Die Topologie moderner Rechenzentren und Geräte in ihnen ermöglicht es uns nicht mehr, uns ausschließlich mit der
Whitebox-Überwachung zu begnügen. Im Laufe der Zeit brauchte ich ein Tool, das die Leistung bestimmter Geräte basierend auf der tatsächlichen Situation bei der Übertragung von Datenverkehr (Datenebene) an eine beliebige Stelle im
Clos-Netzwerk anzeigt. Vor einigen Wochen teilte der Yandex-Netzwerkingenieur Alexander Klimenko auf der
Next Hop- Konferenz seine Erfahrungen bei der Lösung dieses Problems mit.
- Ich arbeite in der Betriebs- und Entwicklungsabteilung des Yandex-Netzwerks und manchmal zwingen sie mich, einige Probleme zu lösen, anstatt schöne Wolken auf Flugblätter zu zeichnen oder eine glänzende Zukunft zu erfinden. Die Leute kommen und sagen, dass etwas für sie nicht funktioniert. Wenn diese Angelegenheit überwacht wird und unsere diensthabenden Ingenieure feststellen, dass sie nicht funktioniert, ist es für mich selbst einfacher. Diese halbe Stunde wird also der Überwachung gewidmet sein.

Früher oder später kommt jeder auf die Idee der Überwachung. Das heißt, zuerst können Sie Appelle der Benutzer selbst sammeln, sie werden auf Sie klopfen und sagen, dass etwas für sie nicht funktioniert. Es ist jedoch klar, dass ein solches System nicht gut skaliert. Wenn Sie mehr als einen Switch haben, wenn Sie ein ausreichend großes Netzwerk haben, können Sie mit dieser Überwachungsoption nicht weit kommen.
Und früher oder später kommen alle zu dem Schluss, dass es notwendig ist, einige Daten von den Geräten zu sammeln. Dies ist der allererste Schritt. Es können Protokolle, verschiedene Daten zu SNMP, Drops, Sie können Topologien gemäß LLDP erstellen usw. sein. Es gibt ein klares Minus - das Gerät selbst stellt Ihnen all diese Informationen zur Verfügung. Es darf nichts sagen, dich täuschen usw.
Die logische Phase bei der Entwicklung Ihrer Überwachung ist die Überwachung auf Hosts. Wir können sagen, dass es einen kleinen Zweig gibt. Wenn Sie das Glück haben oder nicht, ein Netzwerk bei einem Anbieter zu haben, kann der Anbieter Ihnen einige Ihrer eigenen Überwachungsoptionen anbieten. Aber letztes Jahr bei Next Hop
sagte Dima Ershov
, dass unsere Fabrik von zwei einfachen Anbietern gegründet wurde und wir uns einen solchen Luxus nicht leisten können. Oder wir können, aber nur teilweise.
Endlich die letzte Option, die jeder irgendwie mit der Entwicklung des Netzwerks erreicht. Dies ist die Überwachung auf Endhosts. Yandex hat eine solche Überwachung. Es heißt Netmon.

Am Ende der Folie
befindet sich ein Link mit einer detaillierten Darstellung der Funktionsweise von Netmon. Ich werde es buchstäblich auf einer Folie erzählen. Wenn jemand möchte, lesen Sie bitte den Vortrag von einer anderen Netmon-Konferenz.
Netmon sind Agenten, die auf fast jedem Host im Netzwerk installiert sind. Die Aufgabe kommt bei den Agenten an: einige Pakete an einen Netzwerkknoten zu senden. Sie können völlig unterschiedlich sein: UDP, TCP, ICMP. Es können verschiedene Farben sein, dh DSCP und Bestimmungsort. Quell- und Zielports können ebenfalls unterschiedlich sein.
Diese Daten werden aggregiert, in einen separaten Speicher hochgeladen, und wir erhalten hier ein Segment wie das rechts in der Abbildung. Ein Slice kann mehr oder weniger aggregiert sein, je nachdem, was wir sehen möchten. Zum Beispiel haben wir hier, soweit ich sehe, einen Teil der gesamten Konnektivität von Rechenzentren, dh zwischen all unseren Rechenzentren. Wir können tiefer in die Quadrate hineinfallen - sehen Sie die Konnektivität zwischen dem POD oder innerhalb des Gebäudes eines Rechenzentrums; noch tiefer - im POD zwischen den Racks; und noch tiefer - sogar innerhalb des Racks.

Was könnte hier möglicherweise schief gehen? Ein kleiner Exkurs für diejenigen, die den Next Hop des letzten Jahres nicht gesehen haben.
Wir haben 400 Gigabit pro ToR verwendet und im ersten Moment der Implementierung dieser Fabrik nur 200 eingeschlossen, weil es wichtigere Aufgaben gab. Egal warum. Sie schalteten 200 ein, Dienste kamen und sagten: Warum 200? Wir wollen 400! Begann es einzuschalten. Und so kam es, dass der zweite Teil der Fabrik, den wir mit einbezogen hatten, eine Art Ehe im Gedächtnis der Karten hatte. Als Ergebnis schalten wir die Fabrik ein und sehen dieses Bild:

Dieses Netmon, die roten Quadrate, brennt. Wir verstehen, dass alles verloren ist. Wir greifen wie Homer nach unseren Köpfen und versuchen, etwas hektisch zu schieben. Und was zu drücken, was auszuschalten ist, verstehen wir nicht. Das heißt, Netmon zeigt uns das Vorhandensein eines Problems an, zeigt jedoch nicht an, wo sich das Problem tatsächlich im Netzwerk befindet.

Wir sind zu der Aufgabe gekommen, die wir erfüllen müssen. Was ist zu tun? Stellen Sie fest, bei welchem Gerät im Netzwerk ein Problem vorliegt, und nehmen Sie es außer Betrieb - entweder automatisch oder durch die Kräfte von beispielsweise Dienstingenieuren
Darüber hinaus sind die Anfangsbedingungen so, dass wir eine ziemlich regelmäßige Topologie haben, das heißt, es gibt keine merkwürdigen Verbindungen zwischen Spins der zweiten Ebene oder zwischen Tori. Wir haben den größten Teil des Datenverkehrs - TCP, es gibt einen zentralen Ort, der uns bereits mitgeteilt wurde, und die Server werden mehr oder weniger zentral verwaltet. Wir können an diesen zentralen Ort kommen und vernünftigerweise erklären: Leute, wir wollen das, bitte.
Welche Optionen haben wir in Betracht gezogen?

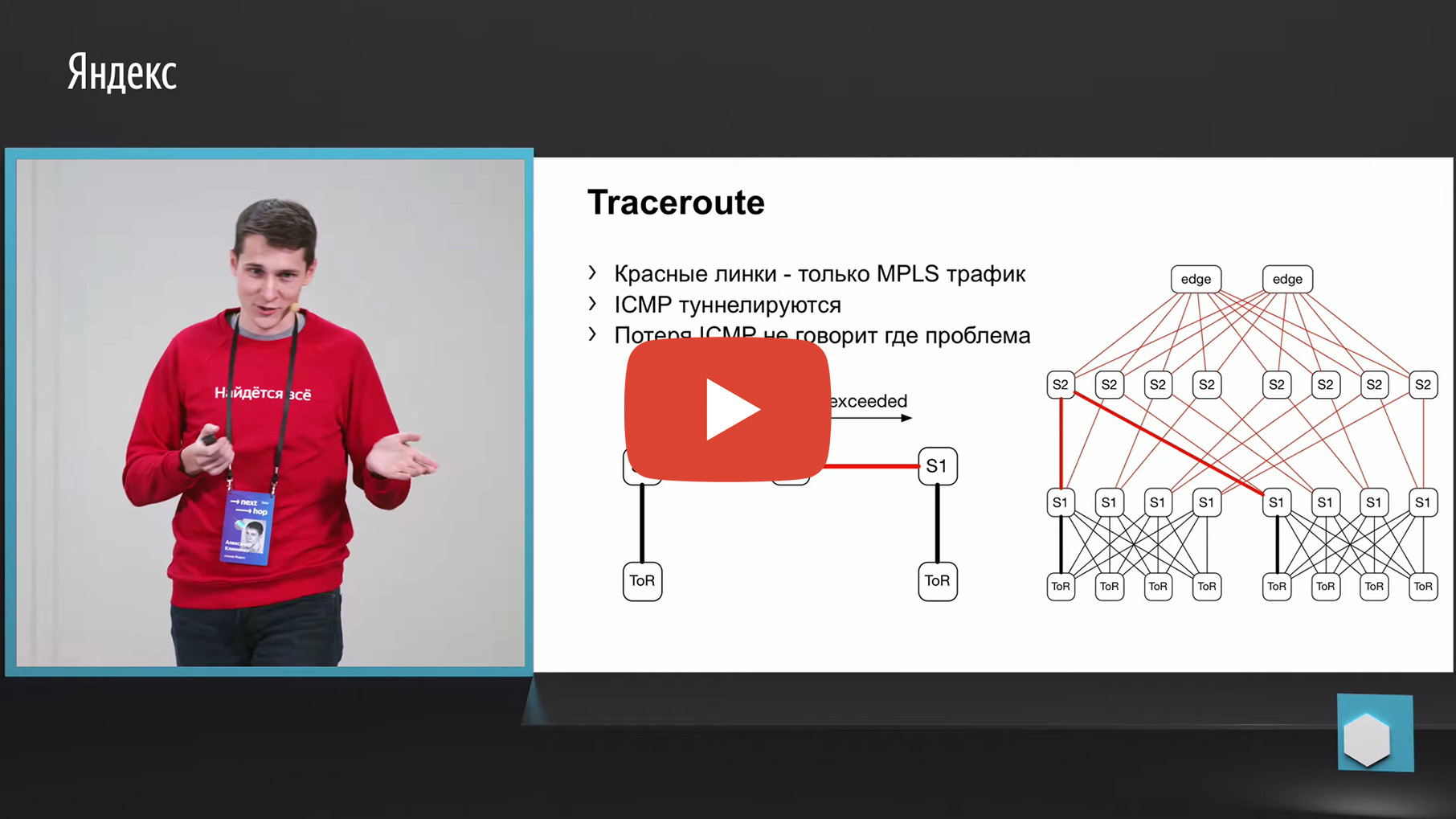
Das erste, was mir in den Sinn kommt, ist die Rückverfolgung. Warum? Da dasselbe Netmon die fehlgeschlagenen Quell- und Zielpaare in einen separaten Kollektor entlädt. Dementsprechend können wir dieses 5-Tupel nehmen, es betrachten und eine Spur mit denselben Parametern erstellen. Und um Daten darüber zu aggregieren, über welche Verbindung oder über welche Geräte die meisten Traces durchlaufen werden.
Leider wird MPLS in unserer Fabrik verwendet (jetzt bewegen wir uns in die entgegengesetzte Richtung wie MPLS, aber wir müssen auch die alten Fabriken irgendwie überwachen, aber sie nicht wegwerfen). Wir haben MPLS in der Fabrik, und das Problem mit MPLS und Ablaufverfolgung besteht darin, dass die TTL-überschrittene ICMP-Nachricht getunnelt werden muss, die der Ablaufverfolgung zugrunde liegt. Wenn wir eine solche Nachricht von Eingang zu Ausgang verloren haben, können wir die Überwachung verlieren. Das heißt, wir werden nicht verstehen, über welche Knoten diese Nachricht geleitet wurde. Dies war für die Überwachung nicht geeignet.
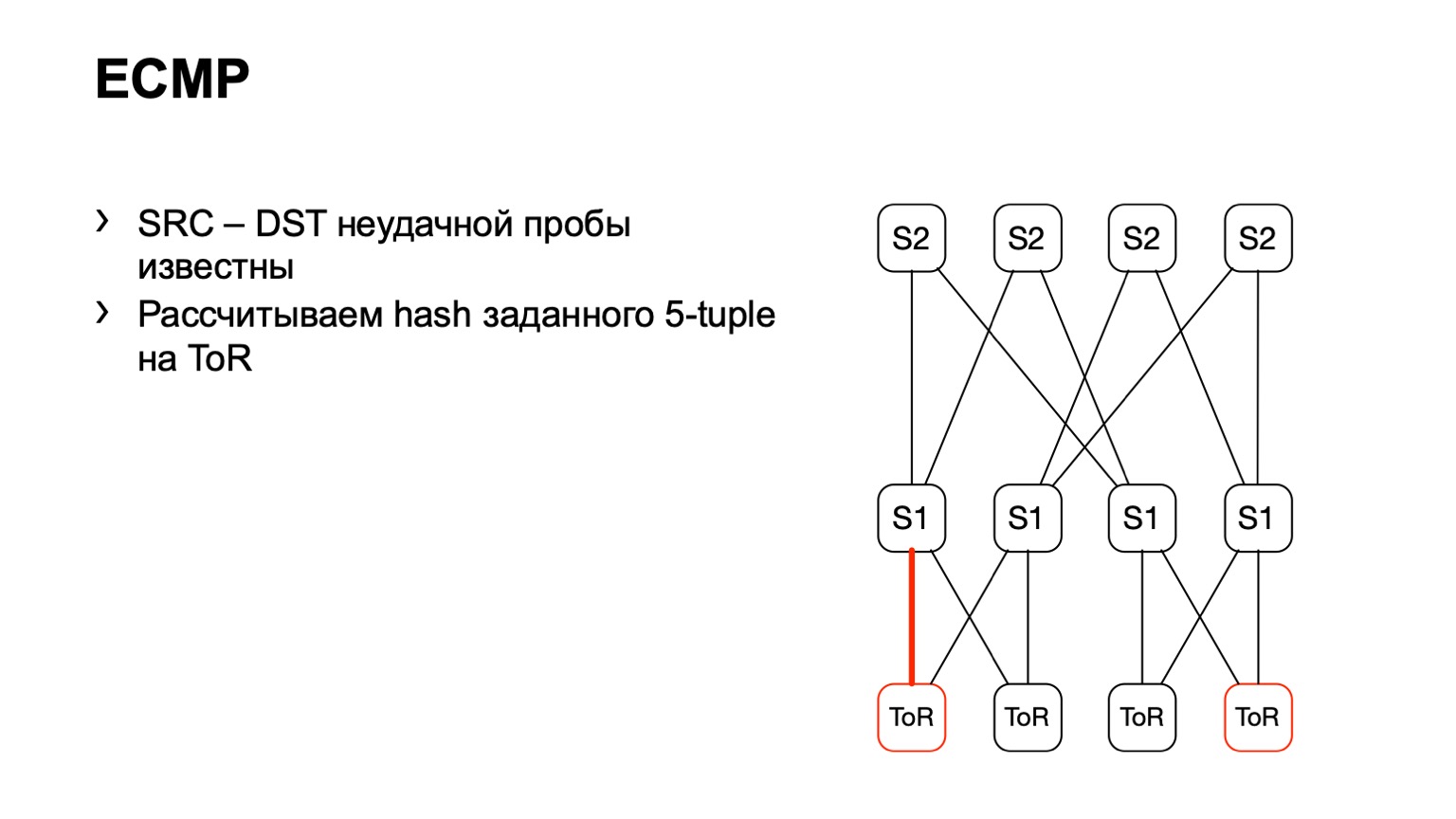
Es gibt eine zweite Option in Bezug auf ECMP. Wir nehmen das gleiche Quell- und Zielpaar, zusätzlich Quell-Port-Ziel-Port. Wir kommen zu einem Stück Eisen, über die API oder über die CLI geben wir dieses Stück Eisen dem Stück Eisen zu und erhalten die Ausgabeschnittstelle. Viele Geräte unterstützen diese Art der Ausgabe.
Wir kommen zu ToR und sehen, dass ToR einen linken oder rechten Link gewählt hat. In diesem Fall ist der linke Link in Richtung des linken S1.
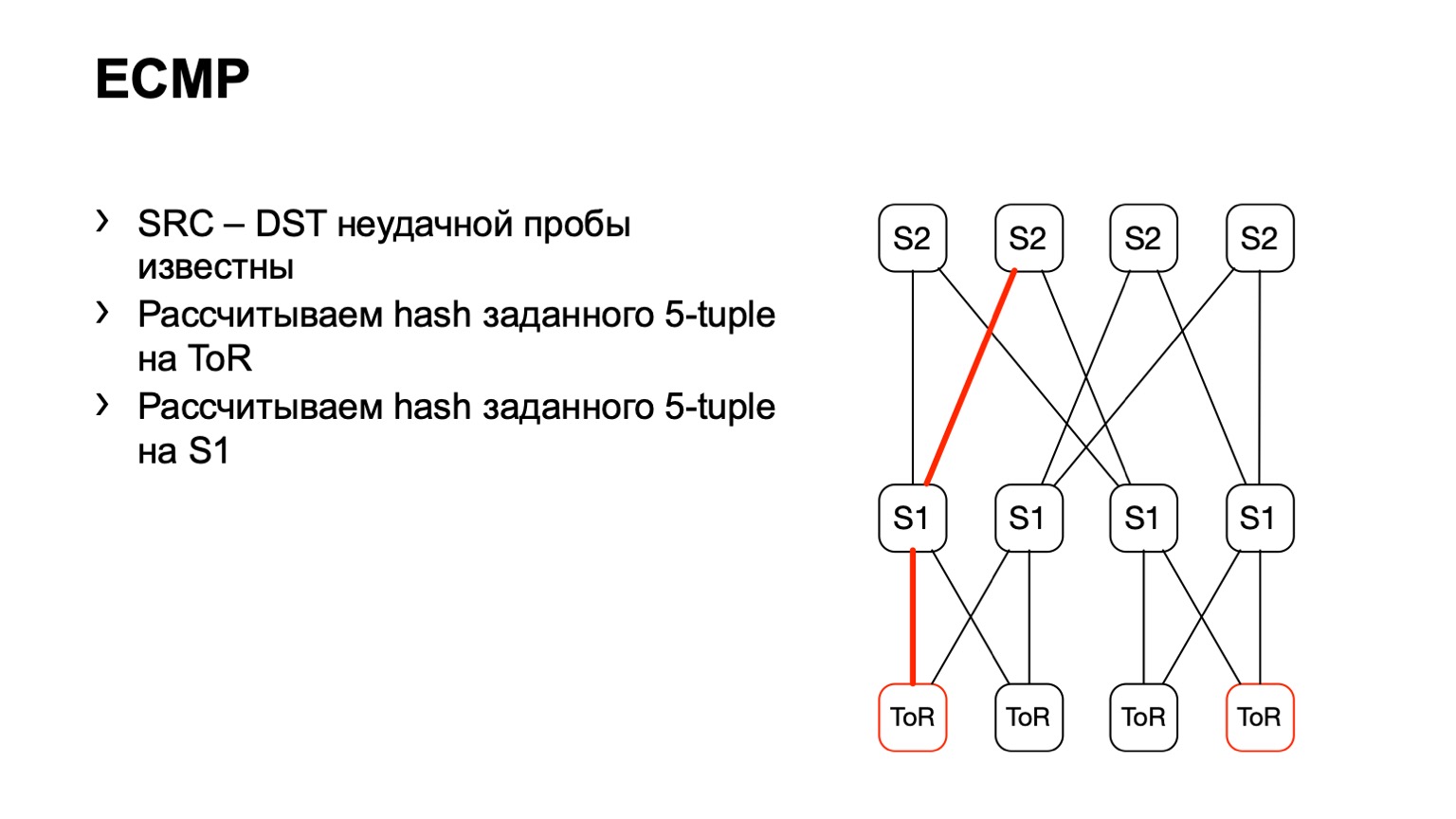
Wir kamen zu diesem S1, schauten nach rechts S2 und auf diese Weise bildete sich ein fertiger Pfad.
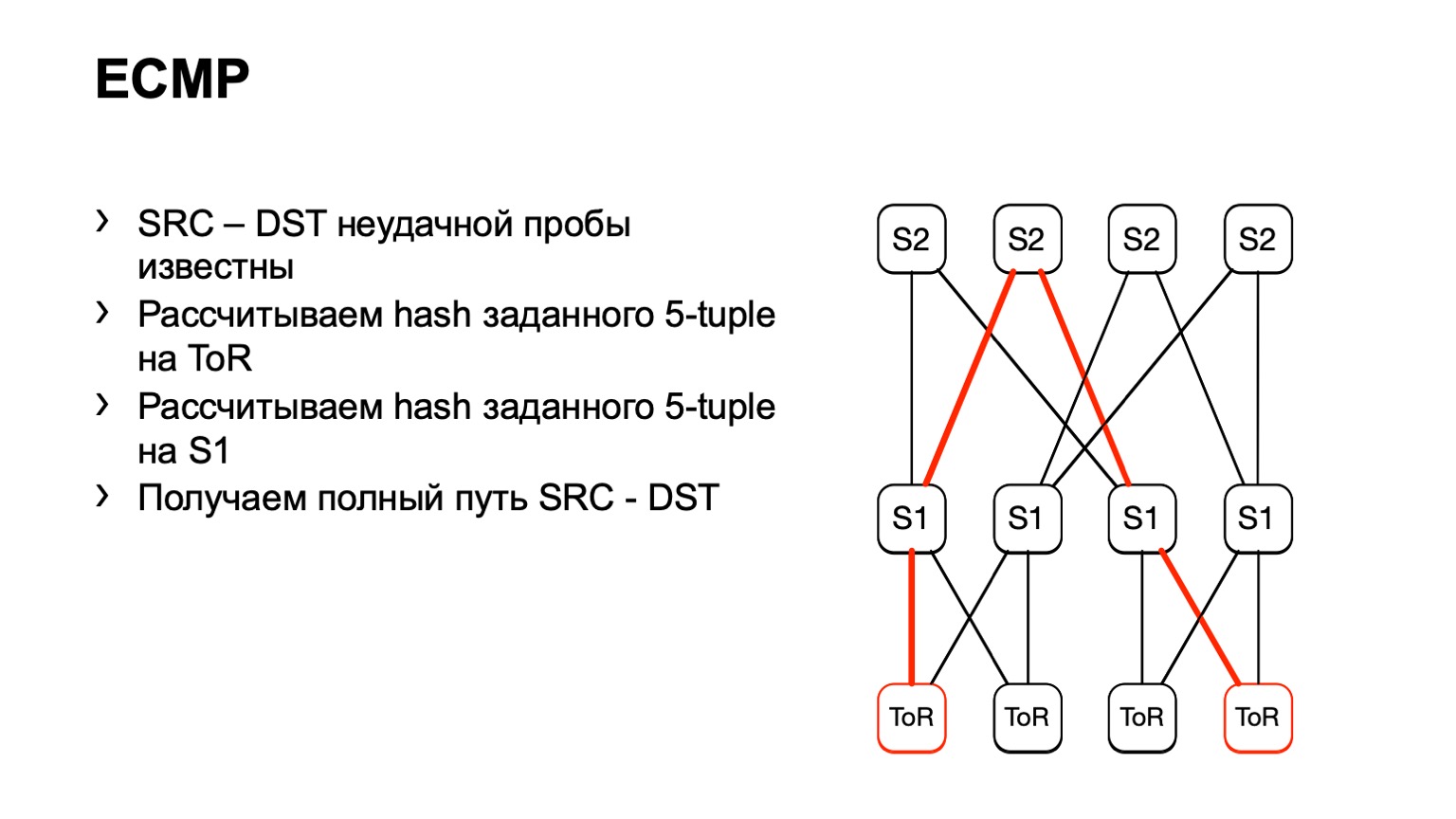
Es gibt einige Nachteile. Erstens können normalerweise nicht alle Geräte diese von uns angegebenen Eingabedaten akzeptieren. Dies liegt an der Tatsache, dass wir IPv6 und MPLS haben, sowie an der Tatsache, dass einige Anbieter dies einfach nicht implementiert haben. Das zweite Minus dieser Lösung: Wir verlassen uns darauf, was das Stück Eisen uns wieder sagt, anstatt zu sehen, was auf den Hosts passiert. Und schließlich das dritte Minus: Während Sie sehen, was dort passiert, kann sich im Netzwerk bereits etwas ändern, und Ihre Daten sind nicht relevant.

Dann stießen wir auf eine interessante Präsentation von Facebook. Wir mochten die Idee, die Facebook vorschlug, und beschlossen, etwas Ähnliches zu versuchen.
Was war die Hauptidee? Verwenden Sie ein eBPF-Programm auf dem Host, um die TCP-Neuübertragung einzufärben, und berechnen Sie dann die Anzahl solcher Pakete. Leider konnten wir das nicht wie auf Facebook machen, wir mussten unser eigenes Fahrrad erfinden. Ich werde versuchen, Ihnen von dem Weg des Schmerzes und des Leidens zu erzählen, den wir durchlaufen haben.
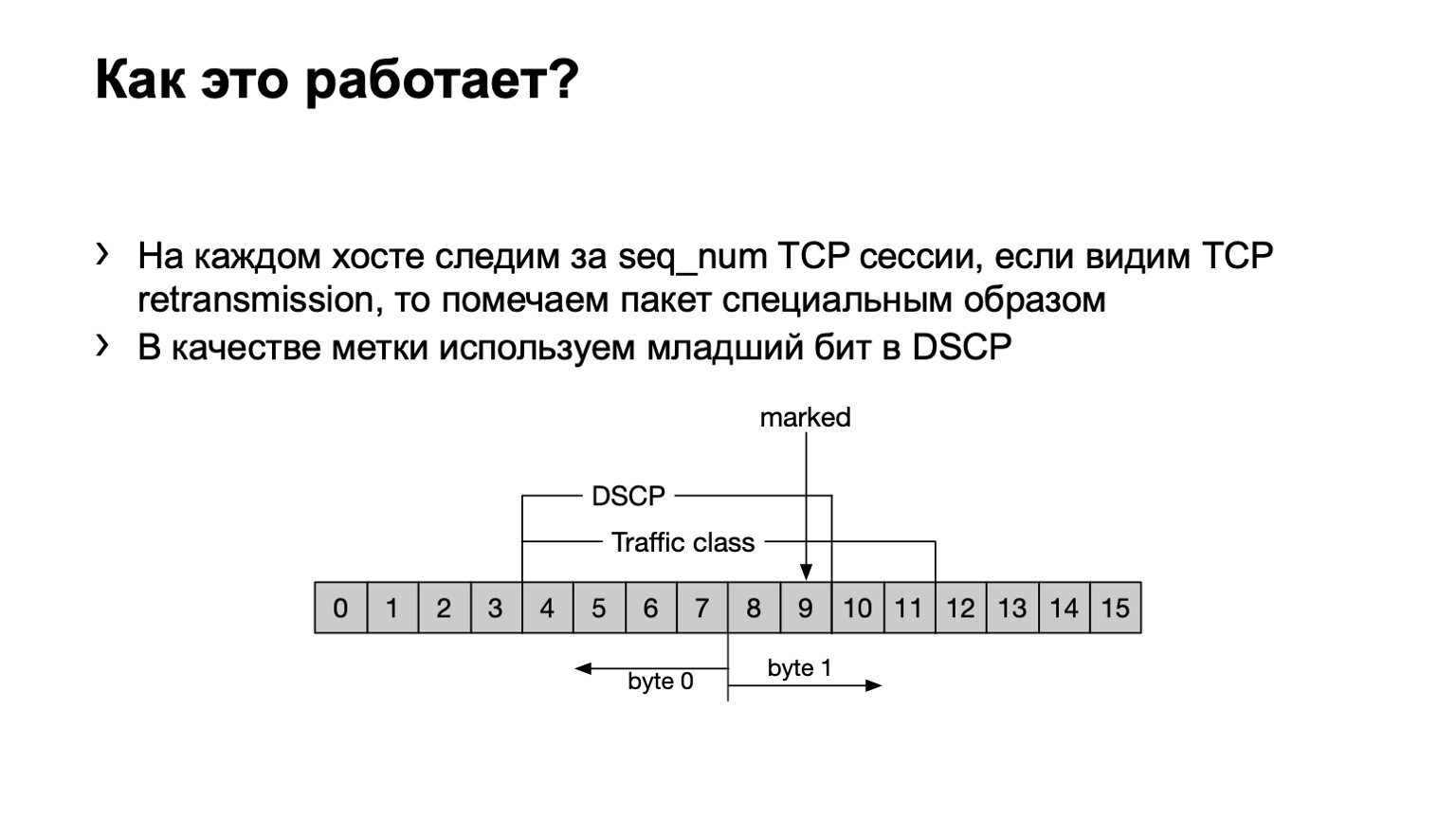
Was haben wir getan Nur für den Fall, ich möchte darauf hinweisen, dass es sich bei der erneuten TCP-Übertragung um TCP-Nachrichten handelt, die mehrmals wiederholt werden, da ihr Empfang nicht bestätigt wurde. Wir haben ein eBPF-Programm auf dem Host installiert und prüfen, ob diese TCP-Nachricht erneut übertragen wird oder nicht. Es macht es kitschig - nach Sequenznummer. Wenn in einer TCP-Sitzung dieselbe Sequenznummer übertragen wird, wird diese erneut übertragen.
Was machen wir mit solchen Paketen? Wir setzen das letzte Bit im DSCP-Feld auf eins, um das Ganze weiter zu berechnen.
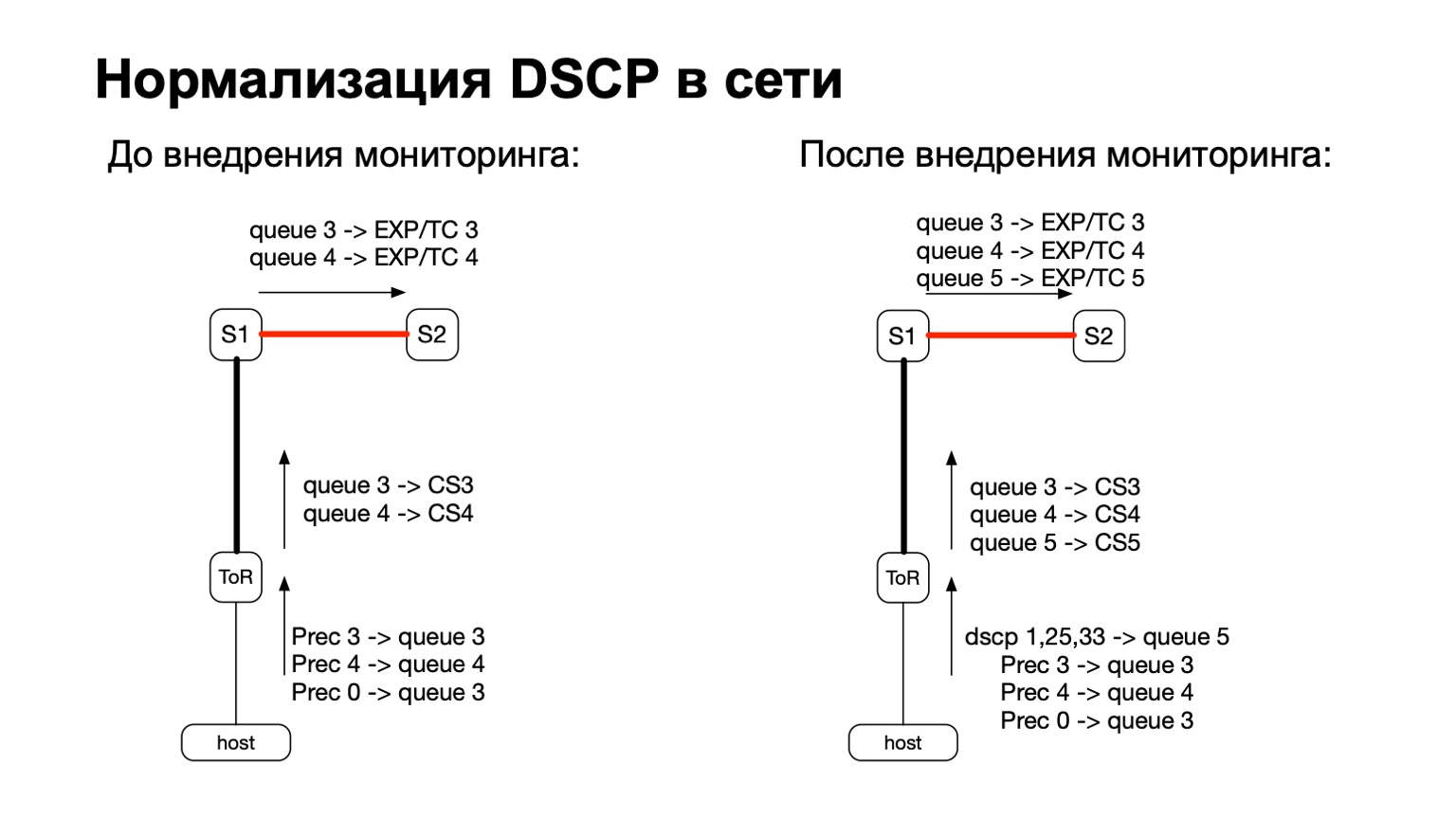
Im Allgemeinen hängt DSCP irgendwie mit QoS zusammen, oder? Und mit QoS ist die Geschichte in unserem Netzwerk ziemlich kompliziert und langjährig. Wir haben bestimmte Richtlinien, die auf ToR-Switches überwacht werden. Zu diesen Richtlinien haben wir nur die Notwendigkeit hinzugefügt, mehr und diese farbigen Pakete zu zählen.
Daher haben wir für farbige Pakete (lesen Sie: für TCP-Neuübertragungspakete vom Host) einfach eine weitere QoS-Warteschlange hinzugefügt. Dies war einfach genug, da wir noch freie Leitungen hatten. Dies ist außerdem praktisch, da es in der Phase des Übergangs zwischen IPv6 und MPLS in der Fabrik, dh in der Phase, in der das Paket S1 fliegt und zu unserem MPLS-Teil der Fabrik übergeht, praktisch ist, EXP / TC im MPLS-Paket-Header für jede bestimmte Warteschlange zu übernehmen und neu zu streichen .
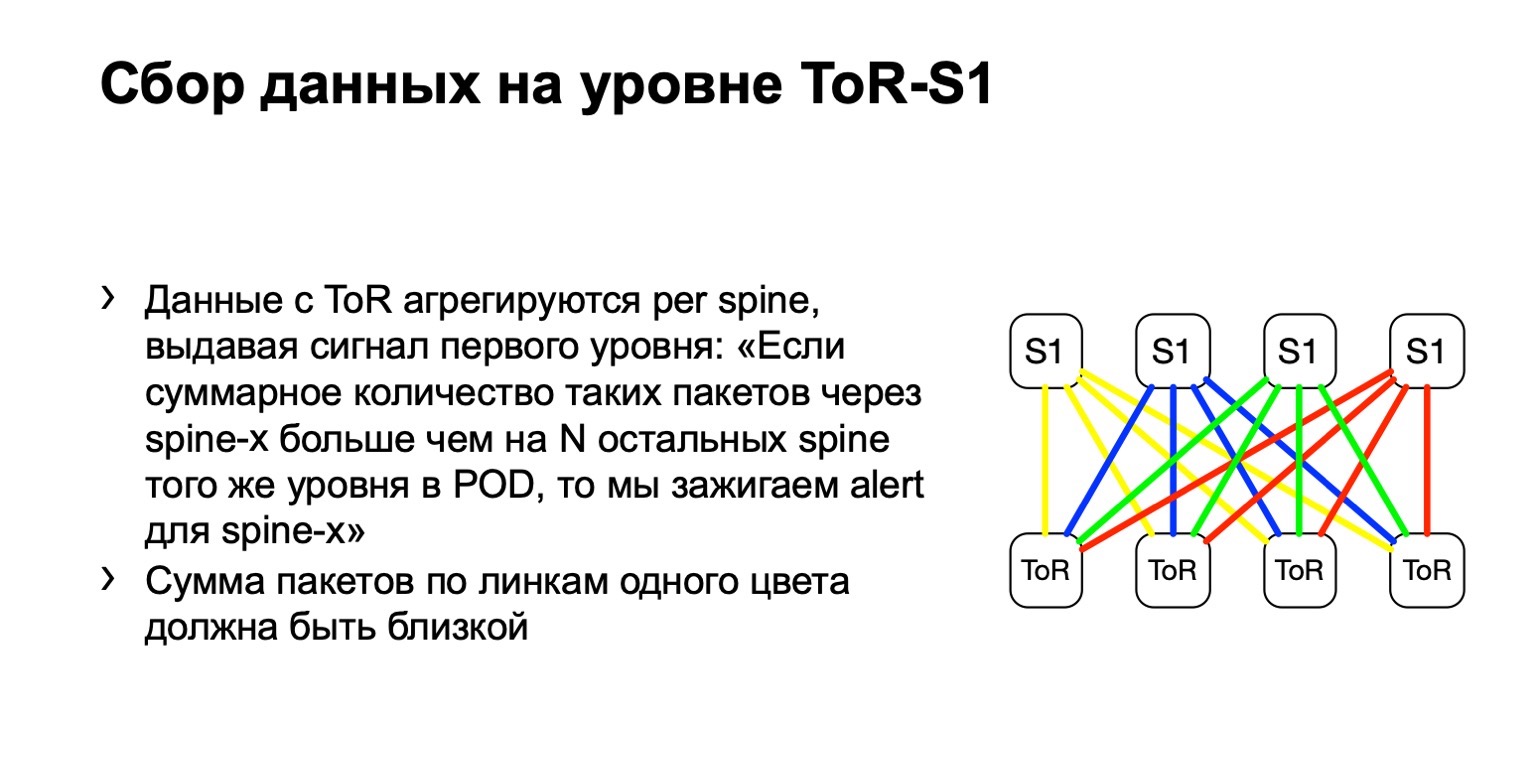
Was machen wir mit diesen Daten? Wir sammeln sie mit Standard-ACL-Filtern, Verkehrsklasse. Das heißt, es funktioniert im Prinzip bei jedem Anbieter. Wir können die Anzahl solcher Pakete überall sammeln und berechnen.
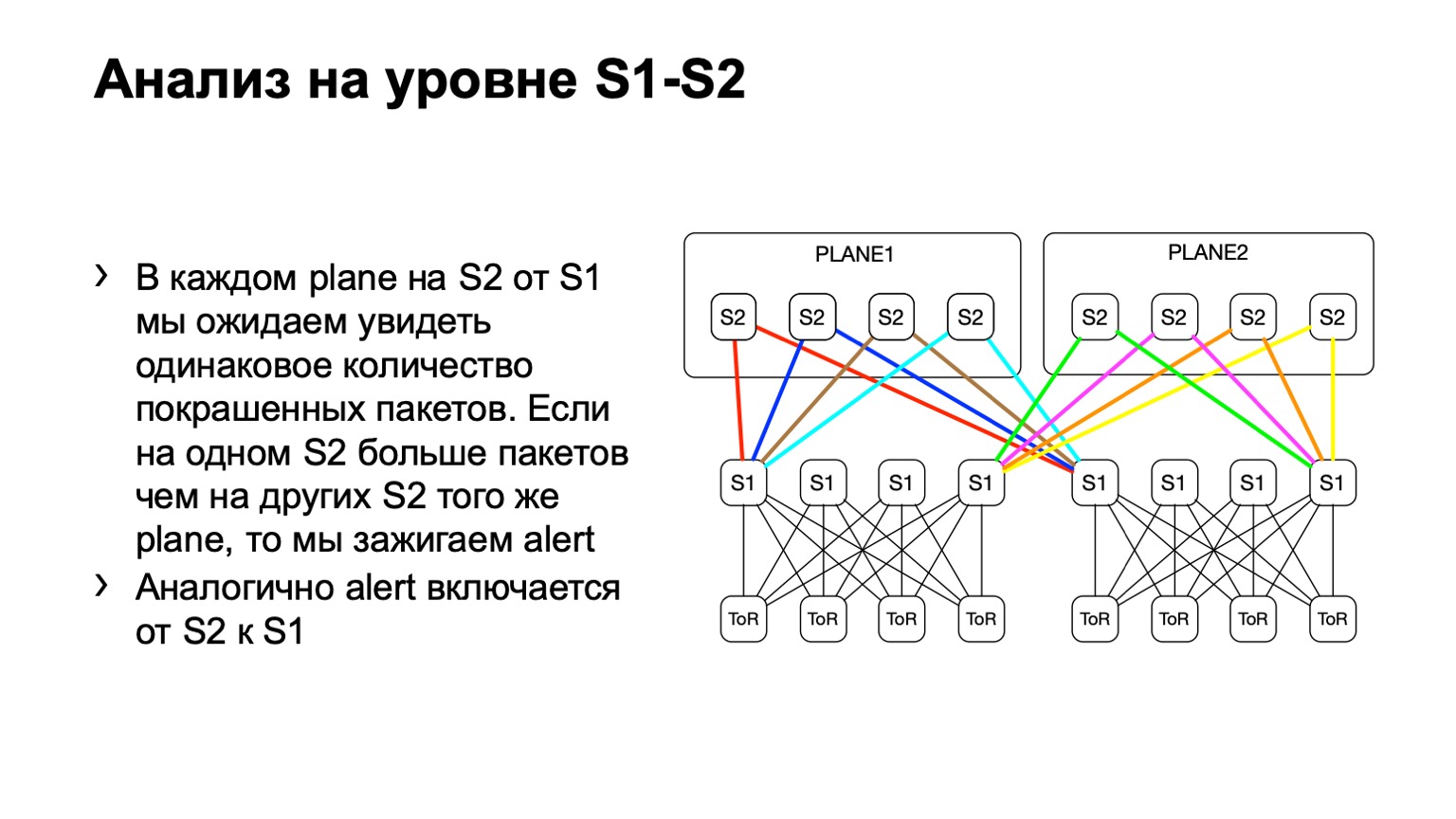
Als nächstes betrachten wir die ungleichmäßige Verteilung solcher Pakete auf dem POD. Darin zum Beispiel vier Rücken, wie auf dem Bild. Wenn die Anzahl der Pakete auf den gelben Links, auf blau, auf grün und auf rot gleich ist, dann glauben wir, dass alles mehr oder weniger gut ist. Wenn wir zu einem bestimmten Zeitpunkt einen Anstieg sehen, beispielsweise auf der rechten Seite der ersten Ebene, verstehen wir, dass dieses Gerät eine erneute Übertragung anzieht, etwas stimmt damit nicht. Dann versuchen wir, es entweder außer Betrieb zu setzen oder zumindest zu leasen. Zumindest wenn wir Probleme mit Netmon sehen, werden wir wissen, mit welchem Gerät sie auftreten können.
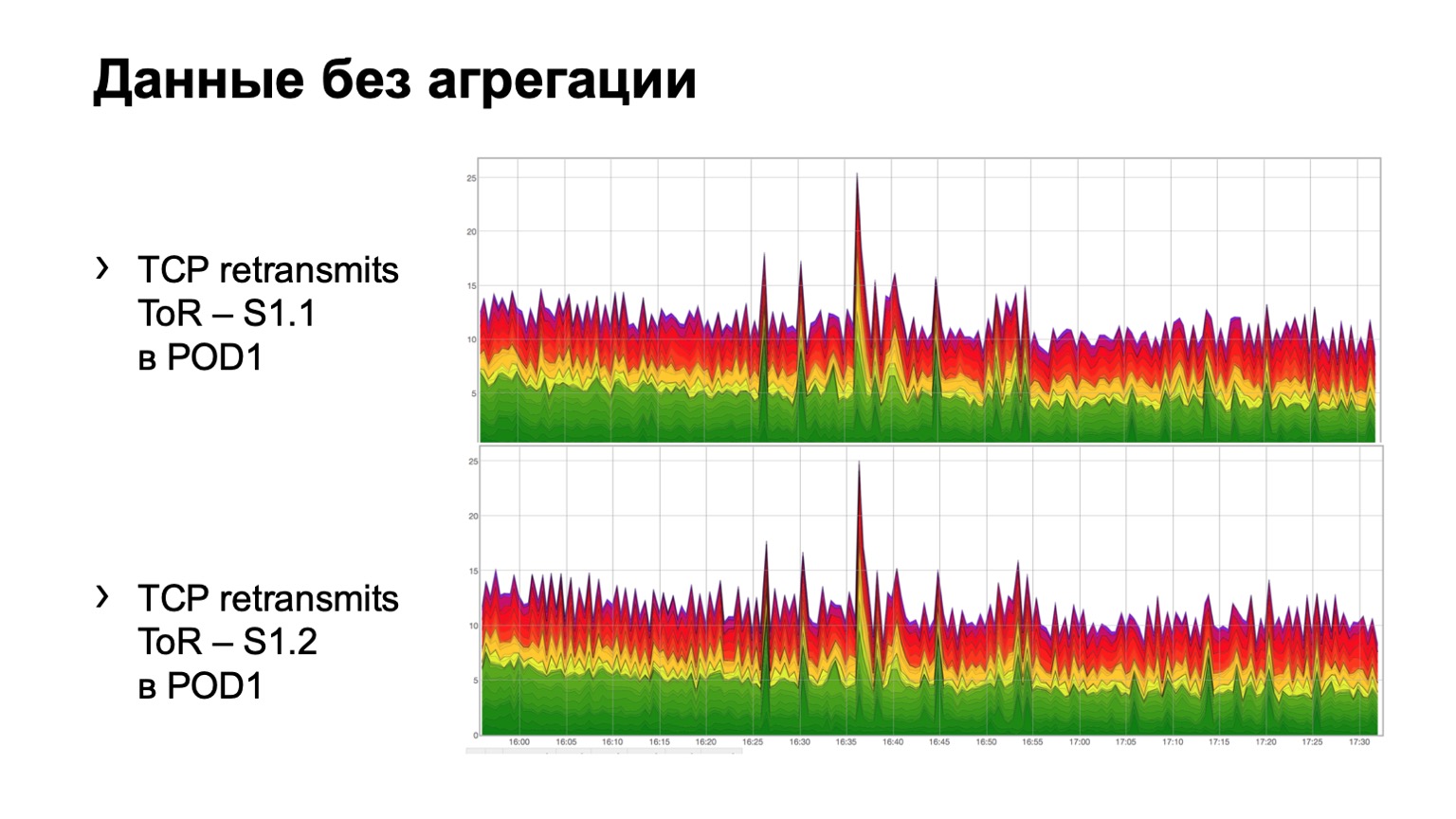
Wie sieht es bei einfachen Rohdaten aus? Hier sind zwei Grafiken. Tatsächlich handelt es sich hierbei um eine erneute Übertragung von Diagrammen mit ToR in Richtung der Wirbelsäule der ersten Ebene. Im Beispiel zwei Wirbelsäulen im Modul. Das obere Diagramm ist die Aggregation der ersten Wirbelsäule, das untere Diagramm ist die zweite Wirbelsäule. Das Anschauen in dieser Form ist nicht sehr praktisch, daher haben wir die Aggregation dieser Informationen hinzugefügt.
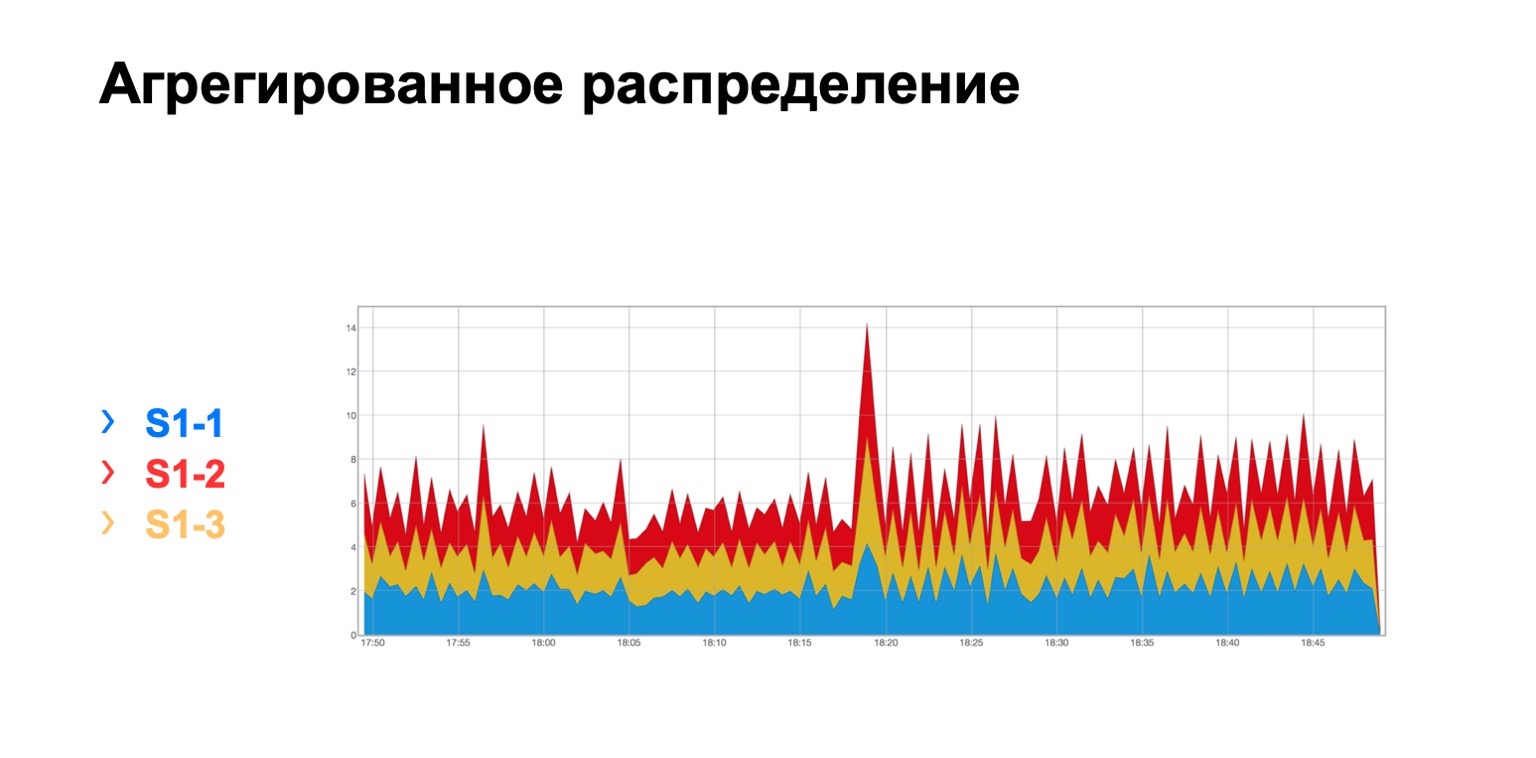
Es sieht so aus. Es gibt ein Modul, in dem drei Stacheln aus irgendeinem Grund, egal welcher, und wir sehen hier eine solche Gesamtverteilung der erneuten Übertragungen auf drei Stacheln. Es ist im Prinzip ziemlich einheitlich.
Für die Wirbelsäule der zweiten Ebene können verschiedene Abweichungen auftreten. Nennen wir sie so. Die Topologie bleibt weiterhin regelmäßig, aber je nach Rechenzentrum können wir eine plattenartige Architektur verwenden oder nicht. Der Punkt hier ist genau der gleiche. Auf einer Ebene sollten wir ungefähr die gleiche Verteilung der farbigen Verpackungen haben.
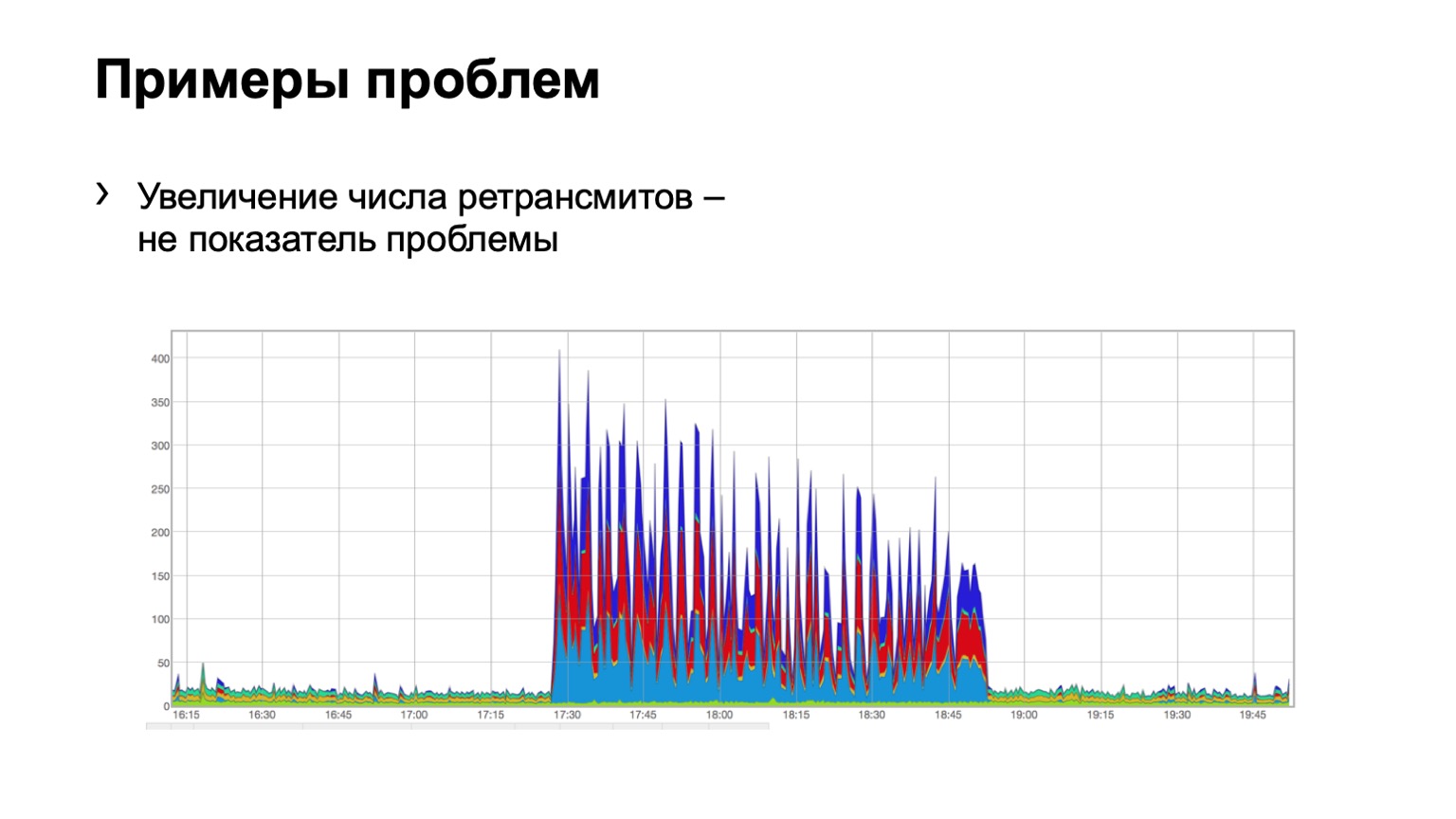
Schauen wir uns einige Beispiele an. Hat jemand ein Problem in einem solchen Diagramm? Hier gibt es ein Problem, aber es ist nicht gleichzeitig da. Ja, das ist Schrödingers Problem. Warum ist sie da und nicht? Da die Anzahl der erneuten Übertragungen zunimmt, ist es direkt offensichtlich, dass etwas für uns passiert ist. Gleichzeitig sehen wir aber, dass dieses Wachstum ziemlich gleichmäßig ist. Das heißt, drei Wirbelsäulenblau, Rot, Blau, gleichmäßige Verteilung über sie. Was bedeutet das? Dass es ein Problem im Netzwerk gab, hängt jedoch nicht mit dieser Ebene der Datenaggregation zusammen. Sie ist woanders.
Vielleicht hat jemand den Port auf Firewalls geschlossen, einen Cluster getrennt, das heißt, etwas ist passiert. Aber wir interessieren uns überhaupt nicht dafür, was da war und warum. Das heißt, wir betrachten ein solches Problem nicht einmal.
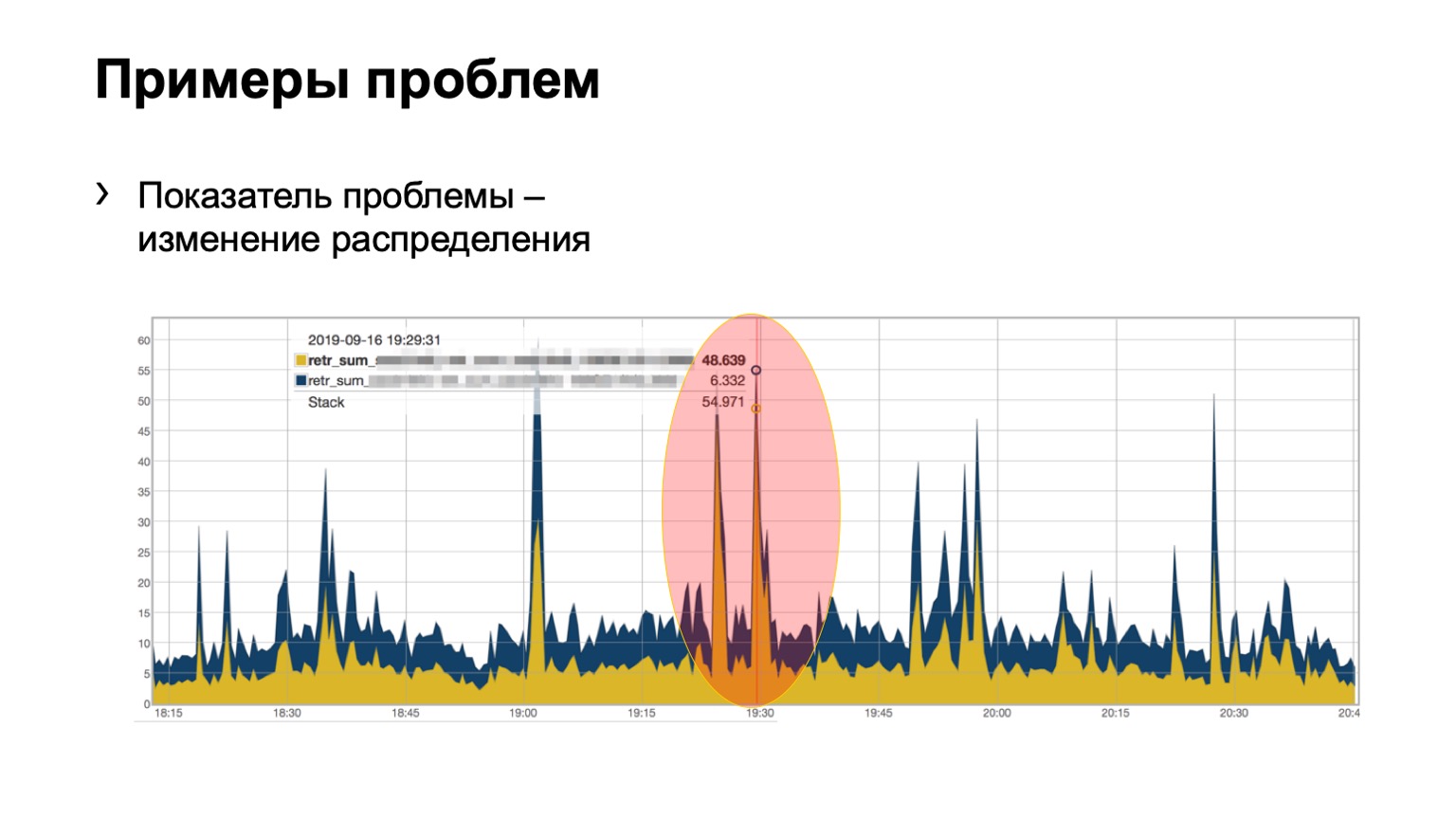
Und hier vielleicht nicht so klar, aber das Problem ist sichtbar. Zwei Stacheln im Modul, 46 bemalte Päckchen flogen auf einen und ein wenig auf den zweiten. Wir verstehen, dass wir ein Problem mit einer Art Wirbelsäule im Netzwerk haben, wir müssen etwas dagegen tun.
Warum habe ich zuerst über den Weg des Schmerzes und des Leidens gesprochen? Weil es bei einer solchen Lösung viele Probleme gibt. Das Hauptproblem ist natürlich das Problem jeder Überwachung, dies ist falsch positiv. Falsch positiv war ziemlich viel. Hauptsächlich aufgrund der Tatsache, dass wir DSCP verwenden und im Allgemeinen an QoS gebunden sind.

Wir haben festgestellt, dass die Pakete anderer Leute in unserer Farbe fliegen und uns auf unsere Überwachung aufmerksam machen. Das heißt, wir denken, dass dies eine erneute Übertragung ist, und jemand anderes legt seine Pakete dort ab und verdirbt im Allgemeinen das Bild für uns. Natürlich begannen wir zu verstehen, fanden viele Orte, an denen wir dachten, dass es funktioniert, aber es funktioniert tatsächlich nicht so, wie wir denken. Zum Beispiel sollte der Verkehr, der in das Netzwerk eintritt, scheinbar neu gestrichen werden, der Verkehr mit den Klassen CS6 und CS7 an den Grenzen sollte nicht in unser Netzwerk gelangen. Aber an einigen Stellen gab es beispielsweise Mängel, und wir haben sie erfolgreich behandelt.
Einige Hersteller präsentierten Überraschungen in der Form, dass Sie Zähler in der Ausgangsrichtung solcher Pakete zählen, und der Chip funktioniert so, dass er bei der Verarbeitung der Ausgangszugriffsliste den Datenverkehr erneut durch sich selbst wickelt und die Hälfte der Chipbandbreite abbeißt . Es waren 900 Gigabit pro Chip, es wurde halb so viel.
Und wir haben einige Verbesserungen vorgenommen, da die Einstellungen auf dem Host unterschiedlich sein können. Das heißt, einige Hosts können häufiger Neuübertragungen senden, einige Hosts können weniger häufig, einige zwei, einige fünf und all diese Warnungen unserer Überwachung, all dies ist falsch positiv.
Zunächst haben wir die Idee aufgegeben, jede TCP-Neuübertragung zu malen. Wir haben erkannt, dass wir im Prinzip nicht jede erneute Übertragung benötigen, um zu verstehen, wo das Problem liegt. Wir fingen an, nur SYN-Retransmit zu malen. SYN ist das erste Paket in der Sitzung. Dies reicht aus, um ein Signal zu empfangen. Wir malen auch SYN-ACL.
Trotzdem gab es einige falsch positive. Wir gingen etwas weiter. Wir haben begonnen, nur die erste TCP-SYN-Neuübertragung in der Sitzung zu malen. Das heißt, es werden tatsächlich mehrere von ihnen gesendet, wir haben jeden gemalt - nur einer begann gemalt zu werden. Wir sind also zu dem gekommen, was wir jetzt haben.
Insgesamt gibt es Netmon, es gibt Agenten auf Hosts, die die erste SYN-Neuübertragung in der Sitzung färben, und wir zählen diese Neuübertragungen auf jedem Gerät, auf fast jeder Verbindung in unserem Netzwerk.

Aber mit den Augen auf das Bild zu schauen, das ich früher gezeigt habe, ist nicht sehr praktisch. Das heißt, Sie können es nicht an einen diensthabenden Beamten verkaufen, da Sie in jedem Abschnitt alles mit Ihren Augen bewerten müssen. Und wir kamen zu der Tatsache, dass ich eine Warnung haben möchte. Ich möchte, dass ein Licht aufleuchtet: Ein Gerät wie dieses ist ein Problem; Ein anderes Gerät ist ein Problem.
Erinnern wir uns an einige mathematische Statistiken. Die Idee mit Alarm ist, dass jedes Gerät im Wesentlichen ein Korb ist. Wir haben eine Erfolgswahrscheinlichkeit und eine Ausfallwahrscheinlichkeit für vier Geräte. Die Wahrscheinlichkeit einer erneuten Übertragung in den Warenkorb, dh Erfolg, beträgt ¼. Es stellt sich eine Binomialverteilung heraus.
Was ist die Schwierigkeit, hier einen Alarm auszulösen? Die Tatsache, dass wir die Schwellenwerte nicht statisch machen können, können wir nicht sagen: Wenn zehn Neuübertragungen auf einem Gerät und neun auf dem anderen ankommen, gibt es kein Problem. Und wenn zehn und fünf, dann gibt es ein Problem. Denn wenn wir es auf tausend PPS skalieren, sind solche Daten nicht mehr relevant. 1000 PPS und 800 PPS zwischen verschiedenen Geräten sind definitiv ein Problem.
Wir können keine statischen Schwellenwerte in PPS oder Bytes festlegen, wir können sie nicht als Prozentsatz festlegen - das gleiche Problem mit ihnen. Daher benötigen wir eine Lösung, die diesen Schwellenwert je nach Anzahl der Pakete mehr oder weniger dynamisch macht.
Und der Reiz der Binomialverteilung besteht darin, dass sie bei der PPS-Erhöhung zur Normalität tendiert, und für eine Normalverteilung können wir bereits die Erwartung, Varianz und das Konfidenzintervall berechnen, was wir getan haben. Das Konfidenzintervall für uns beträgt 3NPQ, dh es hängt von der Anzahl der Pakete durch das Gerät ab. Als Ergebnis haben wir eine dynamische Verschiebungsschwelle.
So sieht unser Signal im Bild aus. Wenn ein Gerät aus der Distribution ausgeschlossen wird, setzen wir eine Flagge darauf - etwas stimmt nicht.

Wo wollen wir uns weiterentwickeln, was wollen wir hier verbessern, zusätzlich natürlich zum Kampf gegen falsch positive Ergebnisse? Zunächst wären wir interessiert zu sehen, was zum Zeitpunkt des Problems da war. Zu diesem Zweck haben wir eine solche Option im Agenten - Debug. Wir können genau das, was erneut übertragen wurde, dh ein 5-Tupel-Paket, in einen separaten Kollektor hochladen und dann betrachten. Dies belastet die Hosts jedoch etwas, so dass es uns manchmal verboten ist, dies zu tun. Wir möchten ERSPAN befestigen und solche Pakete von der Hardware selbst auf den Kollektor entladen, da uns niemand verbietet, dies auf der Hardware zu tun.
Dima Afanasyev
erklärte, wie wir unsere Fabriken entwickeln werden, und einer der Punkte war der Übergang von der MPLS-Fabrik zu IPv6. Was gibt uns das? MPLS verfügt über drei Bits für die QoS-Markierung. In IPv6 mindestens sechs. Derzeit werden in unserem Netzwerk nur drei Bits verwendet. Das heißt, wir haben noch drei weitere Bits, in die wir tatsächlich alle Informationen vom Host einfügen können.
Zum Beispiel malen wir jetzt nur die erste SYN-Neuübertragung in der Sitzung. Und wir können das zweite Bit beispielsweise einfärben, wenn das Paket an ein externes Netzwerk geht. Und wir können erneut senden, dh ein anderes Signal hervorheben, das wir dann separat betrachten werden.
Darüber hinaus droht uns der Übergang zum Design mit Edge Pod, wenn wir DCI an einem bestimmten Ort durchgeführt haben, damit, dass wir an diesem Ort unsere Diffserv-Domäne genauer steuern können. Das heißt, etwas neu streichen und mit Farben tun, um falsch positive Ergebnisse abzuschneiden.
Infolgedessen erwies sich all dies als ziemlich schmerzhaft, aber interessant. Es gab nichts zu befürchten. Wir haben tatsächlich eine Lösung entwickelt, die jeder nutzen kann. Es wird bei praktisch jedem Anbieter getestet, es funktioniert, es ist nicht schwierig. Und es zeigt wirklich, auf welchem Gerät im Netzwerk ein Problem vorliegt. Daher lautet meine Botschaft: Haben Sie keine Angst, dasselbe zu tun, und lassen Sie Ihre Überwachung grün bleiben. Danke fürs Zuhören.