
Analysten zufolge wird der Markt für Rechenzentren in den kommenden Jahren um 38% pro Jahr wachsen und über einen Zeitraum von fünf Jahren auf 35 Mrd. USD anwachsen. Die ressourcenintensivste Nische (gemessen an der Rechenintensität) sind Deep Learning, neuronale Netzwerke und KI-Aufgaben.
Natürlich wird Intel nicht gleichgültig sein, wie Nvidia (und in geringerem Maße AMD) mit seinen GPUs diesen Markt erobern, einschließlich des am schnellsten wachsenden Sektors. Letzte Woche hat der Riese der Mikroelektronikbranche mehrere hochkarätige Ankündigungen auf einmal gemacht:
Aurora-Computermodule
Auf diesen CPUs, GPUs und einer API werden sie Aurora-Computermodule für den namensgebenden Supercomputer mit einem Leistungsniveau von 1 Exaflop (10 ^ 18 Operationen pro Sekunde) zusammenstellen. Es wird davon ausgegangen, dass diese Maschine im Argonne National Laboratory des US-Energieministeriums installiert wird.

Jedes Computermodul verfügt über zwei Sapphire Rapids-Prozessoren und sechs GPUs, die über den CXL-Bus verbunden sind.

Nach
Schätzungen von
AnandTech passen in einem System mit 200 Racks, wie angegeben, ungefähr 2400 Aurora-Knoten mit zwei Einheiten, wenn Sie die Reserve für das Netzwerk und die Laufwerke abziehen. Das sind insgesamt rund 5.000 Sapphire Rapids-Prozessoren und 15.000 Ponte Vecchio. Teilen wir die deklarierte Leistung von 1 Exaflops durch die Anzahl der GPUs, so ergeben sich ca. 66,6 Teraflops pro GPU. Unter der Annahme einer CPU-Leistung von 14 Teraflops erhalten wir weiterhin etwa 50 Teraflops, was einer Verfünffachung der GPU-Leistung in Rechenzentren bis 2021 entspricht.
Natürlich sind die Pläne nicht auf einen Supercomputer für das Energieministerium beschränkt. Intel gab bekannt, dass Lenovo und Atos bereits die Freigabe von Serverplattformen vorbereiten, die auf der Xeon-CPU, der Xe-GPU und OneAPI basieren. Somit finden Aurora-Computermodule in irgendeiner Form Anwendung in anderen Rechenzentren.
Der Supercomputer soll im Jahr 2021 gestartet werden. Gleichzeitig sollen 7-Nanometer-Xe-GPUs auf den Markt kommen.
Laut Intel konvergieren jetzt herkömmliche Hochleistungslösungen (HPC) mit der KI und gehen auf Workloads über, bei denen Deep Learning zum Einsatz kommt. HPC, AI und Analytics sind die drei Hauptauslastungen, die den Bedarf an Computerressourcen erhöhen: „Eine solche Vielfalt von Computeranforderungen fördert heterogenes Computing.
Sagte Rajeeb Hazra, Vizepräsident und General Manager von Intel Enterprise and Government. - Universallösungen sind hier nicht mehr geeignet. In dieser Ära der Konvergenz sollten Sie sich Architekturen ansehen, die auf die unterschiedlichen Anforderungen verschiedener Arten von Workloads abgestimmt sind. “
GPU für Rechenzentren

Ponte Vecchio ist die erste GPU der neuen X
e- Architektur. Die Architektur selbst wird in verschiedenen Segmenten zur Basis für die GPU:
- Hochleistungsrechnen;
- tiefes Lernen;
- Cloud Computing
- Grafik;
- Transcodierung von Medien;
- Arbeitsstationen
- Spielecomputer;
- normale Desktop-PCs;
- mobile und ultramobile Geräte.

Laut Ari Rauch, Vice President für Architektur, Grafik und Software bei Intel, wird eine GPU-Architektur Entwicklern ein „gemeinsames Framework“ bieten. Im Rahmen dieser Architektur entwickelt das Unternehmen jedoch „viele Mikroarchitekturen, die für jede einzelne die effizienteste Leistung bieten“. diese Arbeitsbelastung. "
Die Ponte Vecchio GPU basiert auf der X
e- Mikroarchitektur, die speziell für HPC und AI entwickelt wurde. Zu den Merkmalen der Mikroarchitektur gehört eine flexible Parallelmatrix-Engine mit Vektormatrizen, ein hoher Durchsatz von Gleitkommaberechnungen mit doppelter Genauigkeit (FP64) und ein ultrahoher Durchsatz von Cache und Speicher. Für die Formate INT8, Bfloat16 und FP32 wird es eine separate Matrix-Engine für die parallele Verarbeitung von Matrizen geben (möglicherweise ein Analogon von TensorCore), und für FP64 wird die Beschleunigung für jede Recheneinheit bis zu 40-fach sein.
„Diese Arbeitslast erfordert eine hohe Rechenleistung. Daher haben wir uns darauf konzentriert, eine große Anzahl von Vektor- und Matrixmodulen sowie Parallel-Computing hinzuzufügen, die für diese Arbeitslast angepasst und optimiert sind“, sagte Rauch.
Ponte Vecchio wird die erste GPU der neuen Generation sein. Es implementiert mehrere neue Technologien, die Intel in den letzten Jahren entwickelt hat:
- Produktionsprozess 7 nm;
- geschichtetes Layout von integrierten Foveros 3D-Schaltkreisen;
- EMIB (Embedded Multi-Die Interconnect Bridge) zum Verbinden mehrerer Kristalle auf einem Substrat;
- X e Link zum neuen CXL-Verbindungsstandard (basierend auf PCI Express 5.0) - Zugriff auf die GPU über einen einzigen Speicherplatz.

 Layered Foveros 3D Integrated Circuits aus der Präsentation von Intel im Dezember 2018
Layered Foveros 3D Integrated Circuits aus der Präsentation von Intel im Dezember 2018Technische Daten des Chips wurden noch nicht bekannt gegeben. Sie sagen, dass in diesen GPUs Tausende von Executive Units über XEMF (XE Memory Fabric) mit Speicher und Cache verbunden sein werden.

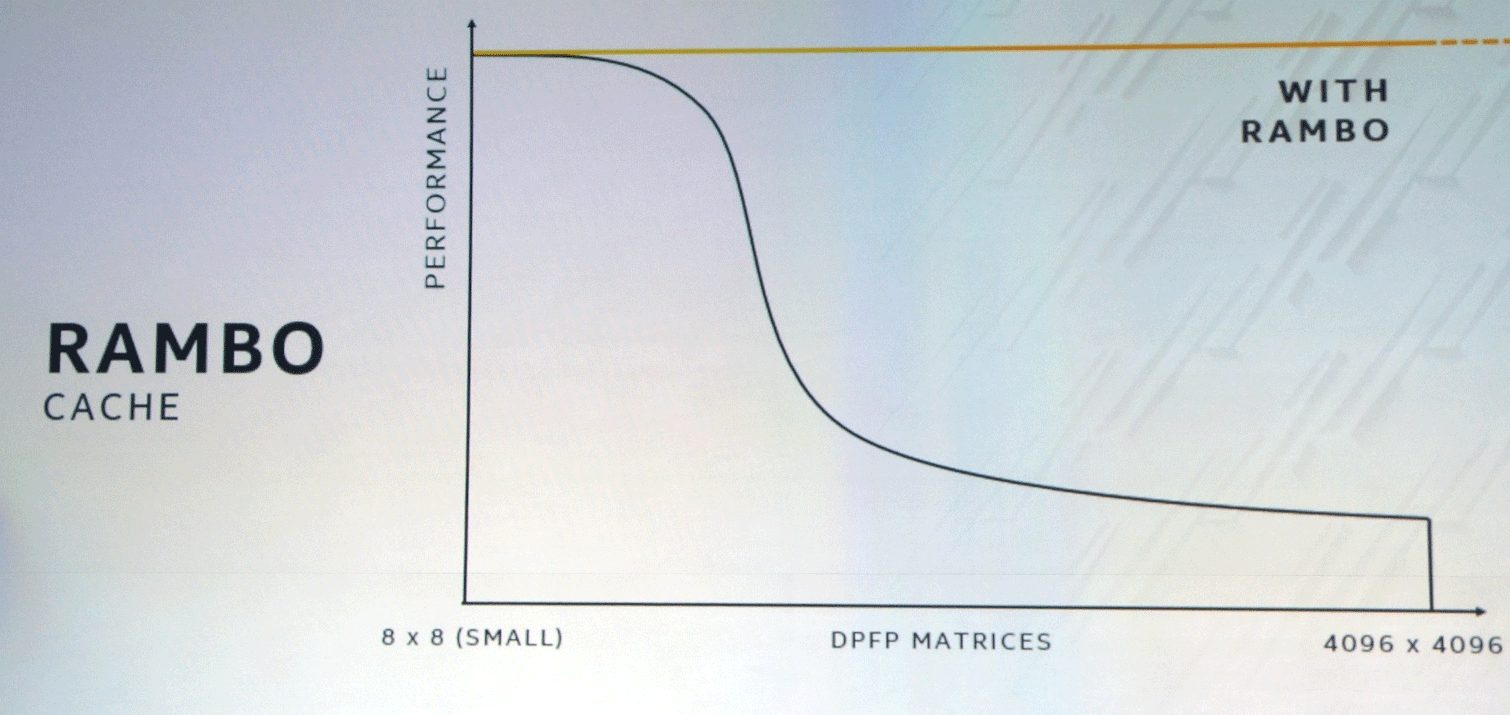
Der XEMF-Bus arbeitet mit dem speziellen ultraschnellen Rambo Cache-Cache, um den Engpass beim Speicherzugriff zu beseitigen. Dieser Cache ist über Foveros mit Rechnereinheiten verbunden, und EMIB wird zum Verbinden des HBM-Speichers verwendet.
Die Kombination aus GPU- und CPU-spezifischen SIMT- und SIMD-Ansätzen und Vektoranweisungen variabler Länge führt in einigen Problemklassen zu einer deutlichen Leistungssteigerung.

Viele erwarten, dass Intel auf dem Markt für Rechenzentren und KI mit Nvidia und AMD konkurrieren wird. Hierbei geht es nicht nur um den Preiswettbewerb, sondern auch um die Entstehung alternativer technologischer Plattformen, die den gesamten technologischen Fortschritt vorantreiben werden.
OneAPI: Abstraktionsscheitelpunkt für heterogenes Eisen
Zusätzlich zur Ankündigung neuer Geräte hat Intel eine Beta-Version von oneAPI-Unified-Software-Interfaces veröffentlicht. Sie sollen Entwicklern die Arbeit erleichtern, die traditionell mit Middleware und Frameworks zwischen verschiedenen Programmiersprachen und Bibliotheken wechseln mussten, um ihre Programme optimal zu optimieren.
Standardmäßig wird in der Branche akzeptiert, dass auf niedriger Ebene für jede Architektur ein anderer Code vorbereitet werden muss. Beispielsweise wurde TensorFlow zum Zeitpunkt der Veröffentlichung zunächst vollständig für die GPU eines Herstellers (für Nvidia CUDA) optimiert.
"OneAPI versucht, diese Probleme zu lösen, indem es eine gemeinsame Low-Level-Schnittstelle für heterogene Hardware mit kompromissloser Leistung anbietet", sagte Bill Savage, Vice President der Abteilung Architektur, Grafik und Software von Intel. "Damit Entwickler Programme direkt auf Hardware über Sprachen und Bibliotheken schreiben können, die für verschiedene Architekturen und Anbieter gleich sind, sowie sicherstellen können, dass Middleware und Frameworks auf einer einzigen API funktionieren und für Entwickler, die an der Spitze dieser Abstraktion stehen, vollständig optimiert sind."
Intel wirbt für oneAPI als "offenen Standard zur Unterstützung der Community und der Branche", der die "Wiederverwendung von Code über Architekturen und Hardware verschiedener Hersteller hinweg" ermöglicht.
Die oneAPI-Spezifikation wird die standardmäßige architekturübergreifende DPC ++ - Programmiersprache enthalten, die auf C ++ und SYCL basiert, sowie "leistungsstarke APIs zur Beschleunigung der wichtigsten domänenspezifischen Funktionen".
Zusätzlich zum DPC ++ - Compiler und zur API-Bibliothek werden spezielle Tools veröffentlicht, darunter VTune Inspector Advisor, ein Debugger und ein "Kompatibilitätstool" für die Portierung von CUDA-Code (Nvidia) nach DPC ++.
Um die Umstellung auf OneAPI zu beschleunigen, hat Intel eine Sandbox in
DevCloud gestartet , um Programme auf einer Reihe von CPUs, GPUs und FPGAs zu entwickeln und zu testen. Für die Arbeit mit der Sandbox ist keine Installation von Hardware oder Software erforderlich.
In der Zwischenzeit stieg der Umsatz von Nvidia im Quartal
auf 3 Milliarden US-Dollar , während das Wachstum auf dem Markt für Rechenzentren in den drei Monaten 11% betrug (726 Millionen US-Dollar). Verkäufe von V100- und T4-Prozessoren brechen alle Rekorde. Intel betrachtet es immer noch von außen, aber wir wissen bereits, wie die Antwort aussehen wird. Das interessanteste ist erst am Anfang.