In dem Artikel wird die Klassifizierung der Tonalität von Textnachrichten in russischer Sprache (und im Wesentlichen jede Klassifizierung von Texten mit derselben Technologie) erörtert. Wir werden
diesen Artikel als Grundlage nehmen, in dem die Klassifizierung der Tonalität in der CNN-Architektur unter Verwendung des Word2vec-Modells berücksichtigt wurde. In unserem Beispiel lösen wir das gleiche Problem der Trennung von Tweets in positive und negative
Daten im selben Datensatz mithilfe des
ULMFit- Modells. Das Ergebnis des Artikels (durchschnittlicher F1-Score = 0,78142) wird als Basis akzeptiert.
Einleitung
Das ULMFIT-Modell wurde 2018 von den Entwicklern von fast.ai (Jeremy Howard, Sebastian Ruder) eingeführt. Der Kern des Ansatzes besteht darin, Transferlernen in NLP-Aufgaben zu verwenden, wenn Sie vorab trainierte Modelle verwenden, die Zeit für das Training Ihrer Modelle zu verkürzen und die Anforderungen an die Größe der gekennzeichneten Testprobe zu reduzieren.
Das Trainingsschema in unserem Fall sieht folgendermaßen aus:

Die Bedeutung des Sprachmodells besteht darin, das nächste Wort nacheinander vorhersagen zu können. Es ist problematisch, lange verbundene Texte auf diese Weise zu erhalten, aber dennoch können Sprachmodelle die Eigenschaften der Sprache erfassen, den Kontext der Verwendung von Wörtern verstehen, daher ist das Sprachmodell (und nicht beispielsweise die Vektoranzeige von Wörtern) die Grundlage der Technologie. Für die Modellierung der Sprache verwendet ULMFit die
AWD-LSTM- Architektur, bei der Dropout nach Möglichkeit aktiv verwendet wird und sinnvoll ist. Die Art des Sprachmodelltrainings wird manchmal als halbüberwachtes Lernen bezeichnet, da das Etikett hier das nächste Wort ist und Sie nichts mit Ihren Händen markieren müssen.
Als vorab trainiertes Sprachmodell werden wir fast das einzige öffentlich
verfügbare verwenden .
Lassen Sie uns den Lernalgorithmus von Anfang an durchgehen.
Wir laden Bibliotheken (wir überprüfen die Version von Fast.ai bei Inkompatibilitäten):
%load_ext autoreload %autoreload 2 import pandas as pd import numpy as np import re import statistics import fastai print('fast.ai version is:', fastai.__version__) from fastai import * from fastai.text import * from sklearn.model_selection import train_test_split path = ''
Out: fast.ai version is: 1.0.58
Wir bereiten Daten für das Training vor
In Analogie werden wir Schulungen zu den
Kurztexten RuTweetCorp von Yulia Rubtsova durchführen , die auf der Grundlage russischsprachiger Nachrichten von Twitter erstellt wurden. Der Körper enthält 114.991 positive Tweets und 111.923 negative Tweets im CSV-Format. Darüber hinaus gibt es eine Datenbank mit nicht zugewiesenen Tweets mit einem Volumen von 17 639 674 Datensätzen im SQL-Format. Die Aufgabe unseres Klassifikators besteht darin, festzustellen, ob der Tweet positiv oder negativ ist.
Da
es lange gedauert hat, das Sprachmodell für 17 Millionen Tweets neu zu trainieren,
und die Aufgabe darin bestand, die Faulheit beim Transferlernen zu zeigen, werden wir das Sprachmodell für einen Text aus dem Trainingsdatensatz neu trainieren, wobei die Basis nicht zugeordneter Tweets vollständig ignoriert wird. Wenn Sie diese Basis zum „Schärfen“ des Sprachmodells verwenden, können Sie wahrscheinlich das Gesamtergebnis verbessern.
Wir bilden Datensätze für Training und Test mit vorläufiger Textverarbeitung. Wir nehmen den Code aus dem
Originalartikel :
def preprocess_text(text): text = text.lower().replace("", "") text = re.sub('((www\.[^\s]+)|(https?://[^\s]+))', 'URL', text) text = re.sub('@[^\s]+', 'USER', text) text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() data = [preprocess_text(t) for t in raw_data]
df_train=pd.DataFrame(columns=['Text', 'Label']) df_test=pd.DataFrame(columns=['Text', 'Label']) df_train['Text'], df_test['Text'], df_train['Label'], df_test['Label'] = train_test_split(data, labels, test_size=0.2, random_state=1)
df_val=pd.DataFrame(columns=['Text', 'Label']) df_train, df_val = train_test_split(df_train, test_size=0.2, random_state=1)
Wir schauen uns an, was passiert ist:
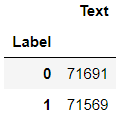
df_train.groupby('Label').count()
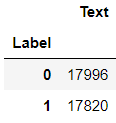
df_val.groupby('Label').count()
df_test.groupby('Label').count()

Ein Sprachmodell lernen
Daten laden:
tokenizer=Tokenizer(lang='xx') data_lm = TextLMDataBunch.from_df(path, tokenizer=tokenizer, bs=16, train_df=df_train, valid_df=df_val, text_cols=0)
Wir schauen uns den Inhalt an:
data_lm.show_batch()

Wir bieten Links zu den gespeicherten Gewichten des
vorgefertigten Modells und ein Wörterbuch:
weights_pretrained = 'ULMFit/lm_5_ep_lr2-3_5_stlr' itos_pretrained = 'ULMFit/itos' pretained_data = (weights_pretrained, itos_pretrained)
Wir schaffen Lernende, aber vorher - eine Krücke für fast.ai. Das vorab trainierte Modell wurde auf einer älteren Version der Bibliothek trainiert, daher müssen Sie die Anzahl der Knoten in der verborgenen Schicht des neuronalen Netzwerks anpassen.
config = awd_lstm_lm_config.copy() config['n_hid'] = 1150 learn_lm = language_model_learner(data_lm, AWD_LSTM, config=config, pretrained_fnames=pretained_data, drop_mult=0.3) learn_lm.freeze()
Wir suchen die optimale Lernrate:
learn_lm.lr_find() learn_lm.recorder.plot()

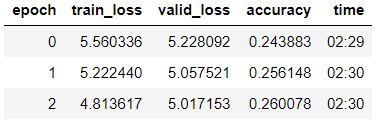
Wir trainieren das Modell der 3. Ära (im Modell ist nur die letzte Gruppe von Schichten nicht gefroren).
learn_lm.fit_one_cycle(3, 1e-2, moms=(0.8, 0.7))
Auftauen des Modells, Unterrichten von 5 weiteren Epochen mit einer niedrigeren Lernrate:
learn_lm.unfreeze() learn_lm.fit_one_cycle(5, 1e-3, moms=(0.8, 0.7))

learn_lm.save('lm_ft')
Wir versuchen, Text auf einem trainierten Modell zu generieren.
learn_lm.predict(" ", n_words=5)
Out: ' '
learn_lm.predict(", ", n_words=4)
Out: ', '
Wir sehen - etwas, was das Modell tut. Unsere Hauptaufgabe ist jedoch die Klassifizierung, und für ihre Lösung werden wir einen Encoder aus dem Modell nehmen.
learn_lm.save_encoder('ft_enc')
Wir trainieren den Klassifikator
Laden Sie Daten für das Training herunter
data_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_val, text_cols=0, label_cols=1, tokenizer=tokenizer)
Schauen wir uns die Daten an, wir sehen, dass die Labels erfolgreich gezählt wurden (0 bedeutet negativ und 1 bedeutet einen positiven Kommentar):
data_clas.show_batch()

Erstellen Sie einen Lernenden mit einer ähnlichen Krücke:
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn = text_classifier_learner(data_clas, AWD_LSTM, config=config, drop_mult=0.5)
Wir laden den in der vorherigen Phase trainierten Encoder und frieren das Modell mit Ausnahme der letzten Gewichtsgruppe ein:
learn.load_encoder('ft_enc') learn.freeze()
Wir suchen die optimale Lernrate:
learn.lr_find() learn.recorder.plot(skip_start=0)

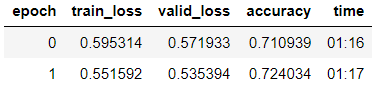
Wir trainieren das Modell mit dem allmählichen Auftauen von Schichten.
learn.fit_one_cycle(2, 2e-2, moms=(0.8,0.7))
learn.freeze_to(-2) learn.fit_one_cycle(3, slice(1e-2/(2.6**4),1e-2), moms=(0.8,0.7))

learn.freeze_to(-3) learn.fit_one_cycle(2, slice(5e-3/(2.6**4),5e-3), moms=(0.8,0.7))

learn.unfreeze() learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3), moms=(0.8,0.7))

learn.save('tweet-0801')
Wir sehen, dass sie an der Validierungsprobe eine Genauigkeit von 80,1% erreichten.
Wir werden das Modell anhand des
ZlodeiBaal- Kommentars zu meinem vorherigen Artikel
testen :
learn.predict(' — ?')
Out: (Category 0, tensor(0), tensor([0.6283, 0.3717]))
Wir sehen, dass das Modell diesen Kommentar negativ zugeschrieben hat :-)
Überprüfen des Modells an einem Testmuster
Die Hauptaufgabe in dieser Phase besteht darin, das Modell auf seine Generalisierungsfähigkeit zu testen. Dazu validieren wir das Modell für den im DataFrame df_test gespeicherten Datensatz, der bis dahin weder für das Sprachmodell noch für den Klassifikator verfügbar war.
data_test_clas = TextClasDataBunch.from_df(path, vocab=data_lm.train_ds.vocab, bs=32, train_df=df_train, valid_df=df_test, text_cols=0, label_cols=1, tokenizer=tokenizer)
config = awd_lstm_clas_config.copy() config['n_hid'] = 1150 learn_test = text_classifier_learner(data_test_clas, AWD_LSTM, config=config, drop_mult=0.5)
learn_test.load_encoder('ft_enc') learn_test.load('tweet-0801')
learn_test.validate()
Out: [0.4391682, tensor(0.7973)]
Wir sehen, dass die Genauigkeit der Testprobe 79,7% betrug.
Schauen Sie sich Confusion Matrix an:
interp = ClassificationInterpretation.from_learner(learn) interp.plot_confusion_matrix()
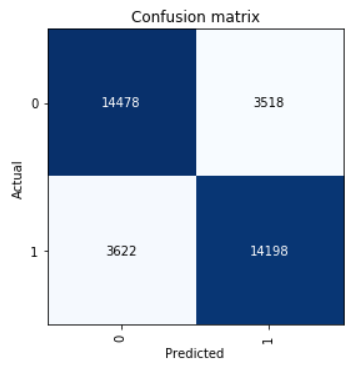
Wir berechnen die Parameter für Genauigkeit, Rückruf und f1-Punktzahl.
neg_precision = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[1][0]) neg_recall = interp.confusion_matrix()[0][0] / (interp.confusion_matrix()[0][0] + interp.confusion_matrix()[0][1]) pos_precision = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[0][1]) pos_recall = interp.confusion_matrix()[1][1] / (interp.confusion_matrix()[1][1] + interp.confusion_matrix()[1][0]) neg_f1score = 2 * (neg_precision * neg_recall) / (neg_precision + neg_recall) pos_f1score = 2 * (pos_precision * pos_recall) / (pos_precision + pos_recall)
print(' F1-score') print(' Negative {0:1.5f} {1:1.5f} {2:1.5f}'.format(neg_precision, neg_recall, neg_f1score)) print(' Positive {0:1.5f} {1:1.5f} {2:1.5f}'.format(pos_precision, pos_recall, pos_f1score)) print(' Average {0:1.5f} {1:1.5f} {2:1.5f}'.format(statistics.mean([neg_precision, pos_precision]), statistics.mean([neg_recall, pos_recall]), statistics.mean([neg_f1score, pos_f1score])))
Out: F1-score Negative 0.79989 0.80451 0.80219 Positive 0.80142 0.79675 0.79908 Average 0.80066 0.80063 0.80064
Das in der Testprobe gezeigte Ergebnis ist ein durchschnittlicher F1-Score = 0,80064.
Gespeicherte Modellgewichte können hier genommen
werden .