
Neuronale Netze in der Bildverarbeitung entwickeln sich aktiv weiter, viele Aufgaben sind noch lange nicht gelöst. Um auf Ihrem Gebiet im Trend zu sein, folgen Sie einfach den Influencern auf Twitter und lesen Sie die relevanten Artikel auf arXiv.org. Wir hatten jedoch die Gelegenheit, an der Internationalen Konferenz für Computer Vision (ICCV) 2019 teilzunehmen. Dieses Jahr findet sie in Südkorea statt. Jetzt möchten wir mit den Lesern von Habr teilen, dass wir gesehen und gelernt haben.
Es waren viele von uns von Yandex: unbemannte Fahrzeugentwickler, Forscher und Mitarbeiter, die mit CV-Aufgaben im Servicebereich befasst waren, sind eingetroffen. Jetzt wollen wir jedoch eine etwas subjektive Sichtweise unseres Teams vorstellen - das Machine Intelligence Labor (Yandex MILAB). Andere Leute haben die Konferenz wahrscheinlich aus ihrem Blickwinkel betrachtet.
Was macht das Labor?Wir machen experimentelle Projekte zur Erzeugung von Bildern und Musik für Unterhaltungszwecke. Wir sind besonders an neuronalen Netzen interessiert, mit denen Sie den Inhalt des Benutzers ändern können (für ein Foto wird diese Aufgabe als Bildbearbeitung bezeichnet).
Ein Beispiel für das Ergebnis unserer Arbeit von der YaC-Konferenz 2019.
Es gibt viele wissenschaftliche Konferenzen, von denen sich jedoch die wichtigsten, sogenannten A * -Konferenzen abheben, auf denen in der Regel Artikel über die interessantesten und wichtigsten Technologien veröffentlicht werden. Es gibt keine genaue Liste der A * -Konferenzen, hier ein Beispiel und unvollständig: NeurIPS (früher NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Die letzten drei sind auf das Thema Lebenslauf spezialisiert.
ICCV auf einen Blick: Poster, Tutorials, Workshops, Stände
1075 Vorträge wurden auf der Konferenz angenommen, die Teilnehmerzahl betrug 7.500. 103 Personen kamen aus Russland, es gab Artikel von Mitarbeitern von Yandex, Skoltech, dem Samsung AI Center Moskau und der Samara University. In diesem Jahr besuchten nicht viele Spitzenforscher das ICCV, aber hier zum Beispiel Alexey (Alyosha) Efros, der immer viele Menschen versammelt:

Bei all diesen Konferenzen werden Artikel in Form von Postern (
mehr zum Format) und die besten auch in Form von Kurzberichten präsentiert.
Hier ist ein Teil der Arbeit aus Russland In den Tutorials können Sie sich in ein Fachgebiet eintauchen, es ähnelt einer Vorlesung an einer Universität. Es wird von einer Person gelesen, normalerweise ohne über bestimmte Werke zu sprechen. Beispiel für ein cooles Tutorial (
Michael Brown, Grundlegendes zu Farben und der kamerainternen Bildverarbeitungs-Pipeline für Computer Vision ):

In Workshops sprechen sie dagegen über Artikel. In der Regel handelt es sich dabei um Arbeiten zu einem engen Thema, Geschichten von Laborleitern über die neuesten Arbeiten der Studenten oder Artikel, die auf der Hauptkonferenz nicht akzeptiert wurden.
Sponsoring-Unternehmen kommen mit Ständen auf die ICCV. In diesem Jahr kamen Google, Facebook, Amazon und viele andere internationale Unternehmen sowie eine große Anzahl von Start-ups - Koreaner und Chinesen. Es gab besonders viele Startups, die sich auf Datenmarkierungen spezialisiert haben. An den Ständen finden Vorstellungen statt, man kann Waren mitnehmen und Fragen stellen. Sponsoring-Unternehmen haben Parteien für die Jagd. Sie schaffen es, Personalvermittler davon zu überzeugen, dass Sie interessiert sind und möglicherweise interviewt werden können. Wenn Sie einen Artikel veröffentlicht (oder darüber hinaus eine Präsentation damit erstellt), die Promotion begonnen oder beendet haben, ist dies ein Plus, aber manchmal können Sie sich auf einen Stand einigen und den Ingenieuren des Unternehmens interessante Fragen stellen.
Trends
Bei der Konferenz können Sie einen Blick auf den gesamten Lebenslauf werfen. Anhand der Anzahl der Poster zu einem bestimmten Thema können Sie bewerten, wie aktuell das Thema ist. Einige Schlussfolgerungen bitten um die Schlüsselwörter:

Zero-Shot, One-Shot, Wenig-Shot, Selbst- und Halb-Supervised: Neue Ansätze für lang untersuchte Probleme
Die Menschen lernen, Daten effizienter zu nutzen. In
FUNIT können Sie beispielsweise Gesichtsausdrücke von Tieren generieren, die nicht im Trainingssatz enthalten waren (Anwenden mehrerer Referenzbilder in der Anwendung). Die Ideen von Deep Image Prior wurden entwickelt, und jetzt können
GAN- Netzwerke in einem Bild trainiert werden - darüber werden wir später
in den Höhepunkten sprechen. Sie können die Selbstüberwachung vor dem Training verwenden (um ein Problem zu lösen, bei dem Sie ausgerichtete Daten synthetisieren können, um beispielsweise den Drehwinkel eines Bildes vorherzusagen) oder gleichzeitig aus markierten und unmarkierten Daten lernen. In diesem Sinne kann die Krone der Schöpfung als ein Artikel
S4L betrachtet werden: Selbstüberwachtes halbüberwachtes Lernen . Das Pre-Training in ImageNet
hilft jedoch nicht immer .

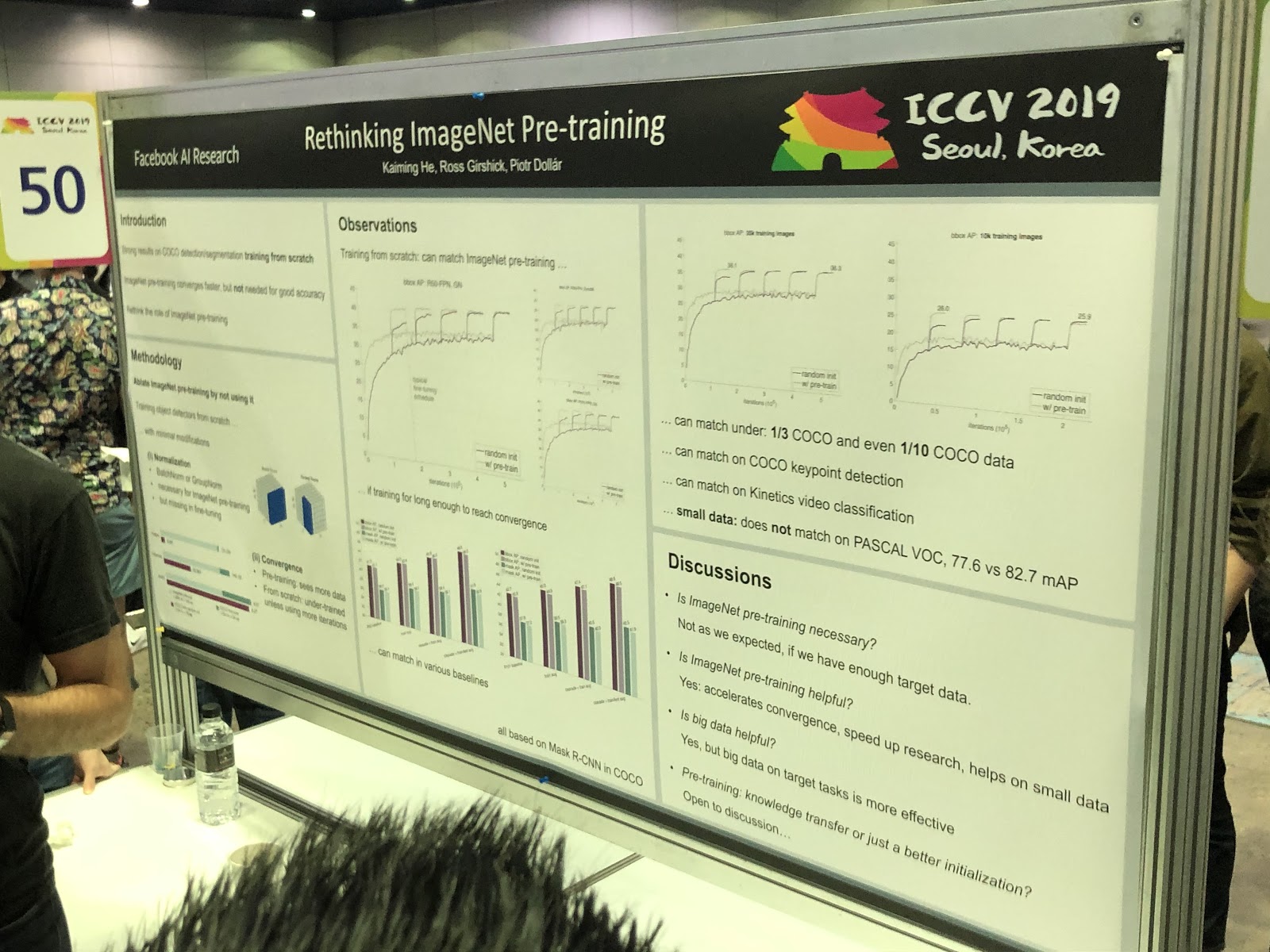
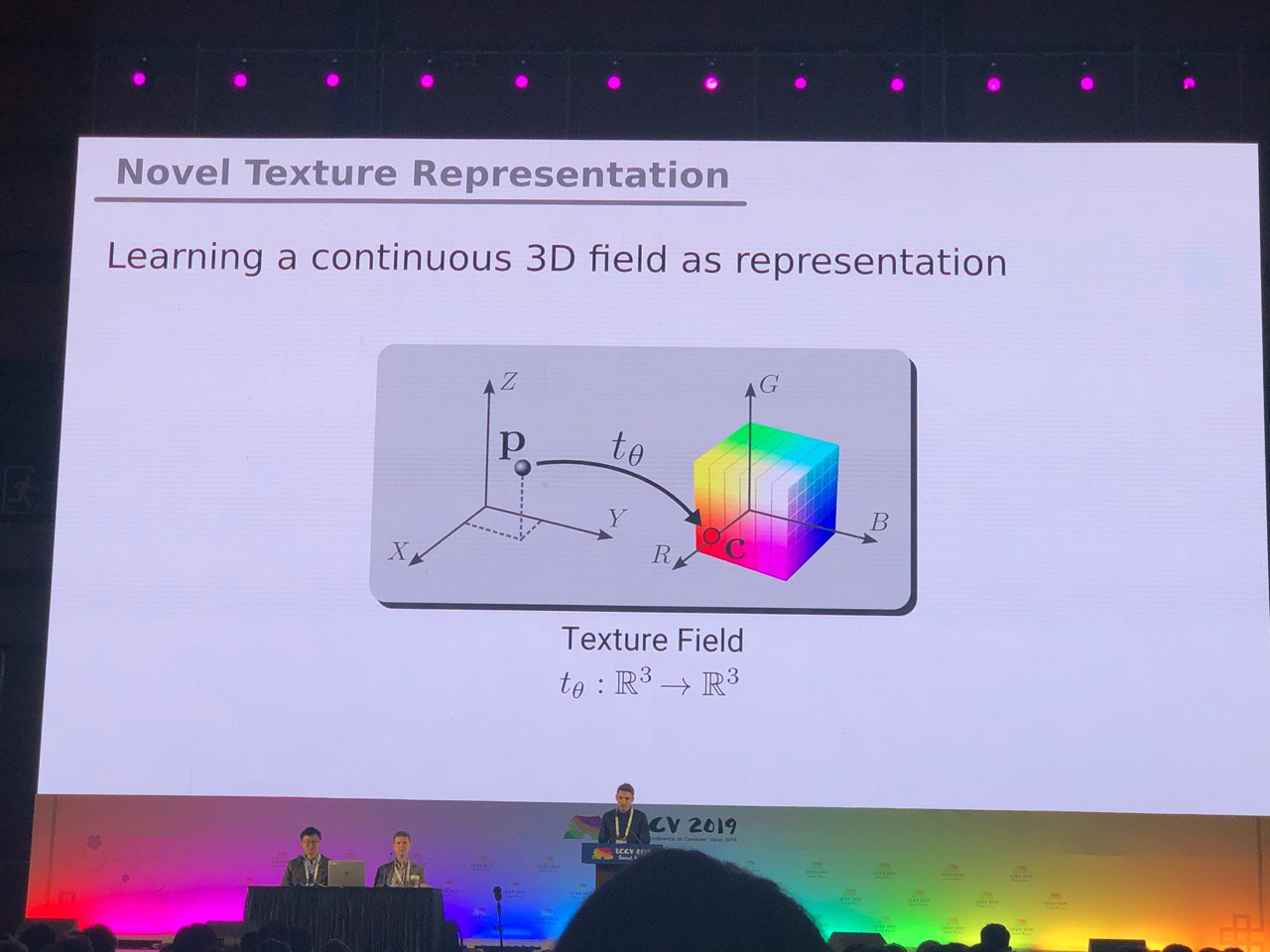
3D und 360 °
Aufgaben, die hauptsächlich für Fotos (Segmentierung, Erkennung) gelöst werden, erfordern zusätzliche Recherchen für 3D-Modelle und Panorama-Videos. Wir haben viele Artikel über die Konvertierung von RGB und
RGB-D in 3D gesehen. Einige Aufgaben, wie das Bestimmen der Pose einer Person (Posenschätzung), werden natürlicher gelöst, wenn wir dreidimensionale Modelle verwenden. Bisher besteht jedoch kein Konsens darüber, wie 3D-Modelle genau dargestellt werden sollen - in Form eines Rasters, einer Punktewolke, von
Voxeln oder
SDF . Hier ist eine andere Option:
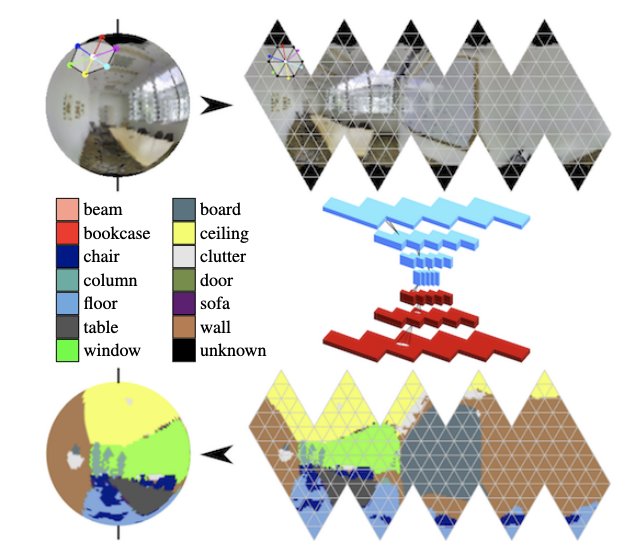
In den Panoramen entwickeln sich aktiv Windungen auf der Kugel (siehe
Orientierungsbewusste semantische Segmentierung auf Ikosaederkugeln ) und die Suche nach Schlüsselobjekten im Rahmen.
Definition der Körperhaltung und Vorhersage menschlicher Bewegungen
Um die Pose in 2D zu bestimmen, gibt es bereits Erfolge - jetzt hat sich der Fokus auf die Arbeit mit mehreren Kameras und in 3D verlagert. Sie können beispielsweise das Skelett durch die Wand bestimmen und Änderungen im WLAN-Signal verfolgen, während es durch den menschlichen Körper fließt.
Auf dem Gebiet der Hand-Schlüsselpunkterkennung wurde viel Arbeit geleistet. Es wurden neue Datensätze angezeigt, einschließlich derer, die auf Videos mit den Dialogen von zwei Personen basieren. Jetzt können Sie Handbewegungen anhand von Audio oder Text einer Unterhaltung vorhersagen. Die gleichen Fortschritte wurden bei den Aufgaben zur Beurteilung des Blicks erzielt.

Sie können auch eine große Sammlung von Werken zur Vorhersage menschlicher Bewegungen hervorheben (z. B.
Human Motion Prediction über räumlich-zeitliches Inpainting oder
Structured Prediction Helps 3D Human Motion Modeling ). Die Aufgabe ist wichtig und wird auf der Grundlage von Gesprächen mit den Autoren am häufigsten zur Analyse des Verhaltens von Fußgängern beim autonomen Fahren verwendet.
Manipulieren von Personen in Fotos und Videos, virtuelle Umkleidekabinen
Der Haupttrend besteht darin, die Gesichtsbilder in Bezug auf die interpretierten Parameter zu ändern. Ideen:
Deepfake auf einem Bild, Ausdrucksänderung durch Gesichtsrendering (
PuppetGAN ), Feedforward-Änderung von Parametern (z. B.
Alter ). Stilübertragungen wurden vom Titel des Themas in die Anwendung der Arbeit verschoben. Eine andere Geschichte - virtuelle Umkleidekabinen, die fast immer schlecht funktionieren,
hier ein Beispiel für eine Demo.


Sketch / Graph Generation
Die Entwicklung der Idee „Lass das Gitter etwas basierend auf früheren Erfahrungen erzeugen“ ist anders geworden: „Zeigen wir dem Gitter, welche Option uns interessiert.“
SC-FEGAN ermöglicht Ihnen geführtes Malen: Der Benutzer kann einen Teil des Gesichts im gelöschten Bereich des Bildes zeichnen und das wiederhergestellte Bild abhängig vom Rendering erhalten.

In einem der 25 Adobe-Artikel für ICCV werden zwei GANs kombiniert: Einer zeichnet eine Skizze für den Benutzer, der andere generiert aus der Skizze ein fotorealistisches Bild (
Projektseite ).

Früher bei der Erstellung von Bildern wurden keine Grafiken benötigt, jetzt wurden sie zu einem Wissensbehälter über die Szene. Der ICCV Best Paper Honourable Mentions Award wurde auch für den Artikel
Specifying Object Attributes and Relations in Interactive Scene Generation verliehen . Im Allgemeinen können Sie sie auf verschiedene Arten verwenden: Generieren Sie Grafiken aus Bildern oder Bilder und Texte aus Grafiken.
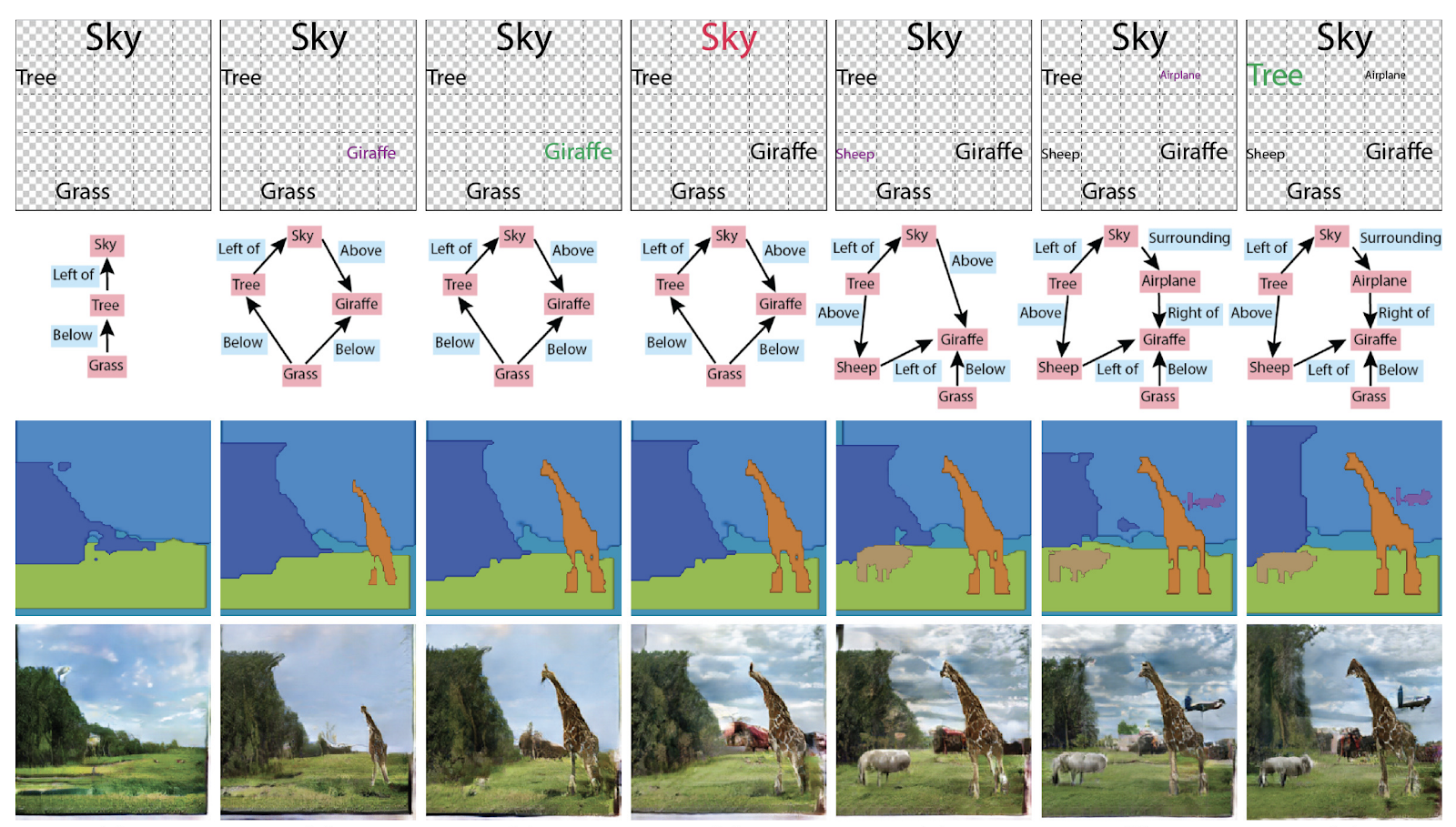
Neuidentifizierung von Personen und Maschinen, Zählung der Menschenmenge (!)
Viele Artikel widmen sich der Verfolgung von Personen und der
erneuten Identifizierung von Personen und Maschinen. Was uns jedoch überraschte, war eine Reihe von Artikeln über das Zählen von Menschen in einer Menschenmenge und allesamt aus China.
Facebook hingegen anonymisiert das Foto. Außerdem macht es das auf interessante Weise: Es lehrt das neuronale Netzwerk, ein Gesicht ohne eindeutige Details zu erzeugen - ähnlich, aber nicht so sehr, dass es von Gesichtserkennungssystemen korrekt erkannt wird.

Schutz vor gegnerischen Angriffen
Mit der Entwicklung von Computer-Vision-Anwendungen in der realen Welt (in unbemannten Fahrzeugen, in der Gesichtserkennung) stellt sich immer häufiger die Frage nach der Zuverlässigkeit solcher Systeme. Um CV vollständig nutzen zu können, müssen Sie sicherstellen, dass das System widerstandsfähig gegen feindliche Angriffe ist. Daher gab es nicht weniger Artikel zum Schutz vor solchen Angriffen als zu den Angriffen selbst. Viel Arbeit galt der Erklärung von Netzwerkvorhersagen (Saliency Map) und der Messung des Vertrauens in das Ergebnis.
Kombinierte Aufgaben
Bei den meisten Aufgaben mit einem Ziel sind die Möglichkeiten zur Qualitätsverbesserung nahezu ausgeschöpft: Einer der neuen Bereiche für weiteres Qualitätswachstum besteht darin, neuronale Netze zu lehren, mehrere ähnliche Probleme gleichzeitig zu lösen. Beispiele:
- Vorhersage von Handlungen + Vorhersage des optischen Flusses,
- Videopräsentation +
Sprachdarstellung (
VideoBERT ),
-
Superauflösung + HDR .
Und es gab Artikel über Segmentierung, die die Haltung und die erneute Identifizierung von Tieren festlegten!

Höhepunkte
Fast alle Artikel waren im Voraus bekannt, der Text war auf arXiv.org verfügbar. Daher erscheint die Präsentation von Werken wie Everybody Dance Now, FUNIT, Image2StyleGAN eher seltsam - dies sind sehr nützliche, aber keineswegs neue Werke. Hier scheint der klassische Prozess der wissenschaftlichen Publikation zu scheitern - die Wissenschaft entwickelt sich zu schnell.
Es ist sehr schwierig, die besten Werke zu bestimmen - es gibt viele davon, die Themen sind unterschiedlich. Mehrere Artikel haben
Auszeichnungen und Referenzen erhalten .
Wir wollen Arbeiten hervorheben, die im Hinblick auf die Bildmanipulation interessant sind, da dies unser Thema ist. Sie erwiesen sich für uns als recht frisch und interessant (wir geben nicht vor, objektiv zu sein).
SinGAN (Best Paper Award) und InGAN
SinGAN:
Projektseite ,
arXiv ,
Code .
InGAN:
Projektseite ,
arXiv ,
Code .
Die Entwicklung der Idee von Deep Image Prior durch Dmitry Ulyanov, Andrea Vedaldi und Victor Lempitsky. Anstatt GAN auf einem Datensatz zu trainieren, lernen Netzwerke aus Fragmenten desselben Bildes, um Statistiken darin zu speichern. Das geschulte Netzwerk ermöglicht es Ihnen, Fotos (SinGAN) zu bearbeiten und zu animieren oder neue Bilder jeder Größe aus den Texturen des Originalbilds zu generieren, wobei die lokale Struktur (InGAN) beibehalten wird.
SinGAN:

InGAN:

Sehen, was ein GAN nicht generieren kann
Projektseite .
Bilderzeugende neuronale Netze empfangen häufig einen zufälligen Rauschvektor als Eingabe. In einem trainierten Netzwerk bilden viele Eingabevektoren einen Raum, kleine Bewegungen, die zu kleinen Änderungen im Bild führen. Mithilfe der Optimierung können Sie das umgekehrte Problem lösen: Finden Sie einen geeigneten Eingabevektor für ein Bild aus der realen Welt. Der Autor zeigt, dass es fast nie möglich ist, ein vollständig passendes Bild in einem neuronalen Netzwerk zu finden. Einige Objekte im Bild werden nicht generiert (anscheinend aufgrund der großen Variabilität dieser Objekte).
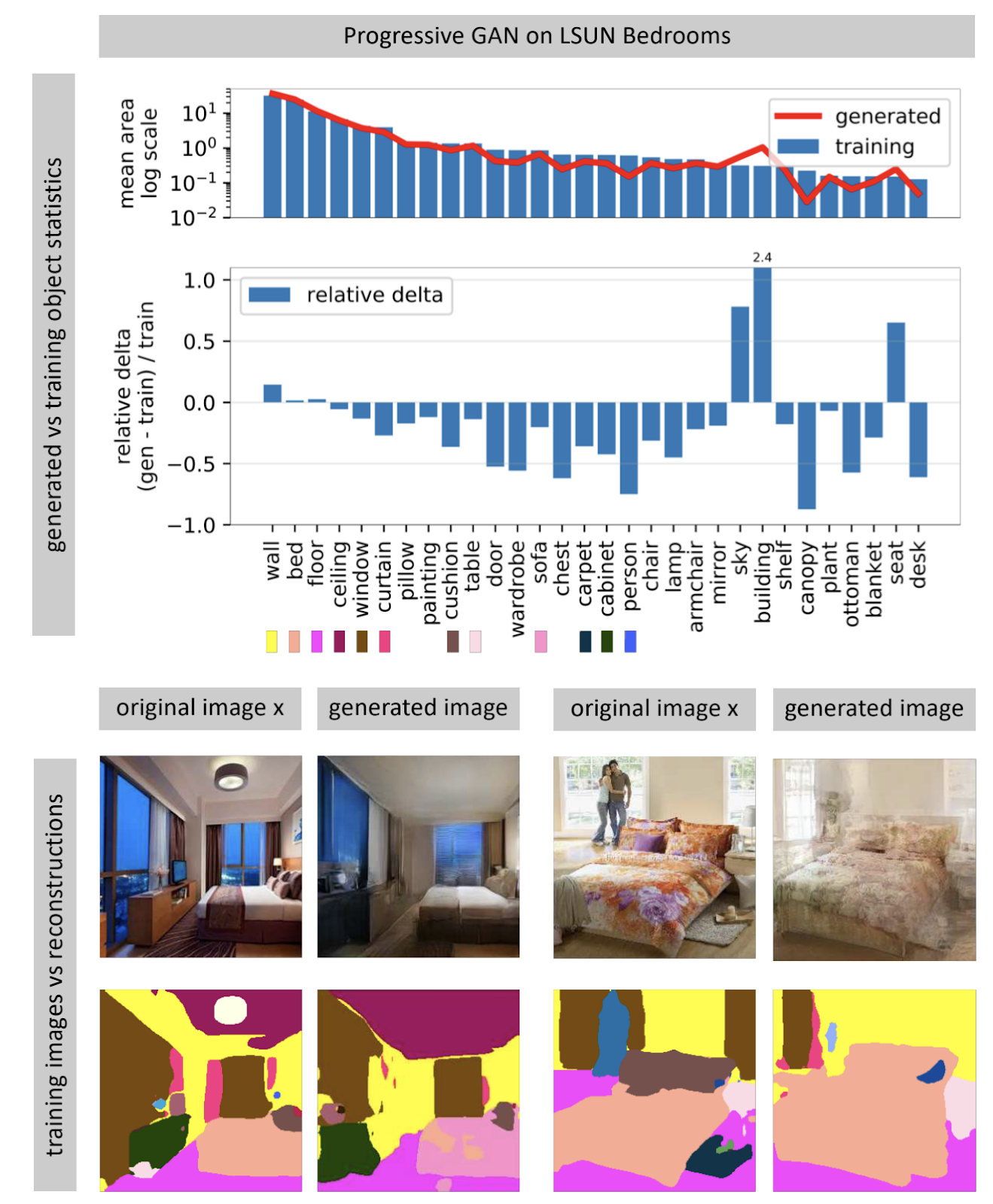
Der Autor geht davon aus, dass die GAN nicht den gesamten Bildraum abdeckt, sondern nur eine Teilmenge, die mit Löchern wie Käse gefüllt ist. Wenn wir versuchen, Fotos aus der realen Welt zu finden, werden wir immer scheitern, weil die GAN immer noch nicht ganz reale Fotos erzeugt. Sie können die Unterschiede zwischen realen und generierten Bildern nur überwinden, indem Sie das Gewicht des Netzwerks ändern, dh es für ein bestimmtes Foto neu trainieren.

Wenn das Netzwerk für ein bestimmtes Foto erneut trainiert wird, können Sie versuchen, verschiedene Manipulationen mit diesem Bild durchzuführen. Im folgenden Beispiel wurde dem Foto ein Fenster hinzugefügt, und das Netzwerk erzeugte zusätzlich Reflexionen am Küchenset. Dies bedeutet, dass das Netzwerk nach der Umschulung für die Fotografie nicht die Fähigkeit verlor, die Verbindung zwischen den Objekten der Szene zu erkennen.

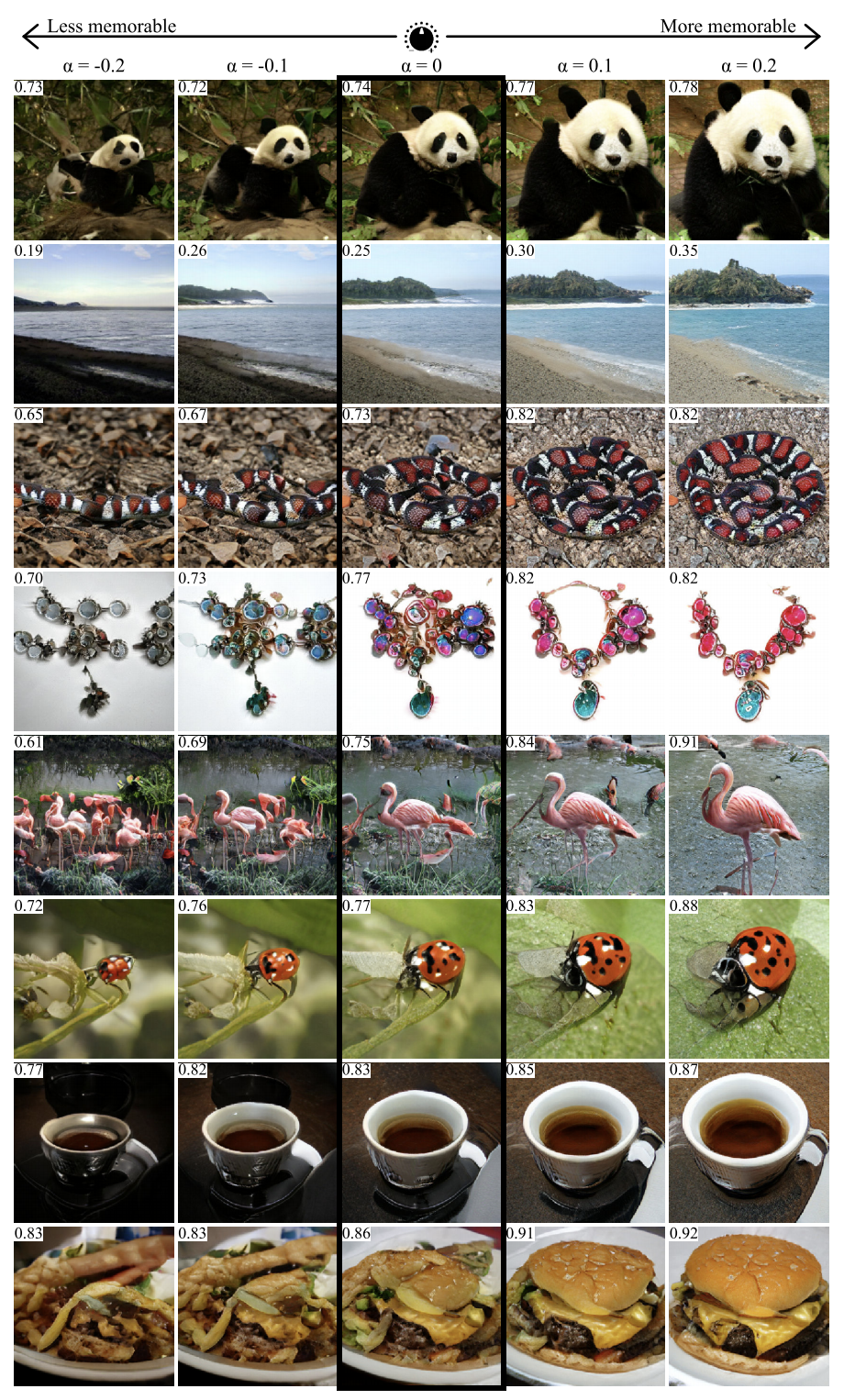
GANalyze: Visuelle Definitionen kognitiver Bildeigenschaften
Projektseite ,
arXiv .
Mit dem Ansatz aus dieser Arbeit können Sie visualisieren und analysieren, was das neuronale Netzwerk gelernt hat. Die Autoren schlagen das Training GAN vor, um Bilder zu erstellen, für die das Netzwerk gegebene Vorhersagen generiert. In dem Artikel wurden mehrere Netzwerke als Beispiele verwendet, einschließlich MemNet, das die Erinnerbarkeit von Fotos vorhersagt. Es stellte sich heraus, dass das Objekt auf dem Foto zur besseren Einprägsamkeit:
- näher an der Mitte sein
- eine runde oder quadratische Form und eine einfache Struktur haben,
- auf einem einheitlichen hintergrund sein,
- ausdrucksstarke Augen enthalten (zumindest für Fotos von Hunden),
- sei heller, reicher, in manchen Fällen - röter.
Liquid Warping GAN: Ein einheitliches Framework für die Nachahmung menschlicher Bewegungen, die Übertragung von Erscheinungsbildern und die Synthese neuartiger Ansichten
Projektseite ,
arXiv ,
Code .
Pipeline zum Erzeugen von Fotos von Personen aus einem Foto. Die Autoren zeigen erfolgreiche Beispiele für die Übertragung der Bewegung einer Person auf eine andere, die Übertragung von Kleidung zwischen Menschen und die Generierung neuer Perspektiven einer Person - alles auf einem Foto. Im Gegensatz zu früheren Arbeiten werden hier zum Erstellen von Bedingungen nicht Schlüsselpunkte in 2D (Pose) verwendet, sondern ein 3D-Netz des Körpers (Pose + Form). Die Autoren haben auch herausgefunden, wie Informationen vom Originalbild auf das generierte übertragen werden können (Liquid Warping Block). Die Ergebnisse sehen anständig aus, aber die Auflösung des resultierenden Bildes beträgt nur 256x256. Zum Vergleich: vid2vid, das vor einem Jahr auf den Markt kam, kann mit einer Auflösung von 2048 x 1024 Pixel erstellt werden, benötigt jedoch bis zu 10 Minuten Videoaufnahme als Datensatz.

FSGAN: Agnostisches Face Swapping und Reenactment
Projektseite ,
arXiv .
Auf den ersten Blick scheint das nichts Ungewöhnliches zu sein: Deepfake mit mehr oder weniger normaler Qualität. Die Hauptleistung der Arbeit ist jedoch die Substitution von Gesichtern in einem Bild. Im Gegensatz zu früheren Arbeiten war eine Ausbildung auf einer Vielzahl von Fotografien einer bestimmten Person erforderlich. Die Pipeline erwies sich als umständlich (Nachstellung und Segmentierung, Ansichtsinterpolation, Inpainting, Blending) und mit vielen technischen Hacks, aber das Ergebnis ist es wert.

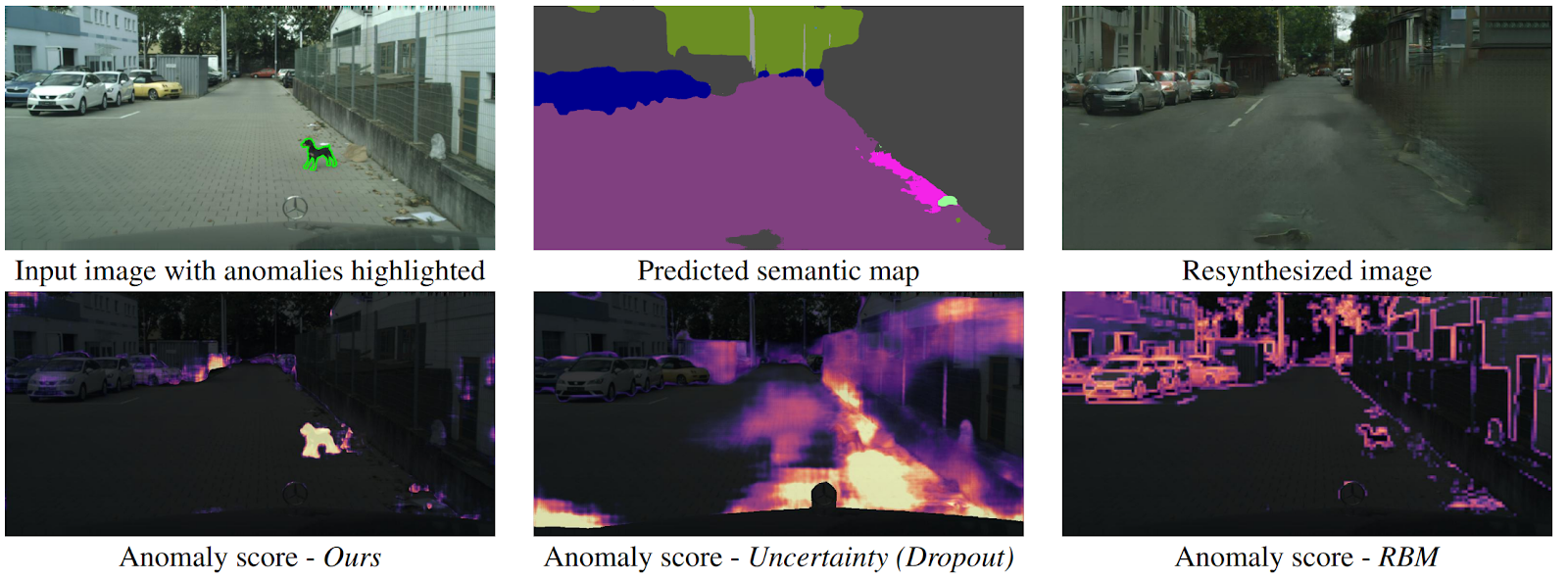
Erkennen des Unerwarteten durch Bildsynthese
arXiv .
Wie kann eine Drohne verstehen, dass plötzlich ein Objekt davor auftauchte, das keiner Klasse semantischer Segmentierung zuzuordnen ist? Es gibt mehrere Methoden, aber die Autoren bieten einen neuen, intuitiven Algorithmus an, der besser als seine Vorgänger funktioniert. Die semantische Segmentierung wird aus dem Eingabebild der Straße vorhergesagt. Es wird in die GAN (pix2pixHD) eingespeist, die versucht, das Originalbild nur von der semantischen Karte wiederherzustellen. Anomalien, die nicht in eines der Segmente fallen, unterscheiden sich erheblich in der Quelle und im generierten Bild. Dann werden drei Bilder (anfänglich, segmentiert und rekonstruiert) an ein anderes Netzwerk gesendet, das Anomalien vorhersagt. Das Dataset hierfür wurde aus dem bekannten Cityscapes-Dataset generiert, wobei versehentlich die Klassen für die semantische Segmentierung geändert wurden. Interessanterweise ist in dieser Umgebung ein Hund, der mitten auf der Straße steht, aber korrekt segmentiert ist (was bedeutet, dass es eine Klasse dafür gibt), keine Anomalie, da das System dies erkennen konnte.
Fazit
Vor der Konferenz ist es wichtig zu wissen, welche wissenschaftlichen Interessen Sie haben, welche Reden ich gerne halten würde und mit wem ich sprechen möchte. Dann wird alles viel produktiver.
ICCV vernetzt sich hauptsächlich. Sie verstehen, dass es Spitzeninstitutionen und Spitzenwissenschaftler gibt, Sie beginnen dies zu verstehen, Menschen kennenzulernen. Und Sie können Artikel über arXiv lesen - und es ist übrigens sehr cool, dass Sie nicht überall nach Wissen suchen können.
Darüber hinaus können Sie auf der Konferenz tief in Themen eintauchen, die nicht in Ihrer Nähe sind, und Trends erkennen. Schreiben Sie eine Liste der Artikel, die Sie lesen möchten. Wenn Sie Student sind, ist dies eine Gelegenheit für Sie, einen potenziellen Wissenschaftler kennenzulernen, wenn Sie aus der Branche stammen, einen neuen Arbeitgeber zu finden und wenn das Unternehmen, dann zeigen Sie sich.
Abonnieren Sie
@loss_function_porn ! Dies ist ein persönliches Projekt: Wir sind zusammen mit
karfly . Die ganze Arbeit, die uns während der Konferenz gefallen hat, haben wir hier gepostet:
@loss_function_live .