
Hallo Habr. Kürzlich gab es einen Wettbewerb von Tinkoff und McKinsey. Der Wettbewerb wurde in zwei Etappen ausgetragen: im ersten Qualifying im Kaggle-Format, d.h. Vorhersagen senden - Bewertung der Qualität der Vorhersage; der Gewinner ist der mit der besten Punktzahl. Der zweite ist der Vor-Ort-Hackathon in Moskau, bei dem die Top-20-Teams der ersten Etappe antreten. In diesem Artikel werde ich über die Qualifikationsphase sprechen, in der es mir gelungen ist, den ersten Platz zu belegen und das MacBook zu gewinnen. Das Team auf der Rangliste hieß "Leshas Kinder".
Der Wettbewerb fand vom 19. September bis 12. Oktober statt. Ich habe genau eine Woche vor dem Ende angefangen zu lösen und mich für fast Vollzeit entschieden.
Kurze Beschreibung des Wettbewerbs:
Im Sommer erschienen Geschichten in der Tinkoff-Bankenanwendung (wie auf Instagram). Auf Storys kann man reagieren wie, nicht mögen, überspringen oder bis zum Ende schauen. Die Aufgabe besteht darin, die Reaktion des Benutzers auf die Geschichte vorherzusagen.
Der Wettbewerb ist meist tabellarisch, aber die Geschichten selbst haben Text und Bilder.
Geschichtenplan

Metrisch
Die Reaktionsprognose kann einen Wert von -1 bis einschließlich 1 annehmen. Je näher der Wert an 1 liegt, desto höher ist die Wahrscheinlichkeit, eine Übereinstimmung zu erhalten. Bei einem Wert von -1 ist es besser, diese Geschichte aus den Augen des Benutzers zu entfernen.
Zur Überprüfung der Genauigkeit von Lösungen wird eine Formel verwendet, die auf das maximal mögliche Ergebnis normiert ist:
\ begin {array} {l} {\ text {weight (event)} = \ left \ {\ begin {array} {ll} {- 10} & {\ text {dislike}} \\ {-0.1} & {\ text {skip}} \\ {0.1} & {\ text {view}} \\ {0.5} & {\ text {like}} \ end {array} \ right.} \\ [15pt] {\ text {Metric} \ left (y _ {\ text {pred}} \ right) = \ sum_ {i = 1} ^ {n} \ left (\ text {weight} \ left (\ text {event} _ {i} \ rechts) \ cdot y _ {\ text {pred,} i} \ rechts)} \ end {array}
Welche Daten gibt es:
- Grundlegende Benutzerinformationen
- Benutzertransaktionen
- Informationen zur Geschichte (json, aus der Sie sie konstruieren können)
- Verlauf der Benutzerreaktionen auf Geschichten.
Als Nächstes werde ich detailliert auf die einzelnen Daten eingehen, wie ich sie verarbeitet habe und welche Features (im Folgenden als Features bezeichnet) ich extrahiert habe.

was ist ursprünglich:
- Benutzer-ID
- anonyme Bankprodukte, die der Benutzer geöffnet (OPN), verwendet (UTL) oder geschlossen (CLS) hat
- Geschlecht, binäres Alter, Familienstand, erster Eintritt in die Bewerbung
- job_title - was die Leute über sich schreiben
- job_position_cd - Berufsbezeichnung einer Person in einer von 22 Kategorien
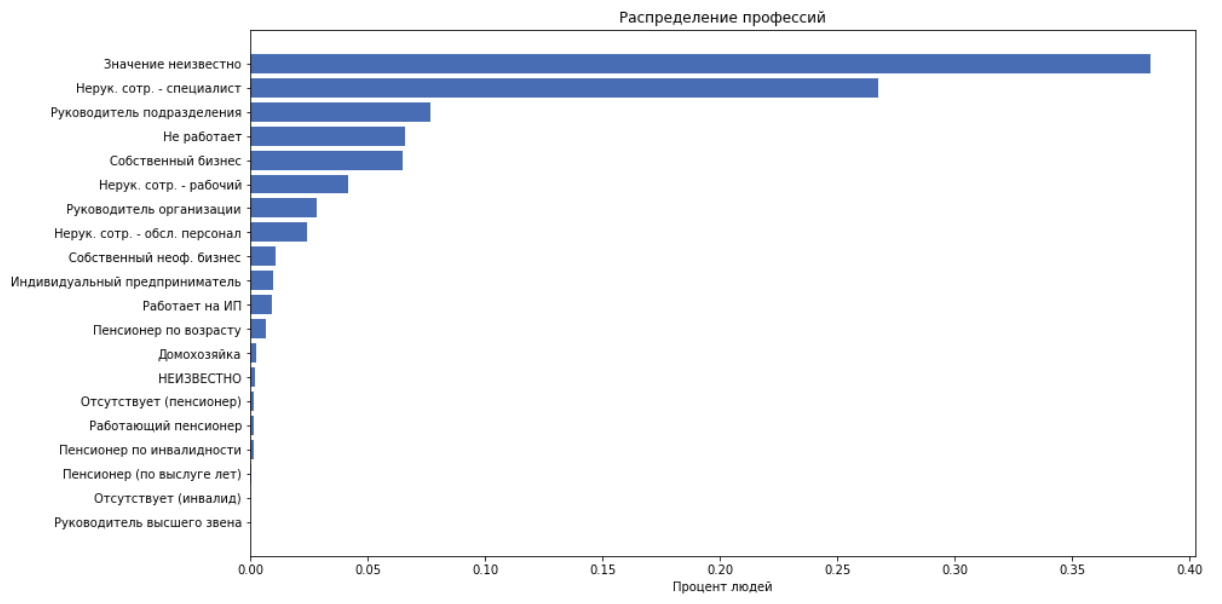
Als Funktionen verwenden wir alle oben genannten Elemente mit Ausnahme von job_title, weil Wir gehen davon aus, dass job_position_cd normalerweise die Position einer Person beschreibt.
Transaktionen

was ist ursprünglich:
- Benutzer-ID
- Tag, Monat der Transaktion
- Transaktionsbetrag (binärisiert in Schritten von 250)
- merchant_id - interne Bankleitzahl der Kasse. Weitere nicht verwendet.
- merchant_mcc
MCC - Händlerkategoriecode. Dies ist der standardisierte Servicecode, den der Empfänger bereitstellt. Diese Information ist offen, hier ist eine Niederschrift . Diese Codes können bequem in Kategorien unterteilt werden, z. B. Unterhaltung, Hotels usw.
Für jede customer_id vergleichen wir die folgenden Funktionen:
- Berechnen Sie die Höhe der Ausgaben, Durchschnittsprüfung, Standardabweichung
- Anzahl der Transaktionen
- Wir teilen mcc-Codes in 20 Kategorien ein und berechnen, wie viele Personen Geld für diese Kategorie ausgegeben haben. Holen Sie sich 20 Funktionen
- Wir erhalten weitere 20 Funktionen, indem wir die Ausgaben in der Kategorie durch die Höhe der Ausgaben dividieren. Das heißt Holen Sie sich den Prozentsatz des Geldes für die Kategorie.
Geschichten
Insgesamt haben wir 959 Geschichten.
was ist ursprünglich:
json sieht so aus:

Dies ist ein solcher Baum von Elementen, bei dem jedes Element durch Schlüssel beschrieben wird: ['guid', 'type', 'description', 'properties', 'content']. Der 'Inhalt' enthält eine Liste von Kindern. Die Geschichte besteht aus Seiten. Der Hintergrund, der Text und die Bilder werden auf die Seite geworfen. Wir hatten keinen Konstruktor für Geschichten, und all dies zu zeichnen ist ziemlich schwierig und keine Tatsache, die in Zukunft sehr hilfreich sein wird.
Stammgäste ziehen den gesamten Text und die entsprechende Schriftgröße heraus. Wir extrahieren die folgenden Funktionen:
- Anzahl der Seiten, Links, Gesamtzahl der Elemente
- durchschnittliche Textschriftgröße
- Anzahl der Textelemente
- "text volume" ist eine Heuristik, bei der die Länge des Texts in Abhängigkeit von der Schriftgröße sorgfältig berücksichtigt wird.
Volumenzählcodedef get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- Nehmen wir nun den gesamten Text und definieren mit Dostojewski die Semantik des Textes: ['neutral', 'negativ', 'überspringen', 'sprechen', 'positiv']. Und füge dies als 5 Merkmale hinzu
Reaktionen

was ist ursprünglich:
- Benutzer-ID und Verlauf
- die Zeit
- Reaktion
Wir verarbeiten die Zeit und fügen Features als Features hinzu:
Als nächstes wird eine Gruppe von Features basierend auf den Daten zu den Reaktionen hinzugefügt, aber jetzt werden wir mit diesem Arsenal von Features kämpfen, um eine Grundlinie zu bilden.
Der beste Ansatz, den das gesamte Top verwendet hat, ist der folgende: Wir reduzieren das Problem auf eine Klassifikation mit mehreren Klassen, d.h. prognostizieren Sie die Wahrscheinlichkeit jeder Reaktion. Wir betrachten die Erwartung einer Beurteilung für diese Geschichte :
Binarisieren :
- unsere Antwort für das Objekt was Wert annehmen kann
Modell
Von Anfang bis Ende habe ich CatBoost verwendet. Dies liegt an der Tatsache, dass CatBoost sofort nützliche Statistiken für kategoriale Features erstellt. Und Statistiken über den Benutzer - wie sehr er zu welchen Reaktionen neigt, und Statistiken über den Verlauf - wie häufig sie nicht reagieren, sind die mächtigsten Merkmale dieser Aufgabe.
Wie CatBoost mit kategorialen Funktionen arbeitet, wird in der Dokumentation ausführlich erläutert.
TLDR:
- generiert mehrere Datenpermutationen
- Geht in Ordnung und erstellt eine mittlere Zielcodierung (MTE) für die Objekte, die er bereits gesehen hat
kurz zu mte in unserem beispielNehmen wir den Wert des Zeichens, zum Beispiel eines von customer_id, betrachten wir den Prozentsatz der Fälle, in denen dieser Kunde reagiert, nicht mag, übersprungen oder angesehen hat. Wir bekommen 4 Zahlen. Wir ersetzen customer_id durch diese 4 Nummern und verwenden sie als Zeichen. Wir machen das für jede customer_id.
Aktuelles Ergebnis
Mit aktuellen Features und einem nicht optimierten Catbust belegte ich damals in der öffentlichen Bestenliste den 11. Platz mit einem Ergebnis von 0,31209
Killerfeatures
Irgendwann tauchte die Hypothese auf, dass die Anwendung je nachdem, wie der Benutzer früher darauf reagiert hat, möglicherweise mehr oder weniger häufig Storys anzeigt. Fügen wir dann Funktionen hinzu, die Folgendes enthalten:
- Wie oft hat der Benutzer den entsprechenden Verlauf in der Vergangenheit / Zukunft während des Monats / Tages / der Stunde / der Summe gesehen?
- Zeit seit dem letzten Anschauen der gleichen Geschichte
- Zeit, nach der der Benutzer das nächste Mal die gleiche Geschichte ansieht
- Tatsächlich lädt der Benutzer mehrere Storys gleichzeitig in einer Sekunde, normalerweise um 5-7. Nennen Sie diese Gruppe von Geschichten eine Gruppe . Ich habe diese Anzahl von Geschichten als Feature in die Gruppe aufgenommen, was zu einer deutlichen Qualitätssteigerung geführt hat.
Natürlich können diese Funktionen in der Produktion nicht verwendet werden, weil Sie werden zum Zeitpunkt der Anwendung des Modells nicht kitschig sein, aber im Wettbewerb sind alle Mittel gut.
So ist es gesagt - getan. Habe 0.35657 auf der Bestenliste.
Modelloptimierung
Ich habe die Parameter mit der Bayes'schen Optimierung durchgearbeitet
Von den interessanten können wir den Parameter max_ctr_complexity erwähnen, der für die maximale Anzahl von kategorialen Features verantwortlich ist, die kombiniert werden können. Beispiel unter dem Spoiler.
Auszug aus der DokumentationAngenommen, die Objekte im Trainingsset gehören zu zwei kategorialen Merkmalen: dem Musikgenre ("Rock", "Indie") und dem Musikstil ("Tanz", "Klassik"). Diese Merkmale können in verschiedenen Kombinationen auftreten. CatBoost kann eine neue Funktion erstellen, die aus einer Kombination der aufgeführten Funktionen besteht ("Dance Rock", "Classic Rock", "Dance Indie" oder "Indie Classic").
Interessante Beobachtungen
CatBoost kann auf der GPU trainiert werden, was das Lernen erheblich beschleunigt, aber auch viele Einschränkungen mit sich bringt, insbesondere in Bezug auf kategoriale Funktionen. Bei dieser Aufgabe ergab das Training auf der GPU ein viel schlechteres Ergebnis als auf der CPU.
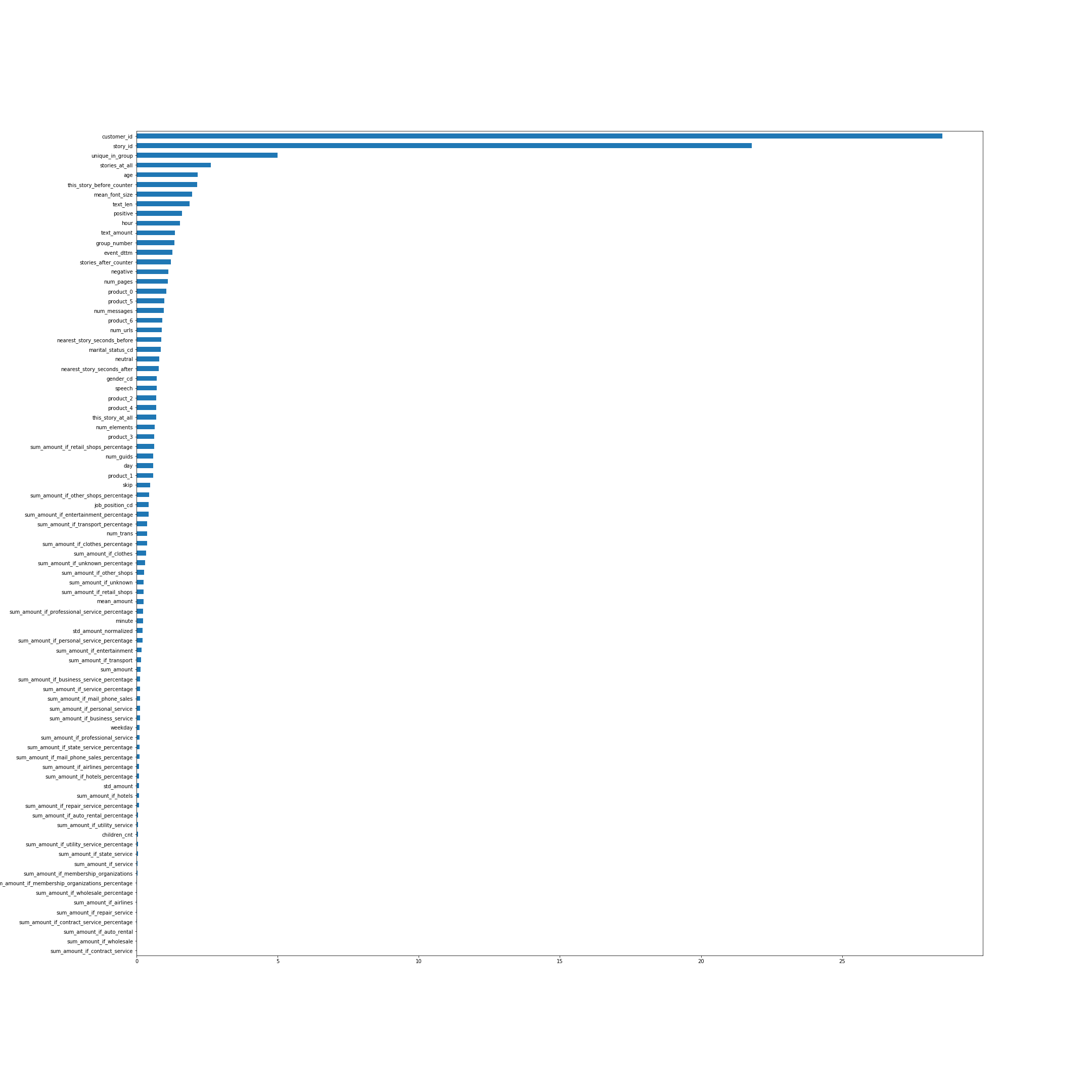
Die Bedeutung von Funktionen nach CatBoost. In vielerlei Hinsicht sprechen die Namen der Features für sich selbst, aber einige, nicht die offensichtlichsten von oben, erkläre ich:
- unique_in_group - Die Anzahl der Storys in der Gruppe. (Innerhalb der Gruppe sind sie immer einzigartig. Zum Zeitpunkt der Erstellung des Features wusste ich das noch nicht.)
- stories_at_all - Die Anzahl der Geschichten, die eine Person in der Zukunft und in der Vergangenheit angesehen hat.
- this_story_before_counter - wie oft haben die Leute diese Geschichte schon gesehen.
- text_amount - diese Heuristik mit dem Textvolumen.
- group_number - Seriennummer der Gruppe.
- next_story_seconds_before / after - im Wesentlichen ist dies die Zeit, bis die nächste Gruppe angezeigt wird.
Das Bild ist anklickbar.
Schauen wir uns die Verteilung der Reaktionen über die Zeit an:

Das heißt Irgendwann ist die Verteilung der Reaktionen sehr unterschiedlich.
Als nächstes möchte ich eine Bestätigung erhalten, dass die Verteilung des Tests mit der am Ende des Trainingsbeispiels übereinstimmt. Senden wir alle als Vorhersage, erhalten wir das Ergebnis 0.00237. Wir prognostizieren alle im letzten Teil des Zuges - wir bekommen ungefähr 0,009, im ersten Teil - ungefähr -0,22. Die Verteilung im Test ist also höchstwahrscheinlich die gleiche wie am Ende des Zuges und sieht definitiv nicht wie der Hauptteil aus. Dies lässt die Hypothese aufkommen, dass, wenn die Verteilung korrigiert wird In unseren Prognosen wird sich das Ergebnis in der Rangliste erheblich verbessern, weil Die Verteilungen im Zug und im Test sind unterschiedlich.
Schwellenwertvorhersagen
Fügen Sie im letzten Schritt zum Abrufen der endgültigen Vorhersagen einen Thrashhold hinzu:
Im letzten Modell hatte ich ungefähr 66% der Einheiten, wenn sie mit einem Papierkorb von 0 digitalisiert wurden. Es stellte sich heraus, dass ein Rückgang der Anzahl von +1 tatsächlich zu einer starken Qualitätssteigerung führte. Es wurden nur die letzten drei Prämissen ausgewertet, und ich habe die Vorhersagen des besten Modells mit verschiedenen Mülleimern gesendet, sodass der Prozentsatz plus eins etwa 62, 58 und 54 betrug.
In einer öffentlichen Rangliste war mein bestes Ergebnis 0,37970 .
Wettbewerbsergebnisse
über öffentliche / private BestenlisteWie bei Wettbewerben für maschinelles Lernen üblich, wird beim Senden von Vorhersagen an das System das Ergebnis nur für einen Teil der gesamten Teststichprobe ausgewertet. Normalerweise ungefähr 30%. Die Ergebnisse für diesen Teil spiegeln sich in der öffentlichen Bestenliste wider. Für den Rest des Tests wird das Endergebnis ausgewertet, das nach dem Ende des Wettbewerbs auf einer privaten Rangliste angezeigt wird.
Am Ende des Wettbewerbs in der öffentlichen Bestenliste war die Situation wie folgt:
- 0,382 - Hier könnte Ihre Werbung sein
- 0.379 - Leshas Kinder
- 0.372 - Gärtner
- 0,35 - faul & akulov
Auf einer privaten Rangliste, in der die Endergebnisse berücksichtigt wurden, hatte ich Glück und die Jungs fielen aus irgendeinem Grund vom vierten auf den vierten Platz. Hier ist die endgültige Position.
- 0,45807 Kinder von Lesha
- 0,45264 Gärtner
- 0,44136 Zhuk
- 0,43704 Hier könnte Ihre Werbung sein
- 0,43474 faul & akulov
Was hat nicht funktioniert
- Ich habe versucht, den gesamten Text der Story mit FastText in einen Vektor zu übersetzen, dann die Vektoren geclustert und die Clusternummer als kategorisches Merkmal verwendet. Dieses Feature war (nach story_id und customer_id) in CatBoosts Feature-Wichtigkeit die Top 3, aber aus irgendeinem Grund war es stabil und verschlechterte das Ergebnis der Validierung erheblich.
- Dank der Cluster konnte man Geschichten finden, die sich auf die Weltmeisterschaft bezogen und nur im Trainingsset vorhanden waren.
Das Auswerfen solcher Objekte aus dem Datensatz hat das Ergebnis jedoch nicht verbessert. - Standardmäßig generiert CatBoost zufällige Permutationen von Objekten und berücksichtigt darauf basierende Zeichen für kategoriale Features. Aber wir können zum katbust sagen, dass wir Zeit in den Daten haben - has_time = True. Dann wird es in Ordnung gehen, ohne den Datensatz zu mischen. In diesem Problem war das Ergebnis mit has_time trotz der Tatsache, dass wir Zeit haben, stabil schlechter.
Im Allgemeinen verwendet das Modell Informationen zu den richtigen Antworten aus der Zukunft, wenn Zeit vorhanden ist, diese jedoch bei der Erstellung der mittleren Zielkodierung nicht berücksichtigt werden sollte, und kann sie dann nachbilden. Bei diesem Problem hatte dies anscheinend keine großen Auswirkungen, und es war wichtiger, mehrmals in verschiedenen Permutationen vorzugehen. - Es gab die Idee, Objekten am Ende des Zuges mehr Gewicht zuzuweisen, d. H. mehr Objekte mit der richtigen Verteilung der Reaktionen zu berücksichtigen. Sowohl bei der Validierung als auch in der öffentlichen Rangliste ergab sich ein schlechteres Ergebnis.
- Sie können beim Training unterschiedliche Reaktionen mit unterschiedlichen Gewichten berücksichtigen. Obwohl sich das für mich nicht verbessert hat, hat es einigen Teams geholfen.
Schlussfolgerungen
Der Wettbewerb erwies sich als interessant, da er viele Komponenten wie Tabellendaten, Texte und Bilder zusammenbrachte. Es gab viel Platz für Recherchen, viel, mit dem man noch experimentieren konnte. Im Allgemeinen musste ich mich nicht langweilen.
Vielen Dank an die Organisatoren des Wettbewerbs!
Der gesamte Code ist auf dem Github veröffentlicht .