Entschlüsselung des Berichts „Typische Implementierung der Überwachung“ durch Nikolay Sivko.
Ich heiße Nikolai Sivko. Ich überwache auch. Okmeter ist die 5 Überwachung, die ich mache. Ich habe beschlossen, alle Menschen vor der Hölle der Überwachung zu retten und jemanden vor diesem Leiden zu retten. Ich versuche immer, in meinen Präsentationen kein Okmeter zu bewerben. Natürlich werden die Bilder von dort sein. Aber die Idee von dem, was ich sagen möchte, ist, dass wir die Überwachung zu einem etwas anderen Ansatz machen, als es normalerweise jeder tut. Wir reden viel darüber. Wenn wir versuchen, jeden einzelnen Menschen davon zu überzeugen, wird er am Ende überzeugt. Ich möchte genau über unseren Ansatz sprechen, damit Sie, wenn Sie die Überwachung selbst durchführen, unseren Rechen vermeiden.

Über das Okmeter auf den Punkt gebracht. Wir machen das Gleiche wie Sie, aber es gibt alle möglichen Chips. Chips:
- Detaillierung;
- eine große Anzahl vorkonfigurierter Trigger, die auf den Problemen unserer Kunden basieren;
- Automatische Konfiguration

Ein typischer Kunde kommt zu uns. Er hat zwei Aufgaben:
1) zu verstehen, dass alles von der Überwachung zusammengebrochen ist, wenn es überhaupt nichts gibt.
2) schnell beheben.
Er kommt, um die Antworten zu überwachen, was mit ihm passiert.
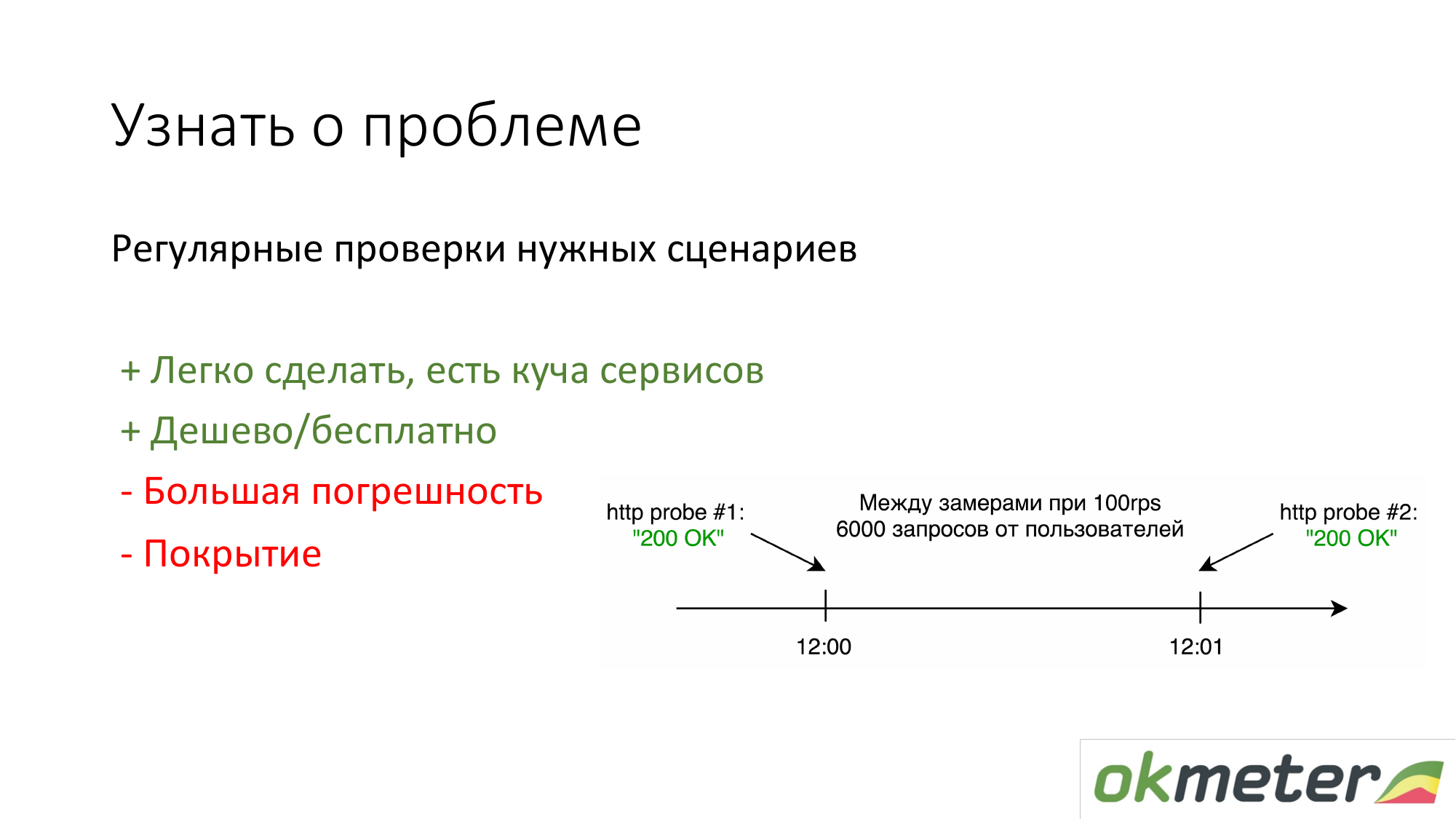
Das erste, was Leute tun, die nichts haben, ist, https://www.pingdom.com/ und andere Dienste zur Überprüfung zu stellen. Der Vorteil dieser Lösung ist, dass sie in 5 Minuten durchgeführt werden kann. Durch Kundenanrufe erfahren Sie nichts mehr über das Problem. Es gibt Probleme mit der Genauigkeit, so dass sie Probleme überspringen. Für einfache Websites reicht dies jedoch aus.

Das zweite, was wir befürworten, ist, anhand der Statistiken der tatsächlichen Benutzer anhand der Protokolle zu zählen. So oft erhält ein bestimmter Benutzer 5xx Fehler. Was ist die Antwortzeit von Benutzern. Es gibt Nachteile, aber im Allgemeinen funktioniert so etwas.

Über nginx: Wir haben es so gemacht, dass jeder Client, der sofort kommt, den Agenten in das Frontend stellt und alles automatisch von ihm übernommen wird. Es beginnt zu analysieren, Fehler treten auf und so weiter. Er hat fast nichts zu konfigurieren.

Die meisten Clients haben jedoch keine Timer in den Standard-Nginx-Protokollen. Diese 90 Prozent der Kunden möchten die Antwortzeit ihrer Website nicht wissen. Wir sind die ganze Zeit damit konfrontiert. Das Nginx-Protokoll muss erweitert werden. Ab sofort werden automatisch Histogramme angezeigt. Dies ist wahrscheinlich ein wichtiger Aspekt der Tatsache, dass die Zeit gemessen werden muss.

Was ziehen wir da raus? In der Praxis nehmen wir Metriken in solchen Dimensionen. Dies sind keine flachen Metriken. Die Metrik heißt index.request.rate - die Anzahl der Abfragen pro Sekunde. Es wird detailliert von:
- der Host, von dem Sie die Protokolle entfernt haben;
- das Protokoll, aus dem diese Daten entnommen wurden;
- http nach Methode;
- http Status;
- Cache-Status.
Dies ist NICHT jede spezifische URL mit allen Argumenten. Wir möchten nicht 100.000 Metriken aus dem Protokoll entfernen.

Wir wollen 1000 Metriken nehmen. Daher versuchen wir, die URL nach Möglichkeit zu normalisieren. Nimm die oberste URL. Und für URLs, die aussagekräftig sind, zeigen wir ein separates Balkendiagramm, separat 5xx.

Hier ist ein Beispiel, wie diese einfache Metrik zu verwendbaren Grafiken wird. Dies ist unser DSL an der Spitze. Ich habe dieses DSL versucht, um die ungefähre Logik zu erklären. Wir haben alle Nginx-Anfragen pro Sekunde entgegengenommen und auf allen Maschinen, die wir haben, ausgelegt. Ich habe Kenntnisse darüber, wie wir es ausgleichen, wie viel RPS wir insgesamt haben (Anfrage pro Sekunde, Anfragen pro Sekunde).

Auf der anderen Seite können wir diese Metrik filtern und nur 4xx anzeigen. Auf einem 4xx-Diagramm können sie entsprechend dem tatsächlichen Status angeordnet werden. Ich erinnere Sie daran, dass dies dieselbe Metrik ist.

In der Grafik können Sie 4xx nach URL anzeigen. Dies ist die gleiche Metrik.

Wir schießen auch ein Histogramm aus den Protokollen. Ein Histogramm ist die Metrik response_time.histrogram, bei der es sich tatsächlich um RPS mit einem zusätzlichen Ebenenparameter handelt. Dies ist nur eine Unterbrechung der Zeit, in der die Anforderung einen Bucket erhält.
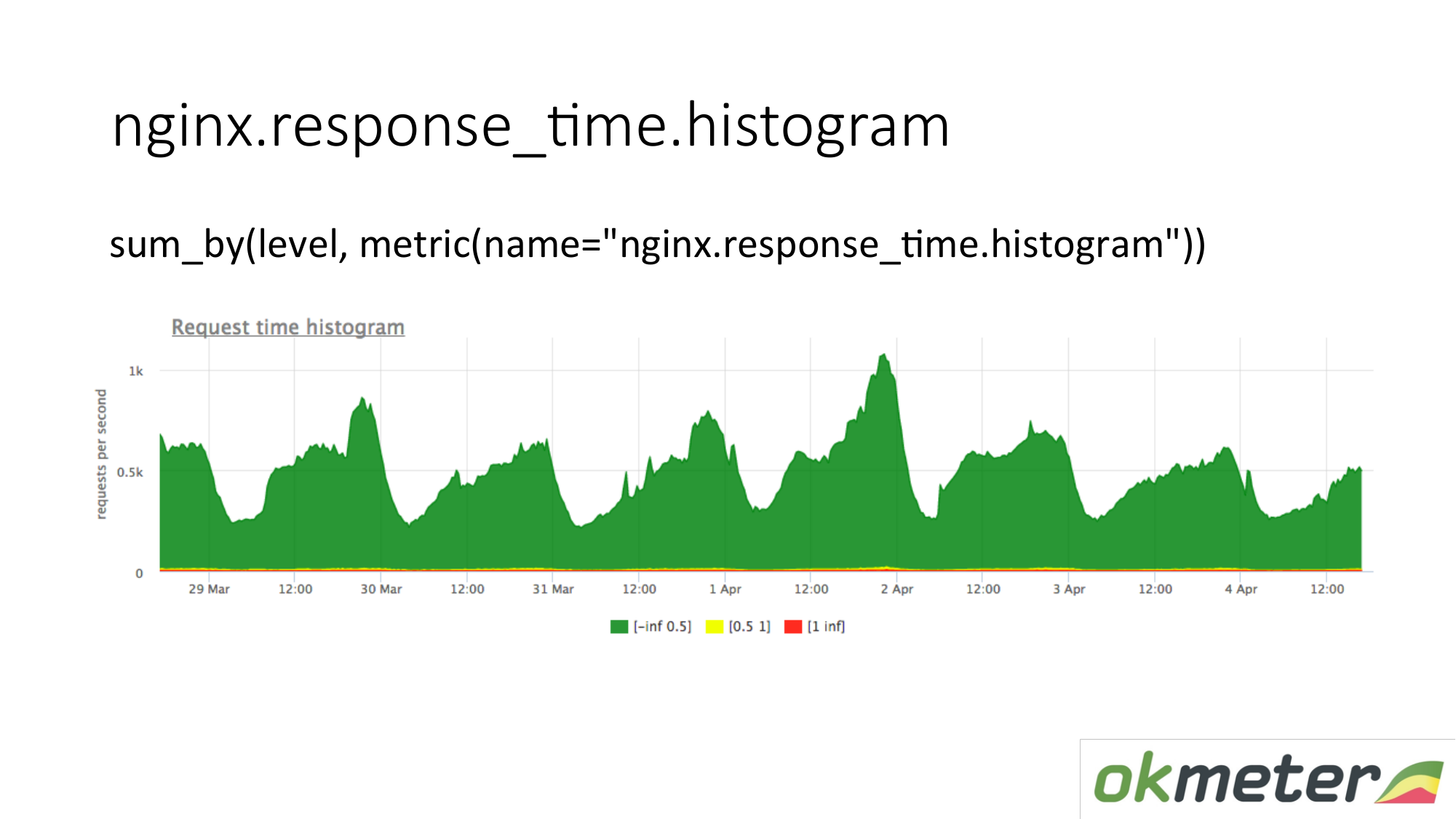
Wir zeichnen eine Anfrage: Fassen Sie das gesamte Histogramm zusammen und sortieren Sie es in Ebenen:
- Langsame Anfragen
- schnelle Anfragen;
- durchschnittliche Anfragen;
Wir haben ein Bild, das bereits von Servern zusammengefasst wurde. Die Metrik ist dieselbe. Ihre physikalische Bedeutung ist verständlich. Aber wir nutzen es auf ganz andere Weise.
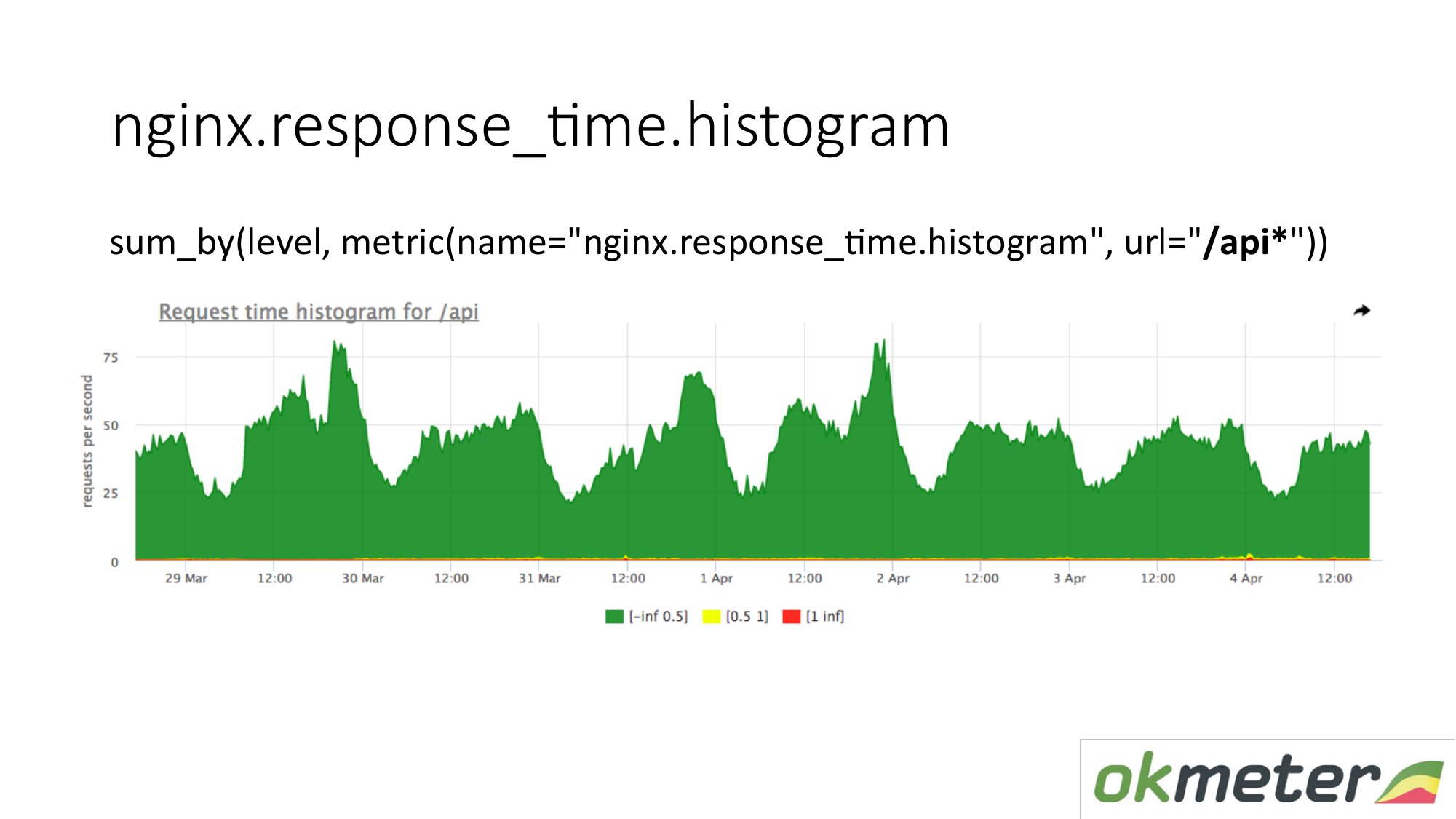
In der Tabelle können Sie das Histogramm nur anhand einer URL anzeigen, die mit "/ api" beginnt. Daher betrachten wir das Histogramm separat. Wir schauen uns an, wie viel in diesem Moment. Wir sehen, wie viele RPS in der URL "/ api" enthalten waren. Dieselbe Metrik, aber eine andere Anwendung.

Ein paar Worte zu Timings in Nginx. Es gibt request_time, die die Zeit vom Beginn der Anforderung bis zur Übertragung des letzten Bytes an den Socket an den Client enthält. Und es gibt upstream_response_time. Sie müssen beide gemessen werden. Wenn wir request_time einfach entfernen, werden dort Verzögerungen aufgrund von Clientverbindungsproblemen mit Ihrem Server angezeigt. Dort werden Verzögerungen angezeigt, wenn Limit Request C Burst konfiguriert ist und der Client im Bad ist. Sie werden nicht verstehen, ob Sie den Server reparieren oder den Hoster anrufen müssen. Dementsprechend entfernen wir beide und es ist ungefähr klar, was passiert.

Mit der Aufgabe zu verstehen, ob die Website funktioniert oder nicht, glaube ich, dass wir mehr oder weniger verstanden haben. Es gibt Fehler. Es gibt Ungenauigkeiten. Allgemeine Grundsätze sind wie folgt.
Nun zur Überwachung der mehrschichtigen Architektur. Denn selbst der einfachste Online-Shop hat mindestens ein Frontend, gefolgt von einer Bitrix und einer Basis. Dies sind bereits viele Links. Der allgemeine Punkt ist, dass Sie einige Indikatoren aus jedem Level schießen müssen. Das heißt, der Benutzer denkt über das Frontend nach. Frontend denkt über Backend nach. Das Backend denkt an das benachbarte Backend. Und alle denken an die Basis. Also gehen wir nach Schichten, nach Abhängigkeiten durch. Wir decken alles mit einer Art Metrik ab. Wir bekommen etwas am Ausgang.

Warum nicht auf eine Schicht beschränkt sein? In der Regel befindet sich zwischen den Schichten ein Netzwerk. Ein großes Netzwerk unter Last ist eine äußerst instabile Substanz. Deshalb passiert dort alles. Plus, die Messungen, die Sie machen, auf welcher Schicht liegen kann. Wenn Sie Messungen auf Schicht „A“ und Schicht „B“ durchführen und diese über das Netzwerk miteinander interagieren, können Sie ihre Messwerte vergleichen und einige Anomalien und Inkonsistenzen feststellen.

Über das Backend. Wir möchten verstehen, wie das Backend überwacht wird. Was tun, um schnell zu verstehen, was passiert? Ich erinnere Sie daran, dass wir bereits die Aufgabe übernommen haben, Ausfallzeiten zu minimieren. Und was das Backend betrifft, empfehlen wir normalerweise Verständnis:
- Wie viel frisst diese Ressource?
- Sind wir an eine Grenze gestoßen?
- Was ist mit der Laufzeit los? Zum Beispiel die JVM-Laufzeitplattform, die Golang-Laufzeit und andere Laufzeit.
- Wenn wir dies alles bereits behandelt haben, ist es für uns interessant, bereits näher an unserem Code zu sein. Wir können entweder die automatische Intrumetrie (statsd, * -metric) verwenden, die uns dies alles zeigt. Oder weisen Sie sich selbst an, indem Sie Timer, Zähler usw. einstellen.
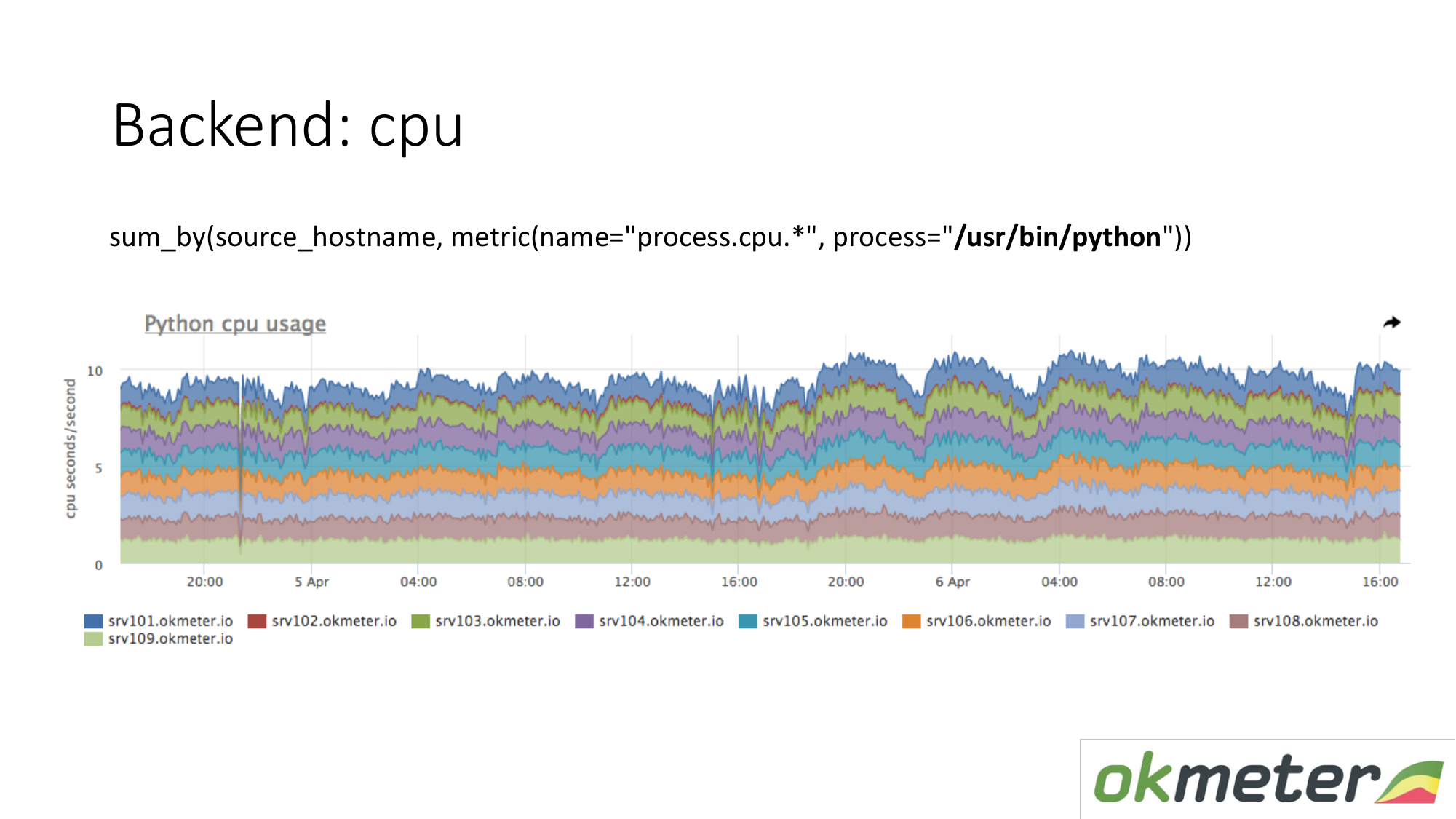
Über die Ressourcen. Unser Standardagent entfernt den Ressourcenverbrauch aller Prozesse. Daher müssen wir für das Backend keine Daten separat erfassen. Wir nehmen und sehen, wie viel die CPU den Prozess verbraucht, zum Beispiel Python auf den maskierten Servern. Wir zeigen alle Server im Cluster in demselben Diagramm, weil wir verstehen möchten, ob wir Ungleichgewichte haben und ob auf demselben Computer etwas explodiert ist. Wir sehen den Gesamtverbrauch von gestern bis heute.
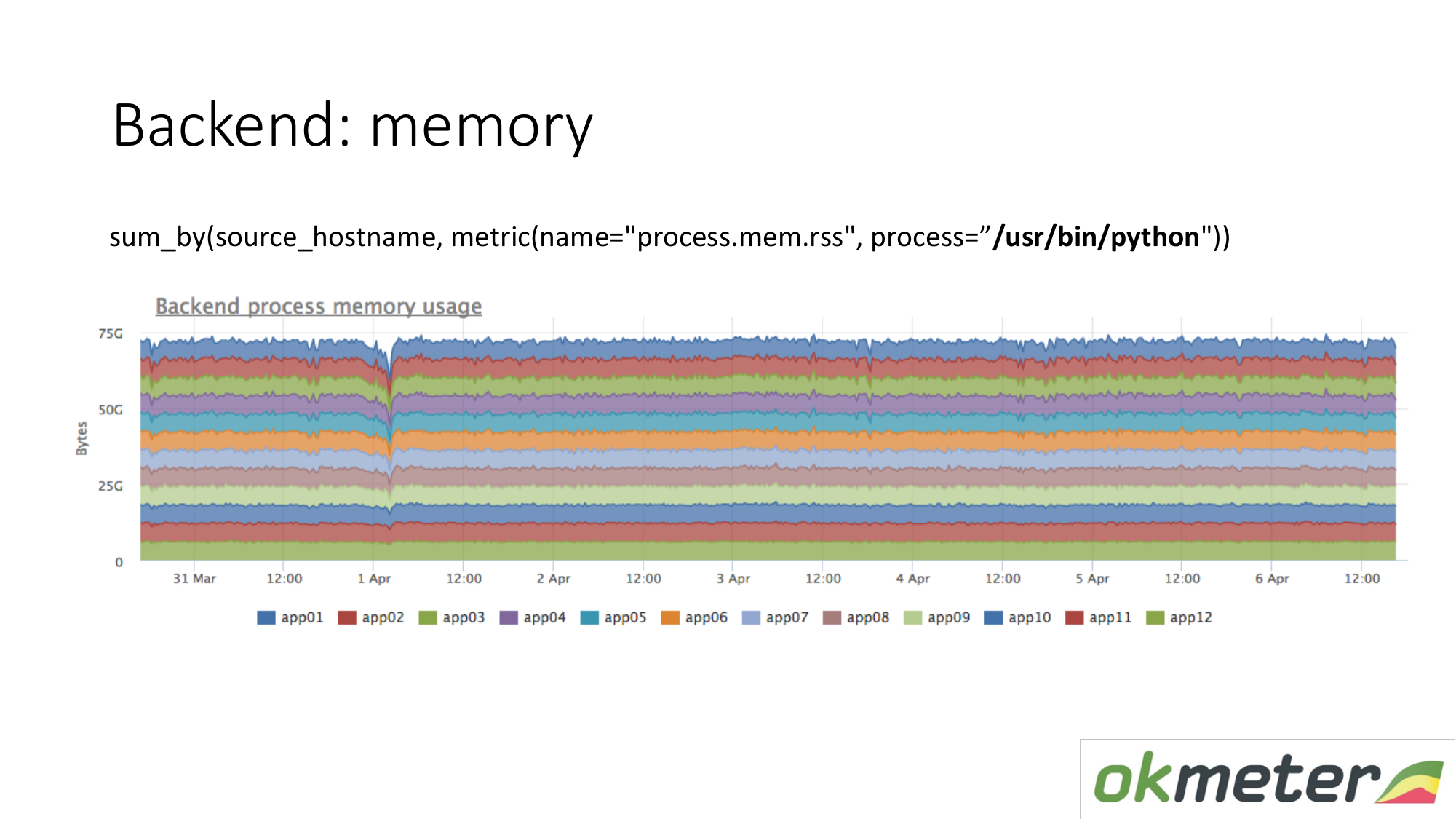
Gleiches gilt für die Erinnerung. Wenn wir es so zeichnen. Wir wählen Python RSS (RSS ist die Größe der Speicherseiten, die dem Prozess vom Betriebssystem zugewiesen wurden und sich derzeit im RAM befinden). Summe nach Host. Wir schauen nirgendwo hin, wo Erinnerungen fließen. Überall ist der Speicher gleichmäßig verteilt. Grundsätzlich haben wir eine Antwort auf unsere Fragen erhalten.
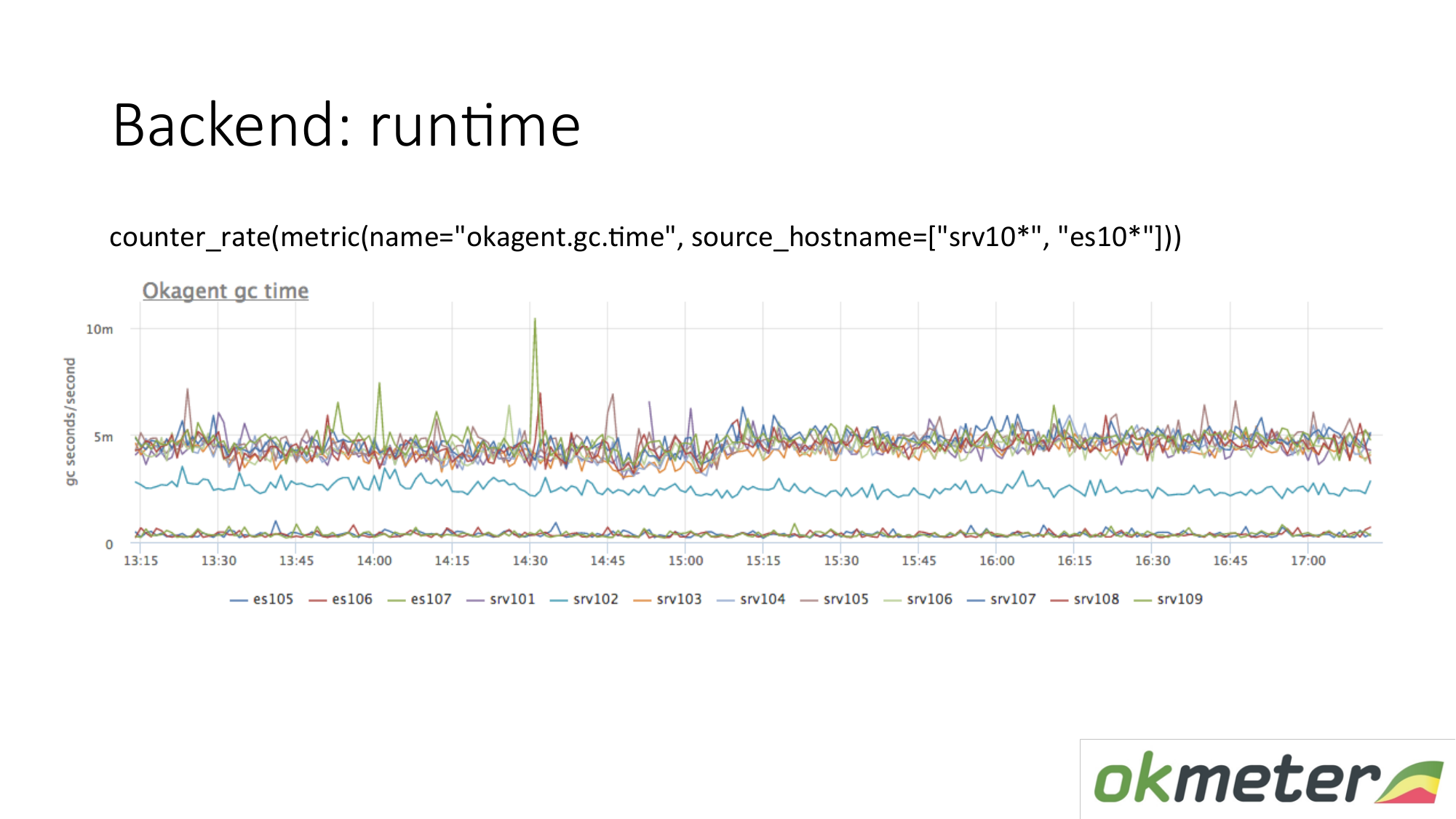
Laufzeitbeispiel. Unser Agent ist in Golang geschrieben. Der Golang-Agent sendet sich Metriken seiner Laufzeit. Dies ist insbesondere die Anzahl der Sekunden, die der Golang-Garbage Collector pro Sekunde für die Garbage Collection benötigt. Wir sehen hier, dass einige Server andere Metriken haben als andere Server. Wir haben eine Anomalie gesehen. Wir versuchen dies zu erklären.
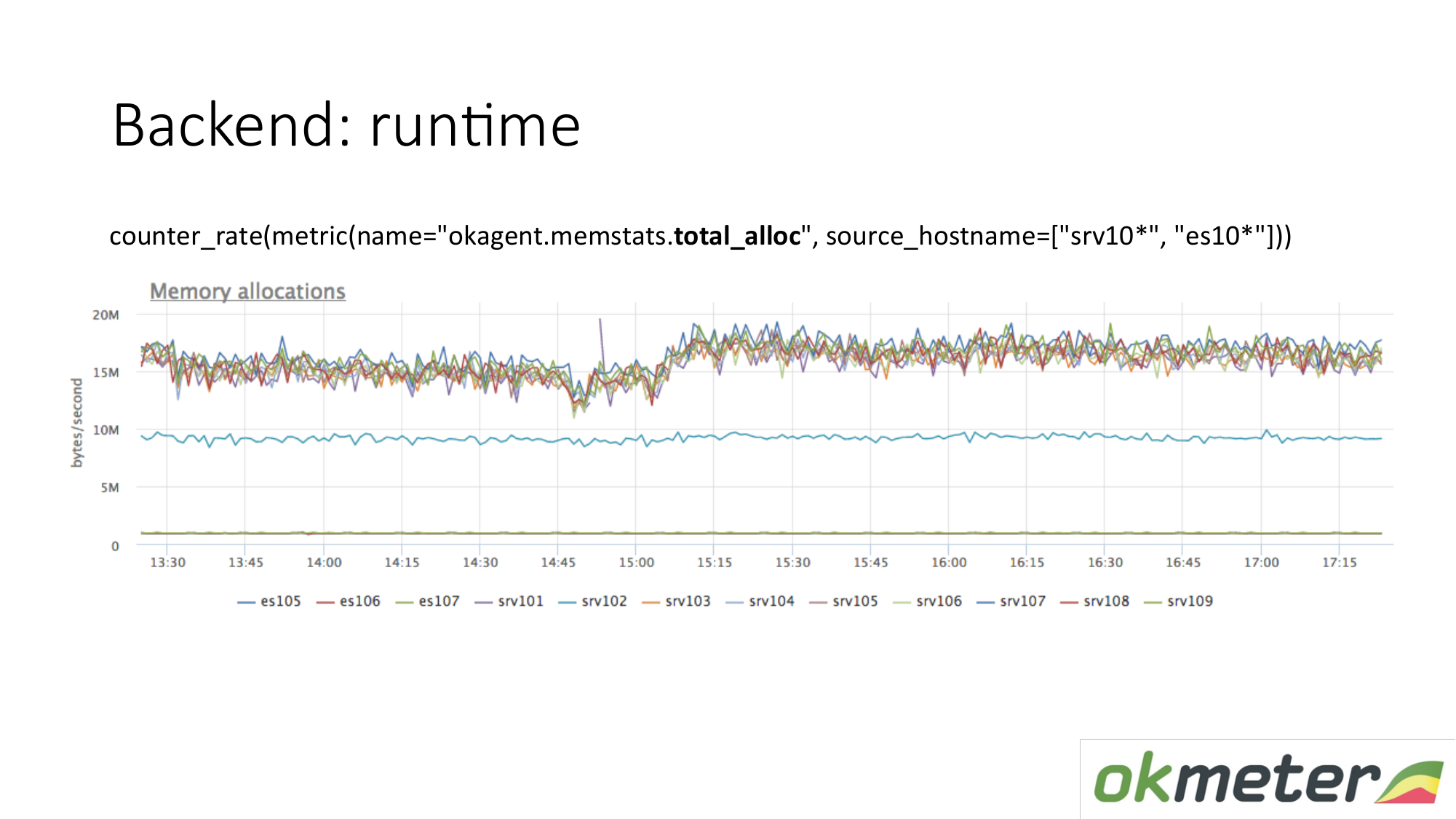
Es gibt eine andere Laufzeitmetrik. Wie viel Speicher wird pro Zeiteinheit zugewiesen? Wir sehen, dass Agenten mit einem Typ, der oben steht, mehr Speicher zuweisen als Agenten, die niedriger sind. Unten finden Sie Agenten mit einem weniger aggressiven Garbage Collector. Das ist logisch. Je mehr Speicher durch Sie geleitet und freigegeben wird, desto größer ist die Belastung des Garbage Collector. Gemäß unseren internen Metriken verstehen wir außerdem, warum wir auf diesen Computern so viel Speicher und auf diesen Computern weniger Speicher benötigen.
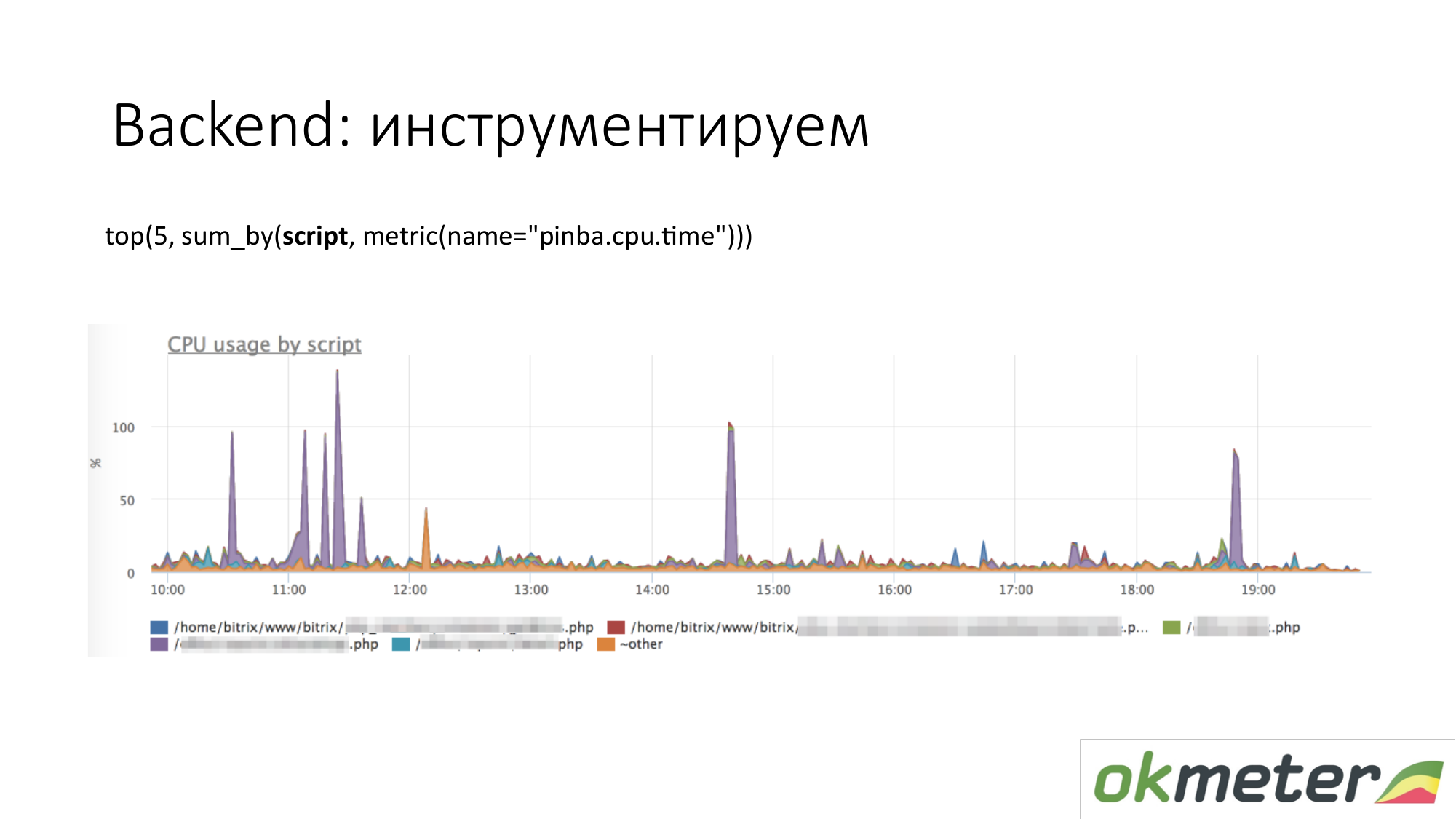
Wenn wir über Instrumentierung sprechen, kommen alle Arten von Tools wie http://pinba.org/ für PHP. Pinba ist eine Erweiterung für PHP von Badoo, die Sie installieren und mit PHP verbinden. Sie können Protobuf sofort über UDP entfernen und senden. Sie haben einen Pinba-Server. Wir haben jedoch einen eingebetteten Pinba-Server im Agenten erstellt. PHP sendet sich selbst, wie viel CPU und Speicher für solche Skripte ausgegeben wurden, wie viel Verkehr von solchen Skripten bereitgestellt wird und so weiter. Hier ist ein Beispiel mit Pinba. Wir zeigen die Top 5 Skripte zum CPU-Verbrauch. Wir sehen einen violetten Ausreißer, der ein verschmierter Punkt von PHP ist. Wir werden den verschmierten Punkt von PHP reparieren oder verstehen, warum es die CPU auffrisst. Wir haben den Umfang des Problems bereits eingegrenzt, damit wir die folgenden Schritte verstehen. Wir schauen uns den Code an und reparieren ihn.

Gleiches gilt für den Verkehr. Wir schauen uns die Top 5 Verkehrsskripte an. Wenn uns das wichtig ist, dann gehen wir und verstehen.

Dies ist eine Tabelle über unsere internen Tools. Wenn wir den Timer durch statsd stellen und die Metriken messen. Wir haben es so gestaltet, dass die Gesamtzeit, die in der CPU oder in Erwartung einer Ressource verbracht wird, entsprechend dem Handler, den wir gerade verarbeiten, und gemäß den wichtigen Phasen Ihres Codes festgelegt wird: Sie haben auf den Kassander gewartet, auf die Elasticsearch gewartet. Das Diagramm zeigt die fünf wichtigsten Stufen für den Handler / metric / query. In der Grafik können Sie die Top 5 Handler für den CPU-Verbrauch anzeigen, also was im Inneren passiert. Es ist klar, was zu beheben ist.
Über das Backend können Sie tiefer gehen. Es gibt Dinge, die nachverfolgen. Das heißt, Sie können diese bestimmte Benutzeranforderung mit einem solchen oder einem solchen Cookie sehen, und IP hat so viele Anforderungen an die Datenbank generiert, dass sie so lange gewartet haben. Wir können nicht zurückverfolgen. Wir verfolgen nicht. Wir können immer noch glauben, dass wir keine Anwendungen und Leistungsüberwachung durchführen.

Über die Datenbank. Das selbe. Datenbanken sind der gleiche Prozess. Er verbraucht Ressourcen. Wenn die Basis sehr latenzempfindlich ist, gibt es leicht unterschiedliche Funktionen. Wir empfehlen zu überprüfen, ob nicht weniger Ressourcen und keine Verschlechterung der Ressourcen vorhanden sind. Es ist ideal zu verstehen, dass Sie verstehen, was sich genau in Ihrem Code geändert hat, wenn die Basis mehr zu verbrauchen begann als verbraucht.
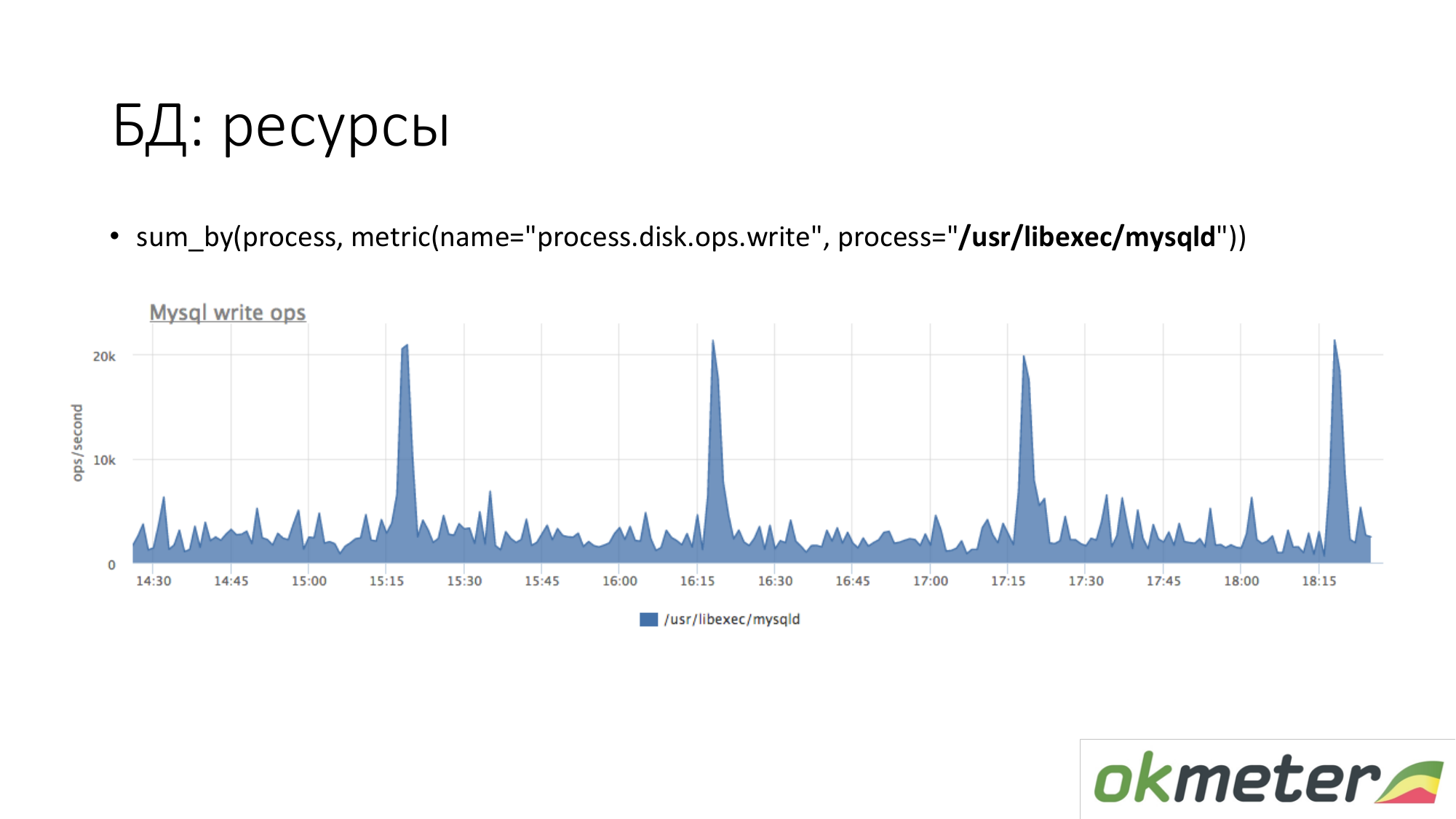
Über die Ressourcen. Auf die gleiche Weise untersuchen wir, wie viel der MySQL-Prozess auf unserer Festplatte generiert. Wir sehen, dass es im Durchschnitt so viel gibt, aber einige Spitzen passieren. Zum Beispiel kommt viel Insert herein und es beginnt um 15.15, 16.15, 17.15 Uhr mit dem Schreiben auf die Festplatte.
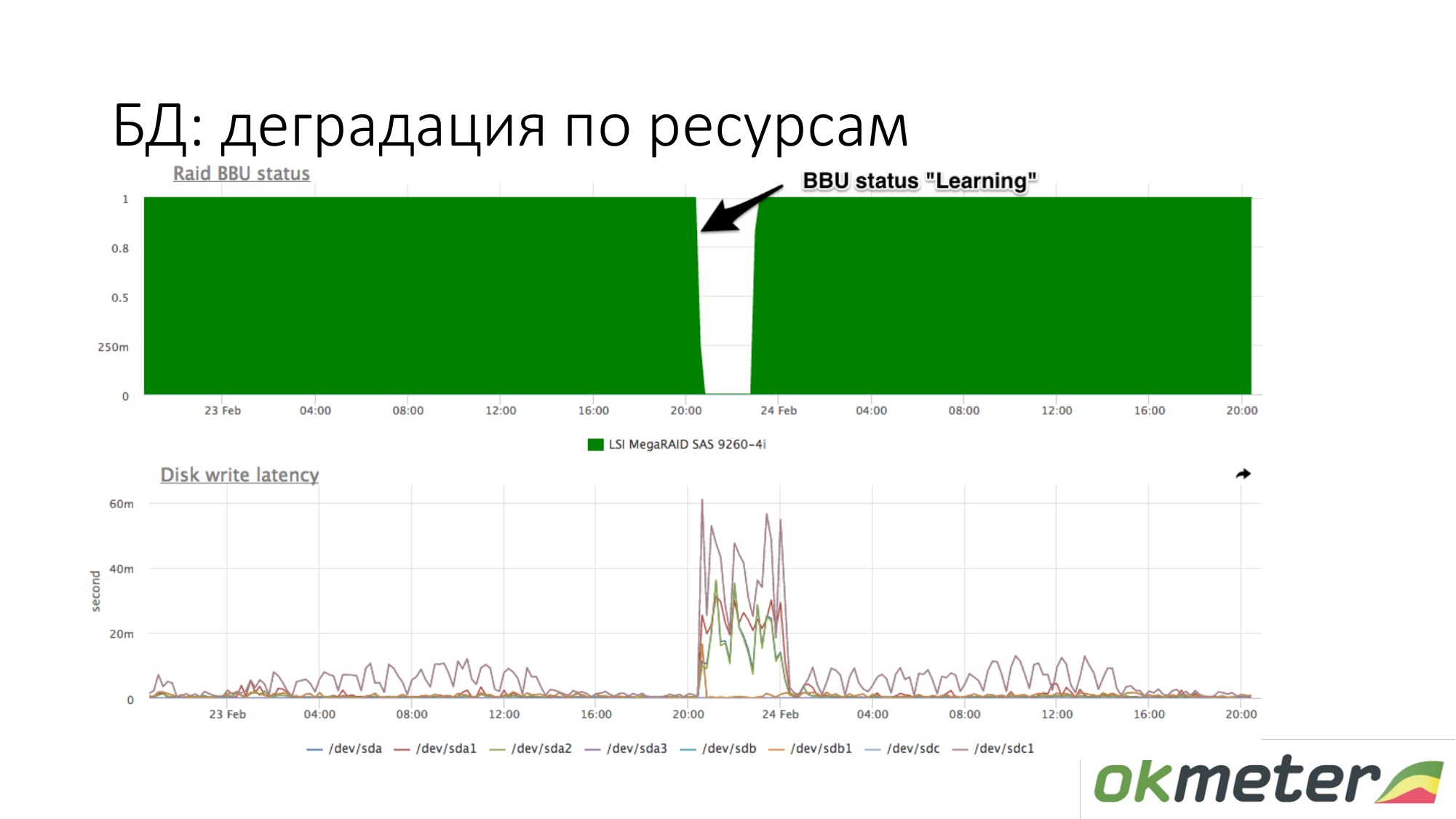
Über die Verschlechterung der Ressourcen. Beispielsweise wurde ein RAID-Akku in den Wartungsmodus versetzt. Sie hörte auf, ein Controller wie eine lebende Batterie zu sein. Zu diesem Zeitpunkt wird der Schreibcache getrennt, und die Latenz der Schreibplatten nimmt zu. Wenn zu diesem Zeitpunkt die Datenbank beim Warten auf eine Festplatte langweilig wird und Sie ungefähr wissen, dass Sie beim Schreiben auf eine Festplatte eine andere Latenz hatten, überprüfen Sie den Akku in RAID.

Ressourcen auf Abruf. Hier ist es nicht so einfach. Kommt auf die Basis an. Die Basis sollte in der Lage sein, über sich selbst zu sagen: Welche Anforderungen werden an Ressourcen usw. gestellt? Der Marktführer dabei ist PostgreSQL. Er hat pg_stat_statements. Sie können verstehen, welche Art von Anforderung Sie mit viel CPU, Lese- und Schreibfestplatte und Datenverkehr haben.
In MySQL ist ehrlich gesagt alles viel schlimmer. Es hat Leistungsschema. Es funktioniert irgendwie ab Version 5.7. Im Gegensatz zu einer einzelnen Ansicht in PostgreSQL ist performance_schema eine 27- oder 23-Systemansichtstabelle in MySQL. Wenn Sie Abfragen an den falschen Tabellen (in der falschen Ansicht) durchführen, können Sie manchmal MySQL verschwenden.
Redis hat Teamstatistiken. Sie sehen, dass ein bestimmter Befehl viel CPU usw. verbraucht.
Cassandra hat Zeiten, um bestimmte Tabellen abzufragen. Da die Cassandra jedoch so konzipiert ist, dass eine Art von Abfrage an die Tabelle gesendet wird, reicht dies für die Überwachung aus.
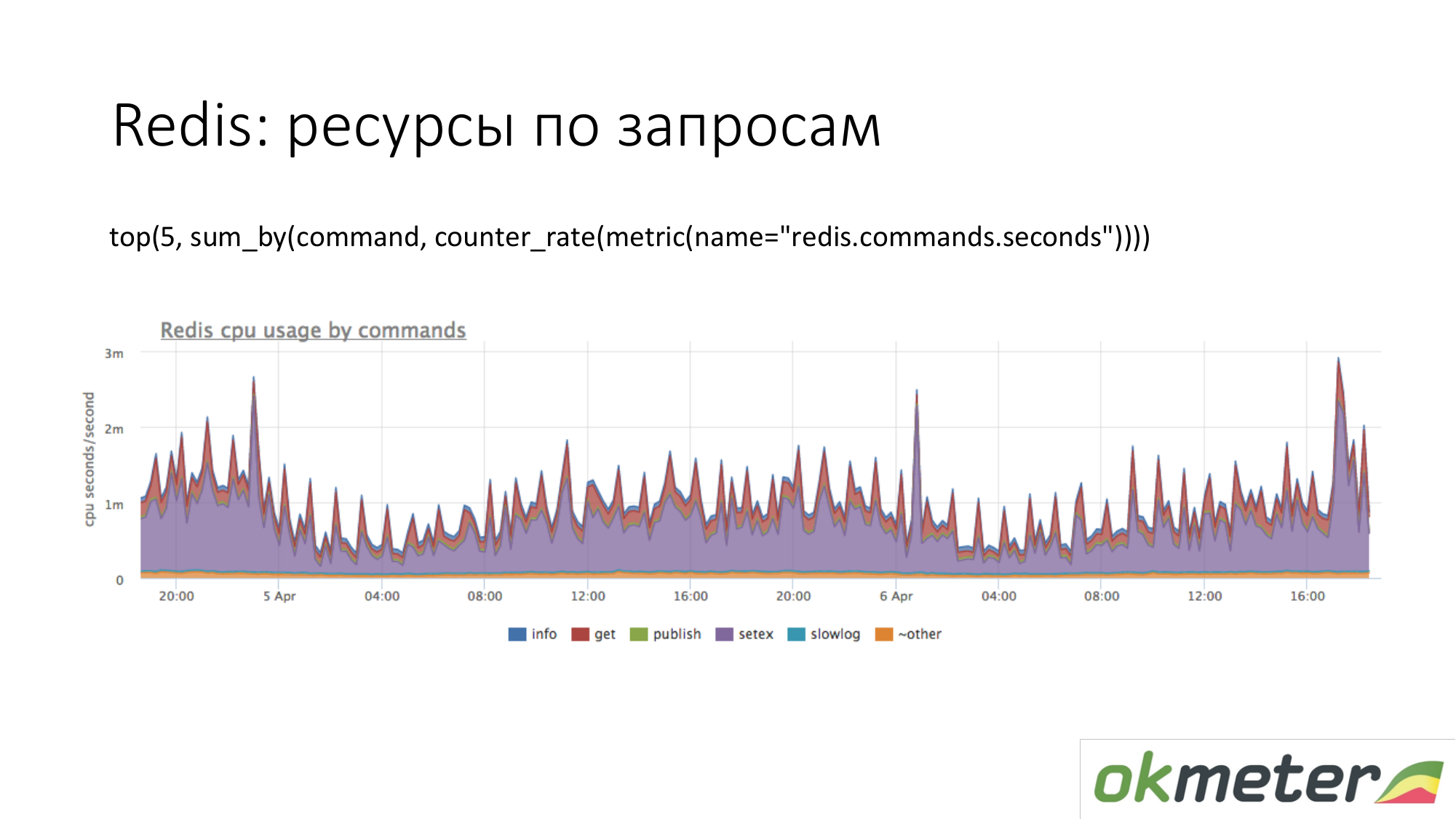
Das ist Redis. Wir sehen, dass lila viel CPU verbraucht. Violett ist ein Setex. Setex - Schlüsseldatensatz mit TTL-Installation. Wenn uns das wichtig ist, lassen Sie uns damit umgehen. Wenn dies für uns nicht wichtig ist, wissen wir nur, wohin alle Ressourcen gehen.
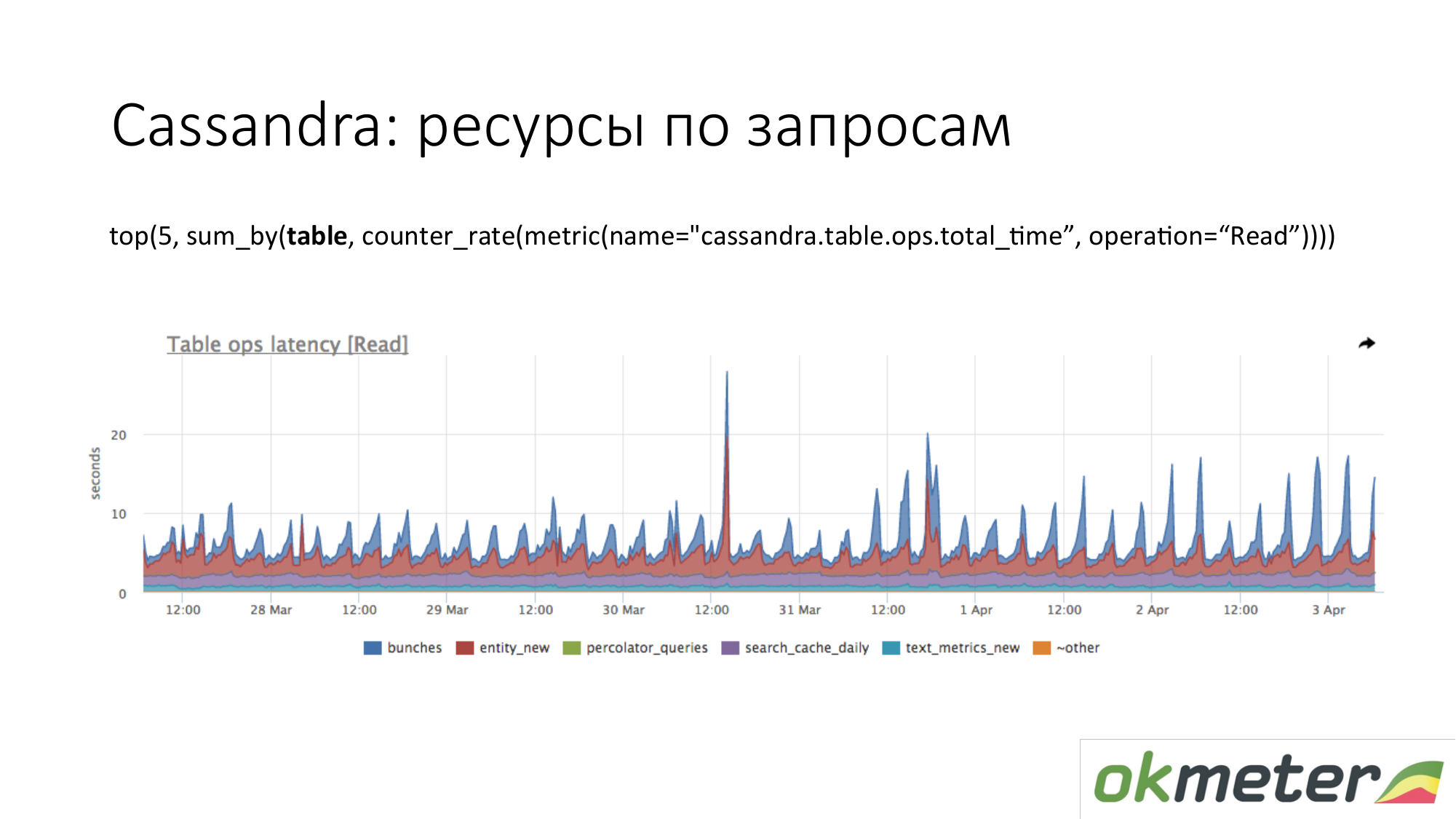
Cassandra. Wir sehen die Top 5 Tabellen für Leseanforderungen nach der Gesamtantwortzeit. Wir sehen diesen Anstieg. Dies sind Abfragen an die Tabelle, und wir verstehen ungefähr, dass eine Abfrage an diese Tabelle einen Code ergibt. Cassandra ist keine SQL-Datenbank, in die wir verschiedene Abfragen für Tabellen durchführen können. Cassandra wird immer elender.

Ein paar Worte zum Workflow arbeiten mit Vorfällen. Wie ich es sehe.
Über Alarm. Unsere Sicht auf den Vorfall-Workflow unterscheidet sich von der allgemein akzeptierten.

Sehr kritisch. Wir benachrichtigen Sie per SMS und über alle Echtzeit-Kommunikationskanäle.
Severy Info ist eine Glühbirne, die Ihnen bei der Arbeit mit Vorfällen helfen kann. Info wird nirgendwo benachrichtigt. Info hängt nur und sagt Ihnen, dass etwas passiert.
Schwere Warnung ist etwas, das benachrichtigt werden kann, vielleicht auch nicht.

Kritische Beispiele.
Die Seite funktioniert überhaupt nicht. Zum Beispiel 5xx 100% oder die Antwortzeit hat sich erhöht und Benutzer haben begonnen zu gehen.
Geschäftslogikfehler. Was ist kritisch. Es ist notwendig, Geld pro Sekunde zu messen. Geld pro Sekunde ist eine gute Datenquelle für Critical. Zum Beispiel die Anzahl der Bestellungen, die Werbung für Anzeigen und andere.

Workflow mit Critical, sodass dieser Vorfall nicht verschoben werden kann. Sie können nicht auf OK klicken und nach Hause gehen. Wenn Critical zu Ihnen gekommen ist und Sie mit der U-Bahn fahren, müssen Sie aus der U-Bahn aussteigen, nach draußen gehen, eine Bank nehmen und mit der Reparatur beginnen. Ansonsten ist es nicht kritisch. Aus diesen Überlegungen konstruieren wir den verbleibenden Schweregrad für das Restattribut.

Warnung. Warnbeispiele.
- Der Speicherplatz ist knapp.
- Der interne Dienst funktioniert lange, aber wenn Sie nicht über Kritisch verfügen, bedeutet dies, dass Sie trotzdem bedingt sind.
- Viele Fehler auf der Netzwerkschnittstelle.
- Am umstrittensten ist, dass der Server nicht verfügbar ist. Wenn Sie mehr als einen Server haben und der Server nicht verfügbar ist, ist dies eine Warnung. Wenn Sie nicht 1 Backend von 100 haben, ist es dumm, von SMS aufzuwachen, und Sie werden nervöse Administratoren bekommen.
Alle anderen Severy sollen Ihnen helfen, mit Critical umzugehen.

Warnung. Wir befürworten diesen Ansatz für die Arbeit mit Warning. Vorzugsweise Warnung tagsüber schließen. Die meisten unserer Kunden haben die Warnmeldung deaktiviert. Sie haben also nicht die sogenannte Überwachungsblindheit. Dies bedeutet, dass Briefe in der Mail gefaltet werden, ohne ein separates Verzeichnis zu lesen. Clients haben die Warnmeldung deaktiviert.
(Soweit ich weiß, ist reine Überwachung unnötige Warnungen und Auslöser, die Ausnahmen hinzugefügt werden - Hinweis des Autors des Beitrags)
Wenn Sie die reine Überwachungstechnik verwenden und 5 neue Warnungen haben, können Sie diese in einem leisen Modus reparieren. Sie hatten heute keine Zeit, das Problem zu beheben, aber sie haben es auf morgen verschoben, wenn auch nicht kritisch. Wenn die Warnung aufleuchtet und sich selbst löscht, muss dies bei der Überwachung verdreht werden, damit Sie sich erneut nicht darum kümmern. Dann werden Sie toleranter gegenüber ihnen sein und dementsprechend wird sich das Leben verbessern.

Beispiele für Informationen. Es ist fraglich, dass die hohe CPU-Auslastung vieler kritisch ist. Wenn nichts davon betroffen ist, können Sie diese Benachrichtigung ignorieren.

Warnung (vielleicht sehe ich Info - eine Notiz des Autors des Beitrags) Dies sind die Lichter, die leuchten, wenn Sie kommen, um das Kritische zu reparieren. Sie sehen zwei Warnschilder nebeneinander (möglicherweise gibt es einen Info-Link - Hinweis des Autors des Beitrags). Sie können Ihnen bei der Lösung des Vorfalls mit Critical helfen. Warum ist die hohe CPU-Auslastung nicht separat in SMS oder in einem Brief klar.
Sinnlose Informationen sind auch schlecht. Wenn Sie sie als Ausnahme konfigurieren, werden Sie Info zu sehr lieben.

Allgemeine Grundsätze für das Alarmdesign. Warnung sollte den Grund zeigen. Das ist perfekt. Dies ist jedoch schwer zu erreichen. Hier arbeiten wir Vollzeit an der Aufgabe und es stellt sich heraus, dass sie teilweise erfolgreich ist.
Alle reden über die Notwendigkeit von Sucht, Auto-Magie. Wenn Sie keine Benachrichtigungen für etwas erhalten, an dem Sie nicht interessiert sind, wird es nicht zu viel geben. In meiner Praxis zeigen Statistiken, dass eine Person im Moment eines kritischen Vorfalls mit ihren Augen etwa hundert Glühbirnen diagonal betrachtet. Er wird dort den richtigen finden und wird nicht glauben, dass die Abhängigkeit irgendwelche Glühbirnen verborgen hat, die mir jetzt helfen würden. In der Praxis funktioniert dies. Sie müssen lediglich unnötige Warnungen bereinigen.

(Hier wurde das Video übersprungen - Anmerkung des Autors des Beitrags)

Es wäre schön, diese Ausfallzeiten zu klassifizieren, damit Sie später damit arbeiten können. Ziehen Sie beispielsweise organisatorische Schlussfolgerungen. Sie müssen verstehen, warum Sie gelogen haben. Wir schlagen vor, in folgende Klassen zu klassifizieren / zu unterteilen:
- von Menschen gemacht
- Hoster eingerichtet
- kamen Bots
Wenn Sie sie klassifizieren, werden alle glücklich sein.

SMS ist angekommen. Was machen wir Zuerst laufen wir, um alles zu reparieren. Bisher ist uns nichts wichtig, außer dass die Ausfallzeit endet. Weil wir motiviert sind, weniger zu lügen. Wenn der Vorfall geschlossen ist, sollte er für das Überwachungssystem geschlossen werden. Wir glauben, dass der Vorfall durch Überwachung überprüft werden sollte. Wenn Ihre Überwachung nicht konfiguriert ist, reicht es aus, um sicherzustellen, dass das Problem behoben ist. Dies muss verdreht werden. Nachdem der Vorfall geschlossen wurde, wird er nicht wirklich geschlossen. Er wartet, während Sie dem Grund auf den Grund gehen. Tatsächlich muss jeder Führer in erster Linie sicherstellen, dass die Probleme nicht erneut auftreten. Damit die Probleme nicht erneut auftreten, müssen Sie dem Grund auf den Grund gehen. Nachdem wir dem Grund auf den Grund gegangen sind, haben wir Daten, um sie zu klassifizieren. Wir analysieren die Gründe. Wenn wir dann dem Grund auf den Grund gehen, müssen wir dies in Zukunft tun, damit der Vorfall nicht erneut auftritt:
- Es braucht zwei Leute pro Viertel, um diese und jene Logik in das Backend zu schreiben.
- müssen mehr Repliken setzen.
Es muss sichergestellt werden, dass nicht genau derselbe Vorfall passiert. Wenn Sie in einem solchen Workflow durch N Iterationen arbeiten, erwartet Sie Glück, gute Betriebszeit.
Warum haben wir sie klassifiziert? Wir können die Statistiken für das Quartal verwenden und verstehen, welche Ausfallzeiten Sie am meisten verursacht haben. Dann arbeiten Sie in diese Richtung. Sie können an allen Fronten arbeiten, was nicht sehr effektiv ist, besonders wenn Sie dort nur wenige Ressourcen haben.

Wir haben dort berechnet, dass wir so viel Zeit liegen, zum Beispiel 90% wegen des Hosters. Wir berechnen, dass wir diesen Hoster wechseln. Wenn sich Leute mit uns anlegen, schicken wir sie zu Kursen. , - — . . , . , .

. :
, , . , , .

: , . : , , . False Positive ( ), , . ?
: . 10- frontend , . 9 frontend nginx, 10- , warning alert . . , . . .
: . , , load avarage 4 , - load avarage 20 .
: load avarage. 100 . CPU usage Hadoop . . . . , , . PostgreSQL autovacuum, worker autovacuum . 99 . Warning . Critical . Critical 10 5 , Critical.
Frage: Wann und wie wird der Schwellenwert ermittelt? Wer macht das?
Antwort: Sie kommen zu uns und sagen: Wir möchten einige Kritiker unseres Projekts fragen. Wenn Sie jetzt 10 5xx pro Sekunde eingeben, wie viele Benachrichtigungen würden Sie vor einer Woche erhalten?
Frage: Was ist die Last all dieser guten Überwachung?
Antwort: Im Durchschnitt ist es im Allgemeinen unsichtbar. Wenn Sie jedoch 50.000 RPS analysieren, sind es 1% bis 10% einer CPU. Da wir nur überwachen, haben wir unseren Agenten optimiert. Wir messen die Leistung der Agenten. Wenn Sie nicht über die Ressourcen verfügen, um auf dem Server zu überwachen, machen Sie etwas falsch. Es sollten immer Ressourcen zur Überwachung vorhanden sein. Wenn Sie dies nicht tun, sind Sie für die Verwaltung Ihres Projekts genauso blind.