
Hallo Khabrovchans! Wir machen Sie weiterhin mit dem russischen hyperkonvergenten System AERODISK vAIR vertraut. Dieser Artikel befasst sich mit der Architektur dieses Systems. Im letzten Artikel haben wir unser ARDFS-Dateisystem analysiert, und in diesem Artikel werden wir alle wichtigen Softwarekomponenten, aus denen vAIR besteht, und ihre Aufgaben behandeln.
Wir beginnen die Beschreibung der Architektur von Grund auf - vom Speicher bis zur Verwaltung.
ARDFS + Raft Cluster Driver-Dateisystem
Die Basis von vAIR ist das verteilte Dateisystem ARDFS, das die lokalen Festplatten aller Clusterknoten zu einem einzigen logischen Pool zusammenfasst, auf dessen Grundlage virtuelle Festplatten mit dem einen oder anderen Fehlertoleranzschema (Replikationsfaktor oder Löschcodierung) aus virtuellen 4-MB-Blöcken gebildet werden. Eine detailliertere Beschreibung der Arbeit von ARDFS finden Sie im vorherigen Artikel.
Raft Cluster Driver ist ein interner ARDFS-Dienst, der das Problem der verteilten und zuverlässigen Speicherung von Dateisystem-Metadaten löst.
ARDFS-Metadaten werden herkömmlicherweise in zwei Klassen unterteilt.
- Benachrichtigungen - Informationen über Operationen mit Speicherobjekten und Informationen über die Objekte selbst;
- Serviceinformationen - Festlegen von Sperren und Konfigurationsinformationen für Speicherknoten.
Der RCD-Dienst wird zum Verteilen dieser Daten verwendet. Es weist automatisch einen Knoten mit der Rolle eines Leiters zu, dessen Aufgabe es ist, Metadaten zu erhalten und über die Knoten zu verbreiten. Ein Führer ist die einzig wahre Quelle dieser Information. Zusätzlich organisiert der Anführer einen Herzschlag, d.h. prüft die Verfügbarkeit aller Speicherknoten (dies hat nichts mit der Verfügbarkeit virtueller Maschinen zu tun, RCD ist nur ein Dienst für die Speicherung).
Wenn der Anführer aus irgendeinem Grund länger als eine Sekunde für einen der normalen Knoten nicht verfügbar ist, organisiert dieser normale Knoten eine Wiederwahl des Anführers und fordert die Verfügbarkeit des Anführers von anderen normalen Knoten an. Bei Beschlussfähigkeit wird der Vorsitzende wiedergewählt. Nachdem der frühere Anführer "aufgewacht" ist, wird er automatisch zu einem gewöhnlichen Knoten, weil der neue Anführer schickt ihm das entsprechende Team.
Die Logik des GGM selbst ist nicht neu. Viele kommerzielle und kostenlose Lösungen von Drittanbietern lassen sich ebenfalls von dieser Logik leiten, aber diese Lösungen passten nicht zu uns (wie das vorhandene Open-Source-FS), da sie ziemlich schwer sind und es sehr schwierig ist, sie für unsere einfachen Aufgaben zu optimieren. Deshalb haben wir nur unsere eigenen geschrieben RCD-Service.
Es mag den Anschein haben, als sei der Anführer ein "schmaler Hals", der die Arbeit in großen Clustern um Hunderte von Knoten verlangsamen kann, aber das ist nicht der Fall. Der beschriebene Prozess läuft fast sofort ab und „wiegt“ sehr wenig, da wir ihn selbst geschrieben haben und nur die wichtigsten Funktionen enthalten. Außerdem geschieht dies vollautomatisch und es verbleiben nur Nachrichten in den Protokollen.
MasterIO - Multithread-E / A-Verwaltungsdienst
Sobald ein ARDFS-Pool mit virtuellen Laufwerken organisiert ist, kann er für E / A verwendet werden. An dieser Stelle stellt sich speziell für hyperkonvergierte Systeme die Frage, wie viel Systemressourcen (CPU / RAM) wir für IO spenden können.
In klassischen Speichersystemen ist diese Frage nicht so akut, da die Speicheraufgabe nur darin besteht, Daten zu speichern (und die meisten Systemspeicherressourcen können sicher unter E / A bereitgestellt werden), und Hyperkonvergenzaufgaben umfassen neben Speicher auch die Ausführung virtueller Maschinen. Dementsprechend erfordert das GCS die Verwendung von CPU- und RAM-Ressourcen hauptsächlich für virtuelle Maschinen. Was ist mit I / O?
Um dieses Problem zu lösen, verwendet vAIR den E / A-Verwaltungsdienst: MasterIO. Die Aufgabe des Dienstes ist einfach - "Nimm alles und teile" Es wird garantiert, dass es die n-te Anzahl von Systemressourcen für die Eingabe und Ausgabe aufnimmt und ausgehend von diesen die n-te Anzahl von Eingabe- / Ausgabeströmen startet.
Zunächst wollten wir einen „sehr intelligenten“ Mechanismus für die Zuweisung von Ressourcen für E / A bereitstellen. Wenn der Speicher beispielsweise nicht ausgelastet ist, können Systemressourcen für virtuelle Maschinen verwendet werden. Wenn die Auslastung auftritt, werden diese Ressourcen innerhalb vorgegebener Grenzen „sanft“ von den virtuellen Maschinen entfernt. Dieser Versuch scheiterte jedoch teilweise. Tests haben gezeigt, dass, wenn die Last schrittweise erhöht wird, alles in Ordnung ist und Ressourcen (die für ein mögliches Entfernen markiert sind) zugunsten von E / A schrittweise aus der VM entnommen werden. Starke Speicherlasten führen jedoch zu einem weniger „sanften“ Entzug von Ressourcen aus virtuellen Maschinen. Infolgedessen häufen sich Warteschlangen auf den Prozessoren und führen zu und die Wölfe sind hungrig und die Schafe sind tot und virtualka hängen, und es gibt keine IOPS.
Vielleicht werden wir in Zukunft auf dieses Problem zurückkommen, aber vorerst haben wir die Ausgabe von Ressourcen für IO in den Händen des guten alten Großvaters implementiert.
Basierend auf den Auslegungsdaten weist der Administrator die n-te Anzahl von CPU-Kernen und RAM für den MasterIO-Dienst vorab zu. Diesen Ressourcen wird ein Monopol zugewiesen, d. H. Sie können in keiner Weise für die Anforderungen der VM verwendet werden, bis der Administrator dies zulässt. Die Ressourcen werden gleichmäßig verteilt, d. H. Jedem Knoten des Clusters wird die gleiche Menge an Systemressourcen entnommen. Zuallererst sind Prozessorressourcen für MasterIO von Interesse (RAM ist weniger wichtig), insbesondere wenn wir Erasure-Codierung verwenden.
Wenn bei der Dimensionierung ein Fehler aufgetreten ist und MasterIO zu viele Ressourcen zugewiesen wurden, kann die Situation einfach behoben werden, indem diese Ressourcen wieder in den VM-Ressourcenpool verschoben werden. Wenn sich die Ressourcen im Leerlauf befinden, kehren sie fast sofort in den VM-Ressourcenpool zurück. Wenn diese Ressourcen jedoch gelöscht werden, müssen Sie eine Weile warten, bis MasterIO sie im Hintergrund freigibt.
Die umgekehrte Situation ist komplizierter. Wenn wir die Anzahl der Kerne für MasterIO erhöhen müssen und diese mit virtuellen Kernen beschäftigt sind, müssen wir mit virtuellen Kernen "verhandeln", dh sie mit Handles auswählen, da dieser Vorgang im automatischen Modus in einer Situation mit starker Lastschwankung mit VM-Einfrierungen und anderem launischem Verhalten behaftet ist.
Dementsprechend muss der Dimensionierung der Leistung hyperkonvergierter IO-Systeme (nicht nur unserer) große Aufmerksamkeit gewidmet werden. Wenig später in einem der Artikel versprechen wir, dieses Problem ausführlicher zu behandeln.
Hypervisor
Hypervisor Aist ist für die Ausführung virtueller Maschinen in vAIR verantwortlich. Dieser Hypervisor basiert auf dem bewährten KVM-Hypervisor. Im Prinzip wurde eine ganze Menge über die Arbeit von KVM geschrieben, sodass es nicht erforderlich ist, diese zu malen. Zeigen Sie lediglich an, dass alle Standardfunktionen von KVM in Stork gespeichert sind und einwandfrei funktionieren.
Daher werden wir hier die Hauptunterschiede zu dem Standard-KVM beschreiben, den wir in Stork implementiert haben. Der Storch ist Teil des Systems (vorinstallierter Hypervisor) und wird von der gemeinsamen vAIR-Konsole über die Web-GUI (russische und englische Version) und SSH (natürlich nur Englisch) gesteuert.
Darüber hinaus werden die Hypervisor-Konfigurationen in der verteilten ConfigDB-Datenbank gespeichert (etwa etwas später), die auch eine zentrale Kontrollstelle darstellt. Das heißt, Sie können eine Verbindung zu einem beliebigen Knoten im Cluster herstellen und alle Knoten verwalten, ohne dass ein separater Verwaltungsserver erforderlich ist.
Eine wichtige Ergänzung zur Standard-KVM-Funktionalität ist das von uns entwickelte HA-Modul. Dies ist die einfachste Implementierung eines Clusters hochverfügbarer virtueller Maschinen, mit der Sie die virtuelle Maschine bei einem Knotenausfall automatisch auf einem anderen Clusterknoten neu starten können.
Ein weiteres nützliches Feature ist die Massenbereitstellung von virtuellen Maschinen (relevant für VDI-Umgebungen), mit der die Bereitstellung von virtuellen Maschinen mit ihrer automatischen Verteilung auf die Knoten in Abhängigkeit von deren Auslastung automatisiert wird.
Die VM-Verteilung zwischen Knoten ist die Basis für den automatischen Lastausgleich (ala DRS). Diese Funktion ist in der aktuellen Version noch nicht verfügbar, wir arbeiten jedoch aktiv daran und sie wird definitiv in einem der nächsten Updates erscheinen.
Der VMware ESXi-Hypervisor wird optional unterstützt. Derzeit wird er mit dem iSCSI-Protokoll implementiert. Eine NFS-Unterstützung ist auch für die Zukunft geplant.
Virtuelle Schalter
Für die Software-Implementierung der Schalter ist eine separate Komponente vorgesehen - Fractal. Wie bei unseren anderen Komponenten gehen wir von einfach zu komplex über. In der ersten Version wird einfaches Switching implementiert, während Routing und Firewall an Geräte von Drittanbietern übertragen werden. Das Funktionsprinzip ist Standard. Die physische Schnittstelle des Servers ist über eine Brücke mit dem Fractal-Objekt verbunden - einer Gruppe von Ports. Eine Gruppe von Ports mit den gewünschten virtuellen Maschinen im Cluster. Die Organisation von VLANs wird unterstützt und in einem der nächsten Releases wird die VxLAN-Unterstützung hinzugefügt. Alle erstellten Switches werden standardmäßig verteilt, d. H. Über alle Knoten des Clusters verteilt. Welche virtuellen Maschinen zu welchen Switches eine Verbindung zur VM herstellen, hängt also nicht vom Standortknoten ab. Dies ist ausschließlich Sache des Administrators.
Überwachung und Statistik
Die für die Überwachung und Statistik verantwortliche Komponente (Arbeitstitel Monica) ist ein überarbeiteter Klon aus dem ENGINE-Speichersystem. Einmal hat er sich gut empfohlen, und wir haben beschlossen, es mit vAIR mit einfacher Abstimmung zu verwenden. Monica wird wie alle anderen Komponenten gleichzeitig auf allen Knoten des Clusters ausgeführt und gespeichert.
Monicas schwierige Aufgaben können wie folgt umrissen werden:
Datenerfassung:
- von Hardware-Sensoren (die Eisen über IPMI geben können);
- aus logischen vAIR-Objekten (ARDFS, Stork, Fractal, MasterIO und anderen Objekten).
Sammeln von Daten in einer verteilten Datenbank;
Interpretation von Daten in Form von:
- Protokolle;
- Warnungen
- Zeitpläne.
Externe Interaktion mit Systemen von Drittanbietern über die Protokolle SMTP (Senden von E-Mail-Warnungen) und SNMP (Interaktion mit Überwachungssystemen von Drittanbietern).
Verteilte Konfigurationsbasis
In den vorherigen Absätzen wurde erwähnt, dass viele Daten gleichzeitig auf allen Knoten des Clusters gespeichert werden. Um diese Speichermethode zu organisieren, wird eine spezielle verteilte ConfigDB-Datenbank bereitgestellt. Wie der Name schon sagt, werden in der Datenbank die Konfigurationen aller Clusterobjekte gespeichert: Hypervisor, virtuelle Maschinen, HA-Modul, Switches, Dateisystem (nicht zu verwechseln mit der FS-Metadaten-Datenbank, dies ist eine andere Datenbank) sowie Statistiken. Diese Daten werden synchron auf allen Knoten gespeichert und die Konsistenz dieser Daten ist eine Voraussetzung für den stabilen Betrieb von vAIR.
Ein wichtiger Punkt: Obwohl die Funktionsweise von ConfigDB für den vAIR-Betrieb von entscheidender Bedeutung ist, wirkt sich ihr Ausfall, obwohl er den Cluster stoppt, nicht auf die Konsistenz der in ARDFS gespeicherten Daten aus, was unserer Meinung nach ein Plus für die Zuverlässigkeit der gesamten Lösung darstellt.
ConfigDB ist auch ein einziger Verwaltungspunkt. Sie können also nach IP-Adresse zu jedem Knoten des Clusters wechseln und alle Knoten des Clusters vollständig verwalten, was sehr praktisch ist.
Darüber hinaus bietet ConfigDB für den Zugriff auf externe Systeme eine Restful-API, über die Sie die Integration in Systeme von Drittanbietern konfigurieren können. Beispielsweise haben wir kürzlich eine Pilotintegration mit mehreren russischen Lösungen in den Bereichen VDI und Informationssicherheit durchgeführt. Wenn die Projekte abgeschlossen sind, schreiben wir hier gerne technische Details.
Das ganze Bild
Als Ergebnis haben wir zwei Versionen der Systemarchitektur.
Im ersten - Hauptfall - werden unsere KVM-basierten Aist-Hypervisor- und Fractal-Software-Switches verwendet.
Szenario 1. Richtig
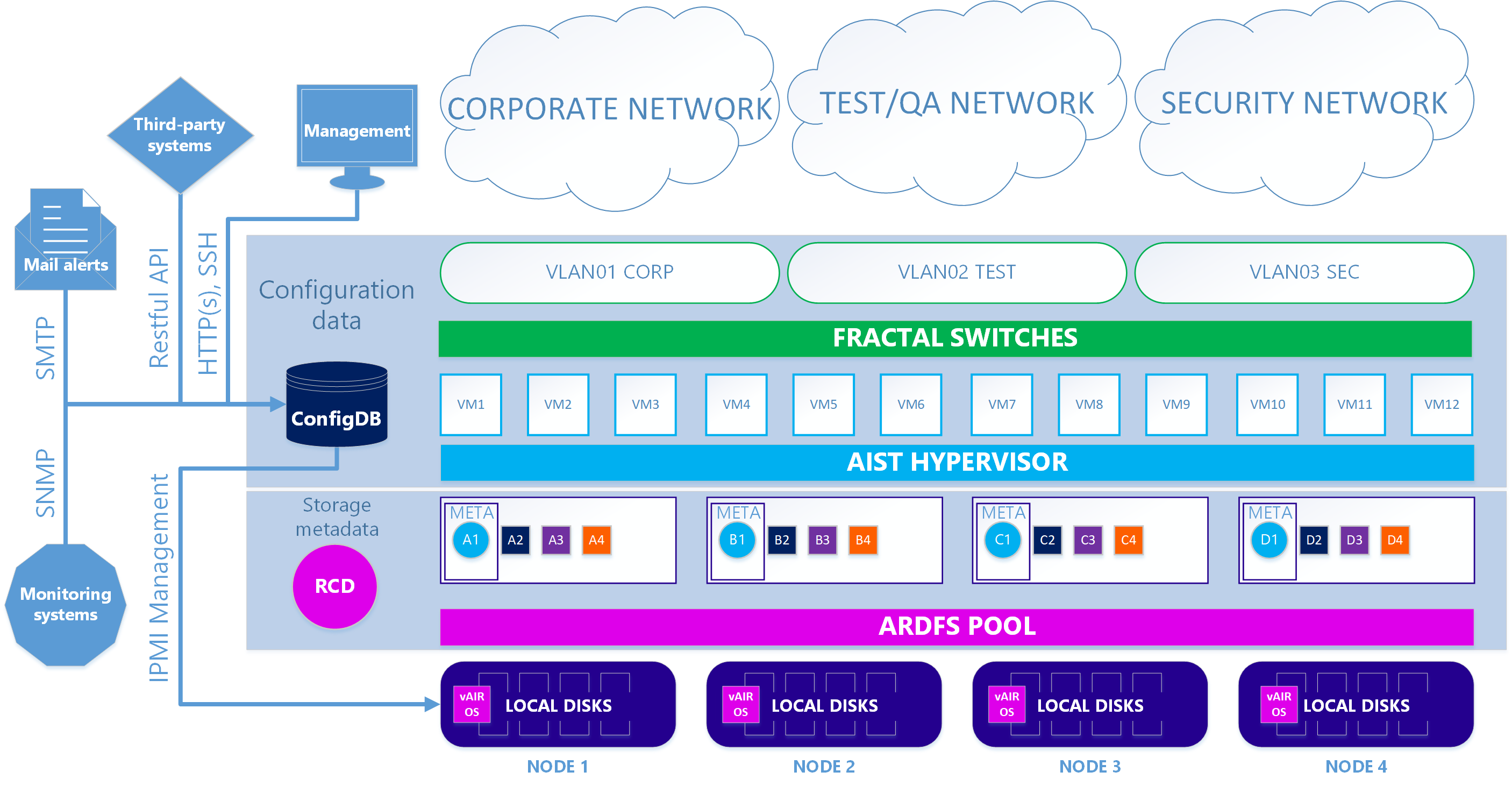
Bei der zweiten - optionalen Option - ist das Schema etwas kompliziert, wenn Sie den ESXi-Hypervisor verwenden möchten. Um ESXi verwenden zu können, muss es auf den lokalen Laufwerken des Clusters auf die übliche Weise installiert werden. Als Nächstes wird auf jedem ESXi-Knoten die virtuelle vAIR MasterVM-Maschine installiert, die eine spezielle vAIR-Distribution enthält, die als virtuelle VMware-Maschine ausgeführt wird.
ESXi stellt alle freien lokalen Festplatten durch direkte Weiterleitung an MasterVM zur Verfügung. Innerhalb von MasterVM werden diese Festplatten bereits standardmäßig in ARDFS formatiert und über die dedizierten Schnittstellen in ESXi nach außen (bzw. zurück zu ESXi) mit dem iSCSI-Protokoll (und in Zukunft wird es auch NFS geben) geliefert. Dementsprechend werden virtuelle Maschinen und Softwarenetzwerke in diesem Fall von ESXi bereitgestellt.
Szenario 2. ESXi
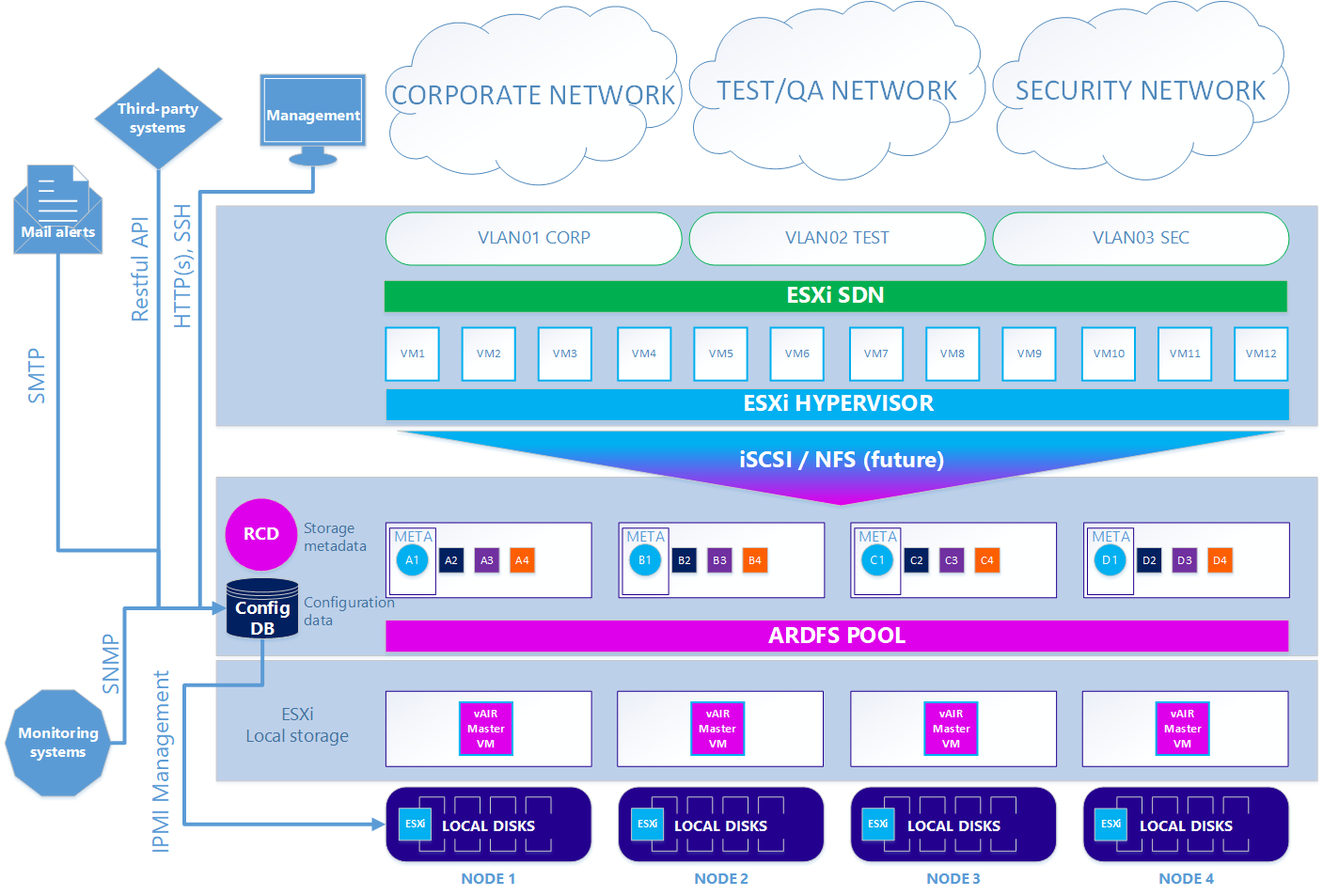
Daher haben wir alle Hauptkomponenten der vAIR-Architektur und ihre Aufgaben zerlegt. Im nächsten Artikel werden wir über die bereits implementierten Funktionen und Pläne für die nahe Zukunft sprechen.
Wir warten auf Kommentare und Vorschläge.