aber wir werden dies in diesem Artikel nicht berücksichtigen, da diese Option nicht sofort verfügbar ist.
Wenn sich mehrere Modelle gleichzeitig drehen sollen, ist es praktisch, für jedes Modell eine Bereitstellung in Kubernetes zu erstellen. In der Konfigurationsdatei können Sie die Anzahl der Herde für jedes Modell angeben, wobei die Beliebtheit des Modells berücksichtigt wird. Wenn viele Anfragen an das Modell kommen, müssen Sie viele Pods dafür angeben. Wenn es nur wenige Anfragen gibt, gibt es nur wenige Pods. Insgesamt sollte die Anzahl der Herde der Anzahl der Grafikkarten im Cluster entsprechen.
Betrachten Sie einen interessanten Punkt. Nehmen wir an, wir haben 4 Grafikkarten und 3 Modelle.
Lassen Sie auf den ersten beiden Grafikkarten die Schlussfolgerung des Gesichtserkennungsmodells steigen, bei einer weiteren Erkennung von Objekten und bei einer weiteren Erkennung von Fahrzeugnummern.
Sie arbeiten, Kunden kommen und gehen, und einmal, zum Beispiel nachts, tritt eine Situation auf, in der eine Grafikkarte mit Inferenzobjekten einfach nicht geladen wird, eine kleine Anzahl von Anforderungen eingeht und Grafikkarten mit Gesichtserkennung überlastet werden. Ich möchte in diesem Moment ein Modell mit Objekten löschen und an seiner Stelle Gesichter starten, um die Linien zu entladen.
Für die automatische Skalierung von Modellen auf Grafikkarten gibt es in Kubernetes Tools - die automatische Skalierung des horizontalen Herds (HPA, horizontaler Pod-Autoscaler).
Kubernetes unterstützt standardmäßig die automatische Skalierung der CPU-Auslastung. Bei einer Aufgabe mit Grafikkarten ist es jedoch viel sinnvoller, Informationen über die Anzahl der Aufgaben für jedes Modell zur Skalierung zu verwenden.
Wir tun dies: Stellen Sie Anforderungen für jedes Modell in eine Warteschlange. Wenn die Anforderungen abgeschlossen sind, entfernen wir sie aus dieser Warteschlange. Wenn es uns gelingt, Anfragen nach gängigen Modellen schnell zu verarbeiten, wächst die Warteschlange nicht. Wenn die Anzahl der Anforderungen für ein bestimmtes Modell plötzlich zunimmt, wächst die Warteschlange. Es wird klar, dass Sie Grafikkarten hinzufügen müssen, die beim Harken der Linie helfen.
Informationen zu den Warteschlangen, die wir über Prometheus über die HPA vertreten:
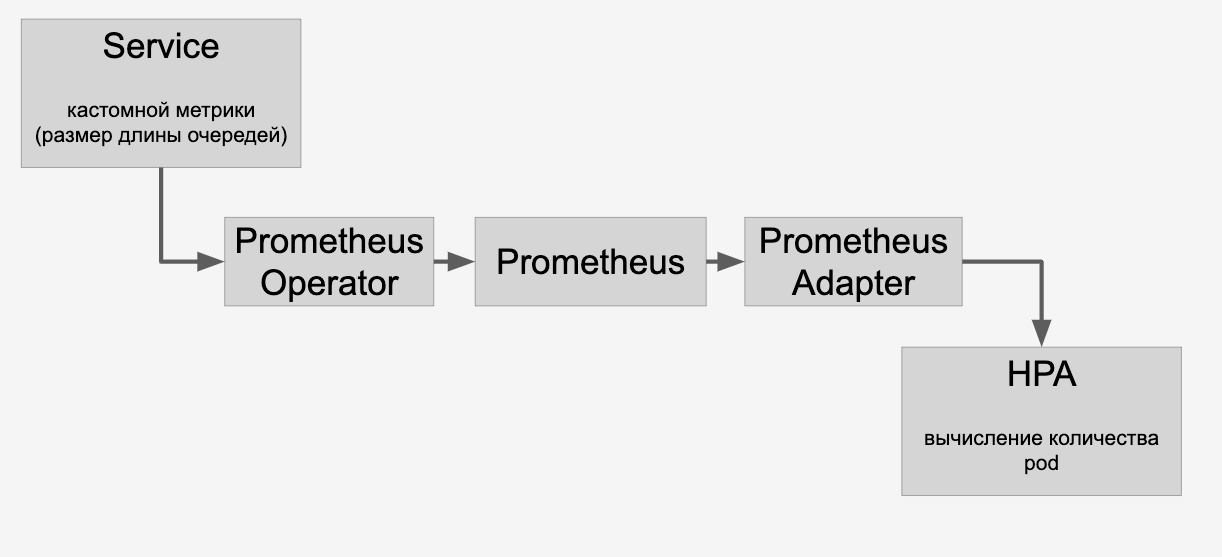
Und dann skalieren wir die Modelle auf den Grafikkarten im Cluster automatisch, abhängig von der Anzahl der Anfragen an sie.
CI / CD
Nachdem Sie die Anwendung beigefügt und in Kubernetes verpackt haben, haben Sie buchstäblich noch einen Schritt bis zum Anfang des Projekts. Sie können CI / CD hinzufügen. Hier ist ein Beispiel aus unserer Pipeline:
Hier startete der Programmierer den neuen Code in den Hauptzweig, wonach das Docker-Image mit unseren Backend-Daemons automatisch erfasst und die Tests ausgeführt werden. Wenn alle Häkchen grün sind, wird die Anwendung in die Testumgebung gegossen. Wenn es keine Probleme gibt, können Sie das Bild problemlos in Betrieb nehmen.
Fazit
In meinem Artikel habe ich einige Aspekte der Arbeit eines hoch ausgelasteten Dienstes mit einer GPU angesprochen. Wir haben über Möglichkeiten gesprochen, die Reaktionszeit eines Dienstes zu verkürzen, wie zum Beispiel:
- Auswahl der optimalen neuronalen Netzwerkarchitektur zur Reduzierung der Latenz;
- Anwendungen zur Optimierung von Frameworks wie TensorRT.
Wir haben die Probleme der Steigerung des Durchsatzes angesprochen:
- die Verwendung von Bildstapeln;
- Anwenden einer Strategie mit fester Latenz, so dass die Anzahl der Inferenzläufe verringert wird, aber jede Inferenz eine größere Anzahl von Bildern verarbeiten würde;
- Optimierung der Dateneingabepipeline zur Minimierung von GPU-Ausfallzeiten;
- "Kampf" mit Prozessor-Trab, Entfernung von CPU-gebundenen Operationen auf andere Server.
Wir haben uns den Prozess der Bereitstellung einer Anwendung mit einer GPU angesehen:
- Verwenden von nvidia-docker in Kubernetes
- Skalierung basierend auf der Anzahl der Anforderungen und HPA (horizontaler Pod-Autoscaler).