Hallo, ich heiße Eugene. Ich arbeite in der Suchinfrastruktur von Yandex.Market. Ich möchte der Habr-Community etwas über die interne Küche des Marktes erzählen - aber es gibt etwas zu erzählen. Zuallererst, wie Market Search, Prozesse und Architektur funktionieren. Wie gehen wir mit Notsituationen um: Was passiert, wenn ein Server abstürzt? Und wenn es 100 solcher Server gibt?
Außerdem erfahren Sie sofort, wie wir neue Funktionen auf einer Reihe von Servern implementieren. Und wie Sie komplexe Services direkt in der Produktion testen können, ohne dass dies den Benutzern unangenehm wird. Im Allgemeinen, wie die Suche nach dem Markt funktioniert, so dass es allen gut geht.
Ein wenig über uns: Welches Problem lösen wir?
Wenn Sie Text eingeben, anhand von Parametern nach Produkten suchen oder Preise in verschiedenen Geschäften vergleichen, gehen alle Anfragen beim Suchdienst ein. Die Suche ist der größte Dienst auf dem Markt.
Wir bearbeiten alle Suchanfragen: von market.yandex.ru, famous.ru, dem Supercheck-Service, Yandex.Advisor und mobilen Anwendungen. Wir nehmen auch Warenangebote in die Suchergebnisse auf yandex.ru auf.
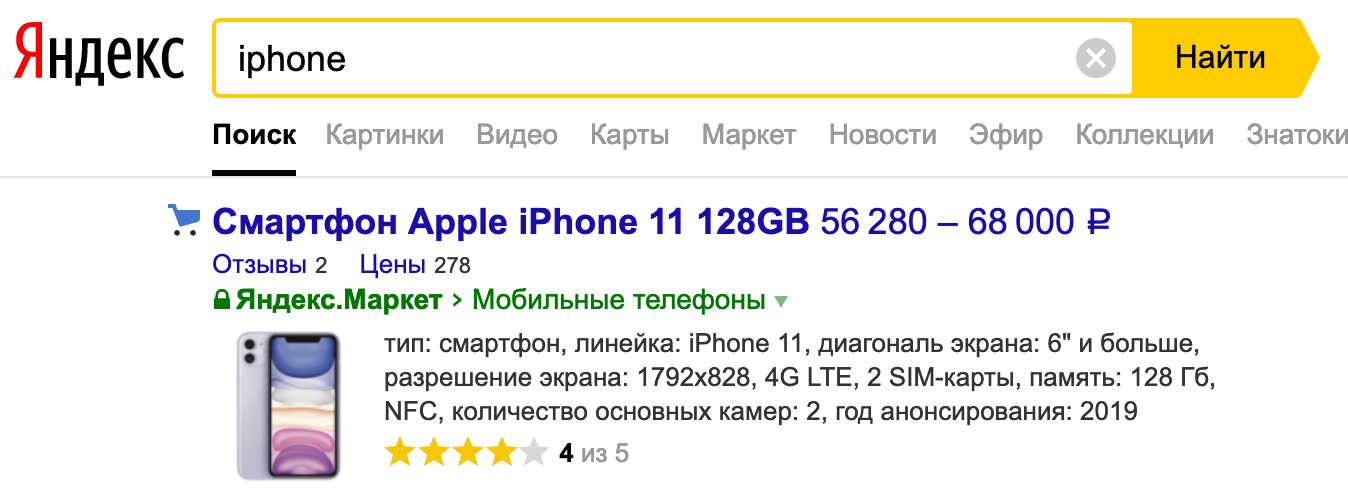
Mit Suchdienst meine ich nicht nur die direkte Suche, sondern auch eine Datenbank mit allen Angeboten auf dem Markt. Der Maßstab ist folgender: Pro Tag werden mehr als eine Milliarde Suchanfragen bearbeitet. Und alles sollte schnell und ohne Unterbrechungen funktionieren und immer das gewünschte Ergebnis liefern.
Was ist was: Marktarchitektur
Beschreiben Sie kurz die aktuelle Architektur des Marktes. Herkömmlicherweise kann es durch das folgende Schema beschrieben werden:
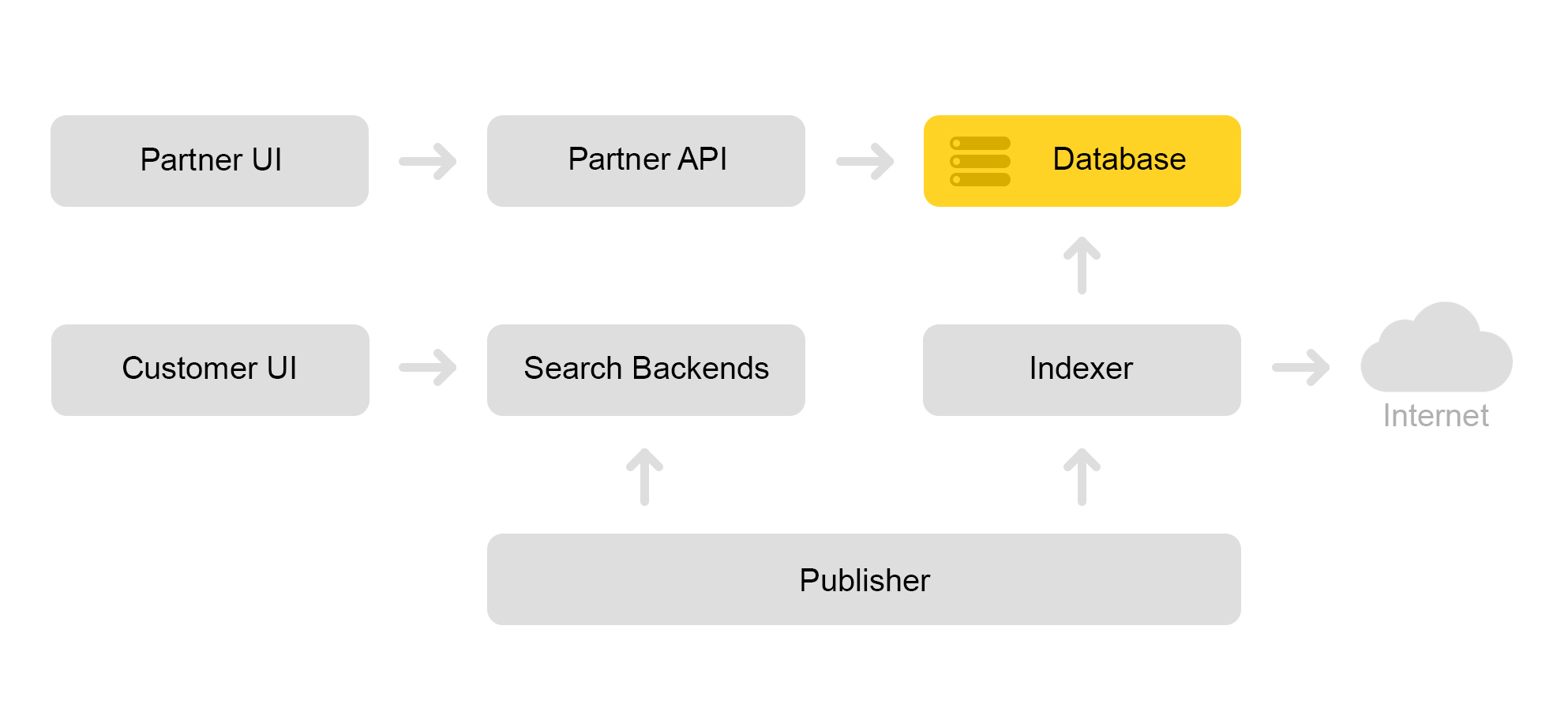
Nehmen wir an, ein Partnergeschäft kommt zu uns. Er sagt, ich möchte ein Spielzeug verkaufen: diese böse Katze mit einem Quietscher. Und eine böse Katze ohne Hochtöner. Und nur eine Katze. Dann muss das Geschäft Angebote erstellen, nach denen der Markt sucht. Der Store bildet eine spezielle XML-Datei mit Angeboten und teilt den Pfad zu dieser XML-Datei über eine Partnerschnittstelle mit. Anschließend lädt der Indexer diese XML-Datei regelmäßig herunter, überprüft sie auf Fehler und speichert alle Informationen in einer riesigen Datenbank.
Es gibt viele solcher gespeicherten XML-Dateien. Aus dieser Datenbank wird ein Suchindex erstellt. Der Index wird im internen Format gespeichert. Nachdem der Index erstellt wurde, lädt der Layout-Dienst ihn in die Suchmaschinen hoch.
Infolgedessen wird eine böse Katze mit einem Quietscher in der Datenbank angezeigt, und auf dem Server wird ein Katzenindex angezeigt.
Ich werde im Teil über die Sucharchitektur darüber sprechen, wie wir nach einer Katze suchen.
Marktsucharchitektur
Wir leben in der Welt der Mikrodienste: Jede eingehende Anfrage an
market.yandex.ru verursacht viele Unterabfragen, und Dutzende von Diensten beteiligen sich an deren Verarbeitung. Das Diagramm zeigt nur einige:
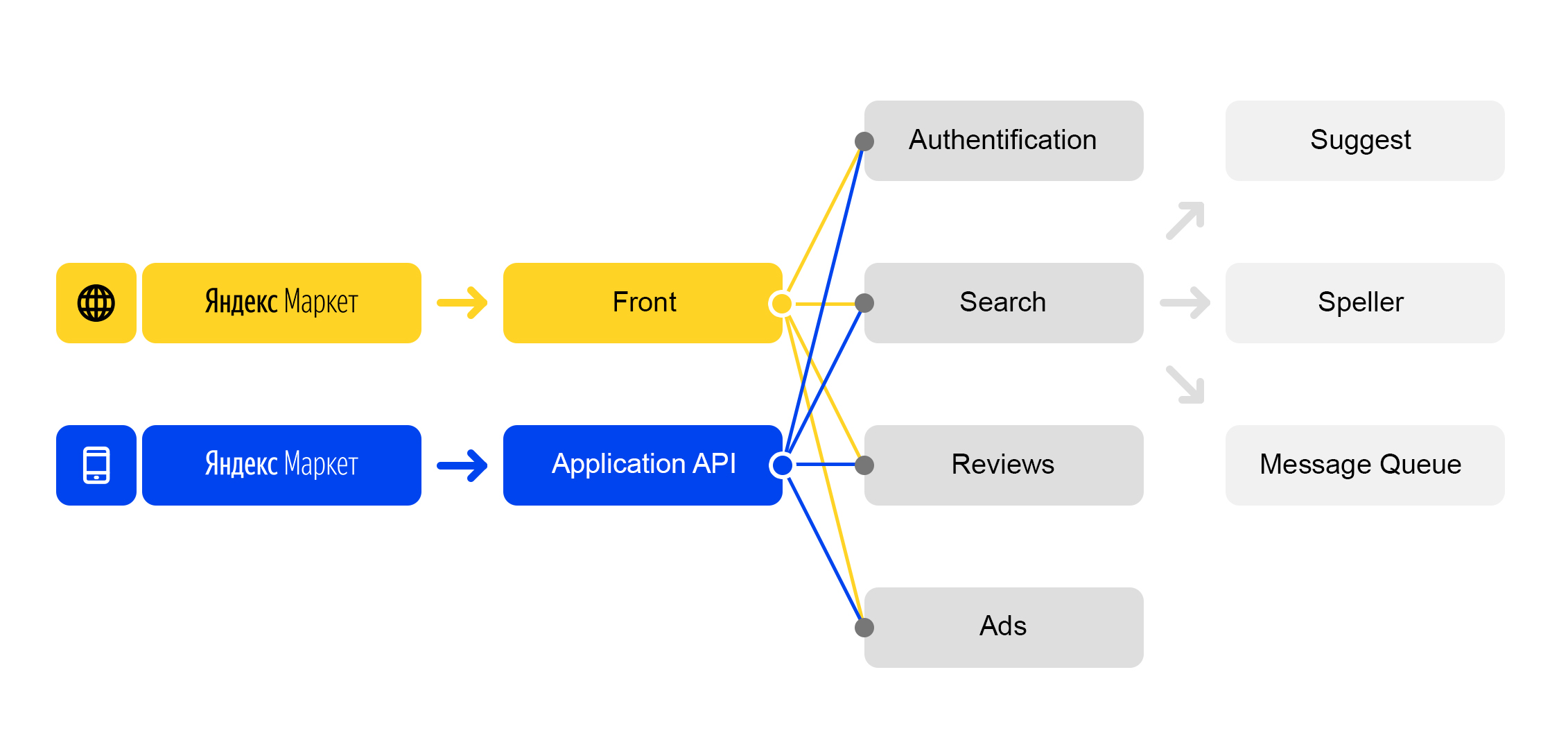 Vereinfachtes Anforderungsverarbeitungsschema
Vereinfachtes AnforderungsverarbeitungsschemaJeder Service hat eine wunderbare Sache - einen eigenen Balancer mit einem eindeutigen Namen:
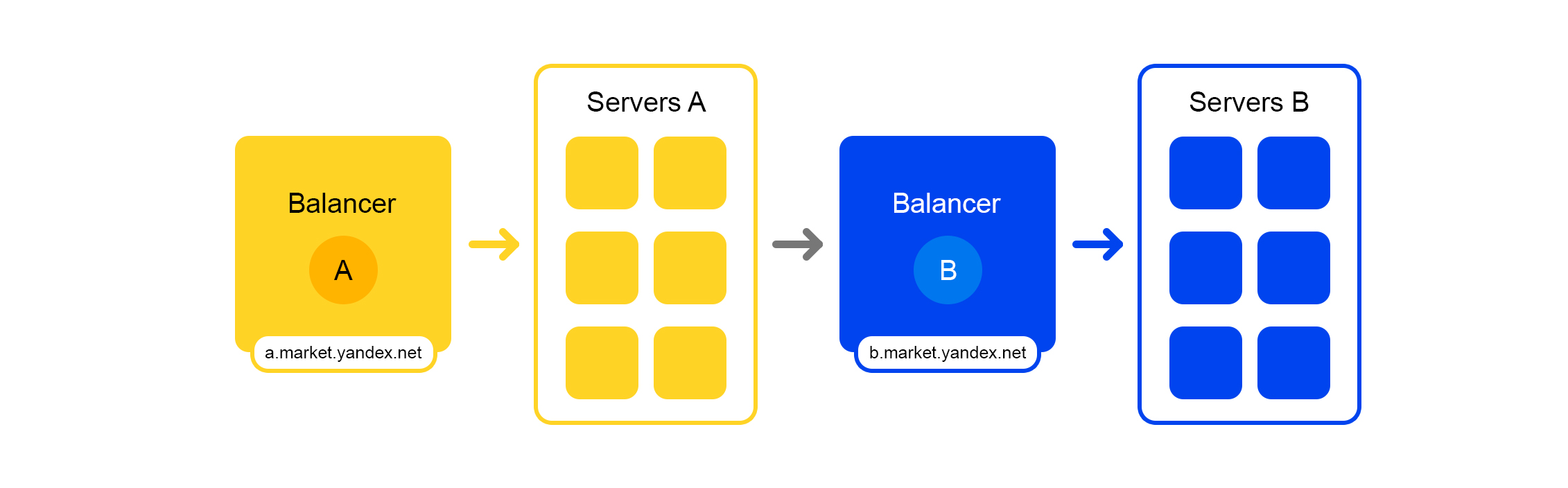
Der Balancer bietet uns große Flexibilität bei der Verwaltung des Dienstes: Sie können beispielsweise die Server ausschalten, was häufig für Updates erforderlich ist. Der Balancer erkennt, dass der Server nicht verfügbar ist, und leitet Anforderungen automatisch an andere Server oder Rechenzentren weiter. Wenn Sie einen Server hinzufügen oder entfernen, wird die Last automatisch zwischen den Servern umverteilt.
Der eindeutige Name des Balancers hängt nicht vom Rechenzentrum ab. Wenn Service A eine Anfrage an B sendet, leitet Balancer B die Anfrage standardmäßig an das aktuelle Rechenzentrum weiter. Wenn der Dienst im aktuellen Rechenzentrum nicht verfügbar ist oder nicht vorhanden ist, wird die Anforderung an andere Rechenzentren umgeleitet.
Ein einziger FQDN für alle Rechenzentren ermöglicht es Service A, sich generell von Standorten zu lösen. Seine Anfrage an Service B wird immer bearbeitet. Eine Ausnahme ist der Fall, wenn sich der Service in allen Rechenzentren befindet.
Bei diesem Balancer ist aber nicht alles so rosig: Wir haben eine zusätzliche Zwischenkomponente. Der Balancer ist möglicherweise instabil und dieses Problem wird durch redundante Server behoben. Es gibt auch eine zusätzliche Verzögerung zwischen den Diensten A und B. In der Praxis beträgt sie jedoch weniger als 1 ms, und für die meisten Dienste ist dies nicht kritisch.
Gegen das Unerwartete: ausgleichende und belastbare Suchdienste
Stellen Sie sich einen Zusammenbruch vor: Sie müssen eine Katze mit einem Quietscher finden, aber der Server stürzt ab. Oder 100 Server. Wie komme ich raus? Verlassen wir den Benutzer wirklich ohne Katze?
Die Situation ist schrecklich, aber wir sind bereit dafür. Ich sage es dir in der richtigen Reihenfolge.
Die Suchinfrastruktur befindet sich in mehreren Rechenzentren:
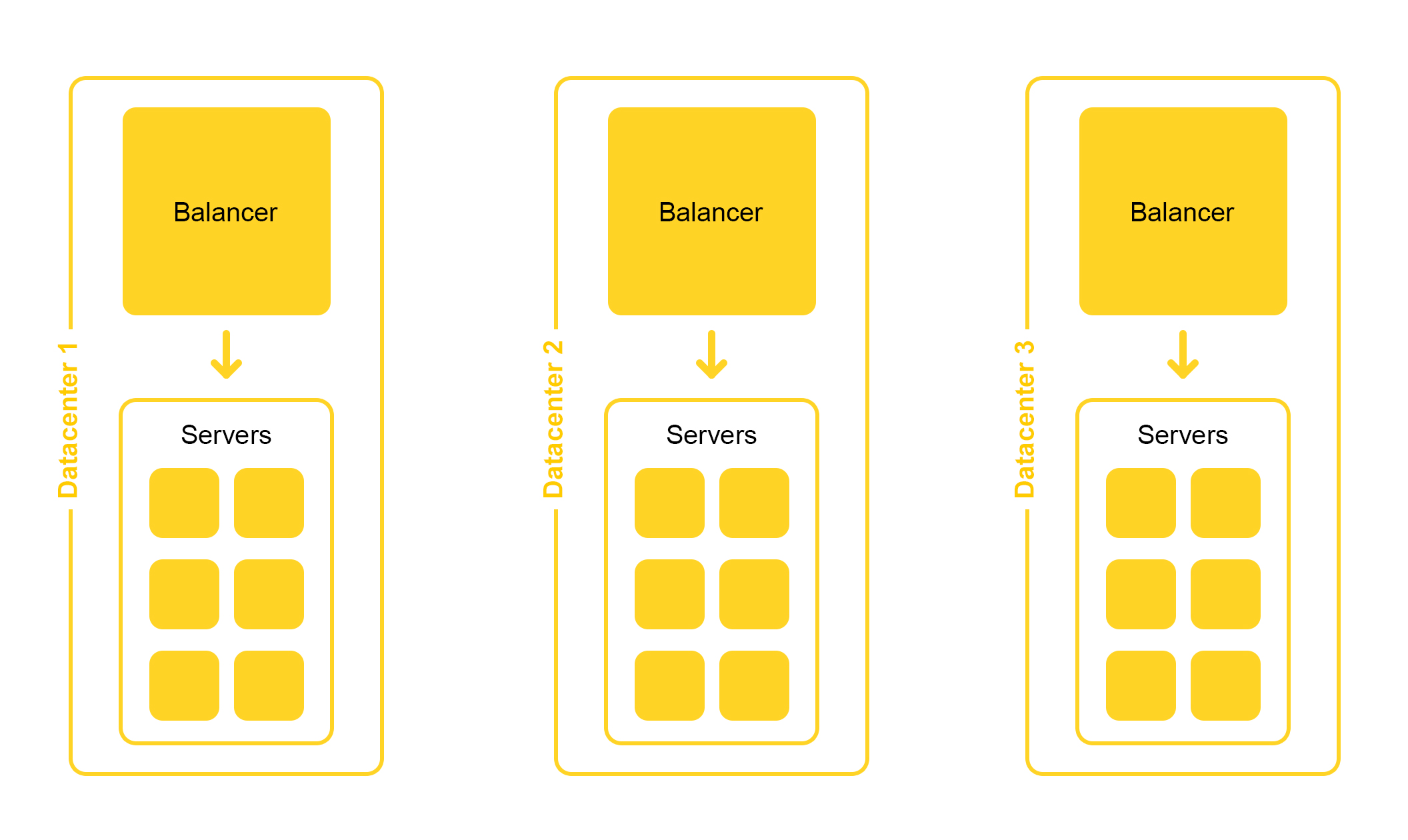
Beim Entwurf legen wir die Möglichkeit fest, ein Rechenzentrum zu deaktivieren. Das Leben ist voller Überraschungen - zum Beispiel kann ein Bagger ein unterirdisches Kabel durchtrennen (ja, das war so). Die Kapazitäten in den verbleibenden Rechenzentren sollten ausreichen, um der Spitzenlast standzuhalten.
Betrachten Sie ein einzelnes Rechenzentrum. In jedem Rechenzentrum das gleiche Schema von Balancern:
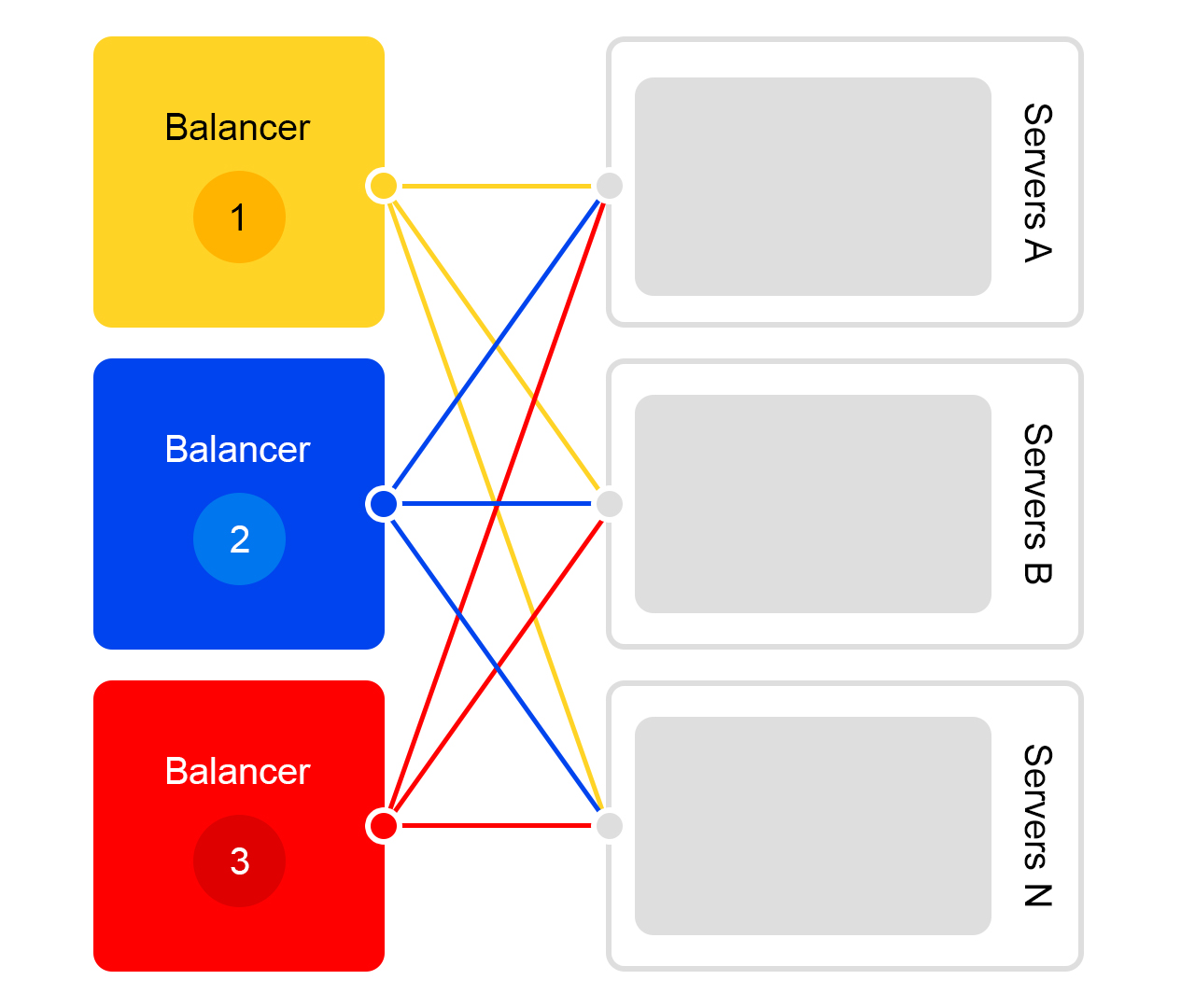
Ein Balancer besteht aus mindestens drei physischen Servern. Eine solche Redundanz dient der Zuverlässigkeit. Balancer arbeiten mit HAProx.
Wir haben uns für HAProx aufgrund seiner hohen Leistung, des geringen Ressourcenbedarfs und der breiten Funktionalität entschieden. In jedem Server funktioniert unsere Suchsoftware.
Die Ausfallwahrscheinlichkeit eines Servers ist gering. Wenn Sie jedoch über viele Server verfügen, steigt die Wahrscheinlichkeit, dass mindestens einer ausfällt.
In der Realität passiert Folgendes: Server stürzen ab. Daher müssen Sie den Status aller Server ständig überwachen. Wenn der Server nicht mehr reagiert, wird er automatisch vom Datenverkehr getrennt. Zu diesem Zweck verfügt HAProxy über eine integrierte Integritätsprüfung. Es wird einmal pro Sekunde an alle Server mit der HTTP-Anforderung "/ ping" gesendet.
Eine weitere Funktion von HAProxy: Mit Agent-Check können Sie alle Server gleichmäßig laden. Zu diesem Zweck stellt HAProxy eine Verbindung zu allen Servern her und gibt ihre Gewichtung abhängig von der aktuellen Auslastung von 1 bis 100 zurück. Die Gewichtung wird basierend auf der Anzahl der Anforderungen in der Verarbeitungswarteschlange und der Auslastung des Prozessors berechnet.
Jetzt geht es darum, eine Katze zu finden. Anfragen der Form
/ Suche? Text = wütend + Katze kommen zur
Suche . Für eine schnelle Suche muss der gesamte Katzenindex im RAM abgelegt werden. Selbst das Lesen von einer SSD ist nicht schnell genug.
Es war einmal eine kleine Angebotsbasis und es gab genug RAM für einen Server. Als die Angebotsdatenbank wuchs, passte nicht mehr alles in diesen Arbeitsspeicher, und die Daten wurden in zwei Teile geteilt: Scherbe 1 und Scherbe 2.

Aber es kommt immer vor: Jede Lösung, auch eine gute, wirft andere Probleme auf.
Der Balancer ging immer noch zu einem Server. Auf der Maschine, auf der die Anfrage eingegangen ist, war jedoch nur die Hälfte des Index vorhanden. Der Rest war auf anderen Servern. Daher musste der Server zu einem benachbarten Computer gehen. Nachdem die Daten von beiden Servern empfangen wurden, wurden die Ergebnisse kombiniert und neu organisiert.
Da der Balancer die Anforderungen gleichmäßig verteilt, wurden alle Server neu angeordnet und gaben nicht nur Daten weiter.
Das Problem trat auf, wenn der benachbarte Server nicht verfügbar war. Die Lösung bestand darin, mehrere Server mit unterschiedlichen Prioritäten als "benachbarten" Server anzugeben. Zuerst wurde die Anfrage an die Server im aktuellen Rack gesendet. Wenn keine Antwort empfangen wurde, wurde die Anfrage an alle Server in diesem Rechenzentrum gesendet. Und zu guter Letzt ging die Anfrage an andere Rechenzentren.
Mit zunehmender Anzahl von Vorschlägen wurden die Daten in vier Teile geteilt. Aber das war nicht die Grenze.
Nun wird eine Konfiguration von acht Shards verwendet. Um Speicherplatz zu sparen, wurde der Index außerdem in den Suchteil (über den die Suche stattfindet) und den Snippet-Teil (der nicht an der Suche beteiligt ist) unterteilt.
Ein Server enthält nur Informationen zu einem Shard. Um eine Suche im gesamten Index durchzuführen, müssen Sie daher auf acht Servern suchen, die unterschiedliche Shards enthalten.
Server sind in Clustern gruppiert. Jeder Cluster enthält acht Suchmaschinen und ein Snippet.
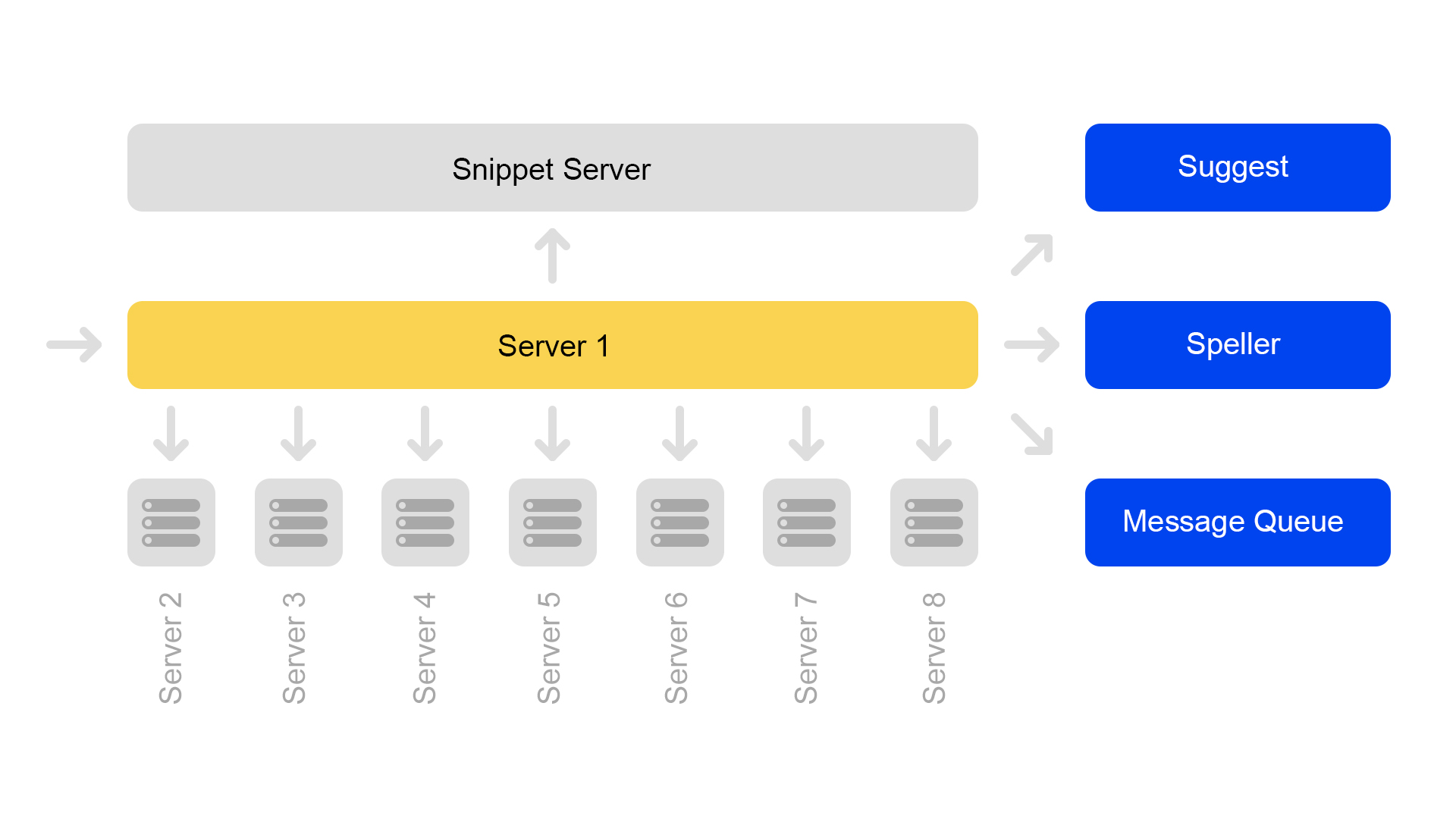
Die Schlüsselwertdatenbank mit statischen Daten wird auf dem Snippet-Server ausgeführt. Sie werden für die Ausstellung von Dokumenten benötigt, beispielsweise eine Beschreibung einer Katze mit einem Quietscher. Die Daten werden speziell auf einem separaten Server abgelegt, um den Speicher der Suchmaschinen nicht zu belasten.
Da Dokument-IDs nur innerhalb eines Index eindeutig sind, kann es vorkommen, dass sich keine Dokumente in den Snippets befinden. Na ja oder so auf einer ID wird es andere Inhalte geben. Damit die Suche funktioniert und die Suche stattfinden kann, besteht daher ein Bedarf an der Konsistenz des gesamten Clusters. Ich werde später darüber sprechen, wie wir die Konsistenz überwachen.
Die Suche selbst ist wie folgt organisiert: Eine Suchabfrage kann an einen von acht Servern gesendet werden. Angenommen, er ist zu Server 1 gekommen. Dieser Server verarbeitet alle Argumente und versteht, wonach und wie gesucht werden muss. Abhängig von der eingehenden Anforderung kann der Server zusätzliche Anforderungen an externe Dienste für die erforderlichen Informationen stellen. Einer Anfrage können bis zu zehn Anfragen an externe Dienste folgen.
Nach dem Sammeln der erforderlichen Informationen beginnt eine Suche in der Angebotsdatenbank. Dazu werden für alle acht Server im Cluster Unterabfragen durchgeführt.
Nach Erhalt der Antworten werden die Ergebnisse zusammengefasst. Zum Generieren des Problems benötigen Sie möglicherweise mehrere weitere Unterabfragen an den Snippet-Server.
Suchanfragen innerhalb des Clusters lauten:
/ shard1? Text = angry + cat . Außerdem werden einmal pro Sekunde Unterabfragen der Form:
/ status zwischen allen Servern innerhalb des Clusters durchgeführt.
Die
/ status- Anforderung erkennt eine Situation, in der der Server nicht verfügbar ist.
Außerdem wird gesteuert, dass auf allen Servern die Suchmaschinenversion und die Indexversion identisch sind, da sonst inkonsistente Daten im Cluster vorhanden sind.
Trotz der Tatsache, dass ein Snippet-Server Anfragen von acht Suchmaschinen verarbeitet, ist sein Prozessor sehr schwach ausgelastet. Aus diesem Grund übertragen wir jetzt Snippet-Daten an einen separaten Dienst.
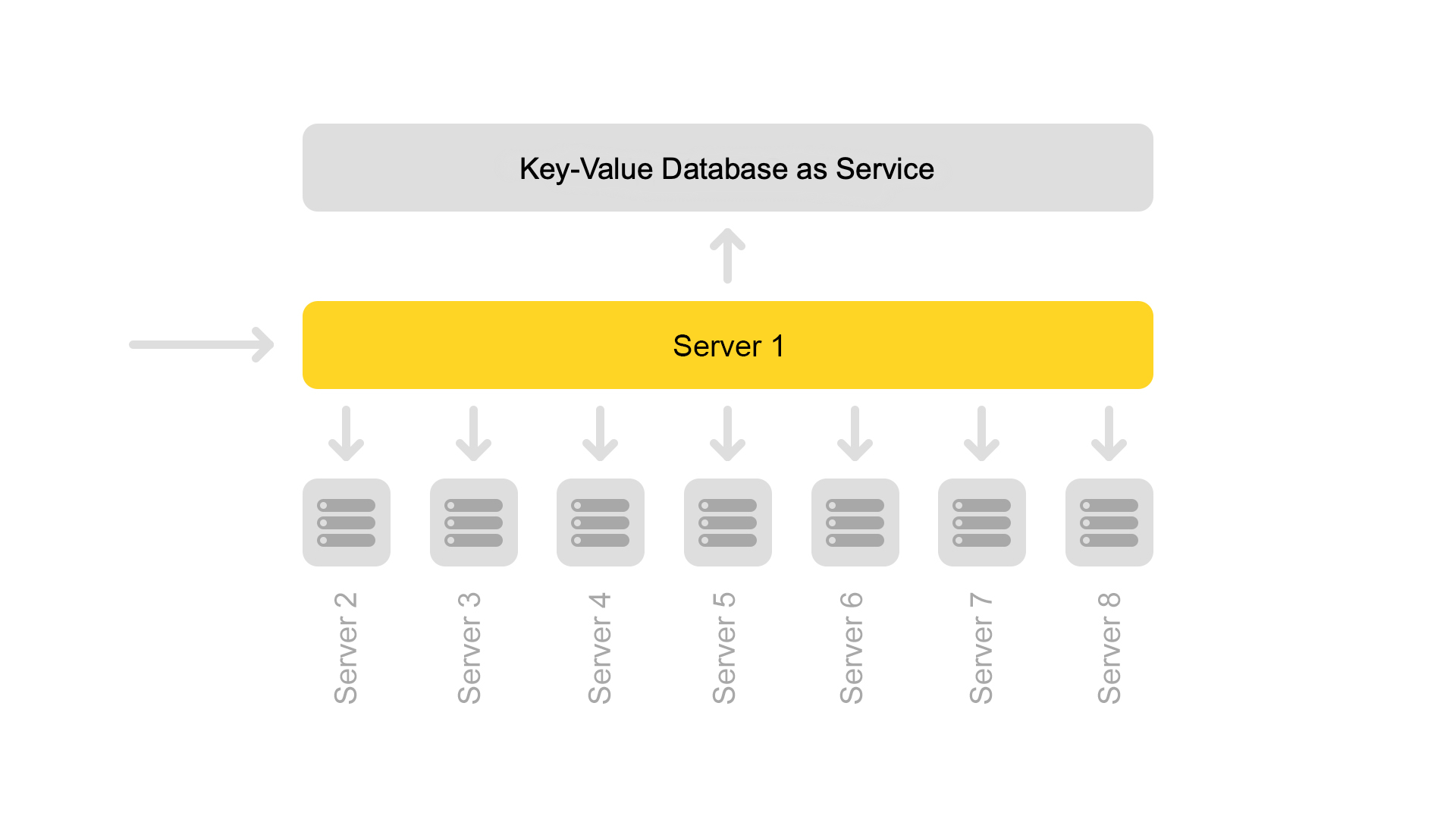
Für die Datenübertragung haben wir Universalschlüssel für Dokumente eingeführt. Jetzt ist die Situation unmöglich, wenn ein Schlüssel Inhalt aus einem anderen Dokument zurückgibt.
Der Übergang zu einer anderen Architektur ist jedoch noch nicht abgeschlossen. Jetzt wollen wir den dedizierten Snippet-Server loswerden. Und dann in der Regel weg von der Clusterstruktur. Auf diese Weise können wir die Skalierung problemlos fortsetzen. Ein zusätzlicher Bonus ist eine erhebliche Eisenersparnis.
Und nun zu den Gruselgeschichten mit Happy End. Betrachten Sie mehrere Fälle von Nichtverfügbarkeit des Servers.
Schrecklich ist passiert: Ein Server ist nicht verfügbar
Angenommen, ein Server ist nicht verfügbar. Die anderen Server im Cluster antworten möglicherweise weiterhin, die Suchergebnisse sind jedoch unvollständig.
Durch eine Statusprüfung erkennen benachbarte Server, dass einer nicht verfügbar ist. Um die Vollständigkeit zu gewährleisten, antworten alle Server im Cluster auf die
/ ping- Anforderung an den Balancer, dass sie ebenfalls nicht verfügbar sind. Es stellt sich heraus, dass alle Server im Cluster gestorben sind (was nicht der Fall ist). Dies ist der Hauptnachteil unseres Cluster-Schemas - deshalb wollen wir davon wegkommen.
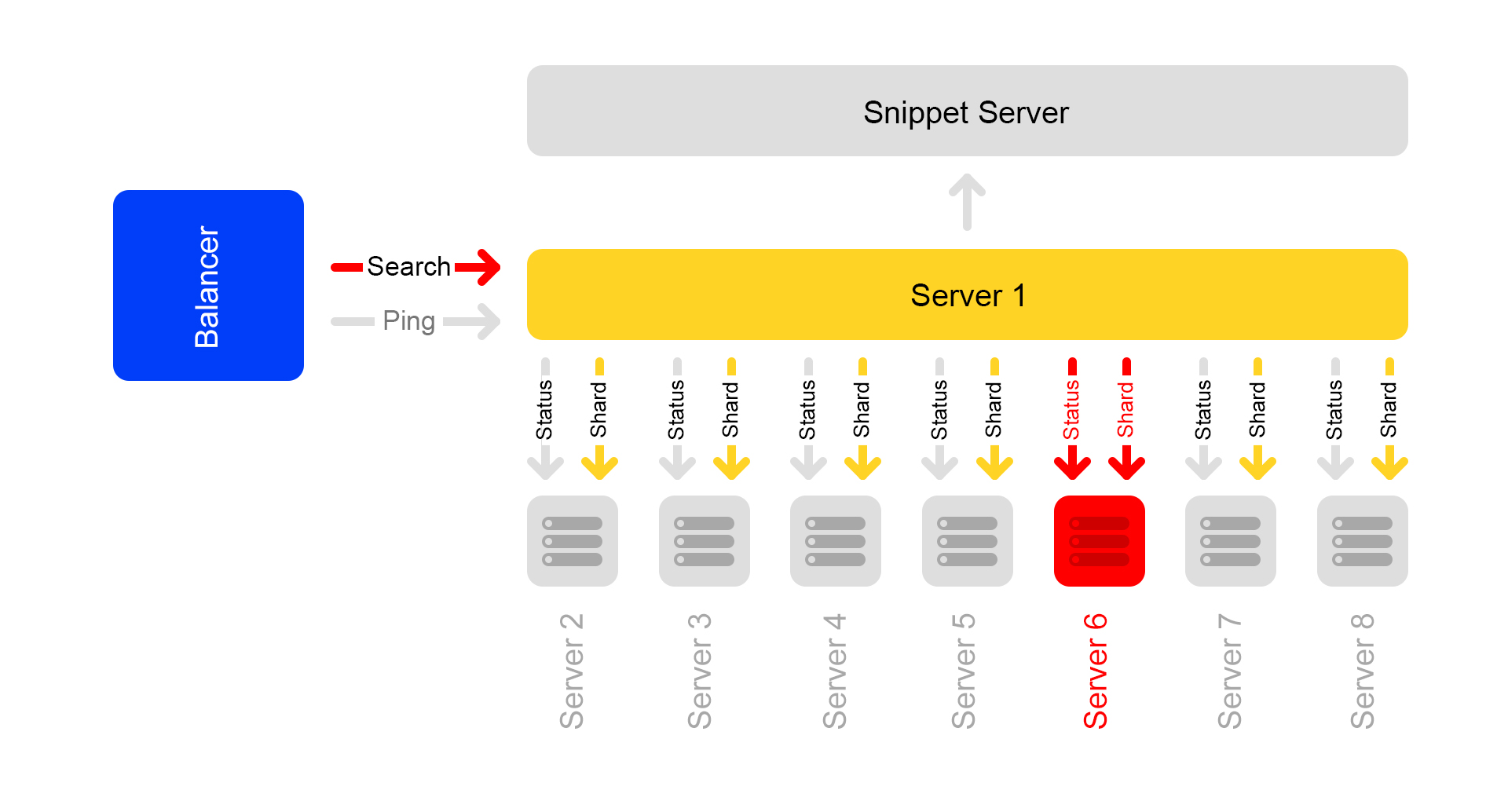
Anfragen, die mit einem Fehler endeten, fragt der Balancer erneut auf anderen Servern.
Außerdem sendet der Balancer keinen Benutzerverkehr mehr an tote Server, überprüft jedoch weiterhin deren Status.
Sobald der Server verfügbar ist, reagiert er auf
/ ping . Sobald normale Antworten auf Pings von toten Servern eingehen, beginnen Balancer, Benutzerverkehr dorthin zu senden. Der Cluster ist wiederhergestellt, Prost.
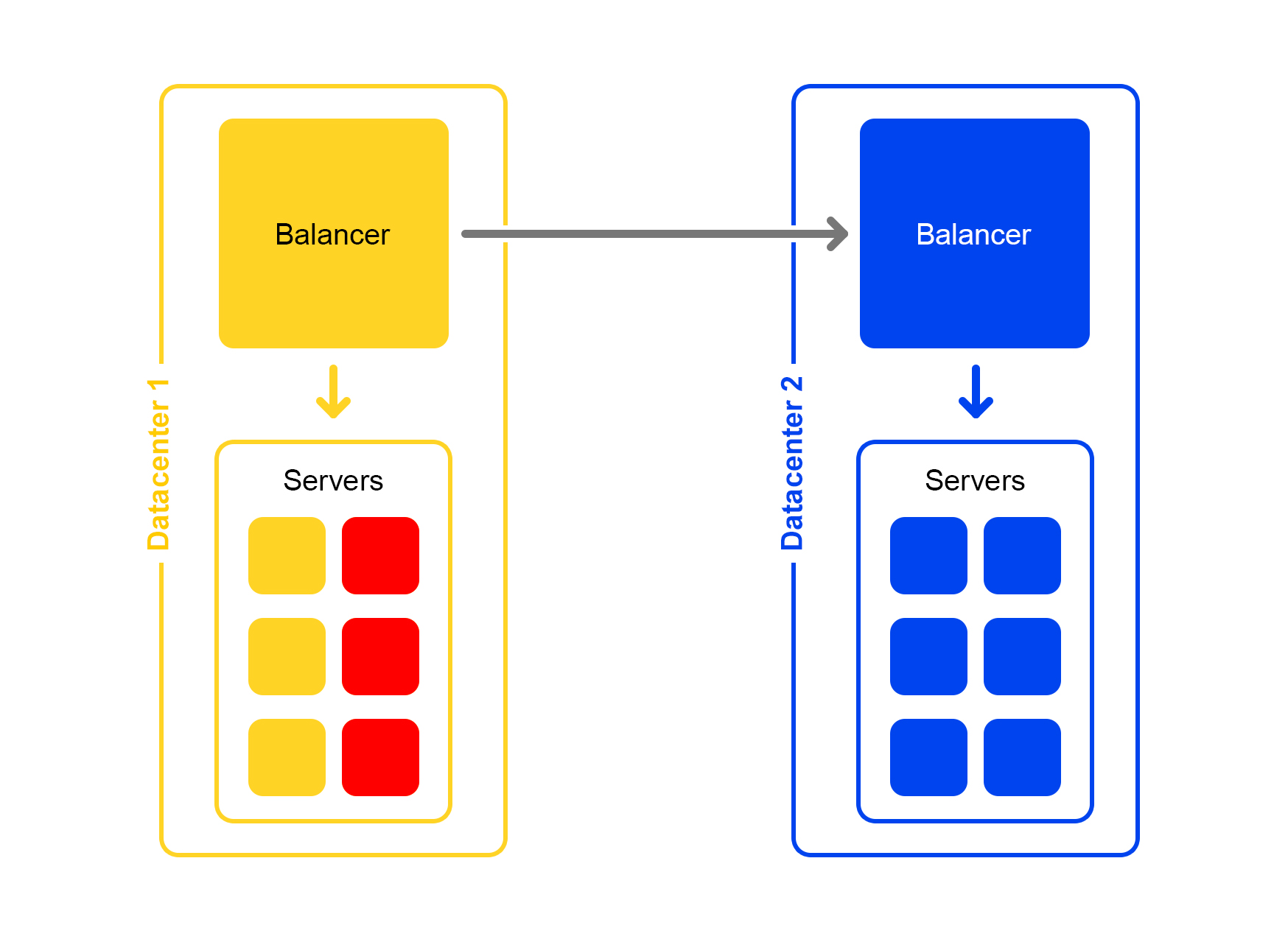
Schlimmer noch: Viele Server sind nicht verfügbar
Ein erheblicher Teil der Server im Rechenzentrum ist heruntergefahren. Was tun, wo laufen? Der Balancer kommt wieder zur Rettung. Jeder Balancer speichert ständig die aktuelle Anzahl der Live-Server. Er berücksichtigt immer die maximale Verkehrsmenge, die das aktuelle Rechenzentrum verarbeiten kann.
Wenn viele Server im Rechenzentrum ausfallen, erkennt der Balancer, dass dieses Rechenzentrum nicht den gesamten Datenverkehr verarbeiten kann.
Anschließend wird der überschüssige Datenverkehr zufällig auf andere Rechenzentren verteilt. Alles funktioniert, jeder ist glücklich.
Wie wir es machen: Releases veröffentlichen
Jetzt erfahren Sie, wie wir die am Service vorgenommenen Änderungen veröffentlichen. Hier haben wir den Weg der Rationalisierung beschritten: Die Einführung eines neuen Releases ist fast vollständig automatisiert.
Wenn das Projekt eine bestimmte Anzahl von Änderungen enthält, wird automatisch eine neue Version erstellt und deren Assembly gestartet.
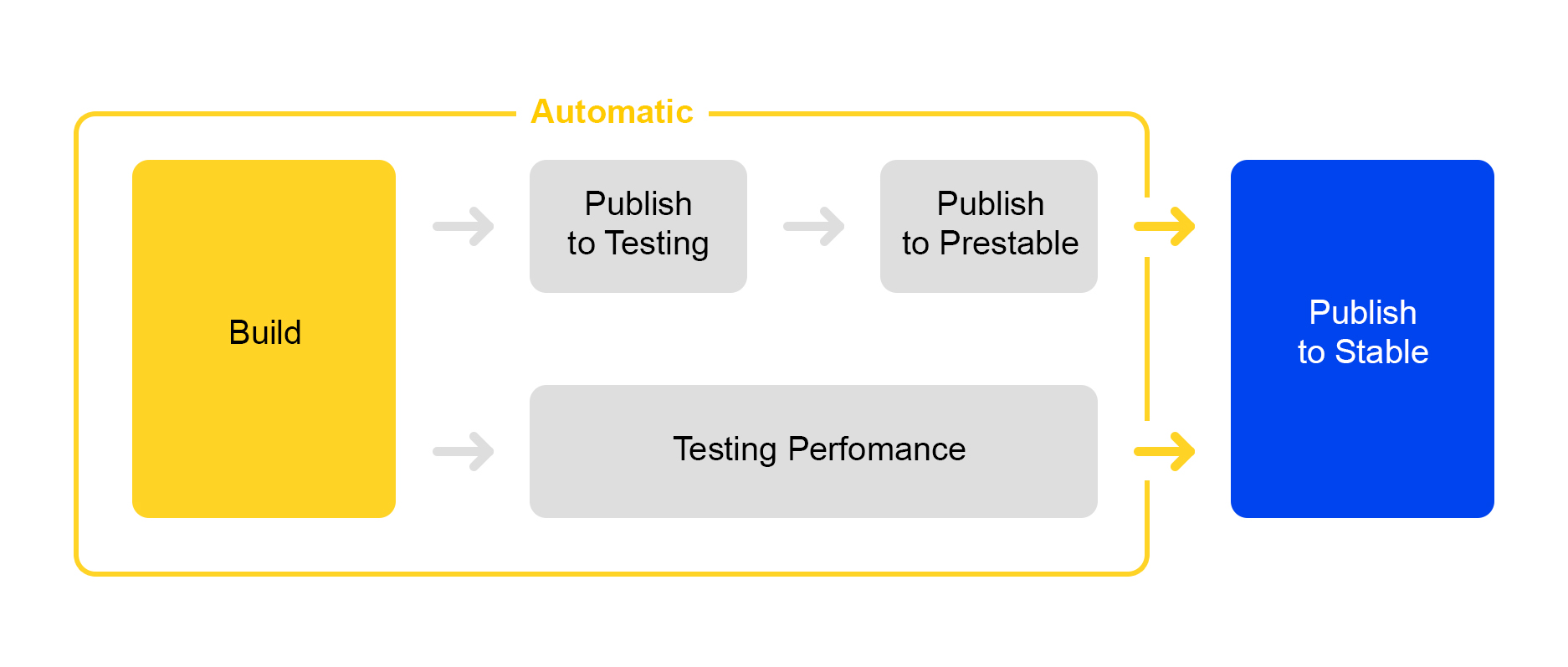
Dann wird der Service zum Testen ausgerollt, wo die Stabilität überprüft wird.
Gleichzeitig wird ein automatischer Leistungstest gestartet. Er nimmt an einem besonderen Dienst teil. Ich werde jetzt nicht über ihn sprechen - seine Beschreibung verdient einen eigenen Artikel.
Wenn die Veröffentlichung im Test erfolgreich ist, startet die Veröffentlichung der Veröffentlichung in prestable automatisch. Prestable ist ein spezieller Cluster, in dem der normale Benutzerverkehr geleitet wird. Wenn ein Fehler zurückgegeben wird, führt der Balancer eine erneute Anforderung in der Produktion durch.
In prestable werden die Reaktionszeiten gemessen und mit dem vorherigen Release in der Produktion verglichen. Wenn alles in Ordnung ist, stellt die Person eine Verbindung her: Sie überprüft die Grafiken und Ergebnisse der Belastungstests und beginnt mit der Einführung in die Produktion.
Alles Gute für den Anwender: A / B-Tests
Es ist nicht immer offensichtlich, ob Änderungen im Service echte Vorteile bringen. Um den Nutzen von Veränderungen zu messen, wurden A / B-Tests entwickelt. Ich werde ein wenig darüber sprechen, wie dies in der Yandex.Market-Suche funktioniert.
Alles beginnt mit dem Hinzufügen eines neuen CGI-Parameters, der neue Funktionen enthält. Unser Parameter sei:
market_new_functionality = 1 . Aktivieren Sie dann im Code diese Funktionalität mit dem Flag:
If (cgi.experiments.market_new_functionality) {
Neue Funktionen werden in der Produktion eingeführt.
Für die Automatisierung von A / B-Tests gibt es einen speziellen Dienst, der
hier ausführlich
beschrieben wird. Im Service wird ein Experiment angelegt. Der Verkehrsanteil ist beispielsweise auf 15% festgelegt. Das Interesse richtet sich nicht an Anfragen, sondern an Benutzer. Die Zeit des Experiments, beispielsweise eine Woche, ist ebenfalls angegeben.
Es können mehrere Versuche gleichzeitig gestartet werden. In den Einstellungen können Sie festlegen, ob eine Überschneidung mit anderen Experimenten möglich ist.
Infolgedessen fügt der Dienst automatisch das Argument
market_new_functionality = 1 zu 15% der Benutzer hinzu. Er berechnet auch automatisch die ausgewählten Metriken. Nach dem Experiment sehen sich die Analysten die Ergebnisse an und ziehen Schlussfolgerungen. Auf der Grundlage der Ergebnisse wird die Entscheidung getroffen, die Produktion aufzunehmen oder zu verfeinern.
Die wendige Hand des Marktes: Produktionstests
Es kommt häufig vor, dass die Funktionsweise neuer Funktionen in der Produktion überprüft werden muss, es gibt jedoch keine Gewissheit darüber, wie sie sich unter "Kampfbedingungen" unter hoher Last verhalten werden.
Es gibt eine Lösung: Flags in CGI-Parametern können nicht nur zum Testen von A / B, sondern auch zum Testen neuer Funktionen verwendet werden.
Wir haben ein Tool entwickelt, mit dem Sie die Konfiguration auf Tausenden von Servern sofort ändern können, ohne den Service Risiken auszusetzen. Es heißt "Stop Crane". Die ursprüngliche Idee war die Möglichkeit, einige Funktionen ohne Layout schnell auszuschalten. Dann wurde das Tool erweitert und komplexer.
Das Schema des Dienstes ist unten dargestellt:
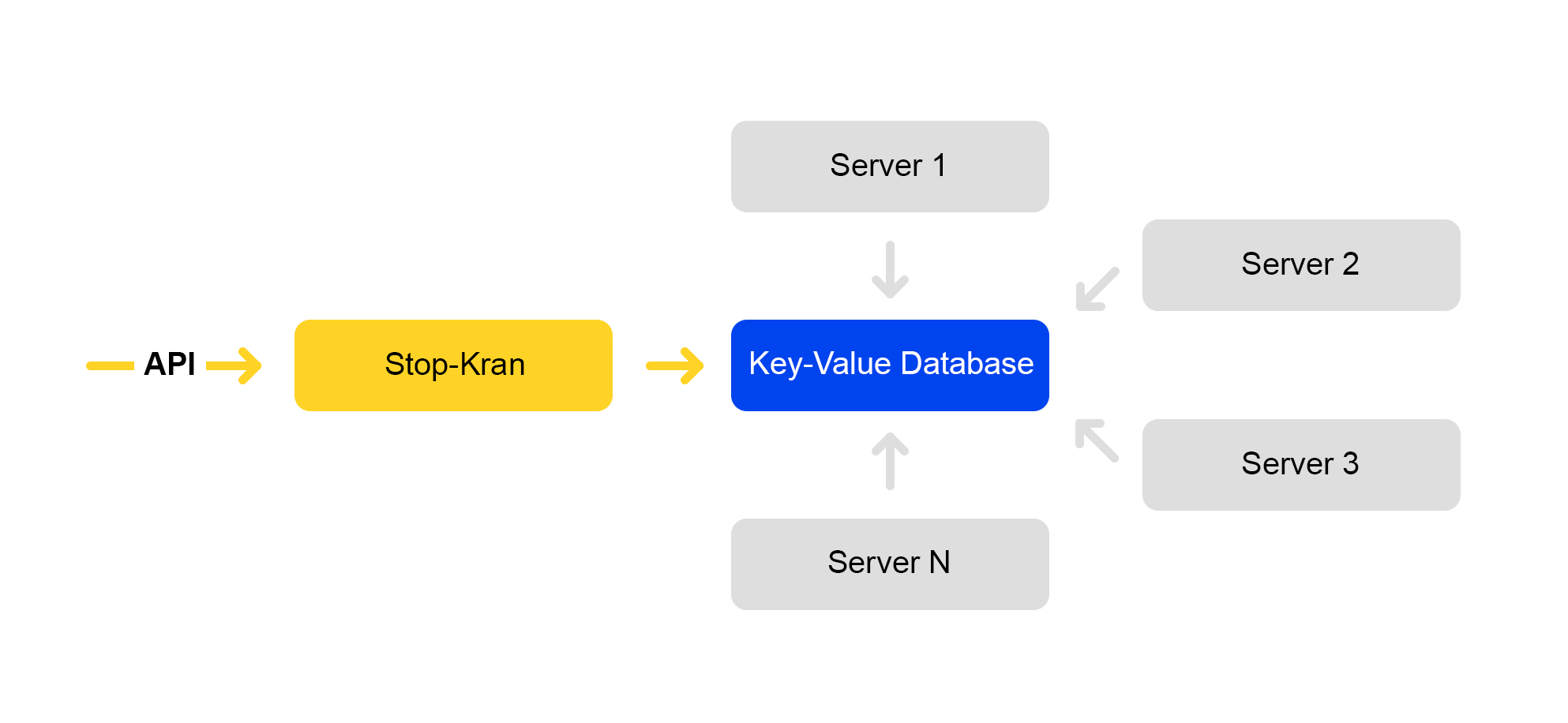
Die API setzt Flag-Werte. Der Verwaltungsdienst speichert diese Werte in einer Datenbank. Alle Server gehen alle zehn Sekunden in die Datenbank, pumpen die Werte der Flags aus und wenden diese Werte auf jede Anforderung an.
In Stop Crane können Sie zwei Arten von Werten festlegen:
1) Bedingte Ausdrücke. Anwenden, wenn einer der Werte ausgeführt wird. Zum Beispiel:
{ "condition":"IS_DC1", "value":"3", }, { "condition": "CLUSTER==2 and IS_BERU", "value": "4!" }
Der Wert "3" wird angewendet, wenn die Anforderung am Speicherort DC1 verarbeitet wird. Und der Wert ist "4", wenn die Anfrage auf dem zweiten Cluster für die Website famous.ru verarbeitet wird.
2) Bedingungslose Werte. Sie werden standardmäßig verwendet, wenn keine der Bedingungen erfüllt ist. Zum Beispiel:
Wert, Wert!Wenn der Wert mit einem Ausrufezeichen endet, erhält er eine höhere Priorität.
Der Parser der CGI-Parameter analysiert die URL. Dann werden die Werte vom Stopp-Tap übernommen.
Es gelten Werte mit folgenden Prioritäten:
- Höhere Priorität ab Stopp Tippen (Ausrufezeichen).
- Der Wert aus der Abfrage.
- Der Standardwert stammt vom Stopp-Tippen.
- Der Standardwert im Code.
Es gibt viele Flags, die in bedingten Werten angegeben sind - sie reichen für alle uns bekannten Szenarien aus:
- Rechenzentrum.
- Umwelt: Produktion, Prüfung, Schatten.
- Veranstaltungsort: Markt, berühmt.
- Clusternummer.
Mit diesem Tool können Sie neue Funktionen auf einer Gruppe von Servern (z. B. nur in einem Rechenzentrum) aktivieren und die Funktionsweise dieser Funktionen überprüfen, ohne dass dies ein Risiko für den gesamten Dienst darstellt. Selbst wenn Sie irgendwo einen schwerwiegenden Fehler gemacht haben, fiel alles und das gesamte Rechenzentrum fiel aus. Balancer leiten Anforderungen an andere Rechenzentren weiter. Endbenutzer werden nichts bemerken.
Wenn Sie ein Problem bemerken, können Sie sofort den vorherigen Wert des Flags zurückgeben, und die Änderungen werden rückgängig gemacht.
Dieser Service hat seine Nachteile: Die Entwickler lieben ihn sehr und versuchen oft, alle Änderungen in den Stop Crane zu übertragen. Wir versuchen, Missbrauch zu bekämpfen.
Der Stop-Crane-Ansatz funktioniert gut, wenn Sie bereits über einen stabilen Code verfügen, der für die Einführung in der Produktion bereit ist. Gleichzeitig haben Sie immer noch Zweifel und möchten den Code unter "Kampfbedingungen" überprüfen.
Der Absperrhahn ist jedoch nicht zum Testen während der Entwicklung geeignet. Für Entwickler gibt es einen separaten Cluster namens „Schattencluster“.
Verdeckte Prüfung: Schattenhaufen
Anforderungen von einem der Cluster werden in den Schattencluster dupliziert. Der Balancer ignoriert jedoch die Antworten dieses Clusters vollständig. Das Schema seiner Arbeit ist unten dargestellt.
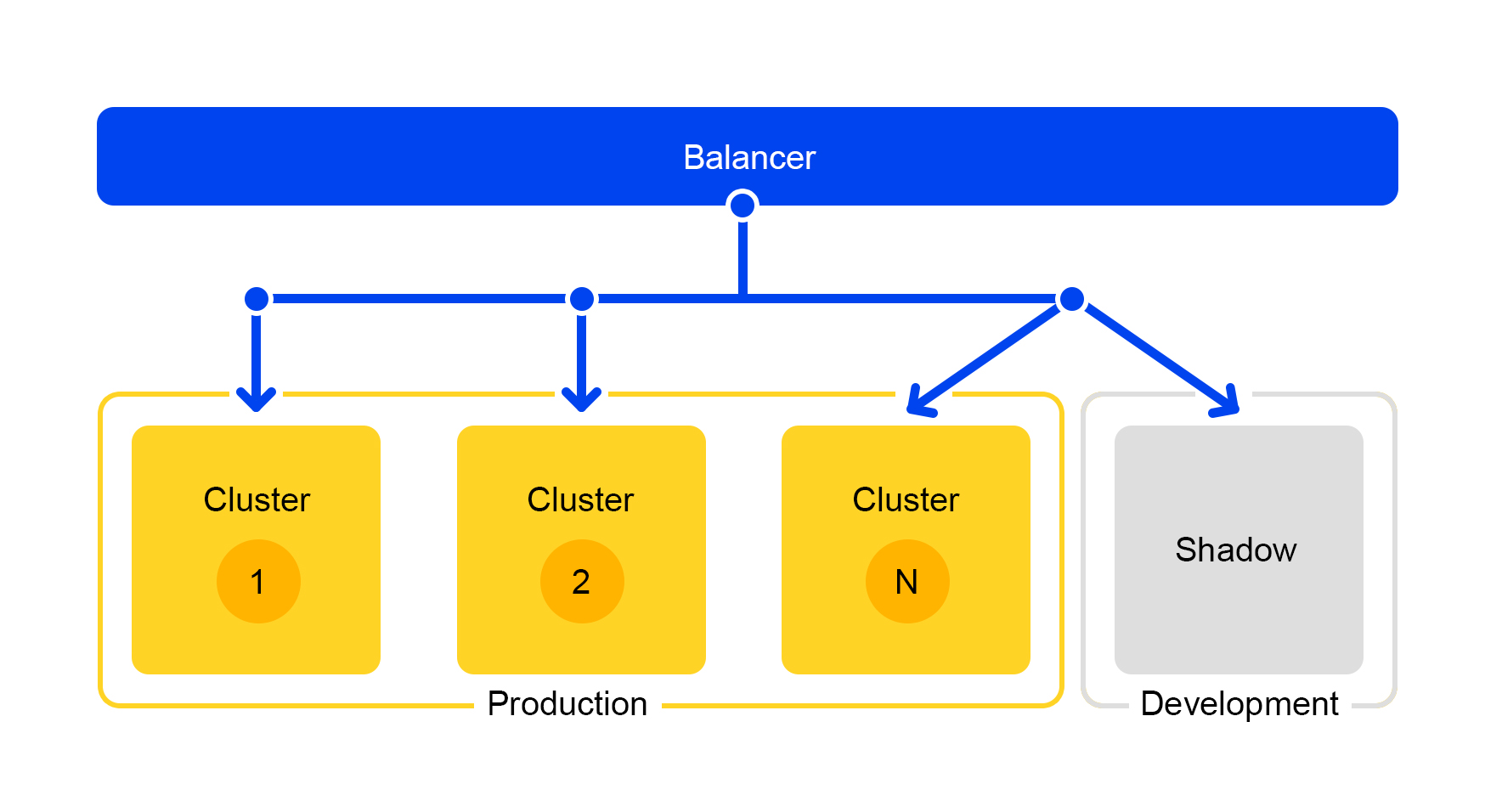
Wir erhalten einen Testcluster, der sich unter realen „Kampfbedingungen“ befindet. Dort fliegt normaler Nutzerverkehr. Die Hardware in beiden Clustern ist identisch, sodass Sie Leistung und Fehler vergleichen können.
Und da der Balancer die Antworten vollständig ignoriert, werden den Endbenutzern die Antworten des Schattenclusters nicht angezeigt. Daher ist es nicht beängstigend, einen Fehler zu machen.
Schlussfolgerungen
Wie haben wir eine Marktsuche aufgebaut?
Damit alles reibungslos funktioniert, teilen wir die Funktionalität in separate Services. Sie können also nur die Komponenten skalieren, die wir benötigen, und die Komponenten einfacher gestalten. Es ist einfach, einem anderen Team eine separate Komponente zuzuweisen und die Verantwortung für die Arbeit daran zu teilen. Eine signifikante Einsparung von Eisen bei diesem Ansatz ist ein offensichtliches Plus.
Der Schattencluster hilft uns auch: Sie können Dienste entwickeln, sie im Prozess testen und gleichzeitig den Benutzer nicht stören.
Na und natürlich in der Produktion einchecken. Müssen Sie die Konfiguration auf tausend Servern ändern? Einfach einen Stoppkran benutzen. So können Sie sofort eine vorgefertigte komplexe Lösung bereitstellen und bei Problemen auf eine stabile Version zurücksetzen.
Ich hoffe, ich konnte zeigen, wie wir den Markt mit einer stetig wachsenden Angebotsbasis schnell und stabil machen. Wie Sie Serverprobleme lösen, eine Vielzahl von Anfragen bearbeiten, die Service-Flexibilität verbessern und dies tun, ohne die Arbeitsprozesse zu unterbrechen.