In den ersten beiden Artikeln habe ich das Thema Automatisierung angesprochen und dessen Rahmen skizziert, in der zweiten habe ich einen Exkurs in die Netzwerkvirtualisierung als ersten Ansatz zur Automatisierung der Konfiguration von Diensten gemacht.
Und jetzt ist es Zeit, ein physisches Netzwerkdiagramm zu zeichnen.
Wenn Sie mit Rechenzentrumsnetzwerken nicht auf dem Laufenden sind, empfehle ich dringend, mit einem
Artikel darüber zu beginnen .
Alle Ausgaben:
Die in dieser Serie beschriebenen Vorgehensweisen sollten auf ein Netzwerk jeglicher Art und Größenordnung mit einer Vielzahl von Anbietern (Nr.) Anwendbar sein. Ein universelles Beispiel für die Anwendung dieser Ansätze kann jedoch nicht beschrieben werden. Daher werde ich mich auf die moderne Architektur des DC-Netzes konzentrieren:
Klose Factory .
DCI arbeitet mit MPLS L3VPN.
Ein Overlay-Netzwerk vom Host wird über dem physischen Netzwerk ausgeführt (dies kann OpenStack VXLAN oder Tungsten Fabric sein oder alles andere, das nur eine grundlegende IP-Konnektivität vom Netzwerk erfordert).
In diesem Fall erhalten wir ein relativ einfaches Szenario für die Automatisierung, da viele Geräte auf die gleiche Weise konfiguriert sind.
Wir werden einen sphärischen Gleichstrom im Vakuum wählen:
- Eine Version des Designs ist überall.
- Zwei Anbieter bilden zwei Ebenen des Netzwerks.
- Ein Gleichstrom gleicht einem anderen wie zwei Wassertropfen.
Inhalt
- Physikalische Topologie
- Routing
- IP-Plan
- Laba
- Fazit
- Nützliche Links
Lassen Sie unseren LAN_DC Service Provider beispielsweise Schulungsvideos über das Überleben in steckengebliebenen Aufzügen hosten.
In Megacities ist dies sehr beliebt, daher gibt es viele physische Maschinen.
Zunächst beschreibe ich das Netzwerk ungefähr so, wie ich es gerne sehen würde. Und dann werde ich es für das Labor vereinfachen.
Physikalische Topologie
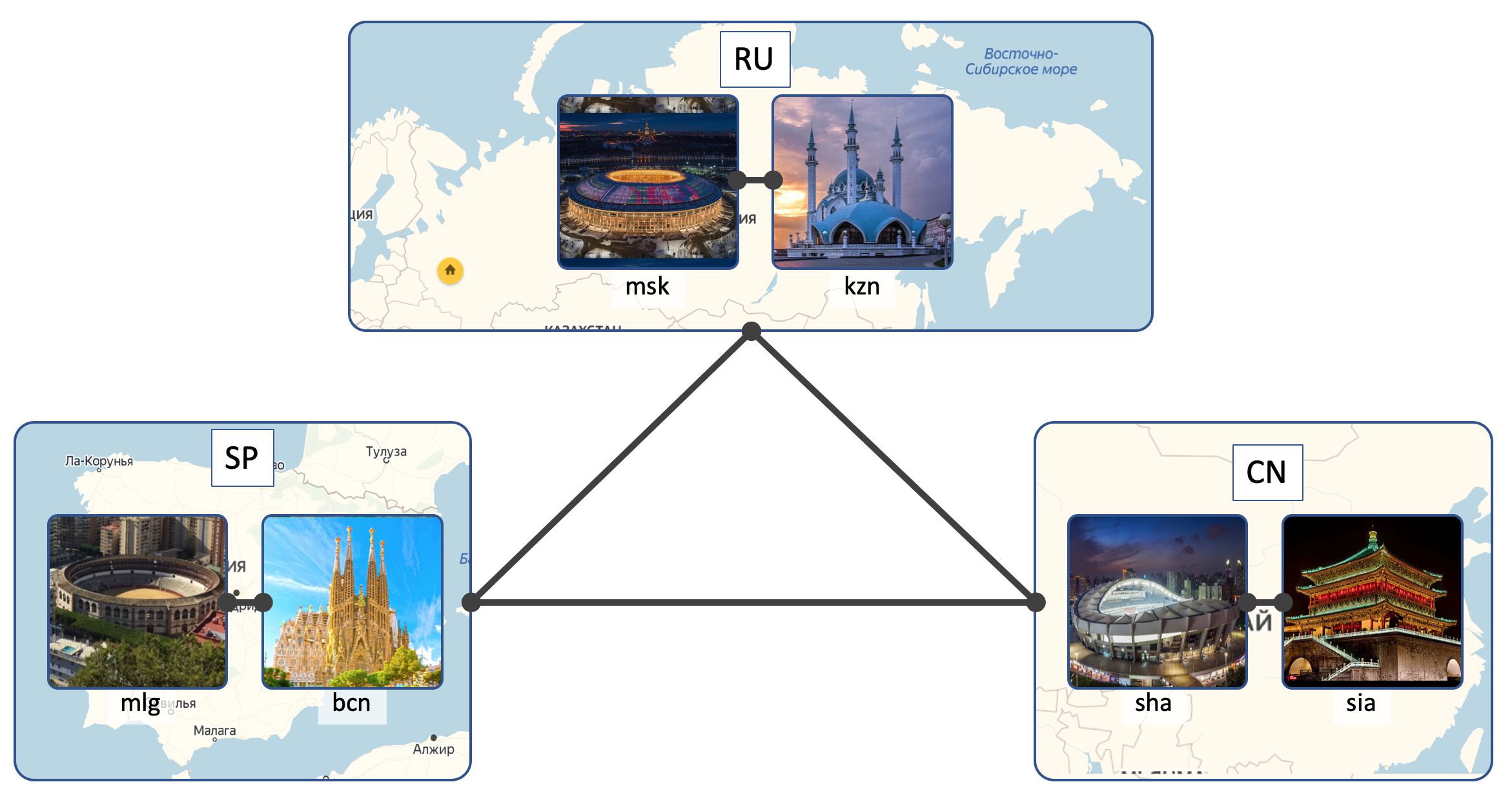
Standorte
LAN_DC wird 6 DCs haben:
- Russland ( RU ):
- Moskau ( msk )
- Kazan ( kzn )
- Spanien ( SP ):
- Barcelona ( bcn )
- Malaga ( mlg )
- China ( CN ):
- Shanghai ( sha )
- Xi'an ( sia )
In DC (Intra-DC)
In allen Domänencontrollern identische interne Konnektivitätsnetzwerke basierend auf der Clos-Topologie.
Welche Art von Netzwerken sind Klose und warum sind sie in einem separaten
Artikel .
In jedem DC gibt es 10 Racks mit Autos, die mit
A ,
B ,
C usw. nummeriert sind.
Jedes Rack hat 30 Autos. Sie werden uns nicht interessieren.
Außerdem gibt es in jedem Rack einen Switch, an den alle Maschinen angeschlossen sind - dies ist der
Top-of-the-Rack-Switch - ToR oder im Sinne der Klose-Fabrik
Leaf .
 Das allgemeine Schema der Fabrik.
Das allgemeine Schema der Fabrik.Wir werden sie mit
XXX- leaf Y bezeichnen , wobei
XXX die aus drei Buchstaben bestehende Abkürzung DC und
Y die Seriennummer ist. Zum Beispiel
kzn-leaf11 .
In den Artikeln erlaube ich mir, die Begriffe Leaf und ToR recht leichtfertig als Synonyme zu verwenden. Man muss jedoch bedenken, dass dies nicht so ist.
ToR ist ein in ein Rack eingebauter Switch, mit dem Maschinen verbunden sind.
Leaf ist die Rolle eines Geräts in einem physischen Netzwerk oder eines Switches der ersten Ebene in Bezug auf die Clos-Topologie.
Das heißt, Leaf! = ToR.
So kann Leaf beispielsweise ein EndofRaw-Schalter sein.
Im Rahmen dieses Artikels werden wir sie jedoch trotzdem als Synonyme bezeichnen.
Jeder ToR-Switch ist wiederum mit vier Upstream-Aggregations-Switches verbunden -
Spine . Unter Spine'y wurde im DC ein Rack zugeteilt. Wir werden es auf die gleiche Weise
benennen :
XXX -dorn Y.Im selben Rack befinden sich Netzwerkgeräte für die Konnektivität zwischen DCs - 2 Router mit integriertem MPLS. Aber im Großen und Ganzen - das sind die gleichen Aufgaben. Aus Sicht der Spine-Switches spielt es also keine Rolle, ob es einen normalen ToR mit angeschlossenen Maschinen oder einen Router für DCI gibt - eine verdammte Sache.
Solche speziellen ToRs werden
Edge-Leaf genannt . Wir werden sie
XXX- Kante Y nennen.Es wird so aussehen.

In dem Diagramm über Kante und Blatt habe ich mich wirklich auf die gleiche Ebene gesetzt.
Klassische dreistufige Netzwerke haben uns gelehrt, den Uplink (der Begriff stammt eigentlich von hier) als Verbindung zu betrachten. Und hier stellt sich heraus, dass der „Uplink“ von DCI wieder nach unten geht, was etwas gegen die übliche Logik verstößt. Bei großen Netzwerken werden, wenn Rechenzentren weiter in kleinere Einheiten unterteilt werden -
PODs (Point of Delivery) - separate
Edge-PODs für DCI und den Zugriff auf externe Netzwerke zugewiesen.
Der Einfachheit halber werde ich auch in Zukunft Edge auf Spine zeichnen, wobei wir uns vor Augen halten, dass es keine Informationen zu Spine und Unterschieden bei der Arbeit mit gewöhnlichen Leaf- und Edge-Leaf-Elementen gibt (obwohl es möglicherweise Nuancen gibt, aber im Allgemeinen ist das so).
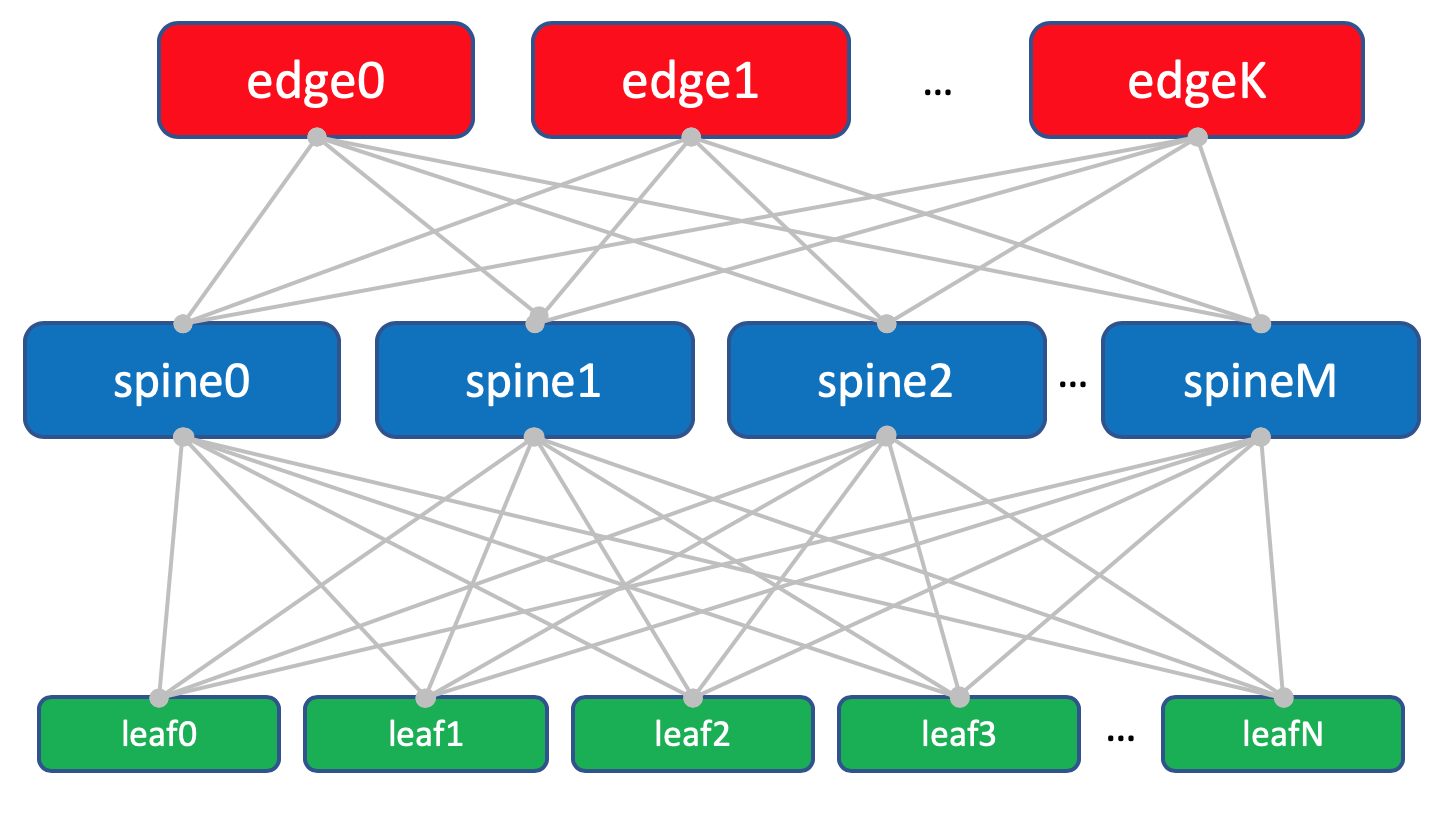 Fabrikplan mit Randblättern.
Fabrikplan mit Randblättern.Trinity Leaf, Spine und Edge bilden ein Underlay-Netzwerk oder eine Factory.
Die Aufgabe der Network Factory (Read Underlay) ist, wie wir bereits in der
Vorgängerversion festgestellt haben, sehr, sehr einfach: IP-Konnektivität zwischen Maschinen innerhalb desselben DC und zwischen bereitzustellen.
Aus diesem Grund wird das Netzwerk als Factory bezeichnet, genau wie beispielsweise eine Switching-Factory in modularen Netzwerkboxen, die in
SDSM14 ausführlicher
beschrieben wird .
Im Allgemeinen wird eine solche Topologie als Factory bezeichnet, da Fabric in Translation ein Fabric ist. Und es ist schwer nicht zuzustimmen:

Fabrik vollständig L3. Keine VLANs, kein Broadcast - das sind großartige Programmierer bei LAN_DC, sie können Anwendungen schreiben, die dem L3-Paradigma entsprechen, und virtuelle Maschinen erfordern keine Live-Migration, da die IP-Adresse gespeichert wird.
Und nochmal: die Antwort auf die Frage, warum das Werk und warum L3 - in einem eigenen
Artikel .
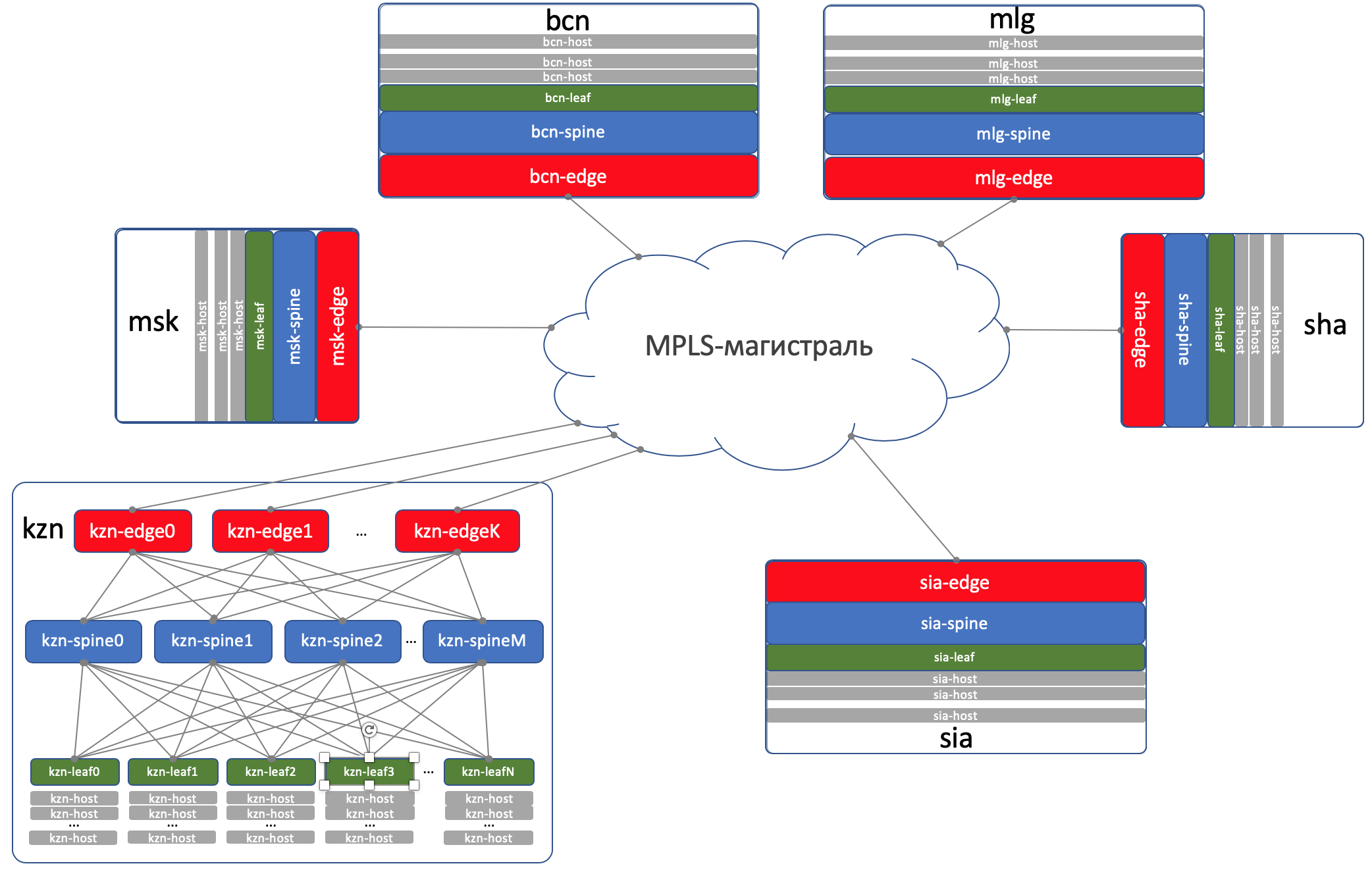
DCI - Data Center Interconnect (Inter-DC)
DCI wird mit Edge-Leaf organisiert, das heißt, sie sind unser Ausgangspunkt zur Autobahn.
Der Einfachheit halber nehmen wir an, dass DCs durch direkte Verbindungen verbunden sind.
Wir schließen externe Konnektivität von der Betrachtung aus.
Mir ist bewusst, dass ich jedes Mal, wenn ich eine Komponente entferne, das Netzwerk erheblich vereinfache. Und mit der Automatisierung unseres abstrakten Netzwerks wird alles in Ordnung sein, aber auf dem realen werden Krücken auftauchen.
Ist das so. Dennoch ist das Ziel dieser Reihe, Ansätze zu denken und zu bearbeiten und imaginäre Probleme nicht heldenhaft zu lösen.
Bei Edge-Leafs wird die Unterlage im VPN platziert und über das MPLS-Backbone (dieselbe direkte Verbindung) übertragen.
Hier ist so ein Top-Level-Schema.
Routing
Für das Routing innerhalb des DC verwenden wir BGP.
Auf OSPF + LDP MPLS-Trunk
Für DCI ist die Organisation der Konnektivität auf der Unterseite BGP L3VPN über MPLS.
 Allgemeines Routing-Schema
Allgemeines Routing-SchemaEs gibt keine OSPF und ISIS im Werk (Routing-Protokoll in der Russischen Föderation verboten).
Dies bedeutet, dass keine automatische Erkennung und Berechnungen des kürzesten Pfades erforderlich sind - nur die manuelle (in der Tat automatische - hier geht es um die Automatisierung) Einrichtung des Protokolls, der Umgebung und der Richtlinien.
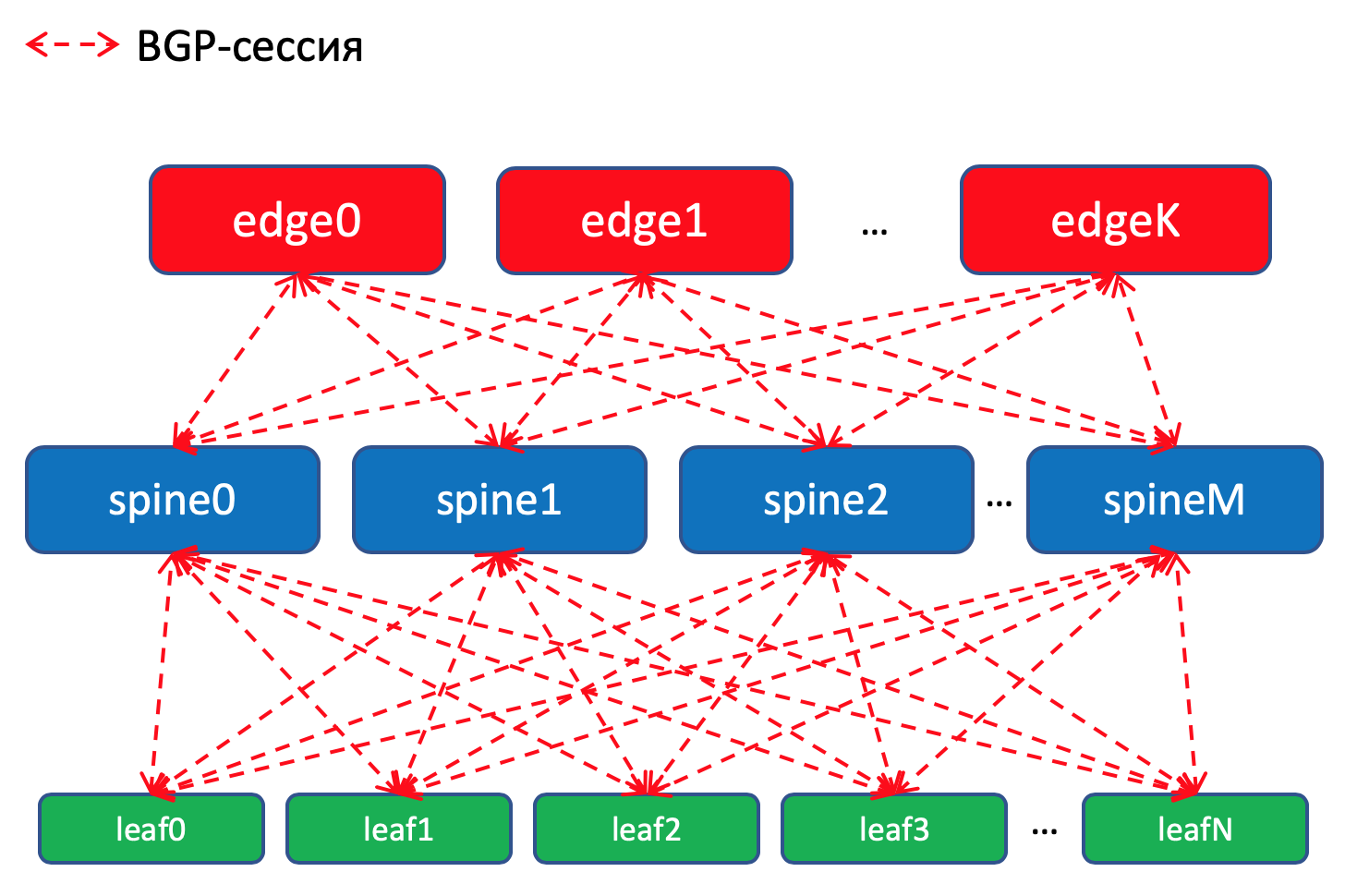 BGP-Routing-Schema im DCWarum BGP?
BGP-Routing-Schema im DCWarum BGP?Es gibt
eine ganze RFC namens Facebook und Arista zu diesem Thema, in der erklärt wird, wie mit BGP
sehr große Netzwerke von Rechenzentren aufgebaut werden. Es liest sich fast wie eine Kunst, sehr zu empfehlen für einen trägen Abend.
Und ein ganzer Abschnitt in meinem Artikel ist diesem Thema gewidmet. Wohin
schicke ich
dich?Kurz gesagt, kein IGP eignet sich für Netzwerke großer Rechenzentren, in denen Tausende von Netzwerkgeräten zum Einsatz kommen.
Darüber hinaus können Sie durch die Verwendung von BGP überall auf die Unterstützung mehrerer verschiedener Protokolle und die Synchronisierung zwischen diesen verzichten.
Hand aufs Herz, in unserer Fabrik, die mit hoher Wahrscheinlichkeit nicht schnell wachsen wird, würde OSPF für die Augen ausreichen. Dies sind eigentlich die Probleme von Megascalern und Cloud-Titanen. Aber stellen wir uns ein paar Probleme vor, die wir brauchen, und wir werden BGP verwenden, wie es Peter Lapukhov hinterlassen hat.
Routing-Richtlinien
Bei Leaf-Switches importieren wir BGP-Präfixe von Underlay-Schnittstellen mit Netzwerken.
Wir werden eine BGP-Sitzung zwischen
jedem Blatt-Wirbelsäulen-Paar haben, in der diese Unterlegungs-Präfixe in einem Pfützennetz angekündigt werden.

In einem Rechenzentrum werden die in ToRe importierten Daten verteilt. Auf Edge-Leafs werden sie aggregiert und in Remote-DCs angekündigt und auf ToRs gesenkt. Das heißt, jeder ToR weiß genau, wie er zu einem anderen ToR in demselben DC gelangt und wo sich der Einstiegspunkt befindet, um zu dem ToR in einem anderen DC zu gelangen.
In DCI werden Routen als VPNv4 übertragen. Dazu wird auf dem Edge-Leaf die Schnittstelle zur Factory in VRF platziert, nennen wir es UNDERLAY, und die Nachbarschaft mit dem Dorn auf dem Edge-Leaf wird innerhalb des VRF und zwischen den Edge-Leafs in der VPNv4-Familie entstehen.
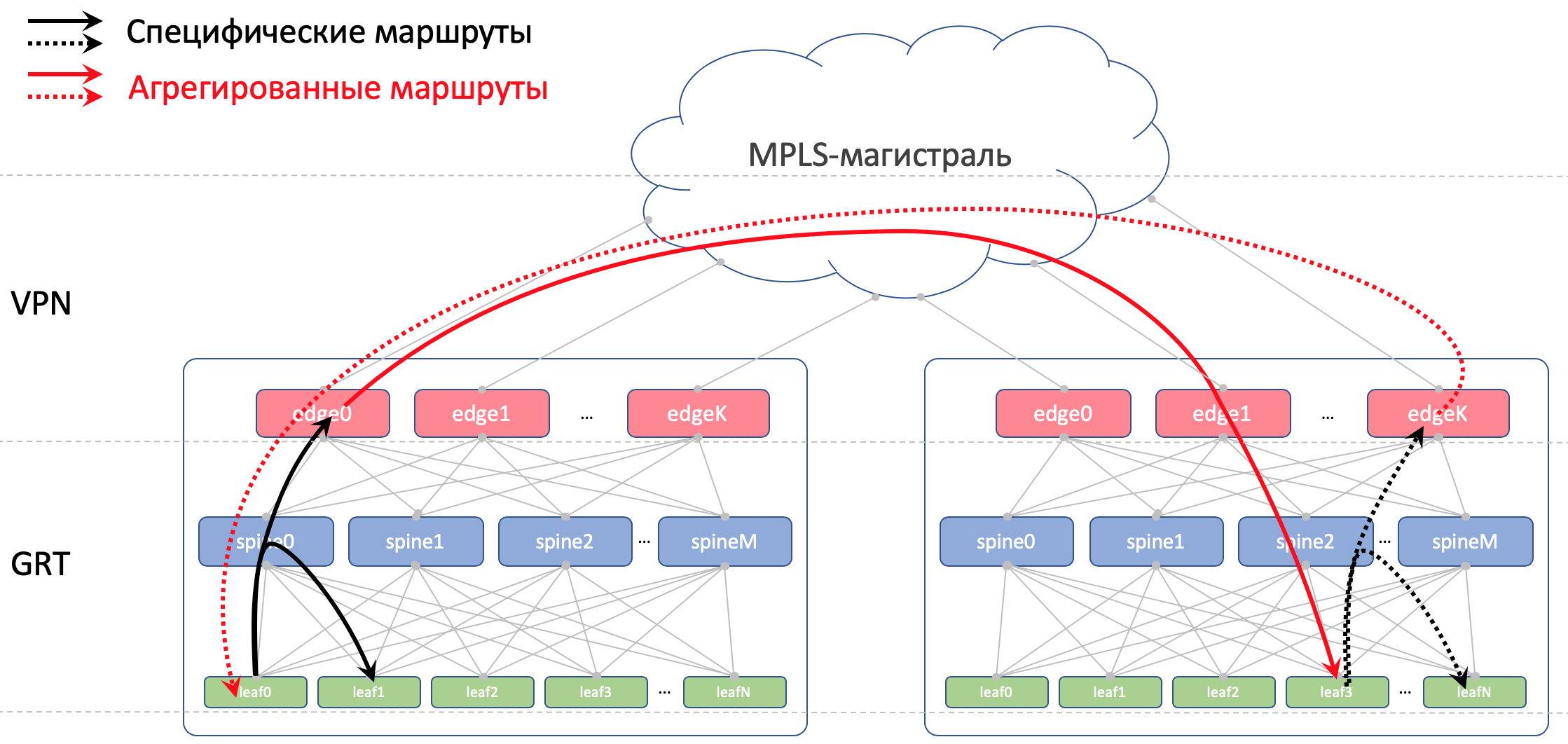
Wir werden auch die erneute Ankündigung von Routen, die von Stacheln empfangen wurden, zu diesen verbieten.
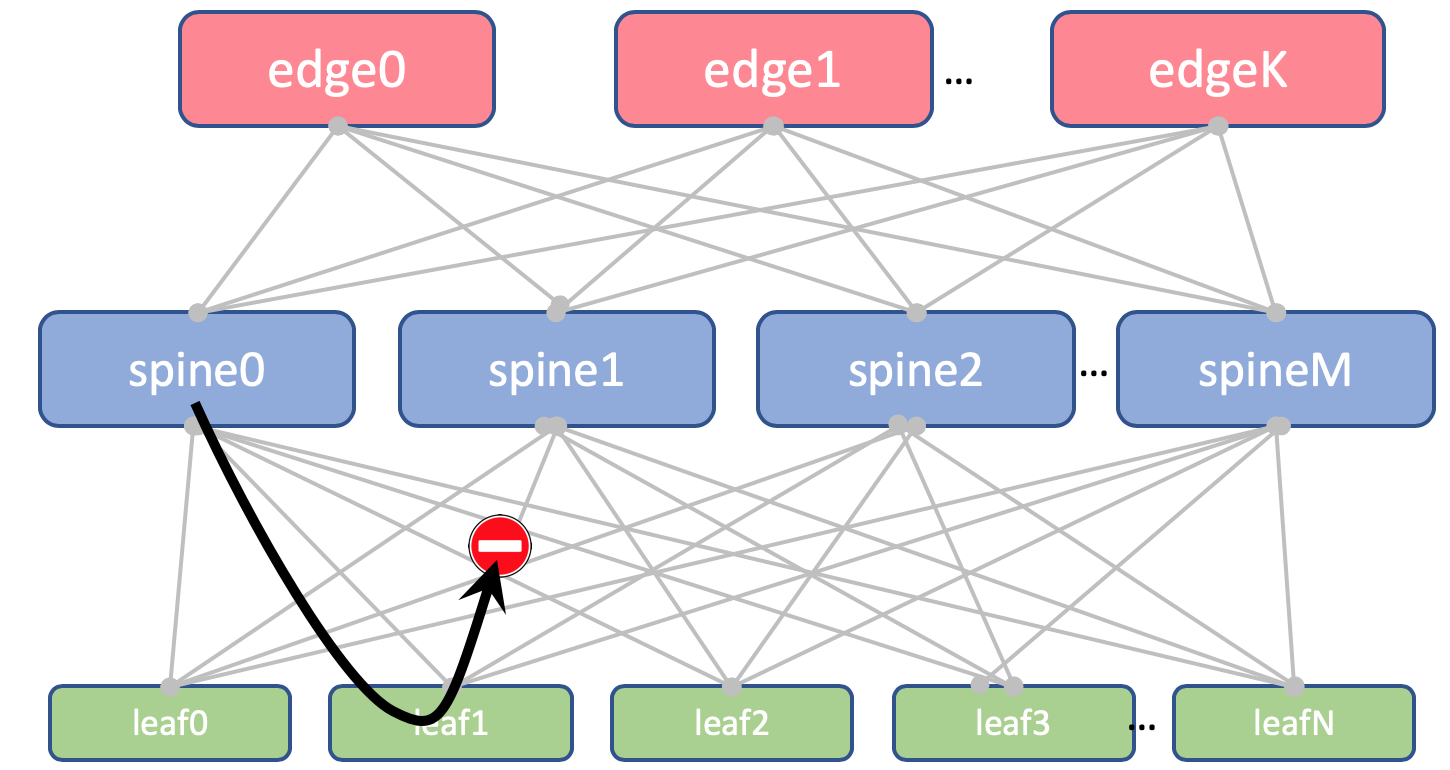
Auf Leaf und Spine werden keine Loopbacks importiert. Wir brauchen sie nur, um die Router-ID zu bestimmen.
Bei Edge-Leafs wird es jedoch in Global BGP importiert. Zwischen Loopback-Adressen richten Edge Leafs eine BGP-Sitzung in der IPv4-VPN-Familie miteinander ein.
Zwischen den EDGE-Geräten befindet sich ein OSPF + LDP-Backbone. Alles in einer Zone. Extrem einfache Konfiguration.
Hier ist ein Bild des Routings.
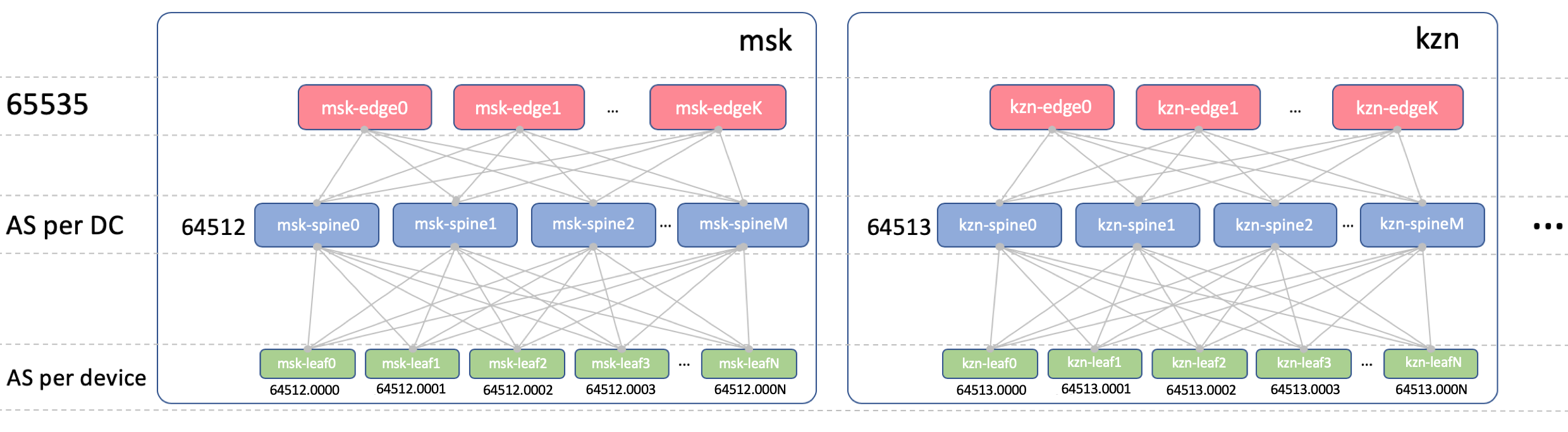
BGP ASN
Edge-Leaf ASN
Auf Edge-Leafs wird in allen DCs ein ASN vorhanden sein. Es ist wichtig, dass es zwischen den Edge-Leafs iBGP gibt und dass wir nicht auf die Nuancen von eBGP stoßen. Es sei 65535. In Wirklichkeit könnte es eine öffentliche AS-Nummer sein.
Wirbelsäule ASN
Bei Spine haben wir einen Lieferavis pro DC. Beginnen wir hier mit der allerersten Nummer aus dem privaten AS-Bereich - 64512, 64513 usw.
Warum ist ASN auf DC?
Wir zerlegen diese Frage in zwei Teile:
- Warum sind die gleichen Lieferavise auf allen Stacheln des gleichen DCs?
- Warum unterscheiden sie sich in verschiedenen DCs?
Warum sind die gleichen Lieferavise auf allen Stacheln eines DCSo sieht die AS-Path Anderlay-Route auf dem Edge-Leaf aus:
[leafX_ASN, spine_ASN , edge_ASN]Wenn Sie versuchen, es wieder bei Spine anzumelden, wird es gelöscht, da sein AS (Spine_AS) bereits in der Liste enthalten ist.
Innerhalb des DC sind wir jedoch völlig zufrieden, dass die Underlay-Routen, die nach Edge geklettert sind, nicht runtergehen können. Die gesamte Kommunikation zwischen Hosts innerhalb des DC sollte innerhalb der Wirbelsäulenebene stattfinden.
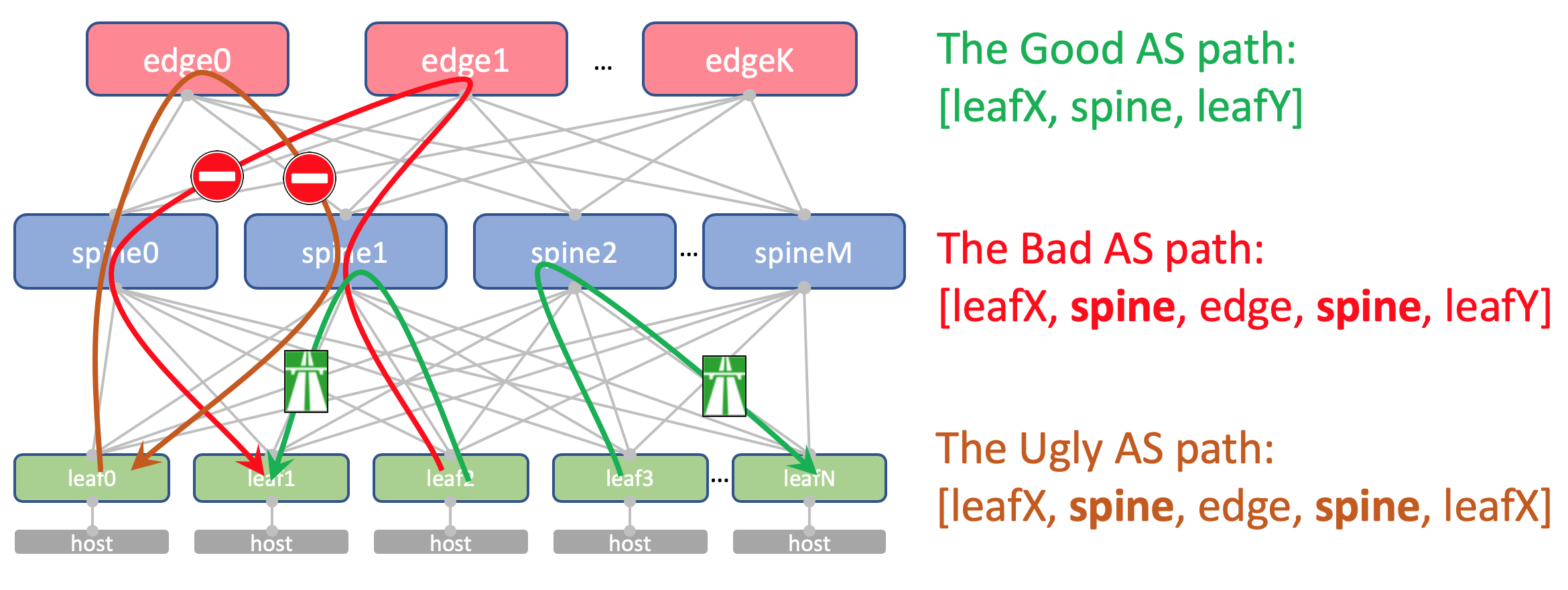
Gleichzeitig erreichen die aggregierten Routen anderer DCs in jedem Fall ToRs frei - in ihrem AS-Path gibt es nur ASN 65535 - die Anzahl der AS Edge-Leafs, weil sie auf ihnen erstellt wurden.
Warum sind in verschiedenen DC unterschiedlichTheoretisch müssen wir möglicherweise Loopbacks und einige virtuelle Servicemaschinen zwischen die Domänencontroller ziehen.
Auf dem Host wird beispielsweise ein Route Reflector oder
dasselbe VNGW (Virtual Network Gateway) ausgeführt, das über BGP mit ToR gesperrt wird und dessen Loopback ankündigt, das von allen Domänencontrollern verfügbar sein sollte.
So sieht sein AS-Pfad aus:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN , edge_ASN, spine_DC2_ASN , leafY_DC2_ASN]Und hier sollte es nirgendwo doppelte Lieferavise geben.
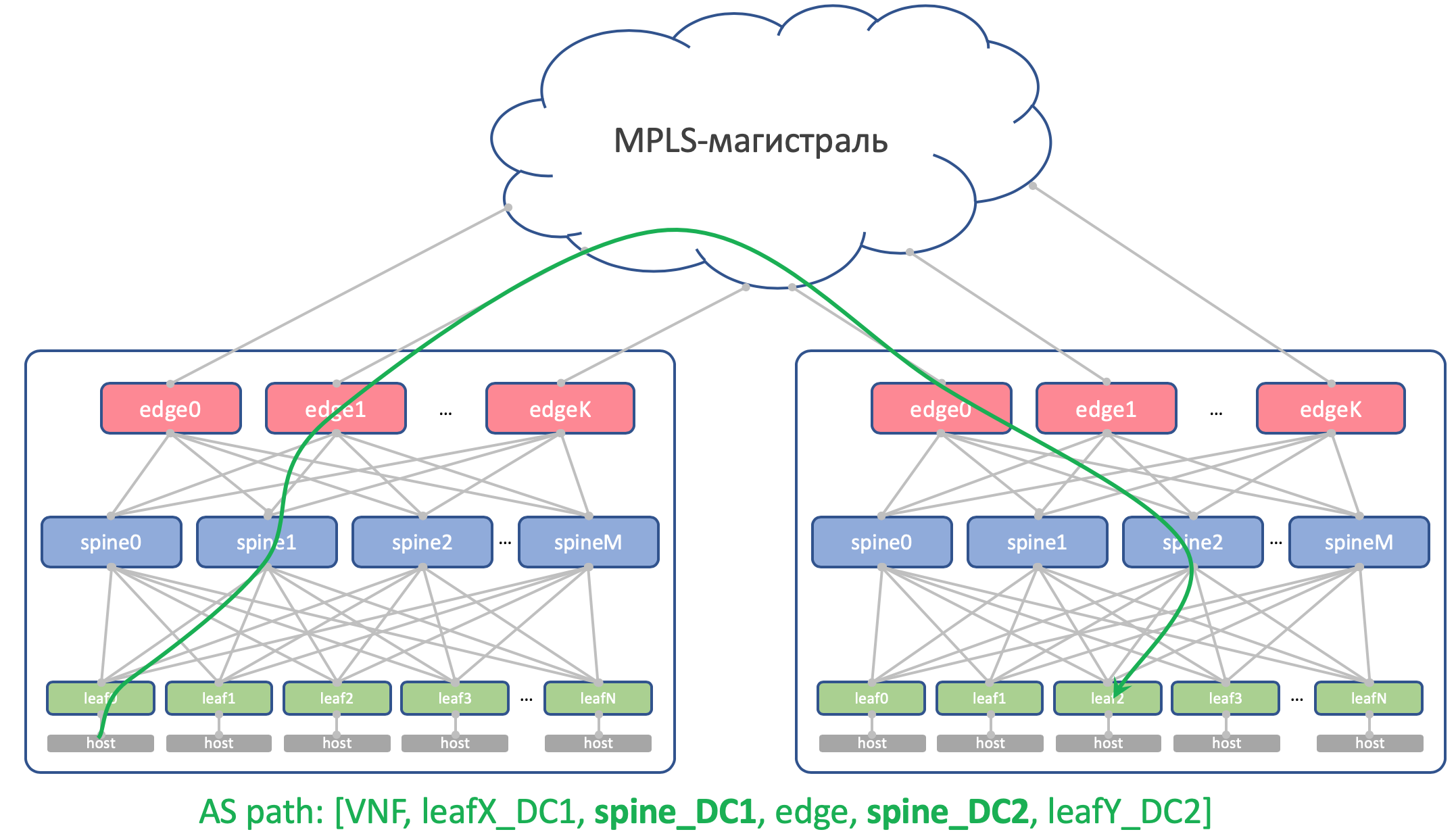
Das heißt, Spine_DC1 und Spine_DC2 sollten sich unterscheiden, genau wie leafX_DC1 und leafY_DC2, und genau dem nähern wir uns.
Wie Sie wahrscheinlich wissen, gibt es Hacks, die es Ihnen ermöglichen, Routen mit sich wiederholenden ASNs entgegen dem Loop Prevention-Mechanismus (allowas-in bei Cisco) zu akzeptieren. Und es hat sogar rechtmäßige Verwendungen. Dies kann jedoch die Ausfallsicherheit des Netzwerks beeinträchtigen. Und ich persönlich bin ein paar Mal reingefallen.
Und wenn wir die Möglichkeit haben, keine gefährlichen Dinge zu benutzen, werden wir sie benutzen.
Blatt asn
Wir haben eine individuelle ASN auf jedem Leaf-Switch im gesamten Netzwerk.
Dies geschieht aus den oben genannten Gründen: AS-Pfad ohne Schleifen, BGP-Konfiguration ohne Lesezeichen.
Damit Routen zwischen Leafs ungehindert passieren können, sollte AS-Path folgendermaßen aussehen:
[leafX_ASN, spine_ASN, leafY_ASN]Wobei leafX_ASN und leafY_ASN schön wären, anders zu sein.
Dies ist auch für die Situation mit der Ankündigung des VNF-Loopback zwischen DCs erforderlich:
[VNF_ASN, leafX_DC1_ASN , spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN ]Wir werden einen 4-Byte-ASN verwenden und ihn basierend auf dem ASN und der Leaf-Switch-Nummer von Spine generieren, und zwar wie
folgt :
Spine_ASN.0000X .
Hier ist ein Bild mit ASN.
IP-Plan
Grundsätzlich müssen wir Adressen für folgende Verbindungen vergeben:
- Unterlegen Sie die Netzwerkadressen zwischen ToR und der Maschine. Sie müssen im gesamten Netzwerk eindeutig sein, damit jede Maschine mit jeder anderen kommunizieren kann. Ideal für 10/8 . Für jedes Rack / 26 mit Rand. Wir werden / 19 für DC und / 17 für die Region zuweisen.
- Verknüpfungsadressen zwischen Leaf / Tor und Spine.
Ich möchte sie algorithmisch zuweisen, dh aus den Namen der Geräte berechnen, die verbunden werden müssen.
Sei es ... 169.254.0.0/16.
169.254.00X.Y / 31 , wobei X die Spine-Nummer und Y das P2P-Netzwerk / 31 ist.
Auf diese Weise können Sie bis zu 128 Racks und bis zu 10 Spine im DC betreiben. Linkadressen können (und werden) von DC zu DC wiederholt. - Wir organisieren die Verbindung Wirbelsäule - Rand-Blatt in den Subnetzen 169.254.10X.Y / 31 , wobei X die Wirbelsäulennummer und Y das P2P-Netzwerk / 31 ist.
- Verknüpfen Sie Adressen vom Edge-Leaf mit dem MPLS-Backbone. Hier ist die Situation etwas anders - der Ort, an dem alle Teile zu einem Kreis verbunden werden, sodass die Wiederverwendung derselben Adressen nicht funktioniert - Sie müssen das nächste freie Subnetz auswählen. Aus diesem Grund werden wir 192.168.0.0/16 als Basis nehmen und die davon befreien.
- Loopback-Adressen. Geben Sie ihnen den gesamten Bereich 172.16.0.0/12 .
- Leaf - at / 25 per DC - die gleichen 128 Racks. Ordnen Sie der Region mit / 23 zu.
- Wirbelsäule - von / 28 am DC - bis zu 16 Wirbelsäulen. Ordnen Sie der Region mit / 26 zu.
- Edge-Leaf - von / 29 auf DC - bis zu 8 Boxen. Ordnen Sie der Region mit / 27 zu.
Wenn wir im DC nicht genug von den ausgewählten Bereichen haben (aber sie werden nicht da sein - wir geben vor, hyper-skeylerostvo zu sein), wählen Sie einfach den nächsten Block aus.
Hier ist ein Bild mit IP-Adressierung.

Loopbacks:
| Präfix | Gerätefunktion | Region | DC |
| 172.16.0.0/23 | Rand | | |
| 172.16.0.0/27 | ru | |
| 172.16.0.0/29 | msk |
| 172.16.0.8/29 | kzn |
| 172.16.0.32/27 | sp | |
| 172.16.0.32/29 | bcn |
| 172.16.0.40/29 | mlg |
| 172.16.0.64/27 | cn | |
| 172.16.0.64/29 | sha |
| 172.16.0.72/29 | sia |
| 172.16.2.0/23 | Wirbelsäule | | |
| 172.16.2.0/26 | ru | |
| 172.16.2.0/28 | msk |
| 172.16.2.16/28 | kzn |
| 172.16.2.64/26 | sp | |
| 172.16.2.64/28 | bcn |
| 172.16.2.80/28 | mlg |
| 172.16.2.128/26 | cn | |
| 172.16.2.128/28 | sha |
| 172.16.2.144/28 | sia |
| 172.16.8.0/21 | blatt | | |
| 172.16.8.0/23 | ru | |
| 172.16.8.0/25 | msk |
| 172.16.8.128/25 | kzn |
| 172.16.10.0/23 | sp | |
| 172.16.10.0/25 | bcn |
| 172.16.10.128/25 | mlg |
| 172.16.12.0/23 | cn | |
| 172.16.12.0/25 | sha |
| 172.16.12.128/25 | sia |
Unterlage:
| Präfix | Region | DC |
| 10.0.0.0/17 | ru | |
| 10.0.0.0/19 | msk |
| 10.0.32.0/19 | kzn |
| 10.0.128.0/17 | sp | |
| 10.0.128.0/19 | bcn |
| 10.0.160.0/19 | mlg |
| 10.1.0.0/17 | cn | |
| 10.1.0.0/19 | sha |
| 10.1.32.0/19 | sia |
Laba
Zwei Anbieter. Ein Netzwerk. ADSM.
Wacholder + Arista. Ubuntu Gute alte Eva.
Die Menge der Ressourcen auf unserer Virtualochka in Miran ist immer noch begrenzt, sodass wir in der Praxis nur ein so vereinfachtes Netzwerk verwenden werden.
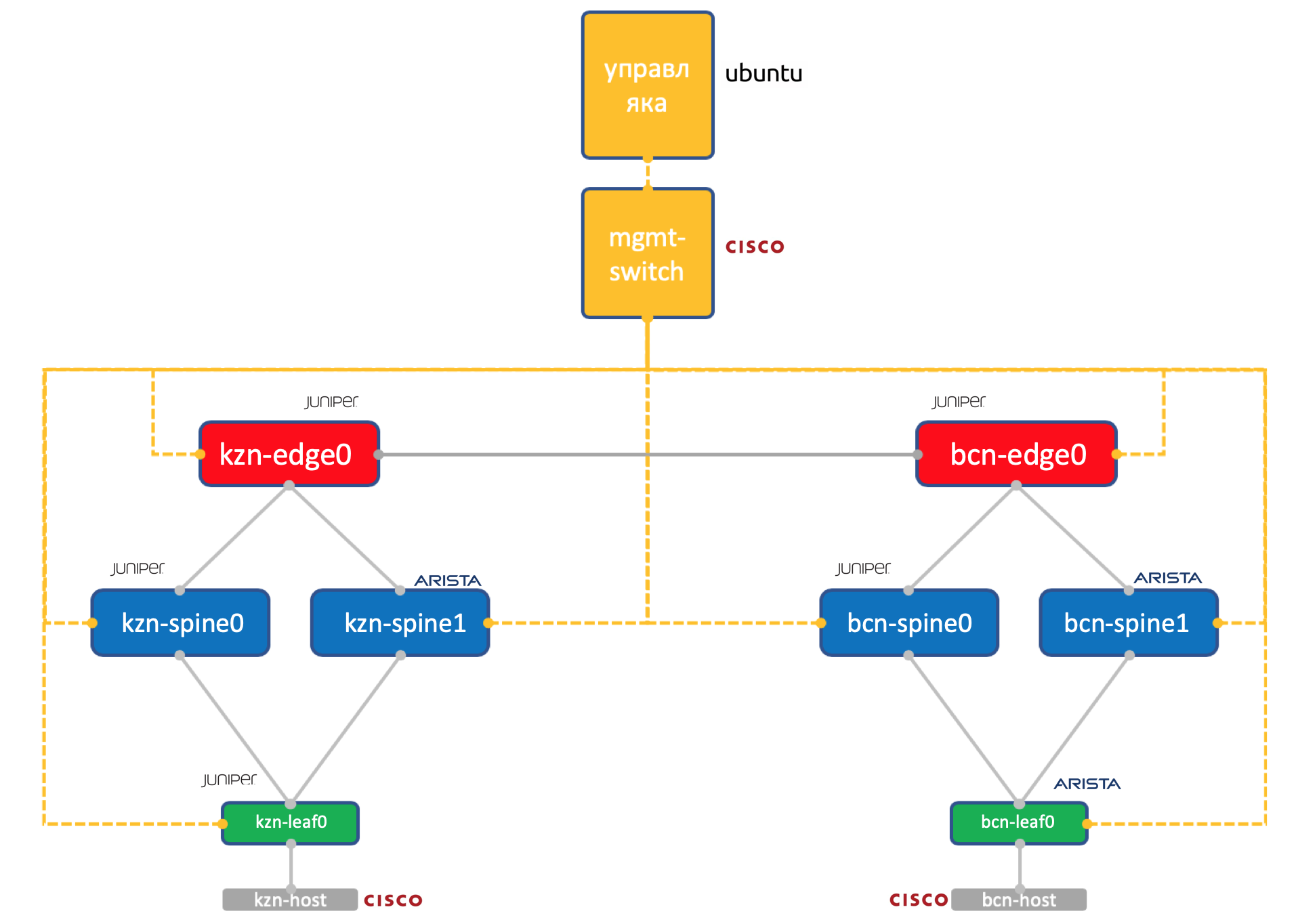
Zwei Rechenzentren: Kasan und Barcelona.
- Jeweils zwei Stacheln: Juniper und Arista.
- Jeweils ein Torus (Leaf) - Juniper und Arista, wobei ein Host verbunden ist (nehmen wir hierfür die leichte Cisco IOL).
- Ein Edge-Leaf-Knoten (bisher nur Juniper).
- Ein Cisco-Switch, der alle regiert.
- Zusätzlich zu Netzwerkboxen wurde eine virtuelle Verwaltungsmaschine gestartet. Ubuntu ausführen.
Sie hat Zugriff auf alle Geräte, IPAM / DCIM-Systeme, eine Reihe von Python-Skripten, Ansible und alles, was wir sonst noch brauchen, dreht sich darauf.
Die vollständige Konfiguration aller Netzwerkgeräte, die wir versuchen, mithilfe von Automatisierung zu reproduzieren.
Fazit
Auch akzeptiert? Unter jedem Artikel ein kurzes Fazit ziehen?
Deshalb haben wir uns für das
dreistufige Klose-Netzwerk innerhalb des DC entschieden, weil wir viel Ost-West-Verkehr erwarten und ECMP wollen.
Wir haben das Netzwerk in physische (Unterlage) und virtuelle (Überlagerung) unterteilt. In diesem Fall startet die Überlagerung vom Host aus, wodurch die Anforderungen an die Unterlagerung vereinfacht werden.
Wir haben BGP aufgrund seiner Skalierbarkeit und Flexibilität der Richtlinien als Routing-Protokoll für die Un-Relay-Netzwerke ausgewählt.
Wir werden separate Knoten für die DCI-Organisation haben - Edge-Leaf.
Auf der Amtsleitung befindet sich OSPF + LDP.
DCI wird basierend auf MPLS L3VPN implementiert.
Bei P2P-Verbindungen werden IP-Adressen anhand von Gerätenamen algorithmisch berechnet.
Lupbacks werden nach der Rolle der Geräte und ihrer Position nacheinander zugewiesen.
Unterlegungspräfixe - nur bei Blattschaltern nacheinander basierend auf ihrer Position.
Angenommen, wir haben die Geräte derzeit nicht installiert.
Daher besteht unser nächster Schritt darin, sie in die Systeme zu integrieren (IPAM, Inventarisierung), den Zugriff zu organisieren, eine Konfiguration zu generieren und bereitzustellen.
Im nächsten Artikel werden wir uns mit Netbox befassen, dem Inventarisierungs- und IP-Speicherverwaltungssystem im DC.
Vielen Dank
- Andrey Glazkov aka @glazgoo zum Korrekturlesen und Bearbeiten
- Alexander Klimenko aka @ v00lk zum Korrekturlesen und Bearbeiten
- Artyom Chernobay für KDPV