Hallo! Mein Name ist Evgeny Kashin und ich arbeite im Yandex Machine Intelligence Labor. Wir haben kürzlich ein Spiel gestartet, in dem Benutzer mit Alice konkurrieren, um Länder anhand von Fotos zu erraten.
Wie Menschen handeln, ist verständlich: Sie erkennen Orte, die sie auf Reisen oder in Filmen gesehen haben, verlassen sich auf Gelehrsamkeit und gesunden Menschenverstand. Das neuronale Netzwerk hat nichts davon. Wir fragten uns, welche Details auf den Bildern ihr die Antwort gaben. Wir haben eine Studie durchgeführt, deren Ergebnisse wir heute mit Habr teilen werden.
Dieser Beitrag wird sowohl für Spezialisten auf dem Gebiet der Bildverarbeitung als auch für alle interessant sein, die in die "künstliche Intelligenz" schauen und die Logik ihrer Arbeit verstehen möchten.

Ein paar Worte zum Spiel "
Errate das Land anhand eines Fotos ." Kurz gesagt, wir haben Fotos von Yandex.Maps gemacht und sie in zwei Gruppen unterteilt. Die erste Gruppe wurde von neuronalen Netzen gezeigt und sagte, wo jeder Schuss gemacht wurde. Nach Durchsicht von Tausenden von Fotos entwickelte das neuronale Netzwerk eine Idee für jedes Land - das heißt, es identifizierte unabhängig Kombinationen von Zeichen, an denen es erkannt werden kann. Wir verwenden die zweite Gruppe von Bildern im Spiel, Alice hat sie nicht gesehen und erinnert sich während des Spiels nicht an sie. Alice spielt gut, aber die Leute haben einen Vorteil: Wir haben das neuronale Netz nicht trainiert, um Kennzeichen, Texte von Zeichen und Zeichen, Flaggen von Staaten zu erkennen.
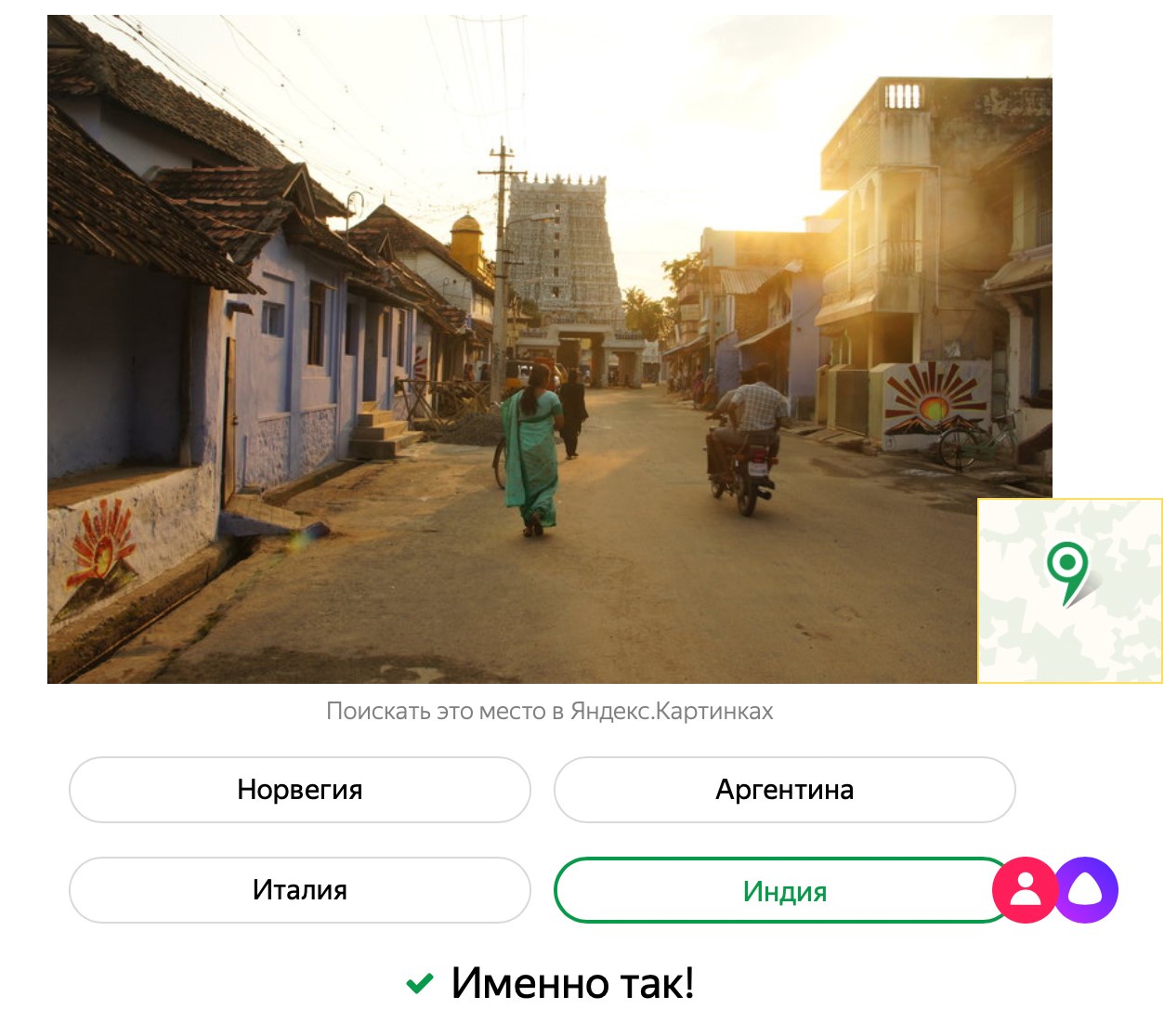
Für das Spiel haben wir das Modell trainiert, um das Land anhand eines Fotos vorherzusagen. Wir haben ein Modell der Computer Vision
SE-ResNeXt-101 genommen ,
das für viele Aufgaben vorab
geschult wurde . Die Zeichen, die aus dem Bild unter Verwendung dieses Faltungs-Neuronalen Netzes erhalten werden, sind ziemlich universell, so dass für den Länderklassifikator nur einige zusätzliche Schichten (der sogenannte Kopf) hinzugefügt werden mussten. Für das Training wurden Yandex.Mart-Daten verwendet: ungefähr 2,5 Millionen Fotos. Viele Bilder passten nicht nach dem Kriterium der Schönheit zum Spiel und wurden gefiltert. Schönheit wird als eine Kombination von Faktoren verstanden: die Qualität des Fotos, die Anwesenheit von Menschen, Text, Wald, Meer. Ähnliche Bilder wurden von derselben Stelle entfernt, so dass sich das Modell nicht an bestimmte Sehenswürdigkeiten erinnerte. Nach all dem Filtern blieben ungefähr 1 Million Fotos übrig. Nachdem wir das Modell anhand dieser Daten trainiert haben, haben wir einen ziemlich genauen Klassifikator erhalten, der das Land nur anhand eines Fotos bestimmt, ohne zusätzliche Informationen zu verwenden.
Da die Klassifizierung unter Verwendung eines neuronalen Netzwerks durchgeführt wird, können wir im Gegensatz zu einfacheren linearen Modellen oder Entscheidungsbäumen keine einfache Interpretation von Vorhersagen erhalten. Aber wir wollten herausfinden, wie ein neuronales Netzwerk anhand eines regulären Fotos einer Straße oder eines Hauses bestimmt, um welches Land es sich handelt. Und die interessantesten Fälle sind ohne Attraktionen im Rahmen.
Zu diesem Zweck haben wir das neuronale Netzwerk von Grund auf trainiert und nicht ganze Bilder, sondern nur kleine Erntestücke eingezogen (damit sich das Modell nicht an bestimmte Orte oder große Objekte erinnert).
Dadurch ist die Aufgabe für das Modell spürbar schwieriger geworden (versuchen Sie, das Land an einem Stück Himmel zu erraten), die Erkennungsgenauigkeit hat sich stark verringert. Andererseits musste das neuronale Netz mehr auf kleine Details achten: ungewöhnliches Mauerwerk, spezifische Muster, Dachart, Pflanzen. Die Größe des auf das Modell angewendeten Zuschnitts änderte sich, und es wurden verschiedene Modelle erhalten, die das Foto auf verschiedenen Abstraktionsebenen betrachteten: Je kleiner der Zuschnitt, desto schwieriger die Aufgabe und desto aufmerksamer das Modell für Details.

Algorithmen zur Interpretation von Vorhersagen können auf Modelle angewendet werden, die auf Erntegrößen unterschiedlicher Größe trainiert wurden. Ich möchte die Vorhersagen in den Quellfotos interpretieren. Die meisten modernen Faltungsnetzwerke verwenden das
Global Average Pooling (GAP) vor der letzten Schicht. Dies ermöglicht es, das Netzwerk auf einer Größe zu trainieren und auf eine andere anzuwenden. Dies liegt daran, dass vor der letzten Ebene räumliche Merkmale, die in Breite und Höhe verteilt sind, für jeden Kanal (Merkmalskarte) zu einer Zahl gemittelt werden. Daher können auf Zuschneiden trainierte Modelle (z. B. 160 × 160 Pixel) für die großen Originalbilder (800 × 800 Pixel) verwendet werden.
Tatsächlich wird die GAP-Schicht nicht nur zur Verwendung des Modells mit unterschiedlichen Auflösungen oder zur Regularisierung benötigt. Es hilft dem neuronalen Netzwerk auch, Informationen über die Position von Objekten bis zur letzten Schicht zu speichern (genau das, was wir brauchen).
Die erste Methode, die wir ausprobiert haben, ist
Class Activation Mapping (CAM).
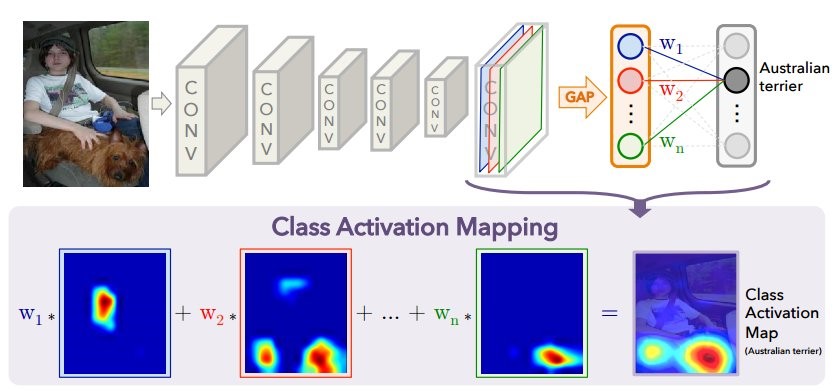
Wenn das Bild dem Eingang des neuronalen Netzwerks zugeführt wird, wird auf der vorletzten Schicht ein reduziertes "Bild" (tatsächlich der Aktivierungstensor) mit den wichtigsten Vorzeichen für jede vorhergesagte Klasse erhalten. Mit der CAM-Methode können Sie die letzten Ebenen so ändern, dass die Ausgabe die Wahrscheinlichkeit jeder Klasse in jeder Region ist. Wenn Sie beispielsweise 60 Klassen (Länder) für ein Eingabebild von 800 × 800 vorhersagen möchten, besteht das endgültige Bild aus 60 Aktivierungskarten mit einer Größe von 25 × 25. Dies ist in der
Originalveröffentlichung gut dargestellt.
Das obige Diagramm zeigt das übliche Modell mit GAP: räumliche Merkmale werden für jeden Kanal auf eine Zahl komprimiert (Merkmalskarte). Danach gibt es eine vollständig verbundene Ebene, die Klassen vorhersagt, die die optimalen Gewichte für jeden Kanal finden. Im Folgenden wird gezeigt, wie Sie die Architektur ändern, um die CAM-Methode zu erhalten: Die GAP-Schicht wird entfernt, und die Gewichte der letzten vollständig verbundenen Schicht, die während des Trainings mit GAP erhalten wurden (siehe Abbildung oben), werden für jeden Kanal an jedem Punkt verwendet. Für jedes Bild werden N Aktivierungskarten für alle vorhergesagten Klassen erhalten. Je heller das Gebiet auf der „Karte“ für jedes Land ist, desto größer ist der Beitrag, den dieser Abschnitt des Bildes zur Entscheidung für ein bestimmtes Land geleistet hat. Was interessant ist: Wenn wir nach dieser Operation jede Aktivierungskarte mitteln (im Wesentlichen GAP anwenden), erhalten wir nur die anfängliche Vorhersage für jede Klasse.

Im Bild sehen Sie eine Aktivierungskarte für die wahrscheinlichste (je nach Modell) Klasse. Es wurde erhalten, indem die Aktivierungskarte 25 × 25 auf die Größe des Originalbildes 800 × 800 gestreckt wurde.
Nachdem wir für jedes Bild eine solche Karte erhalten haben, können wir die wichtigste Ernte für Länder aus verschiedenen Bildern zusammenfassen. Auf diese Weise können Sie die Erntesammlung betrachten und das Land am besten beschreiben.
Die zweite Methode, mit der wir uns entschieden haben, die erste zu vergleichen, ist eine einfache, umfassende Suche. Was ist, wenn wir ein Modell nehmen, das auf kleinen Zuschnitten (z. B. 160 × 160 Pixel) trainiert ist, und jedes Stück damit auf einem großen 800 × 800-Bild vorhersagen? Wenn wir ein Schiebefenster passieren, das jeden Bereich des Bildes überlagert, erhalten wir eine andere Version der Aktivierungskarte, die zeigt, wie wahrscheinlich jedes Stück des Bildes zur Klasse des vorhergesagten Landes gehört.

Das Bild wird in kleine Ausschnitte mit einer Überlappung von 160 × 160 geschnitten. Für jedes Zuschneiden macht das neuronale Netzwerk Vorhersagen. Die Zahl über dem Zuschneiden ist die Wahrscheinlichkeit, zu der Klasse zu gehören, die das Modell schließlich vorhergesagt hat.
Wie bei der ersten Methode können wir wieder die wahrscheinlichsten Stücke für jedes Land auswählen. Die mit beiden Methoden für das Land erhaltenen Bilder können jedoch einheitlich sein (z. B. ein Gebäude aus verschiedenen Winkeln oder eine Version der Textur). Daher wird die beste Ernte für das Land zusätzlich gruppiert - dann werden die meisten ähnlichen Bilder in einem Cluster gesammelt. Danach reicht es aus, mit maximaler Wahrscheinlichkeit ein Bild von jedem Cluster aufzunehmen - für jedes Land werden so viele Bilder angezeigt, wie Cluster angegeben sind. Wir haben Clustering basierend auf den Eigenschaften durchgeführt, die aus der letzten Klassifikatorschicht erhalten wurden. Agglomerative Clusterbildung erwies sich in unserem Fall als die beste.

Nachdem Sie eine ziemlich ähnliche Pipeline für die beiden Methoden erhalten haben, können Sie die Parameter der Algorithmen durchlaufen, um die optimale Kombination zu finden. Zum Beispiel haben wir die Größe des Zuschnitts ausgewählt und uns für zwei Optionen entschieden: 160 und 256 Pixel. Pflanzen unter 160 gaben zu kleine Zeichen, wonach eine Person oft nicht versteht, was abgebildet ist. Und mehr als 256 Pflanzen enthielten manchmal mehrere Objekte gleichzeitig. In der Phase des Clustering müssen verschiedene Parameter ausgewählt werden: die Auswahl des Hauptalgorithmus sowie die Merkmale, mit denen das Clustering durchgeführt wird. Bei vielen Parameterkombinationen war sofort klar, dass sie nicht ausreichend „interessante“ Ernte liefern. Um den endgültigen Algorithmus auszuwählen, haben wir nebeneinander Experimente mit Tolok durchgeführt, um zu verstehen, welche Option laut Angaben der Menschen das jeweilige Land „angemessener“ beschreibt.
Es stellte sich als nicht intuitiv heraus, dass eine einfachere Methode zum Auffinden von Zuschnitten im Bild (normale Suche) „interessantere“ Objekte findet. Dies kann auf die Tatsache zurückzuführen sein, dass das neuronale Netzwerk bei der zweiten Methode (Aufzählung) den benachbarten Teil des Bildes nicht sieht und bei der CAM-Methode die Umgebung des Punkts das Ergebnis beeinflusst. Als Ergebnis erhielten wir eine Visualisierung der charakteristischen Merkmale jedes Landes im automatischen Modus.
Jetzt wissen wir also, welche Teile des Rahmens für das neuronale Netzwerk von entscheidender Bedeutung sind, und wir können sehen, was auf sie gefallen ist. Beispielsweise erkennen die Niederlande ein neuronales Netzwerk an der Kombination von dunklen Backsteinmauern und weißen Fensterkonturen, die Vereinigten Arabischen Emirate - an bestimmten Wolkenkratzern vor dem Hintergrund von Palmen und der Iran - an den charakteristischen Bögen und Ornamenten an den Fassaden.