Die Leistungsfähigkeit von JavaScript und der Browser-APIDie Welt wird immer vernetzter - die Zahl der Menschen mit Internetzugang ist auf
4,5 Milliarden gestiegen.
Diese Daten geben jedoch nicht die Anzahl der Personen wieder, die eine langsame oder unterbrochene Internetverbindung haben. Selbst in den USA können
4,9 Millionen Haushalte nicht mit einer Geschwindigkeit von über 3 Megabit pro Sekunde auf den kabelgebundenen Internetzugang zugreifen.
Der Rest der Welt - diejenigen mit zuverlässigem Internetzugang - neigt immer noch dazu, die Konnektivität zu verlieren.
Einige Faktoren , die die Qualität Ihrer Netzwerkverbindung beeinflussen können, sind:
- Schlechte Abdeckung durch den Anbieter.
- Extreme Wetterbedingungen.
- Stromausfälle.
- Benutzer, die in tote Zonen fallen, z. B. Gebäude, die ihre Netzwerkverbindungen blockieren.
- Zugfahrt und Tunnelfahrt.
- Verbindungen, die von Dritten gesteuert werden und zeitlich begrenzt sind.
- Kulturelle Praktiken, die zu bestimmten Zeiten oder Tagen einen eingeschränkten oder keinen Internetzugang erfordern.
Angesichts dessen ist es klar, dass wir bei der Entwicklung und Erstellung von Anwendungen autonome Erfahrungen berücksichtigen müssen.

Dieser Artikel wurde mit Unterstützung von EDISON Software übersetzt, einem Unternehmen, das hervorragende Aufträge aus Südchina ausführt und auch Webanwendungen und Websites entwickelt .
Ich hatte kürzlich die Möglichkeit, einer vorhandenen Anwendung mithilfe von Servicemitarbeitern, Cache-Speicher und IndexedDB Autonomie hinzuzufügen. Die technische Arbeit, die erforderlich ist, damit die Anwendung offline funktioniert, wurde auf vier separate Aufgaben reduziert, auf die ich in diesem Beitrag eingehen werde.
Service-Arbeiter
Anwendungen, die für die Offline-Verwendung erstellt wurden, sollten nicht stark netzwerkabhängig sein. Konzeptionell ist dies nur möglich, wenn im Fehlerfall Sicherungsoptionen vorhanden sind.
Wenn die Webanwendung nicht geladen werden kann, müssen wir die Ressourcen für den Browser irgendwo (HTML / CSS / JavaScript) verwenden. Woher kommen diese Ressourcen, wenn nicht von einer Netzwerkanforderung? Wie wäre es mit einem Cache. Die meisten Menschen würden zustimmen, dass es besser ist, eine möglicherweise veraltete Benutzeroberfläche bereitzustellen als eine leere Seite.
Der Browser fragt ständig Daten ab. Der Daten-Caching-Dienst als Fallback erfordert weiterhin, dass wir Browseranforderungen abfangen und Caching-Regeln schreiben. Hier kommen Servicemitarbeiter ins Spiel - betrachten Sie sie als Vermittler.
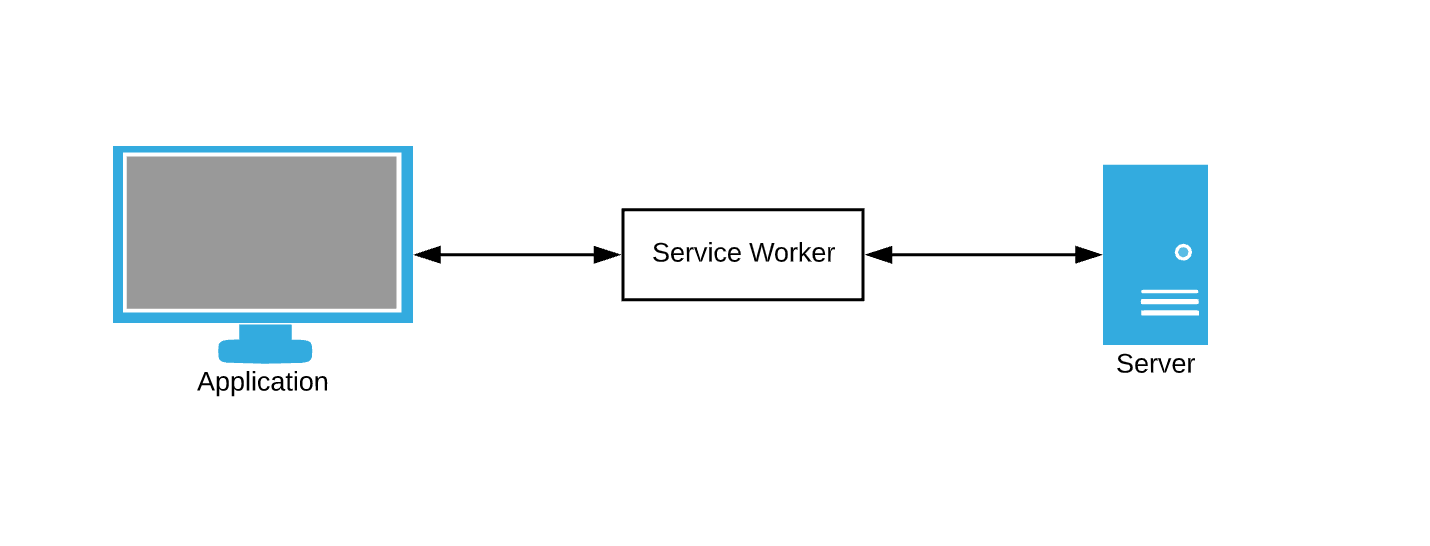
Service Worker ist nur eine JavaScript-Datei, in der wir Ereignisse abonnieren und unsere eigenen Regeln für das Zwischenspeichern und Behandeln von Netzwerkfehlern schreiben können.
Fangen wir an.
Bitte beachten Sie: unsere Demo-AnwendungIn diesem Beitrag werden wir der Demo-Anwendung eigenständige Funktionen hinzufügen. Die Demo-Anwendung ist eine einfache Seite zum Aufnehmen / Ausleihen von Büchern in der Bibliothek. Der Fortschritt wird als eine Reihe von GIFs und die Verwendung von Offline-Chrome DevTools-Simulationen dargestellt.
Hier ist der Ausgangszustand:
Aufgabe 1 - Zwischenspeichern statischer Ressourcen
Statische Ressourcen sind Ressourcen, die sich nicht häufig ändern. HTML, CSS, JavaScript und Bilder können in diese Kategorie fallen. Der Browser versucht, statische Ressourcen mithilfe von Anforderungen zu laden, die vom Servicemitarbeiter abgefangen werden können.
Beginnen wir mit der Registrierung unseres Servicemitarbeiters.
if ('serviceWorker' in navigator) { window.addEventListener('load', function() { navigator.serviceWorker.register('/sw.js'); }); }
Servicemitarbeiter sind
Web-Worker unter der Haube und müssen daher aus einer separaten JavaScript-Datei importiert werden. Die Registrierung erfolgt nach dem Laden der Site mit der
register .
Nachdem wir einen Servicemitarbeiter geladen haben, lassen Sie uns unsere statischen Ressourcen zwischenspeichern.
var CACHE_NAME = 'my-offline-cache'; var urlsToCache = [ '/', '/static/css/main.c9699bb9.css', '/static/js/main.99348925.js' ]; self.addEventListener('install', function(event) { event.waitUntil( caches.open(CACHE_NAME) .then(function(cache) { return cache.addAll(urlsToCache); }) ); });
Da wir die URLs statischer Ressourcen steuern, können wir sie unmittelbar nach der Initialisierung des Servicemitarbeiters mithilfe von
Cache Storage .
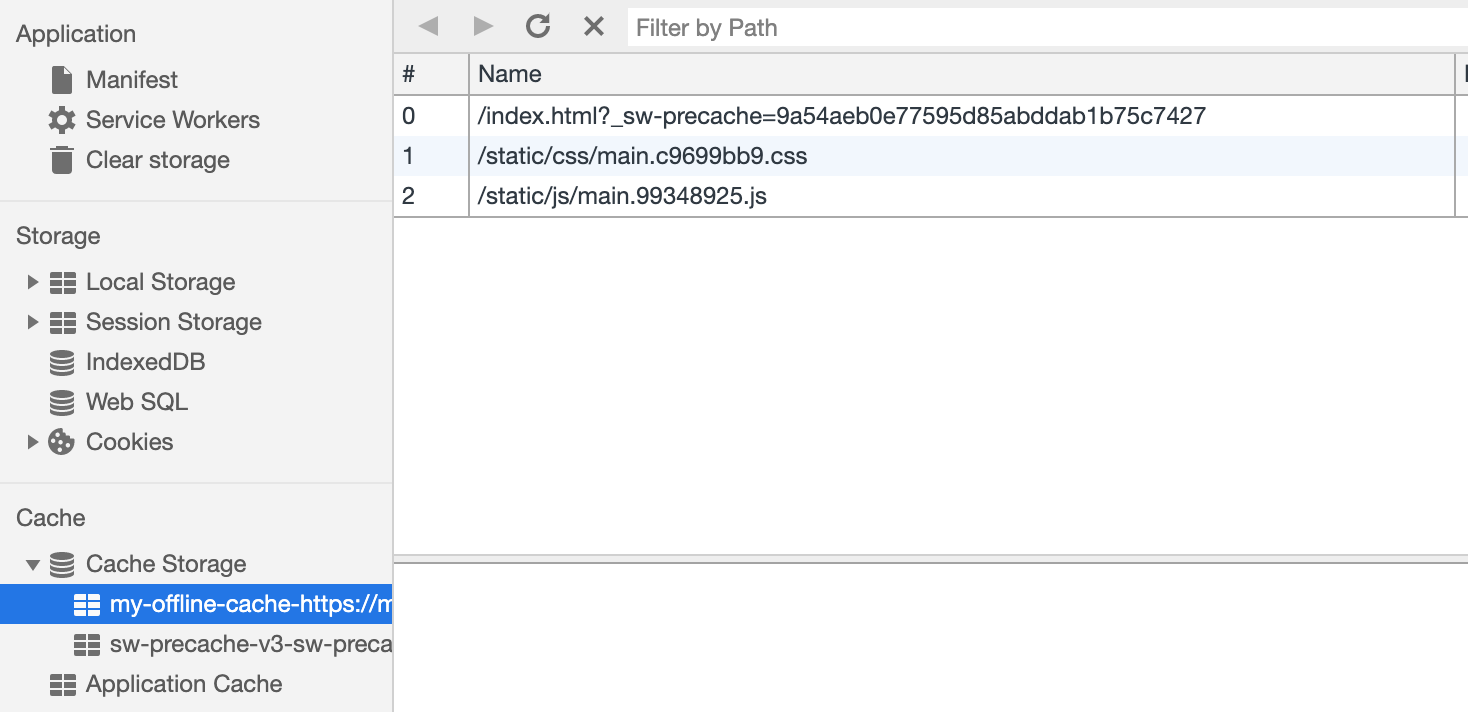
Nachdem unser Cache nun mit den zuletzt angeforderten statischen Ressourcen gefüllt ist, laden wir diese Ressourcen im Falle eines Anforderungsfehlers aus dem Cache.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Das
fetch wird jedes Mal ausgelöst, wenn der Browser eine Anforderung stellt. Unser neuer
fetch verfügt jetzt über eine zusätzliche Logik für die Rückgabe zwischengespeicherter Antworten bei Netzwerkausfällen.
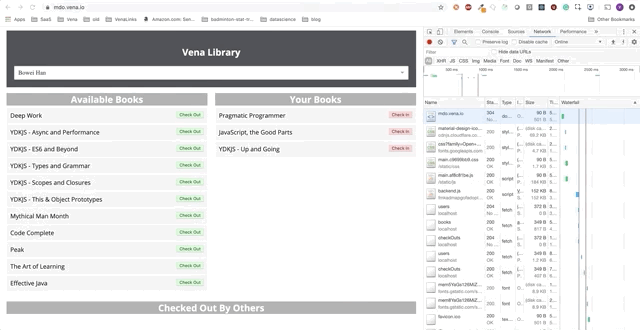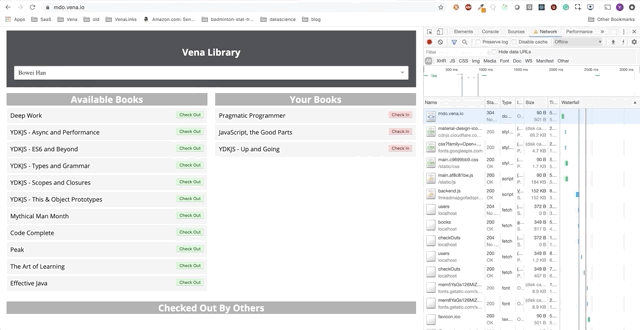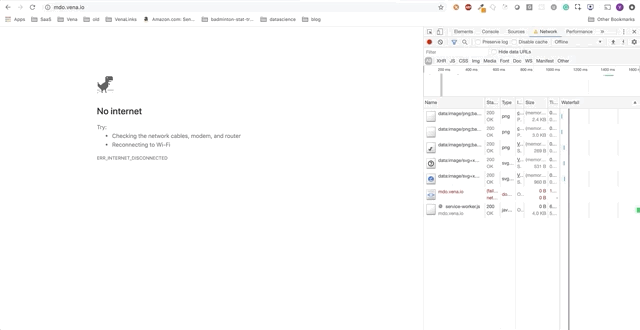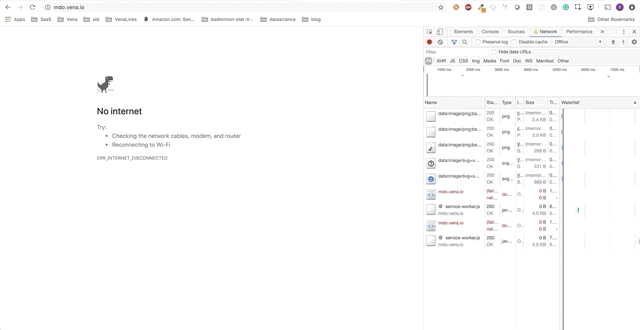
Demo Nummer 1
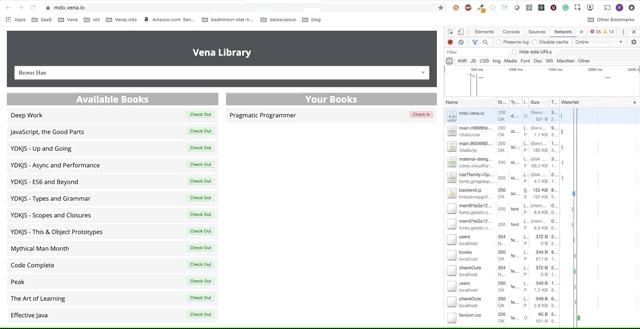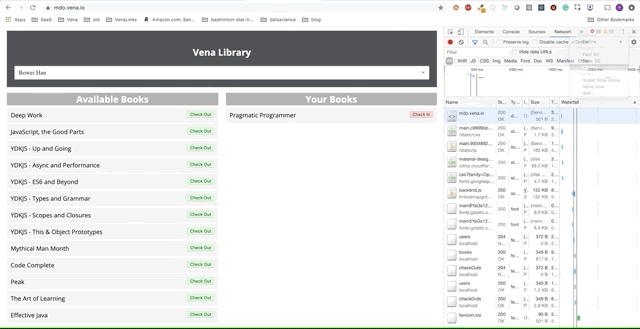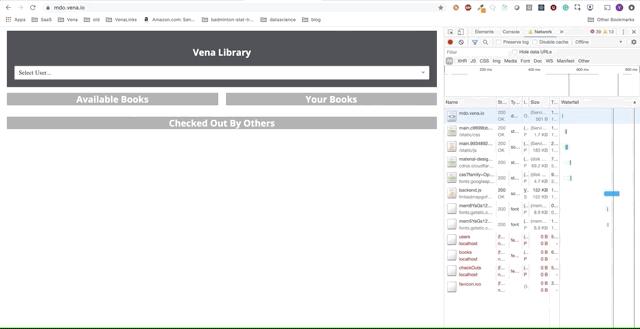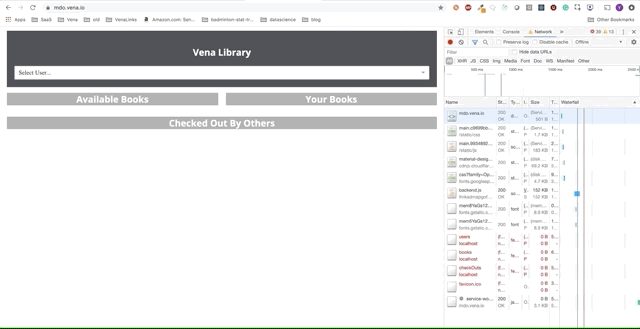
Unsere Demo-Anwendung kann jetzt statische Ressourcen offline bereitstellen! Aber wo sind unsere Daten?
Aufgabe 2 - Zwischenspeichern dynamischer Ressourcen
Single-Page-Anwendungen (SPA) fordern normalerweise nach dem ersten Laden der Seite schrittweise Daten an, und unsere Demo-Anwendung ist keine Ausnahme - die Liste der Bücher wird nicht sofort geladen. Diese Daten stammen normalerweise aus XHR-Anforderungen, die Antworten zurückgeben, die sich häufig ändern, um einen neuen Status für die Anwendung bereitzustellen - daher sind sie dynamisch.
Das Zwischenspeichern dynamischer Ressourcen ist dem Zwischenspeichern statischer Ressourcen sehr ähnlich. Der Hauptunterschied besteht darin, dass der Cache häufiger aktualisiert werden muss. Das Generieren einer vollständigen Liste aller möglichen dynamischen XHR-Anforderungen ist ebenfalls recht schwierig. Daher werden sie bei ihrem Eintreffen zwischengespeichert und haben keine vordefinierte Liste, wie wir es für statische Ressourcen getan haben.
Schauen Sie sich unseren
fetch Handler an:
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Wir können diese Implementierung anpassen, indem wir Code hinzufügen, der erfolgreiche Anforderungen und Antworten zwischenspeichert. Dies stellt sicher, dass wir ständig neue Anforderungen zu unserem Cache hinzufügen und die zwischengespeicherten Daten ständig aktualisieren.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request) .then(function(response) { caches.open(CACHE_NAME).then(function(cache) { cache.put(event.request, response); }); }) .catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Unser
Cache Storage derzeit mehrere Einträge.

Demo Nummer 2
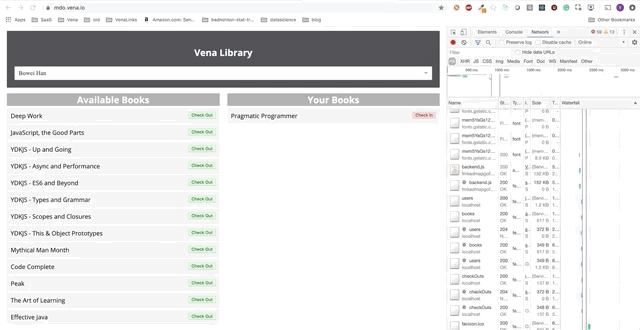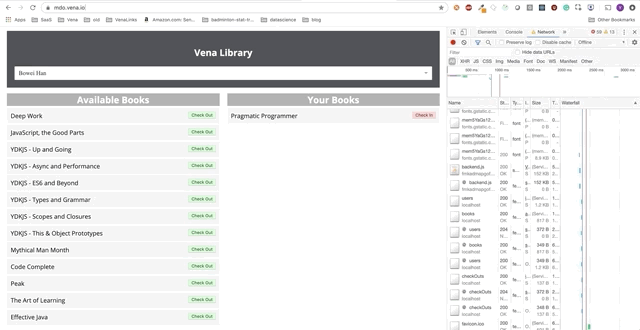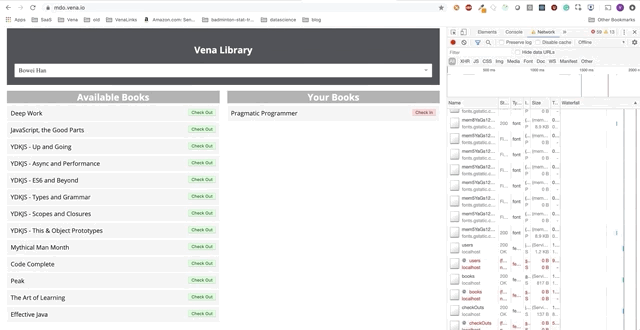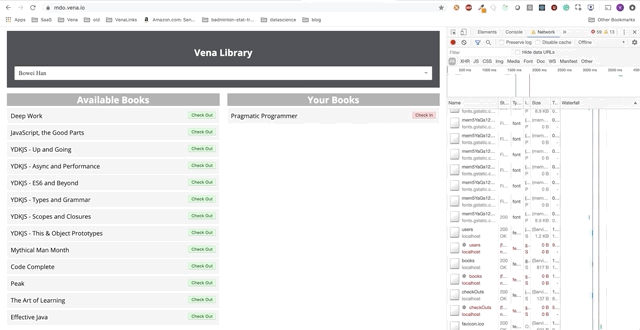
Unsere Demo sieht jetzt beim Booten gleich aus, unabhängig von unserem Netzwerkstatus!
Großartig. Versuchen wir nun, unsere Anwendung zu verwenden.
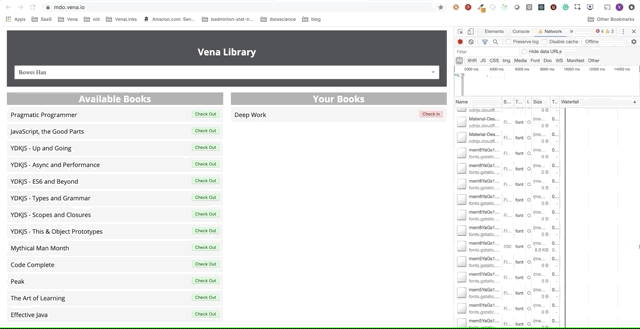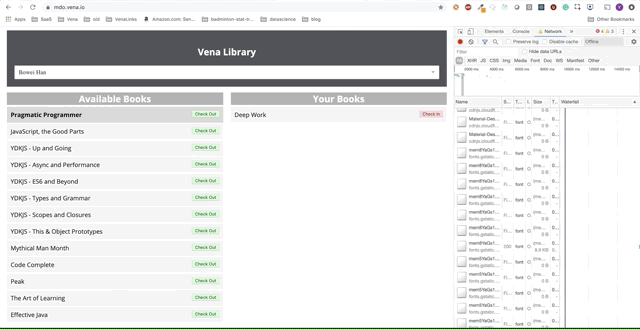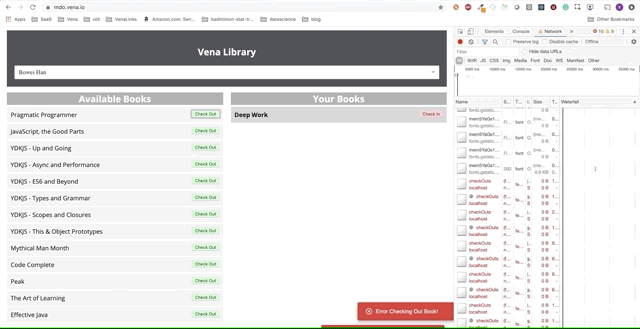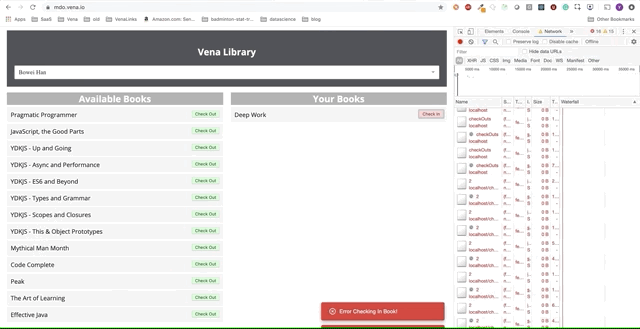
Leider gibt es überall Fehlermeldungen. Es scheint, dass alle unsere Interaktionen mit der Schnittstelle nicht funktionieren. Ich kann das Buch nicht auswählen oder übergeben! Was muss behoben werden?
Aufgabe 3 - Erstellen einer optimistischen Benutzeroberfläche
Derzeit besteht das Problem bei unserer Anwendung darin, dass unsere Datenerfassungslogik immer noch stark von Netzwerkantworten abhängt. Die Aktion zum Ein- und Auschecken sendet eine Anforderung an den Server und erwartet eine erfolgreiche Antwort. Dies ist gut für die Datenkonsistenz, aber schlecht für unsere Standalone-Erfahrung.
Damit diese Interaktionen offline funktionieren, müssen wir unsere Anwendung
optimistischer gestalten . Optimistische Interaktionen erfordern keine Antwort vom Server und zeigen bereitwillig eine aktualisierte Ansicht der Daten an. Der übliche optimistische Vorgang in den meisten Webanwendungen ist das
delete Geben Sie dem Benutzer sofort Feedback, wenn wir bereits über alle erforderlichen Informationen verfügen.
Das Trennen unserer Anwendung vom Netzwerk mithilfe eines optimistischen Ansatzes ist relativ einfach zu implementieren.
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
Der Schlüssel besteht darin, Benutzeraktionen auf dieselbe Weise zu behandeln - unabhängig davon, ob die Netzwerkanforderung erfolgreich ist oder nicht. Das obige Code-Snippet stammt aus dem Redux-Reduzierer unserer Anwendung.
SUCCESS und
FAILURE abhängig von der Verfügbarkeit des Netzwerks gestartet. Unabhängig davon, wie die Netzwerkanforderung abgeschlossen ist, werden wir unsere Bücherliste aktualisieren.
Demo Nummer 3
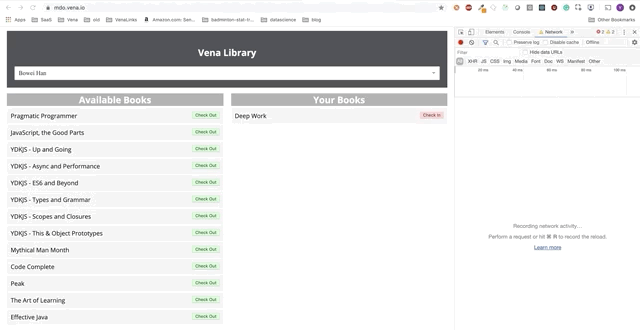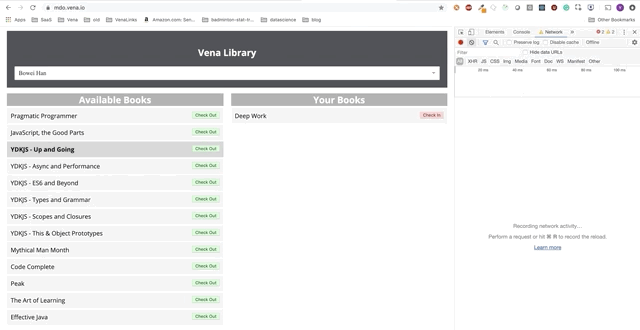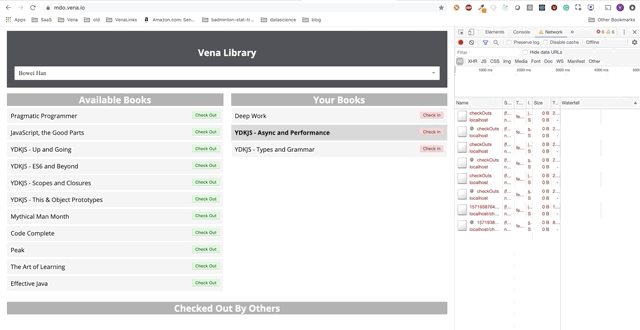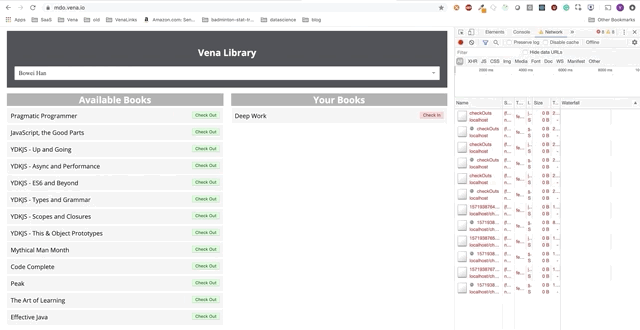
Die Benutzerinteraktion erfolgt jetzt online (nicht wörtlich). Die Schaltflächen "Einchecken" und "Auschecken" aktualisieren die Benutzeroberfläche entsprechend, obwohl die roten Meldungen der Konsole anzeigen, dass Netzwerkanforderungen nicht ausgeführt werden.
Gut! Es gibt nur ein kleines Problem mit optimistischem Offline-Rendering ...
Verlieren wir nicht unser Wechselgeld?

Aufgabe 4 - Benutzeraktionen für die Synchronisierung in die Warteschlange stellen
Wir müssen die Aktionen verfolgen, die der Benutzer ausgeführt hat, als er offline war, damit wir sie mit unserem Server synchronisieren können, wenn der Benutzer zum Netzwerk zurückkehrt. Es gibt verschiedene Speichermechanismen im Browser, die als Warteschlange für Aktionen fungieren können, und wir werden IndexedDB verwenden. IndexedDB bietet einige Dinge, die Sie von LocalStorage nicht erhalten:
- Asynchrone nicht blockierende Operationen
- Deutlich höhere Lagergrenzen
- Transaktionsmanagement
Schauen Sie sich unseren alten Reduziercode an:
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
Lassen Sie es uns ändern, um die Check-In- und Check-Out-Ereignisse während des
FAILURE -Ereignisses in IndexedDB zu speichern.
case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); addToDB(action);
Hier ist die Implementierung des Erstellens von IndexedDB zusammen mit dem addToDB-
addToDB .
let db = indexedDB.open('actions', 1); db.onupgradeneeded = function(event) { let db = event.target.result; db.createObjectStore('requests', { autoIncrement: true }); }; const addToDB = action => { var db = indexedDB.open('actions', 1); db.onsuccess = function(event) { var db = event.target.result; var objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.add(action); }; };
Nachdem alle unsere Offline-Benutzeraktionen im Speicher des Browsers gespeichert sind, können wir den Ereignis-Listener des
online Browsers verwenden, um Daten zu synchronisieren, wenn die Verbindung wiederhergestellt wird.
window.addEventListener('online', () => { const db = indexedDB.open('actions', 1); db.onsuccess = function(event) { let db = event.target.result; let objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.getAll().onsuccess = function(event) { let requests = event.target.result; for (let request of requests) { send(request);
In dieser Phase können wir die Warteschlange von allen Anforderungen löschen, die wir erfolgreich an den Server gesendet haben.
Demo Nummer 4
Die endgültige Demo sieht etwas komplizierter aus. Rechts im dunklen Terminalfenster werden alle API-Aktivitäten protokolliert. Die Demo beinhaltet das Offline-Gehen, das Auswählen mehrerer Bücher und das Online-Zurückkehren.
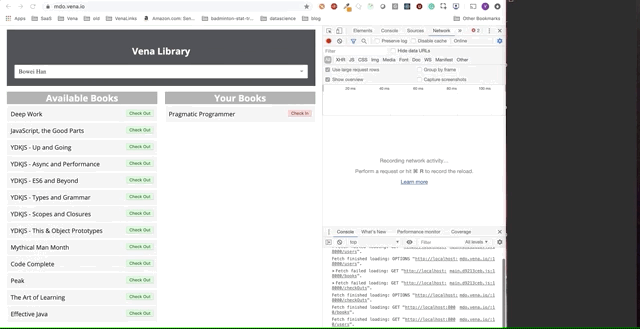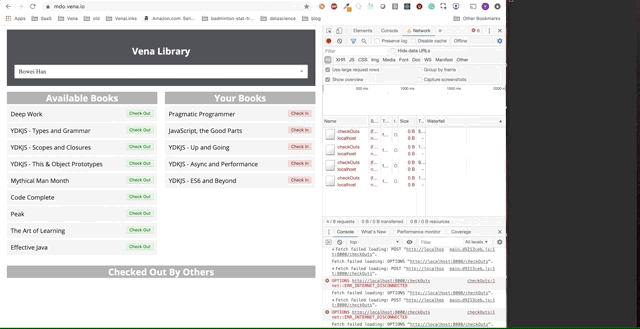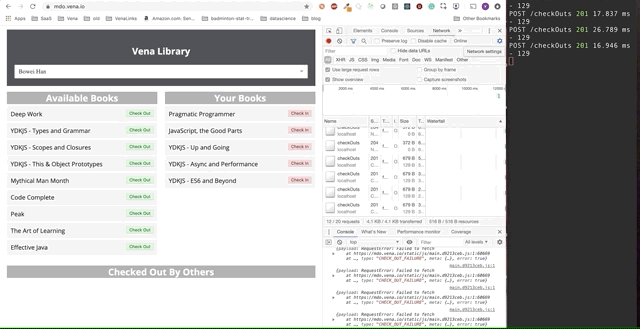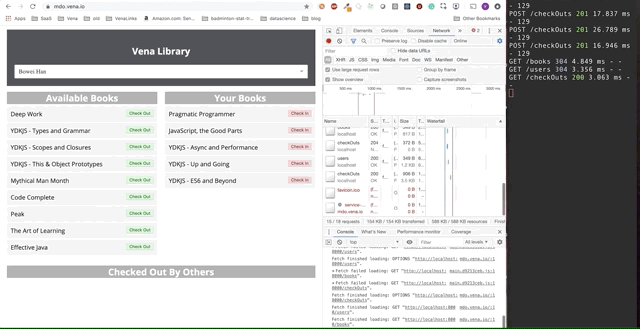
Es ist klar, dass offline gestellte Anforderungen sofort in die Warteschlange gestellt und gesendet wurden, wenn der Benutzer online zurückkehrt.
Dieser "Spiel" -Ansatz ist ein bisschen naiv - zum Beispiel müssen wir wahrscheinlich nicht zwei Anfragen stellen, wenn wir dasselbe Buch annehmen und zurückgeben. Es funktioniert auch nicht, wenn mehrere Personen dieselbe Anwendung verwenden.
Das ist alles
Gehen Sie raus und machen Sie Ihre Webanwendungen offline! Dieser Beitrag zeigt einige der vielen Dinge, die Sie tun können, um Ihren Anwendungen eigenständige Funktionen hinzuzufügen, und ist definitiv nicht vollständig.
Weitere Informationen finden Sie unter
Google Web Fundamentals . Schauen Sie sich
diesen Vortrag an , um eine weitere Offline-Implementierung zu sehen.

Lesen Sie auch den Blog
EDISON Unternehmen:
20 Bibliotheken für
spektakuläre iOS-Anwendung