Wenn die Anzahl der Kommentare unter dem Artikel von einem Fast Jack nahe 1000 liegt, ist sicher - unabhängig vom vom Autor angegebenen Thema - srach wütet im Inneren: Brennpunkte der Politik, umgeben von Couch-Experten zu allen Fragen, psychiatrische Diagnosen auf Distanz nach Profilbild und Spitznamen, Übergänge zu Persönlichkeiten, sarkastische Attacken, Die Unschärfe, die größer ist als die des Xenomorphblutes, und natürlich die Pflichtschale in solchen Fällen, sind die gegenseitigen Anschuldigungen, über die Ihr Partner und Sie ausschließlich diskutieren, um eine Belohnung zu erhalten und / oder im Dienst. Das ist anscheinend gefährlich und schwierig, und auf den ersten Blick scheint es unsichtbar zu sein, und dreißig Silberlinge liegen nicht auf der Straße.
Das Lustigste in dieser Situation ist
Dass Menschen, die stark vom
Internet-Jemand-Falsch- Syndrom betroffen sind, oft eine verdammte Pause von Zeit und Nerven verbringen, um einem anderen zu beweisen, ist ebenso
völlig frei, dass er genau dasselbe
für Geld oder auf Befehl tut. Suchen Sie nach Logik hier? Sie ist nicht. Das ist das Internet, Baby.
Lassen Sie uns eine der
relativ aktuellen Fragen zur angeblichen territorialen Diskriminierung bei Gitlab stellen. Seit der Veröffentlichung des Artikels sind 4 Tage vergangen, und natürlich hat sich die Diskussion vor langer Zeit von dem ursprünglich genannten Thema für ferne Länder entfernt. Diese Sätze klingen:
Eine reale Person kann keinem professionellen Kommentator eines Abonnements etwas entgegensetzen ...
Der Benutzer (so und so) verbringt einfach eine unrealistische Menge an Zeit mit Kommentaren ...
Gleichzeitig weist seine Aktivität keine Muster auf, die normalerweise einem normalen Benutzer eigen sind ...
ps, aber es hat mich dazu gebracht, einen Parser-Analysator für solche Kommentatoren zu schreiben) Mit Angabe der Aktivität nach Stunde, Zeit pro Tag, pro Woche usw. ... Ein gutes Thema für den Artikel)
Also hör auf. Und was sind diese Muster, die „normalerweise dem durchschnittlichen Benutzer eigen sind“? Der Autor dieses Satzes in diesem Thema wurde leider bereits übersetzt, sodass Sie nach dem Zufallsprinzip vorgehen müssen.
Die Frage, die ich vor Ihren Augen stellen möchte, ist klar, die nächste - ist es überhaupt möglich, mithilfe statistischer Methoden dieselben Muster zumindest irgendwie zuverlässig zu unterscheiden, um einen formalen Klassifikator zu erstellen, der Gelegenheitskommentatoren von professionellen unterscheidet? Stellen Sie sich vor: "Laut Habr-Botometer sind Sie mit einer Wahrscheinlichkeit von 76% ein Kreml-Bot." Es wird viel cooler sein als karmische Überfälle aufeinander.
Leider reichen meine Kompetenzen nicht aus, um zu erraten, wie man gräbt, um ein solches Problem zu lösen. Trotzdem habe ich letzte Nacht einen kleinen primitiven Parser „auf die Knie“ geschlagen, der (da die Kommentarseite auch für nicht autorisierte Besucher geöffnet ist) vorerst zwei Dinge tut - a) er sammelt Statistiken aus all seinen Kommentaren (für jetzt ist es nur Zeit) -stamp) und fügt der MySQL-Datenbank hinzu; b) zeichnet ein Zeitdiagramm, auf dem die Ereignisse des Versendens eines Kommentars aus dieser Datenbank vermerkt sind. Auch ohne eine knifflige Analyse hat es sich als ziemlich lustig herausgestellt. So sieht mein Kommentardiagramm aus. Erklärungen sind unten. Es wird am besten in einem separaten Fenster auf einer Skala von 100% oder mehr angezeigt.

Auf der horizontalen Achse ist die Zeit, jedes Pixel entspricht einer Minute, der Preis für Grauteile entspricht einer Stunde, die gesamte horizontale Linie entspricht einem Tag. Der Tag verläuft entlang der vertikalen Achse von unten nach oben, der Teilungspreis beträgt 365 Tage.
In meinem Diagramm gibt es nichts besonders Interessantes. Es ist zu sehen, dass ich gerne 7 bis 8 Stunden schlafe, oft nach Mitternacht ins Bett gehe und manchmal mehrstündige Kommentar-Marathons organisiere, und dass die Aktivität im letzten Jahr die der letzten fünf Jahre übersteigt oder in etwa ihr entspricht.
Oder, Genosse
Gecube schwieg dreieinhalb Jahre lang, und dann brach es durch ...

Ein typisches Habra-Kommentator-Aktivitätsdiagramm sieht
ungefähr so aus (dies ist
QtRoS )

Eine deutliche „Schlafmulde“ links irgendwo in der europäischen Nacht, die bei Tageslicht gemächlich kommentiert wird, möglicherweise mit Unterbrechungen für ein halbes Jahr.
Aber nicht alle Charts sind so langweilig! Wie gefällt dir das:

Über zwei Jahre lang hat unser Kollege anscheinend seinen Biorhythmus nach einer europäischen Nacht irgendwo unter dem mittelatlantischen Rücken umgeschult, außerdem gleichmäßig und allmählich, und dann weitere zwei Jahre verbracht, um an die portugiesische Küste zurückzukehren. Gehen? Schwimmen Ich kann mir keine plausiblen Erklärungen einfallen lassen ... Die ersten drei Stunden der Wachsamkeit, die Kommentare fliegen wie ein Maschinengewehr, und am Ende des Tages warf ich einmal in der Stunde einen Blick auf das, was getan wurde und das ist alles.
Es war übrigens
0xd34df00d .
Und hier ist ein weiteres Rätsel:
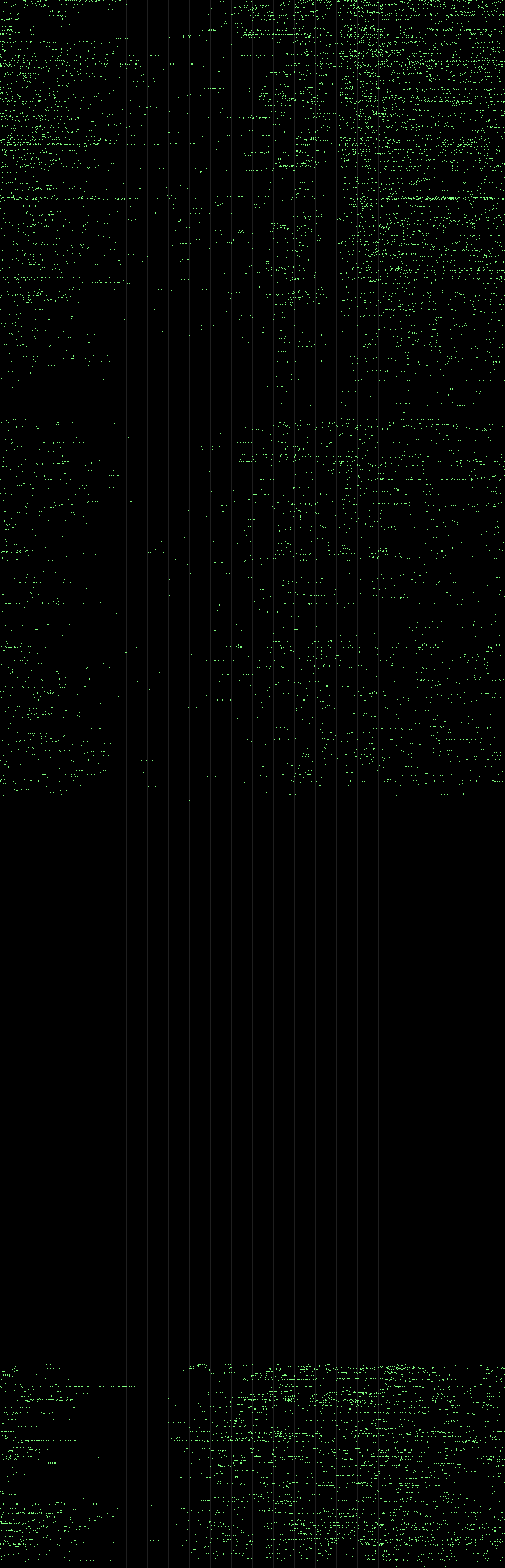
Viereinhalb Jahre lang hielt der Kollege ohne einen einzigen Kommentar durch - er sah, dass er irgendwo in geheimen Klöstern trainierte, wie man tagelang nicht schläft, gemessen an der Anzahl der Kommentare, die in die "Schlafmulde" geschickt wurden.
Das Interessanteste ist jedoch die Anomalie in der 16. Stunde, die mehr als drei Jahre andauert und im letzten Jahr allmählich verblasst. Rauchpause? Mit dem Hund spazieren gehen? Joggen? Was kann noch ein Habrovchanin aus einem Kommentarband auf dem Höhepunkt eines Arbeitstages mit einer solchen täglichen Vorausbestimmung herausreißen? Ich meißele und eine
Stubenhocker , ich kann mir keine solche Selbstdisziplin vorstellen, die sich der respektierte
Khim leisten kann.
Zum Schluss das letzte Diagramm, über das man nachdenken sollte:

Es hat im Allgemeinen keine ausgeprägte "müde Mulde". Vermutet nur knapp den scheinbaren Überschuss der Anzahl der am Nachmittag übermittelten Kommentare, die zuvor gesendet wurden.
Bei allem
Ernst von Komsomol fordere ich den angesehenen
MTyrz auf , vor der Party die
Waffen zu räumen und ehrlich zuzugeben, wie viele Großeltern, Enkelinnen, Käfer und Mäuse Ihr Konto steuern und Kommentare aufschreiben.
Und am Ende die heimtückische Frage: Kann sich irgendjemand so für alles interessieren, dass er den Parser-Code entwickeln und / oder einen Datenbank-Dump oder Zugriff darauf erhalten möchte? Meine eigenen Kenntnisse im Bereich Data Mining und Datenvisualisierung gehen kaum über die allgemeine Kenntnis hinaus. Etwas schlaueres und interessanteres als diese einfachen kleinen Diagramme, die ich mir kaum vorstellen kann. Wenn jemand interessiert ist, schreibe mir in einem Telegramm (Spitzname im Profil).
Vielen Dank für Ihre Aufmerksamkeit!
UPD Ich habe den
Quellcode auf GitHub gepostet.