Am 26. Oktober fand in Linz am Rhein (Deutschland) die Minikonferenz HaxeUp Sessions 2019 statt , die Haxe und verwandten Technologien gewidmet war. Das wichtigste Ereignis war natürlich die endgültige Veröffentlichung von Haxe 4.0.0 (zum Zeitpunkt der Veröffentlichung, dh nach etwa einer Woche, wurde das Update 4.0.1 veröffentlicht ). In diesem Artikel möchte ich Ihnen eine Übersetzung des ersten Berichts der Konferenz vorstellen - einen Bericht über die Arbeit des Haxe-Teams für 2019.

Ein wenig über den Autor des Berichts:
Simon arbeitet seit 2010 mit Haxe zusammen, als er noch Student war und eine Arbeit über Flüssigkeitssimulationen in Flash schrieb. Die Implementierung einer solchen Simulation erforderte einen ständigen Zugriff auf Daten, die den Zustand von Partikeln beschreiben (in jedem Schritt wurden mehr als 100 Abfragen zu Datenfeldern über den Zustand jeder Zelle in der Simulation durchgeführt), während die Arbeit mit Arrays in ActionScript 3 nicht so schnell war. Daher war die anfängliche Implementierung einfach nicht funktionsfähig und musste gefunden werden, um eine Lösung für dieses Problem zu finden. Bei seiner Suche stieß Simon auf einen Artikel von Nicolas Kannass ( Erfinder von Haxe) über die damals nicht dokumentierten Alchemie-Opcodes, die mit ActionScript nicht verfügbar waren, aber Haxe erlaubte, sie zu verwenden. Simon schrieb die Simulation auf Haxe mit Opcodes um und bekam eine funktionierende Simulation! Dank langsamer Arrays in ActionScript lernte Simon Haxe kennen.
Seit 2011 ist Simon Teil der Entwicklung von Haxe. Er begann, OCaml (auf dem der Compiler geschrieben ist) zu studieren und verschiedene Korrekturen am Compiler vorzunehmen.
Und seit 2012 wurde er der Haupt-Compiler-Entwickler. Im selben Jahr wurde die Haxe Foundation gegründet (eine Organisation, deren Hauptziel die Entwicklung und Pflege des Haxe-Ökosystems ist und die die Gemeinde bei der Organisation von Konferenzen und Beratungsdiensten unterstützt), und Simon wurde einer ihrer Mitbegründer.

In den Jahren 2014-2015 lud Simon Josephine Pertosa zur Haxe Foundation ein, die im Laufe der Zeit für die Organisation von Konferenzen und Community Relations verantwortlich war.
2016 hielt Simon seine erste Präsentation zu Haxe und organisierte 2018 die ersten HaxeUp-Sitzungen .

Also, was ist in der Haxe-Welt in den letzten 2019 passiert?
Im Februar und März kamen 2 Release-Kandidaten heraus (4.0.0-rc1 und 4.0.0-rc2)
Im April traten Aurel Bili (als Praktikant) und Alexander Kuzmenko (als Compiler-Entwickler) dem Team der Haxe Foundation bei.
Im Mai fand der Haxe US Summit 2019 statt .
Im Juni wurde Haxe 4.0.0-rc3 veröffentlicht. Und im September - Haxe 4.0.0-rc4 und Haxe 4.0.0-rc5.

Haxe ist nicht nur ein Compiler, sondern auch eine ganze Reihe verschiedener Tools, und während des ganzen Jahres wurde auch ständig daran gearbeitet:
Dank der Bemühungen von Andy Lee verwendet Haxe jetzt Azure Pipelines anstelle von Travis CI und AppVeyor. Dies bedeutet, dass Montage und automatisierte Tests jetzt viel schneller sind.
Hugh Sanderson arbeitet weiterhin an hxcpp (einer Bibliothek zur Unterstützung von C ++ in Haxe).
Plötzlich schlossen sich Benutzer von Github terurou und takashiski der Arbeit an externen Geräten für Node.js an.
Rudy Ges arbeitete an Korrekturen und Verbesserungen, um das C # -Ziel zu unterstützen.
George Corney unterstützt weiterhin den externen HTML-Generator.
Jens Fisher arbeitet an vshaxe (eine Erweiterung für VS Code für die Arbeit mit Haxe) und an vielen anderen Haxe-Projekten.

Und das Hauptereignis des Jahres war natürlich die lang erwartete Veröffentlichung von Haxe 4.0.0 (sowie Neko 2.3.0), die versehentlich mit dem HaxeUp 2019 Linz zusammenfiel :)

Simon widmete den Großteil des Berichts neuen Funktionen in Haxe 4.0.0 (Sie können sie auch aus dem Bericht von Alexander Kuzmenko vom letzten Haxe US-Gipfel 2019 erfahren).

Der neue Eval-Makro-Interpreter ist um ein Vielfaches schneller als der alte. Simon hat in seiner Rede auf dem Haxe Summit EU 2017 ausführlich über ihn gesprochen. Aber seitdem hat es die Debugging-Funktionen des Codes verbessert, viele Fehler behoben und die Implementierung von Strings neu gestaltet.
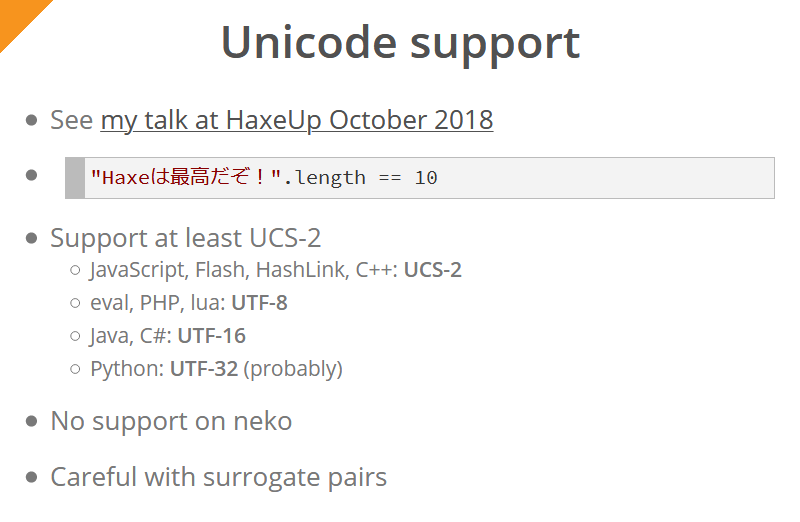
Mit Haxe 4 wird die Unicode-Unterstützung für alle Plattformen (außer Neko) eingeführt. Simon hat dies in seiner letztjährigen Rede ausführlich beschrieben. Für den Endbenutzer des Compilers bedeutet dies, dass der Ausdruck "Haxeは最高だぞ!".length für alle Plattformen gibt immer 10 (wieder mit Ausnahme von Neko).
Die UCS-2-Codierung wird nur minimal unterstützt (für jede Plattform / Sprache wird eine nativ unterstützte Codierung verwendet; der Versuch, überall dieselbe Codierung zu unterstützen, wäre unpraktisch):
- JavaScript, Flash, HashLink und C ++ verwenden die UCS-2-Codierung
- für eval, PHP, lua - UTF-8
- für Java und C # - UTF-16
- für Python - UTF-32
Alle Zeichen, die sich außerhalb der mehrsprachigen Hauptebene befinden (einschließlich Emoji), werden als "Ersatzpaare" dargestellt. Diese Zeichen werden durch zwei Bytes dargestellt. Wenn Sie beispielsweise in Java / C # / JavaScript (dh für Zeichenfolgen in UTF-16- und UCS-2-Codierungen) die Länge einer Zeichenfolge anfordern, die aus einem Emoji besteht, lautet das Ergebnis "2". Diese Tatsache muss bei der Arbeit mit solchen Zeichenfolgen auf diesen Plattformen berücksichtigt werden.
Haxe 4 führt eine neue Art von Iterator ein - Schlüsselwert:

Es funktioniert mit Containern vom Typ Map (Wörterbücher) und Strings (unter Verwendung der StringTools-Klasse). Die Unterstützung für Arrays wurde noch nicht implementiert. Es ist auch möglich, einen solchen Iterator für benutzerdefinierte Klassen zu implementieren. keyValueIterator():KeyValueIterator<K, V> reicht es aus, die keyValueIterator():KeyValueIterator<K, V> -Methode für diese zu implementieren keyValueIterator():KeyValueIterator<K, V> .
Mit dem neuen Meta-Tag @:using können Sie statische Erweiterungen mit Typen an der Stelle ihrer Deklaration verknüpfen.
In dem auf der Folie unten gezeigten Beispiel ist die MyOption Aufzählung mit MyOptionTools verknüpft. MyOptionTools erweitern wir diese Aufzählung statisch (was in der üblichen Situation nicht möglich ist) und erhalten die Möglichkeit, die get() -Methode aufzurufen und sie als Objektmethode zu bezeichnen.

In diesem Beispiel ist die get() -Methode inline, wodurch der Compiler auch den Code weiter optimieren kann: Anstatt die MyOptionTools.get(myOption) -Methode MyOptionTools.get(myOption) , ersetzt der Compiler den gespeicherten Wert, d. H. 12 .
Wenn die Methode nicht als einbettbar deklariert ist, besteht ein weiteres Optimierungswerkzeug, das dem Programmierer zur Verfügung steht, darin, die Funktionen am Ort ihres Aufrufs einzubetten (Call-Site-Inlining). Dazu müssen Sie beim Aufrufen der Funktion zusätzlich das inline :

Dank der Arbeit von Daniil Korostelev hat Haxe nun die Möglichkeit, ES6-Klassen für JavaScript zu generieren. Sie müssen lediglich das Kompilierungsflag -D js-es=6 hinzufügen.
Derzeit generiert der Compiler eine js-Datei für das gesamte Projekt (es ist möglicherweise möglich, in Zukunft separate js-Dateien für jede der Klassen zu generieren, dies kann jedoch bisher nur mit zusätzlichen Tools durchgeführt werden ).

Bei abstrakten Aufzählungen werden jetzt automatisch Werte generiert.
In Haxe 3 mussten die Werte für jeden Konstruktor manuell festgelegt werden. In Haxe 4 verhalten sich abstrakte Aufzählungen, die auf Int nach denselben Regeln wie in C. Abstrakte Aufzählungen, die auf Strings erstellt wurden, verhalten sich ähnlich - für sie stimmen die generierten Werte mit den Namen der Konstruktoren überein.

Erwähnenswert sind auch einige Syntaxverbesserungen:
- abstrakte Aufzählungen und externe Funktionen sind zu vollwertigen Mitgliedern von Haxe geworden, und jetzt müssen Sie nicht mehr die Meta-Tags
@:enum und @:extern , um sie zu deklarieren - 4th Haxe verwendet eine neue Schnittpunktsyntax, die die Essenz expandierender Strukturen besser widerspiegelt. Solche Konstruktionen sind am nützlichsten, wenn Datenstrukturen deklariert werden: Der Ausdruck
typedef T = A & B bedeutet, dass die Struktur T alle Felder der Typen A und B - In ähnlicher Weise deklarieren die vier Typparametereinschränkungen: Der Eintrag
<T:A & B> gibt an, dass der Typ des Parameters T sowohl A als auch B - Die alte Syntax funktioniert (mit Ausnahme der Syntax für Typeinschränkungen, da sie mit der neuen Syntax zur Beschreibung von Funktionstypen in Konflikt steht).

Die neue Syntax zur Beschreibung von Funktionstypen (Funktionstypsyntax) ist logischer: Die Verwendung von Klammern um die Typen von Funktionsargumenten ist visuell einfacher zu lesen. Darüber hinaus können Sie mit der neuen Syntax Argumentnamen definieren, die als Teil der Dokumentation für den Code verwendet werden können (dies hat jedoch keine Auswirkungen auf die Eingabe selbst).

In diesem Fall wird die alte Syntax weiterhin unterstützt und wird nicht als veraltet angesehen Andernfalls wären zu viele Änderungen am vorhandenen Code erforderlich (Simon selbst ist ständig aus Gewohnheit und verwendet weiterhin die alte Syntax).
Haxe 4 hat endlich Pfeilfunktionen (oder Lambda-Ausdrücke)!

Merkmale der Pfeilfunktionen in Haxe sind:
- implizite
return . Wenn der Funktionskörper aus einem Ausdruck besteht, gibt diese Funktion implizit den Wert dieses Ausdrucks zurück - Es ist möglich, die Arten von Funktionsargumenten festzulegen, weil Der Compiler kann den erforderlichen Typ nicht immer bestimmen (z. B.
Float oder Int ). - Wenn der Hauptteil der Funktion aus mehreren Ausdrücken besteht, müssen Sie ihn mit geschweiften Klammern umgeben
- Es gibt jedoch keine Möglichkeit, den Rückgabetyp der Funktion explizit festzulegen
Im Allgemeinen ist die Syntax von Pfeilfunktionen der in Java 8 verwendeten sehr ähnlich (obwohl sie etwas anders funktioniert).
Und da wir Java erwähnt haben, sollte gesagt werden, dass es in Haxe 4 möglich wurde, JVM-Bytecode direkt zu generieren. -D jvm Sie dazu beim Kompilieren eines Projekts unter Java einfach das Flag -D jvm .
Das Generieren eines JVM-Bytecodes bedeutet, dass kein Java-Compiler verwendet werden muss und der Kompilierungsprozess viel schneller ist.

Bisher hat das JVM-Ziel aus folgenden Gründen einen experimentellen Status:
- In einigen Fällen ist der Bytecode etwas langsamer als das Ergebnis der Übersetzung von Haxe in Java und der anschließenden Kompilierung mit Javac. Das Compiler-Team ist sich des Problems bewusst und weiß, wie es behoben werden kann. Es erfordert lediglich zusätzliche Arbeit.
- Es gibt Probleme mit MethodHandle unter Android, die auch zusätzliche Arbeit erfordern (Simon wird sich freuen, wenn ihm bei der Lösung dieser Probleme geholfen wird).

Ein allgemeiner Vergleich des direkten Erzeugens von Bytecode (genjvm) und des Kompilierens von Haxe in Java-Code, der dann in Bytecode (genjava) kompiliert wird:
- Wie bereits erwähnt, ist genjvm in Bezug auf die Kompilierungsgeschwindigkeit schneller als genjava
In Bezug auf die Ausführungsgeschwindigkeit ist der Bytecode genjvm genjava immer noch unterlegen - Es gibt einige Probleme bei der Verwendung von Typparametern und Genjava
- genJvm verwendet MethodHandle, um auf Funktionen zu verweisen, und genjava verwendet die sogenannten "Waneck-Funktionen" (zu Ehren von Kaui Vanek , dank dessen Java- und C # -Unterstützung in Haxe erschienen ist). Obwohl der mit Waneck-Funktionen erhaltene Code nicht schön aussieht, funktioniert er schnell genug.
Allgemeine Tipps für die Arbeit mit Java in Haxe:
- Aufgrund der Tatsache, dass der Garbage Collector in Java schnell ist, sind damit verbundene Probleme selten. Das ständige Erstellen neuer Objekte ist natürlich keine gute Idee, aber Java kommt mit der Speicherverwaltung gut zurecht und die Notwendigkeit, sich ständig um die Zuweisungen zu kümmern, ist nicht so akut wie auf einigen anderen von Haxe unterstützten Plattformen (z. B. in HashLink).
- Der Zugriff auf die Felder einer Klasse in einem JVM-Ziel kann sehr langsam funktionieren, wenn dies über eine Struktur (
typedef ) erfolgt - während der Compiler diesen Code nicht optimieren kann - Übermäßige Verwendung des
inline Schlüsselworts sollte vermieden werden - der JIT-Compiler leistet ziemlich gute Arbeit - Vermeiden Sie die Verwendung von
Null<T> , insbesondere bei komplexen mathematischen Berechnungen. Andernfalls werden im generierten Code viele bedingte Anweisungen angezeigt, die sich negativ auf die Geschwindigkeit Ihres Codes auswirken.
Die neue Haxe 4-Funktion Null-Sicherheit kann dazu beitragen, die Verwendung von Null<T> vermeiden. Alexander Kuzmenko sprach letztes Jahr auf der HaxeUp ausführlich über sie.

In dem obigen Beispiel hat die static safe() -Methode den Strict-Modus für die Überprüfung auf Null-Sicherheit aktiviert, und diese Methode hat einen optionalen arg Parameter, der einen Null-Wert haben kann. Damit diese Funktion erfolgreich kompiliert werden kann, muss der Programmierer eine Überprüfung des arg Argumentwerts hinzufügen (andernfalls zeigt der Compiler eine Meldung an, dass es unmöglich ist, die charAt() -Methode für ein potenziell null-Objekt charAt() ).
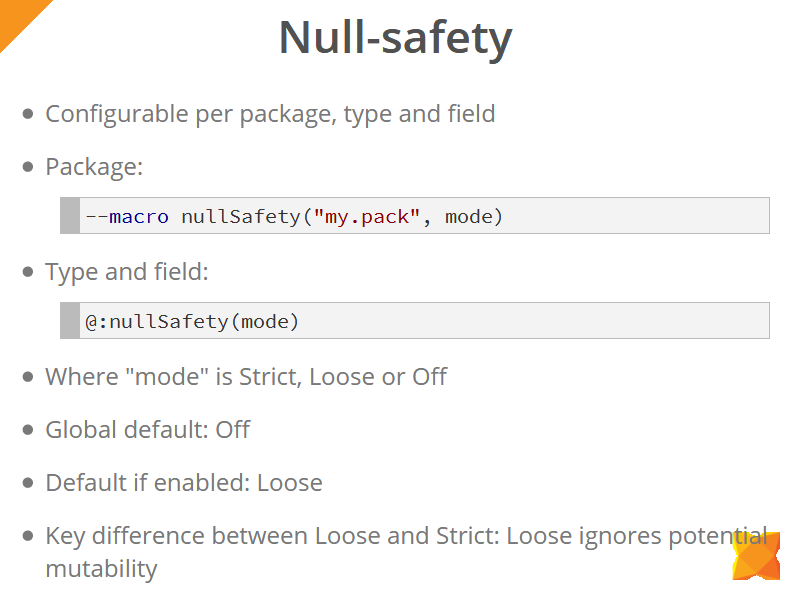
Die Nullsicherheit kann sowohl auf @:nullSafety (mithilfe eines Makros) als auch auf Typen und einzelnen @:nullSafety (mithilfe des Meta-Tags @:nullSafety ) @:nullSafety .
Die Modi, in denen Null-Sicherheitsüberprüfungen funktionieren, sind: Strict, Loose und Off. Global sind diese Überprüfungen deaktiviert (Aus-Modus). Wenn sie aktiviert sind, wird standardmäßig der Loose-Modus verwendet (es sei denn, Sie geben den Modus explizit an). Der Hauptunterschied zwischen dem Loose- und dem Strict-Modus besteht darin, dass im Loose-Modus die Möglichkeit ignoriert wird, Werte zwischen Operationen für den Zugriff auf diese Werte zu ändern. In dem Beispiel auf der Folie unten sehen wir, dass eine null für die Variable x hinzugefügt wurde. Im strengen Modus wird dieser Code jedoch nicht kompiliert, da Bevor Sie direkt mit der Variablen x , wird die sideEffect() -Methode sideEffect() , die möglicherweise den Wert dieser Variablen aufheben kann. Sie müssen daher eine weitere Prüfung hinzufügen oder den Wert der Variablen in eine lokale Variable kopieren, mit der wir weiterhin arbeiten werden.

Haxe 4 führt ein neues final Schlüsselwort ein, das je nach Kontext eine unterschiedliche Bedeutung hat:
- Wenn Sie es anstelle des Schlüsselworts
var , kann dem auf diese Weise deklarierten Feld kein neuer Wert zugewiesen werden. Sie können es nur direkt beim Deklarieren (für statische Felder) oder im Konstruktor (für nicht statische Felder) festlegen. - Wenn Sie es beim Deklarieren einer Klasse verwenden, wird die Vererbung von ihr verboten
- Wenn Sie es als Modifikator für den Zugriff auf die Eigenschaft eines Objekts verwenden, verhindert dies die Neudefinition von Getter / Setter in den Erbenklassen.

Theoretisch kann der Compiler, nachdem er das final Schlüsselwort erfüllt hat, versuchen, den Code zu optimieren, vorausgesetzt, der Wert dieses Felds ändert sich nicht. Diese Möglichkeit wird derzeit jedoch nur in Betracht gezogen und nicht im Compiler implementiert.

Und ein wenig über die Zukunft von Haxe:
- Derzeit wird an einer asynchronen E / A-API gearbeitet
Die Unterstützung von Coroutine ist geplant, aber die Arbeiten an ihnen sind in der Planungsphase noch nicht abgeschlossen. Vielleicht erscheinen sie in Haxe 4.1 und vielleicht später. - Die Tail-Call-Optimierung wird im Compiler angezeigt
- und möglicherweise die auf Modulebene verfügbaren Funktionen . Obwohl sich die Priorität dieser Funktion ständig ändert