2015 schrieb ich über die Tools, die Ruby zum
Erkennen von verwalteten Speicherlecks bereitstellt. In dem Artikel ging es hauptsächlich um leicht handhabbare Lecks. Dieses Mal werde ich über Tools und Tricks sprechen, mit denen Sie Lecks beseitigen können, die in Ruby nicht so einfach zu analysieren sind. Insbesondere werde ich über mwrap, heaptrack, iseq_collector und chap sprechen.
Nicht verwaltete Speicherlecks
Dieses kleine Programm provoziert ein Leck mit einem direkten Aufruf an malloc. Es beginnt mit einem Verbrauch von 16 MB RSS und endet mit 118 MB. Der Code speichert 100.000 Blöcke mit 1024 Bytes und löscht 50.000 davon.
require 'fiddle' require 'objspace' def usage rss = `ps -p
Obwohl RSS 118 MB groß ist, sind unserem Ruby-Objekt nur drei Megabyte bekannt. In der Analyse sehen wir nur einen sehr kleinen Teil dieses sehr großen Speicherverlusts.
Ein echtes Beispiel für ein solches Leck ist
Oleg Dashevsky . Ich empfehle, diesen wunderbaren Artikel zu lesen.
Wenden Sie Mwrap an
Mwrap ist ein Speicherprofiler für Ruby, der alle
Datenzuordnungen im Speicher überwacht, indem er Malloc und andere Funktionen dieser Familie abfängt. Es fängt Aufrufe ab, die diesen Ort und den freien Speicher mit
LD_PRELOAD freigeben . Es verwendet
liburcu zum Zählen und kann Zuordnungs- und
Löschzähler für jeden
Aufrufpunkt in C- und Ruby-Code verfolgen. Mwrap ist klein, etwa doppelt so groß wie RSS für ein Profilprogramm und etwa doppelt so langsam.
Es unterscheidet sich von vielen anderen Bibliotheken durch seine sehr geringe Größe und Ruby-Unterstützung. Es verfolgt Speicherorte in Ruby-Dateien und ist nicht auf Valgrind + Masif C-Level-Backtracks und ähnliche Profiler beschränkt. Dies vereinfacht die Isolierung der Problemquellen erheblich.
Um den Profiler zu verwenden, müssen Sie die Anwendung über die Mwrap-Shell ausführen. Sie implementiert die LD_PRELOAD-Umgebung und führt die Ruby-Binärdatei aus.
Fügen wir Mwrap zu unserem Skript hinzu:
require 'mwrap' def report_leaks results = [] Mwrap.each do |location, total, allocations, frees, age_total, max_lifespan| results << [location, ((total / allocations.to_f) * (allocations - frees)), allocations, frees] end results.sort! do |(_, growth_a), (_, growth_b)| growth_b <=> growth_a end results[0..20].each do |location, growth, allocations, frees| next if growth == 0 puts "#{location} growth: #{growth.to_i} allocs/frees (#{allocations}/#{frees})" end end GC.start Mwrap.clear leak_memory GC.start
Führen Sie nun das Skript mit dem Mwrap-Wrapper aus:
% gem install mwrap % mwrap ruby leak.rb leak.rb:12 growth: 51200000 allocs/frees (100000/50000) leak.rb:51 growth: 4008 allocs/frees (1/0)
Mwrap hat ein Leck im Skript korrekt erkannt (50.000 * 1024). Und nicht nur bestimmt, sondern auch eine bestimmte Linie isoliert (
i = Fiddle.malloc(1024) ), die zu einem Leck führte. Der Profiler hat es korrekt an Aufrufe von
Fiddle.free gebunden.
Es ist wichtig zu beachten, dass es sich um eine Bewertung handelt. Mwrap überwacht den vom Dial Peer zugewiesenen gemeinsam genutzten Speicher und anschließend die Speicherfreigabe. Wenn Sie jedoch einen Aufrufpunkt haben, der Speicherblöcke unterschiedlicher Größe zuweist, ist das Ergebnis ungenau. Wir haben Zugriff auf die Bewertung:
((total / allocations) * (allocations - frees))Um die Leckverfolgung zu vereinfachen, verfolgt Mwrap außerdem
age_total , die Summe der Lebensdauer jedes freigegebenen Elements, und
max_lifespan , die Lebensdauer des ältesten Elements am
max_lifespan . Wenn
age_total / frees groß ist, steigt der Speicherverbrauch trotz zahlreicher Speicherbereinigungen.
Mwrap hat mehrere Helfer, um Lärm zu reduzieren.
Mwrap.clear den gesamten internen Speicher.
Mwrap.quiet {} zwingt Mwrap, den Codeblock zu verfolgen.
Ein weiteres Unterscheidungsmerkmal von Mwrap ist die Verfolgung der Gesamtzahl der zugewiesenen und freigegebenen Bytes. Entfernen Sie
clear aus dem Skript und führen Sie es aus:
usage puts "Tracked size: #{(Mwrap.total_bytes_allocated - Mwrap.total_bytes_freed) / 1024}"
Das Ergebnis ist sehr interessant, da Mwrap trotz der RSS-Größe von 130 MB nur 91 MB sieht. Dies deutet darauf hin, dass wir unseren Prozess aufgeblasen haben. Die Ausführung ohne Mwrap zeigt, dass der Prozess in einer normalen Situation 118 MB dauert, und in diesem einfachen Fall betrug der Unterschied 12 MB. Das Zuordnungs- / Freigabemuster führte zu einer Fragmentierung. Dieses Wissen kann sehr nützlich sein, in einigen Fällen fragmentieren die nicht konfigurierten glibc malloc-Prozesse so stark, dass die sehr große Menge an Speicher, die in RSS verwendet wird, tatsächlich frei ist.
Kann Mwrap ein altes Leck auf dem roten Teppich isolieren?
In
seinem Artikel beschreibt Oleg einen sehr gründlichen Weg, um ein sehr dünnes Leck im roten Teppich zu isolieren. Es gibt viele Details. Es ist sehr wichtig, Messungen durchzuführen. Wenn Sie keine Zeitleiste für den RSS-Prozess erstellen, ist es unwahrscheinlich, dass Sie Lecks beseitigen können.
Lassen Sie uns in eine Zeitmaschine einsteigen und zeigen, wie viel einfacher es ist, Mwrap für solche Lecks zu verwenden.
def red_carpet_leak 100_000.times do markdown = Redcarpet::Markdown.new(Redcarpet::Render::HTML, extensions = {}) markdown.render("hi") end end GC.start Mwrap.clear red_carpet_leak GC.start
Redcarpet 3.3.2:
redcarpet.rb:51 growth: 22724224 allocs/frees (500048/400028) redcarpet.rb:62 growth: 4008 allocs/frees (1/0) redcarpet.rb:52 growth: 634 allocs/frees (600007/600000)
Redcarpet 3.5.0:
redcarpet.rb:51 growth: 4433 allocs/frees (600045/600022) redcarpet.rb:52 growth: 453 allocs/frees (600005/600000)
Wenn Sie es sich leisten können, den Prozess mit der halben Geschwindigkeit auszuführen, indem Sie ihn einfach im Mwrap-Produkt neu starten und das Ergebnis in einer Datei protokollieren, können Sie eine Vielzahl von Speicherlecks identifizieren.
Geheimnisvolles Leck
Vor kurzem wurde Rails auf Version 6 aktualisiert. Im Allgemeinen war die Erfahrung sehr positiv, die Leistung blieb ungefähr gleich. Rails 6 hat einige sehr gute Funktionen, die wir verwenden werden (z. B.
Zeitwerk ). Rails hat die Art und Weise geändert, in der die Vorlagen gerendert wurden. Aus Kompatibilitätsgründen waren einige Änderungen erforderlich. Einige Tage nach dem Update stellten wir einen Anstieg des RSS für Sidekiq-Task-Performer fest.
Mwrap meldete einen starken Anstieg des Speicherverbrauchs aufgrund seiner Zuordnung (
Link ):
source.encode!
Zuerst waren wir sehr verwirrt. Wir haben versucht zu verstehen, warum wir mit Mwrap unzufrieden sind. Vielleicht ist er pleite? Als der Speicherverbrauch zunahm, blieben die Haufen in Ruby unverändert.
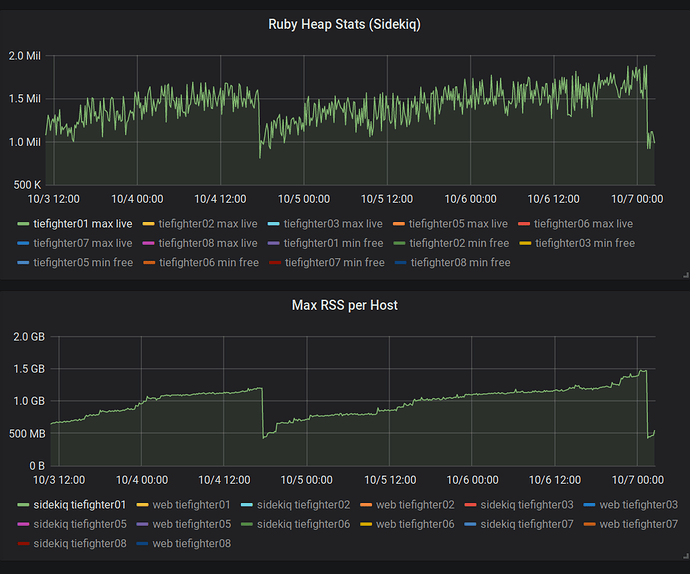
Zwei Millionen Slots im Heap verbrauchten nur 78 MB (40 Bytes pro Slot). Linien und Arrays können mehr Platz beanspruchen, aber es hat den beobachteten abnormalen Speicherverbrauch immer noch nicht erklärt. Dies wurde bestätigt, als ich
rbtrace -p SIDEKIQ_PID -e ObjectSpace.memsize_of_all .
Wo ist die Erinnerung geblieben?
Heaptrack
Heaptrack ist ein
Heapspeicher- Profiler für Linux.
Milian Wolff
erklärte perfekt
, wie der Profiler funktioniert, und sprach in mehreren Reden darüber (
1 ,
2 ,
3 ). Tatsächlich handelt es sich um einen sehr effizienten nativen Heap-Profiler, der mithilfe von
libunwind Backtraces von profilierten Anwendungen sammelt. Es arbeitet merklich schneller als
Valgrind / Massif und hat die Fähigkeit, es für die temporäre Profilerstellung im Produkt viel bequemer zu machen. Es kann an einen bereits laufenden Prozess angehängt werden!
Wie bei den meisten Heap-Profilern muss Heaptrack zählen, wenn jede Funktion in der Malloc-Familie aufgerufen wird. Dieser Vorgang verlangsamt den Prozess definitiv ein wenig.
Meiner Meinung nach ist die Architektur hier die bestmögliche. Das Abfangen erfolgt mit
LD_PRELOAD oder
GDB , um den Profiler zu laden. Mit einer
speziellen FIFO-Datei überträgt er Daten aus dem Profilierungsprozess so schnell wie möglich. Der
Heaptrack- Wrapper ist ein einfaches Shell-Skript, das das Auffinden eines Problems erleichtert. Der zweite Prozess liest Informationen aus dem FIFO und komprimiert die Tracking-Daten im laufenden Betrieb. Da Heaptrack mit „Chunks“ arbeitet, können Sie das Profil innerhalb von Sekunden nach Beginn der Profilerstellung mitten in der Sitzung analysieren. Kopieren Sie einfach die Profildatei an einen anderen Speicherort und starten Sie die Heaptrack-GUI.
Dieses
GitLab-Ticket erzählte mir von der Möglichkeit, Heaptrack zu starten. Wenn sie es ausführen könnten, könnte ich es.
Unsere Anwendung wird in einem Container ausgeführt, und ich muss sie mit
--cap-add=SYS_PTRACE neu starten.
--cap-add=SYS_PTRACE kann GDB
ptrace verwenden , das erforderlich ist, damit Heaptrack sich selbst injiziert. Ich benötige auch einen
kleinen Hack für die Shell-Datei, um
root auf das Profil des Nicht-
root Prozesses anzuwenden (wir haben unsere Discourse-Anwendung im Container unter einem begrenzten Konto gestartet).
Nachdem alles erledigt ist, müssen Sie nur noch die
heaptrack -p PID ausführen und warten, bis die Ergebnisse
heaptrack -p PID . Heaptrack erwies sich als hervorragendes Tool. Es war sehr einfach, alles zu verfolgen, was mit Speicherlecks passiert.
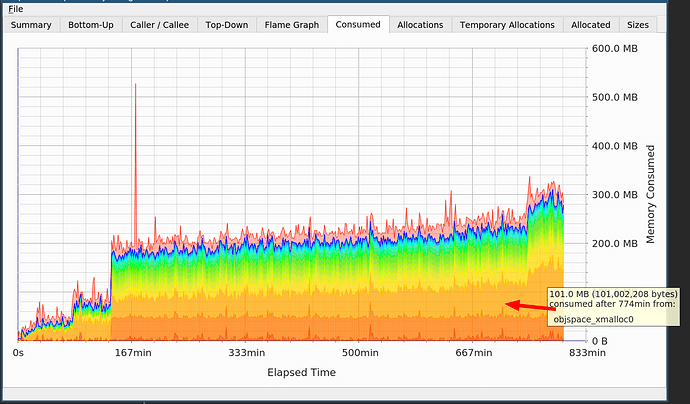
In der Grafik sehen Sie zwei Sprünge, einen aufgrund von
cppjieba und einen aufgrund von
objspace_xmalloc0 in Ruby.
Ich wusste von
Cppjieba . Das Segmentieren der chinesischen Sprache ist teuer. Sie benötigen große Wörterbücher, sodass dies kein Leck ist. Aber was ist mit dem Zuweisen von Speicher in Ruby, was mir das immer noch nicht sagt?
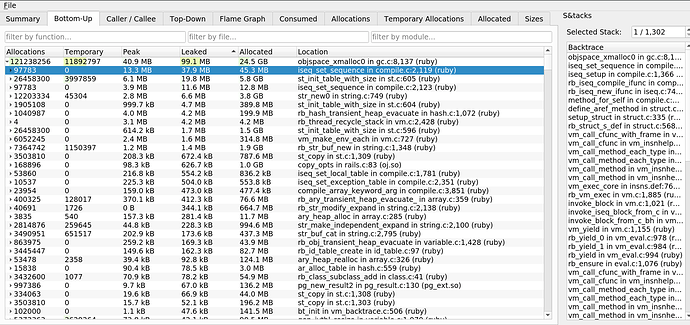
Die Hauptverstärkung hängt mit
iseq_set_sequence in
compile.c . Es stellt sich heraus, dass das Leck auf Anweisungen zurückzuführen ist. Dies beseitigte das von Mwrap entdeckte Leck. Die Ursache war
mod.module_eval(source, identifier, 0) , wodurch Folgen von Anweisungen erstellt wurden, die nicht aus dem Speicher gelöscht wurden.
Wenn ich in einer retrospektiven Analyse sorgfältig einen Heap-Dump von Ruby in Betracht gezogen hätte, hätte ich all diese IMEMOs bemerkt, da sie in diesem Dump enthalten sind. Sie sind während der In-Process-Diagnose einfach unsichtbar.
Von diesem Zeitpunkt an war das Debuggen ziemlich einfach. Ich habe alle Aufrufe des Eval-Moduls verfolgt und die ausgewerteten Daten gespeichert. Ich fand heraus, dass wir einer großen Klasse immer wieder Methoden hinzufügen. Hier ist eine vereinfachte Ansicht des Fehlers, auf den wir gestoßen sind:
require 'securerandom' module BigModule; end def leak_methods 10_000.times do method = "def _#{SecureRandom.hex}; #{"sleep;" * 100}; end" BigModule.module_eval(method) end end usage # RSS: 16164 ObjectSpace size 2869 leak_methods usage
Ruby hat eine Klasse zum Speichern von
RubyVM::InstructionSequence Befehlssequenzen:
RubyVM::InstructionSequence . Ruby ist jedoch zu faul, um diese Wrapper-Objekte zu erstellen, da das unnötige Speichern ineffizient ist. Koichi
Sasada hat die
iseq_collector- Abhängigkeit erstellt. Wenn wir diesen Code hinzufügen, können wir unseren verborgenen Speicher finden:
require 'iseq_collector' puts "#{ObjectSpace.memsize_of_all_iseq / 1024}"
materialisiert jede Folge von Anweisungen, was den Speicherverbrauch des Prozesses leicht erhöhen und dem Garbage Collector etwas mehr Arbeit geben kann.
Wenn wir zum Beispiel die Anzahl der ISEQs vor und nach dem Starten des Kollektors berechnen, werden wir
ObjectSpace.memsize_of_all_iseq unser Zähler der
RubyVM::InstructionSequence Klasse nach dem Starten von
ObjectSpace.memsize_of_all_iseq von 0 auf 11128 steigt (in diesem Beispiel):
def count_iseqs ObjectSpace.each_object(RubyVM::InstructionSequence).count end
Diese Wrapper bleiben während der gesamten Lebensdauer der Methode erhalten. Sie müssen mit einem vollständigen Lauf des Garbage Collectors besucht werden. Unser Problem wurde gelöst, indem die Klasse, die für das Rendern von E-Mail-Vorlagen verantwortlich ist (
Hotfix 1 ,
Hotfix 2 ), wiederverwendet wurde.
Kap
Während des Debuggens habe ich ein sehr interessantes Tool verwendet. Vor einigen Jahren hat Tim Boddy ein internes Tool herausgezogen, mit dem VMWare Speicherlecks analysiert, und den Code geöffnet. Hier ist das einzige Video dazu, das ich gefunden habe:
https://www.youtube.com/watch?v=EZ2n3kGtVDk . Im Gegensatz zu den meisten ähnlichen Tools hat dieses Tool keine Auswirkungen auf den ausführbaren Prozess. Es kann einfach auf die Dateien des Hauptdumps angewendet werden, während glibc als Allokator verwendet wird (jemalloc / tcmalloc usw. werden nicht unterstützt usw.).
Mit chap ist es sehr einfach, das Leck zu erkennen, das ich hatte. Nur wenige Distributionen haben eine Chap-Binärdatei, aber Sie können sie einfach
aus dem Quellcode kompilieren . Er wird sehr aktiv unterstützt.
# 444098 is the `Process.pid` of the leaking process I had sudo gcore -p 444098 chap core.444098 chap> summarize leaked Unsigned allocations have 49974 instances taking 0x312f1b0(51,573,168) bytes. Unsigned allocations of size 0x408 have 49974 instances taking 0x312f1b0(51,573,168) bytes. 49974 allocations use 0x312f1b0 (51,573,168) bytes. chap> list leaked ... Used allocation at 562ca267cdb0 of size 408 Used allocation at 562ca267d1c0 of size 408 Used allocation at 562ca267d5d0 of size 408 ... chap> summarize anchored .... Signature 7fbe5caa0500 has 1 instances taking 0xc8(200) bytes. 23916 allocations use 0x2ad7500 (44,922,112) bytes.
Chap kann Signaturen verwenden, um nach Speicherorten mit unterschiedlichem Speicher zu suchen, und GDB ergänzen. Beim Debuggen in Ruby kann dies eine große Hilfe sein, um festzustellen, welchen Speicher der Prozess verwendet. Es zeigt den insgesamt verwendeten Speicher, manchmal kann glibc malloc so stark fragmentieren, dass das verwendete Volume sehr stark vom tatsächlichen RSS abweichen kann. Sie können die Diskussion lesen:
Feature # 14759: [PATCH] set M_ARENA_MAX für glibc malloc - Ruby Master - Ruby Issue Tracking System . Chap ist in der Lage, den gesamten verwendeten Speicher korrekt zu zählen und eine eingehende Analyse seiner Zuordnung bereitzustellen.
Darüber hinaus kann chap in Workflows integriert werden, um Lecks automatisch zu erkennen und solche Baugruppen zu kennzeichnen.
Follow-up-Arbeit
Diese Debugging-Runde hat mich dazu gebracht, einige Fragen zu unseren Helfer-Toolkits zu stellen:
Zusammenfassung
Unser heutiges Toolkit zum Debuggen sehr komplexer Speicherlecks ist viel besser als vor 4 Jahren! Mwrap, Heaptrack und Chap sind sehr leistungsfähige Tools zur Lösung von Speicherproblemen, die während der Entwicklung und des Betriebs auftreten.
Wenn Sie nach einem einfachen Speicherverlust in Ruby suchen, empfehle ich,
meinen Artikel von 2015 zu lesen, der größtenteils relevant ist.
Ich hoffe, Sie finden es einfacher, wenn Sie das nächste Mal mit dem Debuggen eines komplexen nativen Speicherverlusts beginnen.