Hallo! Heute werde ich den Lesern von Habr erzählen, wie wir die Texterkennungstechnologie entwickelt haben, die in 45 Sprachen funktioniert und für Yandex.Cloud-Benutzer zugänglich ist, welche Aufgaben wir gestellt und wie wir sie gelöst haben. Es ist nützlich, wenn Sie an ähnlichen Projekten arbeiten oder herausfinden möchten, wie es dazu kam, dass Sie heute nur ein Schild eines türkischen Geschäfts fotografieren müssen, damit Alice es ins Russische übersetzt.

Die OCR-Technologie (Optical Character Recognition) entwickelt sich seit Jahrzehnten weltweit. Wir bei Yandex haben begonnen, unsere eigene OCR-Technologie zu entwickeln, um unsere Dienste zu verbessern und den Benutzern mehr Optionen zu bieten. Bilder sind ein großer Teil des Internets und ohne die Fähigkeit, sie zu verstehen, ist die Suche im Internet unvollständig.
Bildanalyselösungen werden immer beliebter. Dies ist auf die Verbreitung künstlicher neuronaler Netze und Geräte mit hochwertigen Sensoren zurückzuführen. Es ist klar, dass es sich in erster Linie um Smartphones handelt, aber nicht nur um solche.
Die Komplexität der Aufgaben im Bereich der Texterkennung nimmt stetig zu - alles begann mit der Erkennung gescannter Dokumente. Dann wurde die
Erkennung von Born-Digital-Bildern mit Texten aus dem Internet hinzugefügt. Dann, mit der wachsenden Popularität von mobilen Kameras, die Erkennung von guten Kameraaufnahmen (
Focused Scene Text ). Und je weiter, desto komplizierter die Parameter: Der Text kann unscharf (
Incidental Scene Text ) sein, in beliebiger Biegung oder Spirale in verschiedenen Kategorien geschrieben - von
Fotos von Belegen bis zu
Regalen und Schildern.
Welchen Weg sind wir gegangen?
Die Texterkennung ist eine separate Klasse von Computer Vision-Aufgaben. Wie viele Computer-Vision-Algorithmen beruhte sie vor der Popularität neuronaler Netze hauptsächlich auf manuellen Funktionen und Heuristiken. In jüngster Zeit hat sich jedoch mit dem Übergang zu neuronalen Netzen die Qualität der Technologie erheblich verbessert. Schauen Sie sich das Beispiel auf dem Foto an. Wie das passiert ist, werde ich weiter erzählen.
Vergleichen Sie die heutigen Erkennungsergebnisse mit den Ergebnissen zu Beginn des Jahres 2018:
Auf welche Schwierigkeiten stießen wir zuerst?
Zu Beginn unserer Reise haben wir Erkennungstechnologien für Russisch und Englisch entwickelt. Die Hauptanwendungsfälle waren fotografierte Seiten mit Texten und Bildern aus dem Internet. Im Laufe der Arbeit haben wir jedoch festgestellt, dass dies nicht ausreicht: Der Text auf den Bildern wurde in jeder Sprache und auf jeder Oberfläche gefunden, und die Bilder erwiesen sich manchmal als von sehr unterschiedlicher Qualität. Dies bedeutet, dass die Erkennung in jeder Situation und bei allen Arten von eingehenden Daten funktionieren sollte.
Und hier stehen wir vor einer Reihe von Schwierigkeiten. Hier sind nur einige:
- Einzelheiten Für eine Person, die es gewohnt ist, Informationen aus Text abzurufen, besteht der Text im Bild aus Absätzen, Linien, Wörtern und Buchstaben, für ein neuronales Netzwerk sieht alles anders aus. Aufgrund der Komplexität des Textes ist das Netzwerk gezwungen, sowohl das Bild als Ganzes zu sehen (zum Beispiel, wenn Menschen sich an den Händen fügten und eine Inschrift bauten) als auch die kleinsten Details (in der vietnamesischen Sprache ändern ähnliche Symbole und ừ die Bedeutung von Wörtern). Separate Herausforderungen bestehen darin, beliebigen Text und nicht standardmäßige Schriftarten zu erkennen.
- Mehrsprachigkeit . Je mehr Sprachen wir hinzufügten, desto mehr stießen wir auf ihre Besonderheiten: In kyrillischen und lateinischen Wörtern bestehen sie aus getrennten Buchstaben, in Arabisch werden sie zusammen geschrieben, in Japanisch werden keine getrennten Wörter unterschieden. Einige Sprachen verwenden die Schreibweise von links nach rechts, andere von rechts nach links. Einige Wörter sind horizontal, andere vertikal geschrieben. Ein universelles Tool sollte all diese Funktionen berücksichtigen.
- Die Struktur des Textes . Um bestimmte Bilder wie Schecks oder komplexe Dokumente zu erkennen, ist eine Struktur, die das Layout von Absätzen, Tabellen und anderen Elementen berücksichtigt, von entscheidender Bedeutung.
- Leistung . Die Technologie wird auf einer Vielzahl von Geräten eingesetzt, auch offline. Daher mussten wir die strengen Leistungsanforderungen berücksichtigen.
Auswahl des Erkennungsmodells
Der erste Schritt zum Erkennen von Text besteht in der Bestimmung seiner Position (Erkennung).
Die Texterkennung kann als Objekterkennungsaufgabe betrachtet werden, bei der einzelne
Zeichen ,
Wörter oder
Linien als Objekt fungieren können.
Es war uns wichtig, dass das Modell anschließend auf andere Sprachen skaliert wurde (jetzt unterstützen wir 45 Sprachen).
Viele Forschungsartikel zur Texterkennung verwenden Modelle, die die Position einzelner
Wörter vorhersagen. Bei einem
universellen Modell weist dieser Ansatz jedoch mehrere Einschränkungen auf. So unterscheidet sich beispielsweise das Konzept eines Wortes für die chinesische Sprache grundlegend vom Konzept eines Wortes, beispielsweise auf Englisch. Einzelne chinesische Wörter werden nicht durch ein Leerzeichen getrennt. In Thai werden nur einzelne Sätze mit einem Leerzeichen verworfen.
Hier sind Beispiele für denselben Text in Russisch, Chinesisch und Thailändisch:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้วLinien sind wiederum in Bezug auf das Seitenverhältnis sehr variabel. Aus diesem Grund sind die Möglichkeiten solcher gängiger Erfassungsmodelle (beispielsweise SSD- oder RCNN-basiert) zur Linienvorhersage begrenzt, da diese Modelle auf Kandidatenregionen / Ankerboxen mit vielen vordefinierten Seitenverhältnissen basieren. Darüber hinaus können die Linien eine beliebige Form haben, beispielsweise gekrümmt, weshalb es für eine qualitative Beschreibung der Linien nicht ausreicht, auch bei einem Drehwinkel ausschließlich ein Quad zu beschreiben.
Trotz der Tatsache, dass die Positionen der einzelnen
Zeichen lokal und beschrieben sind, besteht der Nachteil darin, dass ein separater Nachbearbeitungsschritt erforderlich ist - Sie müssen Heuristiken auswählen, um Zeichen in Wörter und Zeilen zu kleben.
Daher haben wir
das SegLink-Modell als Grundlage für die Erkennung
herangezogen , dessen Hauptidee darin besteht, Zeilen / Wörter in zwei weitere lokale Einheiten zu zerlegen: Segmente und Beziehungen zwischen ihnen.
Detektorarchitektur
Die Architektur des Modells basiert auf einer SSD, die die Position von Objekten auf mehreren Merkmalsskalen vorhersagt. Nur zusätzlich zur Vorhersage der Koordinaten einzelner "Segmente" werden auch "Verbindungen" zwischen benachbarten Segmenten vorhergesagt, dh ob zwei Segmente zu derselben Linie gehören. "Verbindungen" werden sowohl für benachbarte Segmente mit demselben Merkmalsmaßstab als auch für Segmente in benachbarten Bereichen mit benachbarten Maßstäben vorhergesagt (Segmente aus unterschiedlichen Maßstäben von Merkmalen können geringfügig unterschiedlich groß sein und zur selben Linie gehören).
Für jede Skala ist jede Merkmalszelle einem entsprechenden „Segment“ zugeordnet. Für jedes Segment s
(x, y, l) am Punkt (x, y) auf einer Skala l wird Folgendes trainiert:
- p
s ob das gegebene Segment Text ist;
- x
s , y
s , w
s , h
s , θ
s - der Versatz der Basiskoordinaten und der Neigungswinkel des Segments;
- 8 Punkte für das Vorhandensein von „Verbindungen“ mit Segmenten neben der l-ten Skala (L
ws , s ' , s' von {s
(x ', y', l) } / s
(x, y, l) , wobei x –1 ≤ x '≤ x + 1, y - 1 ≤ y' ≤ y + 1);
- 4 Punkte für das Vorhandensein von „Verbindungen“ mit Segmenten neben der 1-Skala (L
c s, s ' , s' von {s
(x ', y', 1-1) }, wobei 2x ≤ x '≤ 2x + 1 , 2y ≤ y '≤ 2y + 1) (was auf die Tatsache zurückzuführen ist, dass sich die Dimension von Merkmalen auf benachbarten Maßstäben genau zweimal unterscheidet).
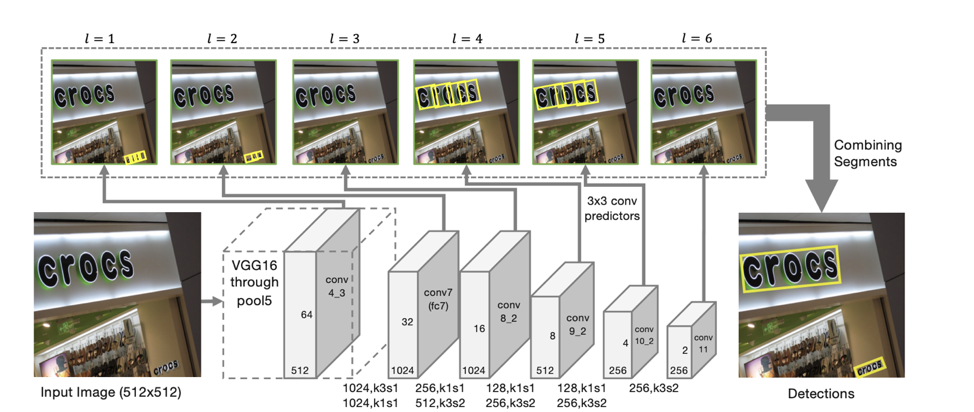
Wenn wir nach solchen Vorhersagen als Eckpunkte alle Segmente nehmen, für die die Wahrscheinlichkeit, dass es sich um Text handelt, größer als die Schwelle α ist, und als Kanten alle Bindungen, deren Wahrscheinlichkeit größer als die Schwelle β ist, dann bilden die Segmente verbundene Komponenten, von denen jede eine Textzeile beschreibt .
Das resultierende Modell weist eine
hohe Verallgemeinerungsfähigkeit auf : Selbst wenn es in den ersten Ansätzen mit russischen und englischen Daten geschult wurde, fand es qualitativ chinesischen und arabischen Text.
Zehn Skripte
Wenn wir zur Erkennung ein Modell erstellen konnten, das sofort für alle Sprachen funktioniert, dann ist es für die Erkennung der gefundenen Linien viel schwieriger, ein solches Modell zu erhalten. Aus diesem Grund haben wir beschlossen,
für jedes Skript ein
eigenes Modell zu verwenden (kyrillisch, lateinisch, arabisch, hebräisch, griechisch, armenisch, georgisch, koreanisch, thailändisch). Aufgrund der großen Schnittmenge in Hieroglyphen wird für Chinesisch und Japanisch ein separates allgemeines Modell verwendet.
Das Modell, das dem gesamten Skript gemeinsam ist, unterscheidet sich vom separaten Modell für jede Sprache um weniger als 1 S.p. Qualität. Gleichzeitig ist die Erstellung und Implementierung eines Modells einfacher als beispielsweise 25 Modelle (die Anzahl der von unserem Modell unterstützten lateinischen Sprachen). Aufgrund der häufigen Präsenz von Englisch in allen Sprachen können alle unsere Modelle zusätzlich zur Hauptsprache auch lateinische Zeichen vorhersagen.
Um zu verstehen, welches Modell für die Erkennung verwendet werden soll, bestimmen wir zunächst, ob die empfangenen Zeilen zu einem der 10 zur Erkennung verfügbaren Skripte gehören.
Es sollte separat angemerkt werden, dass es nicht immer möglich ist, sein Skript eindeutig entlang der Linie zu bestimmen. Beispielsweise sind in vielen Skripten Zahlen oder einzelne lateinische Zeichen enthalten, sodass eine der Ausgabeklassen des Modells ein "undefiniertes" Skript ist.
Skriptdefinition
Um das Skript zu definieren, haben wir einen separaten Klassifikator erstellt. Das Definieren eines Skripts ist viel einfacher als das Erkennen, und das neuronale Netzwerk kann auf einfache Weise auf synthetische Daten umgeschult werden. Daher wurde in unseren Experimenten eine signifikante Verbesserung der Qualität des Modells durch
Vortraining zum Problem der Zeichenkettenerkennung erzielt . Dazu haben wir das Netzwerk zunächst auf das Erkennungsproblem für alle verfügbaren Sprachen geschult. Danach wurde das resultierende Backbone verwendet, um das Modell für die Skriptklassifizierungsaufgabe zu initialisieren.
Während ein Skript in einer einzelnen Zeile oft ziemlich laut ist, enthält das gesamte Bild meistens Text in einer Sprache, entweder zusätzlich zu dem mit Englisch durchsetzten Haupttext (oder im Fall unserer russischen Benutzer). Um
die Stabilität zu
erhöhen , aggregieren wir daher die Vorhersagen der Linien aus dem Bild, um eine stabilere Vorhersage des Bildskripts zu erhalten. Zeilen mit einer vorhergesagten Klasse von "unbestimmt" werden bei der Aggregation nicht berücksichtigt.
Linienerkennung
Wenn wir im nächsten Schritt die Position jeder Zeile und ihres Skripts bereits bestimmt haben, müssen wir
die Zeichenfolge anhand des angegebenen Skripts erkennen , dh anhand der Pixelfolge, um die Zeichenfolge vorherzusagen. Nach vielen Experimenten sind wir zu folgendem aufmerksamkeitsbasiertem Modell von sequence2sequence gekommen:

Wenn Sie CNN + BiLSTM im Encoder verwenden, können Sie Zeichen abrufen, die sowohl lokale als auch globale Kontexte erfassen. Für Text ist dies wichtig - oft wird er in einer Schriftart geschrieben (das Unterscheiden ähnlicher Buchstaben mit Schriftinformationen ist viel einfacher). Um zwei Buchstaben, die mit einem Leerzeichen geschrieben sind, von aufeinanderfolgenden Buchstaben zu unterscheiden, werden auch globale Statistiken für die Zeile benötigt.
Eine interessante Beobachtung : Im resultierenden Modell können die Ausgaben der Aufmerksamkeitsmaske für ein bestimmtes Symbol verwendet werden, um dessen Position im Bild vorherzusagen.
Dies hat uns dazu inspiriert,
die Aufmerksamkeit des Modells klar zu „fokussieren“ . Solche Ideen wurden auch in Artikeln gefunden - zum Beispiel im Artikel „
Focusing Attention: Towards Accurate Text Recognition in Natural Images“ .
Da der Aufmerksamkeitsmechanismus eine Wahrscheinlichkeitsverteilung über den Merkmalsraum ergibt, erhalten wir den Teil der „Aufmerksamkeit“, der sich direkt darauf konzentriert, wenn wir als zusätzlichen Verlust die Summe der Aufmerksamkeitsausgaben innerhalb der Maske nehmen, die dem in diesem Schritt vorhergesagten Buchstaben entsprechen.
Durch die Einführung von loss -log (∑
i, j∈M t α
i, j ), wobei M
t die Maske des zehnten Buchstabens und α die Ausgabe der Aufmerksamkeit ist, fördern wir die Aufmerksamkeit für die Fokussierung auf das gegebene Symbol und helfen damit Neuronale Netze lernen besser.
Bei Trainingsbeispielen, bei denen die Position einzelner Zeichen unbekannt oder ungenau ist (nicht alle Trainingsdaten haben Markierungen auf der Ebene einzelner Zeichen, nicht Wörter), wurde dieser Begriff im endgültigen Verlust nicht berücksichtigt.
Ein weiteres nettes Feature: Mit dieser Architektur können Sie die
Erkennung von Linien von rechts nach links ohne zusätzliche Änderungen vorhersagen (was zum Beispiel für Sprachen wie Arabisch und Hebräisch wichtig ist). Das Modell selbst beginnt von rechts nach links zu erkennen.
Schnelle und langsame Modelle
Dabei sind wir auf ein Problem gestoßen:
Bei "hohen" Schriften , dh vertikal verlängerten Schriften, funktionierte das Modell schlecht. Dies wurde durch die Tatsache verursacht, dass die Abmessung von Zeichen auf der Aufmerksamkeitsebene 8-mal kleiner ist als die Abmessung des Originalbilds, da die Architektur des Faltungsteils des Netzwerks schrittweise verändert wurde. Die Positionen mehrerer benachbarter Zeichen im Quellbild können der Position desselben Merkmalsvektors entsprechen, was in solchen Beispielen zu Fehlern führen kann. Der Einsatz von Architektur mit einer geringeren Einengung der Merkmalsdimension führte zu einer Qualitätssteigerung, aber auch zu einer Verlängerung der Bearbeitungszeit.
Um dieses Problem zu lösen und
die Verarbeitungszeit nicht zu verlängern , haben wir das Modell folgendermaßen verfeinert:
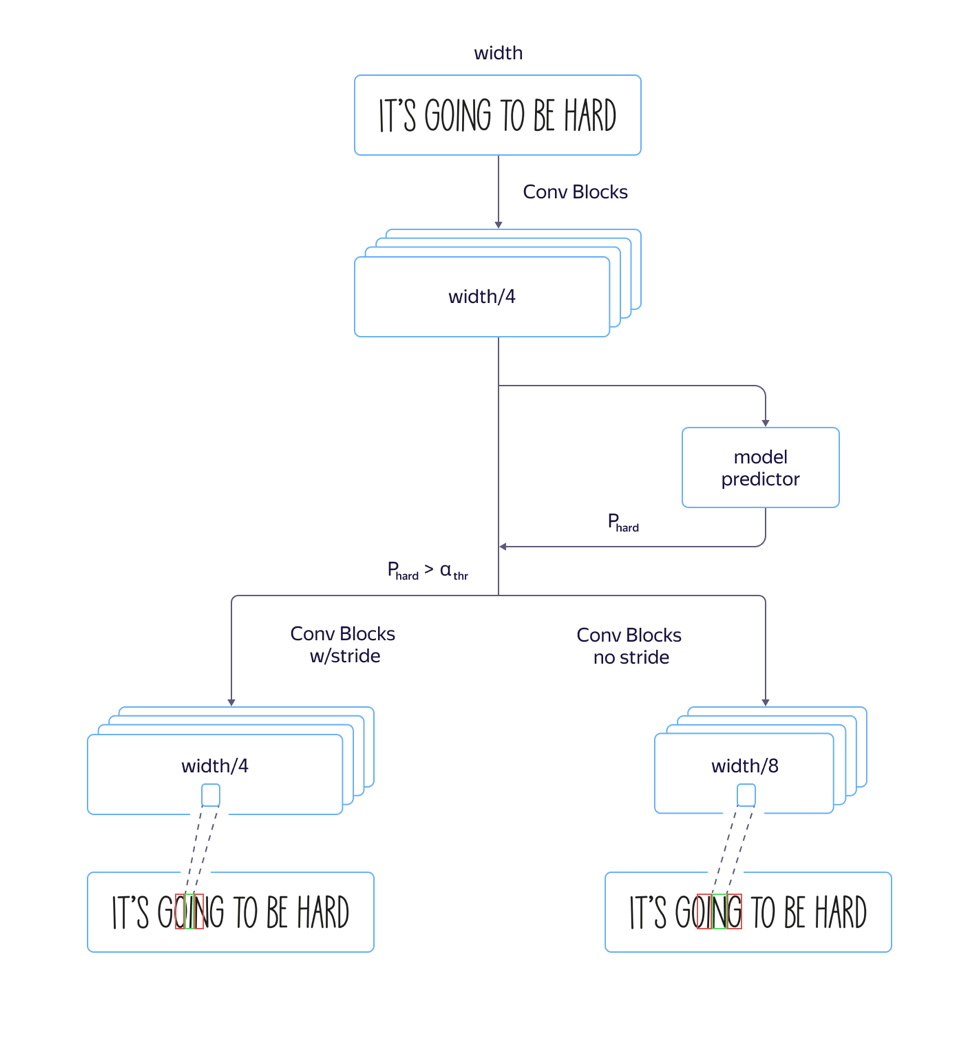
Wir haben sowohl ein schnelles Modell mit vielen Schritten als auch ein langsames mit weniger Schritten trainiert. Auf der Ebene, auf der sich die Modellparameter zu unterscheiden begannen, wurde eine separate Netzwerkausgabe hinzugefügt, die vorhersagte, welches Modell weniger Erkennungsfehler aufweisen würde. Der Totalverlust des Modells setzte sich aus L
klein + L
groß + L
Qualität zusammen . Auf der Zwischenebene hat das Modell also gelernt, die „Komplexität“ dieses Beispiels zu bestimmen. In der Anwendungsphase wurden außerdem der allgemeine Teil und die Vorhersage der „Komplexität“ des Beispiels für alle Linien berücksichtigt, und je nach Ausgabe wurde in Zukunft je nach Schwellenwert entweder ein schnelles oder ein langsames Modell verwendet. Dies ermöglichte es uns, eine Qualität zu erzielen, die sich kaum von der eines langen Modells unterscheidet, während die Geschwindigkeit nur um 5% anstatt der geschätzten 30% zunahm.
Trainingsdaten
Ein wichtiger Schritt bei der Erstellung eines qualitativ hochwertigen Modells ist die Vorbereitung eines großen und abwechslungsreichen Trainingsmusters. Die "synthetische" Natur des Textes ermöglicht es, große Mengen von Beispielen zu generieren und mit realen Daten gute Ergebnisse zu erzielen.
Nach dem ersten Ansatz zur Generierung synthetischer Daten haben wir die Ergebnisse des erhaltenen Modells sorgfältig geprüft und festgestellt, dass das Modell einzelne Buchstaben "I" aufgrund der Verzerrung in den Texten, die zur Erstellung des Trainingssatzes verwendet wurden, nicht gut erkennt. Aus diesem Grund haben wir eine
Reihe von „problematischen“ Beispielen generiert, und als wir sie zu den ursprünglichen Daten des Modells hinzufügten, erhöhte sich die Qualität erheblich. Wir haben diesen Vorgang viele Male wiederholt und dabei immer komplexere Schichten hinzugefügt, bei denen wir die Erkennungsqualität verbessern wollten.
Wichtig ist, dass die generierten
Daten vielfältig und realistisch sind . Wenn Sie möchten, dass das Modell Fotos von Text auf Papierbögen bearbeitet und der gesamte synthetische Datensatz Text enthält, der über Landschaften geschrieben wurde, funktioniert dies möglicherweise nicht.
Ein weiterer wichtiger Schritt besteht darin, die Beispiele zu trainieren, bei denen die aktuelle Erkennung falsch ist. Wenn es eine große Anzahl von Bildern gibt, für die es kein Markup gibt, können Sie die Ausgaben des aktuellen Erkennungssystems, bei denen sie sich nicht sicher ist, nur markieren, wodurch die Kosten für das Markup reduziert werden.
Für komplexe Beispiele haben wir die Nutzer des Yandex.Tolok-Dienstes gebeten, gegen eine Gebühr
Bilder einer bestimmten „komplexen“ Gruppe zu fotografieren und uns zu senden - zum Beispiel Fotos von Warenpaketen:


Qualität der Arbeit an "komplexen" Daten
Wir möchten unseren Nutzern die Möglichkeit geben, mit Fotos jeglicher Komplexität zu arbeiten, da es erforderlich sein kann, Texte nicht nur auf der Seite eines Buches oder eines gescannten Dokuments, sondern auch auf einem Straßenschild, einer Werbung oder einer Produktverpackung zu erkennen oder zu übersetzen. Während wir die hohe Qualität der Arbeit am Fluss von Büchern und Dokumenten aufrechterhalten (wir werden diesem Thema eine eigene Geschichte widmen), widmen wir daher „komplexen Bildsätzen“ besondere Aufmerksamkeit.
Auf die oben beschriebene Weise haben wir eine Reihe von Bildern zusammengestellt, die Text in freier Wildbahn enthalten und für unsere Benutzer nützlich sein können: Fotografien von Schildern, Ankündigungen, Tafeln, Buchumschlägen, Texten auf Haushaltsgeräten, Kleidung und Gegenständen. An diesem Datensatz (auf den unten verwiesen wird) haben wir die Qualität unseres Algorithmus bewertet.
Als Vergleichsmaß haben wir das Standardmaß für die Genauigkeit und Vollständigkeit der Worterkennung im Datensatz sowie das F-Maß verwendet. Ein erkanntes Wort gilt als richtig gefunden, wenn seine Koordinaten mit den Koordinaten des markierten Wortes (IoU> 0.3) übereinstimmen und die Erkennung mit der genau zum Fall markierten übereinstimmt. Zahlen zum resultierenden Datensatz:
Datensatz, Metriken und Skripte zur Reproduktion der Ergebnisse finden Sie
hier .
Upd. Freunde, die unsere Technologie mit einer ähnlichen Lösung von Abbyy verglichen haben, sorgten für große Kontroversen. Wir respektieren die Meinungen der Community und der Branchenkollegen. Gleichzeitig sind wir zuversichtlich in unsere Ergebnisse und haben uns daher für diesen Weg entschieden: Wir werden die Ergebnisse anderer Produkte aus dem Vergleich entfernen, die Testmethode erneut mit ihnen besprechen und zu den Ergebnissen zurückkehren, in denen wir eine allgemeine Einigung erzielen.
Nächste Schritte
An der Schnittstelle zwischen einzelnen Schritten wie Erkennung und Erkennung treten immer wieder Probleme auf: Kleinste Änderungen des Erkennungsmodells machen eine Änderung des Erkennungsmodells erforderlich, sodass wir aktiv daran experimentieren, eine End-to-End-Lösung zu erstellen.
Zusätzlich zu den bereits beschriebenen Möglichkeiten zur Verbesserung der Technologie werden wir eine Anleitung zur Analyse der Struktur des Dokuments entwickeln, die für das Extrahieren von Informationen von grundlegender Bedeutung ist und von den Benutzern nachgefragt wird.
Fazit
Benutzer sind bereits an praktische Technologien gewöhnt und schalten ohne zu zögern die Kamera ein, zeigen auf das Ladenschild, das Menü im Restaurant oder die Seite im Buch in einer Fremdsprache und erhalten schnell eine Übersetzung. Wir erkennen Texte in 45 Sprachen mit bewährter Genauigkeit, und die Möglichkeiten werden sich nur erweitern. Eine Reihe von Tools in Yandex.Cloud ermöglicht es jedem, die bewährten Methoden zu nutzen, die Yandex seit langer Zeit für sich verwendet.
Heute können Sie die fertige Technologie einfach in Ihre eigene Anwendung integrieren und verwenden, um neue Produkte zu erstellen und Ihre eigenen Prozesse zu automatisieren. Die Dokumentation zu unserer OCR finden Sie
hier .
Was zu lesen:
- D. Karatzas, SR Mestre, J. Mas, F. Nourbakhsh und PP Roy, „ICDAR 2011 - Robuster Lesewettbewerb - Herausforderung 1: Lesen von Text in geborenen digitalen Bildern (Web und E-Mail)“ in Document Analysis and Recognition (ICDAR) ), 2011 Internationale Konferenz über. IEEE, 2011, pp. 1485-1490.
- Karatzas D. et al. ICDAR 2015-Wettbewerb für robustes Lesen // 2015 13. Internationale Konferenz für Dokumentenanalyse und -erkennung (ICDAR). - IEEE, 2015 - S. 1156-1160.
- Chee-Kheng Chng et. al. ICDAR2019 Robust Reading Challenge für beliebig geformten Text (RRC-ArT) [ arxiv: 1909.07145v1 ]
- ICDAR 2019 Robust Reading Challenge für gescannte Belege OCR und Informationsextraktion rrc.cvc.uab.es/?ch=13
- ShopSign: Ein Textdatensatz mit verschiedenen Szenen chinesischer Ladenschilder in Straßenansichten [ arxiv: 1903.10412 ]
- Baoguang Shi, Xiang Bai und Serge Belongie erkennen orientierten Text in natürlichen Bildern durch Verknüpfung von Segmenten [ arxiv: 1703.06520 ].
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu und Shuigeng Zhou.