 Basierend auf meinen Auftritten bei Highload ++ und DataFest Minsk 2019
Basierend auf meinen Auftritten bei Highload ++ und DataFest Minsk 2019Für viele ist die Post heute ein wesentlicher Bestandteil des Online-Lebens. Mit ihrer Hilfe führen wir Geschäftskorrespondenz, speichern alle wichtigen Informationen in Bezug auf Finanzen, Hotelreservierungen, Checkout und vieles mehr. Mitte 2018 haben wir eine Produktstrategie für die E-Mail-Entwicklung formuliert. Was soll moderne Post sein?
E-Mails müssen
intelligent sein , dh den Benutzern dabei helfen, auf die zunehmende Menge an Informationen zuzugreifen: Filtern, Strukturieren und Bereitstellen auf die bequemste Weise. Es sollte
nützlich sein , direkt in der Mailbox verschiedene Probleme lösen zu lassen, zum Beispiel Bußgelder zu zahlen (eine Funktion, die ich leider benutze). Gleichzeitig sollte E-Mail natürlich den Schutz von Informationen gewährleisten, indem Spam abgeschnitten und vor Hacks geschützt wird, d. H.
Sicher sein .
Diese Bereiche bestimmen eine Reihe von Schlüsselaufgaben, von denen viele durch maschinelles Lernen effektiv gelöst werden können. Hier finden Sie Beispiele für vorhandene Funktionen, die im Rahmen der Strategie entwickelt wurden - eine für jede Richtung.
- Intelligente Antwort . Es gibt eine intelligente Antwortfunktion in der Mail. Das neuronale Netz analysiert den Text des Buchstabens, versteht seine Bedeutung und seinen Zweck und bietet als Ergebnis die drei am besten geeigneten Antwortoptionen: positiv, negativ und neutral. Dies hilft, beim Beantworten von Briefen Zeit zu sparen, und es macht oftmals auch Spaß, nicht dem Standard zu entsprechen.
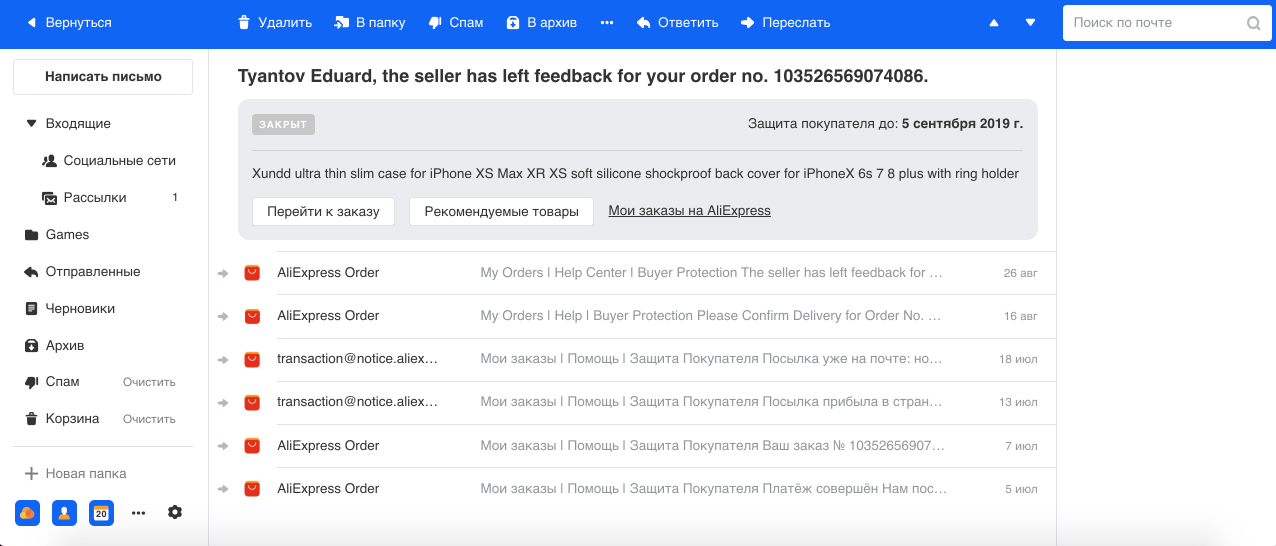
- Gruppierung von Briefen im Zusammenhang mit Bestellungen in Online-Shops. Wir kaufen oft im Internet ein und in der Regel können die Geschäfte für jede Bestellung mehrere Briefe versenden. Zum Beispiel gibt es bei AliExpress, dem größten Dienst, viele Buchstaben für eine Bestellung, und wir haben festgestellt, dass im Terminal-Fall ihre Nummer 29 erreichen kann. Daher wählen wir unter Verwendung des Named-Entity-Recognition-Modells die Bestellnummer und andere Informationen aus dem Text und der Gruppe aus Alle Buchstaben in einem Thread. Wir zeigen auch die grundlegenden Informationen zur Bestellung in einer separaten Box, die die Arbeit mit dieser Art von Briefen erleichtert.
- Antiphishing . Phishing ist eine besonders gefährliche betrügerische Art von E-Mails, mit deren Hilfe Angreifer versuchen, an Finanzinformationen (einschließlich Bankkarten von Benutzern) und Anmeldungen zu gelangen. Solche Briefe ahmen die echten Briefe des Dienstes nach, auch optisch. Daher erkennen wir mithilfe von Computer Vision die Logos und den Stil von Briefen großer Unternehmen (z. B. Mail.ru, Sberbank, Alpha) und berücksichtigen dies zusammen mit Text und anderen Zeichen in unseren Spam- und Phishing-Klassifizierern.
Maschinelles Lernen
Ein wenig über maschinelles Lernen in der Post im Allgemeinen. Mail ist ein stark ausgelastetes System: Auf unseren Servern werden durchschnittlich 1,5 Milliarden Briefe pro Tag an 30 Millionen DAU-Benutzer gesendet. Erfüllen Sie alle erforderlichen Funktionen und Merkmale von ca. 30 maschinellen Lernsystemen.
Jeder Brief durchläuft ein ganzes Klassifizierungsband. Zuerst schneiden wir Spam ab und hinterlassen gute E-Mails. Benutzer bemerken die Wirkung von Anti-Spam häufig nicht, da 95-99% des Spam nicht einmal in den entsprechenden Ordner gelangen. Spam-Erkennung ist ein sehr wichtiger Teil unseres Systems und der schwierigste, da es im Bereich der Spam-Abwehr eine ständige Anpassung zwischen Verteidigungs- und Angriffssystemen gibt, die eine ständige technische Herausforderung für unser Team darstellt.
Als nächstes trennen wir Briefe von Menschen und Robotern. Briefe von Menschen sind am wichtigsten, deshalb stellen wir ihnen Funktionen wie Smart Reply zur Verfügung. Briefe von Robotern gliedern sich in zwei Teile: Transaktionsbriefe - das sind wichtige Briefe von Dienstleistungen, zum Beispiel die Bestätigung von Einkäufen oder Hotelreservierungen, Finanzen und Informationen - dies sind Geschäftswerbung, Rabatte.
Wir glauben, dass Transaktionsbriefe der persönlichen Korrespondenz gleichwertig sind. Sie sollten zur Hand sein, denn oft ist es notwendig, Informationen über die Bestellung oder Buchung eines Tickets schnell zu finden, und wir verbringen viel Zeit damit, nach diesen Briefen zu suchen. Aus praktischen Gründen teilen wir sie automatisch in sechs Hauptkategorien ein: Reisen, Buchungen, Finanzen, Tickets, Registrierungen und schließlich Bußgelder.
Newsletter sind die größte und wahrscheinlich weniger wichtige Gruppe, die keine sofortige Reaktion erfordert, da sich nichts Wesentliches im Leben des Benutzers ändert, wenn er einen solchen Brief nicht liest. In unserer neuen Benutzeroberfläche gliedern wir sie in zwei Threads: soziale Netzwerke und Newsletter. Auf diese Weise wird das Postfach optisch gelöscht und nur wichtige Buchstaben in Sichtweite gelassen.

Bedienung
Eine große Anzahl von Systemen verursacht im Betrieb viele Schwierigkeiten. Schließlich verschlechtern sich Modelle im Laufe der Zeit wie jede andere Software: Zeichen gehen kaputt, Maschinen fallen aus, ein Code rollt herum. Darüber hinaus ändern sich die Daten ständig: Es werden neue Daten hinzugefügt, das Benutzerverhalten wird geändert usw. Daher wird das Modell ohne angemessene Unterstützung mit der Zeit immer schlechter funktionieren.
Wir dürfen nicht vergessen, dass die Auswirkungen auf das Ökosystem umso größer sind, je tiefer maschinelles Lernen in das Leben der Nutzer eindringt und je mehr finanzielle Verluste oder Gewinne die Marktteilnehmer daraus ziehen können. Daher stellen sich die Spieler in immer mehr Bereichen auf die Arbeit mit ML-Algorithmen ein (klassische Beispiele sind Werbung, Suche und der bereits erwähnte Spam-Schutz).
Darüber hinaus haben maschinelle Lernaufgaben eine Besonderheit: Jede, wenn auch unbedeutende, Änderung des Systems kann zu einer Menge Arbeit mit dem Modell führen: Arbeiten mit Daten, Umschulung, Bereitstellung, die sich über Wochen oder Monate hinziehen kann. Je schneller die Umgebung ist, in der Ihre Modelle eingesetzt werden, desto mehr Aufwand erfordert der Support. Ein Team kann viele Systeme erstellen und Spaß daran haben und dann fast alle Ressourcen für den Support aufwenden, ohne etwas Neues tun zu können. Wir sind einmal in einem Anti-Spam-Team auf eine solche Situation gestoßen. Und sie kamen zu dem offensichtlichen Schluss, dass die Wartung automatisiert werden sollte.
Automatisierung
Was kann automatisiert werden? In der Tat fast alles. Ich habe vier Bereiche identifiziert, die die Infrastruktur des maschinellen Lernens definieren:
- Datenerfassung;
- Weiterbildung;
- Bereitstellung;
- Testen & Überwachen.
Wenn die Umgebung instabil ist und sich ständig ändert, ist die gesamte Infrastruktur rund um das Modell viel wichtiger als das Modell selbst. Es mag der gute alte lineare Klassifikator sein, aber wenn Sie die Zeichen richtig anwenden und ein gutes Feedback von den Benutzern erhalten, wird es viel besser funktionieren als State-Of-The-Art-Modelle mit allem Schnickschnack.
Rückkopplungsschleife
Dieser Zyklus kombiniert Datenerfassung, Weiterbildung und Bereitstellung - und zwar den gesamten Aktualisierungszyklus des Modells. Warum ist das wichtig? Schauen Sie sich den Registrierungsplan in der Mail an:

Der Entwickler für maschinelles Lernen hat ein Antibot-Modell eingeführt, das die Registrierung von Bots in der Mail verhindert. Das Diagramm fällt auf einen Wert, bei dem nur echte Benutzer verbleiben. Alles ist ganz toll! Aber vier Stunden vergehen, die Botvods verschärfen ihre Skripte und alles kehrt auf den ersten Platz zurück. In dieser Implementierung hat der Entwickler einen Monat lang Funktionen und ein Schulungsmodell hinzugefügt, aber der Spammer konnte sich in vier Stunden anpassen.
Um nicht so schmerzhaft zu sein und später nicht alles wiederholen zu müssen, müssen wir uns zunächst überlegen, wie die Rückkopplungsschleife aussehen wird und was wir tun werden, wenn sich die Umgebung ändert. Beginnen wir mit der Datenerfassung - dies ist der Treibstoff für unsere Algorithmen.
Datenerfassung
Es ist klar, dass moderne neuronale Netze, je mehr Daten, desto besser sind und tatsächlich Benutzer des Produkts generieren. Benutzer können uns helfen, indem sie die Daten markieren. Sie können sie jedoch nicht missbrauchen, da Benutzer die Fertigstellung ihrer Modelle irgendwann satt haben und zu einem anderen Produkt wechseln.
Einer der häufigsten Fehler (hier beziehe ich mich auf Andrew Ng) ist, dass die Ausrichtung auf die Metriken im Testdatensatz zu stark ist und nicht auf das Feedback des Benutzers, das eigentlich das Hauptmaß für die Qualität der Arbeit ist, wenn wir ein Produkt für den Benutzer erstellen. Wenn der Benutzer die Arbeit des Modells nicht versteht oder nicht mag, ist alles verderblich.
Daher sollte der Nutzer immer abstimmen können, sollte ihm ein Tool zur Rückmeldung geben. Wenn wir der Meinung sind, dass ein finanzbezogener Brief in der Box angekommen ist, müssen wir ihn als "finanzieren" markieren und eine Schaltfläche zeichnen, auf die der Benutzer klicken kann, und sagen, dass er nicht finanziert.
Feedback-Qualität
Sprechen wir über die Qualität des Nutzerfeedbacks. Erstens können Sie und der Benutzer unterschiedliche Bedeutungen in ein Konzept einbringen. Zum Beispiel denken Sie und Produktmanager, dass „Finanzen“ Briefe der Bank sind, und der Benutzer glaubt, dass sich der Brief meiner Großmutter über den Ruhestand auch auf Finanzen bezieht. Zweitens gibt es Benutzer, die gedankenlos gerne Tasten ohne Logik drücken. Drittens kann sich der Benutzer in seinen Schlussfolgerungen zutiefst irren. Ein anschauliches Beispiel für unsere Vorgehensweise ist die Einführung des
nigerianischen Spamklassifikators , einer sehr lustigen Art von Spam, bei der der Benutzer aufgefordert wird, mehrere Millionen Dollar von einem plötzlich in Afrika aufgefundenen entfernten Verwandten zu sammeln. Nach der Einführung dieses Klassifikators haben wir die Klicks auf diese Buchstaben auf "Kein Spam" überprüft, und es stellte sich heraus, dass 80% von ihnen saftiger nigerianischer Spam sind, was darauf hindeutet, dass Benutzer äußerst vertrauenswürdig sein können.
Und vergessen wir nicht, dass nicht nur Menschen auf die Schaltflächen drücken können, sondern auch alle möglichen Bots, die sich als Browser ausgeben. Rohes Feedback ist also nicht gut zum Lernen. Was kann mit diesen Informationen getan werden?
Wir verwenden zwei Ansätze:
- Feedback von verwandten ML . Zum Beispiel haben wir ein Online-Antibotikumsystem, das, wie ich bereits erwähnte, aufgrund einer begrenzten Anzahl von Anzeichen eine schnelle Entscheidung trifft. Und es gibt ein zweites, langsames System, das nachträglich funktioniert. Sie hat mehr Daten über den Benutzer, über sein Verhalten usw. Infolgedessen wird die ausgewogenste Entscheidung getroffen bzw. sie weist eine höhere Genauigkeit und Vollständigkeit auf. Sie können den Unterschied in der Arbeit dieser Systeme in der ersten als Daten für das Training lenken. Ein einfacheres System wird daher immer versuchen, einer komplexeren Leistung näher zu kommen.
- Klassifizierung von Klicks . Sie können einfach jeden Klick des Benutzers klassifizieren, seine Gültigkeit und Verwendbarkeit bewerten. Wir tun dies in Anti-Spam-Mails unter Verwendung der Attribute des Benutzers, seines Verlaufs, der Absenderattribute, des Texts selbst und des Ergebnisses der Klassifizierer. Als Ergebnis erhalten wir ein automatisches System, das Benutzerfeedback validiert. Und da es viel seltener geübt werden muss, kann seine Arbeit zur Hauptaufgabe für alle anderen Systeme werden. Präzision hat bei diesem Modell oberste Priorität, da das Trainieren eines Modells mit ungenauen Daten mit Konsequenzen verbunden ist.
Während wir Daten bereinigen und unsere ML-Systeme neu trainieren, sollten wir die Benutzer nicht vergessen, denn für uns sind Tausende, Millionen von Fehlern in einem Diagramm Statistiken, und für einen Benutzer ist jeder Fehler eine Tragödie. Zusätzlich zu der Tatsache, dass der Benutzer irgendwie mit Ihrem Fehler im Produkt leben muss, erwartet er nach Rückmeldung den Ausschluss einer ähnlichen Situation in der Zukunft. Aus diesem Grund sollten Sie Benutzern nicht nur die Möglichkeit geben, ihre Stimme abzugeben, sondern auch das Verhalten von ML-Systemen zu korrigieren, indem Sie beispielsweise persönliche Heuristiken für jeden Klick auf Feedback erstellen. Bei E-Mails ist es möglicherweise möglich, solche Nachrichten nach Absender und Header für diesen Benutzer zu filtern.
Sie müssen das Modell auch anhand einiger Berichte oder Supportanrufe im halbautomatischen oder manuellen Modus überbrücken, damit auch andere Benutzer nicht unter ähnlichen Problemen leiden.
Heuristik zum Lernen
Es gibt zwei Probleme mit diesen Heuristiken und Krücken. Erstens ist es schwierig, die ständig wachsende Anzahl von Krücken zu warten, ganz zu schweigen von deren Qualität und Langstreckenleistung. Das zweite Problem ist, dass der Fehler möglicherweise nicht häufig auftritt und ein paar Klicks zum erneuten Trainieren des Modells nicht ausreichen. Es scheint, dass diese beiden unabhängigen Effekte wesentlich ausgeglichen werden können, wenn der folgende Ansatz angewendet wird.
- Erstellen Sie eine temporäre Krücke.
- Wir leiten die Daten von ihm an das Modell weiter, es wird regelmäßig abgerufen, einschließlich der empfangenen Daten. Hierbei ist es natürlich wichtig, dass die Heuristik eine hohe Genauigkeit aufweist, um die Qualität der Daten im Trainingssatz nicht zu beeinträchtigen.
- Dann legen wir die Überwachung für den Betrieb der Krücke auf, und wenn die Krücke nach einiger Zeit nicht mehr funktioniert und vollständig vom Modell abgedeckt wird, können Sie sie sicher entfernen. Nun ist es unwahrscheinlich, dass dieses Problem erneut auftritt.
Das Krückenheer ist also sehr nützlich. Die Hauptsache ist, dass ihr Service dringend ist, nicht dauerhaft.
Weiterbildung
Umschulung ist der Prozess des Hinzufügens neuer Daten, die als Ergebnis von Rückmeldungen von Benutzern oder anderen Systemen erhalten wurden, und des Trainings des vorhandenen Modells auf diesen. Es kann verschiedene Probleme bei der Umschulung geben:
- Ein Modell unterstützt möglicherweise einfach keine Weiterbildung und lernt nur von Grund auf neu.
- Nirgendwo im Buch der Natur steht geschrieben, dass Weiterbildung die Qualität der Arbeit in der Produktion verbessern wird. Oft geschieht genau das Gegenteil, dh es ist nur eine Verschlechterung möglich.
- Änderungen können unvorhersehbar sein. Dies ist ein ziemlich subtiler Punkt, den wir für uns selbst identifiziert haben. Auch wenn das neue Modell im A / B-Test im Vergleich zum aktuellen Modell ähnliche Ergebnisse zeigt, bedeutet dies keineswegs, dass es identisch funktioniert. Ihre Arbeit kann um ein Prozent abweichen, was neue Fehler mit sich bringen oder bereits korrigierte alte zurückgeben kann. Sowohl wir als auch die Benutzer wissen bereits, wie sie mit aktuellen Fehlern umgehen müssen, und wenn eine große Anzahl neuer Fehler auftritt, versteht der Benutzer möglicherweise auch nicht, was passiert, da er vorhersehbares Verhalten erwartet.
Das Wichtigste bei der Umschulung ist daher, das Modell zu verbessern oder zumindest nicht zu verschlechtern.
Das erste, woran wir denken, wenn wir über Weiterbildung sprechen, ist der Ansatz des aktiven Lernens. Was bedeutet das? Der Klassifikator bestimmt beispielsweise, ob sich das Schreiben auf Finanzen bezieht, und fügt an der Entscheidungsgrenze eine Auswahl von markierten Beispielen hinzu. Dies funktioniert gut, zum Beispiel in der Werbung, wo es viele Rückmeldungen gibt und Sie das Modell online trainieren können. Und wenn es wenig Rückkopplung gibt, erhalten wir eine stark voreingenommene Stichprobe in Bezug auf die Erzeugung der Datenverteilung, anhand derer es unmöglich ist, das Verhalten des Modells im Betrieb zu bewerten.
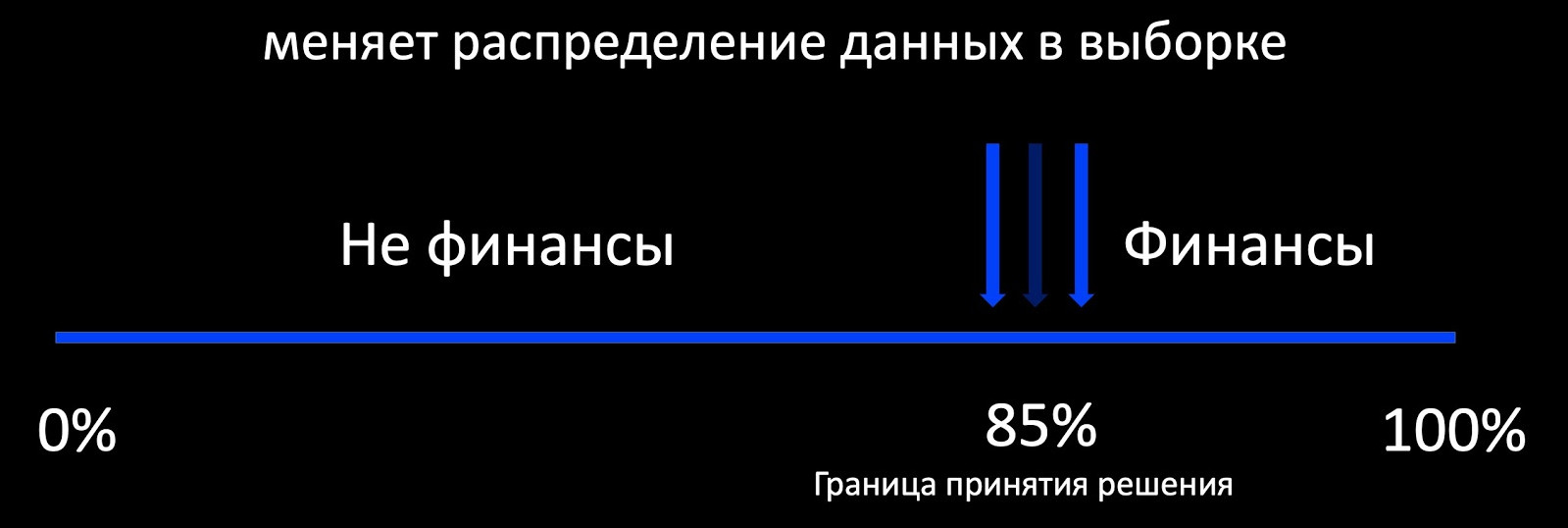
In der Tat ist es unser Ziel, alte Muster, bereits bekannte Modelle, zu erhalten und neue zu erwerben. Hier ist Kontinuität wichtig. Das Modell, das wir oft mit großen Schwierigkeiten herausgebracht haben, funktioniert bereits, sodass wir uns auf seine Leistung konzentrieren können.
In der Post werden verschiedene Modelle verwendet: Bäume, lineare, neuronale Netze. Für jeden erstellen wir einen eigenen Umschulungsalgorithmus. Während des Umschulungsprozesses erhalten wir nicht nur neue Daten, sondern häufig auch neue Funktionen, die wir in allen folgenden Algorithmen berücksichtigen werden.
Lineare Modelle
Nehmen wir an, wir haben eine logistische Regression. Wir bilden das Verlustmodell aus folgenden Komponenten:
- LogLoss auf neuen Daten;
- Wir regulieren die Gewichte neuer Zeichen (wir berühren die alten Zeichen nicht).
- Wir lernen aus alten Daten, um alte Muster zu bewahren.
- und vielleicht das wichtigste: Wir fügen die Harmonische Regularisierung bei, die eine leichte Änderung der Gewichte im Vergleich zum alten Modell gemäß der Norm garantiert.
Da jede Verlustkomponente Koeffizienten aufweist, können wir die optimalen Werte für unsere Aufgabe für die Kreuzvalidierung oder basierend auf den Produktanforderungen auswählen.

Bäume
Gehen wir weiter zu Entscheidungsbäumen. Wir haben den folgenden Algorithmus für die Umschulung von Bäumen aufgenommen:
- Ein Wald von 100-300 Bäumen arbeitet an dem Produkt, das auf dem alten Datensatz trainiert wurde.
- Am Ende löschen wir M = 5 Teile und fügen 2M = 10 neue hinzu, die auf den gesamten Datensatz trainiert wurden, jedoch mit hohem Gewicht aus den neuen Daten, was natürlich eine inkrementelle Änderung des Modells garantiert.
Offensichtlich nimmt die Anzahl der Bäume im Laufe der Zeit erheblich zu und sie müssen regelmäßig reduziert werden, um sich an die Zeitvorgaben anzupassen. Dazu verwenden wir die mittlerweile allgegenwärtige Knowledge Destillation (KD). Kurz über das Prinzip seiner Arbeit.
- Wir haben das aktuelle "komplexe" Modell. Wir starten es auf dem Trainingsdatensatz und erhalten die Wahrscheinlichkeitsverteilung der Klassen am Ausgang.
- Als Nächstes bringen wir dem Schülermodell (in diesem Fall einem Modell mit weniger Bäumen) bei, die Ergebnisse des Modells unter Verwendung der Klassenverteilung als Zielvariable zu wiederholen.
- Hierbei ist zu beachten, dass wir in keiner Weise Datensatzmarkierungen verwenden und daher beliebige Daten verwenden können. Natürlich verwenden wir eine Stichprobe von Daten aus dem Kampfstrom als Übungsbeispiel für das Schülermodell. Das Trainingsset ermöglicht es uns, die Genauigkeit des Modells sicherzustellen, und eine Probe des Flusses garantiert eine ähnliche Leistung auf der Produktionsverteilung, wodurch der Versatz der Trainingsprobe ausgeglichen wird.
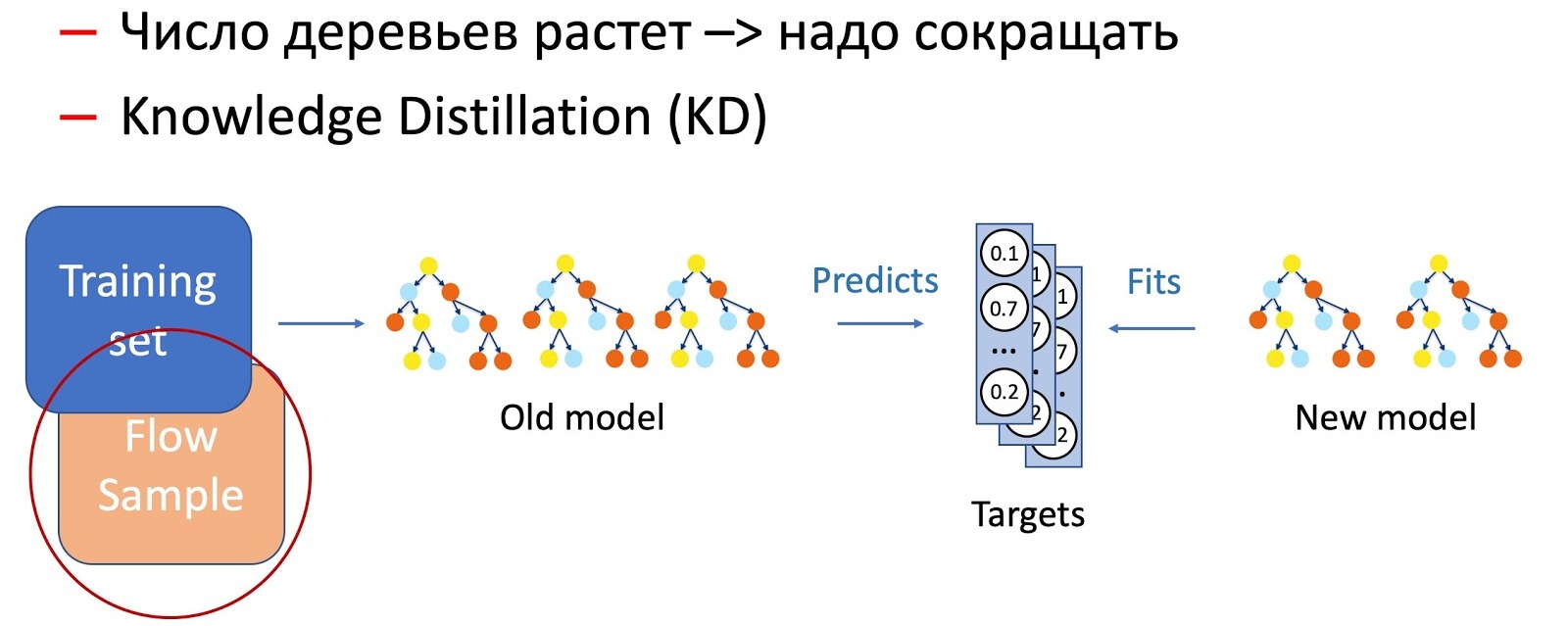
Die Kombination dieser beiden Techniken (Hinzufügen von Bäumen und periodisches Reduzieren ihrer Anzahl mithilfe von Knowledge Distillation) stellt die Einführung neuer Muster und die vollständige Kontinuität sicher.
Mit Hilfe von KD führen wir auch die Unterscheidung von Operationen mit Merkmalen eines Modells durch, zum Beispiel das Entfernen von Merkmalen und das Bearbeiten von Durchgängen. In unserem Fall verfügen wir über eine Reihe wichtiger statistischer Funktionen (Absender, Text-Hashes, URLs usw.), die in einer Datenbank gespeichert sind, deren Eigenschaft abgelehnt werden kann. Das Modell ist natürlich nicht bereit für eine solche Entwicklung von Ereignissen, da es keine Fehlersituationen im Trainingssatz gibt. In solchen Fällen kombinieren wir KD- und Augmentationstechniken: Wenn wir für einen Teil der Daten trainieren, löschen oder nullen wir die erforderlichen Zeichen, und wir nehmen die Bezeichnungen (Ausgaben des aktuellen Modells) als erste, und das Schülermodell lehrt uns, diese Verteilung zu wiederholen.
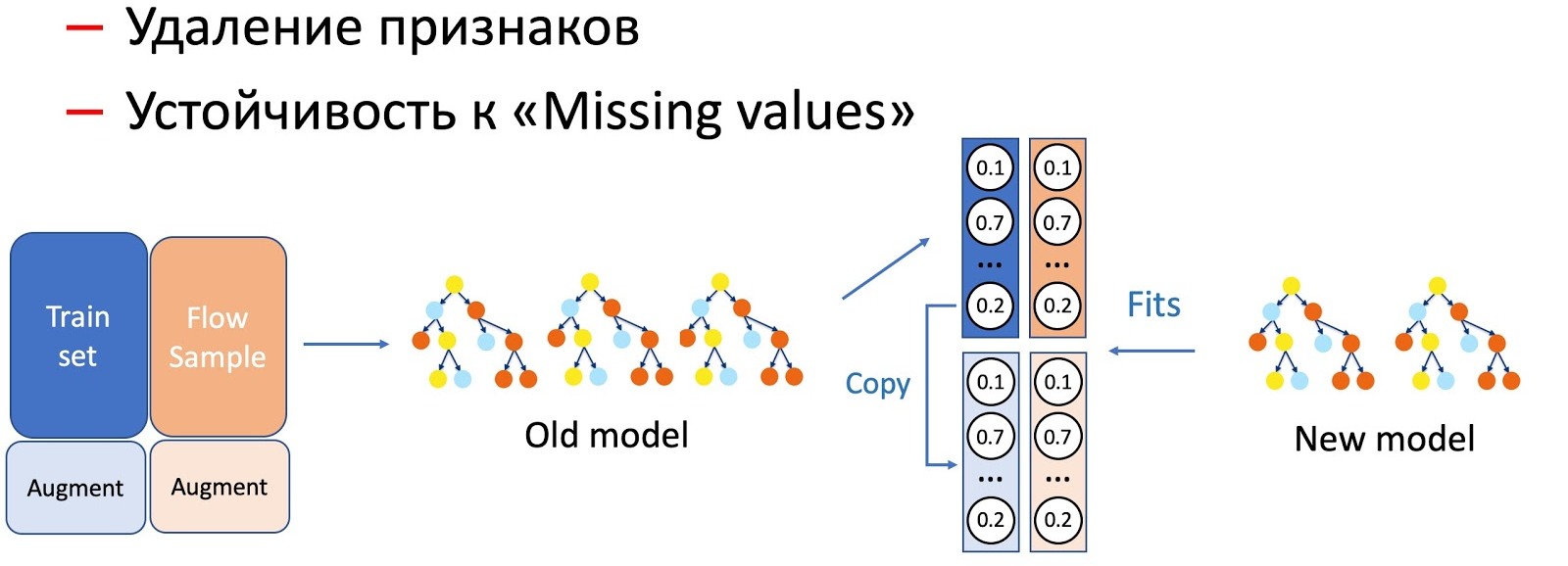
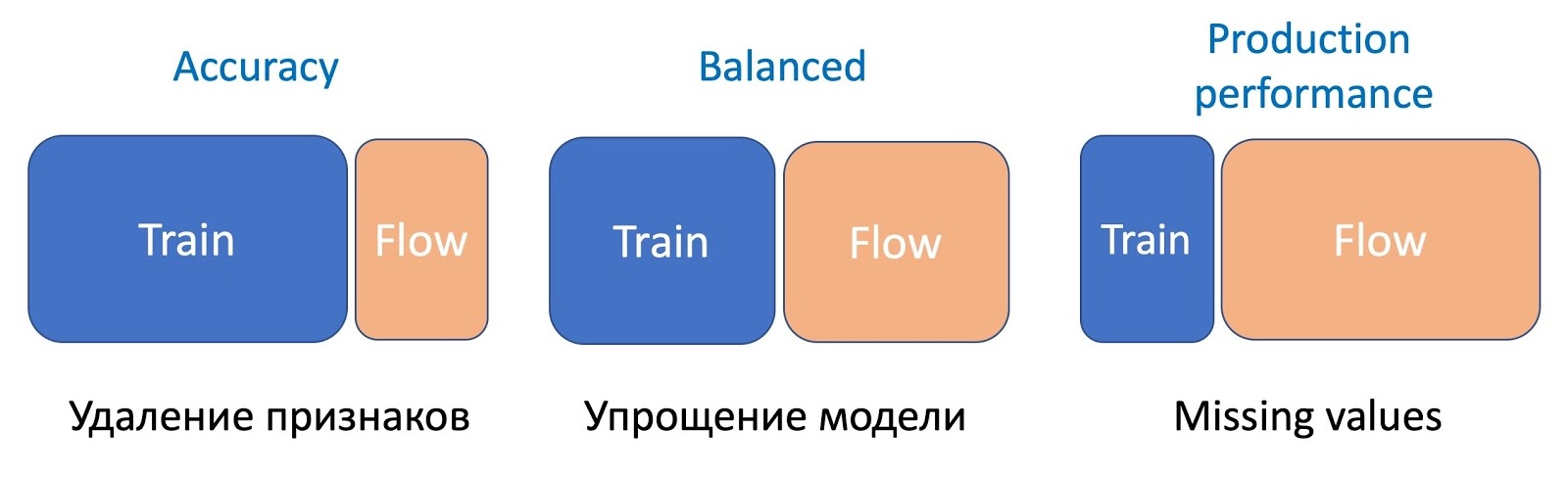
Wir haben festgestellt, dass der Prozentsatz des Probenflusses umso größer ist, je schwerwiegender die Manipulation der Modelle ist.
Um Features zu entfernen, ist die einfachste Operation, nur ein kleiner Teil des Flusses erforderlich, da sich nur ein paar Features ändern und das aktuelle Modell am selben Satz studiert wird - der Unterschied ist minimal. Um das Modell zu vereinfachen (die Anzahl der Bäume um ein Vielfaches zu reduzieren), sind bereits 50 bis 50 erforderlich, und das Auslassen wichtiger statistischer Merkmale, die die Leistung des Modells erheblich beeinträchtigen, erfordert einen noch stärkeren Fluss, um die Arbeit des neuen Modells, das gegen Auslassungen resistent ist, für alle Arten von Buchstaben auszugleichen.
Fasttext
Fahren wir mit FastText fort. Lassen Sie mich daran erinnern, dass die Darstellung (Einbettung) eines Wortes aus der Summe der Einbettung des Wortes selbst und aller seiner Buchstaben N-Gramm, normalerweise Trigramme, besteht. Da Trigramme eine Menge sein können, wird Bucket Hashing verwendet, dh die Umwandlung des gesamten Space in eine bestimmte feste Hashmap. Als Ergebnis wird die Gewichtsmatrix durch die Dimension der inneren Schicht durch die Anzahl der Wörter + Bucket erhalten.
Während der Weiterbildung erscheinen neue Zeichen: Wörter und Trigramme. In der Standard-Nachschulung von Facebook passiert nichts Wesentliches. Nur alte Gewichte mit Kreuzentropie auf neuen Daten werden neu trainiert. , , , , . FastText. ( ), - , .

CNN
. CNN , , , . , , . Triplet Loss (
).
Triplet Loss
Triplet Loss. , . , , .

, , . , . , .
- . (Finetuning): , . , — . , v1 v2. .

, , . , , CNN Fast Text . , ( , , ). . , .

. CNN Fast Text , — . Knowledge Distillation.
, . , , .
Bereitstellen
, .
/B-
, , , , - . , , , A/B-. . 5 %, 30 %, 50 % 100 % , . - , , , . 50 % , , .
A/B- . , A/B- ( 6 24 ), . , /B- ( ), A/B- . , , .
, A/B-. , Precision, Recall , . , , (Complexity) . , -, , , A/B-.

A/B-.
&
, , , , , . , — , .
, — . , . , — - , .
, . ( ). - . , , «» . , , . .

. , , . KL- A/B- , .
, . , NER- -, , . !
Zusammenfassung
.
- . : , . , — , ML-. , , , .
- . — , -. , .
- . . , .
, , ML-, , .