Das kumulative (kumulative) Ergebnis wurde lange Zeit als einer der SQL-Aufrufe angesehen. Überraschenderweise ist es auch nach dem Erscheinen von Fensterfunktionen weiterhin eine Vogelscheuche (auf jeden Fall für Anfänger). Heute schauen wir uns die Mechanik der 10 interessantesten Lösungen für dieses Problem an - von Fensterfunktionen bis zu sehr spezifischen Hacks.
In Tabellenkalkulationen wie Excel wird die laufende Summe sehr einfach berechnet: Das Ergebnis im ersten Datensatz entspricht seinem Wert:
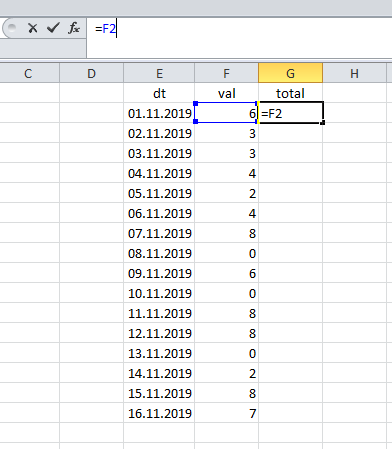
... und dann fassen wir den aktuellen Wert und die vorherige Summe zusammen.

Mit anderen Worten
T o t a l 1 = V ein l u e 1T o t a l 2 = T o t a l 1 + V a l u e 2T o t a l 3 = T o t a l 2 + V a l u e 3 l d o t sTotaln=Totaln−1+Valuen
... oder:
beginFälleTotal1=Wert1,n=1Totaln=Gesamtn−1+Wertn,n geq2 EndeFälle
Das Erscheinen von zwei oder mehr Gruppen in der Tabelle erschwert die Aufgabe etwas: Jetzt zählen wir mehrere Ergebnisse (für jede Gruppe separat). Hier liegt die Lösung jedoch an der Oberfläche: Jedes Mal muss überprüft werden, zu welcher Gruppe der aktuelle Datensatz gehört.
Klicken und ziehen , und die Arbeit ist erledigt:
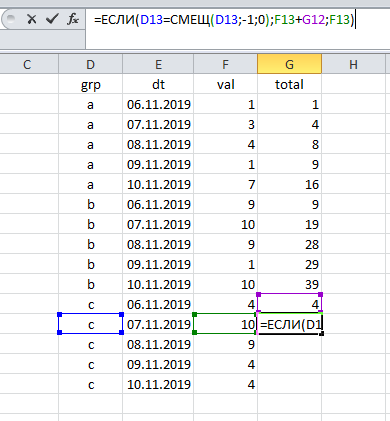
Wie Sie sehen, ist die Berechnung der Gesamtsumme mit zwei unveränderten Komponenten verbunden:
(a) Sortieren der Daten nach Datum und
(b) unter Bezugnahme auf die vorherige Zeile.
Aber was ist SQL? Es gab sehr lange keine notwendige Funktionalität darin. Ein notwendiges Werkzeug - Fensterfunktionen - erschien zuerst nur im
SQL: 2003- Standard. Zu diesem Zeitpunkt befanden sie sich bereits in Oracle (Version 8i). Die Implementierung in anderen DBMSs verzögerte sich jedoch um 5-10 Jahre: SQL Server 2012, MySQL 8.0.2 (2018), MariaDB 10.2.0 (2017), PostgreSQL 8.4 (2009), DB2 9 for z / OS (2007) Jahr) und sogar SQLite 3.25 (2018).
1. Fensterfunktionen
Fensterfunktionen sind wahrscheinlich der einfachste Weg. Im Basisfall (Tabelle ohne Gruppen) betrachten wir Daten nach Datum sortiert:
order by dt
... aber wir interessieren uns nur für die Zeilen vor der aktuellen:
rows between unbounded preceding and current row
Letztendlich brauchen wir eine Summe mit diesen Parametern:
sum(val) over (order by dt rows between unbounded preceding and current row)
Eine vollständige Anfrage würde folgendermaßen aussehen:
select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt;
Bei einer kumulierten Summe für Gruppen (
grp Feld) benötigen wir nur eine kleine Bearbeitung. Nun betrachten wir die Daten basierend auf der Gruppe als in „Fenster“ unterteilt:

Um diese Trennung zu berücksichtigen, müssen Sie die
partition by Schlüsselwort verwenden:
partition by grp
Berücksichtigen Sie dementsprechend den Betrag für diese Fenster:
sum(val) over (partition by grp order by dt rows between unbounded preceding and current row)
Dann wird die gesamte Abfrage folgendermaßen konvertiert:
select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt;
Die Leistung von Fensterfunktionen hängt von den Besonderheiten Ihres DBMS (und seiner Version!), Der Größe der Tabelle und der Verfügbarkeit von Indizes ab. In den meisten Fällen ist diese Methode jedoch am effektivsten. Fensterfunktionen sind jedoch in älteren Versionen des DBMS (die noch verwendet werden) nicht verfügbar. Darüber hinaus befinden sie sich nicht in DBMS wie Microsoft Access und SAP / Sybase ASE. Wenn eine herstellerunabhängige Lösung benötigt wird, sollten Alternativen in Betracht gezogen werden.
2. Unterabfrage
Wie oben erwähnt, wurden Fensterfunktionen sehr spät im Haupt-DBMS eingeführt. Diese Verzögerung sollte nicht überraschen: In der relationalen Theorie werden Daten nicht geordnet. Vielmehr entspricht der Geist der Beziehungstheorie einer Lösung durch eine Unterabfrage.
Eine solche Unterabfrage sollte die Summe der Werte mit einem Datum vor dem aktuellen (und einschließlich des aktuellen) berücksichtigen:
dtrow leqdtcurrentrow .
Was im Code so aussieht:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt;
Eine etwas effizientere Lösung besteht darin, dass die Unterabfrage die Summe bis zum aktuellen Datum berücksichtigt (aber nicht einschließt) und sie dann mit dem Wert in der Zeile zusammenfasst:
select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt;
Bei einem kumulativen Ergebnis für mehrere Gruppen müssen wir eine korrelierte Unterabfrage verwenden:
select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt;
Die Bedingung
g.grp = t2.grp überprüft die Zeilen auf Aufnahme in die Gruppe (was im Prinzip der Arbeit der
partition by grp in Fensterfunktionen ähnlich ist).
3. Interne Verbindung
Da Unterabfragen und Verknüpfungen austauschbar sind, können wir sie problemlos durch andere ersetzen. Dazu müssen Sie Self Join verwenden und zwei Instanzen derselben Tabelle verbinden:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Wie Sie sehen können, ist die Filterbedingung in der Unterabfrage
t2.dt <= s.dt zu einer Verknüpfungsbedingung geworden. Um die Aggregationsfunktion
sum() wir außerdem nach Datum und Wert nach
group by s.dt, s.val .
Ebenso können Sie für den Fall mit verschiedenen Gruppen arbeiten:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
4. Kartesisches Produkt
Probieren Sie das kartesische Produkt aus, da wir die Unterabfrage durch join ersetzt haben. Diese Lösung erfordert nur minimale Änderungen:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Oder für den Fall von Gruppen:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
Die aufgeführten Lösungen (Unterabfrage, innerer Join, kartesischer Join) entsprechen
SQL-92 und
SQL: 1999 und sind daher in fast jedem DBMS verfügbar. Das Hauptproblem bei all diesen Lösungen ist die schlechte Leistung. Dies ist kein großes Problem, wenn wir eine Tabelle mit dem Ergebnis erstellen (aber Sie möchten immer noch mehr Geschwindigkeit!). Weitere Methoden sind viel effektiver (angepasst an die Besonderheiten bestimmter DBMS und deren bereits festgelegte Versionen, Tabellengröße, Indizes).
5. Rekursive Anfrage
Einer der spezifischeren Ansätze ist eine rekursive Abfrage in einem allgemeinen Tabellenausdruck. Dazu benötigen wir einen „Anker“ - eine Abfrage, die die allererste Zeile zurückgibt:
select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple)
Dann werden mit Hilfe von
union all die Ergebnisse einer rekursiven Abfrage zum "Anker" hinzugefügt. Dazu können Sie sich auf das Feld "
dt date" verlassen und einen Tag hinzufügen:
select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
Der Teil des Codes, der eines Tages hinzugefügt wird, ist nicht universell. Dies ist beispielsweise
r.dt = dateadd(day, 1, cte.dt) für SQL Server,
r.dt = cte.dt + 1 für Oracle usw.
Wenn wir den "Anker" und die Hauptanforderung kombinieren, erhalten wir das Endergebnis:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
Die Lösung für den Fall mit Gruppen wird nicht viel komplizierter sein:
with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt)
6. Rekursive Abfrage mit der Funktion row_number()
Die vorherige Entscheidung basierte auf der Kontinuität des Felds
dt date mit einer sequentiellen Erhöhung um 1 Tag. Wir vermeiden dies, indem wir die
row_number() verwenden, die die Zeilen nummeriert. Das ist natürlich unfair - denn wir werden Alternativen zu Fensterfunktionen in Betracht ziehen. Diese Lösung kann jedoch eine Art
Proof of Concept sein : In der Praxis kann es ein Feld geben, das Zeilennummern ersetzt (Datensatz-ID). Darüber hinaus wurde in SQL Server die Funktion
row_number() bevor die vollständige Unterstützung für Fensterfunktionen eingeführt wurde (einschließlich
sum() ).
Für eine rekursive Abfrage mit
row_number() benötigen wir also zwei STEs. Im ersten nummerieren wir nur die Zeilen:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple)
... und wenn die Zeilennummer bereits in der Tabelle enthalten ist, können Sie darauf verzichten. In der folgenden Abfrage
cte1 wir uns bereits
cte1 :
cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 )
Und die ganze Anfrage sieht so aus:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt;
... oder für Gruppen:
with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
7. CROSS APPLY / LATERAL
Eine der exotischsten Methoden zur Berechnung einer laufenden Summe ist die Verwendung der Anweisung
CROSS APPLY (SQL Server, Oracle) oder der entsprechenden
LATERAL (MySQL, PostgreSQL). Diese Operatoren erschienen ziemlich spät (zum Beispiel in Oracle nur ab Version 12c). Und in einigen DBMS (zum Beispiel
MariaDB ) sind sie überhaupt nicht. Daher ist diese Entscheidung von rein ästhetischem Interesse.
Funktionell ist die Verwendung von
CROSS APPLY oder
LATERAL identisch mit der Unterabfrage: Wir hängen das Ergebnis der Berechnung an die Hauptanforderung an:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2
... was so aussieht:
select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt;
Die Lösung für den Fall mit Gruppen wird ähnlich sein:
select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt;
Insgesamt: Wir haben die wichtigsten plattformunabhängigen Lösungen untersucht. Es gibt jedoch spezifische Lösungen für bestimmte DBMS! Da es hier viele Möglichkeiten gibt, wollen wir uns mit einigen der interessantesten befassen.
8. MODEL Anweisung (Oracle)
Die
MODEL Anweisung in Oracle bietet eine der elegantesten Lösungen. Zu Beginn des Artikels untersuchten wir die allgemeine Formel der kumulativen Summe:
beginFälleTotal1=Wert1,n=1Totaln=Gesamtn−1+Wertn,n geq2 EndeFälle
MODEL können Sie diese Formel buchstäblich eins zu eins implementieren! Dazu füllen wir zunächst das
total mit den Werten der aktuellen Zeile
select dt, val, val as total from test_simple
... dann berechnen wir die Zeilennummer als
row_number() over (order by dt) as rn (oder verwenden das fertige Feld mit der Nummer, falls vorhanden). Und schließlich führen wir eine Regel für alle Zeilen außer der ersten ein:
total[rn >= 2] = total[cv() - 1] + val[cv()] .
Die Funktion
cv() ist hier für den Wert der aktuellen Zeile verantwortlich. Und die ganze Anfrage wird so aussehen:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total[rn >= 2] = total[cv() - 1] + val[cv()]) order by dt;
9. Cursor (SQL Server)
Eine laufende Summe ist einer der wenigen Fälle, in denen der Cursor in SQL Server nicht nur nützlich, sondern auch anderen Lösungen vorzuziehen ist (zumindest bis zur Version 2012, in der Fensterfunktionen angezeigt wurden).
Die Umsetzung durch den Cursor ist ziemlich trivial. Zuerst müssen Sie eine temporäre Tabelle erstellen und diese mit Daten und Werten aus der Haupttabelle füllen:
create table
Dann legen wir die lokalen Variablen fest, über die das Update stattfinden wird:
declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0;
Danach aktualisieren wir die temporäre Tabelle über den Cursor:
declare cur cursor local static read_only forward_only for select dt, val from
Und schließlich erhalten wir das gewünschte Ergebnis:
select dt, val, total from
10. Update über eine lokale Variable (SQL Server)
Das Aktualisieren über eine lokale Variable in SQL Server basiert auf undokumentiertem Verhalten und kann daher nicht als zuverlässig angesehen werden. Trotzdem ist dies vielleicht die schnellste Lösung, und das ist interessant.
Erstellen wir zwei Variablen: eine für kumulative Summen und eine Tabellenvariable:
declare @VarTotal int = 0; declare @tv table (dt date null, val int null, total int null );
Füllen Sie zuerst
@tv Daten aus der Haupttabelle
insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt;
Dann aktualisieren
@tv die Tabellenvariable
@tv mit
@VarTotal :
update @tv set @VarTotal = total = @VarTotal + val from @tv;
... woraufhin wir das Endergebnis erhalten:
select * from @tv order by dt;
Zusammenfassung: Wir haben die zehn wichtigsten Methoden zur Berechnung der kumulativen Gesamtsummen in SQL überprüft. Wie Sie sehen, ist dieses Problem auch ohne Fensterfunktionen vollständig lösbar, und die Mechanik der Lösung kann nicht als kompliziert bezeichnet werden.