
Einleitung
I / O-Reaktor (Single-Threaded- Ereignisschleife ) ist ein Muster zum Schreiben von hoch geladener Software, das in vielen gängigen Lösungen verwendet wird:
In diesem Artikel werden wir die Vor- und Nachteile des E / A-Reaktors und das Funktionsprinzip betrachten, eine Implementierung für weniger als 200 Codezeilen schreiben und einen einfachen HTTP-Server zwingen, mehr als 40 Millionen Anforderungen pro Minute zu verarbeiten.
Vorwort
- Der Artikel wurde mit dem Ziel verfasst, die Funktionsweise des E / A-Reaktors zu verstehen und damit die Risiken bei seiner Verwendung zu erkennen.
- Um den Artikel zu beherrschen, sind Kenntnisse der Grundlagen der C-Sprache und ein wenig Erfahrung in der Entwicklung von Netzwerkanwendungen erforderlich.
- Der gesamte Code ist in C geschrieben und entspricht ( Achtung: langes PDF ) dem C11-Standard für Linux und ist auf GitHub verfügbar.
Warum ist das nötig?
Mit der wachsenden Popularität des Internets mussten Webserver eine große Anzahl von Verbindungen gleichzeitig verarbeiten, und daher wurden zwei Ansätze ausprobiert: Blockieren von E / A auf einer großen Anzahl von Betriebssystemthreads und nicht blockierende E / A in Kombination mit einem Ereignisbenachrichtigungssystem, das auch als "System" bezeichnet wird Selektor "( epoll / kqueue / IOCP / etc).
Der erste Ansatz bestand darin, für jede eingehende Verbindung einen neuen Betriebssystem-Thread zu erstellen. Der Nachteil ist die schlechte Skalierbarkeit: Das Betriebssystem muss viele Kontextübergänge und Systemaufrufe durchführen . Sie sind kostspielig und können zu einem Mangel an freiem RAM mit einer beeindruckenden Anzahl von Verbindungen führen.
Die geänderte Version weist eine feste Anzahl von Threads (Thread-Pool) zu, wodurch verhindert wird, dass das System die Ausführung abnormal stoppt, gleichzeitig jedoch ein neues Problem einbringt: Wenn der Thread-Pool zum gegebenen Zeitpunkt durch lange Leseoperationen blockiert wird, können andere Sockets bereits Daten empfangen wird dies nicht tun können.
Der zweite Ansatz verwendet das vom Betriebssystem bereitgestellte Ereignisbenachrichtigungssystem (Systemauswahl). In diesem Artikel wird die häufigste Art der Systemauswahl beschrieben, die auf Warnungen (Ereignissen, Benachrichtigungen) zur Bereitschaft für E / A-Vorgänge und nicht auf Warnungen zu deren Abschluss basiert. Ein vereinfachtes Beispiel seiner Verwendung kann durch das folgende Flussdiagramm dargestellt werden:

Der Unterschied zwischen diesen Ansätzen ist wie folgt:
- Durch das Blockieren von E / A-Vorgängen wird der Benutzer-Stream angehalten, bis das Betriebssystem die eingehenden IP-Pakete ordnungsgemäß in den Byte-Stream ( TCP , Datenempfang) defragmentiert oder genügend Speicherplatz in den internen Schreibpuffern für das anschließende Senden über die Netzwerkkarte (Datenversand) freigegeben hat .
- Nach einer Weile benachrichtigt die Systemauswahl das Programm, dass das Betriebssystem bereits IP-Pakete defragmentiert hat (TCP, Daten empfangen) oder dass bereits genügend Speicherplatz in den internen Aufzeichnungspuffern verfügbar ist (Daten senden).
Zusammenfassend ist das Reservieren des Betriebssystemthreads für jedes E / A eine Verschwendung von Rechenleistung, da die Threads in der Realität nicht mit nützlicher Arbeit beschäftigt sind (der Begriff "Softwareunterbrechung" hat seine Wurzeln). Die Systemauswahl löst dieses Problem, indem das Benutzerprogramm die CPU-Ressourcen wesentlich sparsamer nutzen kann.
Reaktor-I / O-Modell
Eine E / A-Drossel fungiert als Schicht zwischen dem Systemselektor und dem Benutzercode. Das Funktionsprinzip wird durch das folgende Flussdiagramm beschrieben:
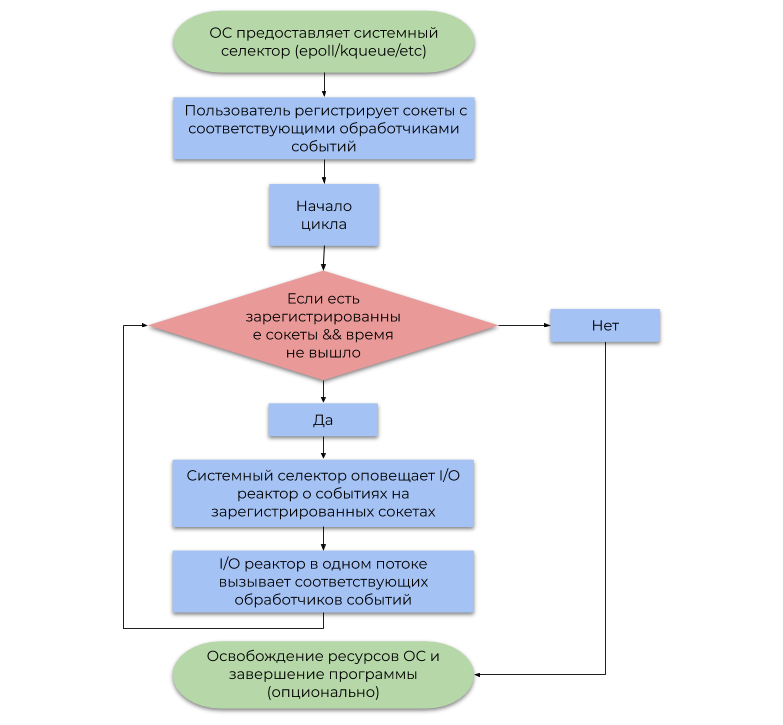
- Lassen Sie mich daran erinnern, dass ein Ereignis eine Benachrichtigung ist, dass ein bestimmter Socket eine nicht blockierende E / A-Operation ausführen kann.
- Ein Ereignishandler ist eine Funktion, die vom E / A-Reaktor aufgerufen wird, wenn ein Ereignis empfangen wird, das dann eine nicht blockierende E / A-Operation ausführt.
Es ist wichtig anzumerken, dass die E / A-Drossel per Definition ein Thread ist, aber nichts hindert die Verwendung des Konzepts in einer Umgebung mit mehreren Threads in Bezug auf 1 Stream: 1-Drossel, wodurch alle CPU-Kerne verwendet werden.
Implementierung
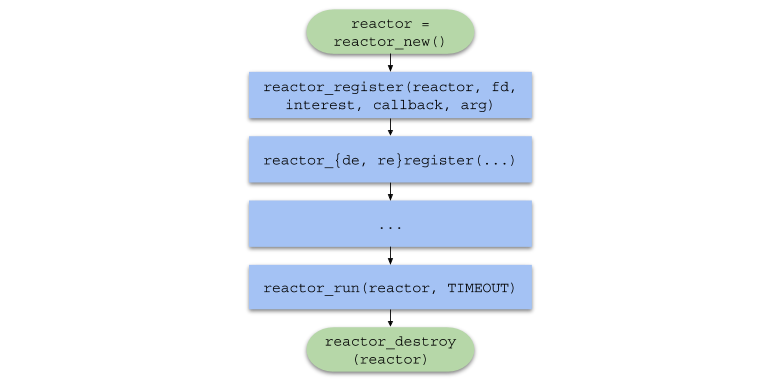
Wir haben die öffentliche Schnittstelle in die Datei " reactor.h " und die Implementierung in die Datei " reactor.h reactor.c . reactor.h wird aus den folgenden Erklärungen bestehen:
Zeige Anzeigen in Reaktor.h typedef struct reactor Reactor; typedef void (*Callback)(void *arg, int fd, uint32_t events); Reactor *reactor_new(void); int reactor_destroy(Reactor *reactor); int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_deregister(const Reactor *reactor, int fd); int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_run(const Reactor *reactor, time_t timeout);
Die E / A-Struktur des Reaktors besteht aus einem Epoll- Selector- Dateideskriptor und einer GHashTable Hash-Tabelle , die jeder Socket CallbackData (einer Struktur aus einer Ereignisbehandlungsroutine und einem Benutzerargument dafür) zuordnet.
Reactor und CallbackData anzeigen struct reactor { int epoll_fd; GHashTable *table;
Bitte beachten Sie, dass wir die Möglichkeit genutzt haben, einen unvollständigen Typ per Zeiger zu behandeln. In reactor.h deklarieren wir den Aufbau des reactor und in reactor.c definieren reactor.c ihn, wodurch der Benutzer daran reactor.c wird, seine Felder explizit zu ändern. Dies ist eines der Muster des Versteckens von Daten , das sich organisch in die Semantik von C einfügt.
Die Funktionen reactor_register , reactor_deregister und reactor_reregister aktualisieren die Liste der Sockets von Interesse und die entsprechenden Ereignishandler in der Systemauswahl und in der Hash-Tabelle.
Registrierungsfunktionen anzeigen #define REACTOR_CTL(reactor, op, fd, interest) \ if (epoll_ctl(reactor->epoll_fd, op, fd, \ &(struct epoll_event){.events = interest, \ .data = {.fd = fd}}) == -1) { \ perror("epoll_ctl"); \ return -1; \ } int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; } int reactor_deregister(const Reactor *reactor, int fd) { REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0) g_hash_table_remove(reactor->table, &fd); return 0; } int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; }
Nachdem der E / A-Reaktor das Ereignis mit dem fd Deskriptor abgefangen hat, ruft er den entsprechenden Ereignishandler auf, in den er fd übergibt, die Bitmaske der generierten Ereignisse und den Benutzerzeiger auf void .
Reaktor_Run () Funktion anzeigen int reactor_run(const Reactor *reactor, time_t timeout) { int result; struct epoll_event *events; if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL) abort(); time_t start = time(NULL); while (true) { time_t passed = time(NULL) - start; int nfds = epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed); switch (nfds) {
Zusammenfassend wird die Kette von Funktionsaufrufen im Benutzercode die folgende Form annehmen:
Single-Thread-Server
Um den E / A-Reaktor unter hoher Last zu testen, schreiben wir einen einfachen HTTP-Webserver, um auf jede Anfrage mit einem Bild zu antworten.
HTTP-Protokoll-KurzübersichtHTTP ist ein Protokoll auf Anwendungsebene , das hauptsächlich für die Serverinteraktion mit einem Browser verwendet wird.
HTTP kann problemlos über das TCP- Transportprotokoll hinaus verwendet werden und sendet und empfängt Nachrichten in dem in der Spezifikation festgelegten Format.
<> <URI> < HTTP>CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
CRLF ist eine Folge von zwei Zeichen: \r und \n , die die erste Abfragezeile, die Überschriften und die Daten voneinander trennen.<> ist eines von CONNECT , DELETE , GET , HEAD , OPTIONS , PATCH , POST , PUT , TRACE . Der Browser sendet einen GET Befehl an unseren Server mit der Bedeutung "Senden Sie mir den Inhalt der Datei."<URI> ist die einheitliche Ressourcenkennung . Wenn beispielsweise URI = /index.html , fordert der Client die Hauptseite der Site an.< HTTP> - HTTP-Protokollversion im HTTP/XY Format. Die bislang am häufigsten verwendete Version ist HTTP/1.1 .< N> ist ein Schlüssel-Wert-Paar im Format <>: <> , das zur weiteren Analyse an den Server gesendet wird.<> - Daten, die der Server benötigt, um den Vorgang abzuschließen. Oft ist es nur JSON oder ein anderes Format.
< HTTP> < > < >CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
< > ist eine Zahl, die das Ergebnis einer Operation darstellt. Unser Server gibt immer den Status 200 zurück (erfolgreicher Betrieb).< > - Zeichenfolgendarstellung des Statuscodes. Für Statuscode 200 ist dies OK .< N> - Ein Header mit demselben Format wie in der Anforderung. Wir werden die Header Content-Length (Dateigröße) und Content-Type: text/html (Rückgabetyp Daten) zurückgeben.<> - vom Benutzer angeforderte Daten. In unserem Fall ist dies der Pfad zum Bild in HTML .
Die http_server.c (Single-Threaded-Server) enthält die Datei common.h , die die folgenden Funktionsprototypen enthält:
Funktionsprototypen in common.h anzeigen static void on_accept(void *arg, int fd, uint32_t events); static void on_send(void *arg, int fd, uint32_t events); static void on_recv(void *arg, int fd, uint32_t events); static void set_nonblocking(int fd); static noreturn void fail(const char *format, ...); static int new_server(bool reuse_port);
Das Funktionsmakro SAFE_CALL() ebenfalls beschrieben und die Funktion fail() definiert. Das Makro vergleicht den Wert des Ausdrucks mit dem Fehler. Wenn die Bedingung erfüllt ist, ruft es die Funktion fail() :
#define SAFE_CALL(call, error) \ do { \ if ((call) == error) { \ fail("%s", #call); \ } \ } while (false)
Die Funktion fail() die übergebenen Argumente an das Terminal aus (wie printf() ) und beendet das Programm mit dem EXIT_FAILURE Code:
static noreturn void fail(const char *format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fprintf(stderr, ": %s\n", strerror(errno)); exit(EXIT_FAILURE); }
Die Funktion new_server() gibt den Dateideskriptor des vom System erstellten "Server" new_server() zurück, der die new_server() socket() , bind() und listen() aufruft und eingehende Verbindungen im nicht blockierenden Modus annehmen kann.
Funktion anzeigen new_server () static int new_server(bool reuse_port) { int fd; SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)), -1); if (reuse_port) { SAFE_CALL( setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)), -1); } struct sockaddr_in addr = {.sin_family = AF_INET, .sin_port = htons(SERVER_PORT), .sin_addr = {.s_addr = inet_addr(SERVER_IPV4)}, .sin_zero = {0}}; SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1); SAFE_CALL(listen(fd, SERVER_BACKLOG), -1); return fd; }
- Beachten Sie, dass der Socket anfänglich im nicht blockierenden Modus mit dem
SOCK_NONBLOCK Flag erstellt wird, sodass der on_accept() Funktion on_accept() die Ausführung des Streams nicht on_accept() . - Wenn
reuse_port true , konfiguriert diese Funktion den Socket mit der Option SO_REUSEPORT Verwendung von setsockopt() , um denselben Port in einer Umgebung mit mehreren Threads zu verwenden (siehe Abschnitt "Server mit mehreren Threads").
Die Ereignisbehandlungsroutine on_accept() wird aufgerufen, nachdem das Betriebssystem ein EPOLLIN Ereignis generiert hat. In diesem Fall kann eine neue Verbindung akzeptiert werden. on_accept() akzeptiert eine neue Verbindung, wechselt in den nicht blockierenden Modus und registriert sich beim on_recv() in der E / A-Drossel.
Funktion on_accept () anzeigen static void on_accept(void *arg, int fd, uint32_t events) { int incoming_conn; SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1); set_nonblocking(incoming_conn); SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv, request_buffer_new()), -1); }
Die Ereignisbehandlungsroutine on_recv() wird aufgerufen, nachdem das Betriebssystem ein EPOLLIN Ereignis generiert hat. In diesem Fall ist die von on_accept() registrierte Verbindung bereit, Daten zu akzeptieren.
on_recv() liest die Daten von der Verbindung, bis die vollständige HTTP-Anforderung empfangen wurde, und registriert dann den on_send() Handler, um die HTTP-Antwort zu senden. Wenn der Client die Verbindung trennt, wird die Registrierung des Sockets aufgehoben und mit close() .
Funktion on_recv () anzeigen static void on_recv(void *arg, int fd, uint32_t events) { RequestBuffer *buffer = arg;
Die Ereignisbehandlungsroutine on_send() wird aufgerufen, nachdem das Betriebssystem ein EPOLLOUT Ereignis generiert hat. EPOLLOUT bedeutet, dass die von on_recv() registrierte Verbindung zum Senden von Daten bereit ist. Diese Funktion sendet eine HTTP-Antwort mit HTML mit dem Bild an den Client und ändert dann die Ereignisbehandlungsroutine erneut in on_recv() .
Funktion on_send () anzeigen static void on_send(void *arg, int fd, uint32_t events) { const char *content = "<img " "src=\"https://habrastorage.org/webt/oh/wl/23/" "ohwl23va3b-dioerobq_mbx4xaw.jpeg\">"; char response[1024]; sprintf(response, "HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: " "text/html" DOUBLE_CRLF "%s", strlen(content), content); SAFE_CALL(send(fd, response, strlen(response), 0), -1); SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1); }
Und schließlich erstellen wir in der Datei http_server.c in der main() -Funktion einen E / A-Reaktor mit reactor_new() , erstellen einen Server-Socket und registrieren ihn, starten den Reaktor mit reactor_run() genau eine Minute und geben dann die Ressourcen frei und reactor_run() aus dem Programm.
Zeigen Sie http_server.c an #include "reactor.h" static Reactor *reactor; #include "common.h" int main(void) { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL( reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); }
Überprüfen Sie, ob alles wie erwartet funktioniert. Wir kompilieren ( chmod a+x compile.sh && ./compile.sh im Stammverzeichnis des Projekts) und starten den selbstgeschriebenen Server, öffnen http://127.0.0.1:18470 im Browser und beobachten, was erwartet wurde:
Leistungsmessung
Zeigen Sie die Eigenschaften meines Autos $ screenfetch MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic MMd /++ -sNMd: Uptime: 2h 34m MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217 ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20 NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080 NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10 NMm dMM -MMm `MMM dMM. dMM WM: Muffin NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y) NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3] hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y -NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9 -dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C] `/dMNmy+/:-------------:/yMMM GPU: NV136 ./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB \.MMMMMMMMMMMMMMMMMMM
Wir messen die Leistung eines Singlethread-Servers. Öffnen wir zwei Terminals: In einem führen wir ./http_server , in dem anderen - wrk . Nach einer Minute werden die folgenden Statistiken im zweiten Terminal angezeigt:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 493.52us 76.70us 17.31ms 89.57% Req/Sec 24.37k 1.81k 29.34k 68.13% 11657769 requests in 1.00m, 1.60GB read Requests/sec: 193974.70 Transfer/sec: 27.19MB
Unser Single-Threaded-Server konnte über 11 Millionen Anfragen pro Minute aus 100 Verbindungen verarbeiten. Kein schlechtes Ergebnis, aber kann es verbessert werden?
Multithread-Server
Wie oben erwähnt, kann eine E / A-Drossel in getrennten Strömen erstellt werden, wodurch alle CPU-Kerne verwendet werden. Wenden wir diesen Ansatz in der Praxis an:
Zeigen Sie http_server_multithreaded.c an #include "reactor.h" static Reactor *reactor; #pragma omp threadprivate(reactor) #include "common.h" int main(void) { #pragma omp parallel { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); } }
Jetzt besitzt jeder Thread einen eigenen Reaktor:
static Reactor *reactor; #pragma omp threadprivate(reactor)
Beachten Sie, dass das Argument für new_server() true . Dies bedeutet, dass wir den Server-Socket auf die Option SO_REUSEPORT , um ihn in einer Umgebung mit mehreren Threads zu verwenden. Sie können hier mehr lesen.
Zweiter Lauf
Jetzt messen wir die Leistung eines Multithread-Servers:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 1.14ms 2.53ms 40.73ms 89.98% Req/Sec 79.98k 18.07k 154.64k 78.65% 38208400 requests in 1.00m, 5.23GB read Requests/sec: 635876.41 Transfer/sec: 89.14MB
Die Anzahl der bearbeiteten Anfragen in 1 Minute hat sich um das 3,28-fache erhöht! Aber bis auf die runde Zahl waren nur ~ zwei Millionen nicht genug, versuchen wir es zu beheben.
Schauen Sie sich zunächst die von perf generierten Statistiken an:
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded Performance counter stats for './http_server_multithreaded': 242446,314933 task-clock (msec) # 4,000 CPUs utilized 1 813 074 context-switches # 0,007 M/sec 4 689 cpu-migrations # 0,019 K/sec 254 page-faults # 0,001 K/sec 895 324 830 170 cycles # 3,693 GHz 621 378 066 808 instructions # 0,69 insn per cycle 119 926 709 370 branches # 494,653 M/sec 3 227 095 669 branch-misses # 2,69% of all branches 808 664 cache-misses 60,604330670 seconds time elapsed
Bei Verwendung der CPU-Affinität führte das Kompilieren mit -march=native , PGO , Erhöhen der Anzahl der Treffer im Cache , Erhöhen von MAX_EVENTS und Verwenden von EPOLLET zu keiner signifikanten Leistungssteigerung. Aber was passiert, wenn Sie die Anzahl der gleichzeitigen Verbindungen erhöhen?
Statistik für 352 gleichzeitige Verbindungen:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 352 connections Thread Stats Avg Stdev Max +/- Stdev Latency 2.12ms 3.79ms 68.23ms 87.49% Req/Sec 83.78k 12.69k 169.81k 83.59% 40006142 requests in 1.00m, 5.48GB read Requests/sec: 665789.26 Transfer/sec: 93.34MB
Man erhielt das gewünschte Ergebnis und damit ein interessantes Diagramm, das die Abhängigkeit der Anzahl der bearbeiteten Anfragen in 1 Minute von der Anzahl der Verbindungen zeigt:
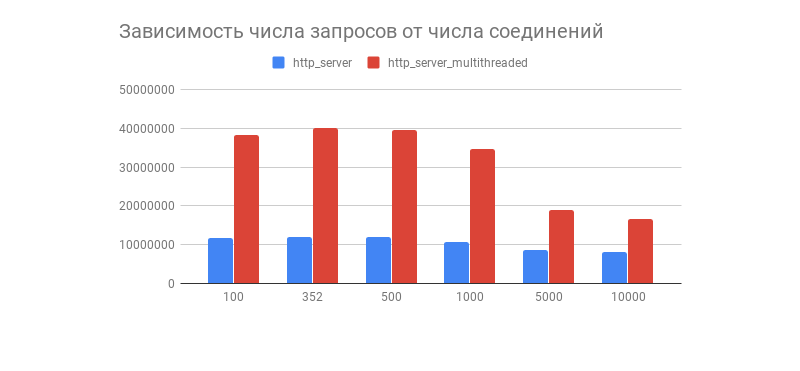
Wir sehen, dass nach ein paar hundert Verbindungen die Anzahl der verarbeiteten Anforderungen von beiden Servern stark abnimmt (in einer Multithread-Version ist dies auffälliger). Hat dies mit der Implementierung des Linux TCP / IP-Stacks zu tun? Fühlen Sie sich frei, Ihre Annahmen über ein solches Diagrammverhalten und Optimierungen von Multithread- und Singlethread-Optionen in die Kommentare einzutragen.
Wie in den Kommentaren erwähnt, zeigt dieser Leistungstest nicht das Verhalten des E / A-Reaktors bei tatsächlichen Lasten, da der Server fast immer mit der Datenbank interagiert, Protokolle anzeigt, Kryptografie mit TLS verwendet usw., wodurch die Last heterogen (dynamisch) wird. Tests zusammen mit Komponenten von Drittanbietern werden in einem Artikel über den E / A-Prozessor durchgeführt.
Nachteile des E / A-Reaktors
Sie müssen verstehen, dass die E / A-Drossel nicht ohne Nachteile ist, und zwar:
- Die Verwendung eines E / A-Reaktors in einer Umgebung mit mehreren Threads ist etwas schwieriger, weil Sie müssen die Abläufe manuell verwalten.
- Die Praxis zeigt, dass die Last in den meisten Fällen heterogen ist, was dazu führen kann, dass ein Thread abgelegt wird, während der andere mit Arbeit geladen wird.
- Wenn eine Ereignisbehandlungsroutine den Stream blockiert, wird auch die Systemauswahl selbst blockiert, was zu schwer zu findenden Fehlern führen kann.
Diese Probleme werden vom E / A-Proktor gelöst, häufig mit einem Scheduler, der die Last gleichmäßig auf den Thread-Pool verteilt, und der über eine komfortablere API verfügt. Es wird später in meinem anderen Artikel besprochen.
Fazit
Damit endete unsere Reise von der Theorie direkt in den Auspuff-Profiler.
Machen Sie sich keine Gedanken darüber, denn es gibt viele andere, gleichermaßen interessante Ansätze zum Schreiben von Netzwerksoftware mit unterschiedlichem Komfort und Geschwindigkeit. Interessant, meiner Meinung nach, Links sind unten angegeben.
Bis bald
Interessante Projekte
Was gibt es noch zu lesen?