Die Protokollierung ist ein wichtiger Bestandteil jeder Anwendung. Jedes Protokollierungssystem durchläuft drei Hauptentwicklungsschritte. Die erste wird an die Konsole ausgegeben, die zweite protokolliert in einer Datei und zeigt ein Framework für die strukturierte Protokollierung an, und die dritte ist die verteilte Protokollierung oder das Sammeln von Protokollen verschiedener Dienste in einem einzigen Zentrum.
Wenn die Protokollierung gut organisiert ist, können Sie verstehen, was, wann und wie es schief geht, und die erforderlichen Informationen an Personen weitergeben, die diese Fehler korrigieren müssen. Für ein System, in dem in 10 Rechenzentren in 190 Ländern 100.000 Nachrichten pro Sekunde gesendet werden und 350 Ingenieure täglich etwas bereitstellen, ist das Protokollierungssystem besonders wichtig.
 Ivan Letenko
Ivan Letenko ist Teamleiter und Entwickler bei Infobip. Um das Problem der zentralisierten Verarbeitung und Protokollverfolgung in der Microservice-Architektur unter solch enormen Belastungen zu lösen, versuchte das Unternehmen verschiedene Kombinationen des ELK-, Graylog-, Neo4j- und MongoDB-Stacks. Infolgedessen haben sie nach viel Rechen ihren Protokolldienst auf Elasticsearch geschrieben, und PostgreSQL wurde als Datenbank für zusätzliche Informationen verwendet.
Im Detail unter der Katze mit Beispielen und Grafiken: Architektur und Entwicklung des Systems, Rechen, Protokollierung und Nachverfolgung, Metriken und Überwachung, die Praxis, mit Elasticsearch-Clustern zu arbeiten und diese mit begrenzten Ressourcen zu verwalten.
Um Ihnen den Kontext vorzustellen, erzähle ich Ihnen ein wenig über das Unternehmen. Wir unterstützen Kundenorganisationen bei der Zustellung von Nachrichten an ihre Kunden: Nachrichten von einem Taxidienst, SMS von einer Bank über die Stornierung oder ein Einmalpasswort bei der Eingabe von VC.
Täglich gehen
350 Millionen Nachrichten für Kunden in 190 Ländern über uns. Jeder von ihnen wird von uns akzeptiert, verarbeitet, abgerechnet, weitergeleitet, angepasst, an Bediener gesendet und in umgekehrter Richtung werden Lieferberichte verarbeitet und Analysen erstellt.
Damit all dies in solchen Bänden funktioniert, haben wir:
- 36 Rechenzentren auf der ganzen Welt;
- Über 5000 virtuelle Maschinen
- Über 350 Ingenieure;
- 730+ verschiedene Microservices.
Dies ist ein komplexes System, und kein einziger Guru kann im Alleingang den vollen Umfang verstehen. Eines der Hauptziele unseres Unternehmens ist die hohe Geschwindigkeit der Bereitstellung neuer Funktionen und Releases für Unternehmen. In diesem Fall sollte alles funktionieren und nicht fallen. Wir arbeiten daran: 40.000 Bereitstellungen im Jahr 2017, 80.000 im Jahr 2018, 300 Bereitstellungen pro Tag.
Wir haben 350 Ingenieure - es stellt sich heraus, dass
jeder Ingenieur täglich etwas einsetzt . Noch vor wenigen Jahren hatte nur eine Person in einem Unternehmen eine solche Produktivität - Kreshimir, unser Hauptingenieur. Wir haben jedoch sichergestellt, dass sich jeder Ingenieur genauso sicher fühlt wie Kresimir, wenn er auf die Schaltfläche Bereitstellen drückt oder ein Skript ausführt.
Was wird dafür benötigt? Zuallererst das
Vertrauen, dass wir verstehen, was im System passiert und in welchem Zustand es ist. Vertrauen wird durch die Fähigkeit gegeben, dem System eine Frage zu stellen und die Ursache des Problems während des Vorfalls und während der Entwicklung des Codes herauszufinden.
Um dieses Vertrauen zu erreichen, investieren wir in
Beobachtbarkeit . Traditionell kombiniert dieser Begriff drei Komponenten:
- Protokollierung;
- Metriken
- Spur.
Wir werden darüber reden. Schauen wir uns zunächst unsere Lösung für die Protokollierung an, aber wir werden auch Metriken und Traces ansprechen.
Evolution
Fast jede Anwendung oder jedes Protokollierungssystem, einschließlich unseres, durchläuft mehrere Entwicklungsstufen.
Der erste Schritt ist die
Ausgabe an die Konsole .
Zweitens: Wir beginnen
mit dem Schreiben von Protokollen in eine Datei. Es wird ein
Framework für die strukturierte Ausgabe in eine Datei angezeigt. Wir verwenden normalerweise Logback, weil wir in der JVM leben. In dieser Phase wird eine strukturierte Protokollierung in einer Datei angezeigt, wobei zu verstehen ist, dass unterschiedliche Protokolle unterschiedliche Ebenen, Warnungen und Fehler aufweisen sollten.
Sobald
es mehrere Instanzen unseres Dienstes oder verschiedene Dienste gibt, erscheint die Aufgabe des
zentralisierten Zugriffs auf die Protokolle für Entwickler und Support. Wir gehen zur verteilten Protokollierung über - wir kombinieren verschiedene Dienste zu einem einzigen Protokollierungsdienst.
Verteilte Protokollierung
Die bekannteste Option ist der ELK-Stack: Elasticsearch, Logstash und Kibana, aber wir haben uns für
Graylog entschieden. Es hat eine coole Oberfläche, die auf die Protokollierung ausgerichtet ist. Alarme werden bereits in der kostenlosen Version ausgeliefert, die beispielsweise nicht in Kibana verfügbar ist. Für uns ist dies eine ausgezeichnete Wahl in Bezug auf Protokolle, und unter der Haube befindet sich die gleiche Elasticsearch.
 In Graylog können Sie Warnungen, Diagramme wie Kibana und sogar Protokollmetriken erstellen.
In Graylog können Sie Warnungen, Diagramme wie Kibana und sogar Protokollmetriken erstellen.Die Probleme
Unser Unternehmen wuchs und irgendwann wurde klar, dass etwas mit Graylog nicht stimmte.
Übermäßige Belastung . Es gab Leistungsprobleme. Viele Entwickler nutzten die coolen Funktionen von Graylog: Sie erstellten Metriken und Dashboards, die die Datenaggregation durchführen. Nicht die beste Wahl, um komplexe Analysen auf dem Elasticsearch-Cluster zu erstellen, der unter hoher Aufzeichnungslast steht.
Kollisionen Es gibt viele Teams, es gibt kein einziges Schema. Wenn eine ID Graylog zum ersten Mal so lange traf, erfolgte die Zuordnung traditionell automatisch. Wenn ein anderes Team entscheidet, dass die UUID als Zeichenfolge geschrieben werden soll, wird das System beschädigt.
Erste Entscheidung
Getrennte Anwendungsprotokolle und Kommunikationsprotokolle . Unterschiedliche Protokolle haben unterschiedliche Szenarien und Anwendungsmethoden. Es gibt beispielsweise Anwendungsprotokolle, für die unterschiedliche Teams unterschiedliche Anforderungen an unterschiedliche Parameter stellen: nach der Speicherzeit im System, nach der Suchgeschwindigkeit.
Daher haben wir als erstes Anwendungsprotokolle und Kommunikationsprotokolle getrennt. Der zweite Typ sind wichtige Protokolle, in denen Informationen über die Interaktion unserer Plattform mit der Außenwelt und über die Interaktion innerhalb der Plattform gespeichert sind. Wir werden mehr darüber reden.
Ersetzte einen wesentlichen Teil der Protokolle durch Metriken . In unserem Unternehmen sind Prometheus und Grafana die Standardauswahl. Einige Teams verwenden andere Lösungen. Es ist jedoch wichtig, dass wir eine große Anzahl von Dashboards mit Aggregationen in Graylog entfernt und alles an Prometheus und Grafana übertragen haben. Dies entlastete die Server erheblich.
Schauen wir uns die Szenarien zum Anwenden von Protokollen, Metriken und Traces an.
Protokolle
Hohe Dimensionalität, Debugging und Forschung . Was sind gute Protokolle?
Protokolle sind die Ereignisse, die wir protokollieren.
Sie können eine große Dimension haben: Sie können Anforderungs-ID, Benutzer-ID, Anforderungsattribute und andere Daten protokollieren, deren Dimension nicht beschränkt ist. Sie eignen sich auch zum Debuggen und Forschen, um dem System Fragen zu stellen und nach Ursachen und Auswirkungen zu suchen.
Metriken
Geringe Dimensionalität, Aggregation, Überwachung und Warnungen . Unter der Haube aller metrischen Erfassungssysteme befinden sich die Zeitreihendatenbanken. Diese Datenbanken leisten hervorragende Arbeit bei der Aggregation, sodass Metriken für die Aggregation, Überwachung und Erstellung von Warnungen geeignet sind.
Metriken reagieren sehr empfindlich auf Datendimensionen.
Bei Metriken sollte die Dimension der Daten tausend nicht überschreiten. Wenn wir einige Anforderungs-IDs hinzufügen, bei denen die Größe der Werte nicht begrenzt ist, treten schnell ernsthafte Probleme auf. Wir sind bereits auf diesen Rechen getreten.
Korrelation und Spur
Protokolle sollten korreliert sein.
Strukturierte Protokolle reichen nicht aus, um bequem nach Daten zu suchen. Es sollten Felder mit bestimmten Werten vorhanden sein: Anforderungs-ID, Benutzer-ID, andere Daten von den Diensten, von denen die Protokolle stammen.
Die traditionelle Lösung besteht darin, der Transaktion (Protokoll) am Eingang des Systems eine eindeutige ID zuzuweisen. Diese ID (Kontext) wird dann über eine Aufrufkette innerhalb eines Dienstes oder zwischen Diensten durch das gesamte System weitergeleitet.
 Korrelation und Rückverfolgung.
Korrelation und Rückverfolgung.Es gibt gut etablierte Begriffe. Der Trace ist in Bereiche unterteilt und zeigt den Aufrufstapel eines Dienstes relativ zu einem anderen, eine Methode relativ zu einem anderen relativ zur Zeitachse. Sie können den Nachrichtenpfad und alle Timings klar verfolgen.
Zuerst haben wir Zipkin benutzt. Bereits 2015 hatten wir einen Proof of Concept (Pilotprojekt) dieser Lösungen.
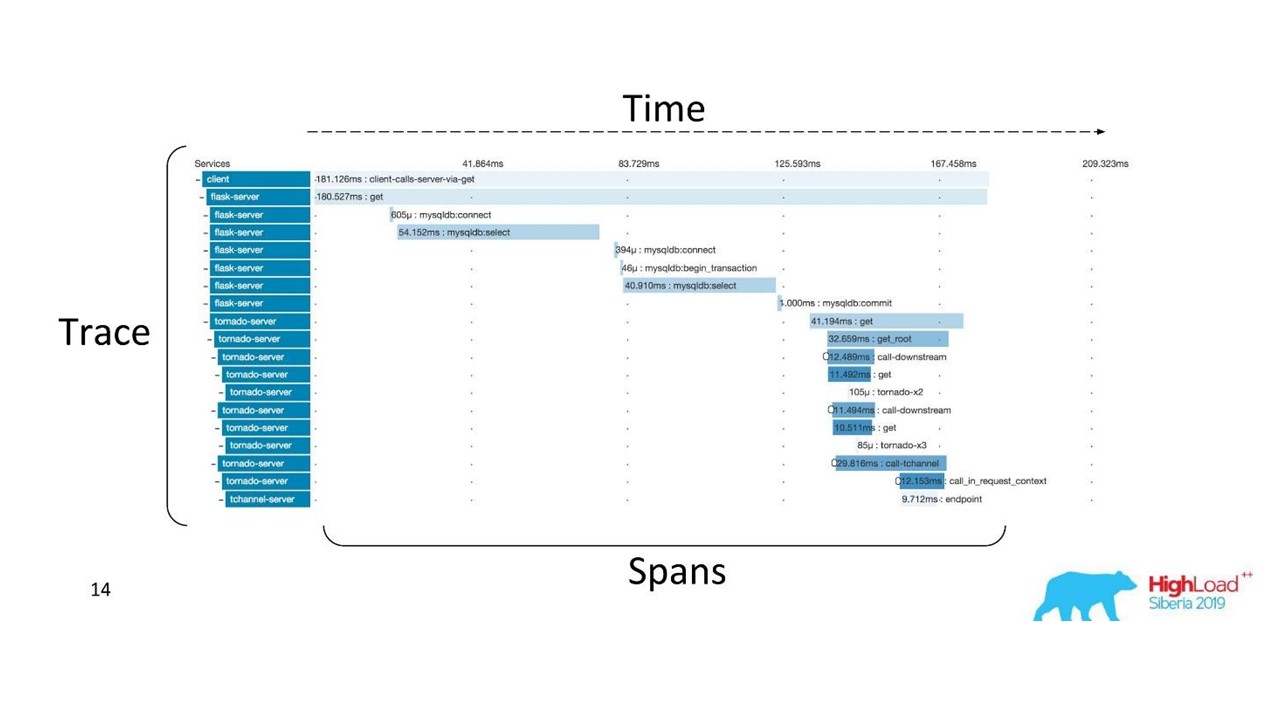 Verteilte Ablaufverfolgung
Verteilte AblaufverfolgungUm dieses Bild zu erhalten, muss der
Code instrumentiert werden . Wenn Sie bereits mit einer vorhandenen Codebasis arbeiten, müssen Sie diese durchgehen - dies erfordert Änderungen.
Um ein vollständiges Bild zu erhalten und von den Traces zu profitieren, müssen Sie
alle Services in der Kette instrumentieren und nicht nur einen Service, an dem Sie gerade arbeiten.
Dies ist ein leistungsstarkes Tool, das jedoch erhebliche Verwaltungs- und Hardwarekosten erfordert. Daher haben wir von Zipkin auf eine andere Lösung umgestellt, die von „as a Service“ bereitgestellt wird.
Lieferberichte
Protokolle sollten korreliert sein. Spuren müssen ebenfalls korreliert werden. Wir brauchen eine einzige ID - einen gemeinsamen Kontext, der über die gesamte Anrufkette weitergeleitet werden kann. Dies ist jedoch häufig nicht möglich - eine
Korrelation tritt innerhalb des Systems aufgrund seines Betriebs auf . Wenn wir eine oder mehrere Transaktionen starten, wissen wir immer noch nicht, dass sie Teil eines einzigen großen Ganzen sind.
Betrachten Sie das erste Beispiel.
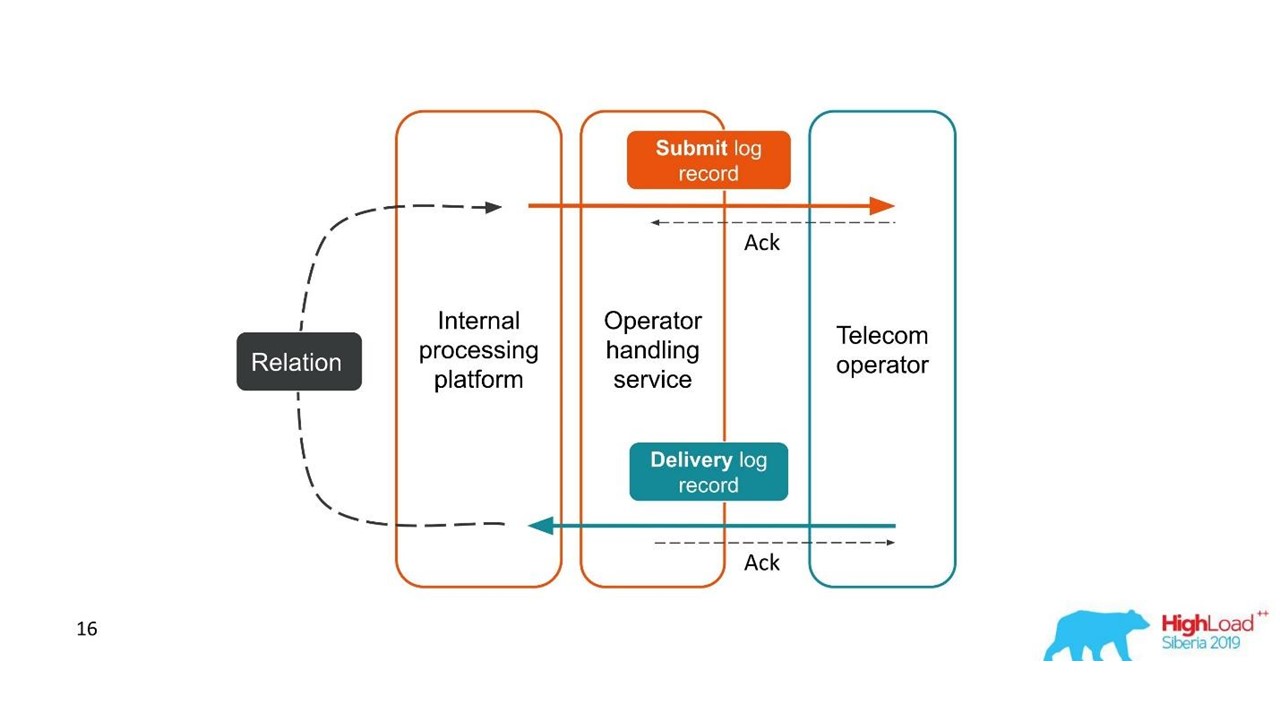 Lieferberichte.
Lieferberichte.- Der Kunde hat eine Anfrage für eine Nachricht gesendet und diese von unserer internen Plattform verarbeitet.
- Der Dienst, der mit dem Bediener interagiert, hat diese Nachricht an den Bediener gesendet - ein Eintrag wurde im Protokollsystem angezeigt.
- Später sendet uns der Betreiber einen Lieferbericht.
- Der Verarbeitungsdienst weiß nicht, auf welche Nachricht sich dieser Zustellungsbericht bezieht. Diese Beziehung wird später auf unserer Plattform erstellt.
Zwei verwandte Transaktionen sind Teile einer einzelnen gesamten Transaktion. Diese Informationen sind für Supportingenieure und Integrationsentwickler sehr wichtig. Dies ist jedoch aufgrund einer einzelnen Ablaufverfolgung oder einer einzelnen ID völlig unmöglich zu erkennen.
Der zweite Fall ist ähnlich - der Client sendet uns eine Nachricht in einem großen Bündel, dann zerlegen wir sie, sie kommen auch in Stapeln zurück. Die Anzahl der Packungen kann sogar variieren, aber dann werden alle kombiniert.
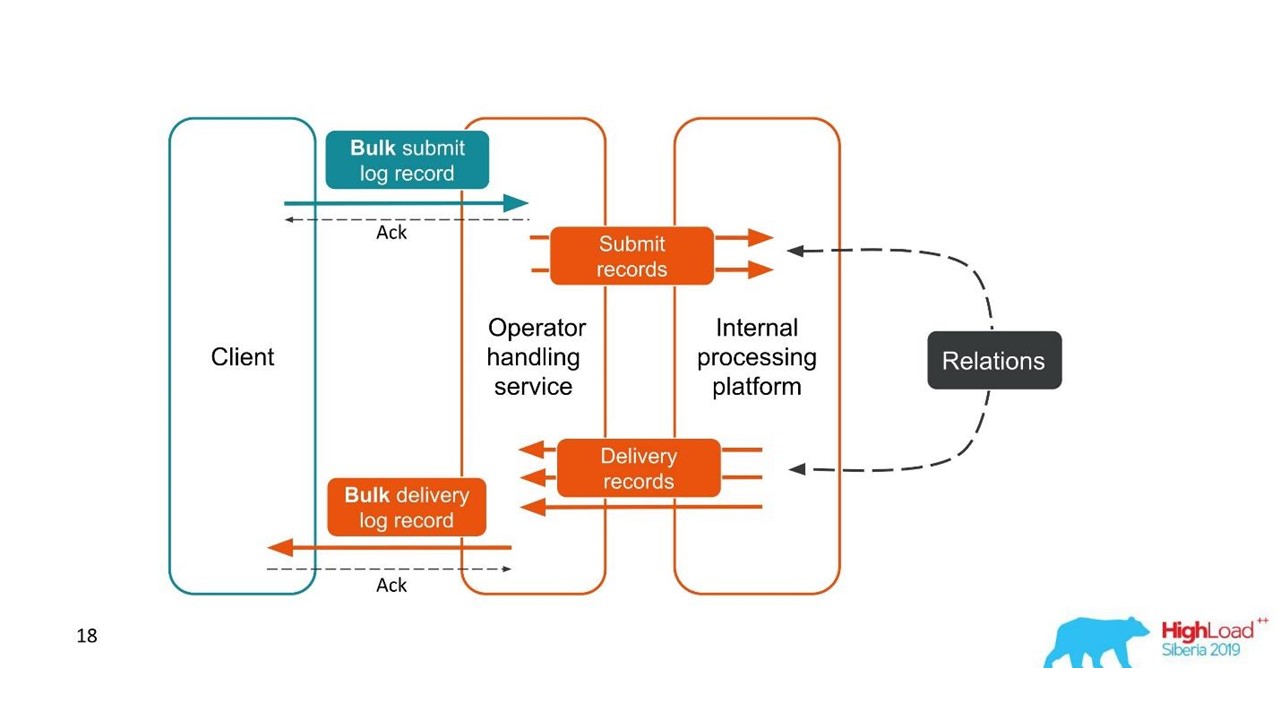
Aus Sicht des Kunden hat er eine Nachricht gesendet und eine Antwort erhalten. Wir haben jedoch mehrere unabhängige Transaktionen, die kombiniert werden müssen. Es stellt sich eine Eins-zu-Viele-Beziehung und ein Lieferbericht heraus - eins zu eins. Dies ist im Wesentlichen ein Diagramm.
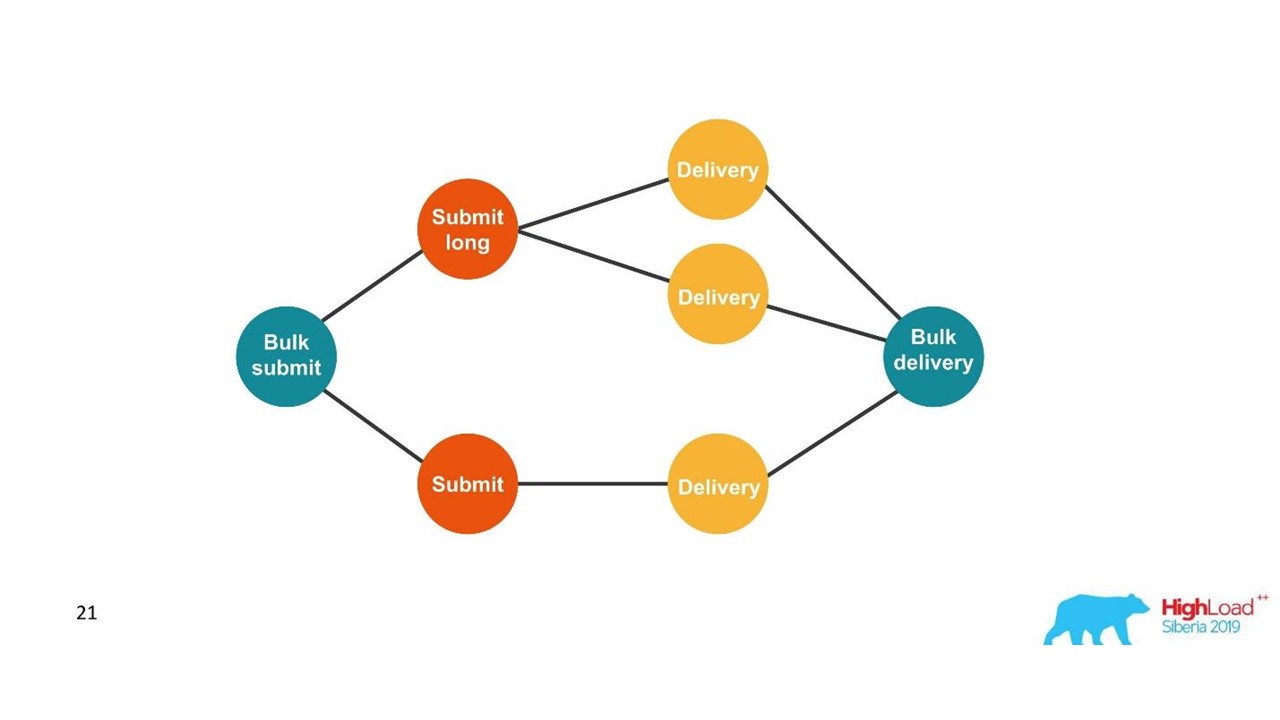 Wir bauen ein Diagramm.
Wir bauen ein Diagramm.Sobald wir ein Diagramm sehen, sind Diagrammdatenbanken, z. B. Neo4j, eine geeignete Wahl. Die Wahl lag auf der Hand, da Neo4j auf Konferenzen coole T-Shirts und kostenlose Bücher anbietet.
Neo4j
Wir haben Proof of Concept implementiert: einen 16-Core-Host, der ein Diagramm mit 100 Millionen Knoten und 150 Millionen Links verarbeiten kann. Das Diagramm belegte nur 15 GB Festplatte - dann passte es zu uns.
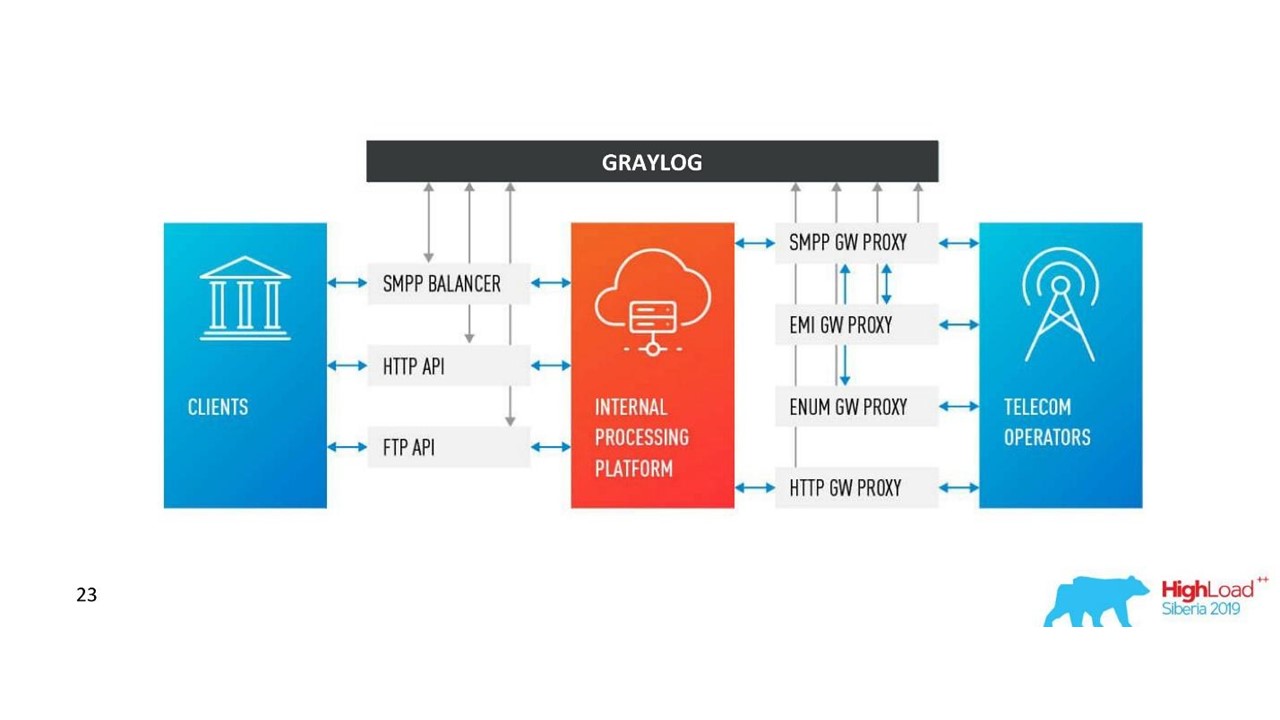 Unsere Entscheidung. Protokollarchitektur.
Unsere Entscheidung. Protokollarchitektur.Zusätzlich zu Neo4j haben wir jetzt eine einfache Oberfläche zum Anzeigen verwandter Protokolle. Mit ihm sehen die Ingenieure das ganze Bild.
Aber ziemlich schnell wurden wir von dieser Datenbank enttäuscht.
Probleme mit Neo4j
Datenrotation . Wir haben leistungsstarke Volumes und Daten müssen gedreht werden. Wenn jedoch ein Knoten aus Neo4j gelöscht wird, werden die Daten auf der Festplatte nicht gelöscht. Ich musste eine komplexe Lösung erstellen und die Diagramme komplett neu erstellen.
Leistung . Alle Diagrammdatenbanken sind schreibgeschützt. Bei der Aufnahme ist die Leistung deutlich geringer. Unser Fall ist genau das Gegenteil: Wir schreiben viel und lesen relativ selten - dies sind Einheiten von Anfragen pro Sekunde oder sogar pro Minute.
Hochverfügbarkeit und Clusteranalyse gegen Gebühr . In unserer Größenordnung bedeutet dies angemessene Kosten.
Deshalb sind wir den anderen Weg gegangen.
Lösung mit PostgreSQL
Wir haben beschlossen, dass die Grafik beim Lesen im Handumdrehen erstellt werden kann, da wir selten lesen. Daher speichern wir in der relationalen PostgreSQL-Datenbank die Adjazenzliste unserer IDs in Form einer einfachen Platte mit zwei Spalten und einem Index für beide. Wenn die Anforderung eintrifft, umgehen wir das Konnektivitätsdiagramm mithilfe des bekannten DFS-Algorithmus (Tiefenüberquerung) und erhalten alle zugehörigen IDs. Das ist aber notwendig.
Datenrotation ist auch leicht zu lösen. Für jeden Tag starten wir eine neue Platte und nach einigen Tagen, wenn die Zeit gekommen ist, löschen wir sie und geben die Daten frei. Eine einfache Lösung.
Wir haben jetzt 850 Millionen Verbindungen in PostgreSQL, sie belegen 100 GB Festplatte. Wir schreiben dort mit einer Geschwindigkeit von 30.000 pro Sekunde, und dafür gibt es in der Datenbank nur zwei VMs mit 2 CPUs und 6 GB RAM. Bei Bedarf kann PostgreSQL Longs schnell schreiben.
Es gibt noch kleine Maschinen für den Service selbst, die sich drehen und steuern.
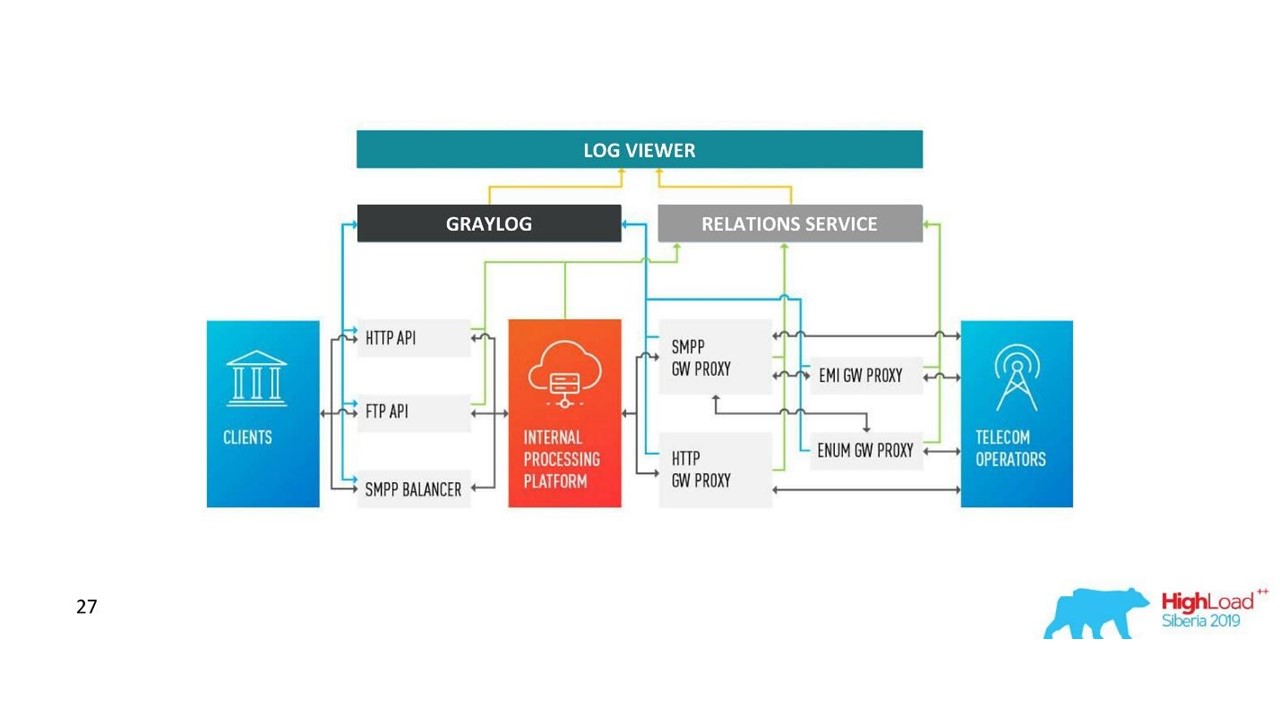 Wie sich unsere Architektur verändert hat.
Wie sich unsere Architektur verändert hat.Herausforderungen mit Graylog
Das Unternehmen wuchs, neue Rechenzentren entstanden, die Auslastung nahm auch bei einer Lösung mit Kommunikationsprotokollen spürbar zu. Wir dachten, dass Graylog nicht mehr perfekt ist.
Einheitliches Schema und Zentralisierung . Ich hätte gerne ein einziges Cluster-Management-Tool in 10 Rechenzentren. Außerdem stellte sich die Frage nach einem einheitlichen Datenabbildungsschema, damit es nicht zu Kollisionen kam.
API Wir verwenden unsere eigene Oberfläche, um die Verbindungen zwischen den Protokollen und der Standard-Graylog-API anzuzeigen. Dies war nicht immer praktisch, wenn Sie beispielsweise Daten aus verschiedenen Rechenzentren anzeigen, korrekt sortieren und markieren müssen. Daher wollten wir die API nach Belieben ändern können.
Leistung ist es schwierig, den Verlust einzuschätzen . Unser Verkehr beträgt 3 TB Protokolle pro Tag, was anständig ist. Daher arbeitete Graylog nicht immer stabil, es war notwendig, in sein Inneres einzudringen, um die Ursachen von Fehlern zu verstehen. Es stellte sich heraus, dass wir es nicht mehr als Werkzeug verwendeten - wir mussten etwas dagegen tun.
Verarbeitungsverzögerungen (Warteschlangen) . Die Standardimplementierung der Warteschlange in Graylog hat uns nicht gefallen.
Die Notwendigkeit, MongoDB zu unterstützen . Graylog schleppt MongoDB, es war notwendig, auch dieses System zu verwalten.
Wir haben erkannt, dass wir zu diesem Zeitpunkt unsere eigene Lösung wollen. Vielleicht gibt es weniger coole Funktionen für Warnungen, die nicht für Dashboards verwendet wurden, aber ihre eigenen sind besser.
Unsere Entscheidung
Wir haben unseren eigenen Protokolldienst entwickelt.
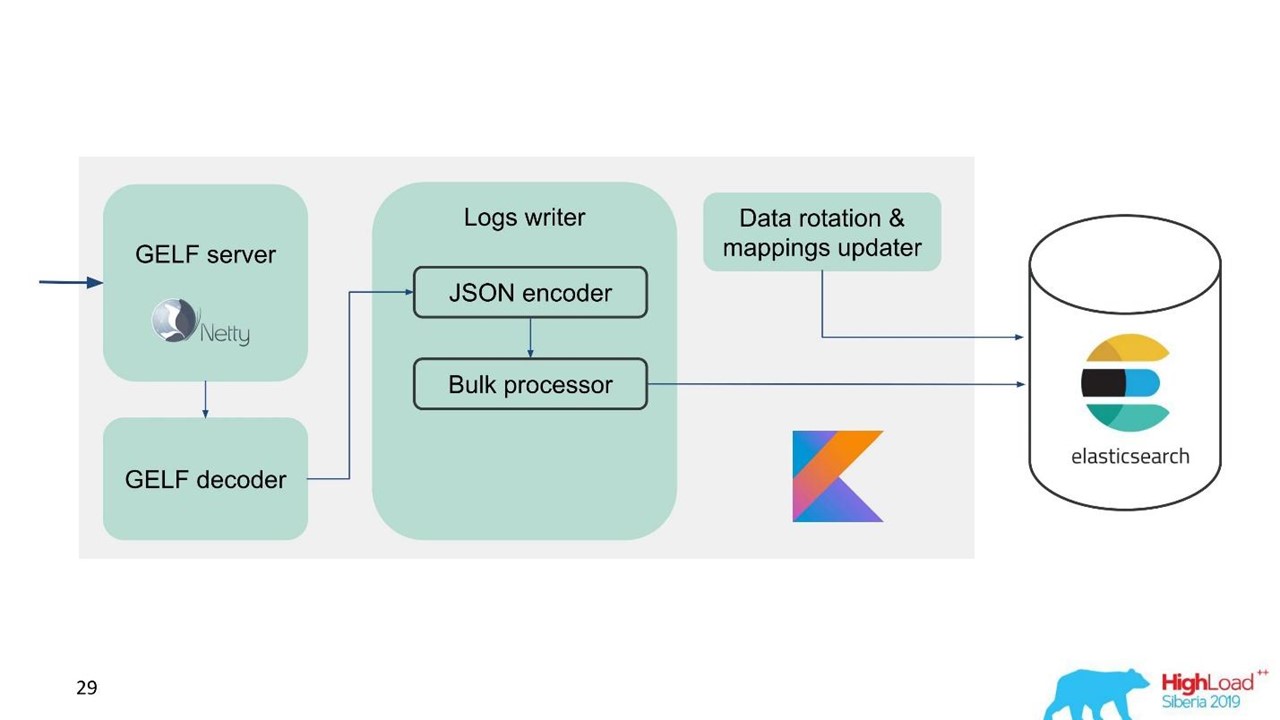 Protokolldienst.
Protokolldienst.Zu diesem Zeitpunkt hatten wir bereits Erfahrung in der Wartung und Instandhaltung großer Elasticsearch-Cluster, daher haben wir Elasticsearch als Grundlage genommen. Der Standard-Stack im Unternehmen ist JVM, aber für das Backend verwenden wir auch Kotlin, weshalb wir diese Sprache für den Service verwendet haben.
Die erste Frage ist, wie Daten gedreht werden und was mit der Zuordnung zu tun ist. Wir verwenden festes Mapping. In Elasticsearch ist es besser, Indizes gleicher Größe zu haben. Aber mit solchen Indizes müssen wir Daten irgendwie abbilden, insbesondere für mehrere Rechenzentren, ein verteiltes System und einen verteilten Zustand. Es gab Ideen, um ZooKeeper zu befestigen, aber dies ist wiederum eine Komplikation von Wartung und Code.
Deshalb haben wir uns einfach entschieden - pünktlich schreiben.
Ein Index für eine Stunde, in anderen Rechenzentren 2 Indizes für eine Stunde, im dritten Index für 3 Stunden, jedoch alle rechtzeitig. Indizes werden in verschiedenen Größen erhalten, da nachts weniger Verkehr herrscht als tagsüber, aber im Allgemeinen funktioniert es. Die Erfahrung hat gezeigt, dass keine Komplikationen erforderlich sind.
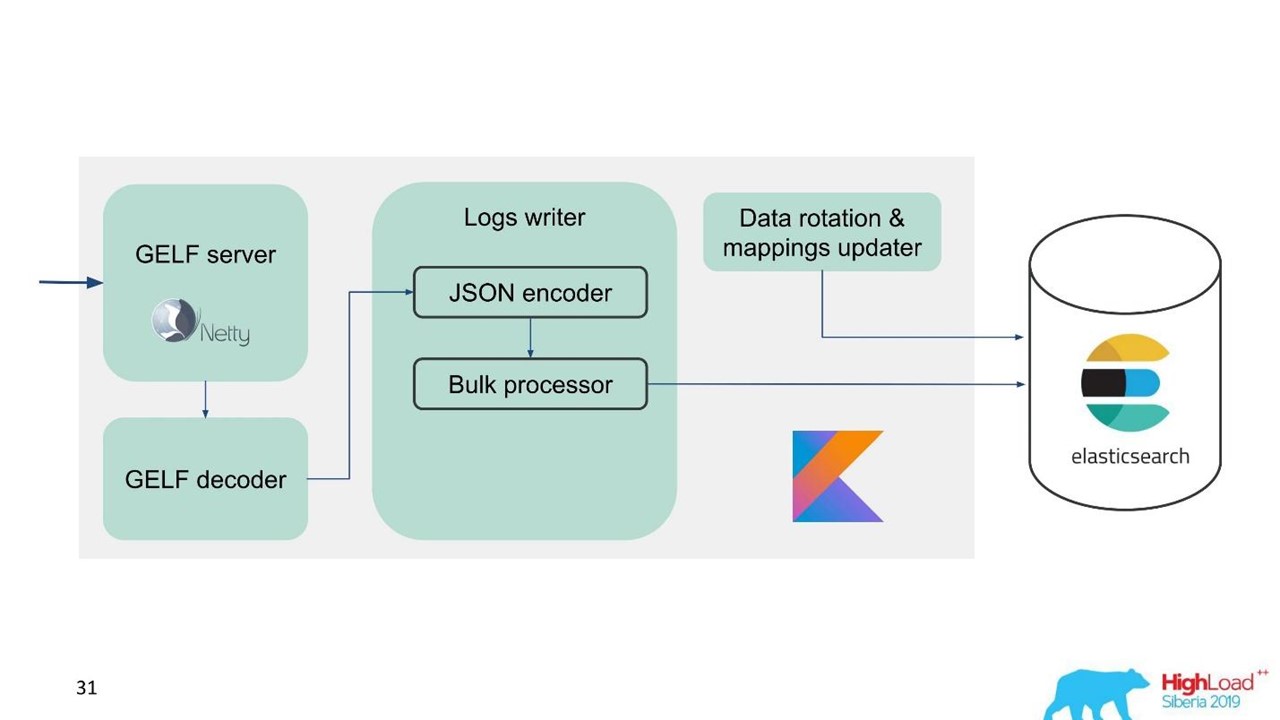
Um die Migration zu vereinfachen und die große Datenmenge zu berücksichtigen, haben wir das GELF-Protokoll gewählt, ein einfaches TCP-basiertes Graylog-Protokoll. Also haben wir einen GELF-Server für Netty und einen GELF-Decoder.
Dann wird JSON zum Schreiben in Elasticsearch codiert. Wir verwenden die offizielle Java-API von Elasticsearch und schreiben in Bulk.
Für eine hohe Aufnahmegeschwindigkeit müssen Sie Bulk'ami schreiben.
Dies ist eine wichtige Optimierung. Die API bietet einen Massenprozessor, der automatisch Anforderungen sammelt und diese dann zur Aufzeichnung in einem Bundle oder im Laufe der Zeit sendet.
Problem mit dem Massenprozessor
Alles scheint in Ordnung zu sein. Aber wir begannen und stellten fest, dass wir uns auf dem Massenprozessor ausruhten - es war unerwartet. Wir können die Werte, auf die wir zählen, nicht erreichen - das Problem kam aus dem Nichts.
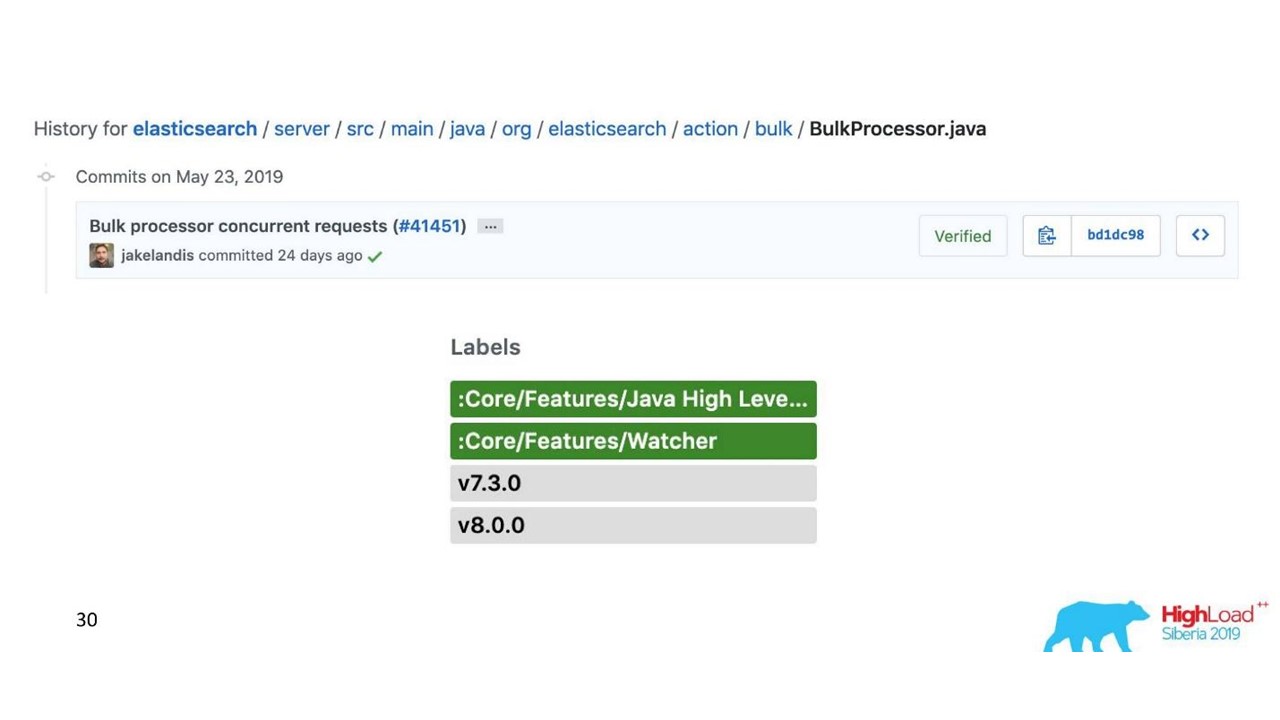
In der Standardimplementierung ist der Massenprozessor Single-Threaded, synchron, obwohl eine Parallelitätseinstellung vorhanden ist. Das war das Problem.
Wir stöberten herum und es stellte sich heraus, dass dies ein bekannter, aber nicht behobener Fehler ist. Wir haben den Massenprozessor ein wenig geändert - eine explizite Sperre durch ReentrantLock vorgenommen. Erst im Mai wurden ähnliche Änderungen am offiziellen Elasticsearch-Repository vorgenommen, die erst ab Version 7.3 verfügbar sein werden. Die aktuelle Version ist 7.1 und wir verwenden Version 6.3.
Wenn Sie auch mit einem Massenprozessor arbeiten und einen Eintrag in Elasticsearch übertakten möchten, sehen Sie sich diese
Änderungen auf GitHub an und portieren Sie zurück zu Ihrer Version. Änderungen betreffen nur den Massenprozessor. Es gibt keine Schwierigkeiten, wenn Sie auf die unten stehende Version portieren müssen.
Alles ist in Ordnung, der Bulk-Prozessor ist weg, die Geschwindigkeit hat sich beschleunigt.
Die Schreibleistung von Elasticsearch ist im Laufe der Zeit instabil, da dort verschiedene Vorgänge stattfinden: Zusammenführen von Indizes, Flush. Außerdem verlangsamt sich die Leistung während der Wartung für eine Weile, wenn beispielsweise ein Teil der Knoten aus dem Cluster entfernt wird.
In diesem Zusammenhang haben wir erkannt, dass wir nicht nur den Puffer im Speicher, sondern auch die Warteschlange implementieren müssen. Wir haben beschlossen, nur abgelehnte Nachrichten an die Warteschlange zu senden - nur solche, die der Massenprozessor nicht in Elasticsearch schreiben konnte.
Wiederholen Sie den Fallback
Dies ist eine einfache Implementierung.
- Wir speichern die abgelehnten Nachrichten in der Datei -
RejectedExecutionHandler .
- In dem angegebenen Intervall in einem separaten Executor erneut einreichen.
- Wir verzögern jedoch keinen neuen Verkehr.
Für Supportingenieure und Entwickler ist der neue Datenverkehr im System deutlich wichtiger als der, der aus irgendeinem Grund während des Anstiegs oder der Verlangsamung von Elasticsearch verzögert wurde. Er verweilte, aber er würde später kommen - keine große Sache. Neuer Verkehr wird priorisiert.
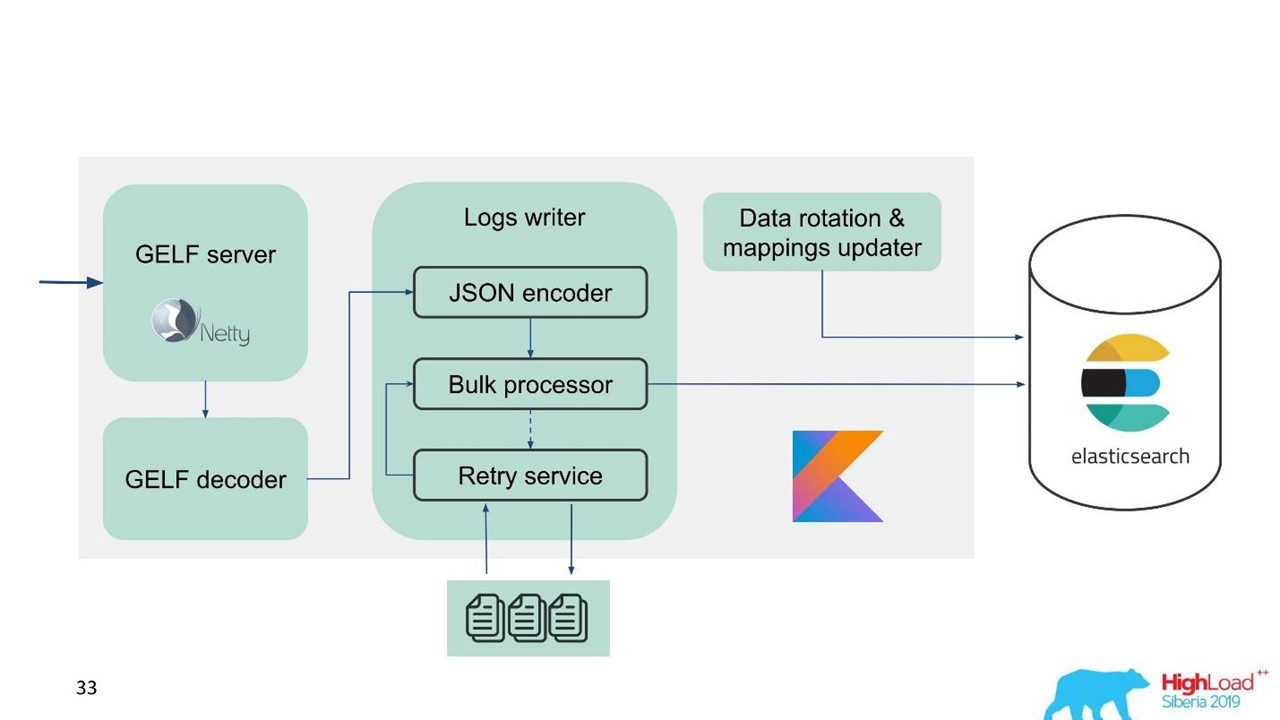 Unser Plan sah so aus.
Unser Plan sah so aus.Lassen Sie uns nun darüber sprechen, wie wir Elasticsearch vorbereiten, welche Parameter wir verwendet und wie wir eingerichtet haben.
Elasticsearch-Konfiguration
Das Problem, mit dem wir konfrontiert sind, ist die Notwendigkeit, Elasticsearch zu übertakten und für das Schreiben zu optimieren, da die Anzahl der Messwerte merklich geringer ist.
Wir haben mehrere Parameter verwendet.
"ignore_malformed": true -
Felder mit dem falschen Typ und nicht das gesamte Dokument verwerfen . Wir möchten die Daten weiterhin speichern, auch wenn aus irgendeinem Grund Felder mit falscher Zuordnung dort durchgesickert sind. Diese Option hängt nicht vollständig mit der Leistung zusammen.
Für Eisen hat Elasticsearch eine Nuance. Als wir nach großen Clustern fragten, wurde uns gesagt, dass RAID-Arrays von SSD-Laufwerken für Ihre Volumes furchtbar teuer sind. Arrays werden jedoch nicht benötigt, da Fehlertoleranz und Partitionierung bereits in Elasticsearch integriert sind. Sogar auf der offiziellen Website gibt es eine Empfehlung, mehr billiges Eisen als weniger teuer und gut zu nehmen. Dies gilt sowohl für Festplatten als auch für die Anzahl der Prozessorkerne, da die gesamte Elasticsearch sehr gut parallel ist.
"index.merge.scheduler.max_thread_count": 1 -
empfohlen für HDD .
Wenn Sie keine SSDs, sondern normale Festplatten erhalten haben, setzen Sie diesen Parameter auf eins. Indizes werden in Stücke geschrieben, dann werden diese Stücke eingefroren. Dies spart ein wenig Festplatte, beschleunigt aber vor allem die Suche. Wenn Sie aufhören, in den Index zu schreiben, können Sie auch das
force merge . Wenn die Belastung des Clusters geringer ist, friert er automatisch ein.
"index.unassigned.node_left.delayed_timeout": "5m" -
Verzögerung der Bereitstellung, wenn ein Knoten verschwindet . Dies ist die Zeit, nach der Elasticsearch mit der Implementierung von Indizes und Daten beginnt, wenn ein Knoten neu gestartet, bereitgestellt oder zur Wartung zurückgezogen wird. Wenn die Festplatte und das Netzwerk jedoch stark belastet sind, ist die Bereitstellung schwierig. Um sie nicht zu überlasten, ist es besser, diese Zeitüberschreitung zu steuern und zu verstehen, welche Verzögerungen erforderlich sind.
"index.refresh_interval": -1 -
Indizes nicht aktualisieren, wenn keine Suchanfragen vorhanden sind . Der Index wird dann aktualisiert, wenn eine Suchabfrage angezeigt wird. Dieser Index kann in Sekunden und Minuten eingestellt werden.
"index.translogDurability": "async" - wie oft fsync ausgeführt werden soll: bei jeder Anforderung oder nach Zeit. Bietet Leistungssteigerungen für langsame Laufwerke.
Wir haben auch eine interessante Möglichkeit, es zu verwenden. Support und Entwickler möchten in der Lage sein, im gesamten Nachrichtentext im Volltext zu suchen und regexp'ov zu verwenden. In Elasticsearch ist dies jedoch nicht möglich - es kann nur nach Token gesucht werden, die bereits in seinem System vorhanden sind. RegExp und Platzhalter können verwendet werden, aber das Token kann nicht mit RegExp beginnen. Deshalb haben wir dem Filter
word_delimiter hinzugefügt:
"tokenizer": "standard" "filter" : [ "word_delimiter" ]
Es teilt Wörter automatisch in Token auf:
- "Wi-Fi" → "Wi", "Fi";
- "PowerShot" → "Power", "Shot";
- "SD500" → "SD", "500".
In ähnlicher Weise wird der Name der Klasse geschrieben, verschiedene Debugging-Informationen. Damit haben wir einige Probleme mit der Volltextsuche geschlossen. Ich empfehle Ihnen, solche Einstellungen hinzuzufügen, wenn Sie mit dem Login arbeiten.
Über den Cluster
Die Anzahl der Shards sollte der Anzahl der Datenknoten für den Lastausgleich entsprechen . Die Mindestanzahl von Replikaten beträgt 1, dann hat jeder Knoten einen Haupt-Shard und ein Replikat. Wenn Sie jedoch über wertvolle Daten verfügen, z. B. Finanztransaktionen, ist es besser, zwei oder mehr zu verwenden.
Die Größe des Shards liegt zwischen einigen GB und einigen zehn GB . Die Anzahl der Shards auf einem Knoten beträgt natürlich nicht mehr als 20 pro 1 GB Elasticsearch-Hüfte. Weitere Elasticsearch verlangsamt sich - wir haben es auch angegriffen. In Rechenzentren mit wenig Datenverkehr drehten sich die Daten nicht im Volumen, es wurden Tausende von Indizes angezeigt und das System stürzte ab.
Verwenden Sie das allocation awareness beispielsweise mit dem Namen eines Hypervisors im Servicefall. Hilft dabei, Indizes und Shards über verschiedene Hypervisoren zu streuen, damit sie sich nicht überlappen, wenn ein Hypervisor ausfällt.
Erstellen Sie vorher Indizes . Gute Praxis, besonders wenn Sie pünktlich schreiben. Der Index ist sofort heiß, bereit und es gibt keine Verzögerungen.
Begrenzen Sie die Anzahl der Shards eines Index pro Knoten .
"index.routing.allocation.total_shards_per_node": 4 ist die maximale Anzahl von Shards eines Index pro Knoten. Im Idealfall gibt es 2 davon, wir setzen 4 für alle Fälle, wenn wir noch weniger Autos haben.
Was ist das Problem hier? Wir verwenden das
allocation awareness - Elasticsearch weiß, wie Indizes richtig auf Hypervisoren verteilt werden. Wir haben jedoch festgestellt, dass Elasticsearch nach längerem Ausschalten des Knotens und anschließender Rückkehr zum Cluster feststellt, dass formal weniger Indizes vorhanden sind und diese wiederhergestellt werden. Bis die Daten synchronisiert sind, gibt es formal nur wenige Indizes auf dem Knoten. Weisen Sie bei Bedarf einen neuen Index zu. Elasticsearch versucht, diese Maschine mit neuen Indizes so dicht wie möglich zu hämmern. Ein Knoten wird also nicht nur dadurch belastet, dass Daten auf ihn repliziert werden, sondern auch durch neuen Datenverkehr, Indizes und neue Daten, die auf diesen Knoten fallen. Kontrolliere und beschränke es.
Wartungsempfehlungen für Elasticsearch
Diejenigen, die mit Elasticsearch arbeiten, sind mit diesen Empfehlungen vertraut.
Wenden Sie während der geplanten Wartung die Empfehlungen für ein fortlaufendes Upgrade an: Deaktivieren Sie die Shard-Zuordnung, synchronisiertes Flush.
Deaktivieren Sie die Shard-Zuordnung . Deaktivieren Sie die Zuweisung von Replikatsplittern, und lassen Sie die Möglichkeit, nur primäre zuzuweisen. Dies hilft Elasticsearch spürbar - es werden keine Daten neu zugewiesen, die Sie nicht benötigen. Sie wissen zum Beispiel, dass der Knoten in einer halben Stunde ansteigt - warum alle Shards von einem Knoten auf einen anderen übertragen? Es passiert nichts Schreckliches, wenn Sie eine halbe Stunde mit dem gelben Cluster leben, wenn nur primäre Scherben verfügbar sind.
Synchronisiert bündig . In diesem Fall synchronisiert sich der Knoten viel schneller, wenn er zum Cluster zurückkehrt.
Mit einer hohen Belastung beim Schreiben in den Index oder bei der Wiederherstellung können Sie die Anzahl der Replikate reduzieren.
Wenn Sie eine große Datenmenge herunterladen, z. B. Spitzenlast, können Sie Shards deaktivieren und später Elasticsearch einen Befehl geben, diese zu erstellen, wenn die Last bereits geringer ist.
Hier sind einige Befehle, die ich gerne benutze:
GET _cat/thread_pool?v - ermöglicht es Ihnen, thread_pool auf jedem Knoten thread_pool : Was ist jetzt angesagt, was sind die Schreib- und Lesewarteschlangen.
GET _cat/recovery/?active_only=true - GET _cat/recovery/?active_only=true Indizes werden wo bereitgestellt, wo die Wiederherstellung stattfindet GET _cat/recovery/?active_only=true
GET _cluster/allocation/explain - in einer praktischen menschlichen Form, warum und welche Indizes oder Replikate nicht zugewiesen wurden.
Zur Überwachung verwenden wir Grafana.
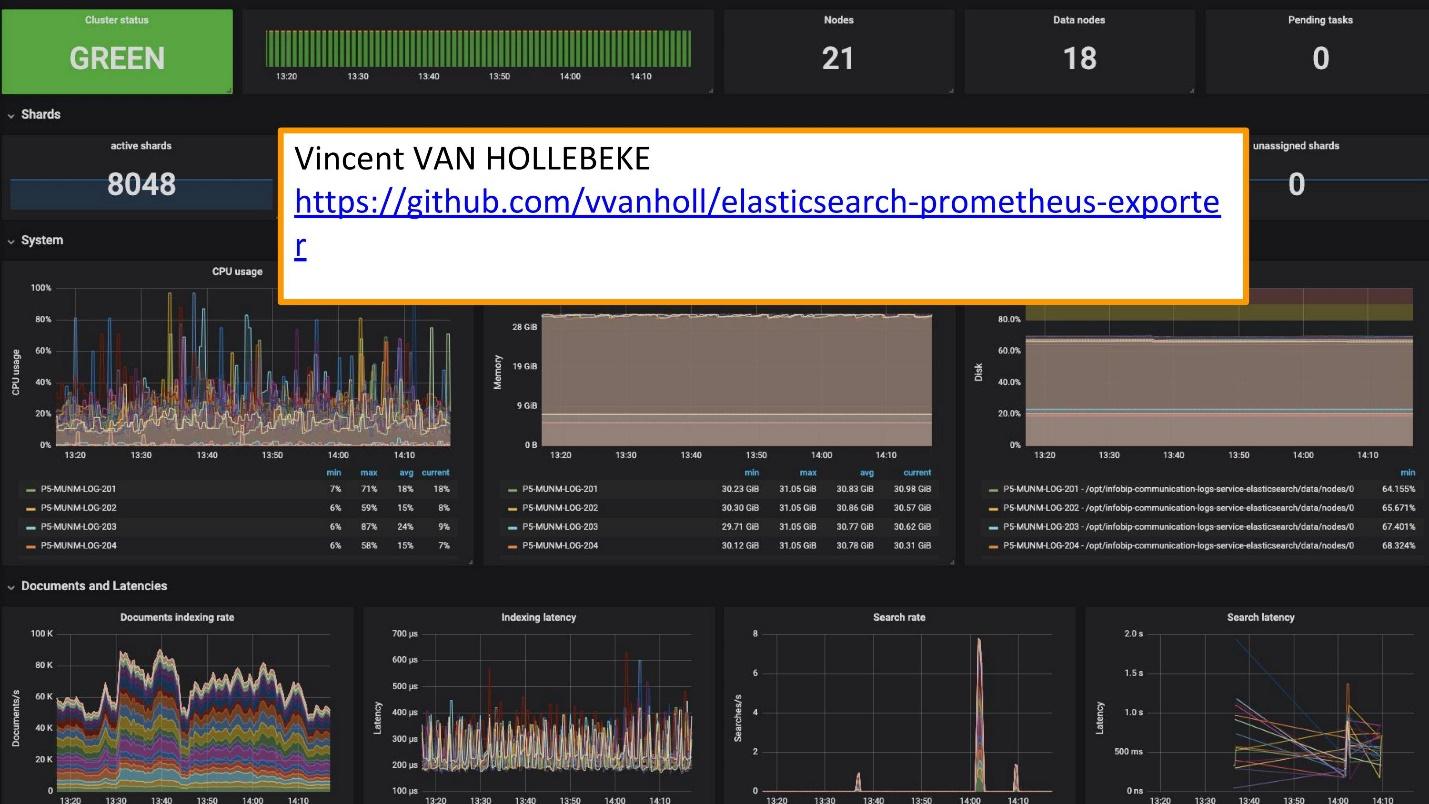
Es gibt einen exzellenten
Exporteur und Grafana-Teamplay von
Vincent van Hollebeke , mit dem Sie den Status des Clusters und alle seine Hauptparameter visuell sehen können. Wir haben es unserem Docker-Image und allen Metriken hinzugefügt, wenn wir es von unserer Box aus bereitstellen.
Schlussfolgerungen zur Protokollierung
Protokolle sollten sein:
- zentralisiert - ein einziger Einstiegspunkt für Entwickler;
- verfügbar - die Fähigkeit zur schnellen Suche;
- strukturiert - zur schnellen und bequemen Extraktion wertvoller Informationen;
- korreliert - nicht nur untereinander, sondern auch mit anderen Metriken und Systemen, die Sie verwenden.
Der schwedische
Melodifestivalen- Wettbewerb wurde kürzlich abgehalten. Dies ist eine Auswahl von Vertretern aus Schweden für Eurovision. Vor dem Wettbewerb hat uns unser Support-Service kontaktiert: „Jetzt wird es in Schweden eine große Ladung geben. Der Verkehr ist sehr sensibel und wir möchten einige Daten korrelieren. Sie haben Daten in den Protokollen, die im Grafana-Dashboard fehlen. Wir haben Metriken, die Prometheus entnommen werden können, aber wir benötigen Daten zu bestimmten ID-Anforderungen. “
Sie fügten Elasticsearch als Quelle für Grafana hinzu und konnten diese Daten korrelieren, das Problem schließen und schnell genug gute Ergebnisse erzielen.
Das Ausnutzen eigener Lösungen ist viel einfacher.
Anstelle der 10 Graylog-Cluster, die für diese Lösung verwendet wurden, haben wir jetzt mehrere Dienste. Dies sind 10 Rechenzentren, aber wir haben nicht einmal ein engagiertes Team und Leute, die sie bedienen. Es gibt mehrere Leute, die an ihnen gearbeitet haben und nach Bedarf etwas ändern. Dieses kleine Team ist perfekt in unsere Infrastruktur integriert - Bereitstellung und Wartung sind einfacher und billiger.
Trennen Sie Fälle und verwenden Sie geeignete Werkzeuge.
Dies sind separate Tools zum Protokollieren, Nachverfolgen und Überwachen. Es gibt kein „goldenes Instrument“, das alle Ihre Bedürfnisse abdeckt.
Um zu verstehen, welches Tool benötigt wird, was überwacht werden muss, wo die Protokolle verwendet werden sollen, welche Anforderungen an die Protokolle gestellt werden, sollten Sie sich unbedingt an
SLI / SLO - Service Level Indicator / Service Level Objective wenden. Sie müssen wissen, was für Ihre Kunden und Ihr Unternehmen wichtig ist und welche Indikatoren sie betrachten.
Eine Woche später wird SKOLKOVO HighLoad ++ 2019 hosten . Am Abend des 7. November wird Ivan Letenko Ihnen erzählen, wie er mit Redis auf dem Produkt lebt. Insgesamt stehen 150 Berichte zu verschiedenen Themen im Programm .
Wenn Sie Probleme haben, HighLoad ++ 2019 live zu besuchen, haben wir gute Nachrichten. In diesem Jahr findet die Konferenz in drei Städten gleichzeitig statt - in Moskau, Nowosibirsk und St. Petersburg. Zur gleichen Zeit. Wie es sein wird und wie man dorthin kommt - erfahren Sie auf einer separaten Promo-Seite der Veranstaltung.