Hallo allerseits! Mein Name ist Vlad und ich arbeite als Datenwissenschaftler im Tinkoff-Team für Sprachtechnologien, die in unserem Sprachassistenten Oleg verwendet werden.
In diesem Artikel möchte ich einen kurzen Überblick über die in der Branche verwendeten Sprachsynthesetechnologien geben und die Erfahrungen unseres Teams beim Aufbau unserer eigenen Synthese-Engine teilen.

Sprachsynthese
Sprachsynthese ist die Erzeugung von Klang basierend auf Text. Dieses Problem wird heute durch zwei Ansätze gelöst:
- Einheitenauswahl [1] oder ein verketteter Ansatz. Es basiert auf dem Verkleben von Audiofragmenten. Seit den späten 90er Jahren gilt es seit langem als De-facto-Standard für die Entwicklung von Sprachsynthese-Engines. Zum Beispiel könnte in Siri [2] eine Stimme gefunden werden, die mit der Geräteauswahlmethode erklingt.
- Parametrische Sprachsynthese [3], deren Kern darin besteht, ein Wahrscheinlichkeitsmodell zu erstellen, das die akustischen Eigenschaften eines Audiosignals für einen bestimmten Text vorhersagt.
Die Sprache von Einheitenauswahlmodellen ist von hoher Qualität, geringer Variabilität und erfordert eine große Datenmenge für das Training. Während für das Training parametrischer Modelle eine viel geringere Datenmenge benötigt wird, erzeugen sie unterschiedlichere Intonationen, litten jedoch bis vor kurzem unter einer im Vergleich zum Ansatz der Geräteauswahl insgesamt eher schlechten Klangqualität.
Mit der Entwicklung von Deep-Learning-Technologien haben parametrische Synthesemodelle jedoch ein signifikantes Wachstum bei allen Qualitätsmetriken erzielt und können Sprache erzeugen, die praktisch nicht von menschlicher Sprache zu unterscheiden ist.
Qualitätsmetriken
Bevor Sie darüber sprechen, welche Sprachsynthesemodelle besser sind, müssen Sie die Qualitätsmetriken bestimmen, anhand derer die Algorithmen verglichen werden.
Da derselbe Text auf unendlich viele Arten gelesen werden kann, gibt es a priori keinen richtigen Weg, um eine bestimmte Phrase auszusprechen. Daher sind die Metriken für die Qualität der Sprachsynthese oft subjektiv und hängen von der Wahrnehmung des Hörers ab.
Die Standardmetrik ist der MOS (Mean Opinion Score), eine durchschnittliche Bewertung der Natürlichkeit von Sprache, die von Bewertern für synthetisierte Audiodaten auf einer Skala von 1 bis 5 angegeben wird. Eine bedeutet völlig unplausiblen Klang und fünf bedeutet Sprache, die nicht vom Menschen zu unterscheiden ist. Bei echten Personen liegen die Aufzeichnungen normalerweise bei etwa 4,5, und ein Wert über 4 wird als ziemlich hoch angesehen.
Wie Sprachsynthese funktioniert
Der erste Schritt zum Aufbau eines Sprachsynthesesystems ist das Sammeln von Daten für das Training. In der Regel handelt es sich dabei um hochwertige Audioaufnahmen, auf denen der Ansager speziell ausgewählte Phrasen liest. Die ungefähre Größe des Datensatzes, der für Modelle zur Auswahl von Trainingseinheiten benötigt wird, beträgt 10 bis 20 Stunden reine Sprache [2], während für Methoden zur Parametrisierung des neuronalen Netzwerks die obere Schätzung etwa 25 Stunden beträgt [4, 5].
Wir diskutieren beide Synthesetechnologien.
Geräteauswahl
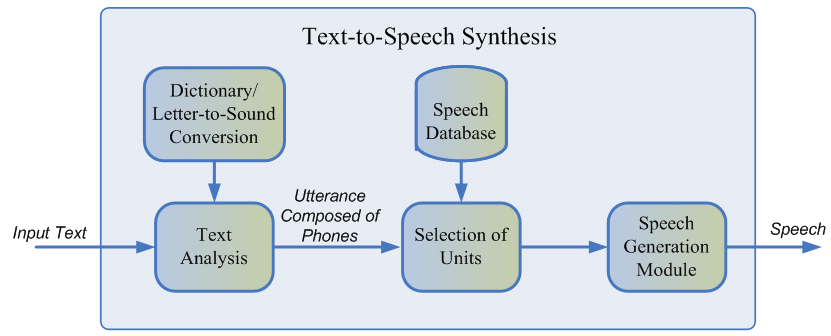
Typischerweise kann die aufgezeichnete Sprache des Sprechers nicht alle möglichen Fälle abdecken, in denen die Synthese verwendet wird. Daher besteht der Kern der Methode darin, die gesamte Audiobasis in kleine Fragmente, sogenannte Units, zu teilen, die dann mit minimaler Nachbearbeitung zusammengeklebt werden. Einheiten sind in der Regel minimale akustische Spracheinheiten, z. B. Telefone oder Diphons [2].
Der gesamte Generierungsprozess besteht aus zwei Phasen: dem NLP-Frontend, das für das Extrahieren der sprachlichen Darstellung des Texts verantwortlich ist, und dem Backend, das die Einheitsstraffunktion für die angegebenen sprachlichen Merkmale berechnet. Das NLP-Frontend enthält:
- Die Aufgabe des Normalisierens des Textes besteht darin, alle Nichtbuchstaben (Zahlen, Prozentzeichen, Währungen usw.) in ihre verbale Darstellung zu übersetzen. Zum Beispiel sollte "5%" in "5%" umgewandelt werden.
- Extrahieren von Sprachmerkmalen aus einem normalisierten Text: Phonemdarstellung, Stress, Wortarten usw.
In der Regel wird das NLP-Frontend mithilfe manuell vorgeschriebener Regeln für eine bestimmte Sprache implementiert. In letzter Zeit besteht jedoch eine zunehmende Tendenz zur Verwendung von Modellen für maschinelles Lernen [7].
Die vom Back-End-Subsystem geschätzte Strafe ist die Summe der Zielkosten oder der Entsprechung der akustischen Darstellung der Einheit für ein bestimmtes Phonem und der Verkettungskosten, dh der Angemessenheit der Verbindung zweier benachbarter Einheiten. Zur Bewertung der Feinfunktionen kann man die Regeln oder das bereits trainierte akustische Modell der parametrischen Synthese verwenden [2]. Die Auswahl der aus Sicht der oben definierten Strafen optimalsten Abfolge von Einheiten erfolgt mit dem Viterbi-Algorithmus [1].
Ungefähre Werte der Auswahlmodelle für MOS-Einheiten für die englische Sprache: 3,7-4,1 [2, 4, 5].
Vorteile des Einheitenselektionsansatzes:
- Der natürliche Klang.
- High-Speed-Generierung.
- Geringe Modellgröße - Dies ermöglicht es Ihnen, die Synthese direkt auf Ihrem Mobilgerät zu verwenden.
Nachteile:
- Die synthetisierte Sprache ist eintönig, enthält keine Emotionen.
- Charakteristische Klebegegenstände.
- Es erfordert eine ausreichend große Trainingsbasis für Audiodaten, um alle Arten von Kontexten abzudecken.
- Im Prinzip kann kein Ton erzeugt werden, der nicht im Trainingssatz enthalten ist.
Parametrische Sprachsynthese
Der parametrische Ansatz basiert auf der Idee, ein probabilistisches Modell zu erstellen, das die Verteilung der akustischen Merkmale eines bestimmten Textes schätzt.
Der Prozess der Sprachgenerierung in der parametrischen Synthese kann in vier Stufen unterteilt werden:
- Das NLP-Frontend ist die gleiche Phase der Datenvorverarbeitung wie beim Unit-Selection-Ansatz, was zu einer Vielzahl kontextsensitiver sprachlicher Funktionen führt.
- Durationsmodell zur Vorhersage der Phonemdauer.
- Ein akustisches Modell, das die Verteilung der akustischen Merkmale auf die sprachlichen wiederherstellt. Akustische Merkmale umfassen Grundfrequenzwerte, spektrale Darstellung des Signals und so weiter.
- Ein Vocoder, der akustische Merkmale in eine Schallwelle übersetzt.
Für Trainingsdauer- und Akustikmodelle können versteckte Markov-Modelle [3], tiefe neuronale Netze oder deren wiederkehrende Varietäten [6] verwendet werden. Ein herkömmlicher Vocoder ist ein Algorithmus, der auf dem Quellfiltermodell [3] basiert und davon ausgeht, dass Sprache das Ergebnis der Anwendung eines linearen Rauschfilters auf das ursprüngliche Signal ist.
Die allgemeine Sprachqualität klassischer parametrischer Methoden ist aufgrund der Vielzahl unabhängiger Annahmen über die Struktur des Schallerzeugungsprozesses recht gering.
Mit dem Aufkommen von Deep-Learning-Technologien ist es jedoch möglich geworden, End-to-End-Modelle zu trainieren, die akustische Zeichen direkt per Buchstabe vorhersagen. Beispielsweise geben die neuronalen Netze Tacotron [4] und Tacotron 2 [5] eine Folge von Buchstaben ein und geben das Kreidespektrogramm unter Verwendung des Algorithmus seq2seq [8] zurück. Somit werden die Schritte 1 bis 3 des klassischen Ansatzes durch ein einzelnes neuronales Netzwerk ersetzt. Das folgende Diagramm zeigt die Architektur des Tacotron 2-Netzwerks, mit dem eine recht hohe Klangqualität erzielt wird.
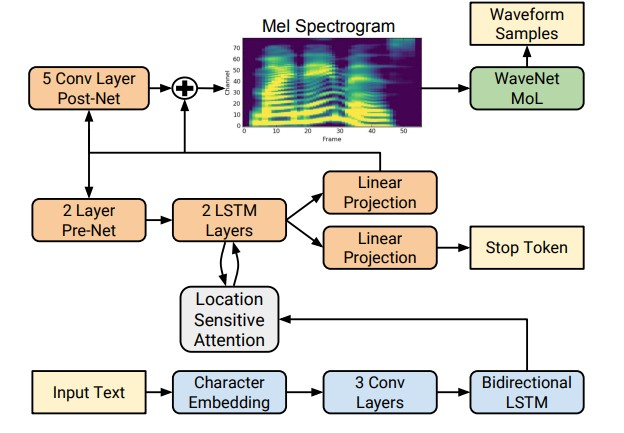
Ein weiterer Faktor für eine signifikante Steigerung der Qualität von synthetisierter Sprache war die Verwendung von Vocodern für neuronale Netze anstelle von Algorithmen für die digitale Signalverarbeitung.
Der erste derartige Vocoder war das neuronale WaveNet-Netzwerk [9], das nacheinander schrittweise die Amplitude der Schallwelle vorhersagte.
Aufgrund der Verwendung einer großen Anzahl von Faltungsschichten mit Lücken, um mehr Kontext zu erfassen und Verbindungen in der Netzwerkarchitektur zu überspringen, konnte eine Verbesserung des MOS um etwa 10% im Vergleich zu Einheitenauswahlmodellen erzielt werden. Das folgende Diagramm zeigt die Architektur des WaveNet-Netzwerks.

Der Hauptnachteil von WaveNet ist die niedrige Geschwindigkeit, die mit einer seriellen Signalabtastschaltung verbunden ist. Dieses Problem kann entweder durch technische Optimierung für eine bestimmte Eisenarchitektur oder durch Ersetzen des Stichprobenplans durch ein schnelleres gelöst werden.
Beide Ansätze wurden in der Branche erfolgreich umgesetzt. Die erste ist bei Tinkoff.ru und als Teil des zweiten Ansatzes führte Google 2017 das Parallel WaveNet [10] -Netzwerk ein, dessen Errungenschaften im Google-Assistenten verwendet werden.
Ungefähre MOS-Werte für neuronale Netzwerkmethoden: 4.4–4.5 [5, 11], dh synthetisierte Sprache unterscheidet sich praktisch nicht von menschlicher Sprache.
Vorteile der parametrischen Synthese:
- Natürlicher und weicher Klang bei Verwendung des End-to-End-Ansatzes.
- Größere Vielfalt in der Intonation.
- Verwenden Sie weniger Daten als Modelle zur Einheitenauswahl.
Nachteile:
- Niedrige Geschwindigkeit im Vergleich zur Geräteauswahl.
- Große rechnerische Komplexität.
So funktioniert die Tinkoff-Sprachsynthese
Wie aus dem Aufsatz hervorgeht, sind Methoden der parametrischen Sprachsynthese, die auf neuronalen Netzen basieren, dem Ansatz der Einheitenauswahl derzeit in ihrer Qualität erheblich überlegen und viel einfacher zu entwickeln. Um unsere eigene Synthesemaschine zu bauen, haben wir sie verwendet.
Für Trainingsmodelle wurden ca. 25 Stunden reine Sprache eines professionellen Sprechers verwendet. Lesetexte wurden speziell ausgewählt, um die Phonetik der Umgangssprache möglichst vollständig abzudecken. Um die Intonationssynthese abwechslungsreicher zu gestalten, haben wir den Ansager außerdem gebeten, je nach Kontext Texte mit einem Ausdruck zu lesen.
Die Architektur unserer Lösung sieht konzeptionell folgendermaßen aus:
- NLP-Frontend, das die Textnormalisierung des neuronalen Netzwerks und ein Modell zum Platzieren von Pausen und Spannungen umfasst.
- Tacotron 2 akzeptiert Buchstaben als Eingabe.
- Autoregressives WaveNet, das in Echtzeit auf der CPU arbeitet.
Dank dieser Architektur generiert unsere Engine Ausdruckssprache in hoher Qualität in Echtzeit, erfordert keine Erstellung eines Phonemwörterbuchs und ermöglicht die Steuerung von Belastungen in einzelnen Wörtern. Beispiele für synthetisiertes Audio können durch Klicken auf den Link angehört werden .
Referenzen:
[1] AJ Hunt, AW Black. Einheitenauswahl in einem verketteten Sprachsynthesesystem unter Verwendung einer großen Sprachdatenbank, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-gesteuerte Geräteauswahl Text-to-Speech-System, Interspeech, 2017.
[3] H. Zen, K. Tokuda, AW Black. Statistische parametrische Sprachsynthese, Speech Communication, Vol. 3, No. 51, nein. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Gänseblümchen Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous . Tacotron: Auf dem Weg zur Ende-zu-Ende-Sprachsynthese.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Natürliche TTS-Synthese durch Konditionierung von WaveNet anhand von Mel-Spektrogramm-Vorhersagen.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Statistische parametrische Sprachsynthese mit tiefen neuronalen Netzen.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman und Brian Roark. Neuronale Modelle der Textnormalisierung für Sprachanwendungen.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequenz zu Sequenz Lernen mit neuronalen Netzen.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior und Koray Kavukcuoglu. WaveNet: Ein generatives Modell für Raw Audio.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman , Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Schnelle High-Fidelity-Sprachsynthese.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Parallele Wellenerzeugung in End-to-End-Text-to-Speech.
[12] Dario Rethage, Jordi Pons und Xavier Serra. Ein Wavenet zum Entrauschen von Sprache.