Bei Fragen im Stil von "Warum?" Es gibt einen älteren Artikel - Natural Geektimes - der den Weltraum sauberer macht .
Viele Artikel mögen aus subjektiven Gründen einige nicht, andere im Gegenteil, es ist schade, dies zu verpassen. Ich möchte diesen Prozess optimieren und Zeit sparen.
In dem obigen Artikel wurde ein Ansatz mit Skripten im Browser vorgeschlagen, der mir jedoch aus folgenden Gründen nicht wirklich gefallen hat (obwohl ich ihn zuvor verwendet habe):
- Für verschiedene Browser auf Ihrem Computer / Telefon müssen Sie es erneut konfigurieren, falls dies überhaupt möglich ist.
- Harte Filterung nach Autoren ist nicht immer bequem.
- Das Problem mit Autoren, deren Artikel nicht fehlen wollen, auch wenn sie einmal im Jahr veröffentlicht werden, ist nicht gelöst.
Das Filtern nach in die Site eingebauten Artikelbewertungen ist nicht immer bequem, da hochspezialisierte Artikel für ihren gesamten Wert eine eher bescheidene Bewertung erhalten können.
Am Anfang wollte ich RSS-Feeds (oder sogar einige) generieren, wobei ich nur das Interessante dort belassen wollte. Aber am Ende stellte sich heraus, dass das Lesen von RSS nicht sehr praktisch erschien: Um einen Artikel zu kommentieren, abzustimmen oder zu Favoriten hinzuzufügen, müssen Sie den Browser durchgehen. Deshalb habe ich einen Bot für ein Telegramm geschrieben, das mir interessante Artikel in PM wirft. Telegramm selbst macht sie schöne Vorschauen, die in Kombination mit Informationen über den Autor / Bewertung / Ansichten ziemlich informativ aussehen.
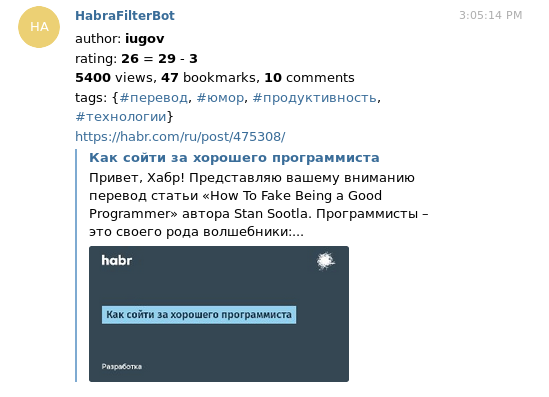
Unter dem Schnitt finden sich Details wie Arbeitsmerkmale, Schreibprozess und technische Lösungen.
Kurz über den Bot
Repository: https://github.com/Kright/habrahabr_reader
Telegramm-Bot: https://t.me/HabraFilterBot
Der Benutzer legt eine zusätzliche Bewertung für Tags und Autoren fest. Danach wird ein Filter auf die Artikel angewendet - die Artikelbewertung auf Habré, die Benutzerbewertung des Autors und der Durchschnitt der Benutzerbewertungen nach Tags werden hinzugefügt. Ist die Menge größer als der benutzerdefinierte Schwellenwert, besteht der Artikel den Filter.
Ein Nebenziel beim Schreiben eines Bots war es, Spaß zu haben und Erfahrungen zu sammeln. Außerdem erinnerte ich mich regelmäßig daran, dass ich nicht Google war und daher viele Dinge so einfach und sogar primitiv wie möglich gemacht wurden. Dies hinderte den Prozess des Schreibens des Bots jedoch nicht daran, sich drei Monate lang zu dehnen.
Vor dem Fenster war Sommer
Der Juli endete und ich beschloss, einen Bot zu schreiben. Und zwar nicht alleine, sondern mit einem Freund, der die Scala gemeistert hat und etwas darauf schreiben wollte. Der Anfang sah vielversprechend aus - der Code wird "Team" sein, die Aufgabe schien einfach und ich dachte, dass der Bot in ein paar Wochen oder einem Monat fertig sein wird.
Trotz der Tatsache, dass ich selbst in den letzten Jahren Code auf dem Felsen geschrieben habe, sieht oder sieht sich normalerweise niemand diesen Code an: Lieblingsprojekte, Überprüfung einiger Ideen, Datenvorverarbeitung, Beherrschung einiger Konzepte aus dem FP. Ich war wirklich daran interessiert, wie der Code im Team aussieht, weil der Code auf dem Felsen auf sehr unterschiedliche Arten geschrieben werden kann.
Was könnte so gelaufen sein ? Wir werden uns jedoch nicht beeilen.
Alles, was passiert, kann anhand der Commit-Historie verfolgt werden.
Ein Freund hat das Repository am 27. Juli erstellt, aber nichts anderes getan, also habe ich angefangen, Code zu schreiben.
30. Juli
Kurz: Ich habe Parsing-RSS-Feeds von Habr geschrieben.
com.github.pureconfig zum com.github.pureconfig Lesen von typsicheren Konfigurationsdateien in case-Klassen (es hat sich als sehr praktisch herausgestellt)scala-xml zum lesen von xml: da ich ursprünglich meine implementierung für rss tape und rss tape im xml-format schreiben wollte, habe ich diese bibliothek zum analysieren verwendet. Tatsächlich tauchte auch Parsing-RSS auf.scalatest für tests. Selbst bei kleinen Projekten spart das Schreiben von Tests Zeit. Wenn Sie beispielsweise das Parsen von XML-Dateien debuggen, können Sie sie viel einfacher in eine Datei herunterladen, Tests schreiben und Fehler beheben. Als später ein Fehler beim Parsen eines seltsamen HTML-Codes mit ungültigen utf-8-Zeichen auftrat, stellte sich heraus, dass es wieder praktischer war, ihn in eine Datei zu schreiben und einen Test hinzuzufügen.- Schauspieler aus Akka. Objektiv wurden sie überhaupt nicht benötigt, aber das Projekt war zum Spaß geschrieben, ich wollte sie ausprobieren. Infolgedessen bin ich bereit zu sagen, dass es mir gefallen hat. Man kann die Idee von OOP von der anderen Seite betrachten - es gibt Akteure, die Nachrichten austauschen. Was interessanter ist - es ist möglich (und notwendig), Code so zu schreiben, dass die Nachricht möglicherweise nicht erreicht wird oder nicht verarbeitet werden kann (im Allgemeinen sollten Nachrichten nicht verloren gehen, wenn ein Konto auf einem einzelnen Computer ausgeführt wird). Zuerst habe ich mir den Kopf zerbrochen und es gab einen Müll im Code, in dem Schauspieler sich gegenseitig abonnierten, aber am Ende habe ich es geschafft, eine ziemlich einfache und elegante Architektur zu erhalten. Der Code in jedem Akteur kann als Singlethread-Code betrachtet werden. Wenn der Akteur abstürzt, startet der Akka ihn neu - es wird ein eher fehlertolerantes System erhalten.
9. August
Ich habe das scala-scrapper Projekt zum Parsen von HTML-Seiten aus dem Habr hinzugefügt (um Informationen wie Artikelbewertung, Anzahl der Lesezeichen usw. abzurufen).
Und Katzen. Diejenigen, die im Fels sind.
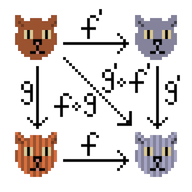
Ich habe dann ein Buch über verteilte Datenbanken gelesen und fand die Idee von CRDT (Conflict-free replicated data type, https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type , habr ) gut. Deshalb habe ich die Typklasse der kommutativen Halbgruppe für gefilmt Informationen zum Artikel über Habré.
Tatsächlich ist die Idee sehr einfach - wir haben Zähler, die sich monoton ändern. Die Anzahl der Promotoren wächst stetig, die Anzahl der Pluspunkte (aber auch die Anzahl der Minuspunkte). Wenn ich zwei Versionen von Informationen zu einem Artikel habe, können Sie diese "zu einer zusammenführen". Berücksichtigen Sie dabei den Status des Zählers, der relevanter ist.
Eine Halbgruppe bedeutet, dass zwei Objekte mit Informationen zu einem Artikel zu einem zusammengeführt werden können. Kommutativ bedeutet, dass Sie sowohl A + B als auch B + A zusammenführen können. Das Ergebnis hängt nicht von der Reihenfolge ab. Daher bleibt die neueste Version erhalten. Assoziativität ist übrigens auch hier.
Zum Beispiel lieferte RSS nach dem Parsen von Entwurf aus leicht gedämpfte Informationen über den Artikel - ohne Metriken wie die Anzahl der Aufrufe. Ein spezieller Darsteller nahm dann Informationen zu den Artikeln und rannte zu den HTML-Seiten, um sie zu aktualisieren und mit der alten Version zusammenzuführen.
Im Allgemeinen bestand wie bei akka keine Notwendigkeit dafür, es war lediglich möglich, updateDate für den Artikel zu speichern und einen neueren Artikel ohne Fusionen zu erstellen, aber der Weg des Abenteuers führte mich.
12. August
Ich begann mich freier zu fühlen und machte aus Gründen des Interesses jeden Chat zu einem eigenen Schauspieler. Theoretisch wiegt ein Akteur allein ungefähr 300 Bytes und kann mindestens von Millionen erstellt werden. Dies ist also ein ganz normaler Ansatz. Es stellte sich für mich eine recht interessante Lösung heraus:
Ein Akteur war die Brücke zwischen dem Telegrammserver und dem Nachrichtensystem in Akka. Er empfing einfach Nachrichten und schickte sie an den gewünschten Chat-Darsteller. Der Darsteller-Chat als Antwort konnte etwas zurücksenden - und es wurde zurück an Telegramme gesendet. Was sehr praktisch war - dieser Schauspieler erwies sich als so einfach wie möglich und enthielt nur die Logik der Antwort auf Nachrichten. Übrigens kamen zu jedem Chat Informationen über neue Artikel, aber auch hier sehe ich keine Probleme.
Im Allgemeinen hat der Bot bereits gearbeitet, auf Nachrichten geantwortet und eine Liste der an den Benutzer gesendeten Artikel geführt, und ich dachte bereits, dass der Bot fast fertig war. Ich beendete langsam kleine Chips wie das Normalisieren der Namen von Autoren und Tags (Ersetzen von "sd f" durch "s_d_f").
Es gab nur einen kleinen, aber - der Staat hat nirgendwo bestanden.
Alles ist schief gelaufen
Sie haben vielleicht bemerkt, dass ich den Bot meistens alleine geschrieben habe. Der zweite Teilnehmer beteiligte sich an der Entwicklung, und die folgenden Änderungen wurden im Code angezeigt:
- Um den Zustand zu speichern, erschien mongoDB. Zur gleichen Zeit brachen die Protokolle im Projekt, weil die Monga aus irgendeinem Grund anfing, sie zu spammen und einige Leute sie einfach global abschalteten.
- Die Akteurbrücke im Telegramm wurde bis zur Unkenntlichkeit transformiert und begann, Nachrichten selbst zu analysieren.
- Schauspieler für Chats waren gnadenlos betrunken, stattdessen erschien ein Schauspieler, der alle Informationen über alle Chats auf einmal in sich versteckte. Für jedes Niesen stieg dieser Schauspieler in Mongu. Ja, es ist schwierig, es an alle Chat-Akteure zu senden, wenn Informationen zu einem Artikel aktualisiert werden (wir sind wie Google, Millionen von Nutzern warten auf eine Million Artikel in einem Chat für alle), aber es ist normal, jedes Mal in eine Monga zu geraten, wenn Sie einen Chat aktualisieren. Wie ich sehr viel später verstand, wurde auch die Funktionslogik der Chats komplett herausgeschnitten und es trat etwas auf, das nicht funktionierte.
- Von den Klassen ist keine Spur mehr vorhanden.
- Eine ungesunde Logik trat bei den Schauspielern auf, die sich gegenseitig abonnierten, was zu einer Rassenbedingung führte.
- Datenstrukturen mit Feldern vom Typ
Option[Int] wurden mit magischen Standardwerten vom Typ -1 zu Int. Später wurde mir klar, dass mongoDB json speichert und es nichts Falsches daran gibt, Option dort zu speichern oder zumindest -1 wie None zu analysieren, aber zu diesem Zeitpunkt wusste ich das nicht und glaubte dem Wort "es ist notwendig". Dieser Code wurde nicht von mir geschrieben, und ich habe mich vorerst nicht darum gekümmert, ihn zu ändern. - Ich fand heraus, dass meine öffentliche IP-Adresse die Eigenschaft hat, sich zu ändern, und jedes Mal, wenn ich sie der Whitelist hinzufügen musste. Ich habe den Bot lokal gestartet, die Monga war irgendwo auf den Monga-Servern als Firma.
- Plötzlich verschwand die Normalisierung von Tags und die Formatierung von Nachrichten für ein Telegramm. (Hmm, warum sollte es?)
- Ich fand es gut, dass der Status des Bots in einer externen Datenbank gespeichert ist und beim Neustart so weiterarbeitet, als wäre nichts passiert. Dies war jedoch das einzige Plus.
Die zweite Person hatte es nicht eilig und all diese Veränderungen erschienen bereits Anfang September auf einem großen Haufen. Ich habe das Ausmaß des Schadens nicht sofort erkannt und begann, die Arbeit der Datenbank zu verstehen, weil hatte sich noch nie zuvor mit ihnen befasst. Erst dann wurde mir klar, wie viel Arbeitscode gekürzt wurde und wie viele Fehler im Gegenzug hinzugefügt wurden.
September
Zuerst dachte ich, es wäre nützlich, Mongu zu beherrschen und alles gut zu machen. Dann begann ich langsam zu verstehen, dass das Organisieren der Kommunikation mit der Datenbank auch eine Kunst ist, in der man Rennen fahren und nur Fehler machen kann. Wenn z. B. zwei Nachrichten vom Typ /subscribe vom Benutzer eingehen und als Antwort auf jede Nachricht ein Eintrag im Kennzeichen erstellt wird, ist der Benutzer zum Zeitpunkt der Verarbeitung dieser Nachrichten nicht signiert. Ich hatte den Verdacht, dass die Kommunikation mit der Monga in der vorhandenen Form nicht optimal geschrieben war. Beispielsweise wurden Benutzereinstellungen zum Zeitpunkt der Anmeldung erstellt. Wenn er vor dem Abonnement versucht hat, sie zu ändern ... hat der Bot nicht geantwortet, weil der Code im Darsteller in die Datenbank für die Einstellungen geklettert ist, nicht gefunden wurde und abgestürzt ist. Bei der Frage, warum die Einstellungen nicht nach Bedarf erstellt werden sollen, stellte ich fest, dass sie nicht geändert werden können, wenn der Benutzer sie nicht abonniert hat da ist ein Fehler.
Es wurde keine Liste von Artikeln zum Chatten gesendet, stattdessen wurde vorgeschlagen, dass ich sie selbst schreibe. Das überraschte mich - im Allgemeinen war ich nicht dagegen, alle möglichen Teile in das Projekt zu ziehen, aber es wäre logisch, diese Dinge hineinzuziehen und anzuschrauben. Aber nein, der zweite Teilnehmer scheint alles vergessen zu haben, hat aber gesagt, dass die Liste im Chat angeblich eine schlechte Entscheidung ist, und Sie müssen einen Teller mit Ereignissen wie "Artikel x wurde an Benutzer x gesendet" anfertigen. Wenn der Benutzer dann das Senden neuer Artikel anforderte, musste eine Anforderung an die Datenbank gesendet werden, welche der Ereignisse Ereignisse in Bezug auf den Benutzer auswählen, weiterhin eine Liste neuer Artikel abrufen, sie filtern, an den Benutzer senden und Ereignisse darüber zurück in die Datenbank werfen.
Der zweite Teilnehmer litt irgendwo in Richtung Abstraktionen, als der Bot nicht nur Artikel von Habr empfangen und nicht nur an Telegramme senden wird.
Irgendwie habe ich die Ereignisse in Form eines separaten Tablets bis zur zweiten Septemberhälfte implementiert. Nicht optimal, aber der Bot funktionierte immerhin und begann mir wieder Artikel zu schicken, und ich fand langsam heraus, was im Code vorging.
Jetzt können Sie zunächst zurückgehen und sich daran erinnern, dass das Repository ursprünglich nicht von mir erstellt wurde. Was könnte so gelaufen sein? Meine Poolanfrage wurde abgelehnt. Es stellte sich heraus, dass ich einen Shortcode hatte, nicht wusste, wie man in einem Team arbeitet, und dass ich Fehler in der aktuellen Implementierungskurve bearbeiten und nicht in einen verwendbaren Zustand ändern musste.
Ich war verärgert und schaute auf die Geschichte der Commits und die Menge des geschriebenen Codes. Ich habe mir die Momente angeschaut, die ursprünglich gut geschrieben und dann wieder abgebrochen wurden ...
F * rk es
Ich erinnerte mich an den Artikel Sie sind nicht Google .
Ich dachte, dass niemand ohne Umsetzung wirklich eine Idee braucht. Ich dachte, dass ich einen funktionierenden Bot haben möchte, der in einer einzelnen Kopie auf einem einzelnen Computer als einfaches Java-Programm funktioniert. Ich weiß, dass mein Bot monatelang ohne Neustart funktioniert, da ich in der Vergangenheit solche Bots geschrieben habe. Wenn er plötzlich fällt und den nächsten Artikel nicht an den Benutzer sendet, fällt der Himmel nicht auf die Erde und es passiert nichts Katastrophales.
Warum brauche ich einen Docker, MongoDB und andere Frachtsoftware mit "ernstem" Inhalt, wenn der Code nicht dumm oder schief funktioniert?
Ich gabelte das Projekt und tat alles, was ich wollte.
Etwa zur gleichen Zeit wechselte ich meinen Job und es fehlte mir schmerzlich an Freizeit. Morgens wachte ich genau im Zug auf, kam spät abends zurück und wollte nichts mehr tun. Ich habe eine Weile nichts getan, dann habe ich den Wunsch, den Bot zu beenden, überwunden und begann, den Code langsam umzuschreiben, während ich morgens zur Arbeit fuhr. Ich kann nicht sagen, dass es produktiv war: In einem rüttelnden Zug mit einem Laptop auf dem Schoß zu sitzen und einen Blick auf den Stapelüberlauf von Ihrem Telefon zu werfen, ist nicht sehr praktisch. Die Zeit hinter dem Schreiben des Codes verging jedoch völlig unbemerkt und das Projekt begann sich langsam in einen funktionierenden Zustand zu versetzen.
Irgendwo tief im Innern gab es einen Zweifel, den mongoDB nutzen wollte, aber ich dachte, dass es neben den Vorteilen des „zuverlässigen“ Zustandsspeichers spürbare Nachteile gibt:
- Die Datenbank wird zu einer weiteren Fehlerquelle.
- Der Code wird immer schwieriger und ich werde ihn länger schreiben.
- Der Code wird langsam und ineffizient. Anstatt das Objekt im Speicher zu ändern, werden die Änderungen an die Datenbank gesendet und bei Bedarf zurückgezogen.
- Es gibt Einschränkungen hinsichtlich der Art der Speicherung von Ereignissen in einer separaten Platte, die den Funktionen der Datenbank zugeordnet sind.
- In der Testversion von Monga gibt es einige Einschränkungen, und wenn Sie darauf stoßen, müssen Sie das Mongu für etwas starten und konfigurieren.
Ich habe Mongu getrunken, jetzt wird der Zustand des Bots einfach im Programmspeicher abgelegt und von Zeit zu Zeit in einer Datei in Form von JSON gespeichert. Vielleicht schreiben sie in den Kommentaren, dass ich falsch liege, weil du es hier verwenden solltest, usw. Aber das ist mein Projekt, der Ansatz mit der Datei ist so einfach wie möglich und es funktioniert auf transparente Weise.
Ich habe magische Werte wie -1 ausgegeben und die normale Option . Die Speicherung einer Hash-Platte mit den gesendeten Artikeln wurde zum Objekt mit den Chat-Informationen hinzugefügt. Löschung von Informationen über Artikel, die älter als fünf Tage sind, hinzugefügt, um nicht alles hintereinander zu speichern. Er brachte die Protokollierung in einen funktionsfähigen Zustand - Protokolle in angemessener Menge werden sowohl in die Datei als auch in die Konsole geschrieben. Mehrere Admin-Befehle wie das Speichern des Status oder das Abrufen von Statistiken wie die Anzahl der Benutzer und Artikel wurden hinzugefügt.
Ich habe ein paar Kleinigkeiten behoben: In den Artikeln wird beispielsweise die Anzahl der Aufrufe, Vorlieben, Abneigungen und Kommentare zum Zeitpunkt des Bestehens des Benutzerfilters angegeben. Im Allgemeinen ist es erstaunlich, wie viele kleine Dinge repariert werden mussten. Ich habe eine Liste geführt, alle „Unebenheiten“ dort notiert und soweit wie möglich korrigiert.
Zum Beispiel habe ich die Möglichkeit hinzugefügt, alle Einstellungen direkt in einer Nachricht festzulegen:
/subscribe /rating +20 /author a -30 /author s -20 /author p +9000 /tag scala 20 /tag akka 50
Und der Befehl /settings zeigt sie in dieser Form an. Sie können Text daraus entnehmen und alle Einstellungen an einen Freund senden.
Es scheint eine Kleinigkeit zu sein, aber es gibt Dutzende ähnlicher Nuancen.
Filterung von Artikeln in Form eines einfachen linearen Modells implementiert - der Benutzer kann eine zusätzliche Bewertung für Autoren und Tags sowie einen Schwellenwert festlegen. Wenn die Summe aus der Bewertung des Autors, der durchschnittlichen Bewertung für Tags und der tatsächlichen Bewertung des Artikels größer als der Schwellenwert ist, wird der Artikel dem Benutzer angezeigt. Sie können den Bot entweder mit dem Befehl / new nach Artikeln fragen oder ihn abonnieren, und er wirft zu jeder Tageszeit Artikel in PM.
Im Allgemeinen hatte ich die Idee, für jeden Artikel mehr Zeichen (Hubs, Anzahl der Kommentare, Lesezeichen, Dynamik der Bewertungsänderungen, Textmenge, Bilder und Code im Artikel, Stichwörter) zu zeichnen und dem Benutzer zu zeigen, ob die Stimmen in Ordnung oder nicht in Ordnung sind Artikel und für jeden Benutzer das Modell zu trainieren, aber ich wurde zu faul.
Darüber hinaus wird die Logik der Arbeit nicht so offensichtlich sein. Jetzt kann ich für patientZero manuell eine Bewertung von +9000 eingeben und mit einer Schwellenbewertung von +20 werde ich garantiert alle seine Artikel erhalten (es sei denn, ich habe -100500 für Tags eingegeben).
Die resultierende Architektur war recht einfach:
- Ein Schauspieler, der den Status aller Chats und Artikel speichert. Es lädt seinen Status von einer Datei auf der Festplatte und speichert ihn von Zeit zu Zeit zurück, jedes Mal in eine neue Datei.
- Ein Schauspieler, der gelegentlich auf den RSS-Feed stößt, erfährt von neuen Artikeln, schaut sich die Links an, analysiert diese und sendet sie an den ersten Schauspieler. Außerdem fragt er manchmal den ersten Schauspieler nach einer Liste von Artikeln, wählt diejenigen aus, die nicht älter als drei Tage sind, aber schon lange nicht mehr aktualisiert wurden, und aktualisiert sie.
- Ein Schauspieler, der mit einem Telegramm kommuniziert. Das Parsen von Nachrichten habe ich hier noch ganz übernommen. Auf eine gute Weise möchte ich es in zwei Teile aufteilen - so dass einer eingehende Nachrichten analysiert und der zweite sich mit Transportproblemen wie dem Weiterleiten nicht gesendeter Nachrichten befasst. Jetzt erfolgt kein erneutes Senden, und die Nachricht, die aufgrund eines Fehlers nicht eingegangen ist, geht einfach verloren (außer dass sie in den Protokollen markiert wird), was jedoch bisher keine Probleme verursacht. Möglicherweise treten Probleme auf, wenn eine Gruppe von Personen den Bot abonniert und ich das Limit für das Senden von Nachrichten erreicht habe.
Was mir gefallen hat - dank Akka hat der Sturz der Schauspieler 2 und 3 im Allgemeinen keinen Einfluss auf die Leistung des Bots. Möglicherweise werden einige Artikel nicht rechtzeitig aktualisiert oder einige Nachrichten erreichen das Telegramm nicht, aber Akka startet den Schauspieler neu und alles funktioniert weiter. Ich speichere die Information, dass der Artikel dem Benutzer nur angezeigt wird, wenn der Telegrammschauspieler antwortet, dass er die Nachricht erfolgreich zugestellt hat. Das Schlimmste, was mir droht, ist, eine Nachricht mehrmals zu senden (wenn sie zugestellt wird, die Bestätigung jedoch auf unbekannte Weise verloren geht). Wenn der erste Schauspieler den Staat nicht in sich behalten, sondern mit einer Art Datenbank kommunizieren würde, könnte er im Prinzip auch ruhig fallen und zum Leben zurückkehren. Ich könnte auch versuchen, durch Hartnäckigkeit den Zustand der Schauspieler wiederherzustellen, aber die derzeitige Umsetzung gefällt mir durch ihre Einfachheit. Nicht, dass mein Code oft abstürzt - im Gegenteil, ich habe viel Mühe darauf verwendet, dies unmöglich zu machen. Aber Scheiße passiert, und die Fähigkeit, das Programm in einzelne Stücke aufzuteilen, schien mir wirklich praktisch und praktisch.
Circle-ci hinzugefügt, um sofort zu erfahren, wenn der Code kaputt geht. Zumindest hat der Code aufgehört zu kompilieren. Am Anfang wollte ich Travis hinzufügen, aber es wurden nur meine Projekte ohne gegabelte Projekte angezeigt. Im Allgemeinen können diese beiden Dinge in offenen Repositorys frei verwendet werden.
Zusammenfassung
Es ist schon November. Der Bot ist geschrieben, ich habe ihn die letzten zwei Wochen benutzt und er hat mir gefallen. Wenn Sie Verbesserungsvorschläge haben - schreiben Sie. Ich sehe keinen Grund, es zu monetarisieren - lass es einfach funktionieren und sende interessante Artikel.
Link zum Bot: https://t.me/HabraFilterBot
Github: https://github.com/Kright/habrahabr_reader
Kleine Schlussfolgerungen:
- Selbst ein kleines Projekt kann lange dauern.
- Sie sind kein Google. Es macht keinen Sinn, einen Spatz aus einer Kanone zu schießen. Eine einfache Lösung kann genauso gut funktionieren.
- Haustierprojekte eignen sich sehr gut zum Experimentieren mit neuen Technologien.
- Telegramm-Bots werden ganz einfach geschrieben. Ohne "Teamwork" und Experimente mit Technologien wäre der Bot in ein oder zwei Wochen geschrieben worden.
- Das Darstellermodell ist eine interessante Sache, die gut zu Multithreading und Code-Resilienz passt.
- Ich scheine selbst zu spüren, warum die Open-Source-Community Gabeln liebt.
- Datenbanken sind insofern gut, als der Status der Anwendung nicht mehr von den Abstürzen / Neustarts der Anwendung abhängt, sondern die Arbeit mit der Datenbank den Code verkompliziert und die Datenstruktur einschränkt.