Wir wollen immer schnell Code schreiben, aber Sie müssen dafür bezahlen. In gewöhnlichen flexiblen Hochsprachen können Programme schnell entwickelt werden, sie werden jedoch nach dem Start langsam ausgeführt. Zum Beispiel ist es ungeheuer langsam, etwas Schweres in reinem Python zu lesen. C-ähnliche Sprachen arbeiten viel schneller, aber es ist einfacher, Fehler in ihnen zu machen, deren Suche den Geschwindigkeitsgewinn auf Null reduziert.
In der Regel wird dieses Dilemma folgendermaßen gelöst: Zuerst schreiben sie den Prototyp auf etwas Flexibles, zum Beispiel auf Python oder R, und dann schreiben sie ihn auf C / C ++ oder Fortran um. Aber dieser Zyklus ist zu lang, können Sie darauf verzichten?

Vielleicht gibt es eine Lösung. Julia ist eine hochqualifizierte und flexible Programmiersprache mit hoher Geschwindigkeit. Julia verfügt über mehrere Versandfunktionen, einen integrierten intelligenten Compiler und Metaprogrammier-Tools.
Gleb Ivashkevich (
phtRaveller ), der Gründer der Datarythmik, der als ehemaliger Physiker maschinelle Lernsysteme für die Industrie und andere Industrien entwickelt, wird Ihnen mehr über Julia erzählen.
Gleb wird erklären, warum neue Sprachen benötigt werden und warum manchmal Python fehlt. Er erklärt Ihnen, was an Julia interessant ist, welche Stärken und Schwächen sie hat, vergleicht sie mit anderen Sprachen und zeigt, welche Aussichten die Sprache auf maschinelles Lernen und Computing im Allgemeinen hat.
Haftungsausschluss. Es wird keine Syntaxanalyse durchgeführt. Habrazhiteli hat Erfahrung mit Entwicklern, daher macht es keinen Sinn zu zeigen, wie man zum Beispiel eine Schleife schreibt.Das Problem zweier Sprachen
Wenn Sie Code schnell schreiben, werden Programme langsam ausgeführt. Wenn Programme schnell arbeiten, schreiben Sie sie für eine lange Zeit.
Klassisches Python fällt in die erste Kategorie. Wenn Sie NumPy entfernen, sollten Sie etwas in reinem Python langsam in Betracht ziehen. Auf der anderen Seite gibt es Sprachen wie C und C ++. Es ist schwierig, ein Gleichgewicht zu finden. Daher schreiben sie in den meisten Fällen zuerst einen Prototyp für etwas Flexibles und schreiben ihn nach dem Debuggen des Algorithmus schneller in die Sprache um. Dies ist ein Beispiel für ein
klares Problem in zwei Sprachen : Ein langer Zyklus, in dem Sie in Python schreiben und es beispielsweise in C oder in Cython neu schreiben müssen.
Spezialisten für maschinelles Lernen und Data Science sind NumPy, Sklearn und TensorFlow. Sie lösen ihre Probleme seit Jahren ohne eine einzige Zeile in C, und es scheint, dass das Problem der beiden Sprachen sie nicht betrifft. Dies ist nicht so, das Problem manifestiert sich
implizit , da der Code in NumPy oder TensorFlow eigentlich nicht wirklich Python ist. Es wird als Metasprache verwendet, um das zu starten, was sich im Inneren befindet. Darin befindet sich genau C / Fortran (im Fall von NumPy) oder C ++ (im Fall von TensorFlow).
Dieses „Merkmal“ ist beispielsweise in PyTorch schlecht sichtbar, in Numpy jedoch deutlich. Wenn beispielsweise ein klassischer Python-Zyklus
for in den Berechnungen enthalten ist, ist ein Fehler aufgetreten. In produktivem Code werden keine Schleifen benötigt, Sie müssen alles neu schreiben, damit NumPy es vektorisieren und schnell berechnen kann.
Gleichzeitig scheint es vielen, dass NumPy schnell ist und damit alles in Ordnung ist. Mal sehen, was NumPy unter der Haube hat, um das zu sehen.
- NumPy versucht, das Problem mit der Python-Typflexibilität zu beheben, sodass es ein ziemlich striktes Typsystem gibt . Wenn das Array einen bestimmten Typ hat, kann sich nichts anderes darin befinden, und wenn
Float64 ist, kann nichts dagegen unternommen werden. - Entsendung. Abhängig von den Arten der Arrays und der auszuführenden Operation entscheidet NumPy in sich selbst, welche Funktion aufgerufen wird, um die Berechnungen so schnell wie möglich durchzuführen. Die Bibliothek versucht, klassisches Python aus der Rechenschleife zu werfen.
Es stellt sich heraus, dass Numpy nicht so schnell ist, wie es scheint. Deshalb gibt es Projekte wie
Cython oder
Numba . Der erste generiert C-Code aus dem "Hybrid" von Python und C, und der zweite kompiliert den Code in Python und dies ist normalerweise schneller.
Wenn NumPy wirklich so schnell wäre, wie es vielen scheint, dann würde die Existenz von Cython und Numba keinen Sinn ergeben.
Wir schreiben alles in Cython neu, wenn wir schnell etwas Großes und Komplexes finden wollen. Eines der Kriterien für die Qualität eines Wrappers in Cython ist das Vorhandensein oder Fehlen von reinen Python-Aufrufen im generierten Code.
Ein einfaches Beispiel: Wir addieren den Typ (gut) oder nicht (schlecht) und erhalten zwei völlig unterschiedliche Codes, obwohl die anfänglichen Optionen nicht anders sind als die Typen.

Wenn wir den C-Code generieren, erhalten wir im ersten Fall Folgendes:
__pyx_t_4 = __pyx_v_i; __pyx_v_result = (__pyx_v_result + (*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) ))));
Und im zweiten
result =0. wird sich in diese verwandeln:
__pyx_t_6 = PyFloat_FromDouble((*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) )))); if (unlikely(!__pyx_t_6)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_6); __pyx_t_7 = PyNumber_InPlaceAdd(__pyx_v_result, __pyx_t_6); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_7); __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0; __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_7); __pyx_t_7 = 0;
Wenn ein Typ angegeben wird, läuft der C-Code blitzschnell. Wenn der Typ nicht angegeben ist, sehen wir normales Python, aber von der C-Seite: Standard-Python-Aufrufe, bei denen aus irgendeinem Grund
float aus
double , Links gezählt werden und eine Menge anderer Garbage-Codes. Dieser Code ist langsam, weil er bei jeder Operation Python aufruft.
Ist es möglich, alle Probleme auf einmal zu lösen
Es ist lustig, dass wir, wenn wir an etwas denken, versuchen, reines Python zu entfernen. Hierfür gibt es zwei Möglichkeiten.
- Verwenden von Cython oder anderen Tools. Es gibt viele Möglichkeiten, wie Sie Ihren Cython-Code optimieren können, um so gut wie keine Python-Aufrufe zu erhalten. Dies ist jedoch nicht die angenehmste Aktivität: In Cython ist nicht alles so offensichtlich, und es wird nur ein bisschen weniger Zeit aufgewendet, als wenn Sie nur alles in C schreiben. Das resultierende Modul kann in Python verwendet werden, es dauert jedoch lange, Fehler treten auf, der Code ist nicht immer offensichtlich und Es ist nicht immer klar, wie man es optimiert.
- Mit Numba wird eine JIT-Kompilierung durchgeführt .
Aber vielleicht gibt es einen besseren Weg, und ich denke, das ist
Julia .
Julia
Die Autoren behaupten, dass dies eine
schnelle ,
hochentwickelte und
flexible Sprache ist, die in Bezug auf die einfache Code-Erstellung mit Python vergleichbar ist. Meiner Meinung nach ist Julia wie eine
Skriptsprache: Sie müssen nicht das tun, was Sie in C tun müssen, wo alles sehr niedrig ist, einschließlich Datenstrukturen. Gleichzeitig können Sie in einer normalen Konsole arbeiten, z. B. mit Python und anderen Sprachen.
Julia verwendet die
Just-In-Time-Kompilierung - dies ist eines der Elemente, die Geschwindigkeit verleihen. Aber die Sprache kann gut rechnen, weil sie für sie entwickelt wurde. Julia wird für wissenschaftliche Aufgaben eingesetzt und bekommt ordentliche Leistung.
Obwohl Julia versucht, wie eine Allzwecksprache auszusehen, ist Julia gut für Computer und nicht sehr gut für Webdienste. Zum Beispiel ist es nicht die beste Wahl, Julia anstelle von Django zu verwenden.
Betrachten wir die Merkmale der Sprache als Beispiel einer primitiven Funktion.
function f(x) α = 1 + 2x end julia> methods(f)
In diesem Code sind vier Funktionen erkennbar.
- Es gibt praktisch keine Einschränkungen für die Verwendung von Unicode . Sie können Formeln aus einem Artikel über vertieftes Lernen oder numerisches Modellieren entnehmen, mit denselben Zeichen neu schreiben und alles wird funktionieren - Unicode wird fast überall genäht.
- Es gibt kein Multiplikationszeichen. Es ist jedoch nicht immer möglich, darauf zu verzichten, zum Beispiel, indem 2.x (eine Gleitkommazahl mal x) Julia schwört.
- Keine
return . Im Allgemeinen wird empfohlen, dass Sie return schreiben return damit Sie sehen können, was gerade passiert. Das Beispiel gibt jedoch α , da die Zuweisung ein Ausdruck ist. - Keine Typen . Es scheint, dass, wenn es Geschwindigkeit gibt, irgendwann die Typen erscheinen sollten? Ja, sie werden erscheinen, aber später.
Julia verfügt über drei Funktionen, die Flexibilität und Geschwindigkeit
bieten :
Mehrfachversand, Metaprogrammierung und Parallelität . Wir werden über die ersten beiden sprechen und die Parallelisierung dem unabhängigen Studium für fortgeschrittene Benutzer überlassen.
Mehrfachterminierung
Der Aufruf von
methods(f) im obigen Beispiel sieht unerwartet aus - über welche Methoden verfügt die Funktion? Wir sind daran gewöhnt, dass wir Klassenobjekte haben, Klassen Methoden. Aber in Julia ist alles auf den Kopf gestellt: Funktionen haben Methoden, weil die Sprache mehrere Dispatchings verwendet.
Mehrfachterminierung bedeutet, dass die auszuführende Variante einer bestimmten Funktion durch den gesamten Satz von Parametertypen dieser Funktion bestimmt wird.
Ich werde kurz beschreiben, wie dies an einem bereits bekannten Beispiel funktioniert.
function f(x) α = 1 + 2x end function f(x::AbstractFloat) α = 1 + sin(x) end julia> methods(f)
Varianten der gleichen Funktion für verschiedene Typen werden als Methoden bezeichnet. Der Code enthält zwei Elemente: das erste für alle Gleitkommazahlen und das zweite für alles andere. Wenn wir die Funktion zum ersten Mal aufrufen, wird Julia entscheiden, welche Methode verwendet und ob sie kompiliert werden soll. Wenn es bereits aufgerufen und kompiliert wurde, übernimmt es das, was ist.
Da in Julia nicht alles so ist, wie wir es gewohnt sind, können Sie hier benutzerdefinierte Typen mit Funktionen versehen. Dies sind jedoch keine Typmethoden im Sinne von OOP. Es wird einfach das Feld sein, in das die Funktion geschrieben wird, da die
Funktion dasselbe vollwertige Objekt ist wie alles andere.
Um herauszufinden, was genau ausgelöst wird, gibt es spezielle Makros. Sie beginnen mit
@ . In diesem Beispiel können
@which mit dem
@which Makro herausfinden, welche Methode für einen bestimmten Fall aufgerufen wurde.

Im ersten Fall entschied Julia, dass 2 eine Ganzzahl ist, die nicht zu
AbstractFloat passt, und rief die erste Option auf. Im zweiten Fall entschied sie, dass es sich um
Float und forderte bereits eine spezialisierte Version. Dies funktioniert ungefähr, wenn Sie für bestimmte Typen andere Methoden hinzufügen.
LLVM und JIT
Julia verwendet das LLVM-Framework zum Kompilieren. Die JIT-Kompilierungsbibliothek wird in einem Sprachpaket geliefert. Beim ersten Aufruf der Funktion prüft Julia, ob die Funktion mit diesem Satz von Typen verwendet wurde, und kompiliert ihn gegebenenfalls. Der erste Start wird einige Zeit in Anspruch nehmen, und dann wird alles schnell funktionieren.
Die Funktion wird zum Zeitpunkt des ersten Aufrufs dieses Parametersatzes übersetzt.
Compiler-Funktionen
- Der Compiler ist vernünftig, da LLVM ein gutes Produkt ist.
- Fortgeschrittene Entwickler können sich den Kompilierungsprozess ansehen und sehen, was er generiert.
- Die Zusammenstellung von Julia und Numba ist ähnlich . In Numba erstellen Sie auch einen JIT-Dekorator, aber in Numba können Sie nicht so oft „einsteigen“ und entscheiden, was optimiert oder geändert werden soll.
Um die Arbeit des Compilers zu veranschaulichen, werde ich ein Beispiel für eine einfache Funktion geben:
function f(x) α = 1 + 3x end julia> @code_llvm f(2) define i64 @julia_f_35897(i64) { top: %1 = mul i64 %0, 3 %2 = add i64 %1, 1 ret i64 %2 }
Mit dem Makro
@code_llvm können Sie das Ergebnis der Generierung
@code_llvm . Diese
LLVM-IR ist
eine Zwischendarstellung , eine Art Assembler.
Im Code wird das Funktionsargument mit 3 multipliziert, zum Ergebnis wird 1 addiert, das Ergebnis wird zurückgegeben. Alles ist so einfach wie möglich. Wenn Sie die Funktion etwas anders definieren, z. B. 3 durch 2 ersetzen, ändert sich alles.
function f(x) α = 1 + 2x end julia> @code_llvm f(2) define i64 @julia_f_35894(i64) { top: %1 = shl i64 %0, 1 %2 = or i64 %1, 1 ret i64 %2 }
Es scheint, was ist der Unterschied: 2, 3, 10? Aber Julia und LLVM sehen, dass Sie etwas schlauer vorgehen können, wenn Sie eine Funktion für eine Ganzzahl aufrufen. Das Multiplizieren mit zwei Ganzzahlen ist eine Linksverschiebung um ein Bit - es ist schneller als das Produkt. Dies funktioniert natürlich nur für Ganzzahlen. Es funktioniert jedoch nicht,
Float um 1 Bit
Float links zu verschieben und das Ergebnis der Multiplikation mit 2 zu erhalten.
Benutzerdefinierte Typen
Benutzerdefinierte Typen in Julia sind genauso schnell wie integrierte Typen. Bei ihnen wird eine Mehrfachplanung durchgeführt, die genauso schnell ist wie bei integrierten Typen. In diesem Sinne ist der Mehrfachversand-Mechanismus tief in die Sprache eingebettet.
Es ist logisch zu erwarten, dass Variablen keine Typen haben, sondern nur Werte. Variablen ohne Typ sind nur eine Markierung, eine Bezeichnung auf einem Container.
Das Typensystem ist hierarchisch. Wir können keine Nachkommen konkreter Typen erstellen, abstrakte Typen können sie nur haben. Abstrakte Typen können jedoch nicht instanziiert werden. Diese Nuance wird nicht jeden ansprechen.
Wie die Autoren der Sprache erklärten, als sie Julia entwickelten, wollten sie das Ergebnis erhalten, und wenn es schwierig war, etwas zu tun, lehnten sie es ab. Ein solches hierarchisches Typensystem war einfacher zu entwickeln. Dies ist kein katastrophales Problem, aber wenn Sie den Kopf zuerst nicht umdrehen, ist dies unpraktisch.
Typen können parametrisiert werden , ähnlich wie in C / C ++. Zum Beispiel können wir eine Struktur haben, in der es Felder gibt, aber die Typen dieser Felder sind nicht spezifiziert - dies sind Parameter. Bei der Instanziierung geben wir einen bestimmten Typ an.
In den meisten Fällen können Typen übersprungen werden . Normalerweise werden sie benötigt, wenn der Typ dem Compiler hilft, zu erraten, wie er am besten kompiliert. In diesem Fall ist es besser, die Typen anzugeben. Sie müssen auch Typen angeben, wenn Sie eine bessere Leistung erzielen möchten.
Mal sehen, was möglich ist und was nicht instanziiert werden kann.

Der erste Typ von
AbstractPoint kann nicht instanziiert werden. Dies ist nur ein gemeinsames übergeordnetes Element für alle Benutzer, die wir beispielsweise in Methoden angeben können. Die zweite Zeile besagt, dass
PlanarPoint{T} ein Nachkomme dieses abstrakten Punktes ist. Unterhalb der Felder beginnen - hier sehen Sie die Parametrierung. Sie können hier ein
float ,
int oder einen anderen Typ eingeben.
Der erste Typ kann nicht instanziiert werden, und für den Rest ist es unmöglich, Nachkommen zu erstellen. Außerdem sind sie standardmäßig
unveränderlich . Um die Felder ändern zu können, muss dies explizit angegeben werden.
Wenn alles fertig ist, können Sie beispielsweise die Entfernung für verschiedene Arten von Punkten berechnen. Im Beispiel ist der erste Punkt auf der Ebene
PlanarPoint , dann auf der Kugel und auf dem Zylinder. Je nachdem, zwischen welchen zwei Punkten wir den Abstand berechnen, müssen wir verschiedene Methoden anwenden. Im Allgemeinen sieht die Funktion folgendermaßen aus:
function describe(p::AbstractPoint) println("Point instance: $p") end
Für
Float64 ,
Float32 ,
Float16 es sein:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:AbstractFloat sqrt((pf.x-ps.x)^2 + (pf.y-ps.y)^2) end
Und für ganze Zahlen sieht die Entfernungsberechnungsmethode folgendermaßen aus:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:Integer abs(pf.x-ps.x) + abs(pf.y-ps.y) end
Für Punkte jedes Typs werden unterschiedliche Methoden aufgerufen.
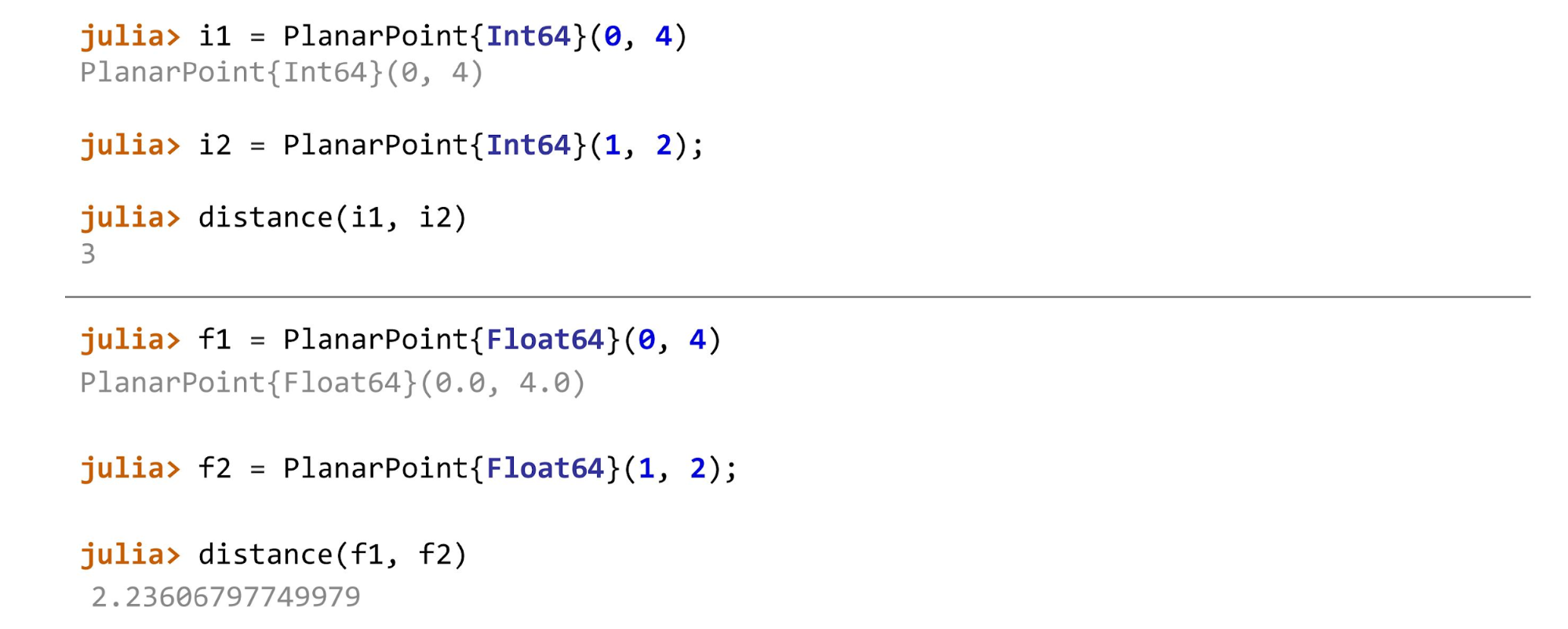
Wenn Sie schummeln und zum Beispiel
distance(f1, i2) anwenden, schwört Julia: „Ich kenne diese Methode nicht! Sie haben mich nach solchen Methoden gefragt und gesagt, dass beide vom selben Typ sind. Du hast mir nicht gesagt, wie ich das zählen soll, wenn ein Parameter
float und der andere
int . "
Geschwindigkeit
Sie haben sich vielleicht schon gefreut: „Es gibt eine JIT-Zusammenstellung: Das Schreiben ist einfach, es wird schnell gehen. Wirf Python raus und fang an, in Julia zu schreiben! “
Aber nicht so einfach. Nicht jedes Feature in Julia wird schnell sein. Das hängt von zwei Faktoren ab.
- Vom Entwickler . Es gibt keine Sprachen, in denen eine Funktion schnell ist. Ein unerfahrener Entwickler schreibt sogar Code in C, der viel langsamer arbeitet als der Python-Code eines erfahrenen Entwicklers. Jede Sprache hat ihre eigenen Tricks und Nuancen, von denen die Leistung abhängt. Der Compiler, egal ob es sich um einen regulären statischen oder einen JIT-Compiler handelt, kann nicht alle denkbaren Optionen bereitstellen und alles überhaupt optimieren.
- Aus Typenstabilität . In einer schnelleren Version werden typstabile Funktionen kompiliert.
Typstabilität
Was ist Typstabilität? Wenn der Compiler nicht verlässlich genug erraten kann, was mit den Typen passiert, muss er eine Menge Wrapper-Code generieren, damit alles funktioniert, was an die Eingabe gelangt.
Ein einfaches Beispiel, um die Typstabilität zu verstehen.

Experten für maschinelles Lernen werden sagen, dass dies eine normale relu-Aktivierung ist: Wenn x> 0, geben Sie es so zurück, wie es ist, andernfalls geben Sie Null zurück. Ein Problem ist die Null nach der Ganzzahl des Fragezeichens. Dies bedeutet, dass, wenn wir diese Funktion für eine Gleitkommazahl aufrufen, in einem Fall eine Gleitkommazahl und in dem anderen eine Ganzzahl zurückgegeben wird.
Der Compiler kann den Ergebnistyp nicht nur anhand des Funktionsargumenttyps erraten. Er muss auch die Bedeutung kennen. Daher wird viel Code generiert.
Als nächstes erstellen wir ein Array von 100 pro 100 Zufallszahlen von 0 bis 1, verschieben es um 0,5, um positive und negative Zahlen gleichmäßig zu verteilen, und messen das Ergebnis. Es gibt zwei interessante Punkte: den Punkt und die Funktion. Der Punkt nach
rand(100,100) bedeutet "auf jedes Element anwenden". Wenn Sie eine Art Sammlung und Skalarfunktion haben, setzen Sie dieser ein Ende, und Julia wird den Rest erledigen. Wir können davon ausgehen, dass dies genauso effektiv ist wie eine normale Schleife in einer normalen kompilierten Sprache. Sie brauchen nicht zu schreiben - alles wird für Sie erledigt.
Derzeit gibt es keine Probleme - das
Problem liegt in der Funktion selbst . Die geschätzte Ausführungszeit einer solchen Option auf einem anständigen Computer für eine solche Matrix beträgt Mikrosekunden. Aber in Wirklichkeit - Millisekunden, das ist zu viel für solch eine winzige Matrix.
Ändern Sie nur eine Zeile.

Die ausgeführte Funktion
zero(x) generiert eine Null des gleichen Typs wie das Argument
(x) . Dies bedeutet, dass unabhängig vom Wert von
x die Art des Ergebnisses immer der Art von
x selbst bekannt ist.
Wenn wir uns nur die Art der Argumente ansehen und die Art des Ergebnisses bereits kennen, sind dies Funktionen, die typstabil sind.
Wenn wir uns die Bedeutung der Argumente ansehen müssen, sind dies keine stabilen Funktionen.
Wenn der Compiler den Code optimieren kann, wird der Unterschied in der Ausführungszeit um zwei Größenordnungen erhalten. Im zweiten Beispiel wurde es nur genau einem neuen Array zugewiesen, ein paar Dutzend Bytes mehr und nichts mehr. Diese Option ist viel effektiver als die vorherige.
Dies ist die Hauptsache, auf die Sie achten müssen, wenn Sie Code in Julia schreiben. Wenn Sie wie in Python schreiben, funktioniert dies wie in Python. Wenn Sie die gleichen Operationen mit NumPy ausführen, spielt die Null mit oder ohne Punkt keine Rolle. Bei Julia kann dies die Leistung erheblich beeinträchtigen.
Glücklicherweise gibt es eine Methode, um herauszufinden, ob ein Problem vorliegt. Dies ist das Makro
@code_warntype , mit dem Sie herausfinden können, ob der Compiler erraten kann, wo sich welche Typen befinden, und optimieren, ob alles in Ordnung ist.

In der ersten Option (links) ist sich der Compiler des Typs nicht sicher und zeigt ihn in rot an. Im zweiten Fall gibt es für ein solches Argument immer
Float64 , sodass Sie Code viel kürzer generieren können.
Dies ist noch keine LLVM, aber der beschriftete Julia-Code,
return 0 oder
return 0.0 ergibt einen Leistungsunterschied von zwei Größenordnungen.
Metaprogrammierung
Metaprogrammierung ist, wenn wir Programme in einem Programm erstellen und sie unterwegs ausführen.
Dies ist eine leistungsstarke Methode, mit der Sie viele verschiedene interessante Dinge tun können. Ein klassisches Beispiel ist Django ORM, bei dem Felder mithilfe von Metaklassen erstellt werden.
Vielen ist der Haftungsausschluss von
Tim Peters , Autor von Zen of Python, bekannt:
„Metaklassen sind eine tiefgreifende Magie, über die sich 99% der Benutzer niemals Gedanken machen sollten. Wenn Sie sich fragen, ob Metaklassen in Python benötigt werden, brauchen Sie sie nicht. Wenn Sie sie brauchen, wissen Sie genau, warum und wie Sie sie verwenden müssen. “
Bei der Metaprogrammierung ist die Situation ähnlich, aber bei Julia ist sie viel tiefer genäht, dies ist ein wichtiges Merkmal der gesamten Sprache. Julia-Code hat dieselbe Datenstruktur wie jeder andere. Sie können Ausdrücke bearbeiten, kombinieren und erstellen, und all dies funktioniert.
julia> x = 4; julia> typeof(:(x+1)) Expr julia> expr = :(x+1) :(x + 1) julia> expr.head :call julia> expr.args 3-element Array{Any,1}: :+ :x 1
Makros sind eines der Metaprogrammierwerkzeuge in Julia : Wir geben ihnen etwas, sie schauen, fügen das Richtige hinzu, entfernen das Unnötige und geben das Ergebnis. In allen vorherigen Beispielen haben wir den Aufruf an die Funktion übergeben, und das Makro im Inneren hat den Aufruf analysiert. All dies geschieht auf der Ebene der Arbeit mit dem Syntaxbaum.
Sie können sehr einfache Ausdrücke analysieren: Wenn es sich beispielsweise um
(x+1) , ist dies ein Aufruf der Funktion
+ (der Zusatz ist kein Operator, wie in vielen anderen Sprachen, sondern eine Funktion) und zwei Argumente: Ein Zeichen (ein Doppelpunkt bedeutet, dass es sich um ein Zeichen handelt) ), und die zweite ist nur eine Konstante.
Ein weiteres einfaches Makrobeispiel:
macro named(name, expr) println("Starting $name") return quote $(esc(expr)) end end julia> @named "some process" x=5; Starting some process julia> x 5
Beispielsweise werden mithilfe von Makros Fortschrittsanzeigen oder Filter für Datenrahmen erstellt - dies ist ein in Julia üblicher Mechanismus.
Makros werden nicht zum Zeitpunkt des Aufrufs ausgeführt, sondern beim Parsen des Codes.
Dies ist die Hauptmakrofunktion in Julia. - , . , , .
,
Julia — . .
- Julia . .
- , . , , C .
- Julia JIT- . , , , , .
- — . .
- ( ). , . , , .
- Julia — .
Ökosystem
, , Julia . , , data science , , , Python. , Python Pandas, , , , Julia .
Julia , Python 2008 . Python, , Julia. , . , Julia.
( ) Python Julia
. Julia: , , .…
. .
- DataFrames.jl .
- JuliaDB , .
- Query.jl . Pandas — - , ..
Plotting .
Matplotlib , Julia. :
VegaLite.jl ,
Plots.jl , ,
Gadfly.jl .
.
TensorFlow , Flux.jl. Flux , , , Keras TensorFlow, . .
Scikit-learn . , , sklearn, , .
XGBoost . , Julia .
?
Jupyter . IDE — Juno, Visual Studio, .
. GPU/TPU . CUDAnative.jl Julia . Julia-, - , . , , , , .
: C, Fortran, Python .
, .
Packaging : Julia: , , ..
, , . , , . ,
PyTorch , TensorFlow, , .
, , , . Julia, , , . ,
,
Zygote.jl . Flux.jl.
julia> using Zygote julia> φ(x) = x*sin(x) julia> Zygote.gradient(φ, π/2.) (1.0,) julia> model = Chain(Dense(768, 128, relu), Dense(128, 10), softmax) julia> loss(x, y) = crossentropy(model(x), y) + sum(norm, params(model)) julia> optimizer = ADAM(0.001) julia> Flux.train!(loss, params(model), data, optimizer) julia> model = Chain(x -> sqrt(x), x->x-1)
φ , , , .
Zygote «source-to-source»: , , .
differentiable programming — — backpropagation , .
Julia : «source-to-source» , . , .
Julia ?
, — . .
- , , , — .
, , .
Julia , .
- , , . Julia «» .
- , API, , .
Moscow Python Conf++ , 27 , Python Julia. , , telegram- MoscowPython.