Vor nicht allzu langer Zeit haben wir uns
angesehen, wie A / B-Experimente in Search angeordnet sind. Der Leiter des Entwicklungsteams für die iOS-Version von Yandex.Browser Andrei Sikerin sav42
sprach beim letzten Treffen von CocoaHeads Russia nur in seinem Projekt über die A / B-Testinfrastruktur.
- Hallo, mein Name ist Andrey Sikerin, ich entwickle Yandex.Browser für iOS. Ich möchte Ihnen sagen, was die Browserexperimentplattform für iOS ist, wie wir sie verwendet haben, welche erweiterten Funktionen sie unterstützt, wie Funktionen diagnostiziert und debuggt werden, die mit dem Experimentiersystem eingeführt wurden und woher die Entropie stammt Münze ist gespeichert.
Also fangen wir an. Wir im Browser für iOS übertragen die Funktion niemals auf einmal an Benutzer. Zuerst führen wir A / B-Tests durch, analysieren Produkt- und technische Metriken, um zu verstehen, wie sich das gerollte Feature auf den Benutzer auswirkt, ob es ihm gefällt oder nicht, ob es einige technische Metriken verschleudert. Dafür setzen wir Analytics ein. Unsere Analyse sieht ungefähr so aus:
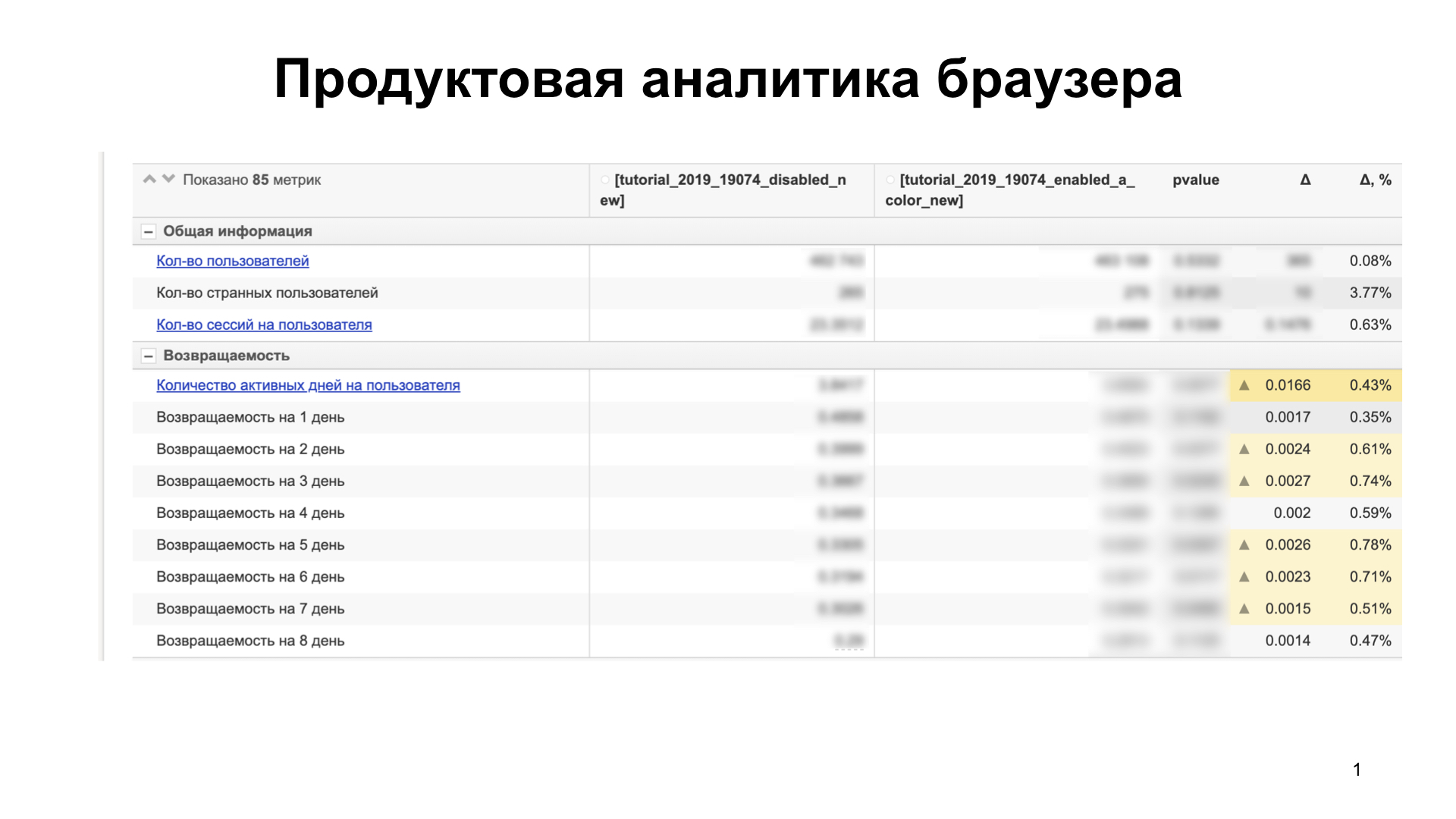
Es gibt ungefähr 85 Metriken. Wir vergleichen mehrere Benutzergruppen. Angenommen, dies erhöht unsere Messdaten - zum Beispiel die Fähigkeit des Produkts, Benutzer zu behalten (Retention) - und verschwendet keine anderen, die nicht auf der Folie sind. Dies bedeutet, dass Benutzer die Funktion mögen und auf eine große Gruppe von Benutzern übertragen werden können.
Wenn wir dennoch etwas verschwenden, dann verstehen wir warum. Wir bauen Hypothesen, bestätigen sie. Wenn wir technische Kennzahlen zeichnen, ist dies ein Blocker. Wir beheben sie und führen das Experiment erneut aus. Und so lange, bis wir alles gemalt haben. Aus diesem Grund führen wir ein Feature ein, bei dem es sich nicht um eine Regressionsquelle handelt.
Sprechen wir über das ursprüngliche Experimentiersystem, das wir verwendet haben. Sie war schon ziemlich entwickelt. Dann werde ich Ihnen sagen, was nicht zu uns gepasst hat.

Erstens basiert es auf dem Chromium-Experimentiersystem und wurde unter iOS nicht vollständig unterstützt. Zweitens war es ursprünglich möglich, Funktionen für verschiedene Benutzergruppen bereitzustellen, und es gab ein Filtersystem, auf dem Anforderungen an Geräte festgelegt werden konnten. Dies ist die Version der Anwendung, in der die Funktion verfügbar ist, das Gebietsschema des Geräts. Nehmen wir an, wir möchten ein Experiment nur für das russische Gebietsschema. Entweder die iOS-Version, für die diese Funktion verfügbar sein wird, oder das Datum, bis zu dem dieser Test gültig sein wird - zum Beispiel, wenn wir einen Test nur bis zu einem bestimmten Datum durchführen möchten. Im Allgemeinen gab es viele Tags und es war sehr praktisch.
Das Experimentiersystem selbst besteht aus einer Datei, die Beschreibungen der Konfigurationen der Experimente enthält. Das heißt, für ein Experiment können mehrere Konfigurationen gleichzeitig vorliegen. Diese Datei ist eine Textdatei, die in protobuf kompiliert und auf dem Server angelegt wird.
Jede Konfiguration besteht aus Gruppen. Es gibt ein Experiment, es hat mehrere Konfigurationen und in jeder von ihnen gibt es mehrere Gruppen. Die Funktion im Code wird an den Namen der aktiven Gruppe der aktiven Konfiguration angehängt. Es mag kompliziert genug erscheinen, aber jetzt werde ich im Detail erklären, was es ist.

Wie funktioniert es technisch? Eine Datei mit Beschreibungen aller Konfigurationen wird auf den Server hochgeladen. Beim Start wird es vom Browser vom Server heruntergeladen und auf der Festplatte gespeichert. Beim nächsten Start dekodieren wir diese Datei als erstes in der Anwendungsinitialisierungskette. Und für jedes einzelne Experiment finden wir eine Konfiguration, die aktiv sein wird.
Die Konfiguration, die für die angegebenen und darin beschriebenen Bedingungen geeignet ist, kann aktiv werden. Wenn mehrere aktive Konfigurationen vorhanden sind, die den angegebenen Bedingungen entsprechen, wird die Konfiguration aktiviert, die in der Datei höher ist.
Weiter in der aktiven Konfiguration wird eine Münze geworfen. Die Münze wird lokal geworfen, und anhand dieser Münze wird auf eine bestimmte Art und Weise, auf die ich später eingehen werde, die aktive Gruppe des Experiments ausgewählt. Und genau dem Namen der aktiven Gruppe des Experiments sind wir im Code beigefügt und prüfen, ob unsere Funktion verfügbar ist oder nicht.
Ein wesentliches Merkmal dieses Systems ist, dass es selbst nichts speichert. Das heißt, sie hat keinen Speicherplatz auf der Festplatte. Bei jedem Start - wir nehmen die Datei, berechnen sie, finden die aktive Konfiguration. In der Konfiguration finden wir entsprechend der Münze die aktive Gruppe, und das Experimentiersystem für dieses Experiment sagt: Diese Gruppe ist ausgewählt. Das heißt, alles wird berechnet, nichts wird gespeichert.

Lassen Sie mich Ihnen eine Datei mit Versuchsbeschreibungen zeigen. Der Browser hat eine solche Funktion - Übersetzer. Sie rollte in einem Experiment aus. Die Datei beginnt mit dem Lernblock. Die Konfiguration eines Experiments beginnt mit diesem Block. Das Experiment wird als Übersetzer bezeichnet. Es kann mehrere solcher Studienblöcke mit diesem Namen geben. Und innerhalb des Lernblocks gibt es viele Experimentierblöcke, denen unterschiedliche Namen zugewiesen wurden. In diesem Fall ist die Experimentgruppe aktiviert. Und es gibt einen Filterblock, der tatsächlich beschreibt, unter welchen Bedingungen diese Konfiguration aktiv werden kann, dh nach welchen Kriterien.
Hier gibt es zwei Tags - channel und ya_min_version. Kanal bedeutet Baugruppenansicht. BETA wird hier angegeben, was bedeutet, dass diese Konfiguration in der Datei nur für die Assemblys aktiviert werden kann, die wir an TestFlight senden. Für den App Store-Build kann diese Konfiguration nach dem Channel-Kriterium nicht aktiviert werden.
ya_min_version bedeutet, dass mit der Mindestversion der Anwendung 19.3.4.43 diese Konfiguration aktiv werden kann. Tatsächlich hat die Funktion in dieser Version der Anwendung bereits ein Formular erworben, das Sie aktivieren können.
Dies ist die einfachste Beschreibung der Konfigurationsgruppe für Übersetzerexperimente. In einer Datei können sich viele solcher Lernblöcke befinden. Mithilfe von Tags im Filterblock setzen wir sie für verschiedene Kanäle, für interne Assemblys, für BETA-Assemblys und für verschiedene Kriterien.
Hier ist eine Versuchsgruppe mit dem Namen "enabled" (aktiviert) und mit einem Wahrscheinlichkeitsgewicht (Wahrscheinlichkeitsgewicht) versehen, dem Gewicht der Versuchsgruppe. Dies ist eine nicht negative Ganzzahl, mit der die aktive Gruppe zum Zeitpunkt des Münzauswurfs bestimmt wird.
Stellen wir uns vor, diese Konfiguration auf der Folie ist aktiv geworden. Das heißt, wir haben die Anwendung wirklich mit der öffentlichen Beta installiert und wir haben wirklich Version 19.3.4.43 und höher. Wie wird die Münze geworfen? Eine Münze ist eine Zufallszahl, die lokal von null bis eins generiert wird.
Damit wir beim nächsten Start in dieselbe Gruppe fallen, wird sie auf der Festplatte gespeichert. Wir werden dies jedoch berücksichtigen. Als Nächstes erkläre ich Ihnen, wie Sie sicherstellen können, dass es nicht gespeichert wird. Die Münze wird weggeworfen. Angenommen, 0.5 wird weggeworfen. Diese Münze ist in einem Segment von Null bis zur Summe der Versuchsgruppen skaliert. In diesem Fall haben wir eine aktivierte Gruppe, deren Gewicht 1000 ist, dh die Summe aller Gruppen wird 1000 sein. "0,5" skaliert auf 500. Dementsprechend teilen alle Gruppen von Experimenten das Intervall von Null auf die Menge der Experimente und Lücken. Und die Gruppe wird aktiv, in deren Intervall der skalierte Wert der Münze anzeigt.
Wir können den Namen der aktiven Gruppe von Experimenten im Code abfragen und so die Zugänglichkeit bestimmen - müssen wir die Funktion aktivieren oder nicht.
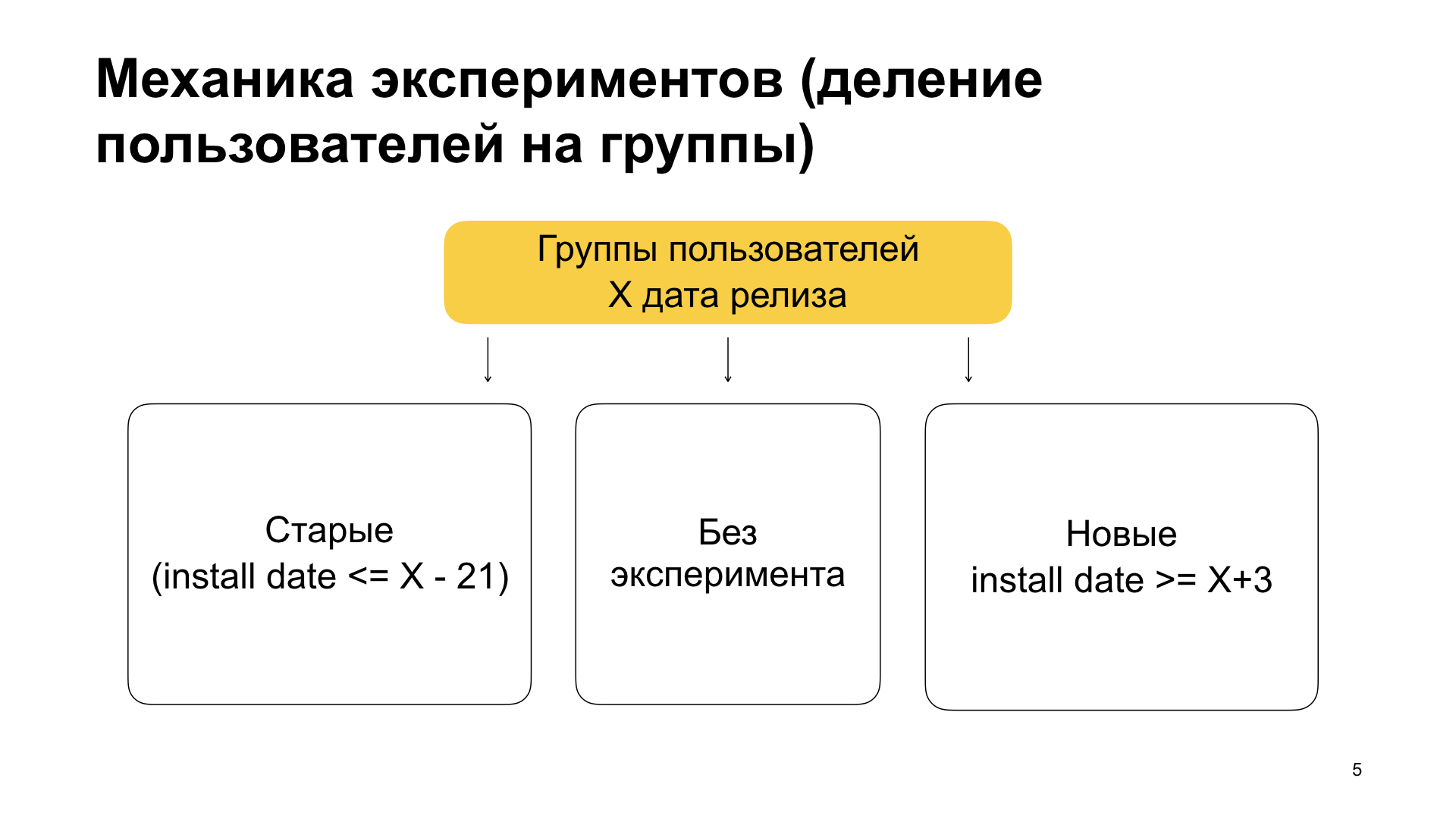
Weiter werden wir uns komplexere experimentelle Konfigurationen ansehen, die wir in der Produktion verwenden. Zunächst ist klar, dass es dumm ist, ein Feature zu 100% zu implementieren. Wir verwenden es nur für die Betaversion oder für interne Assemblys. Für die Produktion verwenden wir folgende Mechanik.
Wir teilen Benutzer in drei Gruppen ein - alte Benutzer, Benutzer ohne Experiment und neue Benutzer. In der Bedeutung bedeutet dies Folgendes. Alte Benutzer sind diejenigen, die unsere Anwendung bereits verwendet und die Anwendung mit Funktionen über die alte Version installiert haben. Das heißt, sie haben es bereits verwendet, sie hatten keine Funktionen, sie haben sich an alles gewöhnt und aktualisieren plötzlich die Anwendung, in der es eine Art Experiment gibt, mit neuen Funktionen. Dann - Benutzer ohne Experiment und neue Benutzer. Neu sind diejenigen, die die Anwendung bereinigen. Das heißt, sie haben Yandex.Browser nie verwendet, sie entschieden sich plötzlich dafür und installierten die Anwendung.
Wie erreichen wir diese Partition? Im Filterblock legen wir die Bedingungen für die Tags min_install_date und max_install_date fest. Angenommen, X ist der 14. März 2019 - dies ist das Veröffentlichungsdatum für den Feature-Build. Dann beträgt max_install_date für alte Benutzer X minus 21 Tage, bevor die Assembly mit Funktionen freigegeben wird. Wenn die Anwendung ein solches Installationsdatum hat, ist es sehr wahrscheinlich, dass der erste Start vor der Veröffentlichung erfolgte. Und vor der Veröffentlichung gab es eine Version ohne Features. Und wenn er nun bedingt eine Version mit Features hat, heißt das, dass er die Bewerbung mit Hilfe eines Updates erhalten hat.
Und für neue Benutzer setzen wir min_install_date. Wir belichten es als X plus ein paar Tage. Dies bedeutet: Wenn er ein solches Installationsdatum hat, das heißt, er hat den ersten Start nach dem Veröffentlichungsdatum der Version mit Features durchgeführt, dann hatte er eine Neuinstallation. Er hat jetzt eine Version mit Funktionen, aber das Installationsdatum war später als diese Version mit Funktionen.
Auf diese Weise teilen wir Benutzer in alte auf, ohne zu experimentieren und ohne neue. Wir tun dies, weil wir sehen: Das Verhalten alter Benutzer unterscheidet sich vom Verhalten neuer Benutzer. Dementsprechend können wir beispielsweise nicht in einer Gruppe mit alten Benutzern übermalen, sondern in einer Gruppe mit neuen Benutzern übermalen oder umgekehrt. Wenn wir ein Experiment mit der gesamten Masse durchführen, sehen wir dies möglicherweise nicht.

Schauen wir uns dieses Experiment an. Wir sehen die folgende Experimentkonfiguration - Übersetzer für den App Store, neue Benutzer. Blockstudie, Namensübersetzer, Gruppe enabled_new. Das Präfix new bedeutet, dass wir die Konfiguration für viele neue Benutzer beschreiben. Gewicht 500 (wenn die Summe aller Gewichte 1000 ist, beträgt die Leistung dieses Satzes 50%). Control_new, Gewicht 500, das ist die zweite Gruppe. Und das Interessanteste sind die Filter für den STABLE-Kanal, also für Baugruppen, die für die Produktion zusammengebaut werden. Version, in der das Feature erschien: 19.4.1. Und hier ist das min_install_date-Tag. Hier wird es im Unix-Zeitformat am 18. April 2019 verschlüsselt. Dies ist einige Tage nach der Veröffentlichung von Version 19.4.1.
Neben dem neuen Präfix gibt es hier noch einen weiteren Teil, der aktiviert und gesteuert wird. Hier ist das Kontrollpräfix, es ist kein Zufall. Und neben der Tatsache, dass wir Benutzer in neue und alte zerlegen, zerlegen wir sie in Gruppen innerhalb des Experiments in mehrere Teile.
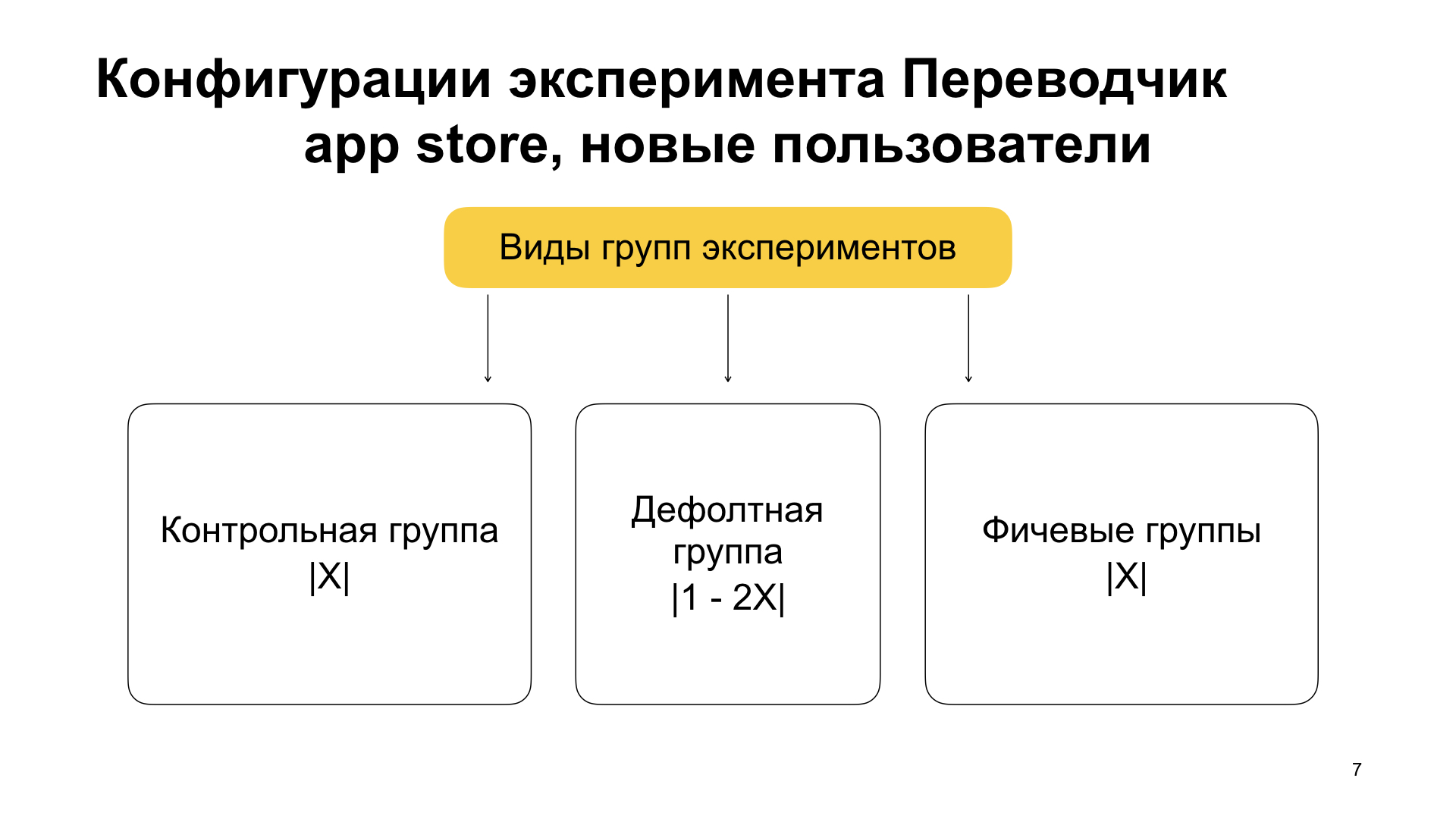
Der erste Teil der Benutzer ist eine Kontrollgruppe mit dem Kontrollpräfix. Es gibt keine Funktionen darin. Sie hat eine X-Gewichtung und eine Feature-Gruppe, die normalerweise als aktiviert bezeichnet wird. Es hat auch eine X-Gewichtung, und das ist wichtig: Dort sollte die Funktion aktiviert sein. Und es gibt eine Standardgruppe mit einer Gewichtung von 1 minus 2X (1000 minus 2X, da 1000 der Wert des Gesamtgewichts aller Gruppen in derselben Konfiguration ist, der standardmäßig akzeptiert wird). Die Standardgruppe enthält auch keine Funktion. Es werden lediglich Benutzer gespeichert, die nach der Aufteilung in Kontroll- und Funktionsbenutzer übrig geblieben sind. Sie können das Experiment bei Bedarf auch erneut ausführen.

Nehmen wir zum Beispiel die Konfiguration für alte Benutzer. Wir werden hier eine Funktions- und Kontrollgruppe sehen. enabled_old - empfohlen. control_old, - control, 10%. default_old - Standard, 80%.
Filter ya_min_version 19.4.1, max_install_date 28. März 2019 notieren. Dies ist ein Datum vor dem Veröffentlichungsdatum. Dementsprechend handelt es sich um eine Konfiguration mit einer Liste von Benutzern, die nach dem Update die Version 19.4.1 erhalten haben. Sie benutzten die Anwendung und verwenden nun die neue Version.
Warum werden Funktions- und Kontrollgruppen benötigt? In der Analyse, die ich auf der ersten Folie gezeigt habe, vergleichen wir die Kontrollgruppe und die Merkmalsgruppe. Sie müssen von gleicher Leistung sein, damit ihre Produktmetriken verglichen werden können.
Daher vergleichen wir die Steuerelement- und Feature-Gruppen in der Analyse für verschiedene alte und neue Benutzergruppen. Wenn wir alles malen, rollen wir das Feature um 100%.

Wie arbeitet ein Codeentwickler mit diesem System? Er kennt die Namen von Feature-Gruppen, das Datum, an dem das Feature aktiviert werden muss, und schreibt eine Zugriffsschicht. Dies ist ein Pseudocode, der eine aktive Gruppe mit dem Namen des Experiments anfordert. Es kann nicht sein. Tatsächlich entsprechen möglicherweise nicht alle Konfigurationen den Bedingungen des Geräts. Dann wird die leere Zeichenfolge zurückgegeben.
Wenn danach der Name der aktiven Gruppe angezeigt wird, müssen Sie die Funktion aktivieren, andernfalls müssen Sie sie deaktivieren. Darüber hinaus wird diese Funktion bereits im Code verwendet, der Funktionen im Browsercode enthält.

Wir haben also mehrere Jahre mit diesem Experimentiersystem gelebt. Alles war in Ordnung, zeigte aber eine Reihe von Mängeln. Der erste Nachteil dieses Ansatzes ist, dass es unmöglich ist, neue Versuchsgruppen hinzuzufügen, ohne den Code zu korrigieren. Das heißt, wenn sich der Name des Experiments für ein Feature wahrscheinlich nicht ändert und dann ein paar weitere Gruppen hinzugefügt werden, kann dies problemlos der Fall sein. Der Zugangscode für Ihr Feature kennt solche Gruppen jedoch nicht, da Sie dies nicht im Voraus vorausgesehen haben. Dementsprechend müssen Sie die Version rollen, experimentieren Sie mit dieser Version, was ein Problem ist. Das heißt, es ist erforderlich, durch Ändern des Codes, neu zu erstellen und im App Store zu veröffentlichen.
Zweitens können Sie nach dem Start des Experiments keine Teile eines Features ausrollen oder ein Feature in Teile aufteilen. Das heißt, wenn Sie plötzlich entschieden haben, dass einige der Features ausgerollt werden können und andere noch im Experiment vorhanden sind, müssen Sie im Voraus überlegen, dieses Feature in zwei Teile aufteilen und sie unabhängig voneinander im Experiment akzeptieren.
Drittens können Sie keine Funktion konfigurieren oder Konfigurationen vergleichen. In Translator gibt es beispielsweise eine Parameter-Zeitüberschreitungszeit für die Translator-API. Das heißt, wenn wir es nicht geschafft haben, in wenigen Millisekunden zu übersetzen, dann sagen wir, versuchen Sie es noch einmal, ein Fehler, kein Glück.
Es ist nicht möglich, dieses Zeitlimit im Experiment festzulegen, da wir entweder die Gruppen festlegen müssen und sofort im Voraus die folgenden Gruppen festlegen müssen: enabled_with_300_ms, enabled_with_600_ms, in deren Namen der Parameterwert codiert ist. Aber es ist unmöglich, den Parameter irgendwie numerisch einzustellen. Wenn wir das vorher nicht gedacht haben, können wir nicht mehr mehrere Konfigurationen vergleichen.
Viertens müssen sich Analysten und Entwickler im Voraus auf Gruppennamen einigen. Das heißt, damit ein Entwickler mit der Entwicklung eines Features beginnen kann, beginnt er normalerweise tatsächlich mit der Verfügbarkeitsrichtlinie dieses Features. Und er muss die Namen der Feature-Gruppen kennen. Dazu muss der Analytiker die Mechanismen des Experiments erläutern - ob wir Benutzer in neue und alte Benutzer aufteilen oder ob alle Benutzer in derselben Gruppe ohne Unterteilung sind.
Oder es könnte ein umgekehrtes Experiment sein. Beispielsweise können wir sofort davon ausgehen, dass die Funktion aktiviert ist, sie jedoch deaktivieren können. Dies ist für den Analysten nicht sehr interessant, da die Funktion noch nicht bereit ist. Er wird die Mechanik des Experiments bestimmen, wenn es fertig ist. Und der Entwickler braucht die Namen der Gruppen und die Mechanik des Experiments im Voraus, sonst muss er ständig Änderungen am Code vornehmen.
Wir haben uns beraten und entschieden, dass es ausreicht, um auszuhalten. So wurde das Projekt Make Experiments Great Again ins Leben gerufen.

Die Schlüsselidee dieses Projekts ist wie folgt. Wenn wir früher an einen Code angehängt waren, einen Code für die Namen der aktiven Gruppen, die der Analyst an uns übergeben hat, haben wir jetzt zwei zusätzliche Entitäten hinzugefügt. Diese Funktion (Feature) und Feature-Parameter (FeatureParam). Auf diese Weise erfindet der Programmierer Features und Feature-Parameter unabhängig voneinander, wählt Bezeichner für sie aus, wählt Standardwerte für sie aus und programmiert die Verfügbarkeit von Features für sie.
Anschließend übergibt er diese Kennungen an den Analytiker. Der Analytiker spezifiziert sie in den Experimentgruppen unter Verwendung des Tags feature_association auf besondere Weise, indem er die Mechanismen der Experimente durchdacht. Wenn diese Gruppe aktiv wird, denken Sie bitte daran, die Funktion mit dem oder den Bezeichnern zu aktivieren oder zu deaktivieren und die Parameter mit diesen Bezeichnern festzulegen.

Wie sieht es in der Testkonfigurationsdatei aus? Hier schauen wir uns die Versuchsgruppe an. Bei aktiviertem Namen wird ein optionales feature_association-Tag hinzugefügt. In diesem Befehlstag enable_feature oder disable_feature werden Bezeichner hinzugefügt.
Es gibt auch einen Parameterblock, von dem es mehrere geben kann. Auch hier gibt es ein Name-Timeout und der einzustellende Wert wird addiert.

Wie sieht das aus Code aus? Der Programmierer deklariert die Entitäten der Klassen Feature und FeatureParam. Und es schreibt Werte von diesen Grundelementen in die Feature-Zugriffsschicht. Anschließend übergibt es diesen Bezeichner an den Analysten, und er legt bereits in der Konfigurationsdatei die Bezeichner im Block der Experimentgruppe mithilfe des Tags feature_association fest. Sobald die Versuchsgruppe aktiv wird, werden die Werte von Merkmalen und Parametern mit diesen Kennungen im Code aus der Datei festgelegt. Wenn die Gruppe keine Parameter und Features enthält, werden die Standardwerte verwendet, die aus dem Code hervorgehen.
Es scheint, dass dies uns gab? Erstens muss der Analyst beim Hinzufügen einer neuen Gruppe den Programmierer nicht auffordern, dem Code eine neue Feature-Gruppe hinzuzufügen, da die Datenzugriffsebene mit Bezeichnern arbeitet, die sich nicht ändern, wenn dem Testsystem eine neue Gruppe hinzugefügt wird.
Zweitens haben wir die Zeit angegeben, zu der Programmierer diese Bezeichner für Features und Feature-Parameter haben, und die Zeit, zu der der Analytiker die Mechanik des Experiments entwickelt. Der Analyst entwickelt sich, wenn das Feature fertig ist, und der Programmierer findet diese Bezeichner ganz am Anfang, wenn er den Code schreibt.
Außerdem können Sie die Funktion in Teile aufteilen. Angenommen, es gibt eine Funktion namens Übersetzer, zu der auch der Übersetzer gehört. Und es gibt eine Funktion von TranslateServiceAPITimeout, die zusätzliche Funktionen enthält, mit denen ein benutzerdefiniertes Zeitlimit für die Übersetzer-API festgelegt werden kann. Auf diese Weise können wir zwei Gruppen von Experimenten durchführen, bei denen der Übersetzer eingeschaltet ist, aber gleichzeitig vergleichen wir, welcher Wert besser ist: 300 Millisekunden oder 600.
. . (FeatureParam).
, , , . , , . , , . . ?

, : Feature FeatureParam. Feature FeatureParam . , Feature FeatureParam, , . . - , , .
-, Feature&FeatureParam. , «», , , . FeatureParam , , API — 300 600 ?
. . - , . public beta, . , .
, : .

? , , .
: . URL, , .
: browser://version — show-variations-cmd. : cheat-, . : .
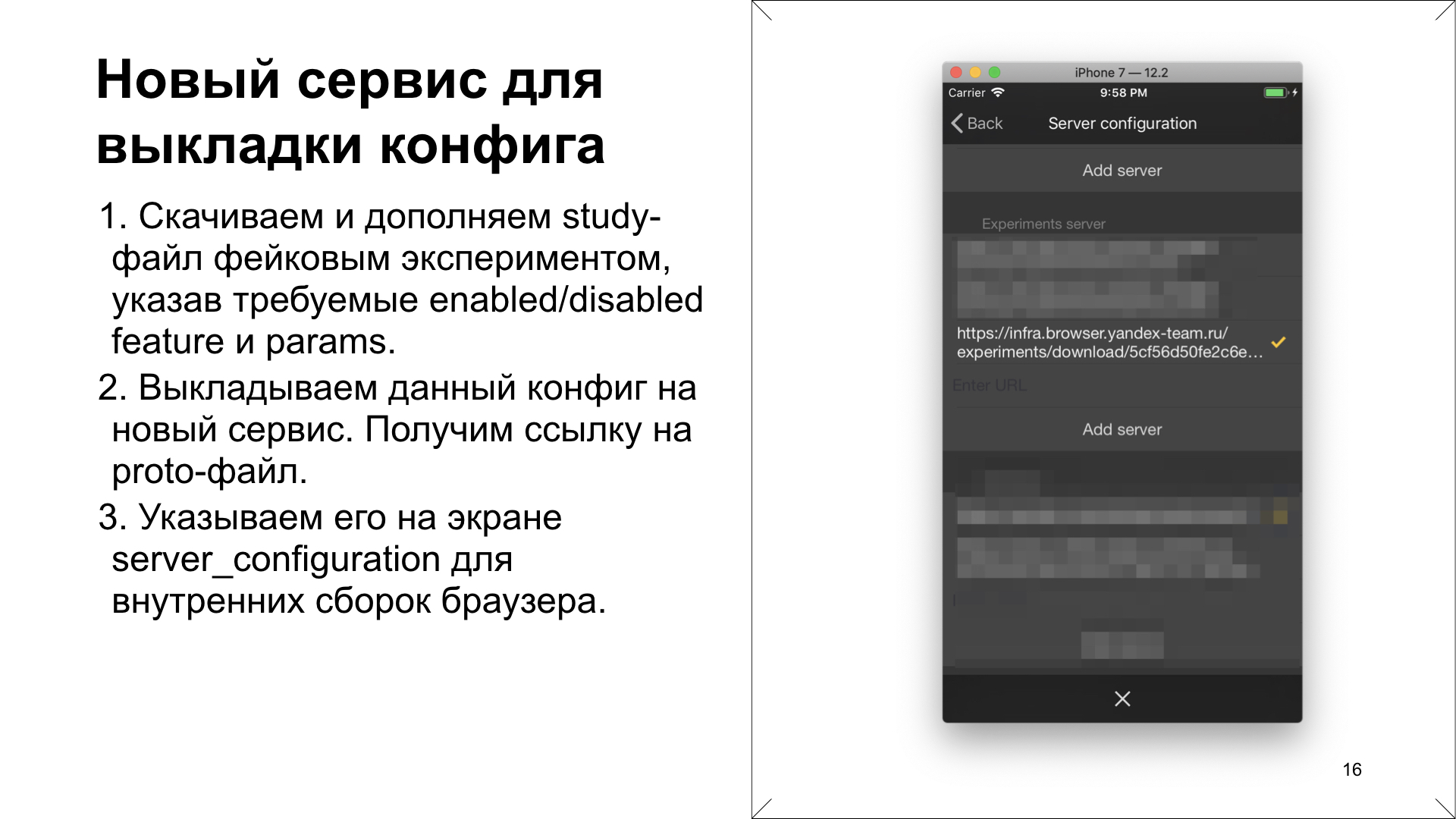
. , . proto- - , study-, . , . Feature&FeatureParam, . , , . , , Feature&FeatureParam .
. proto- . . , . , , .

Der zweite. Feature&FeatureParam? Chromium, . Chromium browser://version, show-variations-cmd.
: enabled-features, force-fieldtrials force-fieldtrials-params, . , . ? , . , Feature1 trial1. Feature2 trial2. Feature3 .
trial1 group1. trial2 group2. force-fieldtrials-params, , trial1 group1, p1 v1, p2 v2. trial2 group2, p3 v3, p4 v4.
, . Chromium, iOS. , .
. --force-fieldtrials=translator/enabled_new/ enabled_new translator.
--force-fieldtrial-params==translator.enablew_new:timeout/5000, translator enabled_new, , , translator, enabled_new timeout, 5 000 .
--enabled-features=TranslateServiceAPITimeout<translator , - translator translator , , , TranslateServiceAPITimeout. , , , , .

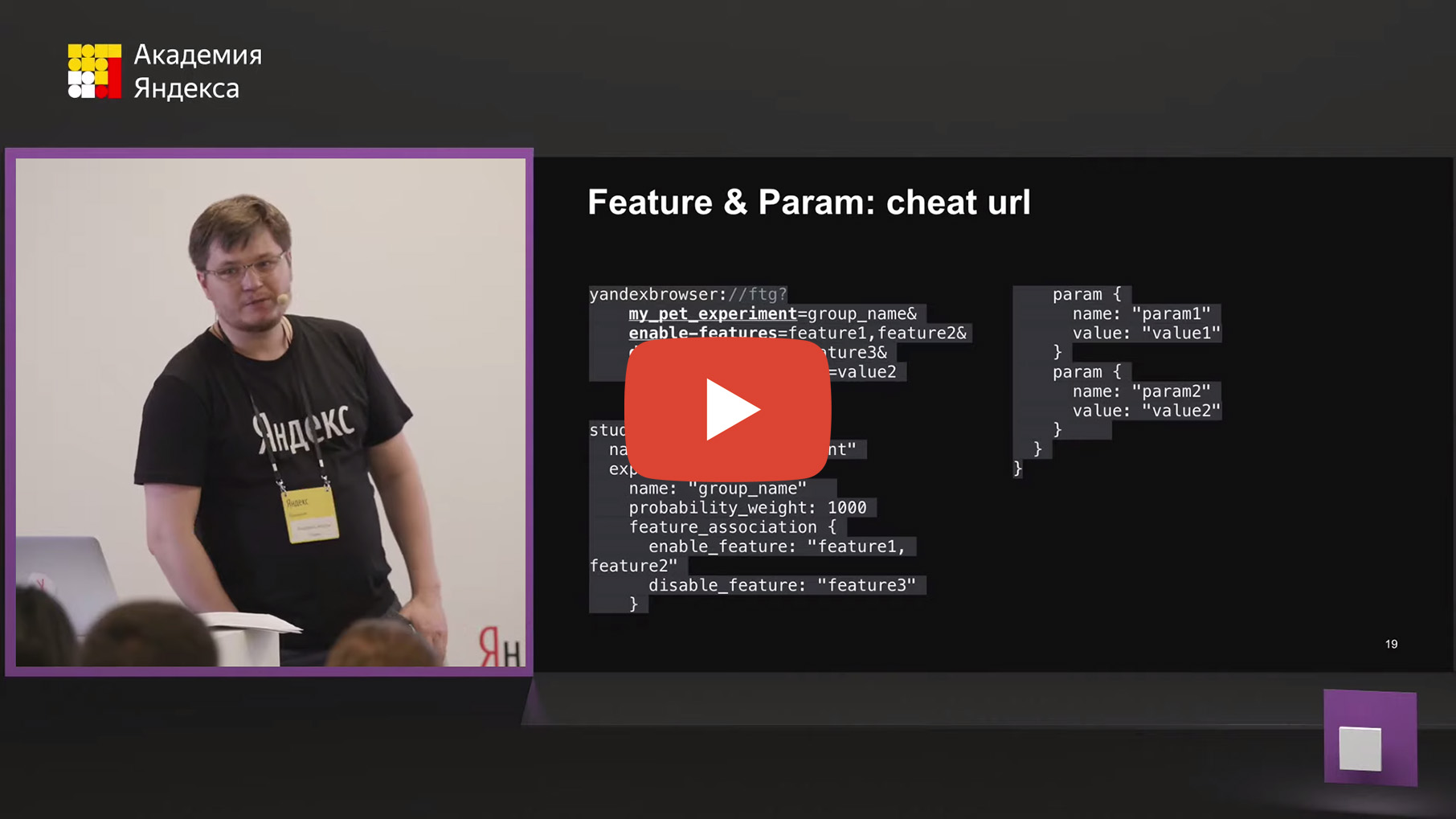
(cheat urls). , , , , , , . . . .
yandexbrowser:// (.), , . . my_pet_experiment=group_name. , enable-features=, , disable-features=, . , &.
(cheat url), . , , , . , , . filter, my_pet_experiment , . 1000, feature_association, , .
, . , , . , — my_pet_experiment — , , . , , study .
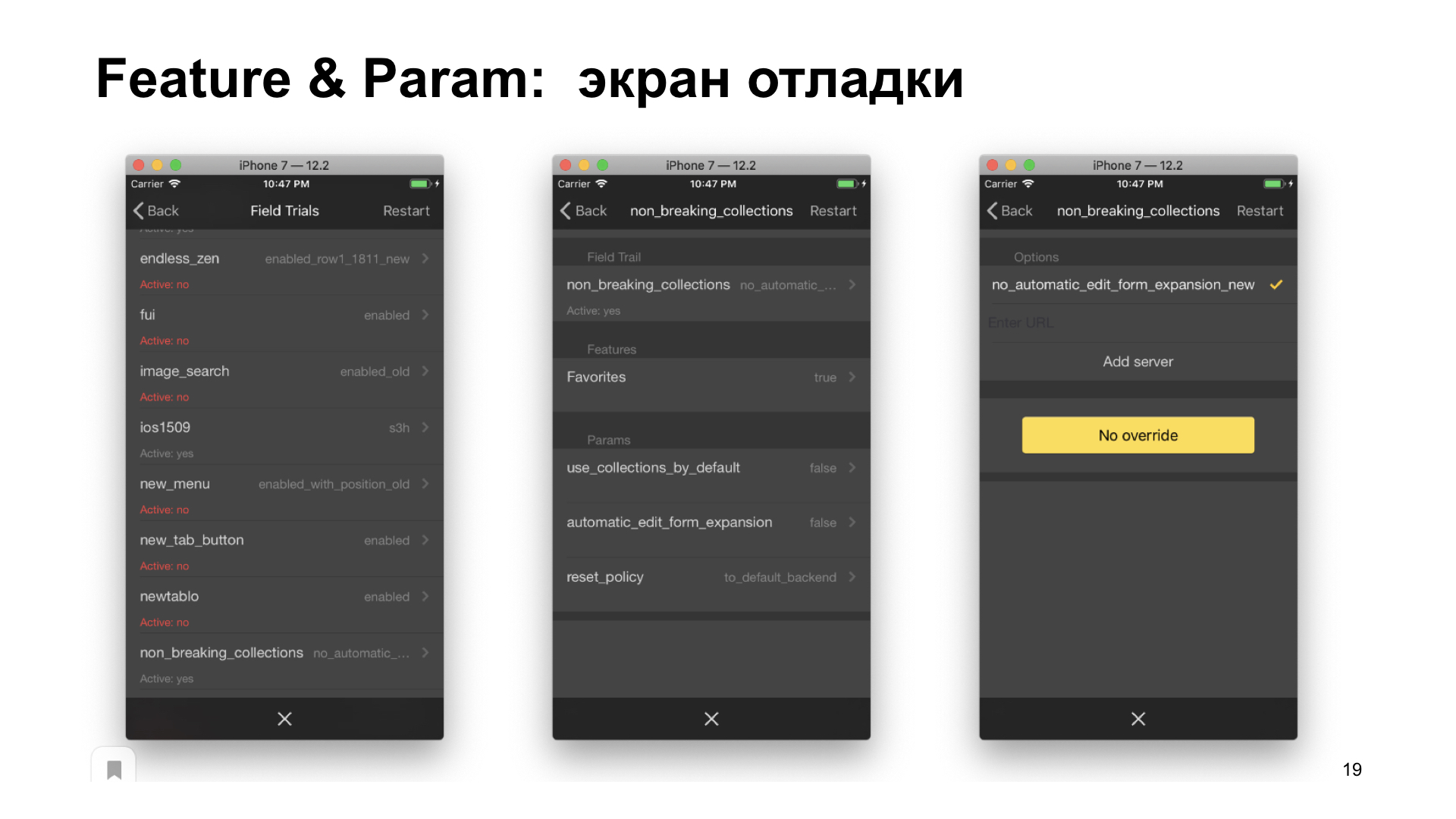
, . — , . . , .
, .

, , , , . , . , .
. . , , ? , . , ?
. .

, . , , UUID, application Identifier, . . hash .
? ? , , UUID, . ? , , . . ? hash hash , . ,
Google, An Efficient Low-Entropy Provider.
, — UUID, , , . , , Chromium.
, , ? ? :
- : , -. .
- . , , , .
- . , , , .
- , .
- . , , (. hromium variation service ).
Chromium, . iOS, . , . Vielen Dank.