TL DR: JSONB kann die Entwicklung von Datenbankschemata erheblich vereinfachen, ohne die Abfrageleistung zu beeinträchtigen.
Einleitung
Lassen Sie uns wahrscheinlich ein klassisches Beispiel für einen der ältesten Anwendungsfälle relationaler Datenbanken (Datenbank) geben: Wir haben eine Entität, und es ist notwendig, bestimmte Eigenschaften (Attribute) dieser Entität beizubehalten. Möglicherweise verfügen jedoch nicht alle Instanzen über die gleichen Eigenschaften. In Zukunft können jedoch weitere Eigenschaften hinzugefügt werden.
Die einfachste Möglichkeit, dieses Problem zu lösen, besteht darin, für jeden Eigenschaftswert eine Spalte in der Datenbanktabelle zu erstellen und die für eine bestimmte Entitätsinstanz erforderlichen Angaben zu machen. Großartig! Das Problem ist behoben ... bis Ihre Tabelle Millionen von Datensätzen enthält und Sie keinen neuen Datensatz hinzufügen müssen.
Betrachten wir das EAV
- Muster (
Entity-Attribute-Value ), so ist es durchaus üblich. Eine Tabelle enthält Entitäten (Datensätze), eine andere Tabelle enthält Namen von Eigenschaften (Attributen), und die dritte Tabelle ordnet Entitäten ihren Attributen zu und enthält den Wert dieser Attribute für die aktuelle Entität. Auf diese Weise haben Sie die Möglichkeit, verschiedene Eigenschaftensätze für verschiedene Objekte zu erstellen und Eigenschaften im Handumdrehen hinzuzufügen, ohne die Struktur der Datenbank zu ändern.
Trotzdem würde ich diese Notiz nicht schreiben, wenn es keine Mängel bei der Verwendung von EVA gäbe. Um beispielsweise eine oder mehrere Entitäten mit jeweils 1 Attribut zu erhalten, sind 2 join'a (Verknüpfungen) in der Abfrage erforderlich: Die erste ist eine Vereinigung mit der Attributtabelle, die zweite ist die Vereinigung mit der Wertetabelle. Wenn eine Entität 2 Attribute hat, werden bereits 4 Verknüpfungen benötigt! Darüber hinaus werden alle Attribute normalerweise als Zeichenfolgen gespeichert, was zu einer Typumwandlung sowohl für das Ergebnis als auch für die WHERE-Klausel führt. Wenn Sie viele Anfragen schreiben, ist dies in Bezug auf die Ressourcennutzung ziemlich verschwenderisch.
Trotz dieser offensichtlichen Mängel wird EAV seit langem zur Lösung derartiger Probleme eingesetzt. Dies waren unvermeidliche Mängel, und es gab einfach keine bessere Alternative.
Aber dann erschien eine neue "Technologie" in PostgreSQL ...
Ab PostgreSQL 9.4 wurde ein JSONB-Datentyp zum Speichern von binären JSON-Daten hinzugefügt. Obwohl das Speichern von JSON in diesem Format in der Regel etwas mehr Platz und Zeit in Anspruch nimmt als das Speichern von JSON in Nur-Text-Formaten, sind die Vorgänge damit viel schneller. JSONB unterstützt auch die Indizierung, wodurch die Abfrage noch schneller wird.
Mit dem JSONB-Datentyp können wir das umfangreiche EAV-Muster ersetzen, indem wir unserer Entitätstabelle nur eine JSONB-Spalte hinzufügen, was das Datenbankdesign erheblich vereinfacht. Aber viele argumentieren, dass dies mit einem Rückgang der Produktivität einhergehen sollte ... Deshalb bin ich in diesem Artikel aufgetaucht.
Testen Sie das Datenbank-Setup
Für diesen Vergleich habe ich eine Datenbank für eine Neuinstallation von PostgreSQL 9.5 mit dem Build von
DigitalOcean Ubuntu 14.04 für 80 US-Dollar erstellt. Nachdem ich einige Parameter in postgresql.conf gesetzt hatte, führte ich
dieses Skript mit psql aus. Die folgenden Tabellen wurden erstellt, um die Daten als EAV darzustellen:
CREATE TABLE entity ( id SERIAL PRIMARY KEY, name TEXT, description TEXT ); CREATE TABLE entity_attribute ( id SERIAL PRIMARY KEY, name TEXT ); CREATE TABLE entity_attribute_value ( id SERIAL PRIMARY KEY, entity_id INT REFERENCES entity(id), entity_attribute_id INT REFERENCES entity_attribute(id), value TEXT );
Unten finden Sie eine Tabelle, in der dieselben Daten gespeichert werden, jedoch mit Attributen in den Spalteneigenschaften des JSONB-Typs.
CREATE TABLE entity_jsonb ( id SERIAL PRIMARY KEY, name TEXT, description TEXT, properties JSONB );
Sieht doch viel einfacher aus, oder? Anschließend wurden den Entitätstabellen (
entity &
entity_jsonb ) 10 Millionen Datensätze hinzugefügt, und dementsprechend wurden dieselben Tabellendaten unter Verwendung des EAV-Musters und des Ansatzes mit der JSONB-Spalte "
entity_jsonb.properties" gefüllt . So haben wir mehrere unterschiedliche Datentypen aus dem gesamten Satz von Eigenschaften erhalten. Beispieldaten:
{ id: 1 name: "Entity1" description: "Test entity no. 1" properties: { color: "red" lenght: 120 width: 3.1882420 hassomething: true country: "Belgium" } }
Jetzt haben wir also die gleichen Daten für zwei Optionen. Beginnen wir mit dem Vergleich der Implementierungen bei der Arbeit!
Designvereinfachung
Es wurde bereits gesagt, dass das Design der Datenbank stark vereinfacht wurde: Eine Tabelle, indem die JSONB-Spalte für Eigenschaften verwendet wurde, anstatt drei Tabellen für EAV. Aber wie spiegelt sich das in den Anfragen wider? So aktualisieren Sie eine Eigenschaft einer Entität:
Wie Sie sehen, sieht die letzte Anfrage nicht einfacher aus. Um den Wert einer Eigenschaft in einem JSONB-Objekt zu aktualisieren, müssen Sie die Funktion
jsonb_set () verwenden und unseren neuen Wert als JSONB-Objekt übergeben. Wir müssen jedoch keine Kennung im Voraus kennen. Wenn wir uns das EAV-Beispiel ansehen, müssen wir sowohl entity_id als auch entity_attribute_id kennen, um aktualisieren zu können. Wenn Sie eine Eigenschaft in einer JSONB-Spalte basierend auf dem Namen des Objekts aktualisieren möchten, erfolgt dies in einer einfachen Zeile.
Nun wählen wir das Objekt, das wir gerade aktualisiert haben, entsprechend dem Zustand seiner neuen Farbe aus:
Ich denke, wir können uns einig sein, dass die Sekunde kürzer (ohne Join!) Und daher besser lesbar ist. Hier ist der Sieg von JSONB! Wir verwenden den Operator JSON - >>, um die Farbe als Textwert aus einem JSONB-Objekt abzurufen. Es gibt auch eine zweite Möglichkeit, mit dem @> -Operator dasselbe Ergebnis im JSONB-Modell zu erzielen:
Dies ist etwas komplizierter: Wir überprüfen, ob das JSON-Objekt in der Eigenschaftsspalte das Objekt rechts vom @> -Operator enthält. Weniger lesbar, produktiver (siehe unten).
Vereinfachen Sie die Verwendung von JSONB noch mehr, wenn Sie mehrere Eigenschaften gleichzeitig auswählen müssen. Hier kommt der JSONB-Ansatz zum Tragen: Wir wählen einfach Eigenschaften als zusätzliche Spalten in unserer Ergebnismenge aus, ohne dass Verknüpfungen erforderlich sind:
Mit EAV benötigen Sie 2 Joins für jede Eigenschaft, die Sie anfordern möchten. Meiner Meinung nach zeigen die obigen Abfragen eine große Vereinfachung im Datenbankdesign. Weitere Beispiele zum Schreiben von JSONB-Anforderungen finden Sie auch in
diesem Beitrag.
Jetzt ist es Zeit, über Leistung zu sprechen.
Leistung
Um die Leistung zu vergleichen, habe ich
EXPLAIN ANALYZE in den Abfragen verwendet, um die Laufzeit zu berechnen. Jede Anforderung wurde mindestens dreimal ausgeführt, da der Abfrageplaner zum ersten Mal länger dauert. Zuerst habe ich Abfragen ohne Indizes ausgeführt. Dies war offensichtlich ein Vorteil von JSONB, da der für EAV erforderliche Join keine Indizes verwenden konnte (Fremdschlüsselfelder wurden nicht indiziert). Danach erstellte ich einen Index für 2 Spalten mit Fremdschlüsseln in der EAV-Wertetabelle sowie einen
GIN- Index für die JSONB-Spalte.
Datenaktualisierungen zeigten die folgenden Ergebnisse in Zeit (in ms). Beachten Sie, dass die Skala logarithmisch ist:

Wir sehen, dass JSONB aus dem oben genannten Grund viel (> 50.000-x) schneller als EAV ist, wenn Sie keine Indizes verwenden. Wenn wir die Spalten mit Primärschlüsseln indizieren, verschwindet der Unterschied fast, aber JSONB ist immer noch 1,3-mal schneller als EAV. Bitte beachten Sie, dass der Index in der JSONB-Spalte hier keine Auswirkung hat, da wir die Eigenschaftsspalte nicht in den Bewertungskriterien verwenden.
Um Daten basierend auf einem Eigenschaftswert auszuwählen, erhalten wir die folgenden Ergebnisse (normale Skala):
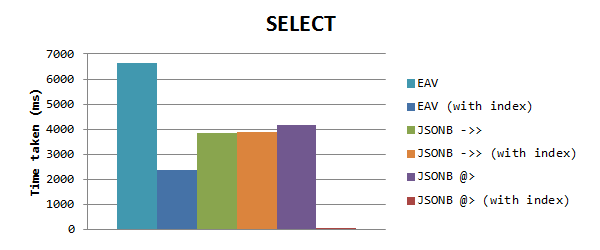
Möglicherweise stellen Sie fest, dass JSONB wieder schneller als EAV ohne Indizes ist. Wenn EAV jedoch mit Indizes arbeitet, ist es immer noch schneller als JSONB. Aber dann sah ich, dass der Zeitpunkt für JSONB-Anfragen derselbe war, was mich dazu veranlasste, dass der GIN-Index nicht funktionierte. Wenn Sie den GIN-Index für eine Spalte mit gefüllten Eigenschaften verwenden, funktioniert dies anscheinend nur mit dem Einschlussoperator @>. Ich habe dies in einem neuen Test verwendet, der eine enorme Auswirkung auf die Zeit hatte: nur 0,153 ms! Dies ist 15.000-mal schneller als EAV und 25.000-mal schneller als operator - >>.
Ich denke es war schnell genug!
DB-Tabellengröße
Vergleichen wir die Tabellengrößen für beide Ansätze. In psql können wir die Größe aller Tabellen und Indizes mit dem
Befehl \ dti + anzeigen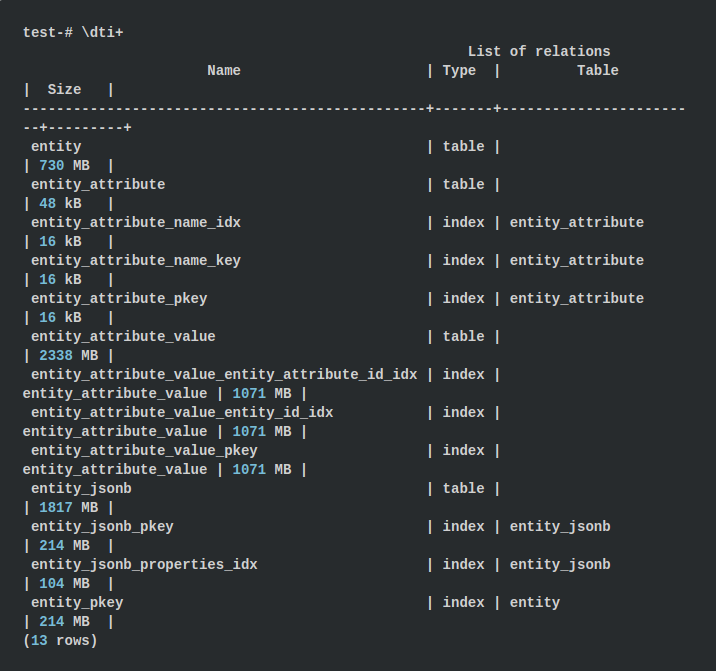
Für den EAV-Ansatz liegen die Tabellengrößen bei etwa 3068 MB und die Indizes bei bis zu 3427 MB, was insgesamt 6,43 GB ergibt. Bei Verwendung des JSONB-Ansatzes werden 1817 MB für die Tabelle und 318 MB für die Indizes verwendet, was 2,08 GB entspricht. Es stellt sich heraus, 3-mal weniger! Diese Tatsache hat mich ein wenig überrascht, da wir in jedem JSONB-Objekt Eigenschaftsnamen speichern.
Trotzdem sprechen die Zahlen für sich: In EAV speichern wir 2 ganzzahlige Fremdschlüssel für den Attributwert, wodurch wir 8 Byte zusätzliche Daten erhalten. Außerdem werden in EAV alle Eigenschaftswerte als Text gespeichert, während in JSONB nach Möglichkeit numerische und logische Werte verwendet werden, was zu einem geringeren Volumen führt.
Zusammenfassung
Im Allgemeinen denke ich, dass das Speichern von Entitätseigenschaften im JSONB-Format das Entwerfen und Verwalten Ihrer Datenbank erheblich vereinfachen kann. Wenn Sie viele Abfragen ausführen, arbeitet alles, was in derselben Tabelle wie die Entität gespeichert ist, effizienter. Und die Tatsache, dass dies die Interaktion zwischen den Daten vereinfacht, ist bereits ein Plus, aber die resultierende Datenbank ist dreimal kleiner im Volumen.
Dem Test zufolge können wir auch den Schluss ziehen, dass der Leistungsverlust sehr gering ist. In einigen Fällen arbeitet JSONB sogar schneller als EAV, was es noch besser macht. Dieser Benchmark deckt jedoch natürlich nicht alle Aspekte ab (z. B. Entitäten mit einer sehr großen Anzahl von Eigenschaften, eine signifikante Erhöhung der Anzahl von Eigenschaften vorhandener Daten, ...). Wenn Sie daher Vorschläge zur Verbesserung haben, wenden Sie sich bitte an uns Fühlen Sie sich frei, einen Kommentar zu hinterlassen!