Foto von Dugan Arnett auf Boston Globe
Suchen Sie noch eine neue Wohnung? Bereit für den letzten Versuch? Wenn ja - folgen Sie mir und ich zeige Ihnen, wie Sie die Ziellinie erreichen.
Kurze Einführung und Referenzen
Es ist der dritte Teil des Zyklus, in dem erläutert wird, wie Sie die optimale Wohnung auf dem Immobilienmarkt finden können. In wenigen Worten die Hauptidee - Finden Sie das beste Angebot unter den Wohnungen in Jekaterinburg, wo ich vorher gelebt habe. Aber ich denke, die gleiche Idee kann im Kontext einer anderen Stadt betrachtet werden.
Wenn Sie die vorherigen Teile nicht gelesen haben, ist es eine gute Idee, sie Teil1 und Teil2 zu lesen.
Dort können Sie auch Ipython-Notizbücher finden .
Dieser Teil musste viel kürzer sein als die vorherigen, aber der Teufel steckt im Detail.
Folgen
Als Ergebnis aller Aktionen haben wir ein ML-Modell (Random Forest) erhalten, das recht gut funktioniert. Nicht so gut wie erwartet (der Score liegt über 87%), aber für echte Daten ist es gut genug. Und ... lassen Sie mich ehrlich sein, diese Gedanken über das Ergebnis hatten einen seltsamen Einfluss auf mich. Ich wollte mehr Punkte, die Lücke zwischen dem erwarteten Ergebnis und der tatsächlichen Vorhersage war kleiner als 3%. Optimismus, gemischt mit Gier, ist mir in den Sinn gekommen

Ich will mehr Gold Genauigkeit
Es ist allgemein bekannt, dass es wahrscheinlich entgegengesetzte Ansätze geben wird, wenn Sie etwas verbessern möchten. Normalerweise sieht es nach einer Wahl aus zwischen:
- Evolution gegen Revolution
- Quantität gegen Qualität
- Umfangreich gegen intensiv
Und wegen des mangelnden Willens, die Pferde im Midstream zu wechseln, habe ich mich für RF (Random Forest) entschieden und ein paar neue Funktionen hinzugefügt.
Es schien eine Idee zu sein, "wir brauchen nur mehr Funktionen", um die Punktzahl zu verbessern. Zumindest dachte ich das.
Per aspera ad astra (durch Strapazen zu den Sternen)
Lassen Sie uns versuchen, über verwandte Funktionen nachzudenken, die den Preis einer Wohnung beeinflussen könnten. Es gibt Eigenschaften von Wohnung wie Balkon oder Alter des Hauses und geo-bezogene Eigenschaften wie Entfernung zur nächsten U-Bahn / Bus-Station. Was könnte für den gleichen Ansatz mit RF als Nächstes kommen?
Idee Nr. 1. Entfernung zum Zentrum
Wir könnten Längen- und Breitengrade (flache Koordinaten) wiederverwenden. Anhand dieser Informationen können wir die Entfernung zum Stadtzentrum berechnen. Die gleiche Idee wurde für Stadtteile verwendet. Je weiter wir vom Zentrum entfernt sind, desto billiger sollte es sein. Und raten Sie mal, was ... es funktioniert! Kein so großes Wachstum ( + 1% der Punktzahl), aber es ist besser als nichts.
Es gibt nur ein Problem: Dieselbe Idee ist für sehr weit entfernte Stadtteile nicht sinnvoll. Wenn Sie außerhalb einer Stadt leben, wissen Sie, dass es für den Preis andere Regeln gibt.
Die Interpretation wird nicht einfach, wenn wir diesen Ansatz extrapolieren.
Idee Nr. 2. In der Nähe der U-Bahn
Die U-Bahn hat einen erheblichen Einfluss auf den Preis. Vor allem, wenn es sich in einer Fußgängerzone befindet. Aber die Bedeutung von "zu Fuß" ist nicht klar. Jede Person kann diesen Parameter auf unterschiedliche Weise interpretieren. Ich könnte das Limit manuell einstellen, aber eine Erhöhung der Punktzahl würde nicht über 0,2% liegen.
Gleichzeitig klappt es mit Flat aus der bisherigen Idee nicht. Es gibt keine U-Bahn in der Nähe.
Idee # 3. Rationalität und Marktgleichgewicht
Das Marktgleichgewicht ist eine Kombination aus Nachfrage und Angebot. Adam Smith hat darüber gesprochen. Natürlich kann der Markt überfordert sein. Aber im Allgemeinen funktioniert diese Idee gut. Zumindest für Häuser, die sich im Bau befinden.
Mit anderen Worten - je mehr Konkurrenten Sie haben, desto geringer ist die Wahrscheinlichkeit, dass die Leute Ihre Wohnung kaufen (andere Dinge sind gleich). Und das führt zu der Vermutung: "Wenn um mich herum andere Wohnungen stehen, muss ich den Preis senken, um mehr Käufer zu bekommen."
Und es klingt nach einer ganz logischen Schlussfolgerung, nicht wahr?
Also zählte ich ÄHNLICHE Wohnungen in der Nähe von jeder von ihnen, im selben Haus und in einem Umkreis von 200 Metern. Die Maßnahmen wurden zum Zeitpunkt des Verkaufs getroffen. Welches Ergebnis würden Sie erwarten? Nur 0,1% bei gegenseitiger Validierung. Traurig aber wahr.
Umdenken
Beenden ist ... manchmal einen Schritt zurück zu machen, um zwei Schritte vorwärts zu machen.
- eine unbekannte weise Person
Okay, ein Frontalangriff funktioniert nicht. Betrachten wir diese Situation aus einem anderen Blickwinkel.
Nehmen wir an, Sie sind jemand, der eine Wohnung in der Nähe eines Flusses weit weg von der lauten Stadt kaufen möchte. Sie haben drei Werbevarianten, die einander ähnlich sind und den gleichen Preis haben (mehr oder weniger). Formale Metriken, die flat beschreiben, geben keinen Aufschluss über die Umgebung. Sie sind nur Metriken auf einem Bildschirm. Aber es gibt etwas Wichtiges.
Eine Wohnungsbeschreibung ist eine tolle Gelegenheit.
Eine flache Beschreibung könnte alles bieten, was Sie brauchen. Es könnte Ihnen eine Geschichte über eine Wohnung, über Nachbarn und erstaunliche Gelegenheiten erzählen, die mit diesem bestimmten Wohnort zusammenhängen. Und manchmal kann eine Beschreibung sinnvoller sein als langweilige Zahlen.
Aber im wirklichen Leben ist etwas anders als unsere Erwartungen. Lassen Sie sich von mir zeigen, was und warum nicht funktioniert.
Was wird nicht funktionieren und warum?
Erwartungen - "Whoa! Ich kann versuchen, Text zu klassifizieren und 'gute' und 'schlechte' Wohnungen zu finden. Ich werde die gleiche Methode anwenden, die normalerweise für die Stimmungsanalyse verwendet wird."
Realität - "Nein, du wirst es nicht tun. Die Leute schreiben nichts Schlechtes gegen ihre Wohnung. Eine reale Situation oder Lüge kann beschönigt werden."
Erwartungen - "Okay. Dann kann ich versuchen, Muster zu finden und die Zielgruppe für eine Wohnung zu finden. Zum Beispiel könnten es ältere Menschen oder Studenten sein."
Realität - "Nein, Sie werden es nicht tun. Manchmal wird in einer Anzeige über verschiedene Altersgruppen und soziale Gruppen gesprochen, es handelt sich nur um Marketing."
Was würde wohl funktionieren und warum?
Einige Stichwörter - Es gibt Wörter, die auf bestimmte Dinge oder Momente im Zusammenhang mit der Wohnung hinweisen. Wenn es sich beispielsweise um ein Studio handelt, ist der Preis niedriger. Verben sind im Allgemeinen nutzlos, aber Substantive und Adverbien können mehr Kontext ergeben.
Die alternative Informationsquelle - Verwenden Sie die Beschreibung, um leere oder NaN-Werte korrekter auszufüllen. Manchmal enthält die Beschreibung mehr Informationen als formale Merkmale der Werbung.
Ich vermute es aufgrund menschlicher Faulheit, nicht benötigte Felder wie "Balkon" auszufüllen. Alles in die Beschreibung einzufügen, scheint eine vorzuziehende Idee zu sein
Ich überspringe die Beschreibung des typischen Prozesses der Tokenisierung / Lemmatisierung / Stemmung. Ich glaube auch, dass es Autoren gibt, die es besser beschreiben können als ich.
Obwohl ich denke, dass das Toolset zum Extrahieren von Features erwähnt werden sollte. Kurz gesagt sieht es so aus.

Trennung-> Übereinstimmung nach Wortart
Nach der Vorverarbeitung des Anzeigentextes habe ich eine Reihe solcher russischer Wörter erhalten.

Der Originaltext ist unter https://pastebin.com/Pxh8zVe3 abgelegt
Ich habe versucht, den Ansatz von Word2Vec zu verwenden, aber es gab kein spezielles Wörterbuch für Wohnungen und Werbung, sodass das allgemeine Bild seltsam aussah
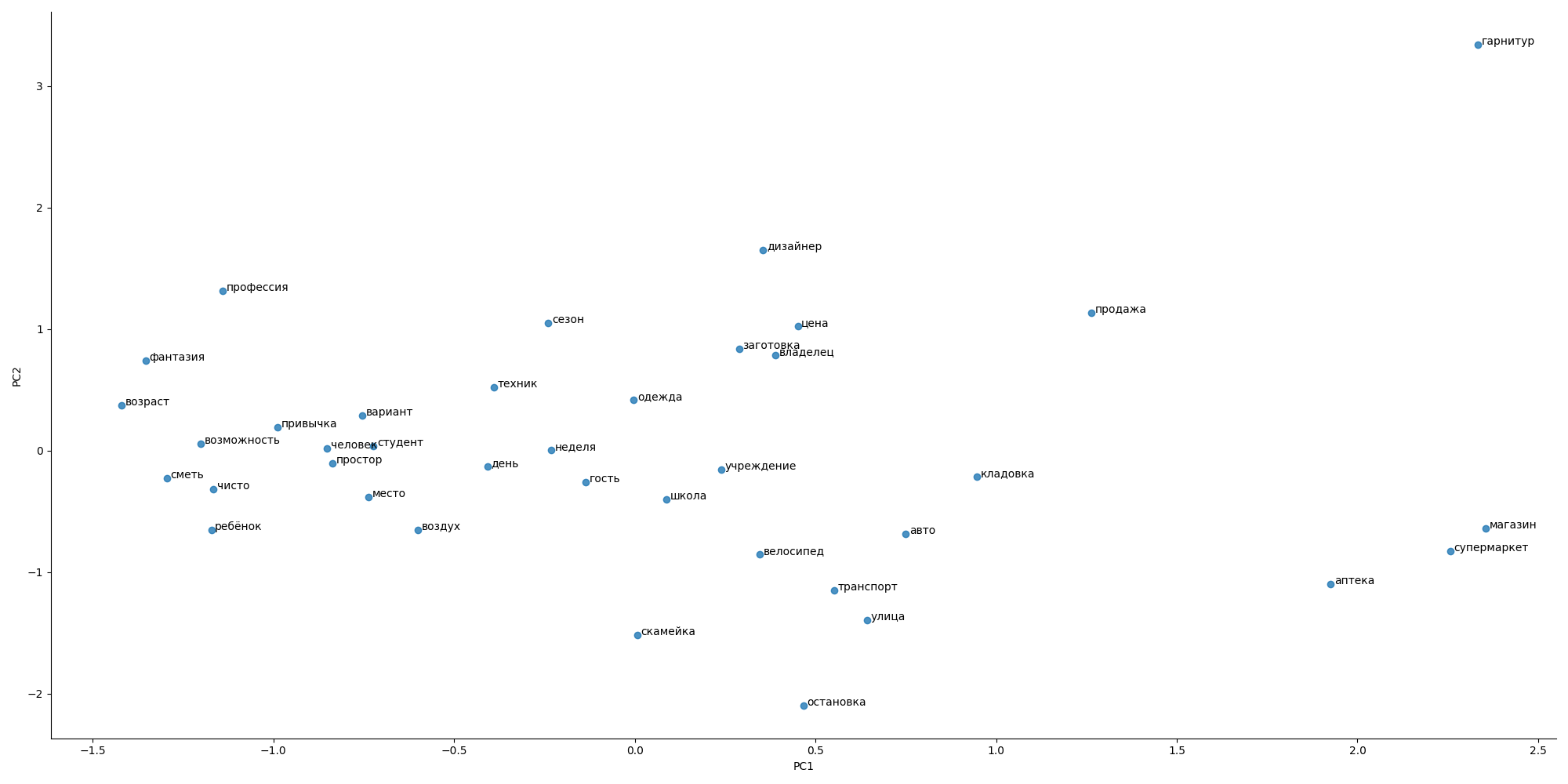
Der Abstand zwischen den Wörtern entspricht nicht den Erwartungen
Deshalb habe ich es so einfach wie möglich gehalten und beschlossen, mehrere neue Spalten für den Datensatz zu erstellen
Ein bisschen weniger Konversation, ein bisschen mehr Action
Zeit, uns die Hände schmutzig zu machen und ein paar praktische Dinge zu tun. Informieren Sie sich über neue Funktionen. Mehrere wichtige Faktoren wurden durch einen Einfluss auf den Preis getrennt.
positive auswirkung
- Möbel - manchmal konnten Leute ein Bett, eine Waschmaschine und so weiter verlassen.
- Luxus - Wohnungen mit luxuriösen Dingen wie Whirlpool oder exklusivem Interieur
- Videokontrolle - sie gibt den Menschen das Gefühl, sicher zu sein, und betrachtet sie häufig als Vorteil
negative Auswirkungen
- Wohnheim - ja, manchmal ist es eine Wohnung in einem Wohnheim. Nicht so beliebt, aber deutlich günstiger als eine durchschnittliche Wohnung
- Eile - Wenn Leute eilen, um ihre Wohnung zu verkaufen, sind sie normalerweise bereit, den Preis zu senken.
- Studio - wie ich schon sagte - sie sind billiger als ihre Wohnungen-Analoga.
Sammeln wir sie in etwas Universalem
df3 = pd.read_csv('flats3.csv') positive_impact = ['', 'luxury',''] negative_impact = ['studio', 'rush','dorm'] geo_features = ['metro','num_of_stops_1km','num_of_shops_1km','num_of_kindergarden_1km', 'num_of_medical_1km','center_distance'] flat_features=['total_area', 'repair','balcony_y', 'walls_y','district_y', 'age_y'] competitors_features = ['distance_200m', 'same_house'] cols = ['cost'] cols+=flat_features cols+=geo_features cols+=competitors_features cols+=positive_impact cols+=negative_impact df3 = df3[cols]
allgemeine Auswirkungen
Es ist nur eine Kombination aus negativen und positiven Eigenschaften. Anfänglich ist es für jede Wohnung gleich 0. Beispielsweise hat ein Studio mit Videokontrolle immer noch eine allgemeine Wirkung von 0 ( 1 [positiv] –1 [negativ] = 0 ).
df3['impact'] = 0 for i, row in df3.iterrows(): impact = 0 for positive in positive_impact: if row[positive]: impact+=1 for negative in negative_impact: if row[negative]: impact-=1 df3.at[i, 'impact'] = impact
Okay, wir haben Daten, neue Funktionen und ein altes Ziel mit 10% des mittleren Fehlers für die Vorhersage. Machen Sie eine typische Operation wie zuvor
y = df3.cost X = df3.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Alter Ansatz (umfangreiches Feature-Wachstum)
Wir werden ein neues Modell bauen, das auf alten Ideen basiert
data = [] max_features = int(X.shape[1]/2) for x in range(1,20): regressor = RandomForestRegressor(verbose=0, n_estimators=128, max_features=max_features, max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score - {max_result.score}\nDepth {max_result.max_depth} ')
Und das Ergebnis war etwas ... unerwartet.
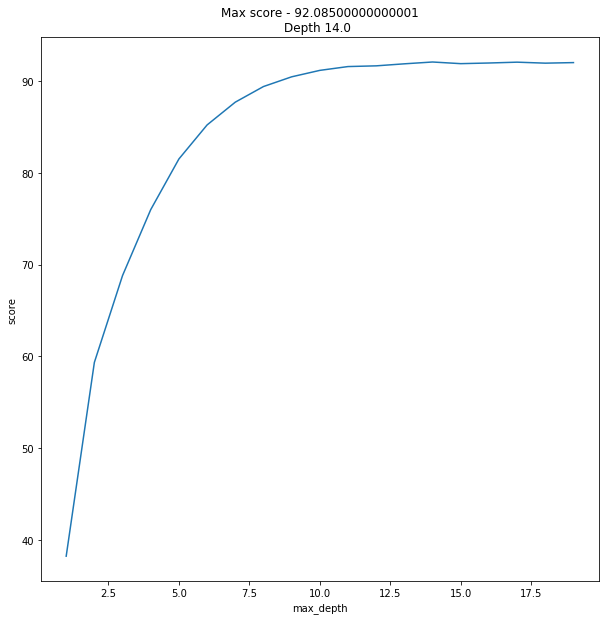
92% ist überwältigendes Ergebnis. Ich meine, zu sagen, dass ich geschockt war, wäre eine Untertreibung.
Aber warum hat es so gut funktioniert? Werfen wir einen Blick auf neue Funktionen.
regressor = RandomForestRegressor(random_state=42, max_depth=max_result.max_depth, n_estimators=128, max_features=max_features) rf3 = regressor.fit(X_train, y_train) feat_importances = pd.Series(rf3.feature_importances_, index=X.columns) feat_importances.nlargest(X.shape[1]).plot(kind='barh')
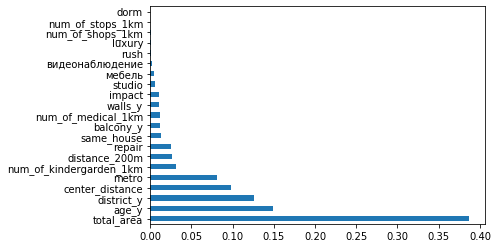
Wichtig sind alle Funktionen für unser Modell
Die Wichtigkeit gibt keine Auskunft über den Beitrag von Features (das ist eine andere Geschichte), sondern zeigt nur, wie aktive Modelle das eine oder andere Feature verwenden. Aber für die aktuelle Situation sieht es informativ aus. Einige der neuen Funktionen sind wichtiger als frühere, andere fast unbrauchbar.
Neuer Ansatz (intensive Arbeit mit Daten)
Nun ... die Ziellinie ist überschritten, das Ergebnis ist erreicht. Könnte es besser sein?
Kurze Antwort - "Ja, es könnte"
- Erstens könnten wir die Tiefe eines Baumes reduzieren. Es wird auch zu einer kürzeren Zeit für Training und Vorhersage führen.
- Zweitens könnten wir die Vorhersage ein wenig verbessern.
Für beide Momente verwenden wir XGBoost . Manchmal bevorzugen die Leute andere Booster wie LightGBM oder CatBoost , aber meiner bescheidenen Meinung nach - der erste ist gut genug, wenn Sie viele Daten haben, ein zweiter ist besser, wenn Sie mit kategorialen Variablen arbeiten. Und als Bonus - XGBoost scheint einfach schneller zu sein
from xgboost import XGBRegressor,plot_importance data = [] for x in range(3,10): regressor = XGBRegressor(verbose=0, reg_lambda=10, n_estimators=1000, objective='reg:squarederror', max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score-{max_result.score}\nDepth {max_result.max_depth} ')

Das Ergebnis ist besser als das vorherige.
Natürlich ist es der nicht große Unterschied zwischen Random Forest und XGBoost. Und jeder von ihnen könnte als gutes Werkzeug zur Lösung unseres Problems mit der Vorhersage verwendet werden. Es liegt an dir.
Fazit
Ist das Ergebnis erreicht? Auf jeden Fall ja.
Die Lösung ist dort verfügbar und kann von jedem kostenlos genutzt werden. Wenn Sie sich für die Bewertung einer Wohnung mit diesem Ansatz interessieren, zögern Sie bitte nicht und kontaktieren Sie mich.
Als Prototyp wurde es dort platziert
Danke fürs Lesen! .