Hallo allerseits! Vor einigen Monaten haben wir unser neues Open-Source-Projekt, das Grafana-Plugin zur Überwachung von Kubernetes, mit dem Namen
DevOpsProdigy KubeGraf, in Betrieb genommen . Der Quellcode des Plugins ist im
öffentlichen Repository von GitHub verfügbar. Und in diesem Artikel möchten wir Ihnen eine Geschichte darüber erzählen, wie wir das Plug-In erstellt haben, welche Tools wir verwendet haben und auf welche Fallstricke wir während des Entwicklungsprozesses gestoßen sind. Lass uns gehen!
Teil 0 - Einführung: Wie sind wir dazu gekommen?
Die Idee, ein eigenes Plugin für Grafan zu schreiben, wurde zufällig geboren. Unser Unternehmen überwacht seit mehr als 10 Jahren Webprojekte unterschiedlicher Komplexität. In dieser Zeit haben wir viel Fachwissen, interessante Fälle und Erfahrung im Umgang mit verschiedenen Überwachungssystemen gesammelt. Und irgendwann haben wir uns gefragt: „Gibt es ein magisches Tool zum Überwachen von Kubernetes, mit dem man, wie man sagt,„ setzen und vergessen “kann?“. Promstandart zum Überwachen von K8s ist natürlich schon lange ein Haufen von Prometheus + Grafana. Und als vorgefertigte Lösung für diesen Stack gibt es eine große Auswahl verschiedener Tools: Prometheus-Operator, Dashboard-Set Kubernetes-Mixin, Grafana-Kubernetes-App.
Das grafana-kubernetes-app-Plugin schien für uns die interessanteste Option zu sein, wurde aber seit mehr als einem Jahr nicht mehr unterstützt und weiß außerdem nicht, wie man mit neuen Versionen von Node-Exporter und Kubezustandsmetriken arbeitet. Und irgendwann entschieden wir uns: "Aber treffen wir nicht unsere eigene Entscheidung?"
Welche Ideen haben wir in unser Plugin umgesetzt:
- Visualisierung der "Anwendungszuordnung": bequeme Darstellung von Anwendungen im Cluster, gruppiert nach Namespace, Bereitstellung ...;
- Visualisierung von Verbindungen der Form "Deployment - Service (+ Ports)".
- Visualisierung der Verteilung von Cluster-Anwendungen durch Cluster-Knoten.
- Sammeln von Metriken und Informationen aus verschiedenen Quellen: Prometheus und K8s API-Server.
- Überwachung sowohl des Infrastrukturteils (Nutzung der Prozessorzeit, des Speichers, des Festplattensubsystems, des Netzwerks) als auch der Anwendungslogik - Integritätsstatus-Pods, Anzahl der verfügbaren Replikate, Informationen zum Durchlauf von Aktivitäts- / Bereitschaftsproben.
Teil 1: Was ist das Grafana Plugin?
Aus technischer Sicht ist das Plugin für Grafana ein Winkelcontroller, der im Grafana-Datenverzeichnis (
/var/grafana/plugins/<Ihr_plugin_name>/dist/module.js ) gespeichert und als SystemJS-Modul geladen werden kann. In diesem Verzeichnis sollte sich auch eine plugin.json-Datei befinden, die alle Metainformationen zu Ihrem Plugin enthält: Name, Version, Typ des Plugins, Links zum Repository / zur Site / zur Lizenz, Abhängigkeiten usw.
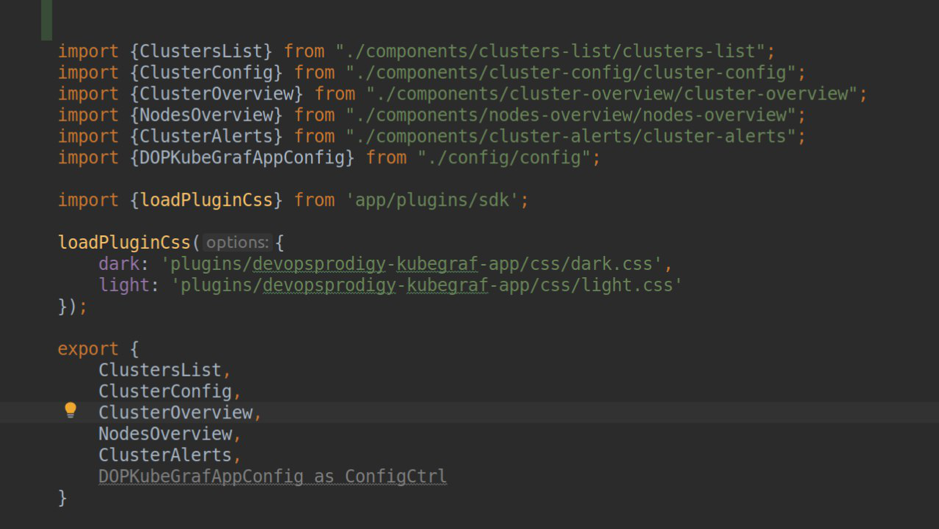 module.ts
module.ts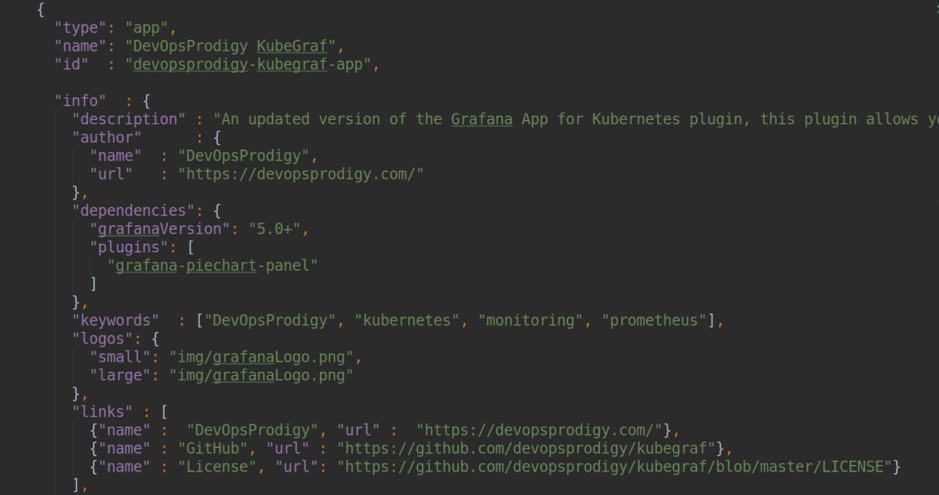 plugin.json
plugin.jsonWie Sie im Screenshot sehen können, haben wir plugin.type = app angegeben. Für Grafana-Plugins gibt es drei Arten:
panel : die gebräuchlichste Art von Plug-In - es ist ein Panel zur Visualisierung von Metriken, mit dem verschiedene Dashboards erstellt werden.
Datenquelle : Plug-In-Connector für eine beliebige Datenquelle (z. B. Prometheus-Datenquelle, ClickHouse-Datenquelle, ElasticSearch-Datenquelle).
App : Ein Plugin, mit dem Sie Ihre eigene Frontend-Anwendung in Grafana erstellen, Ihre eigenen HTML-Seiten erstellen und manuell auf die Datenquelle zugreifen können, um verschiedene Daten anzuzeigen. Plugins anderer Typen (Datenquelle, Panel) und verschiedene Dashboards können ebenfalls als Abhängigkeiten verwendet werden.
 Ein Beispiel für Plugin-Abhängigkeiten mit type = app
Ein Beispiel für Plugin-Abhängigkeiten mit type = app .
Als Programmiersprache können Sie sowohl JavaScript als auch TypeScript verwenden (wir haben uns dafür entschieden).
Die Leerzeichen für Hallo-Welt-Plug-Ins aller Art finden Sie
hier : In diesem Repository gibt es eine große Anzahl von Starter-Packs (es gibt sogar ein experimentelles Beispiel für ein Plugin in React) mit vorinstallierten und konfigurierten Buildern.
Teil 2: Vorbereitung Ihrer lokalen Umgebung
Für die Arbeit am Plugin benötigen wir natürlich einen Kubernetes-Cluster mit allen vorinstallierten Tools: Prometheus, Node-Exporter, Kubezustandsmetrik, Grafana. Die Umgebung sollte schnell, einfach und auf natürliche Weise eingerichtet werden. Um Hot-Reload-Daten bereitzustellen, sollte das Grafana-Verzeichnis direkt vom Computer des Entwicklers bereitgestellt werden.
Die unserer Meinung nach bequemste Art, lokal mit Kubernetes zu arbeiten, ist
Minikube . Der nächste Schritt besteht darin, das Prometheus + Grafana-Bundle mit dem Prometheus-Operator zu erstellen.
Dieser Artikel beschreibt die Installation von prometheus-operator auf minikube. Um die Persistenz zu aktivieren, müssen Sie den Parameter
persistence: true in der Datei charts / grafana / values.yaml festlegen, Ihre eigene PV und PVC hinzufügen und diese im Parameter persistence.existingClaim angeben
Das letzte Startskript für den Minikube sieht folgendermaßen aus:
minikube start --kubernetes-version=v1.13.4 --memory=4096 --bootstrapper=kubeadm --extra-config=scheduler.address=0.0.0.0 --extra-config=controller-manager.address=0.0.0.0 minikube mount /home/sergeisporyshev/Projects/Grafana:/var/grafana --gid=472 --uid=472 --9p-version=9p2000.L
Teil 3: Entwicklung selbst
ObjektmodellIn Vorbereitung auf die Implementierung des Plugins haben wir beschlossen, alle grundlegenden Kubernetes-Entitäten, mit denen wir arbeiten werden, als TypeScript-Klassen zu beschreiben: Pod, Bereitstellung, Daemonset, Statefulset, Job, Cronjob, Service, Knoten, Namespace. Jede dieser Klassen erbt von der gemeinsamen BaseModel-Klasse, die den Konstruktor, den Destruktor und die Methoden zum Aktualisieren und Wechseln der Sichtbarkeit beschreibt. Jede der Klassen beschreibt verschachtelte Beziehungen zu anderen Entitäten, z. B. eine Liste von Pods für eine Entität vom Typ Bereitstellung.
import {Pod} from "./pod"; import {Service} from "./service"; import {BaseModel} from './traits/baseModel'; export class Deployment extends BaseModel{ pods: Array<Pod>; services: Array<Service>; constructor(data: any){ super(data); this.pods = []; this.services = []; } }
Mithilfe von Gettern und Setzern können wir die Metriken der benötigten Entitäten auf bequeme und lesbare Weise anzeigen oder festlegen. Zum Beispiel die formatierte Ausgabe von zuweisbaren CPU-Knoten:
get cpuAllocatableFormatted(){ let cpu = this.data.status.allocatable.cpu; if(cpu.indexOf('m') > -1){ cpu = parseInt(cpu)/1000; } return cpu; }
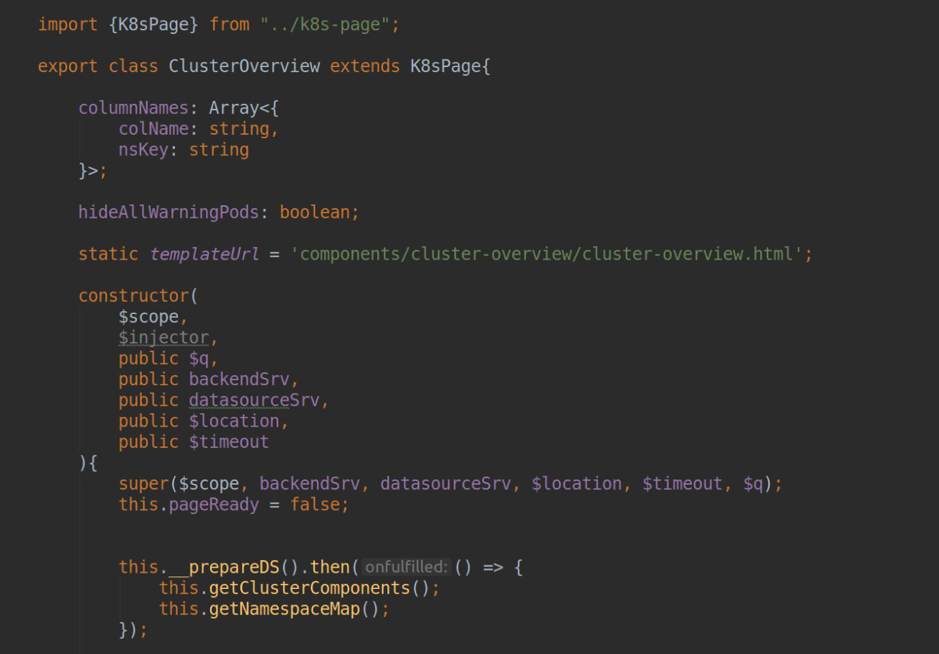
SeitenEine Liste aller Seiten unseres Plugins finden Sie zunächst in unserer pluing.json im Abschnitt Abhängigkeiten:
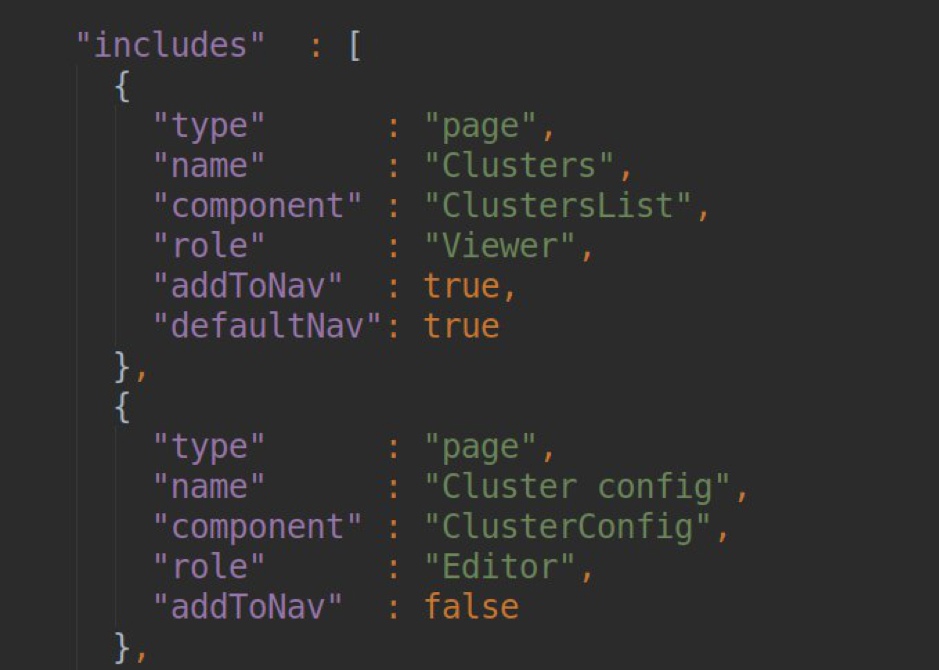
Im Block für jede Seite müssen wir den SEITENTITEL angeben (dieser wird dann in einen Slug konvertiert, über den diese Seite verfügbar sein wird). Name der Komponente, die für den Betrieb dieser Seite verantwortlich ist (die Liste der Komponenten wird nach module.ts exportiert); Angabe der Rolle des Benutzers, für den der Zugriff auf diese Seite verfügbar ist, und der Navigationseinstellungen für die Seitenleiste.
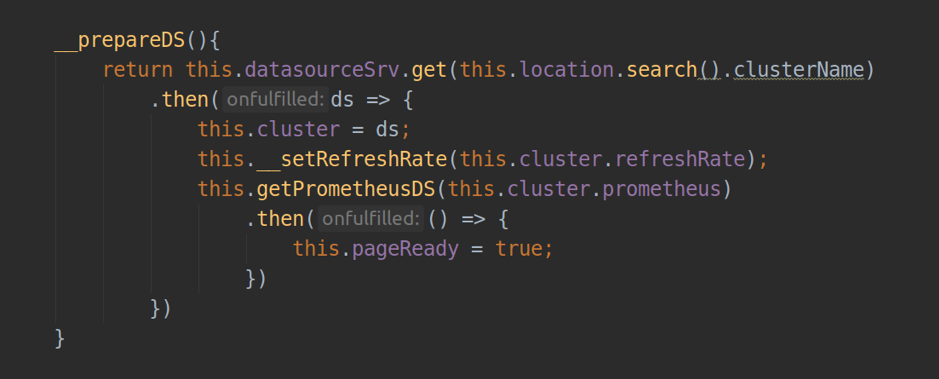
In der Komponente, die für den Betrieb der Seite verantwortlich ist, müssen wir templateUrl installieren und dort den Pfad zur HTML-Datei mit Markup übergeben. Innerhalb des Controllers können wir durch Abhängigkeitsinjektion auf bis zu zwei wichtige Winkeldienste zugreifen:
- backendSrv - ein Dienst, der die Interaktion mit dem grafana api-Server ermöglicht;
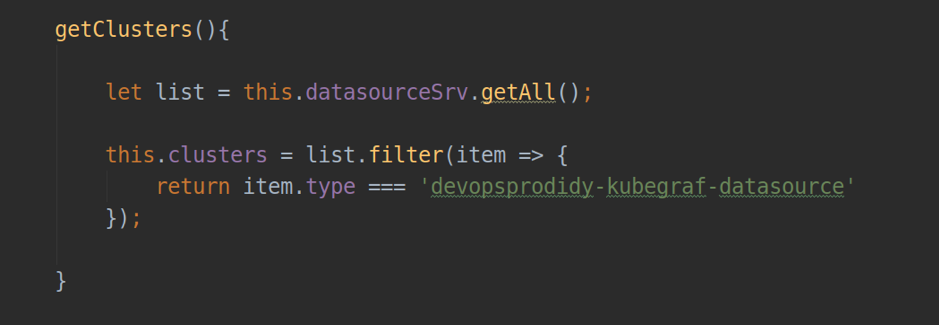
- datasourceSrv - ein Dienst, der die lokale Interaktion mit allen in Ihrer Grafana installierten Datenquellen ermöglicht (z. B. die Methode .getAll () - gibt eine Liste aller installierten Datenquellen zurück'ov; .get (<Name>) - gibt ein Instanzobjekt einer bestimmten Datenquelle zurück.
Teil 4: Datenquelle
Aus der Sicht von Grafana ist die Datenquelle genau das gleiche Plug-In wie alle anderen: Sie hat einen eigenen Einstiegspunkt module.js, es gibt eine Datei mit der Metainformation plugin.json. Bei der Entwicklung eines Plugins mit type = app können wir sowohl mit vorhandenen als auch mit unserer eigenen Datenquelle (z. B. prometheus-Datenquelle) interagieren, die wir direkt im Plugin-Verzeichnis (dist / datasource / *) speichern oder als Abhängigkeit festlegen können. In unserem Fall enthält die Datenquelle den Plugin-Code. Es ist auch erforderlich, die Vorlage config.html und den ConfigCtrl-Controller zu haben, die für die Konfigurationsseite der Datenquelleninstanz verwendet werden, sowie den Datenquellen-Controller, der die Logik Ihrer Datenquelle implementiert.
Im KubeGraf-Plugin ist die Datenquelle aus Sicht der Benutzeroberfläche eine Instanz des Kubernetes-Clusters, in dem die folgenden Funktionen implementiert sind (der Quellcode ist als
Referenz verfügbar):
- Datenerfassung vom k8s API-Server (Abrufen einer Liste mit Namespace'ov, Deployment'ov ...)
- Proxy-Anforderungen in der Prometheus-Datenquelle (die in den Plugin-Einstellungen für jeden bestimmten Cluster ausgewählt ist) und Formatieren von Antworten für die Verwendung von Daten sowohl in statischen Seiten als auch in Dashboards.
- Aktualisieren von Daten auf statischen Seiten des Plugins (mit der eingestellten Aktualisierungsrate).
- Verarbeiten von Anforderungen zum Generieren einer Vorlagenliste in Grafana-Dashboards (Methode .metriFindQuery ())
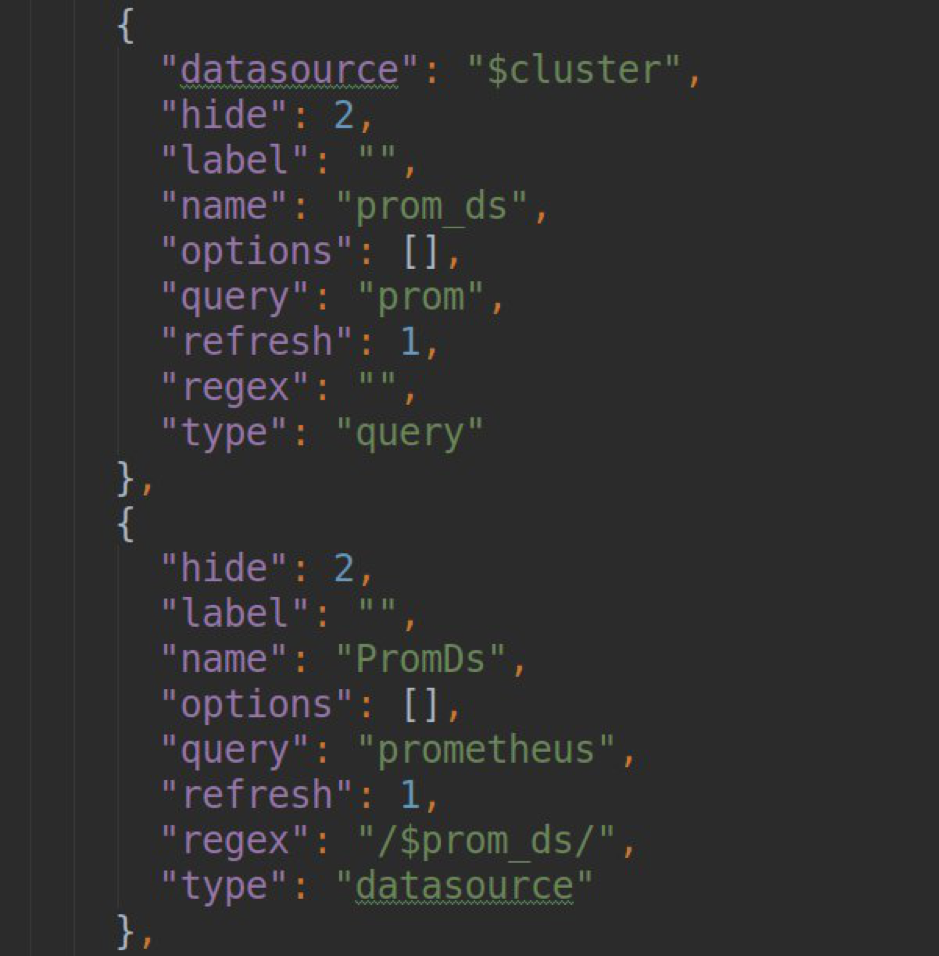
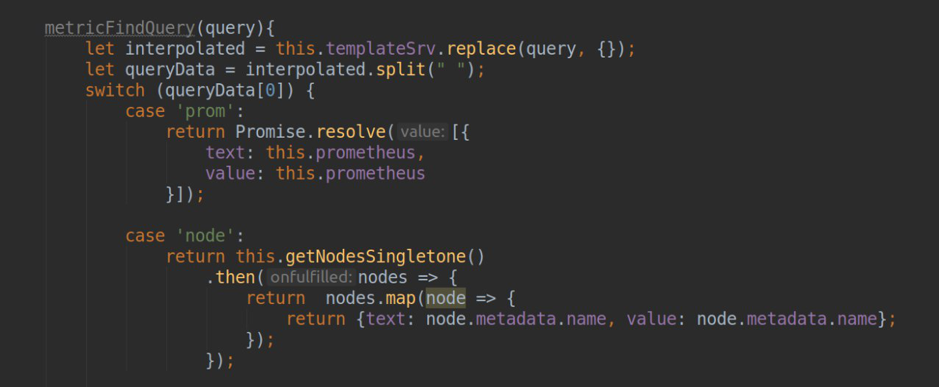
- Testverbindung mit dem endgültigen k8s-Cluster.
testDatasource(){ let url = '/api/v1/namespaces'; let _url = this.url; if(this.accessViaToken) _url += '/__proxy'; _url += url; return this.backendSrv.datasourceRequest({ url: _url, method: "GET", headers: {"Content-Type": 'application/json'} }) .then(response => { if (response.status === 200) { return {status: "success", message: "Data source is OK", title: "Success"}; }else{ return {status: "error", message: "Data source is not OK", title: "Error"}; } }, error => { return {status: "error", message: "Data source is not OK", title: "Error"}; }) }
Ein weiterer interessanter Punkt ist unserer Meinung nach die Implementierung des Authentifizierungs- und Autorisierungsmechanismus für Datenquellen. In der Regel können wir für die Konfiguration des Zugriffs auf die endgültige Datenquelle die integrierte Grafana-Komponente "datasourceHttpSettings" verwenden. Mit dieser Komponente können wir den Zugriff auf die http-Datenquelle konfigurieren, indem wir die URL und die grundlegenden Authentifizierungs- / Autorisierungseinstellungen angeben: Login-Passwort oder Client-Zertifikat / Client-Schlüssel. Um die Möglichkeit zu realisieren, den Zugriff mit einem Inhaber-Token zu konfigurieren (de facto der Standard für k8s), musste ich ein wenig "chemisch" arbeiten.
Um dieses Problem zu lösen, können Sie den in Grafana integrierten "Plugin Routes" -Mechanismus verwenden (weitere Informationen finden Sie auf der
offiziellen Dokumentationsseite ). In den Einstellungen unserer Datenquelle können wir eine Reihe von Routing-Regeln festlegen, die vom grafana-Proxy-Server verarbeitet werden. Beispielsweise besteht für jeden einzelnen Endpunkt die Möglichkeit, Header oder URLs mit der Möglichkeit zur Vorlage von Daten anzubringen, deren Daten aus den Feldern jsonData und secureJsonData entnommen werden können (zum Speichern von Kennwörtern oder Token in verschlüsselter Form). In unserem Beispiel werden Anforderungen des Formulars
/ __ proxy / api / v1 / namespaces an die URL des Formulars weitergeleitet
<Ihre_k8s_api_url> / api / v1 / Namespaces mit dem Header Authorization: Bearer.
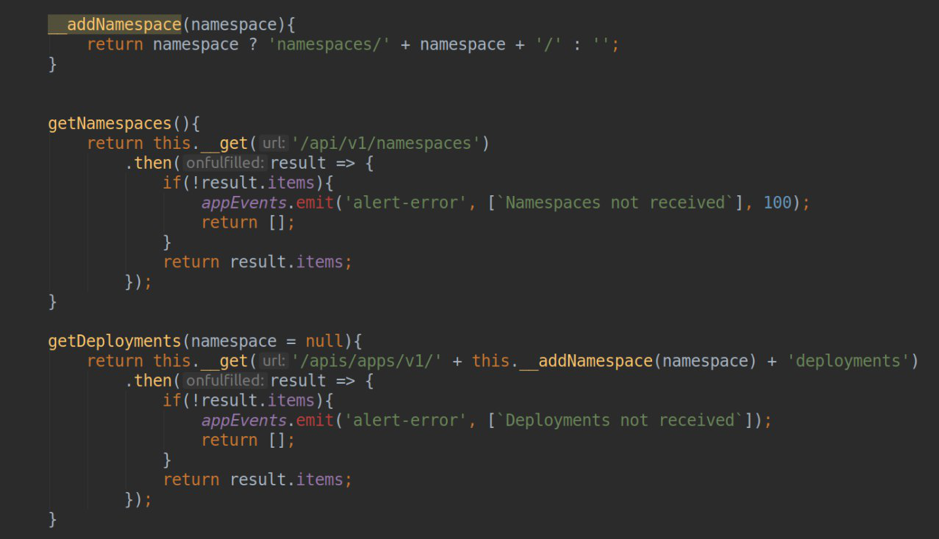
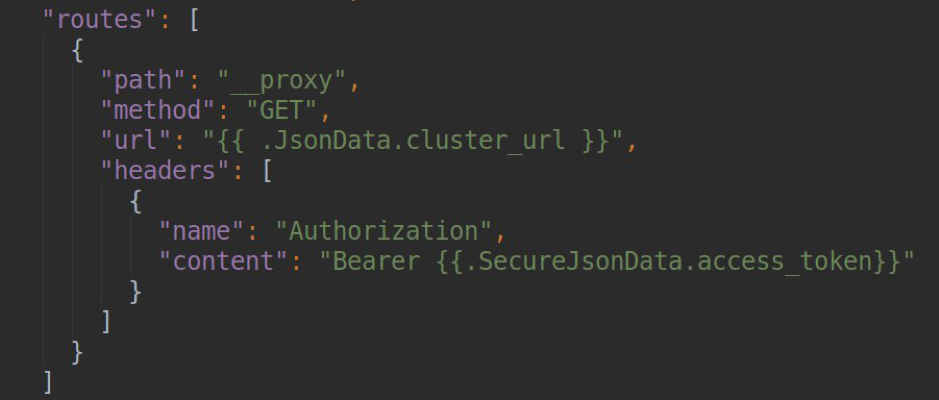
Um mit dem k8s-API-Server arbeiten zu können, benötigen wir natürlich einen Benutzer mit schreibgeschützten Zugriffen. Das Manifest zum Erstellen finden Sie auch im
Quellcode des Plugins .
Teil 5: Veröffentlichung

Nachdem Sie Ihr eigenes Plugin für Grafana geschrieben haben, möchten Sie es natürlich öffentlich zugänglich machen. Grafana ist eine Plugin-Bibliothek, die unter
grafana.com/grafana/plugins verfügbar
istDamit Ihr Plugin im offiziellen Store verfügbar ist, müssen Sie PR in
diesem Repository durchführen, indem Sie der Datei repo.json den folgenden Inhalt hinzufügen:
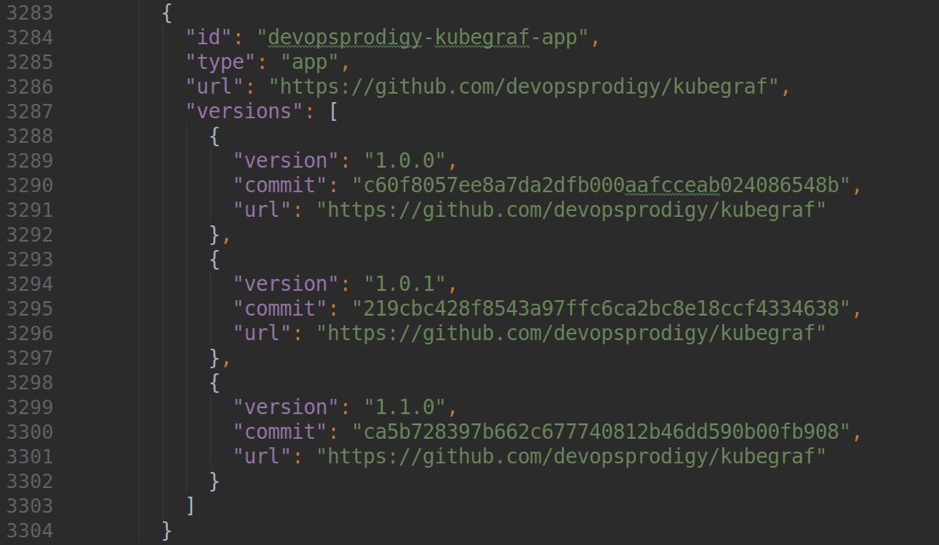
Dabei ist version die Version Ihres Plugins, url ein Link zum Repository und commit ein Hash des Commits, über den eine bestimmte Version des Plugins verfügbar ist.
Und am Ausgang sehen Sie ein wunderschönes Bild der Form:
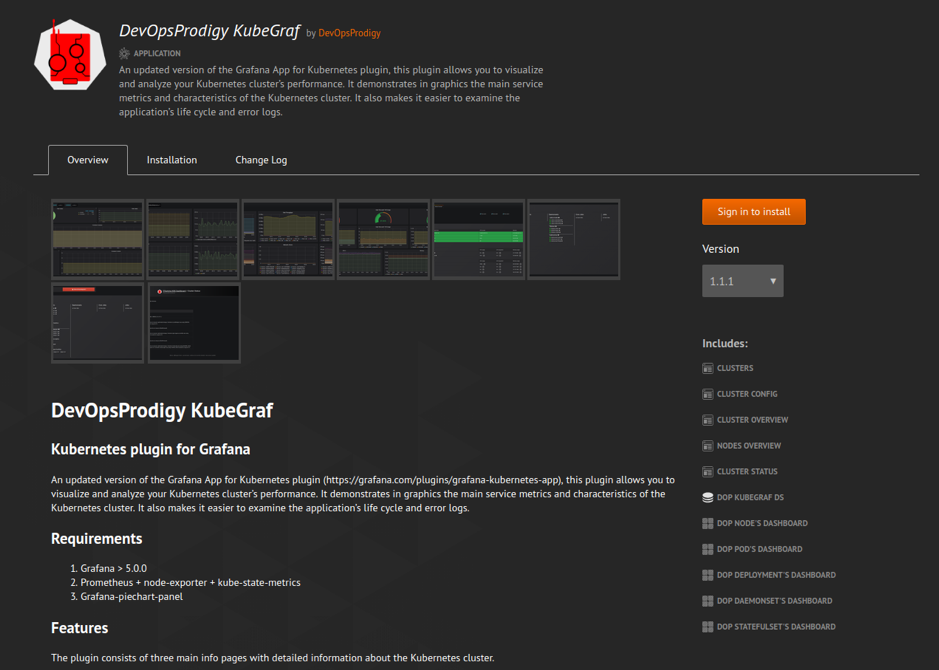
Die Daten dafür werden automatisch aus Ihrer Readme.md-, Changelog.md- und der plugin.json-Datei mit der Plugin-Beschreibung abgerufen.
Teil 6: statt Schlussfolgerungen
Wir haben nicht aufgehört, unser Plugin nach der Veröffentlichung zu entwickeln. Und jetzt arbeiten wir an der korrekten Überwachung der Nutzung der Ressourcen der Clusterknoten, der Einführung neuer Funktionen zur Erhöhung von UX sowie an einer großen Anzahl von Rückmeldungen, die nach der Installation des Plugins sowohl von unseren Kunden als auch vom ishui auf dem Github erhalten wurden (wenn Sie Ihr Problem verlassen oder eine Anfrage stellen, ich Ich werde mich sehr freuen :-)).
Wir hoffen, dass dieser Artikel Ihnen hilft, ein so großartiges Tool wie Grafana zu verstehen und möglicherweise Ihr eigenes Plugin zu schreiben.
Vielen Dank!)