Guten Tag und meinen Respekt, Leser von Habr!
Hintergrund
Bei uns ist es üblich, interessante Erkenntnisse in Entwicklungsteams auszutauschen. Bei der nächsten Besprechung, in der insbesondere die Zukunft von .NET und .NET 5 erörtert wurde, konzentrierten sich meine Kollegen und ich darauf, eine einheitliche Plattform auf diesem Bild zu sehen:
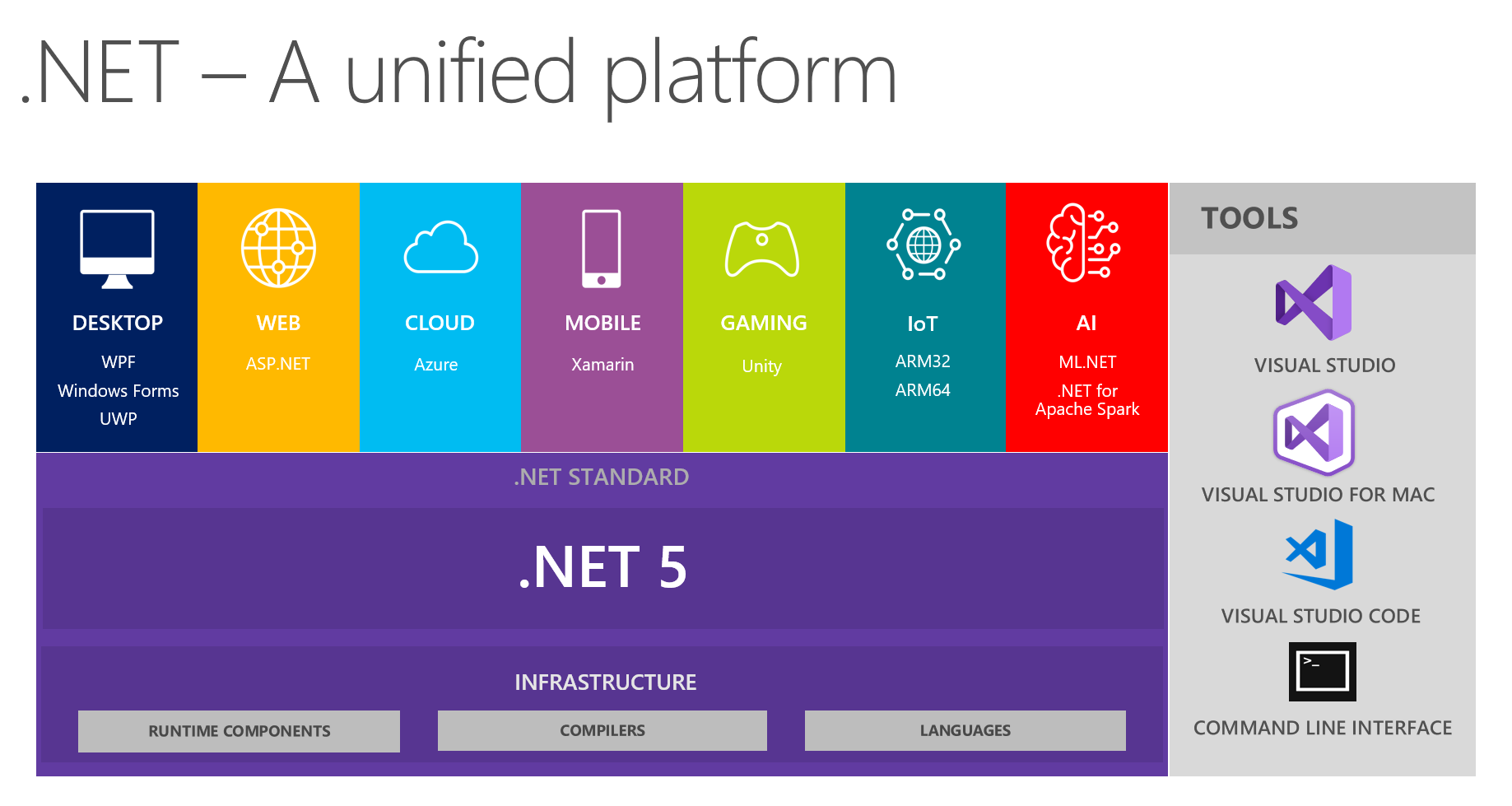
Es zeigt, dass die Plattform DESKTOP, WEB, CLOUD, MOBILE, GAMING, IoT und AI kombiniert. Ich hatte die Idee, ein Gespräch in Form eines kleinen Berichts + Fragen / Antworten zu jedem Thema bei den nächsten Treffen zu führen. Der Verantwortliche für ein bestimmtes Thema bereitet sich vor, liest Informationen über die wichtigsten Neuerungen vor, versucht, etwas mit der gewählten Technologie umzusetzen, und teilt uns dann seine Gedanken und Eindrücke mit. Auf diese Weise erhält jeder aus erster Hand ein echtes Feedback zu den Tools von einer vertrauenswürdigen Quelle. Dies ist sehr praktisch, da Ihre Hände möglicherweise nicht in der Lage sind, alle Themen selbst auszuprobieren und zu stürmen.
Da ich mich seit einiger Zeit aktiv mit maschinellem Lernen als Hobby beschäftige (und es manchmal für nicht-geschäftliche Aufgaben bei der Arbeit verwende), habe ich das Thema AI & ML.NET. Während der Vorbereitung stieß ich auf wundervolle Werkzeuge und Materialien. Zu meiner Überraschung stellte ich fest, dass es auf Habré nur sehr wenige Informationen darüber gibt. Früher in dem offiziellen Blog schrieb Microsoft über die Veröffentlichung von ML.Net und insbesondere von Model Builder. Ich möchte mitteilen, wie ich zu ihm gekommen bin und welche Eindrücke ich durch die Arbeit mit ihm bekommen habe. In diesem Artikel geht es mehr um Model Builder als um ML in .NET als Ganzes. Wir werden versuchen herauszufinden, was MS dem durchschnittlichen .NET-Entwickler bietet, aber mit den Augen einer Person, die sich mit ML auskennt. Gleichzeitig werde ich versuchen, ein Gleichgewicht zwischen dem Nacherzählen des Tutorials, dem absoluten Kauen für Anfänger und der Beschreibung von Details für ML-Spezialisten zu halten, die aus irgendeinem Grund zu .NET kommen mussten.
Hauptteil
Ein kurzer Blick auf ML in .NET bringt mich zur Tutorial-Seite :
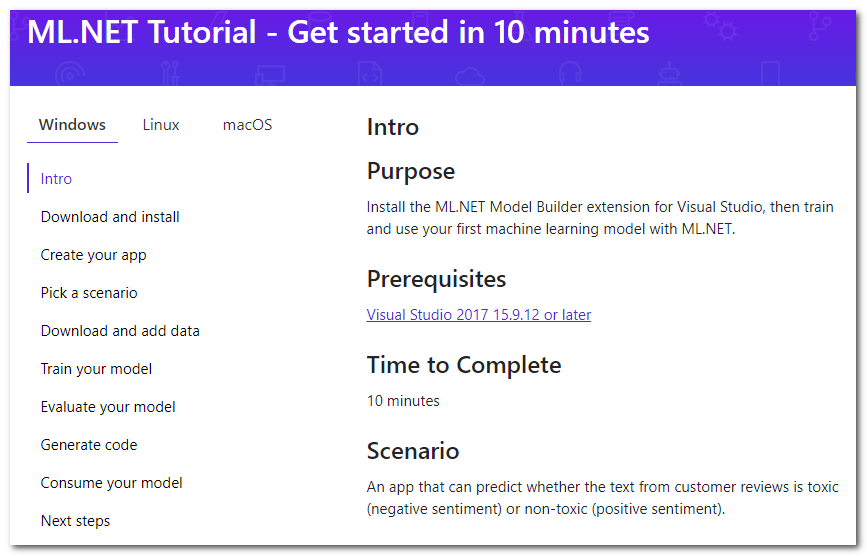
Es stellt sich heraus, dass es für Visual Studio eine spezielle Erweiterung namens Model Builder gibt, mit der Sie "Ihrem Projekt maschinelles Lernen mit der rechten Maustaste hinzufügen können" (kostenlose Übersetzung). Ich werde kurz auf die Hauptschritte des Tutorials eingehen, die angeboten werden, und ich werde Details und meine Gedanken hinzufügen.
Herunterladen und installieren
Knopf drücken, herunterladen, installieren. Das Studio muss neu gestartet werden.
Erstellen Sie Ihre App
Erstellen Sie zunächst eine reguläre C # -Anwendung. Im Tutorial wird vorgeschlagen, Core zu erstellen, passt aber auch zum Framework. Und dann beginnt ML - klicken Sie mit der rechten Maustaste auf das Projekt und wählen Sie Hinzufügen -> Maschinelles Lernen. Das Fenster, das zum Erstellen des Modells angezeigt wird, wird analysiert, da dort die ganze Magie abläuft.
Wählen Sie ein Szenario
Wählen Sie das "Skript" Ihrer Anwendung. Momentan sind 5 verfügbar (das Tutorial ist etwas veraltet, es gibt 4):
- Stimmungsanalyse - Analyse der Tonalität, binäre Klassifikation (binäre Klassifikation), der Text bestimmt seine emotionale Farbe, positiv oder negativ.
- Issue-Klassifizierung - Multiclass-Klassifizierung, das Ziellabel für die Ausgabe (Ticket, Fehler, Supportanrufe usw.) können als eine von drei sich gegenseitig ausschließenden Optionen ausgewählt werden
- Preisvorhersage - Regression, das klassische Regressionsproblem, wenn die Ausgabe eine kontinuierliche Zahl ist; Im Beispiel handelt es sich um eine Wohnungsschätzung
- Bildklassifizierung - Klassifizierung mehrerer Klassen, jedoch bereits für Bilder
- Benutzerdefiniertes Szenario - Ihr Szenario; Ich bin gezwungen zu trauern, dass diese Option nichts Neues sein wird. Zu einem späteren Zeitpunkt werde ich eine der vier oben beschriebenen Optionen auswählen können.
Beachten Sie, dass es keine Multilabel-Klassifizierung gibt, wenn die Zielmethode gleichzeitig viele sein kann (zum Beispiel kann eine Aussage gleichzeitig anstößig, rassistisch und obszön sein, und es kann auch keine davon sein). Für Bilder gibt es keine Option zum Auswählen einer Segmentierungsaufgabe. Ich nehme an, dass sie mit Hilfe des Frameworks im Allgemeinen lösbar sind, aber heute konzentrieren wir uns auf den Builder. Es scheint, dass das Skalieren des Assistenten zum Erweitern der Anzahl der Aufgaben keine schwierige Aufgabe ist. Sie sollten sie daher in Zukunft erwarten.
Daten herunterladen und hinzufügen
Es wird vorgeschlagen, den Datensatz herunterzuladen. Aus der Notwendigkeit, auf Ihren Computer herunterzuladen, schließen wir automatisch, dass das Training auf unserem lokalen Computer stattfinden wird. Das hat beide Pluspunkte:
- Sie kontrollieren alle Daten, können sie korrigieren, lokal ändern und die Experimente wiederholen.
- Sie laden keine Daten in die Cloud hoch, wodurch die Privatsphäre gewahrt bleibt. Immerhin nicht hochladen, ja Microsoft ? :)
und Nachteile:
- Die Lerngeschwindigkeit ist durch die Ressourcen Ihres lokalen Computers begrenzt.
Es wird weiterhin vorgeschlagen, den heruntergeladenen Datensatz als Eingabe des Typs "Datei" auszuwählen. Es gibt auch die Option "SQL Server" zu verwenden - Sie müssen die erforderlichen Serverdetails angeben und dann die Tabelle auswählen. Wenn ich es richtig verstehe, ist es noch nicht möglich, ein bestimmtes Skript anzugeben. Unten schreibe ich über die Probleme, die ich mit dieser Option hatte.
Trainiere dein Modell
In diesem Schritt werden nacheinander verschiedene Modelle trainiert, für jedes wird die Geschwindigkeit angezeigt und am Ende wird das beste ausgewählt. Oh ja, ich habe vergessen zu erwähnen, dass dies AutoML ist - d. H. Der beste Algorithmus und die besten Parameter (nicht sicher, siehe unten) werden automatisch ausgewählt, sodass Sie nichts tun müssen! Es wird vorgeschlagen, die maximale Trainingszeit auf die Anzahl der Sekunden zu beschränken. Heuristiken für die Definition dieser Zeit: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train . Auf meinem Computer lernt in den Standard-10 Sekunden nur ein Modell, daher muss ich viel mehr wetten. Wir fangen an, wir warten.
Hier möchte ich wirklich hinzufügen, dass mir die Namen der Modelle persönlich etwas ungewöhnlich erschienen, zum Beispiel: AveragedPerceptronBinary, FastTreeOva, SdcaMaximumEntropyMulti. Das Wort "Perceptron" wird heutzutage nicht mehr sehr oft verwendet, "Ova" ist wahrscheinlich ein gegen alles, und "FastTree" fällt es mir schwer, was zu sagen.
Eine weitere interessante Tatsache ist, dass LightGbmMulti zu den möglichen Algorithmen gehört. Wenn ich das richtig verstehe, ist dies dasselbe LightGBM, das Steigungs-Boosting-Modul, das jetzt zusammen mit CatBoost mit der einmaligen Regel von XGBoost konkurriert. Er ist ein wenig frustriert mit seiner Geschwindigkeit in der aktuellen Leistung - nach meinen Daten dauerte sein Training die meiste Zeit (ca. 180 Sekunden). Obwohl es sich bei der Eingabe um Text handelt, ist dies nach der Vektorisierung von Tausenden von Spalten mehr als in den Eingabebeispielen nicht der beste Fall für Boosting und Bäume im Allgemeinen.
Bewerten Sie Ihr Modell
Eigentlich die Bewertung der Ergebnisse des Modells. In diesem Schritt können Sie überprüfen, welche Zielmetriken erreicht wurden, und das Modell live testen. Über die Metriken selbst kann hier gelesen werden: MS und sklearn .
Mich hat vor allem die Frage interessiert - woran wurde getestet? Eine Suche auf derselben Hilfeseite gibt eine Antwort - die Partition ist mit 80% bis 20% sehr konservativ. Ich fand nicht die Möglichkeit, dies in der Benutzeroberfläche zu konfigurieren. In der Praxis würde ich das gerne kontrollieren, denn wenn es wirklich viele Daten gibt, kann die Partition sogar 99% und 1% betragen (laut Andrew Ng habe ich selbst nicht mit solchen Daten gearbeitet). Es wäre auch nützlich, zufällige Sampling-Daten festlegen zu können, da die Wiederholbarkeit bei der Konstruktion und Auswahl des besten Modells schwer zu überschätzen ist. Es scheint, dass das Hinzufügen dieser Optionen nicht schwierig ist. Um Transparenz und Einfachheit zu gewährleisten, können Sie sie hinter einem Kontrollkästchen für zusätzliche Optionen verbergen.
Während der Erstellung des Modells werden Tablets mit Geschwindigkeitsanzeigen auf der Konsole angezeigt, deren Generierungscode ab dem nächsten Schritt in den Projekten enthalten ist. Wir können daraus schließen, dass der generierte Code wirklich funktioniert und seine ehrliche Ausgabe ausgegeben wird, keine Fälschung.
Eine interessante Beobachtung - beim Schreiben des Artikels bin ich noch einmal die Schritte des Erbauers gegangen und habe den vorgeschlagenen Datensatz mit Kommentaren von Wikipedia verwendet. Aber als Aufgabe habe ich "Benutzerdefiniert" gewählt, dann eine Mehrklassenklassifizierung als Ziel (obwohl es nur zwei Klassen gibt). Als Ergebnis stellte sich heraus, dass die Geschwindigkeit etwa 10% schlechter war (etwa 73% gegenüber 83%) als die Geschwindigkeit aus dem Screenshot mit binärer Klassifizierung. Für mich ist das etwas seltsam, denn das System hätte erraten können, dass es nur zwei Klassen gibt. Im Prinzip sollten Klassifizierer des Typs Eins gegen Alles (a la Eins gegen Alles, wenn das Mehrklassenklassifizierungsproblem auf die sequentielle Lösung von N-Binärproblemen für jede der N Klassen reduziert wird) in dieser Situation auch eine ähnliche Binärgeschwindigkeit aufweisen.
Code generieren
In diesem Schritt werden zwei Projekte generiert und der Lösung hinzugefügt. Einer von ihnen hat ein vollwertiges Beispiel für die Verwendung des Modells, und der andere sollte nur betrachtet werden, wenn Implementierungsdetails interessant sind.
Für mich selbst entdeckte ich, dass der gesamte Lernprozess prägnant in einer Pipeline aufgebaut ist (Hallo an die Piplines von sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(berührte leicht die Formatierung des Codes, um gut zu passen)
Erinnerst du dich, ich habe über die Parameter gesprochen? Ich sehe keine benutzerdefinierten Parameter, alle Standardwerte. Übrigens können wir anhand des Etiketts SentimentText_tf in der Ausgabe von FeaturizeText Schluss ziehen, dass dies eine Ausdruckshäufigkeit ist (die Dokumentation besagt, dass es sich um n-Gramm und Zeichen des Texts handelt; ich frage mich, ob es eine IDF gibt, die die Häufigkeit von Dokumenten umkehrt).
Verbrauchen Sie Ihr Modell
Eigentlich ein Anwendungsbeispiel. Ich kann nur feststellen, dass Predict elementar gemacht wird.
Nun, das ist eigentlich alles - wir haben alle Schritte des Erbauers untersucht und die wichtigsten Punkte notiert. Dieser Artikel wäre jedoch ohne einen Test der eigenen Daten unvollständig, da jeder, der jemals auf ML und AutoML gestoßen ist, sehr gut weiß, dass jede Maschine Standardaufgaben, synthetische Tests und Datensätze aus dem Internet beherrscht. Aus diesem Grund wurde beschlossen, den Builder auf seine Aufgaben hin zu überprüfen. im folgenden wird immer mit text oder text + kategorischen merkmalen gearbeitet.
Es war kein Zufall, dass ich einen Datensatz mit einigen Fehlern / Problemen / Defekten zur Hand hatte, die in einem der Projekte registriert waren. Es hat 2949 Linien, 8 unausgeglichene Zielklassen, 4 MB.
ML.NET (Laden, Konvertieren, Algorithmen aus der folgenden Liste; 219 Sekunden)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(Stachellöcher in der Platte, um in Markdown zu passen)
Meine Python-Version (Laden, Bereinigen , Konvertieren, dann LinearSVC; hat 41 Sekunden gedauert):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0,80 vs 0,747 Mikro und 0,73 vs 0,542 Makro (die Definition des Makros ist möglicherweise ungenau, wenn es interessant ist, sage ich es Ihnen in den Kommentaren).
Ich bin angenehm überrascht, nur 5% der Differenz. Bei einigen anderen Datensätzen war der Unterschied sogar noch geringer und manchmal überhaupt nicht. Bei der Analyse der Größe des Unterschieds ist zu berücksichtigen, dass die Anzahl der Stichproben in den Datensätzen gering ist. Manchmal habe ich nach dem nächsten Upload (etwas wird gelöscht, etwas wird hinzugefügt) Geschwindigkeitsbewegungen von 2-5 Prozent festgestellt.
Während ich alleine experimentierte, gab es keine Probleme mit dem Builder. Während des Vortrags trafen die Kollegen jedoch noch einige Pfosten:
- Wir haben versucht, ehrlich einen der Datensätze aus der Tabelle in die Datenbank zu laden, sind jedoch auf eine nicht informative Fehlermeldung gestoßen. Ich hatte eine ungefähre Vorstellung davon, welche Art von Plan die Textdaten enthalten, und stellte sofort fest, dass das Problem bei Zeilenvorschüben liegen könnte. Nun, ich habe das Dataset mit pandas.read_csv heruntergeladen , es von \ n \ r \ t befreit , es in tsv gespeichert und bin weitergezogen.
- Während des Trainings des nächsten Modells erhielten sie eine Ausnahmemeldung, dass eine Matrix mit einer Größe von ~ 220.000 pro 1000 nicht bequem in den Speicher passt, sodass das Training gestoppt wird. Gleichzeitig wurde auch das Modell nicht generiert. Was als nächstes zu tun ist, ist unklar. Wir haben die Situation durch Ersetzen des Lernzeitlimits „per Auge“ verlassen, sodass der fallende Algorithmus keine Zeit hat, mit der Arbeit zu beginnen.
Übrigens können wir aus dem zweiten Absatz schließen, dass die Anzahl der Wörter und n-Gramme während der Vektorisierung nicht wirklich durch die obere Grenze begrenzt ist und "n" wahrscheinlich gleich zwei ist. Ich kann aus eigener Erfahrung sagen, dass 200k eindeutig zu viel ist. Normalerweise ist sie entweder auf die häufigsten Vorkommen beschränkt oder wird auf verschiedene Arten von Dimensionsreduktionsalgorithmen angewendet, z. B. SVD oder PCA.
Schlussfolgerungen
Der Builder bietet eine Auswahl verschiedener Szenarien, in denen ich keine kritischen Stellen gefunden habe, die ein Eintauchen in ML erfordern. Unter diesem Gesichtspunkt ist es perfekt als Werkzeug zum "Einstieg" oder zum Lösen typischer einfacher Probleme hier und jetzt. Die tatsächlichen Anwendungsfälle liegen ganz im Ermessen Ihrer Vorstellungskraft. Sie können sich für die von MS angebotenen Optionen entscheiden:
- um das Problem der Stimmungsbeurteilung (Stimmungsanalyse) zu lösen, zum Beispiel in den Kommentaren zu den Produkten auf der Website
- Tickets nach Kategorien oder Teams klassifizieren (Issue-Klassifizierung)
- weiterhin Tickets verspotten, aber mit Hilfe der Preisvorhersage - Zeitkosten abschätzen
Und Sie können etwas Eigenes hinzufügen, um beispielsweise die Aufgabe der Verteilung eingehender Fehler / Incidents an Entwickler zu automatisieren und sie auf die Aufgabe der Klassifizierung nach Text (Zieletikett - ID / Nachname des Entwicklers) zu reduzieren. Oder Sie können die Bediener der internen Workstation bitten, die die Felder in der Karte mit einem festen Wertesatz (Dropdown-Liste) für andere Felder oder eine Textbeschreibung ausfüllen. Dazu müssen Sie lediglich eine Auswahl in csv vorbereiten (für Experimente sind sogar mehrere hundert Zeilen ausreichend), das Modell direkt in UI Visual Studio einlernen und es in Ihr Projekt anwenden, indem Sie den Code aus dem generierten Beispiel kopieren. Ich führe dazu, dass ML.NET meiner Meinung nach durchaus dazu geeignet ist, praktische, pragmatische, alltägliche Aufgaben zu lösen, die keine besonderen Fähigkeiten erfordern und vergebens Auffrischungszeiten erfordern. Darüber hinaus kann es in dem gewöhnlichsten Projekt angewendet werden, das nicht den Anspruch erhebt, innovativ zu sein. Jeder .NET-Entwickler, der bereit ist, eine neue Bibliothek zu erstellen, kann der Autor eines solchen Modells werden.
Ich habe ein bisschen mehr ML-Hintergrund als der durchschnittliche .NET-Entwickler, also habe ich mich für mich entschieden: für Bilder, wahrscheinlich nicht für komplexe Fälle, aber für einfache Tabellenaufgaben, auf jeden Fall ja. Momentan ist es für mich bequemer, eine ML-Aufgabe auf dem vertrauten Python / Numpy / Pandas / Sk-Learn / Keras / Pytorch-Technologie-Stack auszuführen. Allerdings hätte ich einen typischen Fall für das spätere Einbetten in eine .NET-Anwendung mit ML.NET ausgeführt .
Übrigens ist es schön, dass das Text-Framework ohne unnötige Gesten und ohne die Notwendigkeit der Abstimmung durch den Benutzer perfekt funktioniert. Im Allgemeinen ist dies nicht verwunderlich, da in der Praxis die guten alten TfIDFs mit Klassifikatoren wie SVC / NaiveBayes / LR bei kleinen Datenmengen recht gut funktionieren. Dies wurde auf dem Sommer-DataFest in einem Bericht von iPavlov besprochen - auf einer Testsuite wurden word2vec, GloVe, ELMo (Art von) und BERT mit TfIdf verglichen. Bei dem Test konnte in nur einem Fall von 7-10 Fällen eine Überlegenheit von einigen Prozent erreicht werden, obwohl der Umfang der für die Ausbildung aufgewendeten Ressourcen überhaupt nicht vergleichbar ist.
PS: Die Popularisierung von ML unter den Massen ist jetzt im Trend, sogar mit dem " Google-Tool zum Erstellen von KI, das selbst ein Schüler verwenden kann ". Es ist alles lustig und intuitiv für den Benutzer, aber was wirklich hinter den Kulissen in der Cloud vor sich geht, ist unklar. Für .NET-Entwickler ist ML.NET mit einem Model Builder eine attraktivere Option.
Die PSS-Präsentation ging mit einem Knall los, die Kollegen waren motiviert, es zu versuchen :)
Rückmeldung
In einem Newsletter mit der Überschrift "ML.NET Model Builder" stand übrigens:
Geben Sie uns Ihr Feedback
Wenn Sie auf Probleme stoßen, das Gefühl haben, dass etwas fehlt oder Sie etwas an ML.NET Model Builder wirklich lieben, lassen Sie es uns wissen, indem Sie ein Problem in unserem GitHub-Repo erstellen.
Model Builder ist noch in der Vorschau und Ihr Feedback ist sehr wichtig, um die Richtung zu bestimmen, die wir mit diesem Tool einschlagen!
Dieser Artikel kann als Feedback angesehen werden!
Referenzen
Auf ML.NET
Zu einem älteren Artikel mit Anleitung