Die Übersetzung des Artikels wurde speziell für Studenten des Kurses "DevOps Practices and Tools" erstellt .
Dieser Artikel beschreibt die Beziehung zwischen Codestruktur und Organisationsstruktur in der Softwareentwicklung. Ich diskutiere, warum Software und Teams nicht einfach skaliert werden können, welche Lektionen wir in der Natur und im Internet sehen können und wie wir die Konnektivität von Software und Teams reduzieren können, um die Skalierungsprobleme zu überwinden.
Der Artikel basiert auf meiner 20-jährigen Erfahrung mit der Erstellung großer Softwaresysteme und dem Eindruck des Buches
„Accelerate: Die Wissenschaft von Lean Software und DevOps: Aufbau und Skalierung leistungsfähiger Technologieunternehmen“ (Nicole Forsgren, Jez Humble und Gene Kim), in dem Nachforschungen belegen die meisten meiner Behauptungen hier. Dieses Buch ist zum Lesen sehr zu empfehlen.

Software und Befehle skalieren nicht
Oft ist die erste Veröffentlichung, die vielleicht von ein oder zwei Leuten geschrieben wurde, überraschend einfach. Es hat möglicherweise eingeschränkte Funktionen, ist jedoch schnell geschrieben und entspricht den Kundenanforderungen. Die Interaktion mit dem Kunden ist zu diesem Zeitpunkt hervorragend, da der Kunde in der Regel in direktem Kontakt mit den Entwicklern steht. Alle Fehler werden schnell behoben und neue Funktionen können problemlos hinzugefügt werden. Nach einer Weile verlangsamt sich das Tempo. Version 2.0 dauert etwas länger als erwartet. Es ist schwieriger, Fehler zu beheben, und es gibt neue Funktionen, es ist nicht so einfach. Die natürliche Antwort darauf ist das Hinzufügen neuer Entwickler zum Team. Obwohl es so aussieht, als würde jeder zusätzliche Mitarbeiter die Produktivität verringern. Es besteht das Gefühl, dass die Software mit zunehmender Komplexität verkümmert. In extremen Fällen stellen Unternehmen möglicherweise fest, dass sie Programme mit sehr kostspieligem Support verwenden, bei denen es fast unmöglich ist, Änderungen vorzunehmen. Das Problem ist, dass Sie keine „Fehler“ machen müssen, um dies zu erreichen. Es ist so verbreitet, dass man sagen kann, dass dies eine „natürliche“ Eigenschaft von Software ist.
Warum passiert das? Es gibt zwei Gründe: die im Zusammenhang mit dem Code und dem Team. Sowohl Code als auch Befehle lassen sich nicht gut skalieren.
Wenn die Codebasis wächst, wird es für eine Person immer schwieriger, sie zu verstehen. Es gibt feste kognitive Grenzen einer Person. Und zwar kann sich eine Person die Details eines kleinen Systems merken, aber nur, bis es mehr als seinen kognitiven Bereich erreicht. Sobald ein Team auf fünf oder mehr Personen angewachsen ist, ist es für eine Person fast unmöglich, sich darüber im Klaren zu sein, wie alle Teile des Systems funktionieren. Und wenn niemand das ganze System versteht, taucht Angst auf. In einem großen, eng gekoppelten System ist es sehr schwierig, die Auswirkung von signifikanten Änderungen zu verstehen, da das Ergebnis nicht lokalisiert ist. Um die Auswirkungen von Änderungen zu minimieren, beginnen Entwickler, Problemumgehungen und Codeduplizierungen zu verwenden, anstatt gemeinsame Features zu identifizieren und Abstraktionen und Generalisierungen zu erstellen. Dies kompliziert das System weiter und verstärkt diese negativen Trends. Entwickler fühlen sich nicht länger für Code verantwortlich, den sie nicht verstehen und nicht gerne überarbeiten. Die technische Verschuldung wächst. Es macht auch die Arbeit unangenehm und unbefriedigend und stimuliert einen „Talentabfluss“, wenn die besten Entwickler abreisen, die leicht Arbeit an anderer Stelle finden können.
Teams skalieren auch nicht. Wenn die Teams wachsen, wird die Kommunikation komplexer. Eine einfache Formel kommt ins Spiel:
c = n(n-1)/2(wobei n die Anzahl der Personen und c die Anzahl der möglichen Verbindungen zwischen Teammitgliedern ist)Mit dem Wachstum ihres Teams wächst ihr Bedarf an Kommunikation und Koordination exponentiell. Wenn ein bestimmtes Team überschritten wird, ist es für ein Team sehr schwierig, eine integrale Struktur zu bleiben, und die natürliche menschliche soziale Tendenz, sich in kleinere Gruppen aufzuteilen, führt zur Bildung informeller Untergruppen, auch wenn das Management nicht daran teilnimmt. Die Kommunikation mit Kollegen wird schwieriger und wird natürlich durch neue Führungskräfte und Top-Down-Kommunikation ersetzt. Teammitglieder werden von Kollegen im System zu regulären Produktionsmitarbeitern. Die Motivation leidet, es gibt kein Gefühl
der Eigenverantwortung aufgrund des
Effekts der Verantwortungsdiffusion .
Das Management greift in dieser Phase häufig ein und nähert sich formell der Schaffung neuer Teams und Managementstrukturen. Es ist jedoch weder formal noch informell von Bedeutung, dass es für große Unternehmen schwierig ist, Motivation und Interesse aufrechtzuerhalten.
Normalerweise geben unerfahrene Entwickler und schlechtes Management diesen Skalierungspathologien die Schuld. Das ist aber unfair. Skalierungsprobleme sind eine „natürliche“ Eigenschaft wachsender und sich entwickelnder Software. Dies geschieht immer dann, wenn Sie das Problem nicht in einem frühen Stadium finden, den Abweichungspunkt nicht verstehen und keine Anstrengungen unternehmen, um das Problem zu lösen. Softwareentwicklungsteams werden ständig zusammengestellt, die Menge an Software in der Welt wächst ständig und der größte Teil der Software ist relativ klein. Daher wird ein erfolgreiches und sich entwickelndes Produkt häufig von einem Team erstellt, das keine Erfahrung in der Entwicklung in großem Maßstab hat. Und es ist unrealistisch, von Entwicklern zu erwarten, dass sie den Wendepunkt erkennen und verstehen, was zu tun ist, wenn sich Skalenprobleme manifestieren.
Nature Scaling-Lektionen
Ich habe kürzlich das ausgezeichnete Buch
„Scale“ von Geoffrey West gelesen. Es geht um die Skalenmathematik in biologischen und sozioökonomischen Systemen. Seine These ist, dass alle großen komplexen Systeme den grundlegenden Skalengesetzen gehorchen. Dies ist eine faszinierende Lektüre, die ich sehr empfehlen kann. In diesem Artikel möchte ich mich auf seine Sichtweise konzentrieren, dass viele biologische und soziale Systeme überraschend gut skalieren. Schauen Sie sich den Körper eines Säugetiers an. Alle Säugetiere haben die gleichen Zelltypen, Knochenstrukturen, Nerven- und Kreislaufsysteme. Der Größenunterschied zwischen Maus und Blauwal beträgt jedoch ca. 10 ^ 7. Wie nutzt die Natur die gleichen Materialien und Strukturen für Organismen unterschiedlichster Größe? Die Antwort scheint zu sein, dass die Evolution fraktal verzweigte Strukturen entdeckt hat. Schau dir den Baum an. Jeder Teil davon sieht aus wie ein kleiner Baum. Das gleiche gilt für das Kreislauf- und Nervensystem von Säugetieren. Es handelt sich um verzweigte fraktale Netzwerke, in denen ein kleiner Teil Ihrer Lunge oder Blutgefäße wie eine kleinere Version des Ganzen aussieht.

Können wir diese Ideen aus der Natur übernehmen und auf Software anwenden? Ich denke, wir können wichtige Lektionen lernen. Wenn wir große Systeme bauen können, die aus kleinen Teilen bestehen, die selbst wie komplette Systeme aussehen, können wir die Pathologien enthalten, die die meisten Programme betreffen, wenn sie wachsen und sich entwickeln.
Gibt es Softwaresysteme, die sich erfolgreich um mehrere Größenordnungen skalieren lassen? Die Antwort liegt auf der Hand - das Internet, ein globales Softwaresystem mit Millionen von Knoten. Subnetze sehen wirklich aus und funktionieren wie kleinere Versionen des gesamten Internets.
Anzeichen für lose gekoppelte Software
Die Fähigkeit, separate, lose gekoppelte Komponenten in einem großen System zu isolieren, ist die Hauptmethode für eine erfolgreiche Skalierung. Das Internet ist in der Tat ein Beispiel für eine lose gekoppelte Architektur. Dies bedeutet, dass jeder Knoten, Dienst oder jede Anwendung im Netzwerk die folgenden Eigenschaften aufweist:
- Es wird ein gemeinsames Kommunikationsprotokoll verwendet.
- Die Datenübertragung erfolgt über einen eindeutigen Vertrag mit anderen Knoten.
- Für die Kommunikation sind keine Kenntnisse über bestimmte Implementierungstechnologien erforderlich.
- Versionierung und Bereitstellung sind unabhängig.
Das Internet ist skalierbar, da es sich um ein Netzwerk von Knoten handelt, die über eine Reihe klar definierter Protokolle kommunizieren. Knoten interagieren nur über Protokolle, deren Implementierungsdetails den interagierenden Knoten nicht bekannt sein sollten. Das globale Internet wird nicht als einzelnes System bereitgestellt. Jeder Knoten verfügt über eine eigene Version und ein eigenes Bereitstellungsverfahren. Einzelne Knoten erscheinen und verschwinden unabhängig voneinander. Die Übermittlung an Internet-Protokolle ist das einzige, was für das gesamte System wirklich wichtig ist. Wer jeden Knoten erstellt hat, wann er erstellt oder gelöscht wurde, welche Version er hat, welche spezifischen Technologien und Plattformen er verwendet, all dies hat nichts mit dem Internet als Ganzes zu tun. Das ist es, was wir unter lose gekoppelter Software verstehen.
Zeichen einer locker gekoppelten Organisation
Wir können Teams nach denselben Prinzipien skalieren:
- Jedes Subteam sollte wie eine kleine Softwareentwicklungsorganisation aussehen.
- Interne Prozesse und Teamkommunikation sollten nicht über das Team hinausgehen.
- Die zur Implementierung der Software verwendeten Technologien und Prozesse sollten nicht außerhalb des Teams diskutiert werden.
- Teams sollten nur über externe Themen miteinander kommunizieren: gemeinsame Protokolle, Funktionen, Service-Levels und Ressourcen.
Kleine Entwicklungsteams sind effektiver als große. Sie müssen daher große Teams in kleinere Gruppen aufteilen. Die Lektionen der Natur und des Internets besagen, dass Untergruppen wie einzelne kleine Softwareentwicklungsorganisationen aussehen sollten. Wie klein sind sie Idealerweise von ein bis fünf Personen.
Wichtig ist, dass jedes Team wie eine kleine unabhängige Softwareentwicklungsorganisation aussieht. Andere Arten, Teams zu organisieren, sind weniger effektiv. Oft besteht die Versuchung, ein großes Team in Funktionen zu unterteilen. Aus diesem Grund verfügen wir über ein Architektenteam, ein Entwicklungsteam, ein DBA-Team, ein Testerteam, ein Bereitstellungsteam und ein Supportteam. Dies löst jedoch keines der oben genannten Skalierungsprobleme. Alle Teams sollten an der Entwicklung eines Features teilnehmen und häufig iterativ, wenn Sie Projektmanagement im Stil eines Wasserfalls vermeiden möchten.
Kommunikationsbarrieren zwischen diesen Funktionsteams werden zu einem Haupthindernis für eine effiziente und rechtzeitige Bereitstellung. Teams sind eng miteinander verbunden, da sie wichtige interne Details austauschen müssen, um zusammenzuarbeiten. Darüber hinaus stimmen die Interessen verschiedener Teams nicht überein: Entwickler erhalten in der Regel eine Auszeichnung für neue Funktionen, Tester für Qualität und Unterstützung für Stabilität. Diese unterschiedlichen Interessen können zu Konflikten und schlechten Ergebnissen führen. Warum sollten sich Entwickler um Protokolle sorgen, wenn sie diese nie lesen? Warum sollten sich Tester um die Lieferung kümmern, wenn sie für die Qualität verantwortlich sind?
Stattdessen sollten wir Teams für lose gekoppelte Services organisieren, die Geschäftsfunktionen unterstützen, oder für eine logische Gruppe von Funktionen. Jeder Unterbefehl sollte seine eigene Software entwerfen, codieren, testen, bereitstellen und warten. Höchstwahrscheinlich sind die Mitglieder eines solchen Teams Spezialisten mit einem breiten Profil und keine engen Spezialisten, da es in einem kleinen Team erforderlich sein wird, diese Rollen zu trennen. Sie sollten sich auf die maximal mögliche Automatisierung von Prozessen konzentrieren: automatisiertes Testen, Bereitstellen, Überwachen. Teams müssen ihre eigenen Tools auswählen und die Architektur für ihre Systeme entwerfen. Obwohl die für die Interaktion von Diensten verwendeten Protokolle auf Organisationsebene festgelegt werden sollten, sollte die Auswahl der zu ihrer Implementierung verwendeten Tools an die Teams delegiert werden. Und das passt sehr gut zum DevOps-Modell.
Der Grad der Unabhängigkeit eines Teams spiegelt den Grad der Verbundenheit der gesamten Organisation wider. Im Idealfall sollte sich die Organisation um die Funktionalität der Software und letztendlich den geschäftlichen Nutzen des Teams sowie die Kosten für die Teamressourcen kümmern.
In diesem Fall spielt der Softwarearchitekt eine wichtige Rolle. Es sollte sich nicht auf bestimmte Tools und Technologien konzentrieren, die von Teams verwendet werden, oder die Details der internen Architektur von Diensten beeinträchtigen. Stattdessen sollte der Schwerpunkt auf Protokollen und Interaktionen zwischen verschiedenen Diensten und dem Zustand des gesamten Systems liegen.
Conways umgekehrtes Gesetz: Die Organisationsstruktur muss die Zielarchitektur modellieren
Wie passen schwache Softwarekohärenz und schwache Teamkohärenz zusammen?
Conways Gesetz besagt:
"Organisationen, die Systeme entwerfen, sind auf ein Design beschränkt, das die Kommunikationsstruktur dieser Organisation kopiert."
Dies basiert auf der Beobachtung, dass die Architektur eines Softwaresystems die Struktur der Organisation widerspiegelt, die es erstellt. Wir können Conways Gesetz "hacken", indem wir es umdrehen. Organisieren Sie unsere Teams, um die gewünschte Architektur widerzuspiegeln. In diesem Sinne müssen wir lose gekoppelte Teams mit lose gekoppelten Softwarekomponenten ausrichten. Aber sollte es eine Eins-zu-Eins-Beziehung sein? Ich denke im Idealfall ja. Obwohl es gut zu sein scheint, wenn ein kleines Team an mehreren lose gekoppelten Diensten arbeitet. Ich würde sagen, dass der Wendepunkt für die Skalierung für Teams größer ist als für Software, so dass dieser Organisationsstil akzeptabel erscheint. Es ist wichtig, dass die Softwarekomponenten mit ihrer eigenen Versionierung und Bereitstellung getrennt bleiben, auch wenn einige von ihnen von einem Team entwickelt werden. Wir möchten in der Lage sein, das Team zu teilen, wenn es zu groß wird, indem wir entwickelte Dienste auf verschiedene Teams übertragen. Dies ist jedoch nicht möglich, wenn die Dienste eng miteinander verbunden sind oder einen Prozess, eine Versionierung oder eine Bereitstellung gemeinsam nutzen.
Wir müssen die Arbeit mehrerer Teams an denselben Komponenten vermeiden. Dies ist ein Anti-Muster. In gewisser Hinsicht sogar noch schlimmer als die Arbeit eines großen Teams mit einer großen Codebasis, da Kommunikationsbarrieren zwischen Teams zu einem noch stärkeren Gefühl von mangelnder Eigenverantwortung und Kontrolle führen.
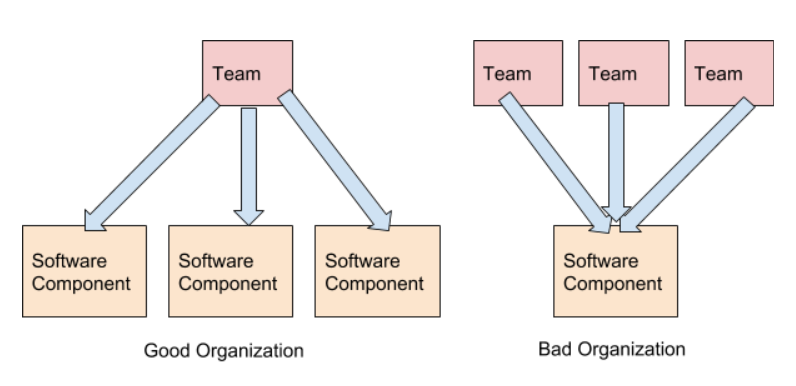
Die Interaktion zwischen lose gekoppelten Teams, die lose gekoppelte Software erstellen, wird minimiert. Nehmen Sie noch einmal das Internet-Beispiel. Häufig können Sie die von einem anderen Unternehmen bereitgestellte API verwenden, ohne direkt damit zu kommunizieren (wenn der Vorgang einfach ist und Dokumentation vorhanden ist). Wenn Teams interagieren, sollten interne Teamentwicklungs- und Implementierungsprozesse nicht diskutiert werden. Stattdessen sollten Funktionalität, Servicelevel und Ressourcen erörtert werden.
Die Verwaltung lose verbundener Teams, die lose verbundene Software erstellen, sollte einfacher sein als Alternativen. Eine große Organisation sollte sich darauf konzentrieren, Teams klare Ziele und Anforderungen in Bezug auf Funktionalität und Servicelevel zu liefern. Die Ressourcenanforderungen sollten vom Team stammen, obwohl sie von der Organisation verwendet werden können, um die Kapitalrendite zu messen.
Locker gekoppelte Teams entwickeln locker gekoppelte Software
Eine schwache Konnektivität in der Software und zwischen den Teams ist der Schlüssel zum Aufbau einer hocheffektiven Organisation. Und meine Erfahrung bestätigt diesen Punkt. Ich habe in Organisationen gearbeitet, in denen die Teams nach Funktionen, nach Software-Ebene oder sogar nach Kunden getrennt waren. Ich habe auch in großen chaotischen Teams auf einer einzigen Codebasis gearbeitet. In all diesen Fällen gab es jedoch Probleme mit der Skalierung, die oben erwähnt wurden. Die angenehmste Erfahrung war immer, als mein Team eine vollwertige Einheit war, die unabhängig mit der Erstellung, Prüfung und Bereitstellung unabhängiger Dienste befasst war. Aber Sie müssen sich nicht auf meine Lebensgeschichten verlassen. Accelerate (oben beschrieben) hat Forschungsergebnisse, die diese Ansicht stützen.
Wenn Sie dieses Material bis zum Ende gelesen haben, empfehlen wir Ihnen, sich eine Aufzeichnung eines offenen Webinars zum Thema „Ein Tag im Leben von DevOps“ anzusehen.