Heute wollen wir über das Insight-Driven-Konzept sprechen und wie es mit DataOps und ModelOps in die Praxis umgesetzt werden kann. Der Insight-Driven-Ansatz ist ein umfassendes Thema, über das wir in unserer kürzlich erstellten Bibliothek nützlicher Materialien zum Thema Datenmanagement ausführlich sprechen (der Link wird unten aufgeführt sein). In der heutigen Habratopica werden wir uns auf die wichtigsten Phasen des Lebenszyklus von Modellen des maschinellen Lernens konzentrieren Dies ist eines der Hauptthemen des Konzepts.

Was ist die Essenz des Insight-Driven-Ansatzes?
Viele Experten haben lange über die Bedeutung von
datengesteuert gesprochen , was natürlich im Allgemeinen absolut richtig ist, da bei diesem Ansatz Managemententscheidungen durch die Analyse von Daten effizienter getroffen werden und nicht nur Intuition und persönliche Führungserfahrung. Forrester-Analysten stellen
fest, dass Unternehmen, die sich bei ihren Aktivitäten auf Datenanalysen verlassen, durchschnittlich 30% schneller wachsen als Wettbewerber.
Wir alle wissen jedoch, dass das Unternehmen nicht von der Verfügbarkeit von Daten als solchen ausgeht, sondern von der Fähigkeit, mit ihnen zu arbeiten - also Erkenntnisse zu finden, die monetarisiert werden können und für die es sich lohnt, Daten zu sammeln, zu verarbeiten und zu analysieren. Aus diesem Grund sprechen wir speziell über den Insight-Driven-Ansatz als erweiterte Version von Data-Driven.
Meistens meinen die meisten Spezialisten beim Arbeiten mit Daten in erster Linie strukturierte Informationen innerhalb des Unternehmens. Vor nicht allzu langer Zeit haben wir jedoch darüber gesprochen, warum die große Mehrheit der Unternehmen nicht etwa 80% der potenziell verfügbaren Daten verwendet. Insight-Driven schafft lediglich die Grundlage für die Ergänzung des Bildes durch externe unstrukturierte Informationen sowie die Ergebnisse der Dateninterpretation, um nach impliziten Abhängigkeiten zwischen diesen zu suchen.
Der versprochene Link zu einer kompletten Materialbibliothek zum Thema Datenmanagement , wo es das erwähnte Video zu nicht verwendeten Daten gibt.
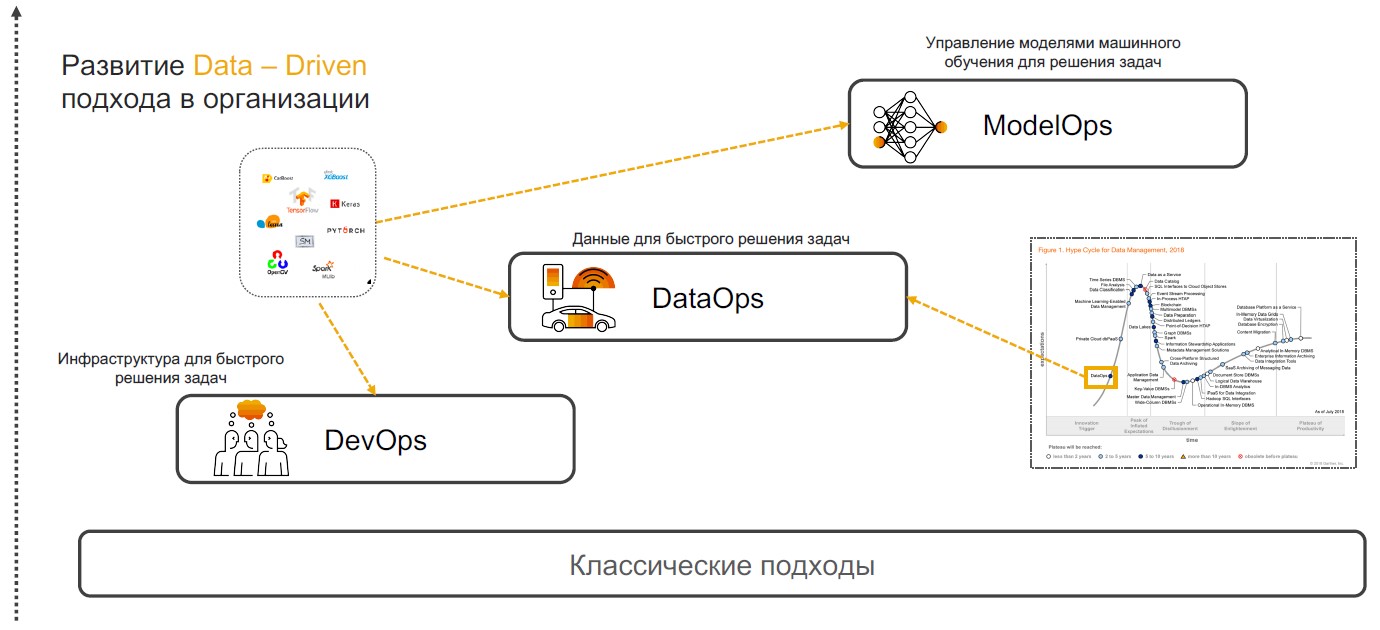
DevOps + DataOps + ModelOps
Insight-Driven-Praktiken basieren auf DevOps, DataOps und ModelOps. Lassen Sie uns darüber sprechen, warum eine Kombination dieser speziellen Praktiken die vollständige Umsetzung des Ansatzes gewährleisten kann.
 DevOps + DataOps
DevOps + DataOps . DevOps beinhaltet die Verkürzung der Zeit für die Produktfreigabe, die Aktualisierung und die Minimierung der Kosten für weiteren Support durch den Einsatz von Tools für die Versionskontrolle, die kontinuierliche Integration, das Testen und Überwachen sowie das Release-Management. Wenn wir diesen Praktiken ein Verständnis dafür hinzufügen, welche Daten sich innerhalb des Unternehmens befinden, wie Format und Struktur verwaltet werden, mit Tags versehen, Qualität
nachverfolgt , transformiert und aggregiert werden und die Möglichkeit haben,
Daten schnell zu analysieren und zu visualisieren, erhalten wir
DataOps . Der Schwerpunkt dieses Ansatzes liegt auf der Implementierung von Szenarien mithilfe von Modellen für maschinelles Lernen, die Entscheidungsunterstützung, Insightsuche und Prognose bieten.
ModelOps . Sobald das Unternehmen beginnt, Modelle für maschinelles Lernen aktiv einzusetzen, müssen sie verwaltet, Qualitätsmetriken überwacht, umgeschult, verglichen, aktualisiert und versioniert werden. ModOps ist eine Reihe von Methoden und Ansätzen, die das Lebenszyklusmanagement solcher Modelle vereinfachen. Es wird von Unternehmen verwendet, die sich mit einer Vielzahl von Modellen in verschiedenen Geschäftsbereichen befassen, z. B. Streaming-Services.
Die Implementierung des Insight-Driven-Ansatzes in einem Unternehmen ist keine triviale Aufgabe. Aber für diejenigen, die noch mit ihm zusammenarbeiten möchten, sagen wir Ihnen, wie das geht.
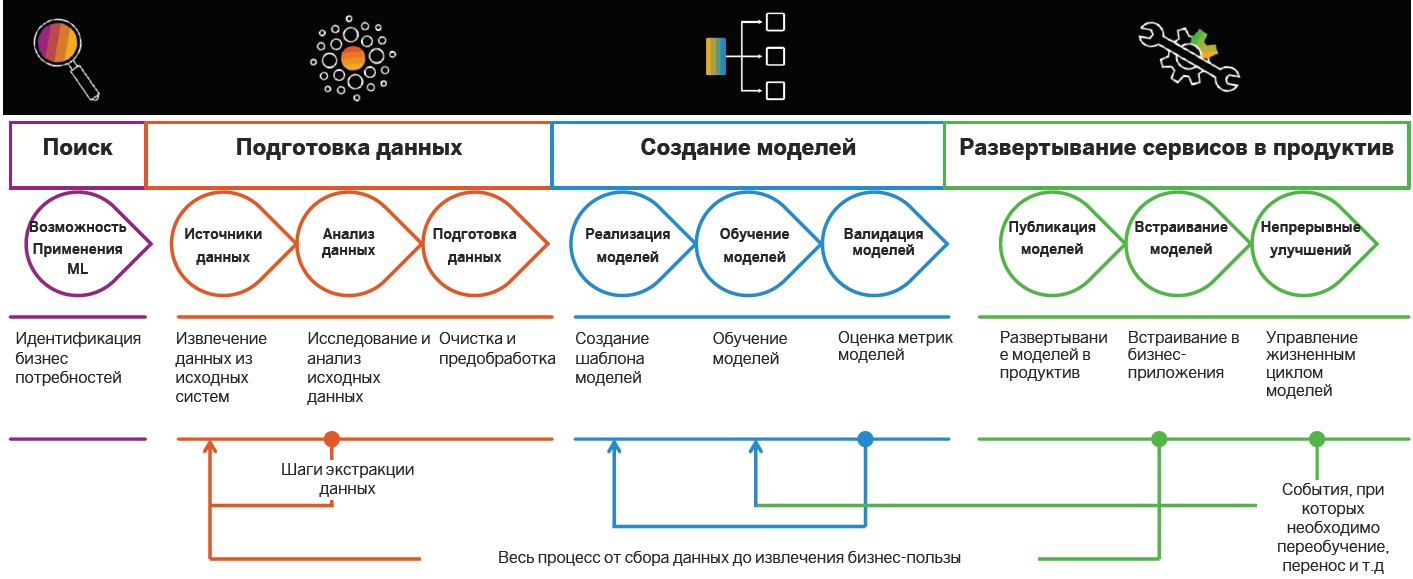
Recherche und Datenaufbereitung
Die Implementierung von Insight-Driven-Praktiken beginnt mit der Suche und Aufbereitung von Daten. Später werden sie analysiert und verwendet, um Modelle von MOs zu erstellen. Zuvor wurden jedoch Fälle ermittelt, in denen intelligente Algorithmen nützlich sein können.
Definition von Aufgaben . In dieser Phase setzt das Unternehmen Geschäftsziele, zum Beispiel die Steigerung des Gewinns auf dem Markt. Anschließend werden Geschäftsmessdaten ermittelt, um diese zu erreichen, z. B. eine Erhöhung der Anzahl neuer Kunden, die Größe des durchschnittlichen Schecks und der Conversion-Prozentsatz. Es gibt also Szenarien, in denen bereits nach relevanten Daten gesucht werden kann.
 Beschaffung und Datenanalyse
Beschaffung und Datenanalyse . Wenn die Ziele und Anweisungen für den Datenabruf definiert sind, ist die Zeit gekommen, die Quellen zu analysieren. Diese und die nachfolgenden Phasen der Entwicklung intelligenter Szenarien, die sich auf die Vorbereitung beziehen, beanspruchen 70-80% des Budgets der Unternehmen bei der Implementierung. Tatsache ist, dass die Qualität des Datensatzes die Genauigkeit der entworfenen maschinellen Lernmodelle beeinflusst. Die erforderlichen Informationen sind jedoch häufig auf verschiedene Systeme verteilt - sie können in relationalen Datenbanken wie MS SQL, Oracle, PostgreSQL, auf der Hadoop-Plattform und vielen anderen Quellen gespeichert sein. Zu diesem Zeitpunkt müssen Sie wissen, wo sich die relevanten Daten befinden und wie sie erfasst werden.
Oft entladen und verarbeiten Analysten alles manuell, was die Prozesse erheblich verlangsamt und das Fehlerrisiko erhöht. Wir bei SAP bieten unseren Kunden die Implementierung eines Metasystems an, das eine Verbindung zu den richtigen Quellen herstellt und auf Anfrage Daten sammelt.
So können Sie alle Tabellen, externen Pools mit unstrukturierten Daten und anderen Quellen katalogisieren - Tags festlegen (einschließlich hierarchischer) und relevante Informationen schnell erfassen. Wenn sich Informationen zu einem Client in verschiedenen Datenbanken befinden, ist es bedingt ausreichend, diese Entitäten anzugeben. Wenn Sie das nächste Mal einen „Client-Datensatz“ benötigen, wählen Sie eine fertige Vitrine.
Sobald die Datenquellen identifiziert sind, können Sie mit der
Verfolgung und Profilerstellung der Datenqualität fortfahren . Diese Operation ist erforderlich, um die Anzahl der Lücken und eindeutigen Werte zu ermitteln und die Gesamtqualität der Daten zu überprüfen. Für all dies können Sie Dashboards mit Regeln erstellen und alle Änderungen nachverfolgen.
Datentransformation . Der nächste Schritt ist die direkte Arbeit mit Daten, die die Aufgaben lösen sollen. Dazu werden die Daten gelöscht: geprüft, dedupliziert, in die Lücken gefüllt. Dieser Vorgang kann durch eine flussbasierte Programmierung vereinfacht werden. In diesem Fall haben wir es mit einer Abfolge von Operationen zu tun - einer Pipeline. Die Ausgabe kann für spätere Arbeiten an eine grafische Oberfläche oder ein anderes System gesendet werden. Hier werden die Datenhandler als Konstruktor (und je nach Szenario) zusammengestellt. Dies kann eine periodische oder Streaming-Verarbeitung oder ein REST-Service sein.

Das Konzept der Flow-basierten Programmierung eignet sich zur Lösung einer Vielzahl von Aufgaben: von der Umsatzprognose über die Bewertung der Servicequalität bis hin zur Ermittlung der Gründe für den Abfluss von Kunden. Es gibt zwei Tools zum Suchen und Aufbereiten von Daten in SAP. Das erste ist
SAP Data Intelligence für Datenanalysten. Im Gegensatz zu ähnlichen Plattformen funktioniert diese Lösung mit verteilten Daten und erfordert keine Zentralisierung. Sie bietet eine einheitliche Umgebung für die Implementierung, Veröffentlichung, Integration, Skalierung und Unterstützung von Modellen. Das zweite Tool ist
SAP Agile Data Preparation , ein kleiner Datenvorbereitungsservice für Analysten und Geschäftsanwender. Es verfügt über eine einfache Benutzeroberfläche, mit deren Hilfe ein Datensatz erfasst, Informationen gefiltert, verarbeitet und zugeordnet werden können. Es kann in einem Showcase zur Übertragung von Self-Service-BI veröffentlicht werden - Self-Service-Systeme zur Erstellung von Analyseszenarien (sie erfordern keine fundierten Kenntnisse auf dem Gebiet der Datenwissenschaft).
Modellerstellung
Nach der Vorbereitung sind Sie an der Reihe, maschinelle Lernmodelle zu erstellen. Hier werden unterschieden: Forschung, Prototyping und Produktivität. Die letzte Phase umfasst die Implementierung von Pipelines für die Schulung und Anwendung von Modellen.
Forschung und Prototyping . Derzeit sind viele thematische Frameworks und Bibliotheken verfügbar. Führend in der Nutzungshäufigkeit sind TensorFlow und PyTorch, deren Popularität im vergangenen Jahr um 243%
gestiegen ist . Die SAP-Plattform bietet die Möglichkeit, eines dieser Frameworks zu verwenden und kann flexibel mit Bibliotheken wie CatBoost von Yandex, LightGBM von Microsoft, Scikit-Learn und Pandas ergänzt werden. Sie können den
HANA-DataFrame weiterhin in der Hanaml-Bibliothek verwenden. Diese API ahmt Pandas nach, und mit HANA können Sie große Datenmengen mit "Lazy Computing" verarbeiten.
Für Prototyping-Modelle bieten wir Jupyter Lab an. Dies ist ein Open-Source-Tool für Data-Science-Profis. Wir haben es in das SAP-Ökosystem integriert und gleichzeitig die Funktionalität erweitert. Jupyter Lab arbeitet auf der Data Intelligence-Plattform und kann dank der integrierten sapdi-Bibliothek eine Verbindung zu allen in den vorherigen Schritten verbundenen Datenquellen herstellen, Experimente und Qualitätsmetriken zur weiteren Analyse überwachen.
Unabhängig davon sollten Notebooks, Datasets, Schulungs- und
Inferenz-Pipelines sowie Dienste für die Bereitstellung von Modellen konsistent sein. Verwenden Sie das ML-Skript (versioniertes Objekt), um alle diese Objekte zu kombinieren.
Model Training . Es gibt zwei Möglichkeiten, mit ML-Skripten zu arbeiten. Es gibt Modelle, die überhaupt nicht geschult werden müssen. Zum Beispiel bieten wir in SAP Data Intelligence Gesichtserkennungssysteme, automatische Übersetzung, OCR (optische Zeichenerkennung) und andere an. Sie arbeiten alle sofort. Auf der anderen Seite gibt es solche Modelle, die geschult und produktiv sein müssen. Dieses Training kann sowohl im Data Intelligence-Cluster selbst als auch auf externen Rechenressourcen stattfinden, die nur für die Dauer der Berechnungen verbunden sind.
"Under the hood" in SAP Data Intelligence ist die Kubernetes-Plattform, sodass alle Bediener an Docker-Container gebunden sind. Für die Arbeit mit dem Modell ist es ausreichend, die Docker-Datei zu beschreiben und Tags für die verwendeten Bibliotheken und Versionen an sie anzuhängen.
Eine andere Möglichkeit, Modelle zu erstellen, ist die Verwendung von AutoML. Dies sind automatisierte MO-Systeme. Solche Tools werden von
H2O ,
Microsoft ,
Google usw. entwickelt. Sie arbeiten
in dieser Richtung
am MIT . Die Ingenieure der Universität konzentrieren sich jedoch nicht auf Einbettung und Produktivität. SAP hat auch ein AutoML-System, das sich auf schnelle Ergebnisse konzentriert. Sie arbeitet in HANA und hat direkten Zugriff auf die Daten - sie müssen nirgendwo verschoben oder geändert werden. Jetzt entwickeln wir eine Lösung, die sich auf die Qualität der Modelle konzentriert - wir werden später eine Veröffentlichung ankündigen.
Lebenszyklus-Management . Die Bedingungen ändern sich, die Informationen sind veraltet, sodass die Genauigkeit von MO-Modellen mit der Zeit abnimmt. Nachdem wir neue Daten gesammelt haben, können wir das Modell neu trainieren und die Ergebnisse verfeinern. Beispielsweise verwendet ein großer Getränkehersteller Informationen zu Verbrauchervorlieben in 200 verschiedenen Ländern, um intelligente Systeme zu trainieren. Das Unternehmen berücksichtigt den Geschmack der Menschen, die Zuckermenge, den Kaloriengehalt von Getränken und sogar die Produkte, die Konkurrenzmarken in den Zielmärkten anbieten. MO-Modelle bestimmen automatisch, welche der Hunderte von Produkten das Unternehmen in einer bestimmten Region am besten akzeptiert.
 Agentenbasierte Komponenten im SAP Data Hub wiederverwenden
Agentenbasierte Komponenten im SAP Data Hub wiederverwendenModellversionen und -aktualisierungen müssen jedoch auch durchgeführt werden, wenn neue Algorithmen und Hardwarekomponentenaktualisierungen veröffentlicht werden. Ihre Implementierung kann die Genauigkeit und Qualität der in der Arbeit verwendeten Modelle verbessern.
Insight-Driven für Unternehmenswachstum
Der oben beschriebene Ansatz zur Verwaltung der Lebenszyklusphasen von Modellen des maschinellen Lernens ist in der Tat ein universeller Rahmen, der es einem Unternehmen ermöglicht, einsichtsorientierter zu werden und die Arbeit mit Daten als Haupttreiber für das Unternehmenswachstum zu nutzen. Organisationen, die dieses Konzept verkörpern, wissen mehr, wachsen schneller und arbeiten unserer Meinung nach viel interessanter mit dieser Spitzentechnologie!
Weitere Informationen zum Erstellen des Insight-Driven-Konzepts finden Sie in unserer
Bibliothek nützlicher Datenverwaltungsmaterialien , in der wir Videos, nützliche Broschüren und Testzugriffe auf SAP-Systeme gesammelt haben.