Wie mache ich den Herbst weich?

Ich habe keine umfassende Anleitung zur Fehlerbehandlung in React-Anwendungen gefunden und daher beschlossen, die in diesem Artikel gesammelten Erfahrungen zu teilen. Der Artikel richtet sich an Einsteiger-Entwickler und kann als Ausgangspunkt für die Systematisierung der Fehlerbehandlung in der Anwendung dienen.
Probleme und Zielsetzung
Montagmorgen trinkst du ruhig Kaffee und rühmst dich, dass du mehr Fehler behoben hast als letzte Woche. Dann kommt der Manager und winkt mit den Händen. "Wir sind abgefallen, alles ist sehr traurig, wir verlieren Geld." Sie starten und öffnen Ihren Mac, wechseln zur Produktionsversion Ihres SPA, machen ein paar Klicks, um den Fehler zu spielen, sehen den weißen Bildschirm und nur der Allmächtige weiß, was dort passiert ist, klettern in die Konsole, beginnen zu graben, innerhalb der Komponente t gibt es eine Komponente mit dem sprechenden Namen b, in dem der Fehler die Eigenschaft getId von undefined nicht lesen kann. Nach stundenlanger Recherche stürzen Sie sich mit einem Siegesschrei auf den Hotfix. Solche Überfälle kommen mit einiger Häufigkeit vor und sind zur Norm geworden, aber was ist, wenn ich sage, dass alles anders sein kann? Wie kann die Zeit für das Debuggen von Fehlern verkürzt und der Prozess so aufgebaut werden, dass der Client während der Entwicklung praktisch keine unvermeidlichen Fehlkalkulationen bemerkt?
Lassen Sie uns die aufgetretenen Probleme der Reihe nach untersuchen:- Selbst wenn der Fehler im Modul nicht signifikant oder lokalisiert ist, wird die gesamte Anwendung in jedem Fall funktionsunfähig
Vor Version 16 von React verfügten Entwickler nicht über einen einzigen standardmäßigen Fehlerbehebungsmechanismus, und es gab Situationen, in denen Datenbeschädigungen nur in den nächsten Schritten zu einem Rückgang des Renderns oder zu einem ungewöhnlichen Anwendungsverhalten führten. Jeder Entwickler handhabte Fehler, weil er daran gewöhnt war, und das imperative Modell mit try / catch passte im Allgemeinen nicht gut zu den deklarativen Prinzipien von React. In Version 16 erschien das Tool "Fehlergrenzen", mit dem versucht wurde, diese Probleme zu lösen. Wir werden überlegen, wie es angewendet werden soll. - Der Fehler wird nur in der Produktionsumgebung reproduziert oder kann ohne zusätzliche Daten nicht reproduziert werden.
In einer idealen Welt entspricht die Entwicklungsumgebung der Produktion und wir können jeden Fehler lokal reproduzieren, aber wir leben in der realen Welt. Es gibt keine Debugging-Tools im Kampfsystem. Es ist schwierig und nicht produktiv, solche Vorfälle aufzudecken. Grundsätzlich müssen Sie sich mit verschleiertem Code und dem Mangel an Informationen über den Fehler auseinandersetzen und nicht mit dem Wesen des Problems. Wir werden die Frage, wie die Bedingungen der Entwicklungsumgebung an die Produktionsbedingungen angeglichen werden sollen, nicht berücksichtigen. Wir werden jedoch Tools berücksichtigen, mit denen Sie detaillierte Informationen zu aufgetretenen Vorfällen erhalten.
All dies verringert die Geschwindigkeit der Entwicklung und die Bindung der Benutzer an das Softwareprodukt. Deshalb habe ich mir die drei wichtigsten Ziele gesetzt:
- Verbessern Sie die Benutzererfahrung mit der Anwendung im Falle von Fehlern.
- Reduzieren Sie die Zeit zwischen dem Einstieg in die Produktion und der Erkennung des Fehlers.
- Beschleunigen Sie das Auffinden und Debuggen von Problemen in der Anwendung für den Entwickler.
Welche Aufgaben müssen gelöst werden?- Behandeln Sie kritische Fehler mit Error Boundary
Um die Benutzerfreundlichkeit der Anwendung zu verbessern, müssen kritische Benutzeroberflächenfehler abgefangen und verarbeitet werden. In dem Fall, in dem die Anwendung aus unabhängigen Komponenten besteht, ermöglicht eine solche Strategie dem Benutzer, mit dem Rest des Systems zu arbeiten. Wenn möglich, können wir auch versuchen, die Anwendung nach einem Absturz wiederherzustellen.
- Speichern Sie erweiterte Fehlerinformationen
Wenn ein Fehler auftritt, senden Sie Debugging-Informationen an den Überwachungsserver, der Informationen zu Vorfällen filtert, speichert und anzeigt. Dies hilft uns, Fehler nach der Bereitstellung schnell zu erkennen und zu beheben.
Kritische FehlerbehandlungAb Version 16 hat React das Standardverhalten bei der Fehlerbehandlung geändert. Ausnahmen, die mit Error Boundary nicht abgefangen wurden, führen dazu, dass die Bereitstellung des gesamten React-Baums aufgehoben wird und die gesamte Anwendung nicht mehr funktioniert. Diese Entscheidung wird durch die Tatsache begründet, dass es besser ist, nichts zu zeigen, als dem Benutzer die Möglichkeit zu geben, ein unvorhersehbares Ergebnis zu erzielen. Weitere
Informationen finden Sie in der
offiziellen Dokumentation zu React .
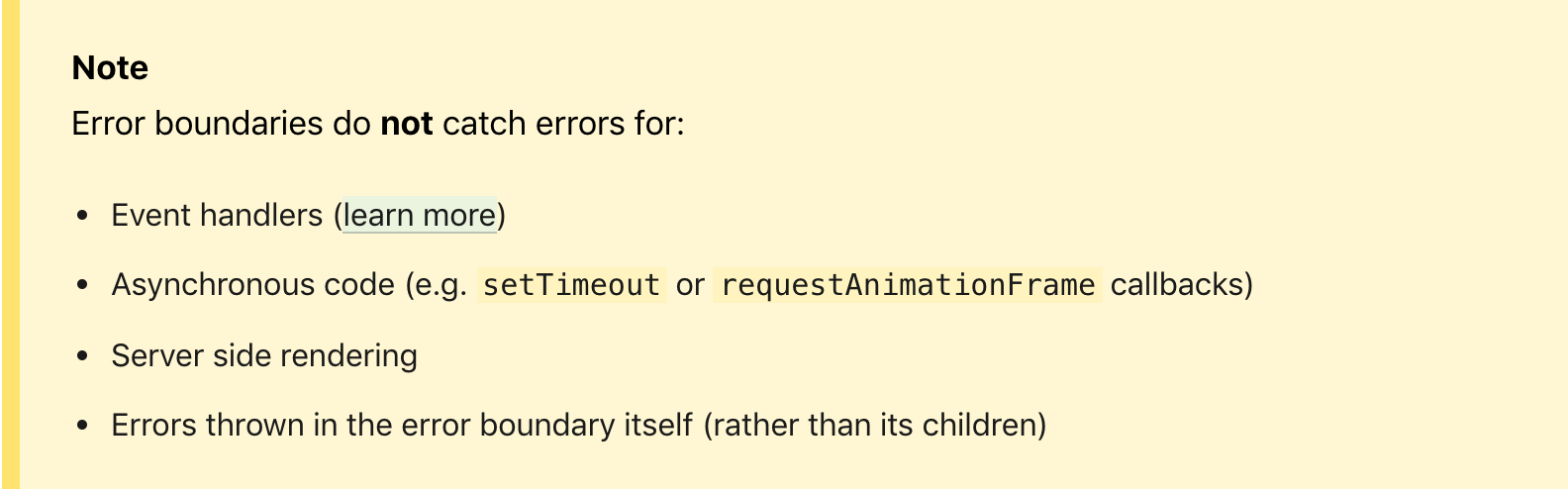
Viele sind auch verwirrt über den Hinweis, dass die Fehlergrenze keine Fehler von Ereignishandlern und asynchronem Code abfängt. Wenn Sie jedoch darüber nachdenken, kann jeder Handler letztendlich den Status ändern, auf dessen Grundlage ein neuer Renderzyklus aufgerufen wird, der letztendlich ausgeführt wird Konto kann einen Fehler im UI-Code verursachen. Andernfalls ist dies kein kritischer Fehler für die Benutzeroberfläche und kann innerhalb des Handlers auf eine bestimmte Weise behandelt werden.
Aus unserer Sicht ist ein kritischer Fehler eine Ausnahme, die im UI-Code aufgetreten ist. Wenn er nicht verarbeitet wird, wird die Bereitstellung des gesamten React-Baums aufgehoben. Die verbleibenden Fehler sind unkritisch und können entsprechend der Anwendungslogik verarbeitet werden, z. B. über Benachrichtigungen.
In diesem Artikel konzentrieren wir uns auf die Behandlung kritischer Fehler, obwohl unkritische Fehler im schlimmsten Fall auch zu einer Inoperabilität der Benutzeroberfläche führen können. Ihre Verarbeitung ist schwer in einen gemeinsamen Block aufzuteilen und jeder Einzelfall erfordert eine Entscheidung in Abhängigkeit von der Anwendungslogik.
Im Allgemeinen können unkritische Fehler sehr kritisch sein (z. B. Wortspiele). Informationen zu diesen Fehlern sollten daher auf die gleiche Weise protokolliert werden wie bei kritischen Fehlern.
Jetzt entwerfen wir Error Boundary für unsere einfache Anwendung. Sie besteht aus einer Navigationsleiste, einer Kopfzeile und einem Hauptarbeitsbereich. Es ist einfach genug, sich nur auf die Fehlerbehandlung zu konzentrieren, aber es hat eine typische Struktur für viele Anwendungen.
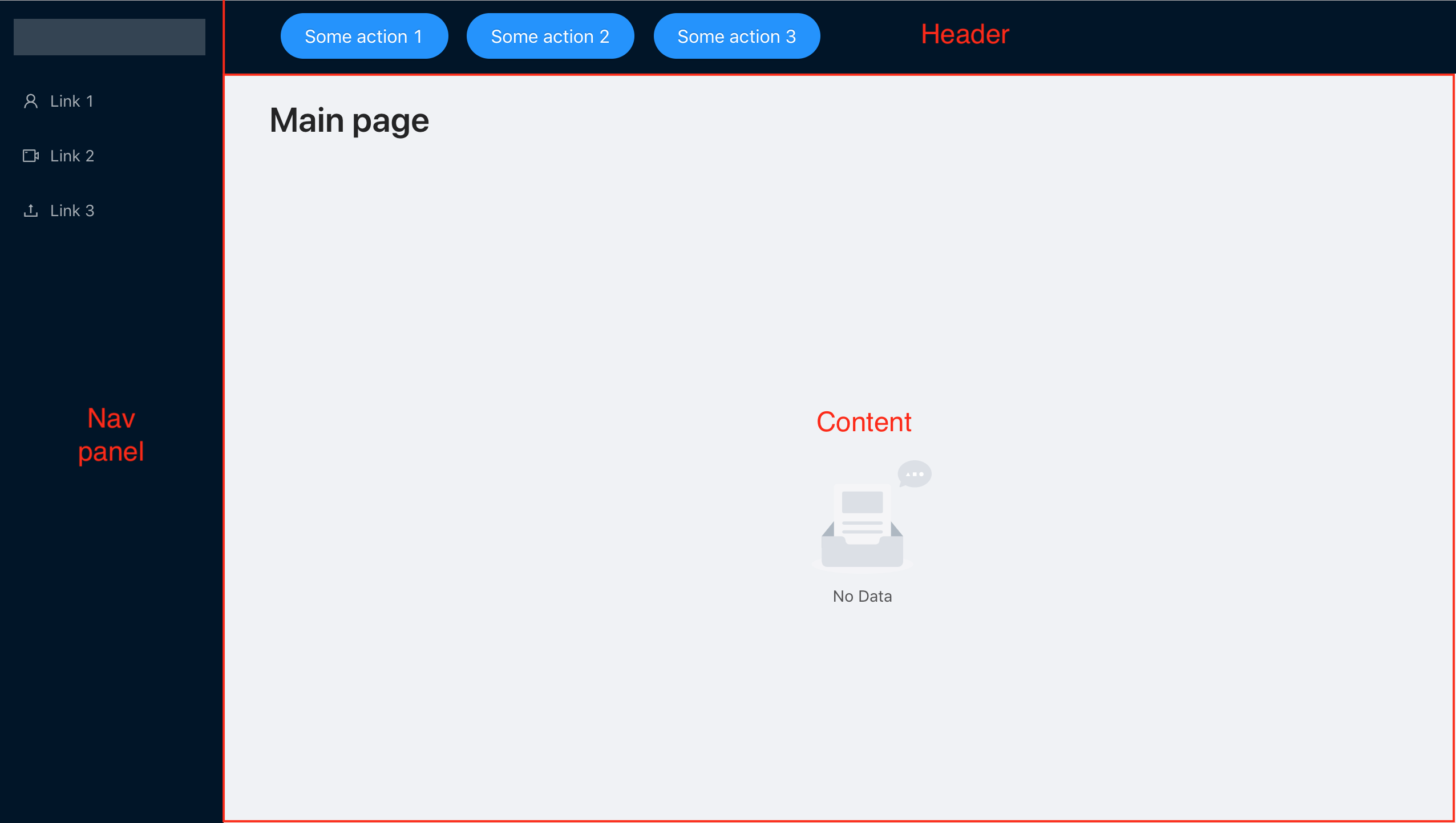
Wir haben ein Navigationsfenster mit 3 Links, von denen jeder zu voneinander unabhängigen Komponenten führt. Daher möchten wir ein solches Verhalten erzielen, dass wir auch dann mit den anderen Komponenten weiterarbeiten können, wenn eine der Komponenten nicht funktioniert.
Infolgedessen haben wir für jede Komponente eine Fehlergrenze, auf die über das Navigationsmenü und die allgemeine Fehlergrenze zugegriffen werden kann, die über den Absturz der gesamten Anwendung informiert, falls ein Fehler in der Kopfzeilenkomponente, im Navigationsbereich oder in ErrorBoundary aufgetreten ist, der jedoch nicht behoben wurde weiter verarbeiten und verwerfen.
Erwägen Sie, eine gesamte Anwendung aufzulisten, die in ErrorBoundary eingeschlossen ist
const AppWithBoundary = () => ( <ErrorBoundary errorMessage="Application has crashed"> <App/> </ErrorBoundary> )
function App() { return ( <Router> <Layout> <Sider width={200}> <SideNavigation /> </Sider> <Layout> <Header> <ActionPanel /> </Header> <Content> <Switch> <Route path="/link1"> <Page1 title="Link 1 content page" errorMessage="Page for link 1 crashed" /> </Route> <Route path="/link2"> <Page2 title="Link 2 content page" errorMessage="Page for link 2 crashed" /> </Route> <Route path="/link3"> <Page3 title="Link 3 content page" errorMessage="Page for link 3 crashed" /> </Route> <Route path="/"> <MainPage title="Main page" errorMessage="Only main page crashed" /> </Route> </Switch> </Content> </Layout> </Layout> </Router> ); }
In ErrorBoundary gibt es keine Magie, es ist nur eine Klassenkomponente, in der die componentDidCatch-Methode definiert ist. Das heißt, jede Komponente kann zu ErrorBoundary gemacht werden, wenn Sie diese Methode darin definieren.
class ErrorBoundary extends React.Component { state = { hasError: false, } componentDidCatch(error) {
So sieht ErrorBoundary für die Page-Komponente aus, die in den Content-Block gerendert wird:
const PageBody = ({ title }) => ( <Content title={title}> <Empty className="content-empty" /> </Content> ); const MainPage = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary>
Da ErrorBoundary eine reguläre React-Komponente ist, können wir dieselbe ErrorBoundary-Komponente verwenden, um jede Seite in einen eigenen Handler einzubinden. Dabei werden einfach verschiedene Parameter an ErrorBoundary übergeben, da es sich um verschiedene Instanzen der Klasse handelt, deren Status nicht voneinander abhängt .
WICHTIG: ErrorBoundary kann Fehler nur in Komponenten abfangen, die sich im Baum darunter befinden.In der folgenden Auflistung wird der Fehler nicht von der lokalen ErrorBoundary abgefangen, sondern vom Handler über der Struktur ausgelöst und abgefangen:
const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> {null.toString()} </ErrorBoundary> );
Und hier wird der Fehler von der lokalen ErrorBoundary abgefangen:
const ErrorProneComponent = () => null.toString(); const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> <ErrorProneComponent /> </ErrorBoundary> );
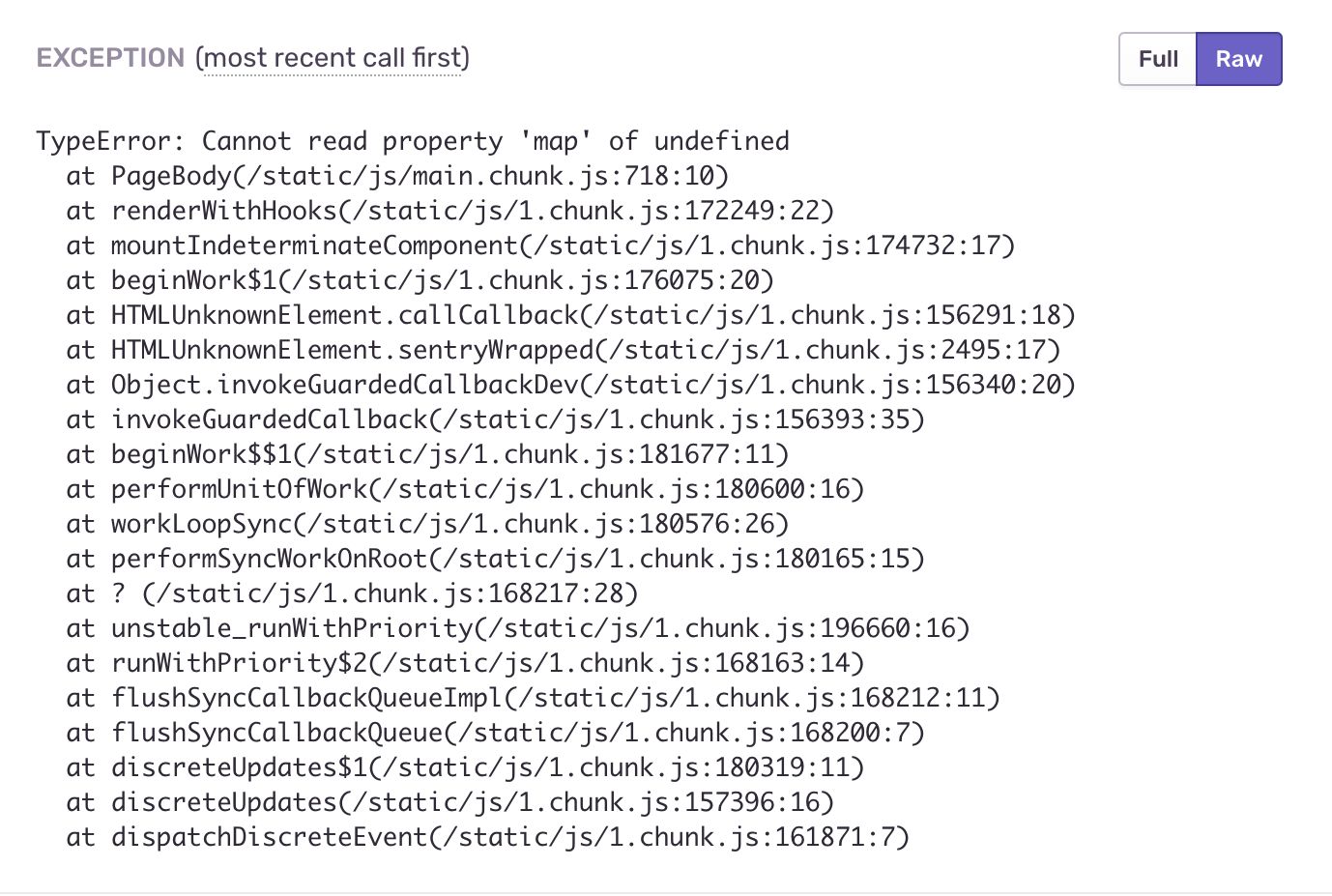
Nachdem wir jede einzelne Komponente in unsere ErrorBoundary eingeschlossen haben, haben wir das erforderliche Verhalten erreicht, den absichtlich fehlerhaften Code mit link3 in die Komponente eingefügt und gesehen, was passiert. Wir haben absichtlich vergessen, den Parameter steps zu übergeben:
const PageBody = ({ title, steps }) => ( <Content title={title}> <Steps current={2} direction="vertical"> {steps.map(({ title, description }) => (<Step title={title} description={description} />))} </Steps> </Content> ); const Page = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary> );
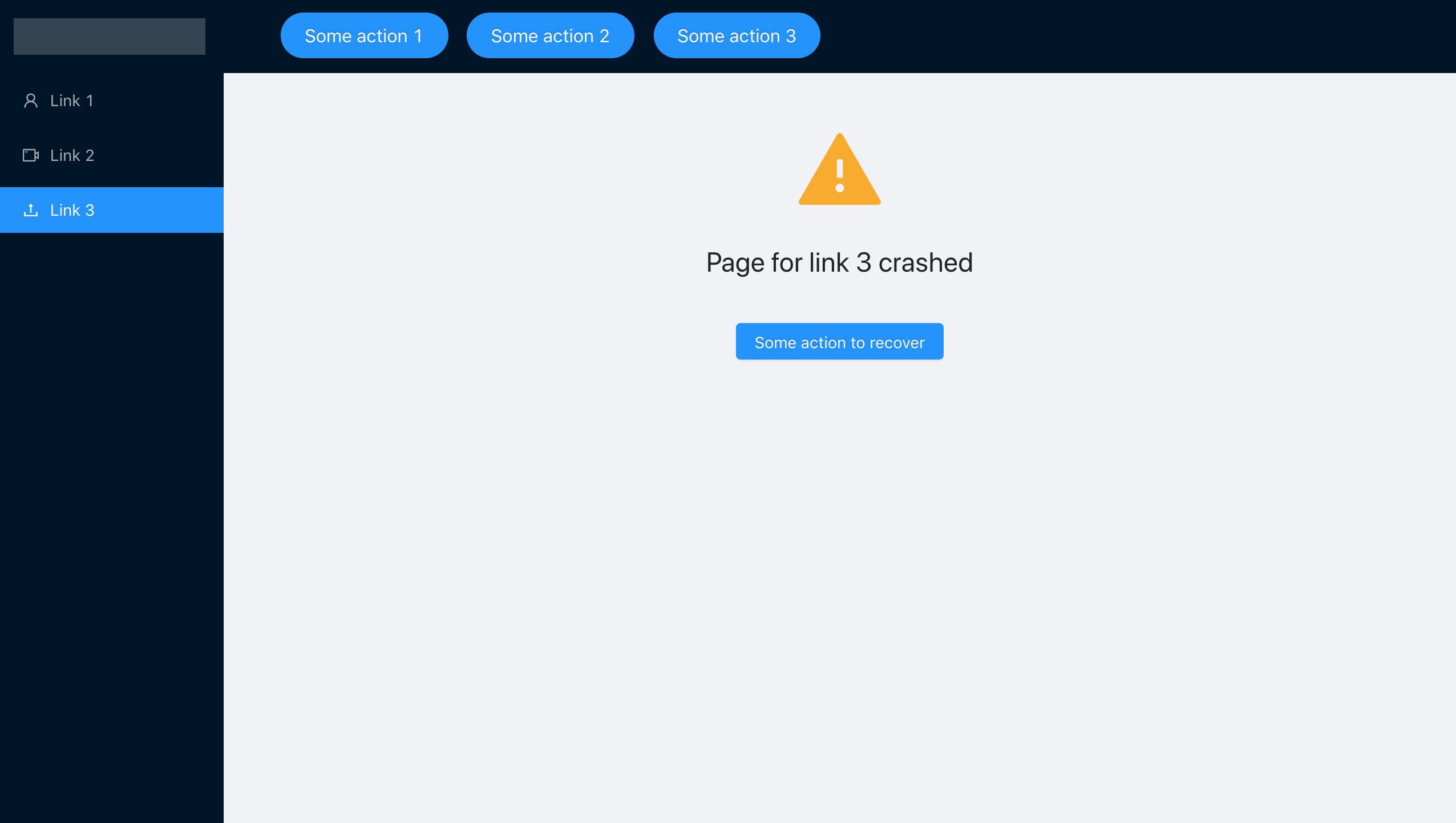
Die Anwendung teilt uns mit, dass ein Fehler aufgetreten ist, der jedoch nicht vollständig abfällt. Wir können durch das Navigationsmenü navigieren und mit anderen Abschnitten arbeiten.
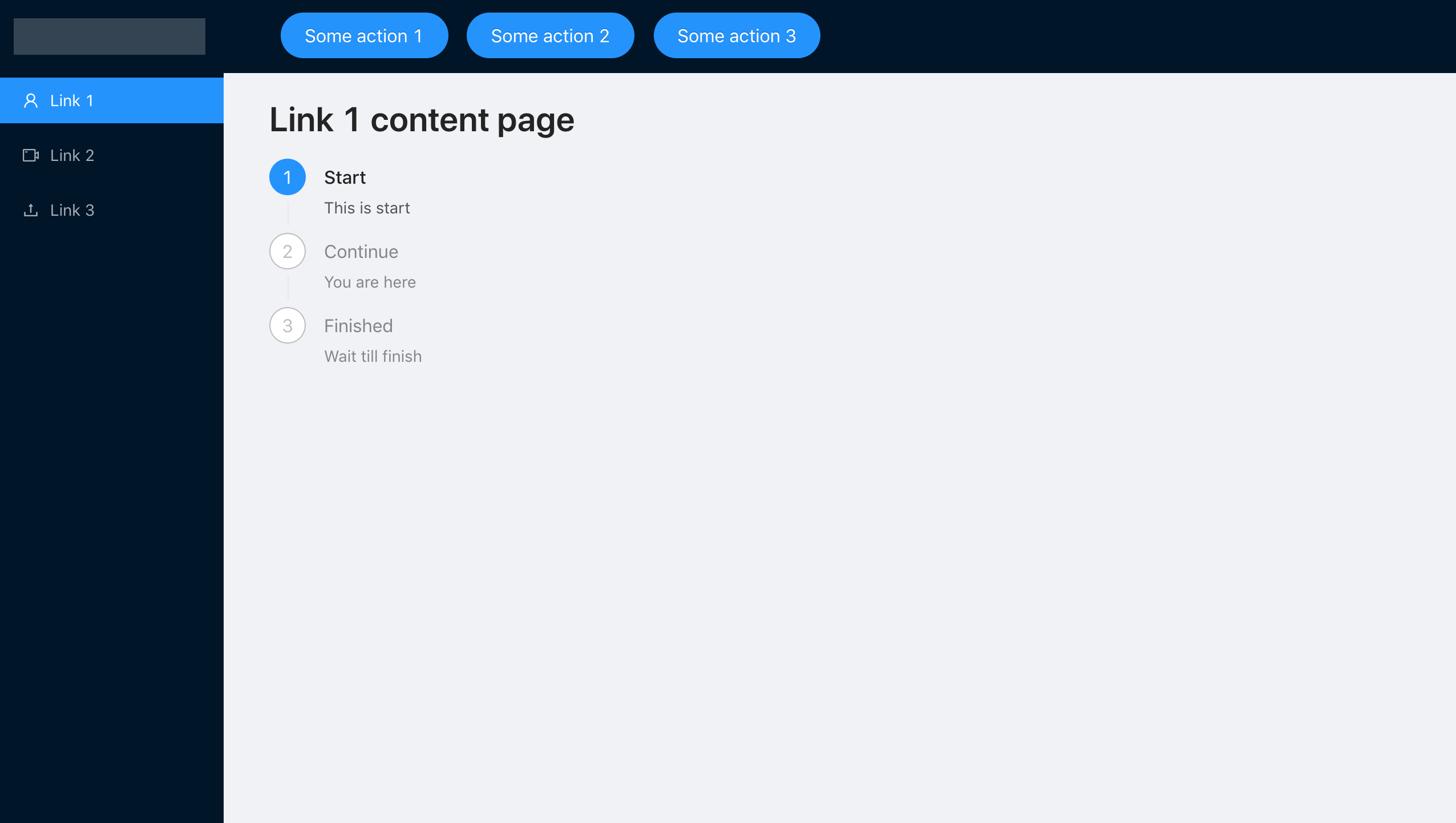
Mit einer solch einfachen Konfiguration können wir unser Ziel problemlos erreichen, aber in der Praxis widmen nur wenige Personen der Fehlerbehandlung viel Aufmerksamkeit und planen nur die regelmäßige Ausführung der Anwendung.
Fehlerinformationen werden gespeichertNachdem wir genügend ErrorBoundary in unserer Anwendung platziert haben, müssen Informationen zu Fehlern gespeichert werden, um sie so schnell wie möglich zu erkennen und zu korrigieren. Am einfachsten ist es, SaaS-Dienste wie Sentry oder Rollbar zu verwenden. Sie verfügen über eine sehr ähnliche Funktionalität, sodass Sie jeden Fehlerüberwachungsdienst verwenden können.
Ich werde ein grundlegendes Beispiel für Sentry zeigen, da Sie in nur einer Minute nur minimale Funktionalität erhalten. Gleichzeitig erkennt Sentry selbst Ausnahmen und ändert sogar console.log, um alle Fehlerinformationen abzurufen. Danach werden alle Fehler, die in der Anwendung auftreten, gesendet und auf dem Server gespeichert. Sentry verfügt über Mechanismen zum Filtern von Ereignissen, Verschleiern persönlicher Daten, Verknüpfen mit Veröffentlichungen und vielem mehr. Wir werden nur das grundlegende Integrationsszenario betrachten.
Um eine Verbindung herzustellen, müssen Sie sich auf der offiziellen Website registrieren und die Schnellstartanleitung durchgehen, die Sie sofort nach der Registrierung weiterleitet.
In unserer Anwendung fügen wir nur ein paar Zeilen hinzu und alles hebt ab.
import * as Sentry from '@sentry/browser'; Sentry.init({dsn: “https:
Klicken Sie erneut auf den Link / Link3 in unserer Anwendung und rufen Sie den Fehlerbildschirm auf. Anschließend rufen wir die Sentry-Oberfläche auf. Anscheinend ist ein Ereignis aufgetreten und schlägt im Inneren fehl.
Fehler werden automatisch nach Art, Häufigkeit und Zeitpunkt des Auftretens gruppiert, verschiedene Filter können angewendet werden. Wir haben ein Ereignis - wir fallen hinein und auf dem nächsten Bildschirm sehen wir eine Reihe nützlicher Informationen, zum Beispiel Stack-Trace

und die letzte Benutzeraktion vor dem Fehler (Breadcrumbs).
Selbst mit einer so einfachen Konfiguration können wir Fehlerinformationen sammeln, analysieren und für die weitere Fehlersuche verwenden. In diesem Beispiel wird vom Client im Entwicklungsmodus ein Fehler gesendet, sodass wir die vollständigen Informationen über die Komponente und die Fehler beobachten können. Um ähnliche Informationen aus dem Produktionsmodus zu erhalten, müssen Sie zusätzlich die Synchronisierung der Versionsdaten mit Sentry konfigurieren, in der die Quellkarte in sich selbst gespeichert wird. Auf diese Weise können Sie genügend Informationen speichern, ohne die Größe des Bundles zu erhöhen. Wir werden eine solche Konfiguration im Rahmen dieses Artikels nicht betrachten, aber ich werde versuchen, in einem separaten Artikel über die Fallstricke einer solchen Lösung nach ihrer Implementierung zu sprechen.
Das ergebnis:Die Fehlerbehandlung mit ErrorBoundary ermöglicht es uns, Ecken mit einem teilweisen Absturz der Anwendung auszugleichen, wodurch die Benutzerfreundlichkeit des Systems erhöht wird, und spezielle Fehlerüberwachungssysteme zu verwenden, um die Zeit für die Erkennung und das Debuggen von Problemen zu verkürzen.
Überlegen Sie sorgfältig, wie Sie die Fehler Ihrer Bewerbung verarbeiten und überwachen sollen. Dies erspart Ihnen in Zukunft viel Zeit und Mühe.
Eine durchdachte Strategie verbessert in erster Linie den Prozess der Bearbeitung von Vorfällen und wirkt sich erst dann auf die Struktur des Codes aus.PS Sie können verschiedene ErrorBoundary-Konfigurationsoptionen ausprobieren oder Sentry im Zweig feature_sentry selbst mit der Anwendung verbinden und die Schlüssel durch die Schlüssel ersetzen, die Sie bei der Registrierung auf der Site erhalten haben.
Git-Hub Demo-AnwendungReacts offizielle Dokumentation zur Fehlergrenze