 Das CS-1-Computerdiagramm zeigt, dass das meiste der Stromversorgung und Kühlung der riesigen Wafer-Scale-Engine (WSE) auf der Platte gewidmet ist. Foto: Cerebras-Systeme
Das CS-1-Computerdiagramm zeigt, dass das meiste der Stromversorgung und Kühlung der riesigen Wafer-Scale-Engine (WSE) auf der Platte gewidmet ist. Foto: Cerebras-SystemeIm August 2019 gaben Cerebras Systems und sein Herstellungspartner TSMC den
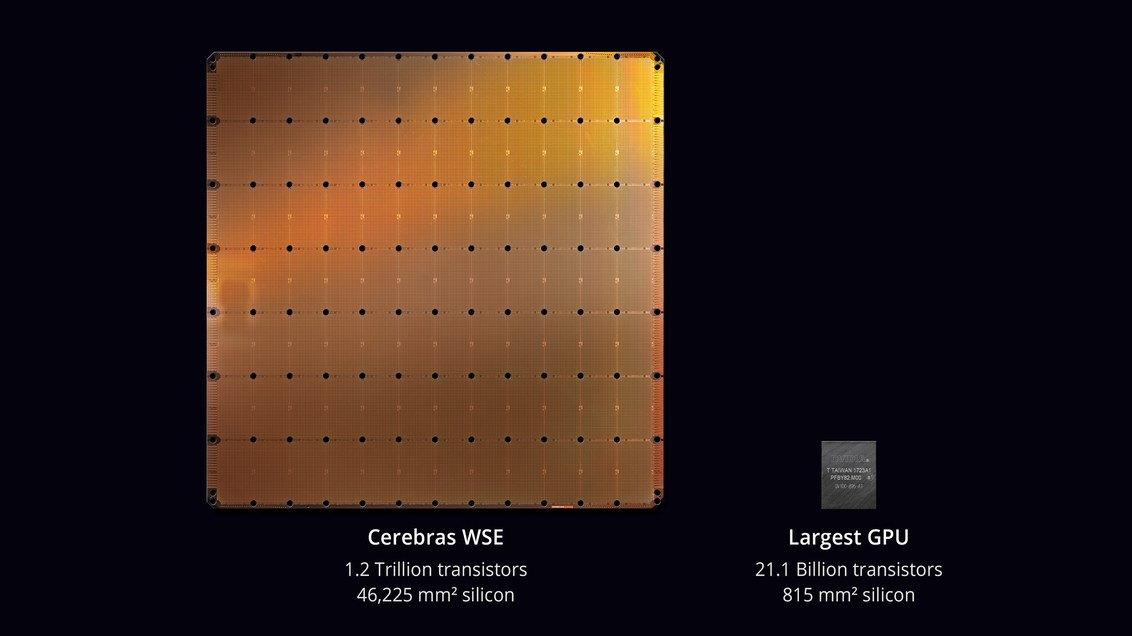
größten Chip in der Geschichte der Computertechnologie bekannt . Mit einer Fläche von 46.225 mm² und 1,2 Billionen Transistoren ist der WSE-Chip (Wafer Scale Engine) ungefähr 56,7-mal größer als die größte GPU (21,1 Milliarden Transistoren, 815 mm²).
Skeptiker sagten, dass die Entwicklung eines Prozessors nicht die schwierigste Aufgabe sei. Aber wie funktioniert das in einem echten Computer? Wie hoch ist der Prozentsatz fehlerhafter Arbeiten? Welche Leistung und Kühlung wird benötigt? Wie viel kostet eine solche Maschine?
Es scheint, dass die Ingenieure von Cerebras Systems und TSMC diese Probleme lösen konnten. Am 18. November 2019 stellten sie auf der
Supercomputing- Konferenz
2019 offiziell den
CS-1 vor , "den weltweit schnellsten Computer für das Rechnen auf dem Gebiet des maschinellen Lernens und der künstlichen Intelligenz".
Die ersten Exemplare von CS-1 wurden bereits an Kunden gesendet. Eine davon wird im Argonne National Laboratory des US-Energieministeriums installiert, in dem mit der Montage des leistungsstärksten Supercomputers der USA aus
Aurora-Modulen auf der neuen Intel-GPU-Architektur begonnen wird. Ein weiterer Kunde war das Livermore National Laboratory.
Der Prozessor mit 400.000 Kernen ist für Rechenzentren zur Verarbeitung von Daten im Bereich des maschinellen Lernens und der künstlichen Intelligenz ausgelegt. Cerebras behauptet, dass der Computer KI-Systeme um Größenordnungen effizienter trainiert als vorhandene Geräte. Leistung CS-1 entspricht „Hunderten von GPU-basierten Servern“, die Hunderte von Kilowatt verbrauchen. Gleichzeitig belegt es nur 15 Einheiten im Server-Rack und verbraucht etwa 17 kW.
 WSE-Prozessor. Foto: Cerebras-Systeme
WSE-Prozessor. Foto: Cerebras-SystemeAndrew Feldman, CEO und Mitbegründer von Cerebras Systems, sagt, der CS-1 sei "der schnellste KI-Computer der Welt". Er verglich es mit Googles TPU-Clustern und stellte fest, dass jeder von ihnen „10 Racks benötigt und mehr als 100 Kilowatt verbraucht, um ein Drittel der Leistung einer einzelnen CS-1-Installation zu erbringen“.
 Computer CS-1. Foto: Cerebras-Systeme
Computer CS-1. Foto: Cerebras-SystemeDas Erlernen großer neuronaler Netze kann auf einem Standardcomputer Wochen dauern. Die Installation eines CS-1 mit einem Prozessorchip mit 400.000 Kernen und 1,2 Billionen Transistoren erledigt diese Aufgabe in Minuten oder sogar Sekunden,
schreibt IEEE Spectrum. Cerebras lieferte jedoch keine echten Testergebnisse zum Testen von Hochleistungsaussagen wie
MLPerf-Tests . Stattdessen knüpfte das Unternehmen direkt Kontakte zu potenziellen Kunden - und durfte eigene Modelle neuronaler Netze auf CS-1 trainieren.
Dieser Ansatz ist nicht ungewöhnlich, sagen Analysten: „Jeder verwaltet seine eigenen Modelle, die er für sein eigenes Unternehmen entwickelt hat“, sagte
Karl Freund , Analyst für künstliche Intelligenz bei Moor Insights & Strategies. "Dies ist das einzige, was für Kunden wichtig ist."
Viele Unternehmen entwickeln spezielle Chips für KI, darunter Vertreter der traditionellen Industrie wie Intel, Qualcomm sowie verschiedene Startups in den USA, Großbritannien und China. Google hat einen Chip speziell für neuronale Netze entwickelt - einen Tensor-Prozessor oder TPU. Mehrere andere Hersteller folgten diesem Beispiel. KI-Systeme arbeiten im Multithread-Modus, und der Engpass verschiebt Daten zwischen den Chips: „Das Anschließen der Chips verlangsamt sie tatsächlich und erfordert viel Energie“,
erklärt Subramanian Iyer, Professor an der University of California in Los Angeles, der sich darauf spezialisiert hat Entwicklung von Chips für künstliche Intelligenz. Gerätehersteller prüfen viele verschiedene Optionen. Einige versuchen, Interprozessverbindungen zu erweitern.
Das vor drei Jahren gegründete Unternehmen Cerebras, das mehr als 200 Millionen US-Dollar an Risikofinanzierungen erhalten hat, hat einen neuen Ansatz vorgeschlagen. Die Idee ist, alle Daten auf einem riesigen Chip zu speichern - und damit die Berechnungen zu beschleunigen.

Die gesamte Mikroschaltungsplatte ist in 400.000 kleinere Abschnitte (Kerne) unterteilt, da einige davon nicht funktionieren. Der Chip ist so konstruiert, dass er fehlerhafte Bereiche umfahren kann. Programmierbare SLAC-Kerne (Sparse Linear Algebra Cores) sind für lineare Algebra, dh für Berechnungen im Vektorraum, optimiert. Das Unternehmen hat auch die Sparsity Harvesting-Technologie entwickelt, um die Rechenleistung unter spärlichen Workloads (mit Nullen) wie Deep Learning zu verbessern. Vektoren und Matrizen im Vektorraum enthalten normalerweise viele Nullelemente (von 50% bis 98%), sodass bei herkömmlichen GPUs der größte Teil der Berechnung verschwendet wird. Im Gegensatz dazu filtern SLAC-Kerne Nulldaten vor.
Die Kommunikation zwischen den Kernen wird vom Swarm-System mit einem Durchsatz von 100 Petabits pro Sekunde bereitgestellt. Hardware-Routing, Latenz gemessen in Nanosekunden.
Die Kosten für einen Computer werden nicht genannt. Unabhängige Experten glauben, dass der tatsächliche Preis vom Prozentsatz der Ehe abhängt. Außerdem sind die Leistung des Chips und die Anzahl der in realen Proben betriebenen Kerne nicht zuverlässig bekannt.
Software
Cerebras hat einige Details zum Softwareteil des CS-1-Systems bekannt gegeben. Mit der Software können Benutzer ihre eigenen Modelle für maschinelles Lernen mit Standard-Frameworks wie
PyTorch und
TensorFlow erstellen . Das System verteilt dann 400.000 Kerne und 18 Gigabyte SRAM-Speicher auf dem Chip auf die Schichten des neuronalen Netzwerks, so dass alle Schichten ihre Arbeit ungefähr zur gleichen Zeit wie ihre Nachbarn abschließen (Optimierungsaufgabe). Infolgedessen werden Informationen von allen Schichten ohne Verzögerung verarbeitet. Mit einem 100-Gigabit-Ethernet-E / A-Subsystem mit 12 Ports kann der CS-1 1,2 Terabit Daten pro Sekunde verarbeiten.
Die Konvertierung des neuronalen Quellnetzwerks in eine optimierte ausführbare Darstellung (Cerebras Linear Algebra Intermediate Representation, CLAIR) erfolgt durch den Cerebras Graph Compiler (CGC). Der Compiler weist jedem Teil des Diagramms Rechenressourcen und Speicher zu und vergleicht sie dann mit dem Rechenarray. Dann wird der Kommunikationspfad gemäß der internen Struktur der Platte berechnet, die für jedes Netzwerk eindeutig ist.
 Verteilung der mathematischen Operationen eines neuronalen Netzwerks durch Prozessorkerne. Foto : Großhirn
Verteilung der mathematischen Operationen eines neuronalen Netzwerks durch Prozessorkerne. Foto : GroßhirnAufgrund der enormen Größe von WSE befinden sich alle Schichten in einem neuronalen Netzwerk gleichzeitig darauf und arbeiten parallel. Dieser Ansatz ist einzigartig für WSE - laut Cerebras verfügt kein anderes Gerät über genügend internen Speicher, um alle Schichten auf einem Chip gleichzeitig zu speichern. Eine solche Architektur mit der Platzierung des gesamten neuronalen Netzwerks auf einem Chip bietet aufgrund des hohen Durchsatzes und der geringen Latenz große Vorteile.
Die Software kann die Optimierungsaufgabe für mehrere Computer ausführen, sodass der Computercluster als eine große Maschine fungieren kann. Ein Cluster von 32 CS-1-Computern weist eine etwa 32-fache Leistungssteigerung auf, was auf eine sehr gute Skalierbarkeit hinweist. Laut Feldman unterscheidet sich dies von GPU-basierten Clustern: „Heute verhält sich ein GPU-Cluster nicht mehr wie ein einziger großer Computer. Du bekommst viele kleine Autos. “
In der
Pressemitteilung heißt es, dass das Argonne National Laboratory seit zwei Jahren mit Cerebras zusammenarbeitet: "Durch den Einsatz von CS-1 haben wir die Trainingsgeschwindigkeit für neuronale Netze drastisch erhöht, wodurch wir die Produktivität unserer Forschung steigern und signifikante Erfolge erzielen konnten."
Eine der ersten Lasten für CS-1 wird eine
neuronale Netzwerksimulation einer Kollision von Schwarzen Löchern und Gravitationswellen sein, die als Ergebnis dieser Kollision erzeugt werden. Die vorherige Version dieser Aufgabe arbeitete an 1024 von 4392 Knoten des
Theta- Supercomputers.