Der Artikel beschreibt Ansätze zur Erstellung personalisierter Produkt- und Inhaltsempfehlungen sowie mögliche Anwendungsfälle.
Personalisierte Produkt- und Inhaltsempfehlungen werden verwendet, um die Conversion zu steigern, die Durchschnittsprüfung durchzuführen und die Benutzerfreundlichkeit zu verbessern.

Ein Beispiel für die Verwendung dieses Ansatzes ist Amazon und Netflix. Amazon begann in den ersten Jahren seines Bestehens mit der Verwendung eines kollaborativen Filteransatzes und erzielte nur durch den Algorithmus ein Umsatzwachstum von 10%. Netflix erhöht die Menge der angezeigten Inhalte aufgrund des Ansatzes basierend auf dem Algorithmus des Empfehlungssystems um 40%. Es ist jetzt einfacher, ein Unternehmen zu benennen, das diesen Ansatz nicht verwendet, als alle aufzulisten, die ihn verwenden.
Netflix hat eine faszinierende Geschichte im Zusammenhang mit dieser Technologie. In den Jahren 2006-2009 (noch bevor der Austragungsort des Kaggle ML-Wettbewerbs bekannt wurde) kündigte Netflix einen offenen Wettbewerb zur Verbesserung des Algorithmus mit einem Preispool von 1.000.000 USD an. Der Wettbewerb dauerte 2 Jahre und mehrere tausend Entwickler und Wissenschaftler nahmen daran teil. Wenn Netflix sie in dem Staat anheuert, sind die Kosten um ein Vielfaches höher als der versprochene Preis. Infolgedessen gewann eines der Teams, indem es eine Lösung mit der erforderlichen Qualität 2 Stunden früher als das andere Team sendete und das Ergebnis des Gewinners wiederholte. Infolgedessen ging das Geld an ein schnelles Team. Der Wettbewerb hat sich zu einem Katalysator für qualitative Veränderungen im Bereich der personalisierten Empfehlungen entwickelt.
Der Hauptansatz zur Lösung des Problems des Aufbaus von Empfehlungssystemen ist die kollaborative Filterung.
Die Idee des kollaborativen Filterns ist einfach: Wenn ein Benutzer ein Produkt kauft oder Inhalte ansieht, werden wir Benutzer mit ähnlichen Vorlieben finden und unserem Kunden empfehlen, dass Leute wie er konsumieren, der Kunde jedoch nicht. Dies ist ein benutzerbasierter Ansatz.
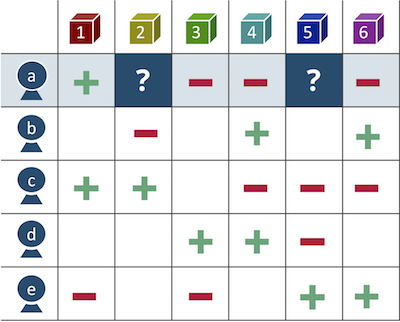 Abbildung 1 - Produktpräferenzmatrix
Abbildung 1 - ProduktpräferenzmatrixEbenso können Sie das Problem aus der Sicht der Waren betrachten und ergänzende Waren in den Warenkorb des Kunden aufnehmen, indem Sie den durchschnittlichen Scheck erhöhen oder die Waren, die nicht auf Lager sind, durch eine analoge Ware ersetzen. Dies ist ein objektbasierter Ansatz.
Im einfachsten Fall wird der Algorithmus zum Auffinden der nächsten Nachbarn verwendet.
Beispiel: Wenn Maria den Film „Titanic“ und „Star Wars“ mag, ist Anya diejenige, die ihrem Geschmack am nächsten kommt und neben diesen Filmen auch „Hachiko“ gesehen hat. Empfehlen wir Maria den Film „Hachiko“. Es ist klärungsbedürftig, dass in der Regel nicht ein nächster Nachbar, sondern mehrere verwendet werden, wobei die Ergebnisse gemittelt werden.
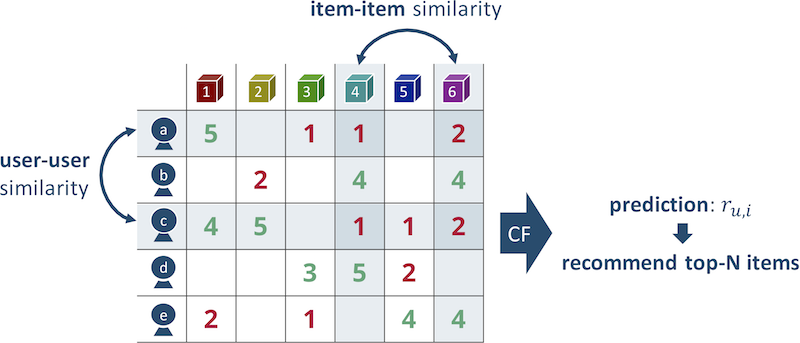 Fig. 2 Das Funktionsprinzip des Algorithmus der nächsten Nachbarn
Fig. 2 Das Funktionsprinzip des Algorithmus der nächsten NachbarnAlles scheint einfach zu sein, aber die Qualität der Empfehlungen, die diesen Ansatz verwenden, ist gering.
Betrachten Sie komplexe Algorithmen von Empfehlungssystemen, die auf der Eigenschaft von Matrizen oder vielmehr auf der Zerlegung von Matrizen beruhen.
Der klassische Algorithmus ist SVD (Singular Matrix Decomposition).
Die Bedeutung des Algorithmus ist, dass die Matrix der Produktpräferenzen (die Matrix, in der die Zeilen Benutzer und die Spalten die Produkte sind, mit denen Benutzer interagierten) als das Produkt von drei Matrizen dargestellt wird.
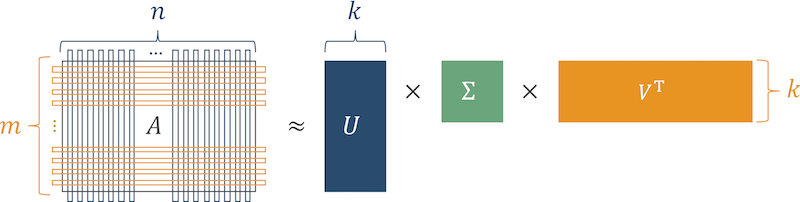 Abb. 3 SVD-Algorithmus
Abb. 3 SVD-AlgorithmusNach dem Wiederherstellen der ursprünglichen Matrix zeigen Zellen, in denen der Benutzer Nullen und "große" Zahlen hatte, den Grad des latenten Interesses an dem Produkt. Ordnen Sie diese Nummern an und erhalten Sie eine Liste der für den Benutzer relevanten Produkte.
Während dieses Vorgangs erscheinen dem Benutzer und dem Produkt "latente" Zeichen. Dies sind Zeichen, die den "verborgenen" Zustand des Benutzers und des Produkts anzeigen.
Es ist jedoch bekannt, dass sowohl der Benutzer als auch das Produkt neben den „latenten“ auch offensichtliche Anzeichen aufweisen. Dies sind Geschlecht, Alter, durchschnittlicher Kaufbeleg, Region usw.
Versuchen wir, unser Modell mit diesen Daten anzureichern.
Dazu verwenden wir den Algorithmus der Faktorisierungsmaschine.
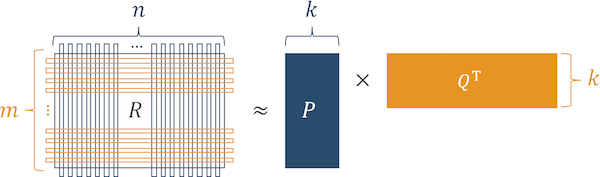 Fig. 4 Funktionsalgorithmus von Faktorisierungsmaschinen
Fig. 4 Funktionsalgorithmus von FaktorisierungsmaschinenErfahrungsgemäß
erzielen bei
Data4 Fallstudien im Bereich der
Bauempfehlungssysteme für Online-Shops, nämlich Faktorisierungsmaschinen, das beste Ergebnis. Aus diesem Grund haben wir mit Faktorisierungsmaschinen ein Empfehlungssystem für unseren Kunden KupiVip erstellt. Das Wachstum der RMSE-Metrik betrug 6-7%.
Matrixbasierte Ansätze haben jedoch ihre Nachteile. Die Anzahl der verallgemeinerten Muster der gegenseitigen Warenkombination ist nicht groß. Um dieses Problem zu lösen, ist es ratsam, neuronale Netze zu verwenden. Für ein neuronales Netzwerk sind jedoch Datenmengen erforderlich, über die nur große Unternehmen verfügen.
Erfahrungsgemäß verfügt bei
Data4 nur ein Kunde über ein neuronales Netzwerk für personalisierte Produktempfehlungen, die das beste Ergebnis
liefern . Mit Erfolg können Sie jedoch bis zu 10% der RMSE-Metrik erhalten. Neuronale Netze werden auf YouTube und einigen der größten Content-Websites verwendet.
Anwendungsfälle
Für Online-Shops
- Empfehlen Sie Produkte, die für den Benutzer relevant sind, auf den Seiten des Onlineshops
- Verwenden Sie den "you may like" -Block in der Produktkarte
- Im Warenkorb empfehlen ergänzende Waren (Fernbedienung für TV)
- Wenn das Produkt nicht auf Lager ist, empfehlen Sie eine analoge
- Erstellen Sie personalisierte Newsletter
Für den Inhalt
- Steigern Sie das Engagement, indem Sie relevante Artikel, Filme, Bücher und Videos empfehlen
Andere
- Empfehlen Sie Menschen in Dating-Apps
- Empfehlen Sie Gerichte in einem Restaurant
In dem Artikel haben wir die Grundlagen der Geräteempfehlungssysteme und Fallstudien besprochen. Wir haben gelernt, dass das Hauptprinzip darin besteht, Produkte mit ähnlichen Vorlieben und der Verwendung eines kollaborativen Filteralgorithmus zu empfehlen.
Im nächsten Artikel werden Life-Hacks von Empfehlungssystemen basierend auf realen Geschäftsfällen betrachtet. Wir zeigen, welche Metriken am besten verwendet werden und welcher Proximity-Koeffizient für die Vorhersage zu wählen ist.