
Hallo! Mein Name ist Askhat Nuryev, ich bin ein führender Automatisierungsingenieur bei DINS.
Ich arbeite seit 7 Jahren bei Dino Systems. Während dieser Zeit musste ich mich mit verschiedenen Aufgaben befassen: vom Schreiben automatisierter Funktionstests bis zum Testen der Leistung und Hochverfügbarkeit. Allmählich beschäftigte ich mich mehr mit der Organisation von Tests und der Optimierung von Prozessen im Allgemeinen.
In diesem Artikel werde ich erzählen:
- Was ist, wenn Fehler bereits in die Produktion gelangt sind?
- Wie können Sie um die Qualität des Systems konkurrieren, wenn Sie die Fehler nicht mit Ihren Händen zählen und Ihre Augen nicht überarbeiten können?
- Was sind die Fallstricke bei der automatischen Fehlerbehandlung?
- Welche Boni kann ich durch die Analyse von Abfragestatistiken erhalten?
DINS ist das Entwicklungszentrum von RingCentral, einem Marktführer unter den Cloud-Anbietern von Unified Communications. Ringentral bietet alles für die Geschäftskommunikation, von klassischer Telefonie, SMS, Besprechungen bis hin zur Funktionalität von Contact Centern und Produkten für komplexe Teamarbeit (a la Slack). Diese Cloud-Lösung befindet sich in eigenen Rechenzentren, und der Client muss nur die Site abonnieren.
Das System, an dessen Entwicklung wir beteiligt sind, bedient 2 Millionen aktive Benutzer und verarbeitet täglich mehr als 275 Millionen Anfragen. Das Team, an dem ich arbeite, entwickelt die API.
Das System hat eine ziemlich komplizierte API. Mit ihm können Sie SMS senden, Anrufe tätigen, Videokonferenzen sammeln, Konten einrichten und sogar Faxe senden (Hallo, 2019). In vereinfachter Form sieht das Schema der Interaktion von Diensten ungefähr so aus. Ich scherze nicht.

Es ist klar, dass ein solch komplexes und hoch belastetes System eine große Anzahl von Fehlern verursacht. Zum Beispiel haben wir vor einem Jahr Zehntausende von Fehlern pro Woche erhalten. Dies sind Tausendstel Prozent im Verhältnis zur Gesamtzahl der Anfragen, aber dennoch sind so viele Fehler ein Chaos. Wir haben sie dank des entwickelten Support-Service entdeckt. Diese Fehler betreffen jedoch die Benutzer. Darüber hinaus entwickelt sich das System ständig weiter, die Anzahl der Kunden wächst. Und die Anzahl der Fehler auch.
Zuerst haben wir versucht, das Problem auf klassische Weise zu lösen.
Wir haben uns versammelt, nach Protokollen aus der Produktion gefragt, etwas korrigiert, etwas vergessen und Dashboards in Kibana und Sumologic erstellt. Aber insgesamt hat es nicht geholfen. Bugs sind trotzdem durchgesickert, haben sich Benutzer beschwert. Es wurde klar, dass etwas schief lief.
Automatisierung
Natürlich haben wir verstanden und festgestellt, dass 90% der Zeit, die für die Behebung des Fehlers aufgewendet wird, für das Sammeln von Informationen aufgewendet wird. Hier ist was genau:
- Holen Sie sich die fehlenden Informationen von anderen Abteilungen.
- Untersuchen Sie die Serverprotokolle.
- Untersuchen Sie das Verhalten unseres Systems.
- Verstehen Sie, ob dieses oder jenes Systemverhalten fehlerhaft ist.
Und nur die restlichen 10% haben wir direkt für die Entwicklung ausgegeben.
Wir dachten - aber was ist, wenn wir ein System erstellen, das selbst Fehler findet, ihnen Priorität einräumt und alle Daten anzeigt, die zur Behebung erforderlich sind?
Ich muss sagen, dass die Idee eines solchen Dienstes einige Bedenken hervorrief.
Jemand sagte: "Wenn wir alle Fehler selbst finden, warum brauchen wir dann eine Qualitätssicherung?"
Andere sagten das Gegenteil: "Du wirst in diesem Haufen Käfer ertrinken!".
Mit einem Wort, es hat sich gelohnt, einen Dienst zu leisten, wenn man nur versteht, welcher von ihnen richtig ist.
Spoiler(beide Gruppen von Skeptikern haben sich geirrt)
Fertige Lösungen
Zunächst haben wir uns entschlossen zu sehen, welche der ähnlichen Systeme bereits auf dem Markt sind. Es stellte sich heraus, dass es viele von ihnen gibt. Sie können Raygun, Sentry, Airbrake hervorheben, es gibt andere Dienste.
Aber keiner von ihnen passte zu uns, und hier ist der Grund:
- Bei einigen Diensten mussten wir zu große Änderungen an der vorhandenen Infrastruktur vornehmen, einschließlich Änderungen am Server. Airbrake.io müsste Dutzende, Hunderte von Systemkomponenten verfeinern.
- Andere sammelten Daten über unsere eigenen Fehler und schickten sie irgendwohin. Unsere Sicherheitsrichtlinie erlaubt dies nicht - Benutzer- und Fehlerdaten sollten bei uns bleiben.
- Nun, sie sind auch ziemlich teuer.
Wir machen unser
Es wurde klar, dass wir unseren Service leisten sollten, zumal wir bereits eine sehr gute Infrastruktur dafür aufgebaut hatten:
- Alle Dienste haben bereits Protokolle in ein einziges Repository geschrieben - Elastic. In Protokollen wurden einheitliche Kennungen von Anforderungen über alle Dienste geworfen.
- Leistungsstatistiken wurden zusätzlich in Hadoop aufgezeichnet. Wir haben mit Impala und Metabase mit Protokollen gearbeitet.
Von allen Serverfehlern (
gemäß der Klassifizierung der HTTP-Statuscodes ) ist 500 Code der vielversprechendste in Bezug auf die Fehleranalyse. In Reaktion auf die Fehler 502, 503 und 504 können Sie in einigen Fällen die Anforderung einfach nach einiger Zeit wiederholen, ohne dem Benutzer die Antwort anzuzeigen. Gemäß den Empfehlungen der RC Platform API sollten Benutzer den Support kontaktieren, wenn sie als Antwort auf einen Anruf den Statuscode 500 erhalten.
Die erste Version des Systems sammelte Abfrageausführungsprotokolle, alle aufgetretenen Stapelspuren, Benutzerdaten und legte den Fehler in den Tracker, in unserem Fall JIRA.
Unmittelbar nach dem Testlauf haben wir festgestellt, dass das System eine erhebliche Anzahl doppelter Fehler verursacht. Unter diesen Duplikaten hatten jedoch viele fast die gleichen Stapelspuren.
Es war notwendig, die Methode zur Identifizierung der gleichen Fehler zu ändern. Fahren Sie mit der Analyse rein statistischer Daten fort, um die Grundursache des Fehlers zu finden. Stapelspuren charakterisieren das Problem gut, sind jedoch nur schwer miteinander zu vergleichen. Die Zeilennummern ändern sich von Version zu Version, Benutzerdaten und anderes Rauschen treten in sie ein. Außerdem werden sie nicht immer in das Protokoll aufgenommen - bei einigen verworfenen Anforderungen sind sie einfach nicht vorhanden.
In seiner reinsten Form sind Stapelspuren für die Verfolgung von Fehlern unpraktisch.
Es war notwendig, Muster und Vorlagen für Stapelspuren auszuwählen und sie von Informationen zu befreien, die sich häufig änderten. Nach einer Reihe von Experimenten haben wir beschlossen, reguläre Ausdrücke zu verwenden, um die Daten zu löschen.
Als Ergebnis haben wir eine neue Version veröffentlicht, in der Fehler durch diese eindeutigen Vorlagen identifiziert wurden, wenn Stapelspuren verfügbar waren. Und wenn sie nicht verfügbar waren, dann auf die alte Weise über die http-Methode und die API-Gruppe.
Und danach gab es praktisch keine Duplikate mehr. Es wurden jedoch viele eindeutige Fehler gefunden.
Der nächste Schritt besteht darin, zu verstehen, wie Fehler priorisiert werden, die früher behoben werden müssen. Wir haben Prioritäten gesetzt durch:
- Die Häufigkeit des Fehlers.
- Die Anzahl der Benutzer, um die sie sich kümmert.
Basierend auf den gesammelten Statistiken haben wir begonnen, wöchentliche Berichte zu veröffentlichen. Sie sehen so aus:
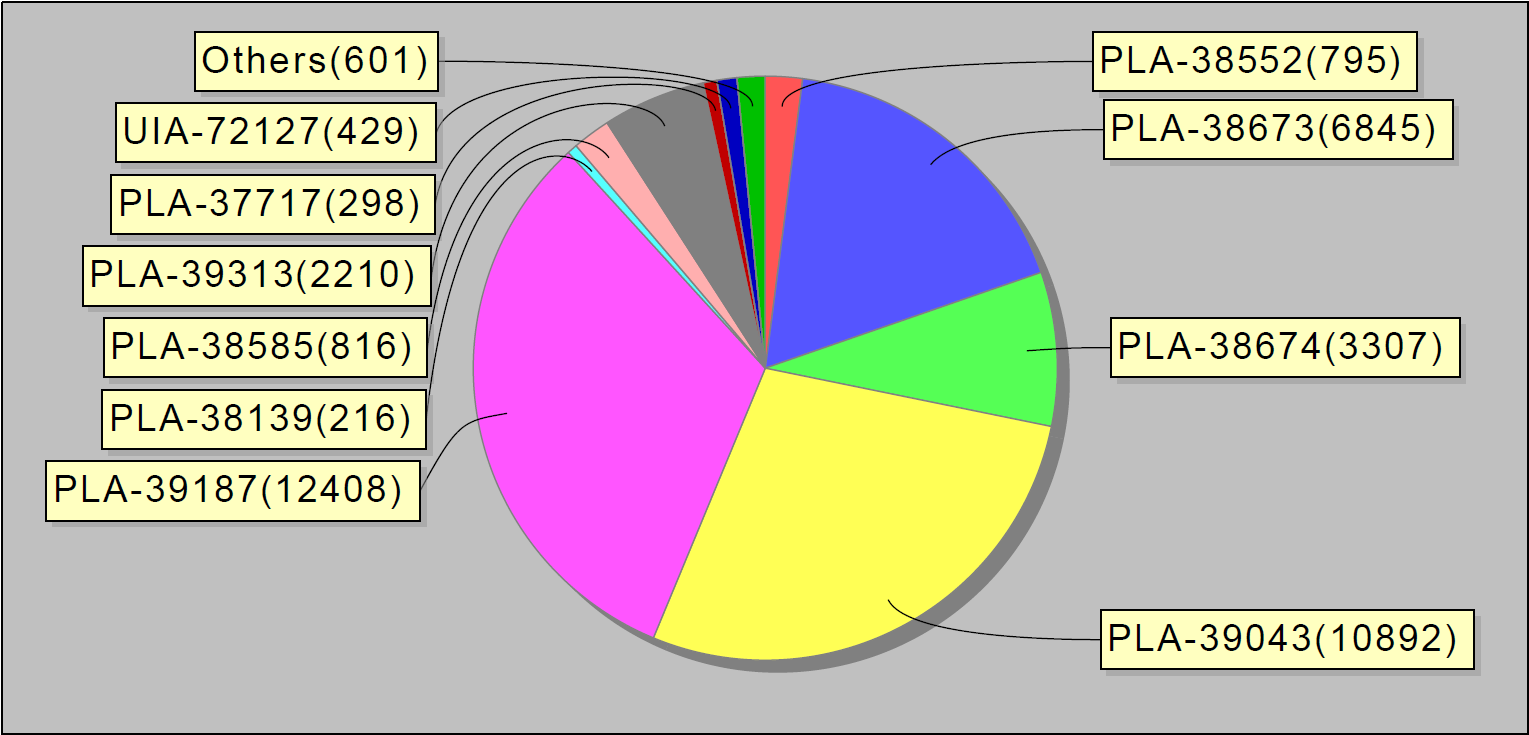
Oder zum Beispiel die 10 häufigsten Fehler pro Woche. Interessanterweise machten diese 10 Fehler in Jira 90% der Servicefehler aus:
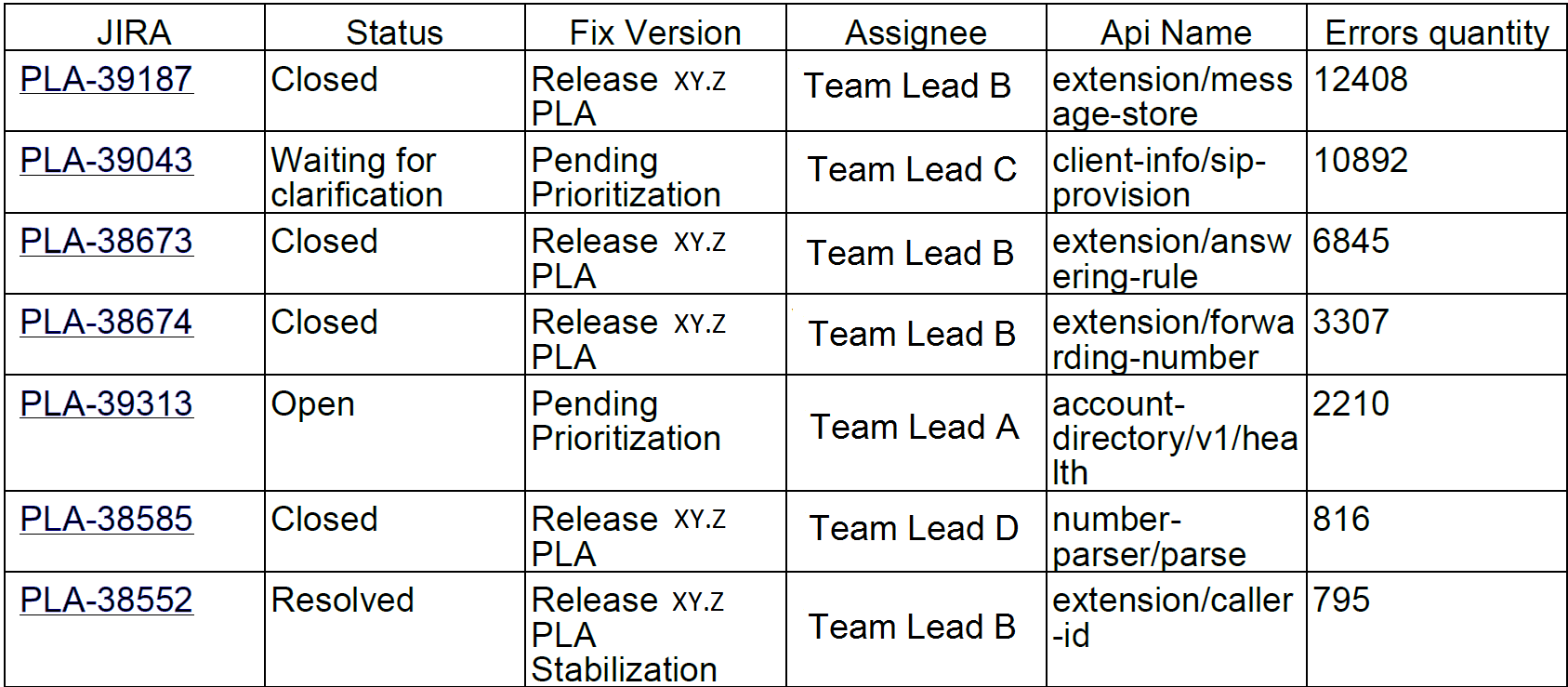
Wir haben solche Berichte an Entwickler und Teamleiter gesendet.
Einige Monate nach dem Start des Systems wurde die Anzahl der Probleme spürbar geringer. Sogar unser kleines MVP (minimal lebensfähiges Produkt) hat dazu beigetragen, Fehler besser auszuräumen.
Das Problem
Vielleicht würden wir hier aufhören, wenn nicht für einen Unfall.
Einmal kam ich zur Arbeit und bemerkte, dass das System Fehler wie heiße Kuchen nietet: einer nach dem anderen. Nach einer kurzen Untersuchung wurde klar, dass Dutzende dieser Fehler von einem Dienst stammten. Um herauszufinden, was los ist, ging ich in den Chatroom des Bereitstellungsteams. Es gab Leute, die daran beteiligt waren, neue Versionen von Diensten in der Produktion zu installieren und sicherzustellen, dass sie wie erwartet funktionierten.
Ich fragte: "Leute, was ist mit diesem Service passiert?".
Und sie antworten: "Vor einer Stunde haben wir dort eine neue Version installiert."
Schritt für Schritt haben wir das Problem identifiziert und eine vorübergehende Lösung gefunden, dh den Server neu gestartet.
Es wurde deutlich, dass das "fehlerhafte" System nicht nur von Entwicklern und Ingenieuren benötigt wird, die für die Qualität verantwortlich sind. Interessiert sind auch die Ingenieure, die für den Zustand der Server in der Produktion verantwortlich sind, sowie die Leute, die neue Versionen auf den Servern installieren. Der von uns entwickelte Service zeigt genau, welche Fehler in der Produktion während Systemänderungen auftreten, z. B. beim Installieren von Servern, Anwenden einer neuen Konfiguration usw.
Und wir haben uns für eine weitere Entwicklungsiteration entschieden.
Bei der Fehlerbehandlung haben wir der Datenbank und den Dashboards in Grafana einen Datensatz mit Statistiken zur Problemwiedergabe hinzugefügt. So sieht die grafische Verteilung der Fehler pro Tag im gesamten System aus:

Und so - Fehler in einzelnen Diensten.

Wir haben auch Auslöser mit Eskalationen an die zuständigen Engineering-Teams verschraubt - falls es viele Fehler gibt. Wir richten die Datenerfassung auch alle 30 Minuten ein (statt wie bisher einmal am Tag).
Der Prozess unseres Systems sah folgendermaßen aus:
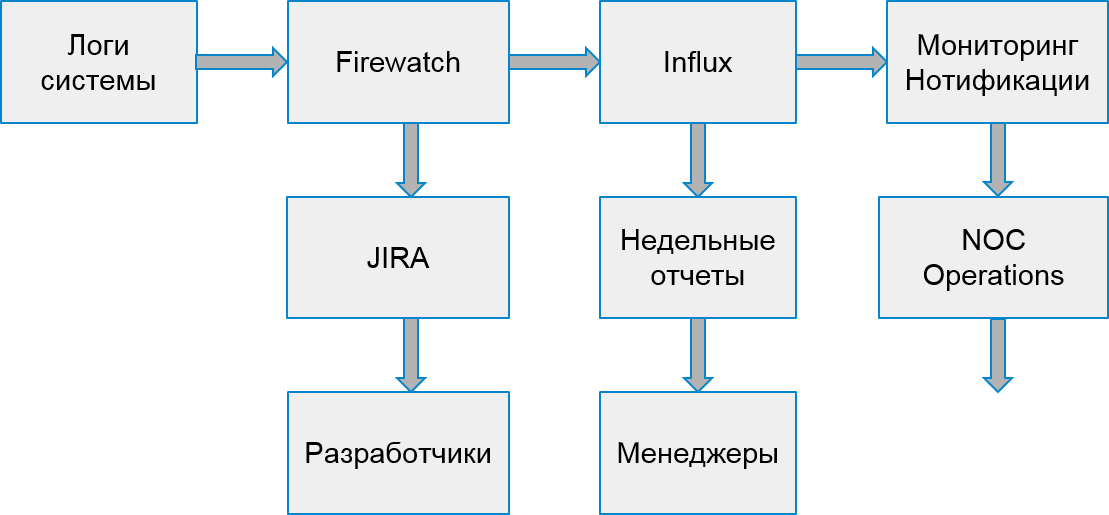
Kundenfehler
Benutzer litten jedoch nicht nur unter Serverfehlern. Es kam auch vor, dass der Fehler aufgrund der Implementierung von Clientanwendungen auftrat.
Um mit Clientfehlern umzugehen, haben wir uns entschlossen, einen weiteren Such- und Analyseprozess zu erstellen. Zu diesem Zweck haben wir zwei Arten von Fehlern ausgewählt, die Unternehmen betreffen: Autorisierungsfehler und Drosselfehler.
Durch Drosselung wird das System vor Überlastung geschützt. Wenn die Anwendung oder der Benutzer ihr Anforderungskontingent überschreitet, gibt das System einen Fehlercode 429 und einen Wiederholungs-Header zurück. Der Wert des Headers gibt die Zeit an, nach der die Anforderung für eine erfolgreiche Ausführung wiederholt werden muss.
Anwendungen können unbegrenzt gedrosselt bleiben, wenn sie keine neuen Anforderungen mehr senden. Endbenutzer können diese Fehler nicht von anderen unterscheiden. Dies führt zu Beschwerden beim Support.
Glücklicherweise ermöglichen die Infrastruktur und das Statistiksystem, auch Clientfehler zu verfolgen. Wir können dies tun, weil Entwickler von Anwendungen, die unsere API verwenden, sich vorregistrieren und ihren eindeutigen Schlüssel erhalten müssen. Jede Anforderung vom Client muss ein Autorisierungstoken enthalten, andernfalls erhält der Client einen Fehler. Mit diesem Token berechnen wir die Anwendung.
So sieht die Überwachung von Drosselfehlern aus. Fehlerspitzen entsprechen Wochentagen und an Wochenenden - im Gegenteil, es gibt keine Fehler:

Genauso wie bei internen Fehlern, die auf Statistiken von Hadoop basieren, haben wir verdächtige Anwendungen gefunden. Erstens in Bezug auf die Anzahl der erfolgreichen Anfragen auf die Anzahl der Anfragen, die mit Code 429 abgeschlossen wurden. Wenn wir mehr als die Hälfte dieser Anfragen erhalten haben, dachten wir, dass die Anwendung nicht richtig funktioniert.
Später begannen wir, das Verhalten einzelner Anwendungen mit bestimmten Benutzern zu analysieren. Unter den verdächtigen Anwendungen haben wir das spezifische Gerät gefunden, auf dem die Anwendung ausgeführt wird, und beobachtet, wie oft Anforderungen nach dem ersten Drosselungsfehler ausgeführt werden. Wenn die Anforderungshäufigkeit nicht abnahm, behandelte die Anwendung den Fehler nicht wie erwartet.
Ein Teil der Anwendungen wurde in unserem Unternehmen entwickelt. So konnten wir sofort verantwortliche Ingenieure finden und Fehler schnell korrigieren. Wir haben uns entschlossen, die verbleibenden Fehler an ein Team zu senden, das externe Entwickler kontaktierte und ihnen half, ihre Anwendung zu reparieren.
Für jede solche Anwendung haben wir:
- Wir erstellen eine Aufgabe in JIRA.
- Wir erfassen Statistiken in Influx.
- Wir bereiten Auslöser für chirurgische Eingriffe vor, falls die Anzahl der Fehler stark zunimmt.
Das System zum Arbeiten mit Clientfehlern sieht folgendermaßen aus:
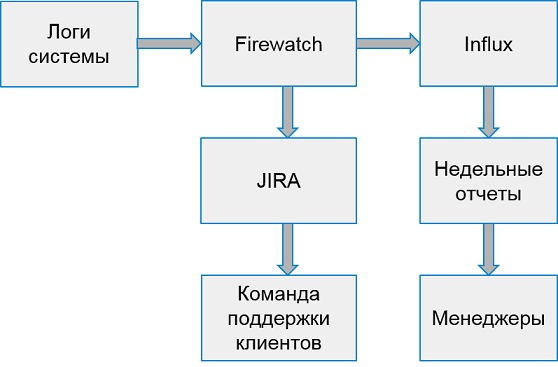
Einmal pro Woche sammeln wir Berichte der 10 schlechtesten Anwendungen nach Anzahl der Fehler.
Nicht fangen, sondern warnen
Wir haben also gelernt, wie man Fehler im Produktionssystem findet und wie man sowohl mit Serverfehlern als auch mit Clientfehlern umgeht. Alles scheint in Ordnung zu sein, aber ...
Tatsächlich reagieren wir jedoch zu spät - Fehler betreffen bereits Benutzer!
Warum nicht versuchen, Fehler früher zu finden?
Natürlich wäre es cool, alles in Testumgebungen zu finden. Testumgebungen sind jedoch Räume mit weißem Rauschen. Sie werden derzeit aktiv entwickelt. Täglich funktionieren mehrere verschiedene Serverversionen. Das zentrale Erfassen von Fehlern ist zu früh. Es sind zu viele Fehler darin, zu oft ändert sich alles.
Das Unternehmen verfügt jedoch über spezielle Umgebungen, in denen alle stabilen Baugruppen integriert sind, um die Leistung, die zentralisierte manuelle Regression und Hochverfügbarkeitstests zu überprüfen. Solche Umgebungen sind in der Regel immer noch nicht stabil genug. Es gibt jedoch Teams, die daran interessiert sind, Probleme mit diesen Umgebungen zu analysieren.
Aber es gibt noch ein Hindernis: Hadoop sammelt keine Daten aus diesen Umgebungen! Wir können nicht dieselbe Methode verwenden, um Fehler zu erkennen. Wir müssen nach einer anderen Datenquelle suchen.
Nach einer kurzen Suche haben wir uns entschlossen, das Statistik-Streaming zu verarbeiten und die Daten aus der Warteschlange zu lesen, in die unsere Dienste zur Übertragung an Hadoop schreiben. Es reichte aus, eindeutige Fehler zu akkumulieren und beispielsweise alle 30 Minuten stapelweise zu verarbeiten. Es ist einfach, ein Warteschlangensystem einzurichten, das Daten liefert. Sie mussten lediglich den Empfang und die Verarbeitung verfeinern.
Wir begannen zu beobachten, wie sich die gefundenen Fehler nach der Erkennung verhalten. Es stellte sich heraus, dass die meisten gefundenen und nicht behobenen Fehler später in der Produktion auftreten. Also finden wir sie richtig.
Aus diesem Grund haben wir einen Prototyp des Systems, der Institutionen und der Tracking Error erstellt. Bereits in der aktuellen Form können Sie die Qualität des Systems verbessern, Fehler feststellen und korrigieren, bevor Benutzer davon erfahren. Wenn wir früher Zehntausende fehlerhafter Anfragen pro Woche bearbeitet haben, sind es jetzt nur noch 2-3 Tausend. Und wir korrigieren sie viel schneller.
Was weiter
Natürlich werden wir hier nicht aufhören und das System der Such- und Nachverfolgungsfehler weiter verbessern. Wir haben Pläne:
- Analyse weiterer API-Fehler.
- Integration mit Funktionstests.
- Zusätzliche Funktionen zur Untersuchung von Vorfällen in unserem System.
Aber dazu beim nächsten Mal mehr.