Redash hat vor kurzem begonnen, von einem Task-Ausführungssystem auf ein anderes zu wechseln. Sie begannen nämlich den Übergang von Sellerie zu RQ. In der ersten Phase wurden nur diejenigen Aufgaben auf die neue Plattform übertragen, die keine direkten Anforderungen erfüllen. Zu diesen Aufgaben gehören das Senden von E-Mails, das Ermitteln der zu aktualisierenden Anforderungen, das Aufzeichnen von Benutzerereignissen und andere unterstützende Aufgaben.

Nach der Bereitstellung all dessen wurde festgestellt, dass RQ-Mitarbeiter viel mehr Computerressourcen benötigen, um das gleiche Aufgabevolumen zu lösen, das Sellerie zur Lösung verwendete.
Das Material, dessen Übersetzung wir heute veröffentlichen, ist der Geschichte gewidmet, wie Redash die Ursache des Problems herausgefunden und damit umgegangen hat.
Ein paar Worte zu den Unterschieden zwischen Sellerie und RQ
Sellerie und RQ haben das Konzept der Prozessarbeiter. Sowohl dort als auch dort für die Organisation der parallelen Ausführung von Aufgaben mit der Erstellung von Gabeln. Beim Start des Sellerie-Workers werden mehrere Verzweigungsprozesse erstellt, von denen jeder Aufgaben autonom verarbeitet. Im Fall von RQ enthält die Instanz des Workers nur einen Unterprozess (als "Arbeitspferd" bezeichnet), der eine Aufgabe ausführt, und wird dann zerstört. Wenn der Arbeiter die nächste Aufgabe aus der Warteschlange herunterlädt, erstellt er ein neues "Arbeitstier".
Wenn Sie mit RQ arbeiten, können Sie den gleichen Grad an Parallelität wie bei der Arbeit mit Sellerie erzielen, indem Sie einfach mehr Arbeitsprozesse ausführen. Es gibt jedoch einen subtilen Unterschied zwischen Sellerie und RQ. In Sellerie erstellt ein Worker beim Start viele Instanzen von Unterprozessen und verwendet diese dann wiederholt, um viele Aufgaben auszuführen. Und im Fall von RQ müssen Sie für jeden Job eine neue Gabel erstellen. Beide Ansätze haben ihre Vor- und Nachteile, aber darüber werden wir hier nicht sprechen.
Leistungsmessung
Bevor ich mit der Profilerstellung begann, entschied ich mich, die Systemleistung zu messen, indem ich herausfand, wie lange der Worker-Container für die Verarbeitung von 1000 Jobs benötigt. Ich habe beschlossen, mich auf die Aufgabe
record_event zu konzentrieren, da dies eine häufige leichte Operation ist. Um die Leistung zu messen, habe ich den Befehl
time . Dies erforderte einige Änderungen am Projektcode:
- Um die Leistung von 1000 Tasks zu messen, entschied ich mich für den RQ-Batch-Modus, in dem der Prozess nach der Verarbeitung der Tasks beendet wird.
- Ich wollte vermeiden, meine Messungen mit anderen Aufgaben zu beeinflussen, die für die Zeit geplant waren, in der ich die Systemleistung gemessen habe. Also habe ich
record_event in eine separate Warteschlange namens benchmark @job('default') und @job('default') durch @job('benchmark') . Dies wurde unmittelbar vor der record_event in tasks/general.py .
Jetzt konnten Messungen gestartet werden. Zunächst wollte ich wissen, wie lange es dauert, einen Arbeiter ohne Last zu starten und anzuhalten. Diese Zeit kann von den später erhaltenen Endergebnissen abgezogen werden.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
Die Initialisierung des Workers auf meinem Computer dauerte 14,7 Sekunden. Ich erinnere mich daran.
Dann habe ich 1000
record_event -
record_event in die
benchmark Warteschlange gestellt:
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
Danach habe ich das System auf die gleiche Weise wie zuvor gestartet und herausgefunden, wie lange es dauert, bis 1000 Jobs verarbeitet sind.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
Wenn ich 14,7 Sekunden von dem, was passiert ist, abziehe, habe ich herausgefunden, dass 4 Arbeiter 1000 Aufgaben in 102 Sekunden bearbeiten. Versuchen wir nun herauszufinden, warum dies so ist. Dazu werden wir, während die Arbeiter beschäftigt sind, sie mit
py-spy .
Profiling
Wir fügen der Warteschlange weitere 1.000 Aufgaben hinzu (dies muss aufgrund der Tatsache geschehen, dass während der vorherigen Messungen alle Aufgaben verarbeitet wurden), führen die Arbeiter aus und spionieren sie aus.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
Ich weiß, dass die vorherige Mannschaft sehr lang war. Um die Lesbarkeit zu verbessern, empfiehlt es sich, das Dokument in einzelne Fragmente zu zerlegen und an den Stellen zu unterteilen, an denen Sequenzen von
&& Zeichen vorkommen. Die Befehle müssen jedoch nacheinander in derselben
docker-compose exec worker bash Sitzung ausgeführt werden, damit alles so aussieht. Hier finden Sie eine Beschreibung der Funktionen dieses Befehls:
- Startet 4 Batchworker im Hintergrund.
- Es wartet 15 Sekunden (ungefähr so viel wird benötigt, um den Download abzuschließen).
- Installiert
py-spy . rq-info und findet die PID eines der Worker heraus.profile.svg für 10 Sekunden Informationen über die Arbeit des Mitarbeiters mit der zuvor empfangenen PID auf und speichert die Daten in der Datei profile.svg
Als Ergebnis wurde der folgende "feurige Zeitplan" erhalten.
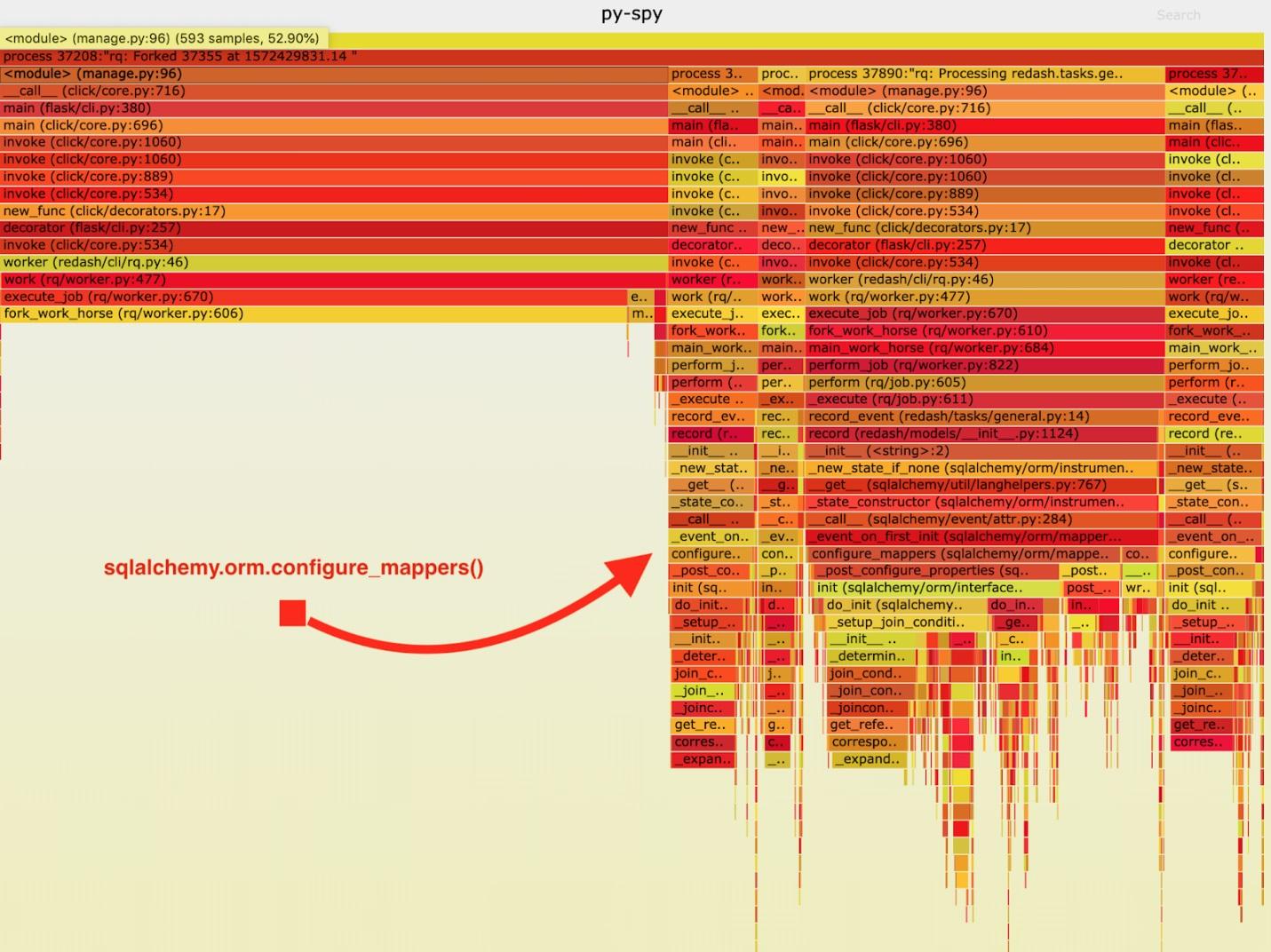 Visualisierung der von py-spy gesammelten Daten
Visualisierung der von py-spy gesammelten DatenNach der Analyse dieser Daten habe ich festgestellt, dass der Task
record_event sehr lange in
sqlalchemy.orm.configure_mappers . Dies geschieht bei jeder Aufgabe. Aus der Dokumentation habe ich gelernt, dass zu dem Zeitpunkt, der mich interessiert, die Beziehungen aller zuvor erstellten Mapper initialisiert werden.
Solche Dinge müssen nicht bei jeder Gabel passieren. Wir können die Beziehung einmal im übergeordneten Mitarbeiter initialisieren und vermeiden, diese Aufgabe in den "Arbeitspferden" zu wiederholen.
Daher habe ich dem Code einen Aufruf von
sqlalchemy.org.configure_mappers() hinzugefügt,
sqlalchemy.org.configure_mappers() ich das „Arbeitspferd“
sqlalchemy.org.configure_mappers() und erneut Messungen durchgeführt habe.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
Wenn Sie von diesen Ergebnissen 14,7 Sekunden abziehen, haben wir die Zeit, die 4 Mitarbeiter für die Verarbeitung von 1000 Aufgaben benötigen, von 102 Sekunden auf 24,6 Sekunden verkürzt. Dies ist eine vierfache Leistungssteigerung! Dank dieses Fixes konnten wir die RQ-Produktionsressourcen vervierfachen und die gleiche Systembandbreite beibehalten.
Zusammenfassung
Aus all dem habe ich die folgende Schlussfolgerung gezogen: Es ist erwähnenswert, dass sich die Anwendung anders verhält, wenn es sich um den einzigen Prozess handelt und wenn es sich um Gabeln handelt. Wenn es bei jeder Aufgabe erforderlich ist, einige schwierige offizielle Aufgaben zu lösen, ist es besser, sie rechtzeitig zu erledigen, nachdem dies einmal vor Fertigstellung der Gabel getan wurde. Solche Dinge werden während des Testens und Entwickelns nicht erkannt. Nachdem Sie das Gefühl haben, dass etwas mit dem Projekt nicht stimmt, messen Sie die Geschwindigkeit und gehen Sie zum Ende, während Sie nach den Ursachen für Probleme mit der Leistung suchen.
Sehr geehrte Leser! Haben Sie in Python-Projekten Leistungsprobleme festgestellt, die Sie durch eine sorgfältige Analyse eines funktionierenden Systems lösen könnten?
