Wir haben ein Netzwerk von Rechenzentren entwickelt, mit dem Sie Computercluster mit mehr als 100.000 Servern und einer Teilungsbandbreite von mehr als einem Petabit pro Sekunde bereitstellen können.
Aus dem Bericht von Dmitry Afanasyev erfahren Sie mehr über die Grundprinzipien des neuen Designs, die Skalierungstopologien, die mit diesen Problemen einhergehen, Lösungen für diese Probleme sowie die Merkmale des Routings und der Skalierung der Weiterleitungsebenenfunktionen moderner Netzwerkgeräte in dicht verbundenen Topologien mit einer großen Anzahl von ECMP-Routen . Darüber hinaus sprach Dima kurz über die Organisation der externen Konnektivität, die physische Ebene, das Kabelsystem und Möglichkeiten zur weiteren Steigerung der Kapazität.

- Guten Tag allerseits! Mein Name ist Dmitry Afanasyev, ich bin ein Netzwerkarchitekt von Yandex und beschäftige mich hauptsächlich mit dem Design von Rechenzentrumsnetzwerken.

Meine Geschichte dreht sich um das aktualisierte Rechenzentrumsnetzwerk von Yandex. Dies ist größtenteils eine Weiterentwicklung unseres Designs, aber gleichzeitig gibt es einige neue Elemente. Dies ist eine Review-Präsentation, da in kurzer Zeit viele Informationen angepasst werden mussten. Wir beginnen mit der Wahl einer logischen Topologie. Dann wird es einen Überblick über die Steuerebene und die Probleme mit der Skalierbarkeit der Datenebene geben. Schauen wir uns einige Funktionen der Geräte an. Wir werden auch auf die Entwicklungen im Rechenzentrum mit MPLS eingehen, über die wir vor einiger Zeit gesprochen haben.

Was ist Yandex in Bezug auf Workloads und Services? Yandex ist ein typischer Hyperscaler. Wenn Sie in Richtung Benutzer schauen, bearbeiten wir in erster Linie Benutzeranfragen. Auch verschiedene Streaming-Dienste und Datenausgabe, weil wir auch Speicherdienste haben. Wenn es näher am Backend liegt, werden dort Infrastrukturlasten und -dienste angezeigt, z. B. verteilte Objektspeicher, Datenreplikation und natürlich persistente Warteschlangen. Eine der Hauptarten von Lasten ist MapReduce und dergleichen, Streaming-Verarbeitung, maschinelles Lernen usw.

Wie ist die Infrastruktur, auf der dies alles geschieht? Auch hier sind wir ein sehr typischer Hyperskaler, obwohl wir uns vielleicht etwas näher an der Seite des Spektrums befinden, an der sich die kleineren Hyperskaler befinden. Aber wir haben alle Attribute. Wo immer möglich, verwenden wir Standardhardware und horizontale Skalierung. Das Ressourcen-Pooling wächst stetig: Wir arbeiten nicht mit separaten Maschinen und Racks, sondern kombinieren sie zu einem großen Pool austauschbarer Ressourcen mit einigen zusätzlichen Services, die für die Planung und Zuordnung zuständig sind. Wir arbeiten mit all diesen Pools.
Wir haben also die nächste Ebene - das Computing-Cluster auf Betriebssystemebene. Es ist sehr wichtig, dass wir den von uns verwendeten Technologie-Stack vollständig kontrollieren. Wir kontrollieren Endpunkte (Hosts), Netzwerk und Software-Stack.
Wir haben mehrere große Rechenzentren in Russland und im Ausland. Sie werden mithilfe der MPLS-Technologie durch ein Backbone verbunden. Unsere interne Infrastruktur basiert fast ausschließlich auf IPv6. Da wir jedoch externen Datenverkehr verarbeiten müssen, der noch immer hauptsächlich über IPv4 bereitgestellt wird, müssen wir die über IPv4 eingehenden Anforderungen irgendwie an die Front-End-Server weiterleiten und noch ein wenig an externe IPv4-Server weiterleiten. Internet - zum Beispiel zur Indizierung.
In den letzten Iterationen des Netzwerkdesigns für Rechenzentren werden mehrstufige Clos-Topologien verwendet, in denen nur L3 verwendet wird. Wir haben L2 vor einiger Zeit verlassen und atmeten erleichtert auf. Schließlich umfasst unsere Infrastruktur Hunderttausende von Computerinstanzen (Serverinstanzen). Die maximale Clustergröße betrug vor einiger Zeit etwa 10.000 Server. Dies ist vor allem darauf zurückzuführen, wie dieselben Betriebssysteme auf Cluster-Ebene - Scheduler, Ressourcenzuweisung usw. - funktionieren können. Da auf der Seite der Infrastruktursoftware Fortschritte erzielt wurden, sind jetzt etwa 100.000 Server in einem Computercluster vorgesehen Wir hatten die Aufgabe, Netzwerkfabriken aufzubauen, die eine effiziente Bündelung von Ressourcen in einem solchen Cluster ermöglichen.

Was wollen wir von einem Rechenzentrumsnetzwerk? Erstens - viel billige und ziemlich gleichmäßig verteilte Bandbreite. Weil das Netzwerk das Substrat ist, über das wir Ressourcen bündeln können. Die neue Zielgröße beträgt ungefähr 100.000 Server in einem Cluster.
Natürlich wollen wir auch eine skalierbare und stabile Steuerebene, da bei einer so großen Infrastruktur selbst bei zufälligen Ereignissen viele Kopfschmerzen auftreten und die Steuerebene uns keine Kopfschmerzen bereiten soll. Gleichzeitig wollen wir den darin enthaltenen Zustand minimieren. Je kleiner der Zustand, desto besser und stabiler funktioniert alles, desto einfacher ist die Diagnose.
Natürlich brauchen wir Automatisierung, weil es unmöglich ist, eine solche Infrastruktur manuell zu verwalten, und das war vor einiger Zeit unmöglich. Wann immer möglich, benötigen wir soweit möglich operative Unterstützung und CI / CD-Unterstützung.
Bei solchen Größen von Rechenzentren und Clustern ist die Aufgabe, die schrittweise Bereitstellung und Erweiterung ohne Unterbrechung des Dienstes zu unterstützen, sehr akut geworden. Wenn in Clustern die Größe von tausend Autos wahrscheinlich nahe bei zehntausend Maschinen liegt, können sie immer noch als ein Vorgang ausgerollt werden - das heißt, wir planen, die Infrastruktur zu erweitern, und mehrere tausend Maschinen werden als ein Vorgang hinzugefügt, dann entsteht kein Cluster mit der Größe von hunderttausend Autos einfach so, es ist seit einiger zeit gebaut worden. Und es ist wünschenswert, dass die gesamte Zeit, die bereits abgepumpt wurde, die bereitgestellte Infrastruktur zur Verfügung steht.
Und eine Anforderung, die wir hatten und hinter uns gelassen haben: Dies ist die Unterstützung für Mandantenfähigkeit, dh Virtualisierung oder Netzwerksegmentierung. Jetzt müssen wir dies nicht mehr auf der Netzwerkfactory-Ebene tun, da die Segmentierung an die Hosts ging und dies die Skalierung für uns sehr einfach machte. Dank IPv6 und eines großen Adressraums mussten in der internen Infrastruktur keine doppelten Adressen verwendet werden, die Adressierung war bereits eindeutig. Aufgrund der Tatsache, dass Filterung und Netzwerksegmentierung auf Hosts angewendet wurden, müssen in Rechenzentrumsnetzwerken keine virtuellen Netzwerkeinheiten erstellt werden.

Eine sehr wichtige Sache ist, dass wir nicht brauchen. Wenn einige Funktionen aus dem Netzwerk entfernt werden können, vereinfacht dies die Lebensdauer erheblich und erweitert in der Regel die Auswahl an verfügbarer Hardware und Software und vereinfacht die Diagnose erheblich.
Was brauchen wir also nicht, was konnten wir ablehnen, nicht immer mit Freude in dem Moment, als dies geschah, sondern mit großer Erleichterung, als der Prozess abgeschlossen war?
Zunächst die Ablehnung von L2. Wir brauchen L2 weder real noch emuliert. Wird aufgrund der Tatsache, dass wir den Anwendungsstapel steuern, nicht in großem Umfang verwendet. Unsere Anwendungen sind horizontal skaliert, sie arbeiten mit L3-Adressierung, sie sorgen sich nicht wirklich darum, dass eine bestimmte Instanz ausfällt, sie rollen nur eine neue aus, sie müssen nicht auf der alten Adresse rollen, da es eine separate Ebene für die Serviceerkennung und Überwachung von Maschinen im Cluster gibt . Wir verlagern diese Aufgabe nicht auf das Netzwerk. Die Aufgabe des Netzwerks besteht darin, Pakete von Punkt A zu Punkt B zu liefern.
Es gibt auch keine Situationen, in denen sich Adressen innerhalb des Netzwerks bewegen, und dies muss überwacht werden. In vielen Designs wird dies normalerweise zur Unterstützung der VM-Mobilität benötigt. Wir nutzen die Mobilität virtueller Maschinen nicht in der internen Infrastruktur genau des großen Yandex, und wir sind außerdem der Ansicht, dass dies mit der Netzwerkunterstützung auch dann nicht möglich sein sollte. Wenn Sie dies wirklich tun müssen, müssen Sie dies auf Hostebene tun und die Adressen, die in Overlays migrieren können, so steuern, dass das darunterliegende Routingsystem selbst (Transportnetzwerk) nicht berührt oder zu viele dynamische Änderungen vorgenommen werden.
Eine andere Technologie, die wir nicht verwenden, ist Multicast. Ich kann Ihnen im Detail sagen warum. Das macht das Leben viel einfacher, denn wenn sich jemand mit ihm befasst und beobachtet, wie genau die Steuerebene eines Multicasts aussieht - in allen Installationen, mit Ausnahme der einfachsten, sind dies große Kopfschmerzen. Darüber hinaus ist es beispielsweise schwierig, eine gut funktionierende Open Source-Implementierung zu finden.
Schließlich gestalten wir unsere Netzwerke so, dass sie nicht zu viele Änderungen aufweisen. Wir können uns darauf verlassen, dass der Fluss externer Ereignisse im Routing-System gering ist.

Welche Probleme treten auf und welche Einschränkungen sollten bei der Entwicklung eines Rechenzentrumsnetzwerks berücksichtigt werden? Kosten natürlich. Skalierbarkeit, auf welches Niveau wir wachsen wollen. Die Notwendigkeit einer Erweiterung, ohne den Dienst zu stoppen. Bandbreitenverfügbarkeit. Die Sichtbarkeit dessen, was im Netzwerk passiert, für Überwachungssysteme, für Betriebsteams. Die Unterstützung für die Automatisierung ist wiederum so weit wie möglich, da verschiedene Aufgaben auf verschiedenen Ebenen gelöst werden können, einschließlich der Einführung zusätzlicher Ebenen. Gut und nicht- [wann immer möglich] -abhängig von Anbietern. Obwohl in verschiedenen historischen Perioden, je nachdem, welcher Abschnitt zu betrachten war, war diese Unabhängigkeit leichter oder schwerer zu erreichen. Wenn wir einen Teil der Chips von Netzwerkgeräten nehmen, dann reden wir bis vor kurzem über die Unabhängigkeit von Anbietern. Wenn wir auch Chips mit hohem Durchsatz wollen, kann dies sehr willkürlich sein.

Mit welcher logischen Topologie bauen wir unser Netzwerk auf? Dies wird ein mehrstufiges Clos sein. Tatsächlich gibt es derzeit keine wirklichen Alternativen. Und die Clos-Topologie ist gut genug, auch wenn wir sie mit verschiedenen fortgeschrittenen Topologien vergleichen, die jetzt eher im Bereich des akademischen Interesses liegen, wenn wir Switches mit einer großen Basis haben.
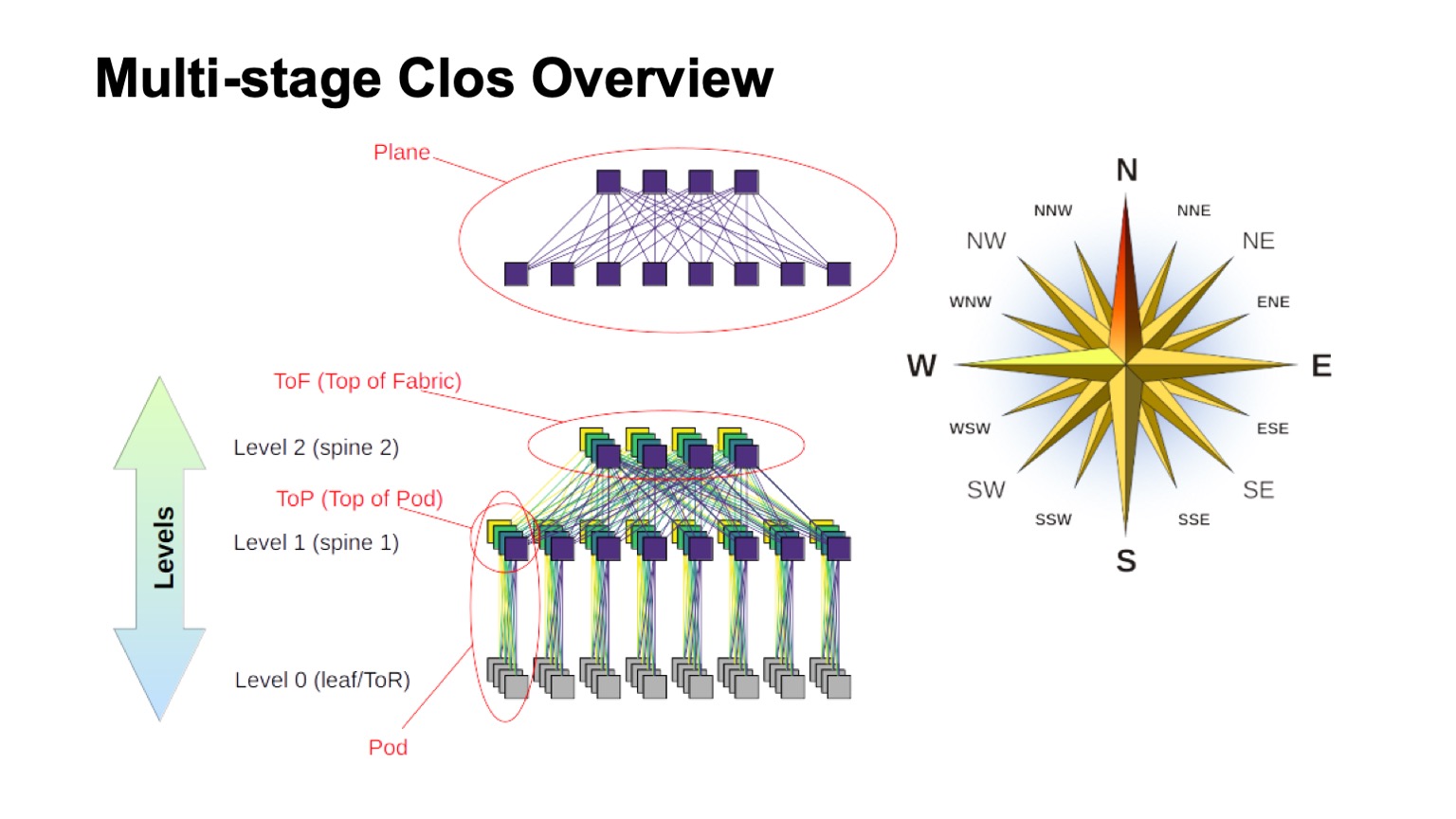
Wie ist das geschichtete Clos-Netzwerk ungefähr aufgebaut und wie heißen die verschiedenen Elemente darin? Zuallererst stieg der Wind auf, um herauszufinden, wo der Norden, wo der Süden, wo der Osten, wo der Westen ist. Netze dieses Typs werden normalerweise von Personen gebaut, die einen sehr großen Verkehr von West nach Ost haben. Wie für den Rest der Elemente ist oben ein virtueller Schalter gezeigt, der aus kleineren Schaltern zusammengesetzt ist. Dies ist die Grundidee des rekursiven Aufbaus von Clos-Netzwerken. Wir nehmen Elemente mit einer Art Radix und verbinden sie, so dass das, was passiert ist, als Switch mit einer größeren Radix betrachtet werden kann. Wenn Sie noch mehr benötigen, kann der Vorgang wiederholt werden.
In Fällen, in denen es zum Beispiel bei Clos mit zwei Ebenen möglich ist, Komponenten, die in meinem Diagramm vertikal sind, eindeutig zu unterscheiden, werden sie normalerweise als Ebenen bezeichnet. Wenn wir Clos-mit drei Ebenen von Wirbelsäulenschaltern bauen würden (alle, die keine Borderline- und keine ToR-Schalter sind und nur für den Transit verwendet werden), würden die Flugzeuge komplizierter aussehen, zwei Ebenen sehen so aus. Den Block der ToR- oder Leaf-Schalter und die zugehörigen Wirbelsäulenschalter der ersten Ebene nennen wir Pod. Wirbelsäulenschalter der Stufe 1 oben auf dem Pod befinden sich oben auf dem Pod und oben auf dem Pod. Die Schalter, die sich oben in der gesamten Fabrik befinden, sind die oberste Schicht der Fabrik, Top of Fabric.

Natürlich stellt sich die Frage: Clos-Netze sind seit einiger Zeit aufgebaut, die Idee selbst stammt in der Regel aus der Zeit der klassischen Telefonie, TDM-Netze. Vielleicht ist etwas Besseres aufgetaucht, vielleicht kannst du irgendwie etwas Besseres tun? Ja und nein Theoretisch ja, in der Praxis in naher Zukunft definitiv nicht. Da es eine Reihe interessanter Topologien gibt, werden einige sogar in der Produktion verwendet. Dragonfly wird beispielsweise in HPC-Anwendungen verwendet. Es gibt auch interessante Topologien wie Xpander, FatClique, Jellyfish. Wenn Sie sich kürzlich Berichte zu Konferenzen wie SIGCOMM oder NSDI ansehen, finden Sie eine relativ große Anzahl von Artikeln zu alternativen Topologien mit besseren Eigenschaften (die eine oder andere) als Clos.
Alle diese Topologien haben jedoch eine interessante Eigenschaft. Es verhindert ihre Implementierung in den Netzwerken von Rechenzentren, die wir auf Standardhardware aufbauen wollen und die angemessenes Geld kosten. In all diesen alternativen Topologien ist der größte Teil des Bandes leider nicht über die kürzesten Wege zugänglich. Daher verlieren wir sofort die Fähigkeit, die traditionelle Steuerebene zu verwenden.
Theoretisch ist die Lösung des Problems bekannt. Dies sind beispielsweise Modifikationen des Verbindungszustands unter Verwendung des k-kürzesten Pfades, es gibt jedoch wiederum keine Protokolle, die in der Produktion implementiert und in großem Umfang auf Geräten verfügbar wären.
Da der größte Teil der Kapazität nicht auf kürzestem Weg erreichbar ist, müssen wir nicht nur die Steuerebene so ändern, dass alle diese Pfade ausgewählt werden (und dies ist übrigens ein viel größerer Zustand in der Steuerebene). Die Weiterleitungsebene muss noch geändert werden. In der Regel sind mindestens zwei zusätzliche Funktionen erforderlich. Dies ist eine Gelegenheit, alle Entscheidungen über die Weiterleitung von Paketen einmalig zu treffen, beispielsweise auf einem Host. Dies ist tatsächlich Quell-Routing. In der Literatur zu Verbindungsnetzen wird es manchmal als All-at-Once-Weiterleitungsentscheidung bezeichnet. Und adaptives Routing ist bereits eine Funktion, die wir für Netzwerkelemente benötigen. Dies führt beispielsweise dazu, dass wir den nächsten Hop anhand der Informationen zur geringsten Last in der Warteschlange auswählen. Beispielsweise sind andere Optionen möglich.
Die Richtung ist also interessant, aber leider können wir sie derzeit nicht anwenden.

Okay, entschied sich für die logische Topologie von Clos. Wie werden wir es skalieren? Mal sehen, wie es funktioniert und was getan werden kann.

Im Clos-Netzwerk gibt es zwei Hauptparameter, die wir irgendwie variieren und bestimmte Ergebnisse erzielen können: Radix-Elemente und die Anzahl der Ebenen im Netzwerk. Ich zeige schematisch, wie der eine und der andere die Größe beeinflusst. Idealerweise kombinieren wir beides.
Es ist ersichtlich, dass die Gesamtbreite des Clos-Netzwerks ein Produkt aller Ebenen von Wirbelsäulen-Switches des südlichen Radix ist, wie viele Verbindungen wir haben, wie sie verzweigen. So skalieren wir die Größe des Netzwerks.
In Bezug auf die Kapazität, insbesondere bei ToR-Switches, gibt es zwei Skalierungsoptionen. Entweder können wir unter Beibehaltung der allgemeinen Topologie schnellere Verknüpfungen verwenden oder wir können mehr Ebenen hinzufügen.
Wenn Sie sich die detaillierte Version des Clos-Netzwerks (in der unteren rechten Ecke) ansehen und zu diesem Bild mit dem Clos-Netzwerk unten zurückkehren ...
... dann ist das genau die gleiche Topologie, aber auf dieser Folie ist sie kompakter zusammengeklappt und die Werksebenen überlagern sich. Es ist ein und dasselbe.

Wie sieht die Skalierung eines Clos-Netzwerks in Zahlen aus? Hier habe ich Daten darüber, welche maximale Breite ein Netzwerk erhalten kann, wie viele Racks, ToR-Switches oder Leaf-Switches maximal vorhanden sind, und ob sie sich nicht in Racks befinden. Dies hängt davon ab, welche Basis von Switches für Stacheln verwendet wird Ebenen und wie viele Ebenen wir verwenden.
Es zeigt, wie viele Racks wir haben können, wie viele Server und wie viel all dies bei einer Leistung von 20 kW pro Rack verbrauchen kann. Ein wenig zuvor erwähnte ich, dass wir eine Clustergröße von etwa 100.000 Servern anstreben.
Es ist ersichtlich, dass bei dieser gesamten Konstruktion zweieinhalb Optionen von Interesse sind. Es gibt eine Option mit zwei Schichten von Stacheln und 64-Port-Switches, die etwas kurz ist. Passgenaue Optionen für Wirbelsäulen-Switches mit 128 Ports (mit 128 Radix) mit zwei Ebenen oder Switches mit 32 Radix mit drei Ebenen. Und in allen Fällen, in denen es mehr Radix und mehr Ebenen gibt, können Sie ein sehr großes Netzwerk aufbauen, aber wenn Sie den erwarteten Verbrauch betrachten, gibt es in der Regel Gigawatt. Sie können das Kabel verlegen, aber es ist unwahrscheinlich, dass wir an einem Ort so viel Strom bekommen. Wenn Sie sich Statistiken ansehen, öffentliche Daten zu Rechenzentren - es gibt nur sehr wenige Rechenzentren mit einer geschätzten Kapazität von mehr als 150 MW. Darüber hinaus befinden sich an Rechenzentrumsstandorten in der Regel mehrere große Rechenzentren ziemlich nahe beieinander.
Es gibt noch einen weiteren wichtigen Parameter. Wenn Sie sich die linke Spalte ansehen, wird dort die nutzbare Bandbreite angezeigt. Es ist leicht zu bemerken, dass in einem Clos-Netzwerk ein erheblicher Teil der Ports für die Verbindung der Switches untereinander aufgewendet wird. Nutzbare Bandbreite können Sie den Servern zur Verfügung stellen. Natürlich spreche ich über bedingte Ports und über den Strip. In der Regel sind die Verbindungen innerhalb des Netzwerks schneller als die Verbindungen zu den Servern, aber je Bandeinheit gibt es noch einige Bänder innerhalb des Netzwerks. Und je mehr Ebenen wir verwenden, desto höher sind die Stückkosten für die Bereitstellung dieses Streifens nach außen.
Darüber hinaus ist auch dieses zusätzliche Band nicht genau dasselbe. Während die Zeitspannen kurz sind, können wir so etwas wie DAC (Direct Attach Copper, dh Twinax-Kabel) oder Multimode-Optiken verwenden, die noch mehr oder weniger vernünftiges Geld kosten. Sobald wir authentischer auf Spannweiten umschalten, handelt es sich in der Regel um Single-Mode-Optiken, und die Kosten für dieses zusätzliche Band steigen deutlich an.
Wenn wir zur vorherigen Folie zurückkehren und ein Clos-Netzwerk erstellen, ohne es erneut zu abonnieren, ist es einfach, das Diagramm zu betrachten und zu sehen, wie das Netzwerk aufgebaut ist. Wenn wir jede Ebene von Wirbelsäulenschaltern hinzufügen, wiederholen wir den gesamten Streifen, der sich darunter befand. Plus-Pegel - plus dasselbe Band, dieselbe Anzahl von Ports an den Switches wie auf dem vorherigen Pegel, dieselbe Anzahl von Transceivern. Daher ist es sehr wünschenswert, die Anzahl der Stufen von Wirbelsäulenschaltern zu minimieren.
Anhand dieses Bildes ist klar, dass wir wirklich auf so etwas wie Switches mit 128 Radix aufbauen wollen.

Hier ist im Prinzip alles das Gleiche wie ich gerade gesagt habe, diese Folie wird eher später betrachtet.

, ? , - . , . , . , . , , , , . ( ), control plane , , , , . , , .
, , , SerDes- — - . forwarding . , , , , , Clos-, . .
, , . , , , , , , , , , .

— , . , , . , , , - , . , , , , .
, , , . -, , . , , 128 , .
, , , data plane. . , , . , , , . , , , , 128 , . . . .
, - , . ( ), , — ToR- leaf-, . - , , , , - . , , , - .

, , .

? . , , , : leaf-, 1, 2. , — twinax, multimode, single mode. , , , , , .
. , , multimode , , , 100- . , , , single mode , , single mode, - CWDM, single mode (PSM) , , , .
: , 100 425 . SFP28 , QSFP28 100 . multimode .
- , - , - - . , . , - Pods twinax- ( ).
, , , CWDM. .
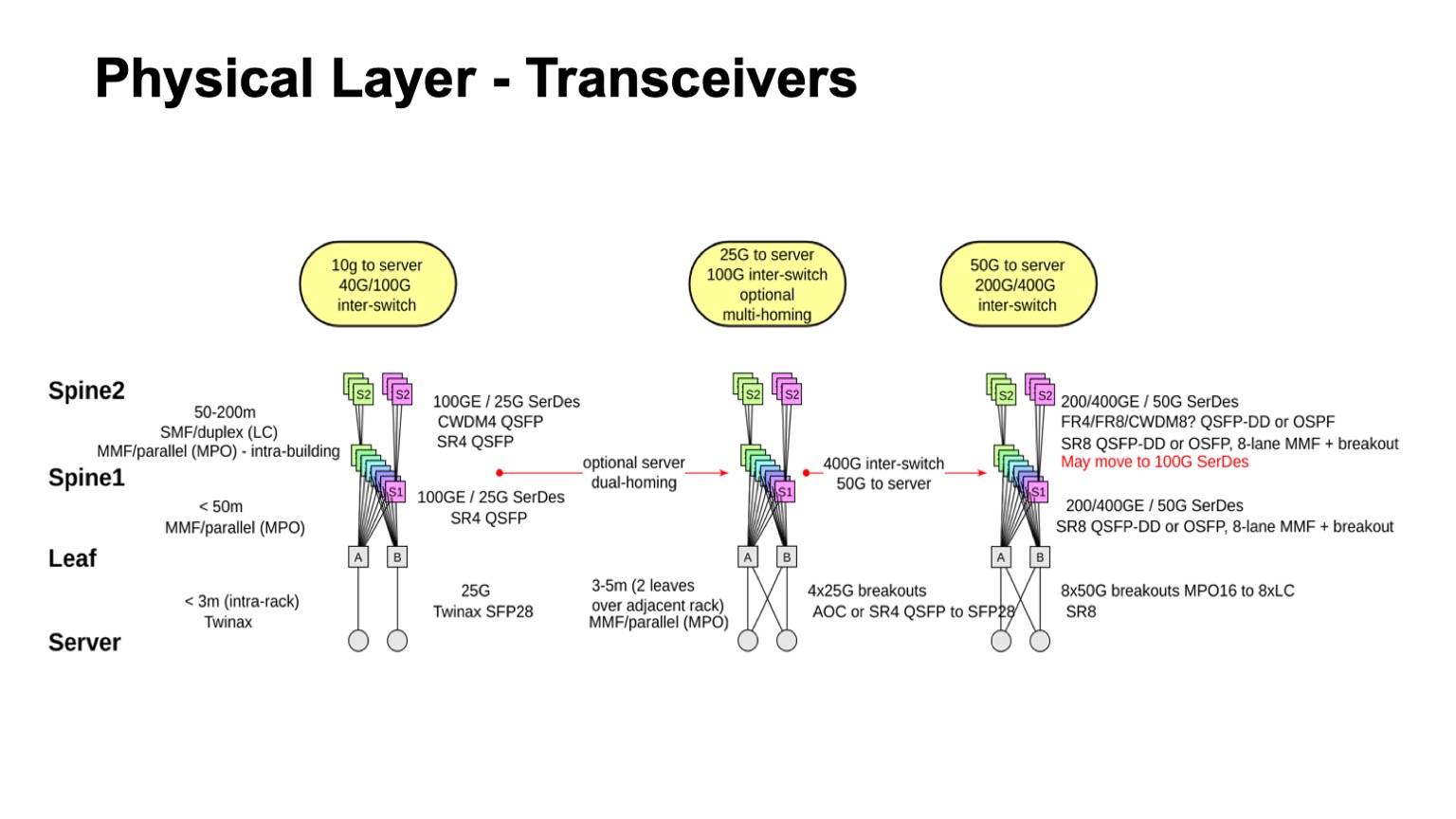
, , . , , 50- SerDes . , , 400G, 50G SerDes- , 100 Gbps per lane. , 50 100- SerDes 100 Gbps per lane, . , 50G SerDes , , , 100G SerDes . - , , .
. , 400- 200- 50G SerDes. , , , , , , . 128. , , , , .
, , . , , , , , 100- , .

— , . , . leaf- — , . , , — .
, , , -. , , - -, . . , , , . - -, -, , , , . : . - , « », Clos-, . , , .
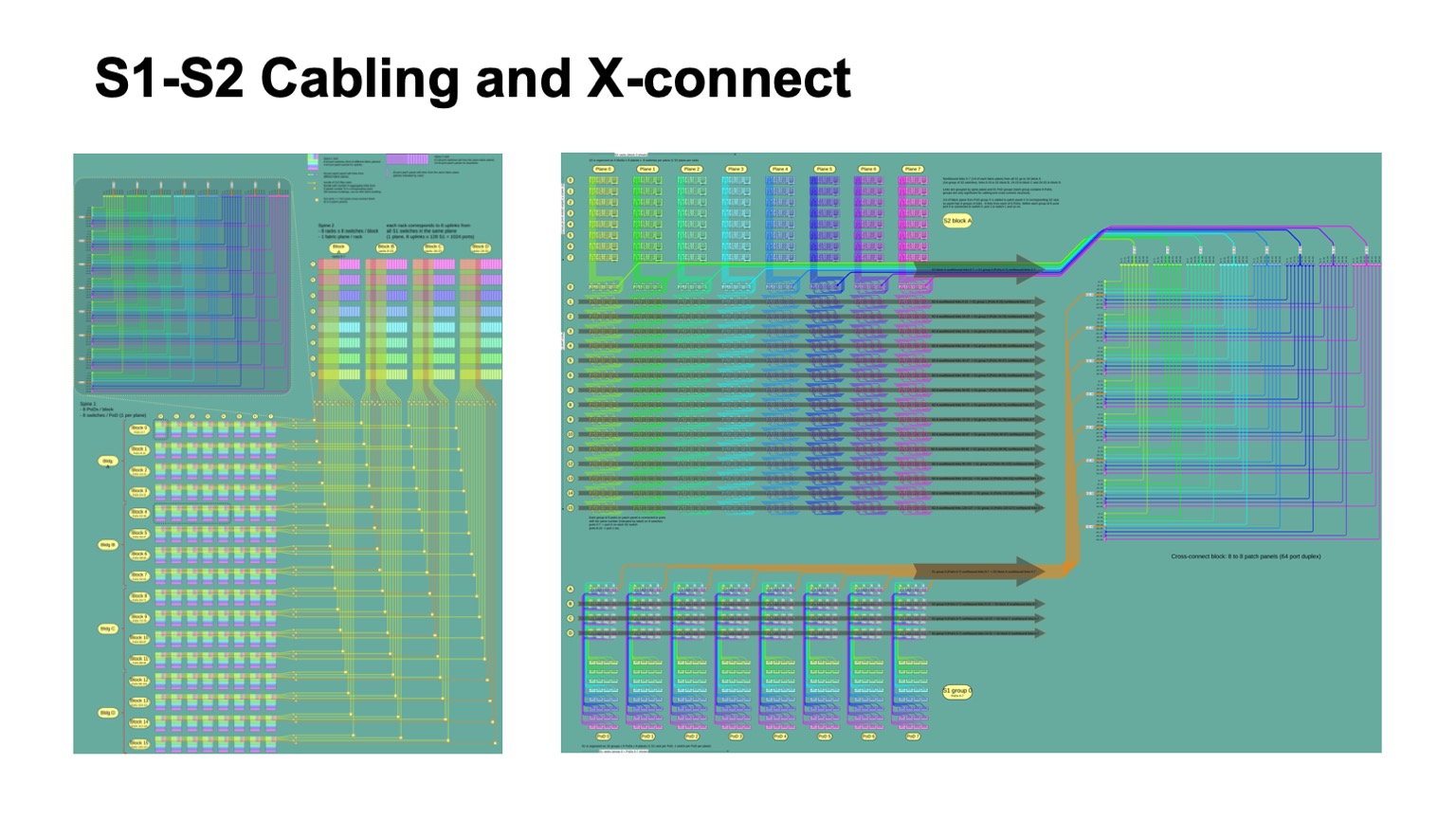
. - , , , , -2-.
. , - 512 512 , , , -2. Pods -1, -, -2.

So sieht es aus. -2 () -. , . -, . , , .

: , . control plane-? , - , link state , , , , . , — , link state . , , , , fanout, control plane . link state .
— BGP. , RFC 7938 BGP -. : , , , path hunting. , , , valley free. , , , . , , . . .
, , BGP. eBGP, link local, : ToR, -1- Pod, Top of Fabric. , BGP , .

, , , , control plane. L3 , , . — , , , multi-path, multi-path , , , . , , , , , . , multi-path, ToR-.

, , — . , , , , BGP, . , corner cases , BGP .
RIFT, .

— , data plane , . : ECMP , Next Hop.
, , Clos- , , , , , . , ECMP, single path-. Alles ist gut. , Clos- , Top of fabric, , . , , . , ECMP state.
data plane ? LPM (longest prefix match), , 100 . Next Hop , , 2-4 . , Next Hops ( adjacencies), - 16 64. . : MPLS -? , .

. , . white boxes MPLS. MPLS, , , , ECMP. Und hier ist warum.

ECMP- IP. Next Hops ( adjacencies, -). , -, Next Hop. IP , , Next Hops.

MPLS , . Next Hops . , , .
, 4000 ToR-, — 64 ECMP, -1 -2. , , ECMP-, ToR , Next Hops.

, Segment Routing . Next Hops. wild card: . , .
, - . ? Clos- . , Top of fabric. . , , Top of fabric, , , . , , , , .
— . , Clos- , , , ToR, Top of fabric , . Pod, Edge Pod, .
. , , Facebook. Fabric Aggregator HGRID. -, -. , . , touch points, . , , -. , - , , . , , . overlays, .

? — CI/CD-. , , , . , , . , , .
, . . — .
. , RIFT. congestion control , , , , RDMA .
, , , , overhead. — HPC Cray Slingshot, commodity Ethernet, . overhead .

, , . — . — . - scale out — . , . . Vielen Dank.