Hallo!
Sehen Sie oft giftige Kommentare in sozialen Netzwerken? Dies hängt wahrscheinlich von den Inhalten ab, die Sie gerade ansehen. Ich schlage vor, ein wenig mit diesem Thema zu experimentieren und das neuronale Netzwerk zu unterrichten, um die Kommentare der Hasser zu bestimmen.
Unser globales Ziel ist es, festzustellen, ob ein Kommentar aggressiv ist, dh, es handelt sich um eine binäre Klassifikation. Wir werden ein einfaches neuronales Netzwerk schreiben, es auf einen Datensatz von Kommentaren aus verschiedenen sozialen Netzwerken trainieren und dann eine einfache Analyse mit Visualisierung durchführen.
Für die Arbeit werde ich Google Colab verwenden. Mit diesem Dienst können Sie Jupyter Notebooks ausführen und haben kostenlosen Zugriff auf die GPU (NVidia Tesla K80), wodurch das Lernen beschleunigt wird. Ich benötige das Backend TensorFlow, die Standardversion in Colab 1.15.0, also aktualisiere einfach auf 2.0.0.
Wir importieren das Modul und aktualisieren.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Sie können die aktuelle Version so sehen.
print(tf.__version__)
Vorbereitende Arbeiten erledigt, wir importieren alle notwendigen Module.
import os import numpy as np
Beschreibung der verwendeten Bibliotheken
- os - für die Arbeit mit dem Dateisystem
- numpy - für die Arbeit mit Arrays
- pandas - eine Bibliothek zur Analyse von Tabellendaten
- Keras - um ein Modell zu bauen
- keras.preprocessing.Text - zur Textverarbeitung, um es in numerischer Form zum Trainieren eines neuronalen Netzwerks einzureichen
- sklearn.train_test_split - um Testdaten vom Training zu trennen
- matplotlib - um den Lernprozess zu visualisieren
- sklearn.normalize - um Test- und Trainingsdaten zu normalisieren
Analysieren von Daten mit Kaggle
Ich lade Daten direkt in den Colab-Laptop. Außerdem extrahiere ich sie bereits ohne Probleme.
path = 'labeled.csv' df = pd.read_csv(path) df.head()
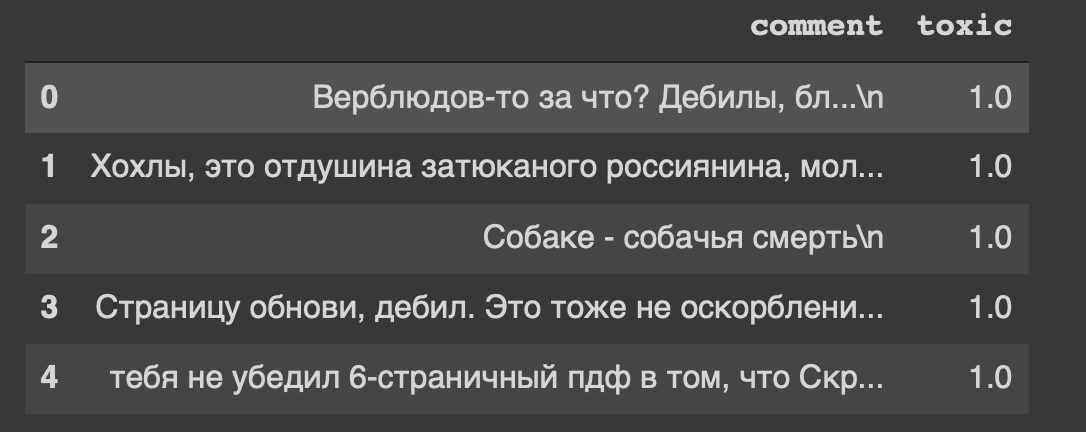
Und das ist die Überschrift unseres Datensatzes ... Ich fühle mich auch irgendwie unwohl von "Seite aktualisieren, Idiot".
Da unsere Daten in der Tabelle enthalten sind, werden wir sie in zwei Teile unterteilen: Daten für das Training und für das Testmodell. Aber das ist alles Text, etwas muss getan werden.
Datenverarbeitung
Entfernen Sie die Zeilenumbrüche aus dem Text.
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
Kommentare haben einen echten Datentyp, wir müssen sie in eine ganze Zahl übersetzen. Speichern Sie es anschließend in einer separaten Variablen.
target = np.array(df['toxic'].astype('uint8')) target[:5]
Jetzt werden wir den Text mit der Tokenizer-Klasse leicht verarbeiten. Lassen Sie uns eine Kopie davon schreiben.
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
Schnell über die Parameter- num_words - Anzahl fester Wörter (am häufigsten)
- Filter - eine Folge von Zeichen, die gelöscht werden sollen
- lower - ein boolescher Parameter, der steuert, ob der Text in Kleinbuchstaben geschrieben wird
- split - das Hauptsymbol zum Teilen eines Satzes
- char_level - Gibt an, ob ein einzelnes Zeichen als Wort betrachtet wird
Und jetzt werden wir den Text mit der Klasse verarbeiten.
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
Wir haben 14.000 Beispielzeilen und 30.000 Feature-Spalten.

Ich baue ein Modell aus zwei Schichten: Dicht und Ausfallend.
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
Wir normalisieren die Matrix und teilen die Daten wie vereinbart in zwei Teile auf (Training und Test).
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
Model Training
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
Ich werde den Lernprozess bei den letzten Iterationen zeigen.

Visualisierung des Lernprozesses
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
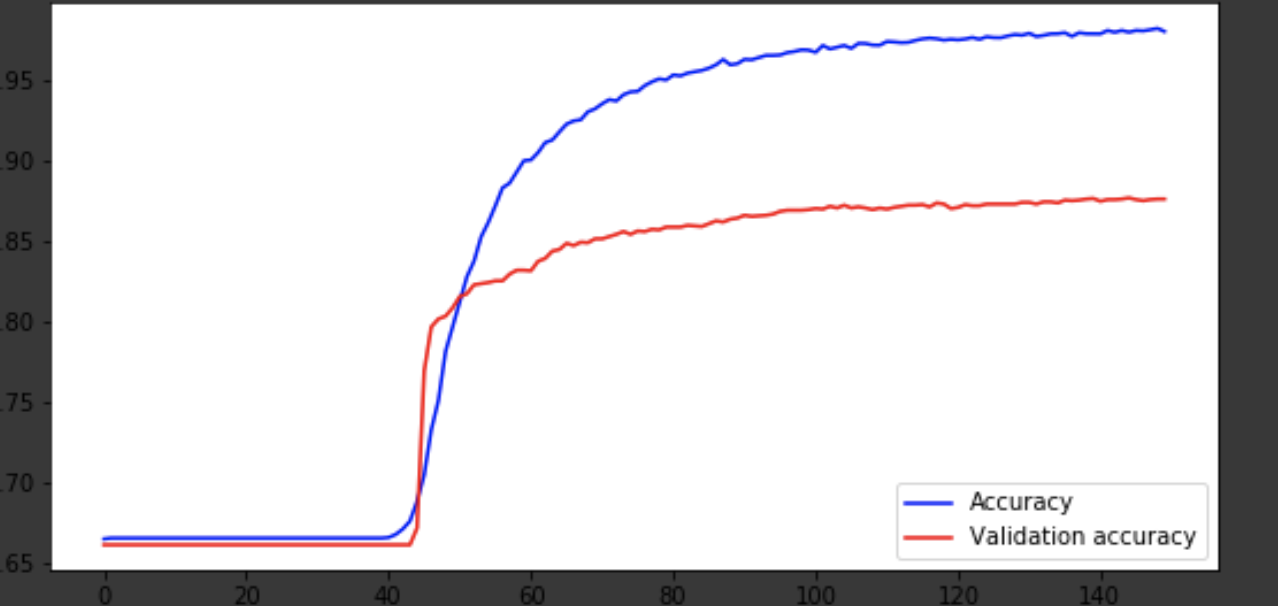
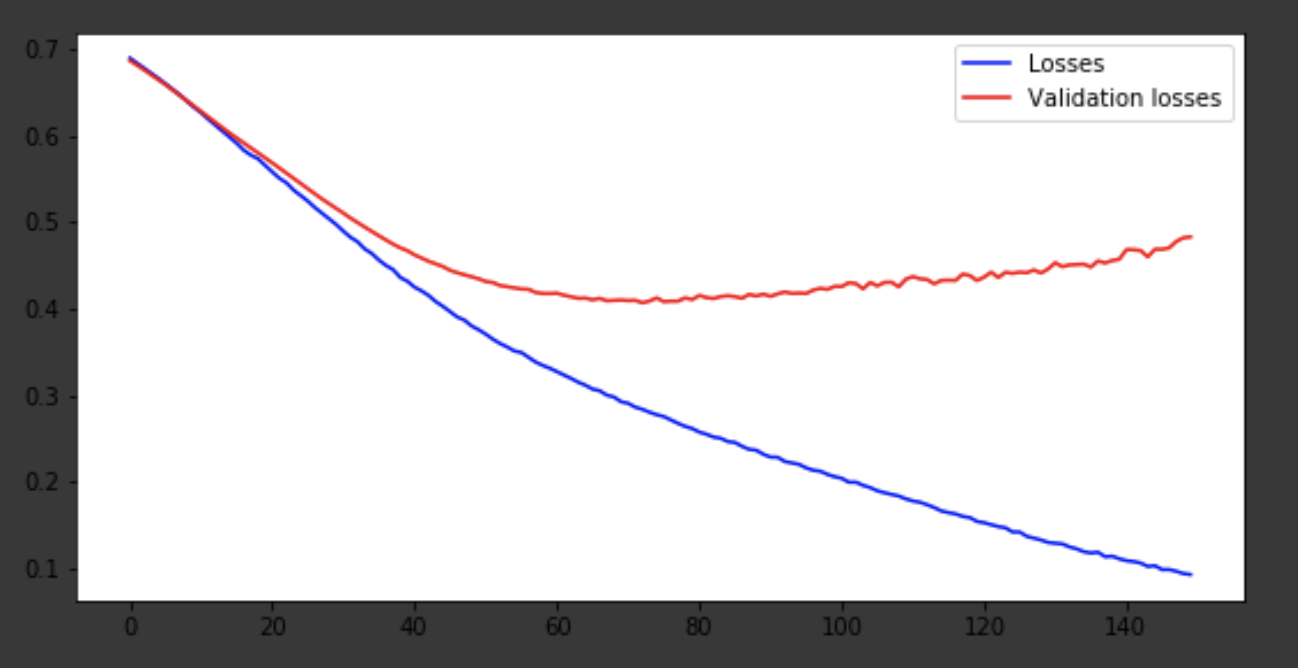
Fazit
Das Modell kam um die 75. Ära heraus, und dann verhält es sich schlecht. Die Genauigkeit von 0,85 stört nicht. Sie können Spaß mit der Anzahl der Ebenen und Hyperparameter haben und versuchen, das Ergebnis zu verbessern. Es ist immer interessant und gehört zum Job. Schreiben Sie über Ihre Gedanken in Kommentare, wir werden sehen, wie viele Hüte dieser Artikel gewinnen wird.