
In einem
früheren Artikel haben wir RabbitMQ-Cluster auf Fehlertoleranz und Hochverfügbarkeit untersucht. Nun lasst uns tief in Apache Kafka graben.
Die Replikationseinheit ist hier eine Partition. Jedes Thema hat einen oder mehrere Abschnitte. Jede Sektion hat einen Anführer mit oder ohne Anhänger. Beim Erstellen eines Themas werden die Anzahl der Partitionen und die Replikationsrate angegeben. Der übliche Wert ist 3, was drei Bemerkungen bedeutet: ein Anführer und zwei Anhänger.
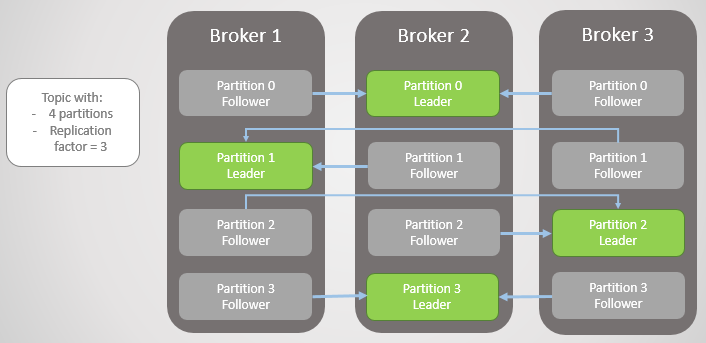 Abb. 1. Vier Abschnitte sind auf drei Makler verteilt
Abb. 1. Vier Abschnitte sind auf drei Makler verteiltAlle Lese- und Schreibanforderungen gehen an den Leiter. Follower senden regelmäßig Anfragen an den Leiter, um die neuesten Nachrichten zu erhalten. Verbraucher wenden sich niemals an Follower, letztere gibt es nur für Redundanz und Fehlertoleranz.

Abschnitt fehlgeschlagen
Wenn ein Broker ausfällt, scheitern häufig Führungskräfte mehrerer Sektionen. In jedem von ihnen wird der Follower eines anderen Knotens zum Anführer. Tatsächlich ist dies nicht immer der Fall, da sich der Synchronisationsfaktor auch auf Folgendes auswirkt: Gibt es synchronisierte Follower, und wenn nicht, ist der Übergang zu einem nicht synchronisierten Replikat zulässig. Aber jetzt wollen wir es nicht komplizieren.
Broker 3 verlässt das Netzwerk - und für Abschnitt 2 wird ein neuer Leader für Broker 2 gewählt.
 Abb. 2. Broker 3 stirbt und sein Anhänger auf Broker 2 wird zum neuen Anführer von Abschnitt 2 gewählt
Abb. 2. Broker 3 stirbt und sein Anhänger auf Broker 2 wird zum neuen Anführer von Abschnitt 2 gewähltDann verlässt Broker 1 und Abschnitt 1 verliert auch seinen Anführer, dessen Rolle an Broker 2 geht.
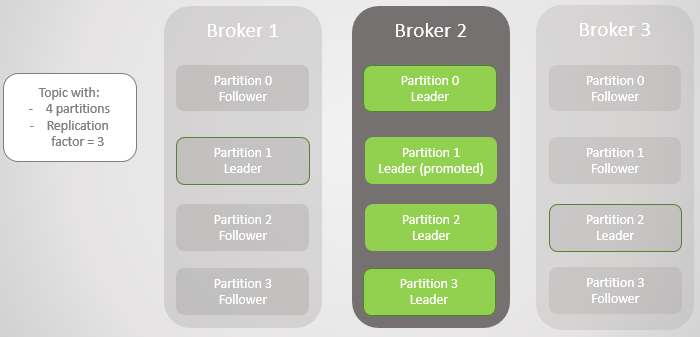 Abb. 3. Es ist nur noch ein Makler übrig. Alle Führungskräfte befinden sich auf demselben Null-Redundanz-Broker.
Abb. 3. Es ist nur noch ein Makler übrig. Alle Führungskräfte befinden sich auf demselben Null-Redundanz-Broker.Wenn Broker 1 zum Netzwerk zurückkehrt, fügt er vier Follower hinzu, wodurch jeder Abschnitt redundant ist. Alle Leader blieben jedoch bei Broker 2.
 Abb. 4. Leader verbleiben bei Broker 2
Abb. 4. Leader verbleiben bei Broker 2Wenn Broker 3 steigt, kehren wir zu drei Replikaten pro Abschnitt zurück. Aber alle Anführer sind immer noch bei Broker 2.
 Abb. 5. Unausgeglichene Platzierung der Führungskräfte nach der Wiederherstellung der Broker 1 und 3
Abb. 5. Unausgeglichene Platzierung der Führungskräfte nach der Wiederherstellung der Broker 1 und 3Kafka hat ein Tool zum besseren Ausgleich von Führungskräften als RabbitMQ. Dort mussten Sie ein Drittanbieter-Plug-In oder -Skript verwenden, das die Richtlinien für die Migration des Hauptknotens geändert hat, indem die Redundanz während der Migration verringert wurde. Außerdem mussten sich große Warteschlangen bei der Synchronisation mit Unzugänglichkeiten abfinden.
Kafka hat ein Konzept von „bevorzugten Hinweisen“ für die Führungsrolle. Wenn die Themenbereiche erstellt werden, versucht Kafka, die Führungslinien gleichmäßig auf die Knoten zu verteilen, und markiert diese ersten Führungslinien als bevorzugt. Im Laufe der Zeit können aufgrund von Serverneustarts, Fehlern und Konnektivitätsfehlern Leiter auf anderen Knoten landen, wie im oben beschriebenen Extremfall.
Um dies zu beheben, bietet Kafka zwei Optionen:
- Mit der Option auto.leader.rebalance.enable = true kann der Controllerknoten Führungslinien automatisch wieder bevorzugten Replikaten zuweisen und dadurch die gleichmäßige Verteilung wiederherstellen.
- Ein Administrator kann das Skript kafka-preferred-replica-election.sh ausführen, um es manuell neu zuzuweisen .
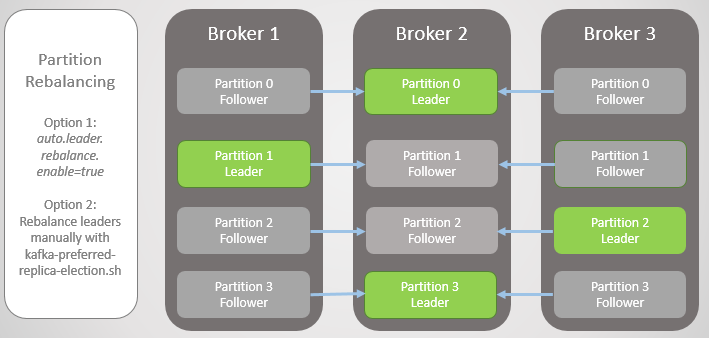 Abb. 6. Replikate nach dem Neuausgleich
Abb. 6. Replikate nach dem NeuausgleichEs war eine vereinfachte Version des Versagens, aber die Realität ist komplexer, obwohl hier nichts zu kompliziert ist. Auf synchronisierte Replikate (In-Sync Replicas, ISR) kommt es an.
Synchronisierte Replikate (ISR)
ISR ist eine Gruppe von Replikaten einer Partition, die als "synchronisiert" (synchronisiert) angesehen wird. Es gibt einen Anführer, aber möglicherweise keine Anhänger. Ein Follower gilt als synchronisiert, wenn er vor Ablauf des Intervalls
replica.lag.time.max.ms exakte Kopien aller Führungsnachrichten
erstellt hat .
Der Follower wird aus dem ISR-Set entfernt, wenn er:
- hat für das Intervall replica.lag.time.max.ms (als tot eingestuft) keine Anforderung zur Stichprobe gestellt
- hatte keine Zeit zum Aktualisieren für das Intervall replica.lag.time.max.ms (als langsam eingestuft)
Follower stellen
Abrufanforderungen im Intervall
replica.fetch.wait.max.ms , das standardmäßig 500 ms beträgt.
Um den Zweck von ISR klar zu erläutern, müssen Sie sich die Bestätigungen des Herstellers (Herstellers) und einige Fehlerszenarien ansehen. Produzenten können wählen, wann ein Broker eine Bestätigung sendet:
- acks = 0, Bestätigung wird nicht gesendet
- acks = 1, Bestätigung wird gesendet, nachdem der Leiter eine Nachricht in sein lokales Protokoll geschrieben hat
- acks = all, die Bestätigung wird gesendet, nachdem alle Replikate im ISR eine Nachricht in die lokalen Protokolle geschrieben haben
Wenn der ISR die Nachricht in der Kafka-Terminologie gespeichert hat, wird sie festgeschrieben. Acks = all ist die sicherste Option, aber auch eine zusätzliche Verzögerung. Schauen wir uns zwei Beispiele für Fehler an und wie die verschiedenen Acks-Optionen mit dem ISR-Konzept interagieren.
Acks = 1 und ISR
In diesem Beispiel sehen wir, dass Daten verloren gehen können, wenn der Anführer nicht auf das Speichern jeder Nachricht von allen Followern wartet. Das Wechseln zu einem nicht synchronisierten Follower kann durch Festlegen von
unclean.leader.election.enable aktiviert oder deaktiviert werden.
In diesem Beispiel ist der Hersteller auf acks = 1 eingestellt. Die Sektion ist auf alle drei Broker verteilt. Broker 3 ist im Rückstand, er hat sich vor acht Sekunden mit dem Leader synchronisiert und liegt jetzt mit 7456 Nachrichten im Rückstand. Broker 1 hat nur eine Sekunde Rückstand. Unser Produzent sendet eine Nachricht und erhält schnell eine Bestätigung zurück, ohne dass langsame oder tote Follower zu viel Aufwand haben, den der Anführer nicht erwartet.
 Abb. 7. ISR mit drei Replikaten
Abb. 7. ISR mit drei ReplikatenBroker 2 schlägt fehl und der Hersteller erhält einen Verbindungsfehler. Nach dem Führungswechsel zu Broker 1 verlieren wir 123 Nachrichten. Der Follower auf Broker 1 war Teil des ISR, synchronisierte sich jedoch nicht vollständig mit dem Leader, als er fiel.
 Abb. 8. Bei einem Fehler gehen Nachrichten verloren
Abb. 8. Bei einem Fehler gehen Nachrichten verlorenIn der
bootstrap.servers- Konfiguration listet der Hersteller mehrere Broker auf, und er kann einen anderen Broker fragen, der der neue Leiter des Abschnitts wurde. Anschließend stellt er eine Verbindung zum Broker 1 her und sendet weiterhin Nachrichten.
 Abb. 9. Das Senden von Nachrichten wird nach einer kurzen Pause fortgesetzt
Abb. 9. Das Senden von Nachrichten wird nach einer kurzen Pause fortgesetztBroker 3 hinkt noch weiter hinterher. Es werden Abrufanforderungen gestellt, es kann jedoch keine Synchronisierung durchgeführt werden. Dies kann auf eine langsame Netzwerkverbindung zwischen Brokern, ein Speicherproblem usw. zurückzuführen sein. Es wurde aus dem ISR entfernt. Jetzt besteht ISR aus einer Replik - dem Anführer! Der Hersteller sendet weiterhin Nachrichten und empfängt eine Bestätigung.
 Abb. 10. Der Follower von Broker 3 wird aus dem ISR entfernt
Abb. 10. Der Follower von Broker 3 wird aus dem ISR entferntBroker 1 fällt und die Rolle des Anführers geht mit dem Verlust von 15286 Nachrichten an Broker 3! Der Hersteller erhält eine Verbindungsfehlermeldung. Es war nur aufgrund der Einstellung
unclean.leader.election.enable = true möglich, zum Leader außerhalb des ISR zu
wechseln . Wenn es auf
false gesetzt ist , wäre der Übergang nicht aufgetreten, und alle Lese- und Schreibanforderungen würden abgelehnt. In diesem Fall warten wir auf die Rückgabe von Broker 1 mit seinen unberührten Daten im Replikat, der wieder die Führung übernimmt.
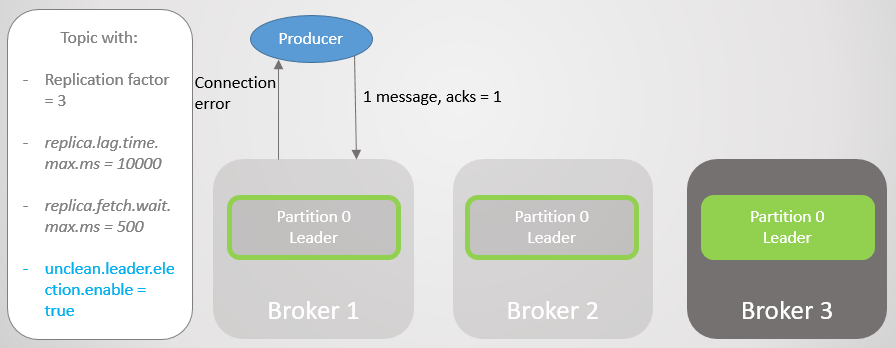 Abb. 11. Broker 1 Tropfen. Wenn ein Fehler auftritt, geht eine große Anzahl von Nachrichten verloren
Abb. 11. Broker 1 Tropfen. Wenn ein Fehler auftritt, geht eine große Anzahl von Nachrichten verlorenDer Hersteller stellt eine Verbindung zum letzten Makler her und sieht, dass er jetzt der Leiter der Sektion ist. Er beginnt, Nachrichten an Broker 3 zu senden.
 Abb. 12. Nach einer kurzen Pause werden die Nachrichten erneut an Abschnitt 0 gesendet
Abb. 12. Nach einer kurzen Pause werden die Nachrichten erneut an Abschnitt 0 gesendetWir haben gesehen, dass der Hersteller neben kurzen Unterbrechungen beim Aufbau neuer Verbindungen und der Suche nach einem neuen Marktführer ständig Nachrichten verschickte. Diese Konfiguration bietet Zugänglichkeit durch Konsistenz (Datensicherheit). Kafka verlor Tausende von Nachrichten, akzeptierte aber weiterhin neue Einträge.
Acks = all und ISR
Wiederholen wir dieses Szenario noch einmal, aber mit
acks = all . Delay Broker 3 durchschnittlich vier Sekunden. Der Hersteller sendet eine Nachricht mit
acks = all und erhält jetzt keine schnelle Antwort. Der Leiter wartet, bis alle Nachrichten im ISR die Nachricht gespeichert haben.
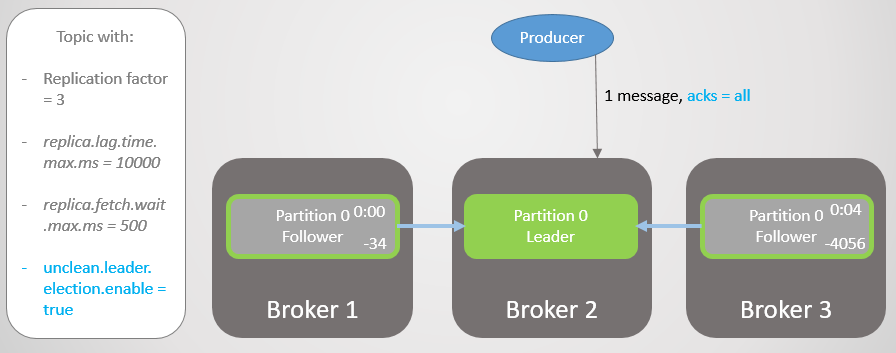 Abb. 13. ISR mit drei Replikaten. Einer ist langsam und verursacht eine Verzögerung bei der Aufnahme
Abb. 13. ISR mit drei Replikaten. Einer ist langsam und verursacht eine Verzögerung bei der AufnahmeNach vier Sekunden zusätzlicher Verzögerung sendet Broker 2 eine Bestätigung. Alle Replikate sind jetzt vollständig aktualisiert.
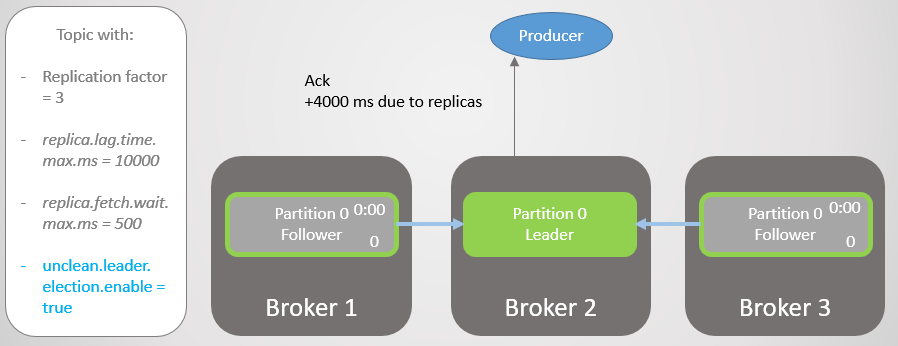 Abb. 14. Alle Replikate speichern Nachrichten und es wird eine Bestätigung gesendet
Abb. 14. Alle Replikate speichern Nachrichten und es wird eine Bestätigung gesendetBroker 3 ist jetzt noch weiter hinten und wird vom ISR entfernt. Die Verzögerung wird erheblich reduziert, da im ISR keine langsamen Replikate mehr vorhanden sind. Broker 2 wartet nur noch auf Broker 1 und hat eine durchschnittliche Verzögerung von 500 ms.
 Abb. 15. Das Replikat auf Broker 3 wird aus dem ISR entfernt
Abb. 15. Das Replikat auf Broker 3 wird aus dem ISR entferntDann fällt Broker 2, und die Führung geht auf Broker 1 über, ohne dass Nachrichten verloren gehen.
 Abb. 16. Broker 2 fällt
Abb. 16. Broker 2 fälltDer Hersteller findet einen neuen Anführer und beginnt, ihm Nachrichten zu senden. Die Verzögerung wird immer noch reduziert, da das ISR jetzt aus einer Replik besteht! Daher
fügt die Option
acks = all keine Redundanz hinzu.
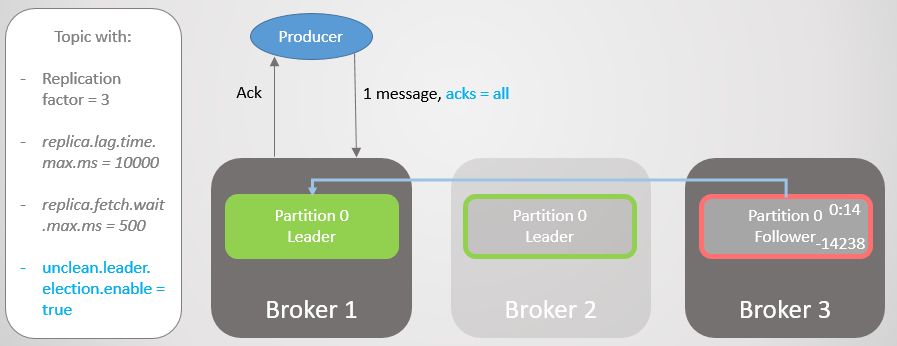 Abb. 17. Das Replikat auf Broker 1 übernimmt die Führung, ohne Nachrichten zu verlieren
Abb. 17. Das Replikat auf Broker 1 übernimmt die Führung, ohne Nachrichten zu verlierenDann fällt Broker 1 und die Führung geht mit dem Verlust von 14.238 Nachrichten auf Broker 3 über!
 Abb. 18. Broker 1 stirbt, und ein Führungswechsel mit unsauberer Einrichtung führt zu erheblichen Datenverlusten
Abb. 18. Broker 1 stirbt, und ein Führungswechsel mit unsauberer Einrichtung führt zu erheblichen DatenverlustenWir konnten die Option
unclean.leader.election.enable nicht auf
true setzen . Standardmäßig ist es
falsch . Wenn Sie
acks = all mit
unclean.leader.election.enable = true festlegen, wird die Barrierefreiheit durch zusätzliche Datensicherheit
erhöht . Wie Sie sehen, können wir dennoch Nachrichten verlieren.
Was aber, wenn wir die Datensicherheit erhöhen wollen? Sie können
unclean.leader.election.enable = false setzen , dies schützt uns jedoch nicht unbedingt vor Datenverlust. Fiel der Anführer schwer und nahm die Daten mit, gehen die Nachrichten immer noch verloren, und die Erreichbarkeit geht verloren, bis der Administrator die Situation wiederherstellt.
Es ist besser, die Redundanz aller Nachrichten zu gewährleisten und ansonsten die Aufzeichnung zu verweigern. Dann ist zumindest aus Sicht des Brokers ein Datenverlust nur bei zwei oder mehr gleichzeitigen Ausfällen möglich.
Acks = all, min.insync.replicas und ISR
Mit der Themenkonfiguration
min.insync.replicas erhöhen wir die Datensicherheit. Lassen Sie uns den letzten Teil des letzten Szenarios noch einmal
durchgehen , diesmal jedoch mit
min.insync.replicas = 2 .
Daher hat Broker 2 einen Replikat-Leader, und der Follower von Broker 3 wird aus dem ISR entfernt.
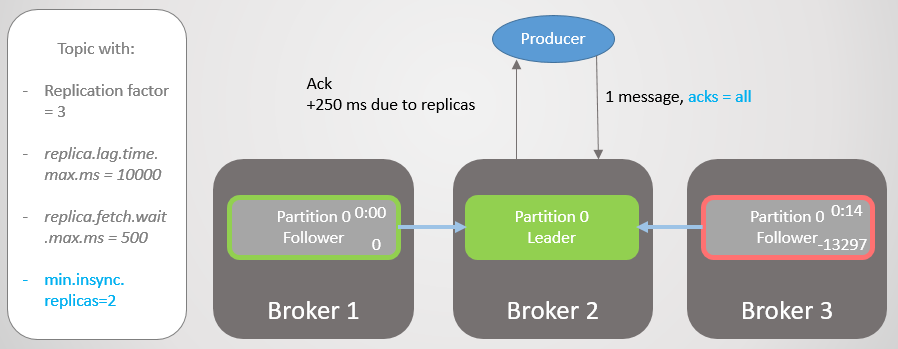 Abb. 19. ISR von zwei Repliken
Abb. 19. ISR von zwei ReplikenBroker 2 fällt, und die Führung geht auf Broker 1 über, ohne dass Nachrichten verloren gehen. Aber jetzt besteht ISR nur noch aus einer Replik. Dies entspricht nicht der Mindestanzahl für den Empfang von Datensätzen. Daher antwortet der Broker auf den Versuch, eine Aufzeichnung mit dem Fehler
NotEnoughReplicas durchzuführen .
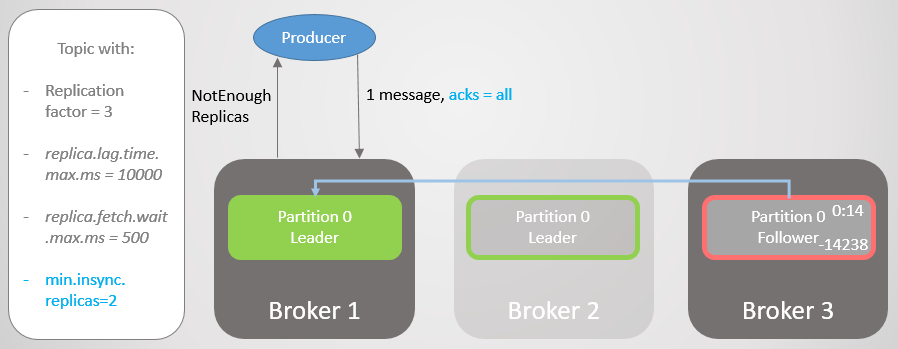 Abb. 20. Die Anzahl der ISRs ist um eins niedriger als in min.insync.replicas angegeben
Abb. 20. Die Anzahl der ISRs ist um eins niedriger als in min.insync.replicas angegebenDiese Konfiguration beeinträchtigt die Verfügbarkeit aus Gründen der Konsistenz. Bevor wir eine Nachricht bestätigen, garantieren wir, dass sie auf mindestens zwei Replikaten aufgezeichnet ist. Dies gibt dem Hersteller viel mehr Vertrauen. Hier ist ein Nachrichtenverlust nur möglich, wenn zwei Replikate gleichzeitig in einem kurzen Intervall fehlschlagen, bis die Nachricht auf einen zusätzlichen Follower repliziert wird, was unwahrscheinlich ist. Aber wenn Sie ein Superparanoiker sind, können Sie das Replikationsverhältnis auf 5 und
min.insync.replicas auf 3
einstellen . Dann müssen drei Broker gleichzeitig fallen, um den Datensatz zu verlieren! Natürlich zahlen Sie für diese Zuverlässigkeit eine zusätzliche Verzögerung.
Wann ist die Zugänglichkeit für die Datensicherheit erforderlich
Wie
bei RabbitMQ ist manchmal eine Barrierefreiheit für die Datensicherheit erforderlich. Sie müssen darüber nachdenken:
- Kann ein Publisher einfach einen Fehler zurückgeben und ein höherer Dienst oder Benutzer es später erneut versuchen?
- Kann ein Herausgeber eine Nachricht lokal oder in einer Datenbank speichern, um es später erneut zu versuchen?
Wenn die Antwort Nein lautet, verbessert die Optimierung der Barrierefreiheit die Datensicherheit. Sie verlieren weniger Daten, wenn Sie die Verfügbarkeit wählen, anstatt die Aufzeichnung zu verwerfen. Es kommt also darauf an, ein Gleichgewicht zu finden, und die Entscheidung hängt von der jeweiligen Situation ab.
Die Bedeutung von ISR
Mit der ISR-Suite können Sie das optimale Verhältnis zwischen Datensicherheit und Latenz auswählen. Zum Beispiel, um sicherzustellen, dass die meisten Replikate im Fehlerfall verfügbar sind, und um die Auswirkungen von toten oder langsamen Replikaten in Bezug auf die Verzögerung zu minimieren.
Wir selbst wählen den Wert von
replica.lag.time.max.ms entsprechend unseren Bedürfnissen. Im Wesentlichen bedeutet dieser Parameter, welche Verzögerung wir mit
acks = all akzeptieren
können . Der Standardwert ist zehn Sekunden. Wenn Ihnen das zu lang ist, können Sie es reduzieren. Dann nimmt die Häufigkeit von Änderungen in der ISR zu, da Anhänger häufiger gelöscht und hinzugefügt werden.
RabbitMQ ist nur eine Sammlung von Spiegeln, die repliziert werden müssen. Langsame Spiegel führen zu einer zusätzlichen Verzögerung, und die Reaktion von toten Spiegeln kann vor dem Ablauf von Paketen erwartet werden, die die Verfügbarkeit jedes Knotens prüfen (Nettotick). ISRs sind ein interessanter Weg, um diese Probleme mit erhöhter Latenz zu vermeiden. Wir riskieren jedoch den Verlust von Redundanz, da ISR nur zu einem Leader reduziert werden kann. Verwenden Sie die Einstellung
min.insync.replicas , um dieses Risiko zu vermeiden.
Garantie für Kundenkonnektivität
In den
bootstrap.servers- Einstellungen des Herstellers und des Verbrauchers können Sie mehrere Broker für die Verbindung von Clients angeben. Die Idee ist, dass es beim Trennen eines Knotens mehrere Ersatzknoten gibt, mit denen der Client eine Verbindung herstellen kann. Dies sind nicht unbedingt Abteilungsleiter, sondern lediglich ein Sprungbrett für das Bootstrapping. Der Client kann sie fragen, auf welchem Knoten sich der Leiter des Lese- / Schreibabschnitts befindet.
In RabbitMQ können Clients eine Verbindung zu einem beliebigen Host herstellen, und das interne Routing sendet bei Bedarf eine Anforderung. Dies bedeutet, dass Sie einen Load Balancer vor RabbitMQ installieren können. Für Kafka müssen Clients eine Verbindung zum Host herstellen, auf dem sich der Leiter der entsprechenden Partition befindet. In dieser Situation liefert der Load Balancer nicht. Die Liste
bootstrap.servers ist wichtig, damit Clients auf die richtigen Knoten zugreifen und diese nach einem Absturz finden können.
Kafka-Konsens-Architektur
Bisher haben wir nicht darüber nachgedacht, wie der Cluster vom Sturz des Brokers erfährt und wie ein neuer Anführer ausgewählt wird. Um zu verstehen, wie Kafka mit Netzwerkpartitionen arbeitet, müssen Sie zunächst die Konsensarchitektur verstehen.
Jeder Kafka-Cluster wird zusammen mit dem Zookeeper-Cluster bereitgestellt. Hierbei handelt es sich um einen verteilten Konsensdienst, mit dem das System in einem bestimmten Status einen Konsens erzielen kann, bei dem die Konsistenz Vorrang vor der Verfügbarkeit hat. Die Genehmigung von Lese- und Schreibvorgängen erfordert die Zustimmung der meisten Zookeeper-Knoten.
Zookeeper speichert den Clusterstatus:
- Liste der Themen, Abschnitte, Konfiguration, aktuelle Hauptreplikate, bevorzugte Replikate.
- Cluster-Mitglieder. Jeder Broker pingt in einen Zookeeper-Cluster. Wenn er für einen bestimmten Zeitraum kein Ping erhält, schreibt Zookeeper, dass der Broker nicht erreichbar ist.
- Die Auswahl der primären und sekundären Knoten für den Controller.
Der Controller-Knoten ist einer der Kafka-Broker, der für die Wahl der Replikationsleiter verantwortlich ist. Zookeeper sendet an den Controller Benachrichtigungen über Cluster-Mitgliedschaft und Themenänderungen, und der Controller muss gemäß diesen Änderungen handeln.
Nehmen Sie zum Beispiel ein neues Thema mit zehn Abschnitten und einem Replikationskoeffizienten von 3. Der Controller muss den Leiter jedes Abschnitts auswählen, um die Leiter optimal auf die Broker zu verteilen.
Für jeden Abschnitt führt der Controller Folgendes aus:
- aktualisiert Informationen in Zookeeper über ISR und den Führer;
- sendet einen LeaderAndISRCommand-Befehl an jeden Broker, der eine Replik dieses Abschnitts veröffentlicht, und informiert die Broker über den ISR und den Leader.
Wenn ein Broker mit einem Anführer fällt, sendet Zookeeper eine Benachrichtigung an den Controller und wählt einen neuen Anführer aus. Wieder aktualisiert der Controller zuerst Zookeeper und sendet dann einen Befehl an jeden Broker, um ihn über einen Führungswechsel zu informieren.
Jeder Leiter ist für die Rekrutierung von ISRs verantwortlich. Die
Einstellung replica.lag.time.max.ms bestimmt, wer dorthin fährt. Wenn sich die ISR ändert, gibt der Anführer die neuen Informationen an Zookeeper weiter.
Zookeeper wird immer über Änderungen informiert, so dass das Management im Falle eines Ausfalls reibungslos zum neuen Leiter wechselt.
 Abb. 21. Konsens Kafka
Abb. 21. Konsens KafkaReplikationsprotokoll
Durch das Verstehen der Replikationsdetails können Sie potenzielle Datenverlustszenarien besser verstehen.
Musteranfragen, Log End Offset (LEO) und Highwater Mark (HW)
Wir haben in Betracht gezogen, dass Follower regelmäßig Abholanfragen an den Leader senden. Das Standardintervall beträgt 500 ms. Dies unterscheidet sich von RabbitMQ darin, dass in RabbitMQ die Replikation nicht vom Warteschlangenspiegel, sondern vom Assistenten initiiert wird. Der Master drückt Änderungen an den Spiegeln.
Der Leader und alle Follower behalten das Etikett für Log End Offset (LEO) und Highwater (HW). Die LEO-Marke speichert den Versatz der letzten Nachricht im lokalen Replikat, und HW speichert den Versatz des letzten Commits. Denken Sie daran, dass die Nachricht für den Commit-Status in allen ISR-Replikaten gespeichert werden muss. Dies bedeutet, dass LEO in der Regel etwas vor HW liegt.
Wenn ein Leiter eine Nachricht erhält, speichert er sie lokal. Der Follower stellt eine Abrufanforderung und übergibt seinen LEO. Dann sendet der Leader ein Nachrichtenpaket, das mit diesem LEO beginnt, und sendet auch die aktuelle HW. Wenn der Leiter die Information erhält, dass alle Replikate die Nachricht mit einem bestimmten Versatz gespeichert haben, verschiebt er die HW-Markierung. Nur der Anführer kann die HW bewegen, sodass alle Anhänger den aktuellen Wert in den Antworten auf ihre Anfrage kennen. Dies bedeutet, dass Follower sowohl bei der Berichterstattung als auch beim Wissen über HW hinter dem Marktführer zurückbleiben können. Verbraucher erhalten Nachrichten nur bis zur aktuellen HW.
Beachten Sie, dass "dauerhaft" bedeutet, dass in den Speicher und nicht auf die Festplatte geschrieben wird. Aus Performancegründen synchronisiert Kafka in einem festgelegten Intervall auf die Festplatte. RabbitMQ verfügt ebenfalls über ein solches Intervall, sendet jedoch erst dann eine Bestätigung an den Herausgeber, wenn der Master und alle Mirrors die Nachricht auf die Festplatte geschrieben haben. Kafka-Entwickler haben aus Performance-Gründen beschlossen, eine Bestätigung zu senden, sobald die Nachricht in den Speicher geschrieben wurde. Kafka stützt sich auf die Tatsache, dass durch Redundanz das Risiko einer kurzfristigen Speicherung bestätigter Nachrichten nur im Speicher ausgeglichen wird.
Leader-Fehler
Wenn ein Anführer fällt, benachrichtigt Zookeeper den Controller und wählt eine neue Nachbildung des Anführers aus. Der neue Leader setzt mit seinem LEO eine neue HW-Marke. Dann erhalten die Follower Informationen über den neuen Anführer. Abhängig von der Version von Kafka wählt der Follower eines von zwei Szenarien:
- Kürzt das lokale Protokoll an die berühmte HW und sendet nach dieser Markierung eine Nachricht an den neuen Anführer.
- Es sendet eine Anfrage an den Leiter, um HW zum Zeitpunkt seiner Wahl als Leiter herauszufinden, und schneidet dann das Protokoll auf diesen Offset ab. Ab diesem Offset werden dann periodische Anforderungen für die Stichprobenerfassung gestellt.
Der Follower muss das Protokoll möglicherweise aus den folgenden Gründen kürzen:- Wenn ein Anführer ausfällt, gewinnt der erste bei Zookeeper registrierte ISR-Anhänger die Wahl und wird zum Anführer. Obwohl alle Anhänger in der ISR als "synchronisiert" gelten, haben sie möglicherweise nicht alle Nachrichten des früheren Anführers erhalten. Möglicherweise verfügt der ausgewählte Follower nicht über die aktuellste Kopie. Kafka garantiert, dass es keine Diskrepanzen zwischen den Repliken gibt. Um Unstimmigkeiten zu vermeiden, muss jeder Anhänger sein Protokoll zum Zeitpunkt seiner Wahl auf den HW-Wert des neuen Leiters kürzen. Dies ist ein weiterer Grund, warum das Setzen von acks = all für die Konsistenz so wichtig ist.
- . , . , , , , , .
c
, : HW ( ). , RabbitMQ . . , « ». . .
Kafka — , , RabbitMQ, . . Kafka — , . . Kafka HW ( ) , . , , , LEO.
ISR . , , , ISR. .
Kafka , RabbitMQ, , . Kafka , .
:
- 1. , Zookeeper.
- 2. , Zookeeper.
- 3. , Zookeeper.
- 4. , Zookeeper.
- 5. Kafka, Zookeeper.
- 6. Kafka, Zookeeper.
- 7. Kafka Kafka.
- 8. Kafka Zookeeper.
.
1. , Zookeeper
 Abb. 22. 1. ISR
Abb. 22. 1. ISR3 1 2, Zookeeper. 3 .
replica.lag.time.max.ms ISR . , ISR, . Zookeeper , .
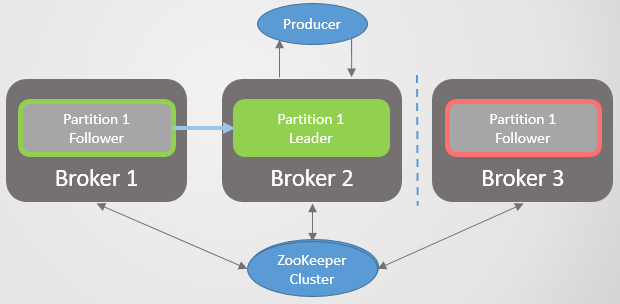 Abb. 23. 1. ISR, replica.lag.time.max.ms
Abb. 23. 1. ISR, replica.lag.time.max.ms(split-brain) , RabbitMQ. .
2. , Zookeeper
 Abb. 24. 2.
Abb. 24. 2., Zookeeper. , ISR , , . , . , . Zookeeper , .
 Abb. 25. 2. ISR
Abb. 25. 2. ISR3. , Zookeeper
Zookeeper, . ISR. Zookeeper , , .
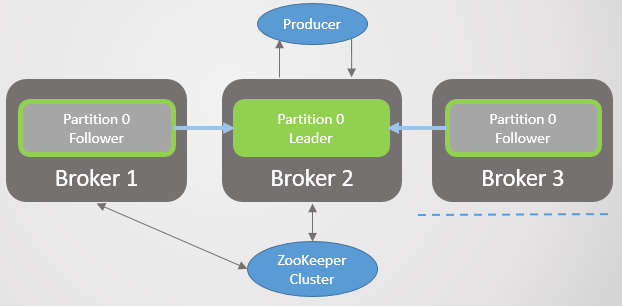 Abb. 26. 3.
Abb. 26. 3.4. , Zookeeper
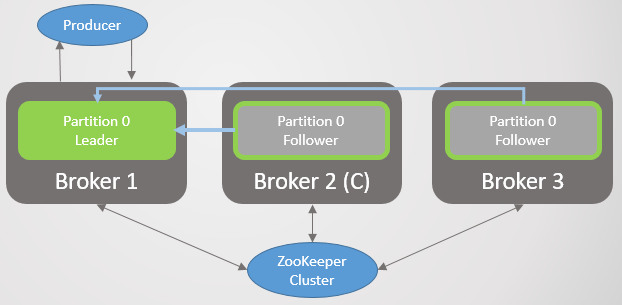 Abb. 27. 4.
Abb. 27. 4.Zookeeper, .
 Abb. 28. 4. Zookeeper
Abb. 28. 4. ZookeeperZookeeper . . ,
acks=1 . , ISR . Zookeeper, , .
acks=all , ISR , . ISR, - .
. , , , HW, , . . , . , , .
 Abb. 29. 4. 1
Abb. 29. 4. 15. Kafka, Zookeeper
Kafka, Zookeeper. ISR, , .
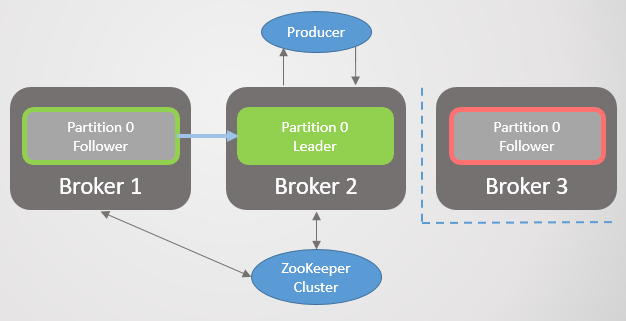 Abb. 30. 5. ISR
Abb. 30. 5. ISR6. Kafka, Zookeeper
 Abb. 31. 6.
Abb. 31. 6., Zookeeper.
acks=1 .
 Abb. 32. 6. Kafka Zookeeperreplica.lag.time.max.ms
Abb. 32. 6. Kafka Zookeeperreplica.lag.time.max.ms , ISR , , Zookeeper, .
, Zookeeper , .
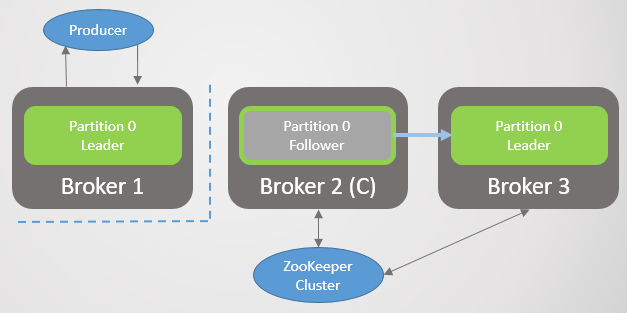 Abb. 33. 6.
Abb. 33. 6., . 60 . .
 Abb. 34. 6.
Abb. 34. 6., . , Zookeeper , . HW .
 Abb. 35. 6.
Abb. 35. 6.,
acks=1 min.insync.replicas 1. , , , , — , . ,
acks=1 .
, , ISR . - . , ,
acks=all , ISR . . —
min.insync.replicas = 2 .
7. Kafka Kafka
, Kafka . , 6. .
8. Kafka Zookeeper
Zookeeper Kafka. , Zookeeper, . , , , Kafka.
, , , . , , , .
- Zookeeper,
acks=1 . Zookeeper .
acks=all .
min.insync.replicas , , 6.
, Kafka:
- , acks=1
- (unclean) , ISR, acks=all
- Zookeeper, acks=1
- , ISR . , acks=all . , min.insync.replicas=1 .
- . , . .
, , . —
acks=all min.insync.replicas 1.
RabbitMQ Kafka
. RabbitMQ . , . RabbitMQ. , . . , ( ) .
Kafka . . . , . , , . , - , . , .
RabbitMQ Kafka . , RabbitMQ . :
- fsync alle paar hundert Millisekunden
- Mirrors können erst nach der Lebensdauer von Paketen erkannt werden, die die Verfügbarkeit jedes Knotens überprüfen (Net Tick). Wenn der Spiegel langsamer wird oder herunterfällt, wird eine Verzögerung hinzugefügt.
Kafka verlässt sich darauf, dass Sie Nachrichten bestätigen können, sobald sie auf mehreren Knoten gespeichert sind. Aus diesem Grund besteht die Gefahr,
dass bei einem gleichzeitigen Ausfall Nachrichten jeglicher Art (auch
acks = all ,
min.insync.replies = 2 ) verloren gehen.
Insgesamt zeigt Kafka eine bessere Leistung und wurde ursprünglich für Cluster entwickelt. Die Anzahl der Follower kann aus Gründen der Zuverlässigkeit auf 11 erhöht werden. Ein Replikationsfaktor von 5 und eine minimale Anzahl von Replikaten in einem synchronisierten Zustand von
min.insync.replicas = 3 machen einen Nachrichtenverlust zu einem sehr seltenen Ereignis. Wenn Ihre Infrastruktur eine solche Replikationsrate und Redundanzstufe bereitstellen kann, können Sie diese Option auswählen.
RabbitMQ-Clustering eignet sich für kleine Warteschlangen. Aber auch kleine Warteschlangen können bei hohem Datenverkehr schnell wachsen. Sobald die Warteschlangen groß sind, müssen Sie eine schwierige Wahl zwischen Verfügbarkeit und Zuverlässigkeit treffen. RabbitMQ-Cluster eignen sich am besten für nicht typische Situationen, in denen die Vorteile der Flexibilität von RabbitMQ die Nachteile einer Clusterbildung überwiegen.
Eines der Gegenmittel gegen die große Warteschlangenanfälligkeit von RabbitMQ besteht darin, sie in viele kleinere zu zerlegen. Wenn Sie keine vollständige Bestellung der gesamten Warteschlange, sondern nur relevante Nachrichten (z. B. Nachrichten eines bestimmten Kunden) oder gar nichts benötigen, ist diese Option akzeptabel: Sehen Sie sich mein
Rebalanser- Projekt zum Aufteilen der Warteschlange an (das Projekt befindet sich noch in einem frühen Stadium).
Vergessen Sie nicht, eine Reihe von Fehlern in den Cluster- und Replikationsmechanismen von RabbitMQ und Kafka zu beheben. Im Laufe der Zeit sind die Systeme ausgereifter und stabiler geworden, aber keine einzige Nachricht wird jemals zu 100% vor Verlust geschützt sein! Außerdem ereignen sich in Rechenzentren schwere Unfälle!
Wenn ich etwas verpasst habe, einen Fehler gemacht habe oder Sie mit einem der Punkte nicht einverstanden sind, können Sie gerne einen Kommentar schreiben oder mich kontaktieren.
Die Leute fragen mich oft: "Was soll ich wählen, Kafka oder RabbitMQ?", "Welche Plattform ist besser?". Die Wahrheit ist, dass es wirklich von Ihrer Situation, Ihrer aktuellen Erfahrung usw. abhängt. Ich traue mich nicht, meine Meinung zu äußern, da es zu stark vereinfacht wird, eine Plattform für alle Anwendungsfälle und mögliche Einschränkungen zu empfehlen. Ich habe diese Artikelserie geschrieben, damit Sie sich Ihre eigene Meinung bilden können.
Ich möchte sagen, dass beide Systeme auf diesem Gebiet führend sind. Vielleicht bin ich ein bisschen voreingenommen, weil ich aufgrund der Erfahrung meiner Projekte eher geneigt bin, Dinge wie garantierte Nachrichtenbestellung und Zuverlässigkeit zu schätzen.
Ich sehe andere Technologien, denen diese Zuverlässigkeit und garantierte Bestellung fehlt, und schaue dann auf RabbitMQ und Kafka - und ich verstehe den unglaublichen Wert dieser beiden Systeme.