Mehrkernprozessoren sind an der Tagesordnung. Früher oder später muss sich jeder praktische Programmierer in das Labyrinth der Multithread-Programmierung begeben und sich mit den "Monstern" treffen, die dort leben. Sprechen wir darüber, wo wir auf diese Weise beginnen sollen und welche Tools und Ansätze dazu beitragen, dass wir als Sieger hervorgehen. Diesen Bericht habe ich zukünftigen Teilnehmern des
ganzjährigen Praktikums von Yandex gemacht.
- Ich heiße Seva Minkov. Ich arbeite in der Cloud-Infrastrukturabteilung der Suchabteilung. Ich beschäftige mich hauptsächlich mit dem Backend. Ich schreibe in verschiedenen Sprachen, aber meistens handelt es sich um Java und Sprachen, die auf der Java Virtual Machine (JVM) ausgeführt werden.
Unser Team entwickelt eine interne Cloud, in der fast alle Yandex-Dienste gestartet werden - sowohl öffentlich bekannte wie Search, Mail und Alice als auch verschiedene interne Dienste, virtuelle Maschinen sowie kurzlebige MapReduce-Aufgaben und maschinelles Lernen.
Unsere Cloud ist nicht statisch: Das Unternehmen wächst, die Anzahl der Dienste und die Ressourcen, die sie verbrauchen, steigen. Und unser Team steht sehr oft vor der Herausforderung, die Leistung zu skalieren und zu verbessern. Dies erreichen wir durch die Verwendung aller verfügbaren Tools, einschließlich der vertikalen Skalierung, dh durch die Beschleunigung einzelner Systemkomponenten, um einige Singlethread-Algorithmen so umzuschreiben, dass sie schneller arbeiten. Wir machen horizontale Skalierung: Zerkleinern des Systems in kleine Teile, um durch Hinzufügen von Servern, Prozessoren, Kernen usw. eine bessere Leistung zu erzielen.
Und die Multithread-Programmierung hilft uns dabei sehr. Wir werden heute über ihn sprechen - woher kam es, warum ist es relevant? Was ist ein Speichermodell und wie wird es in Java allgemein dargestellt? Wir werden auf einige praktische Aspekte eingehen, um Ihre Anwendungen zu testen und ihre Richtigkeit zu überprüfen.
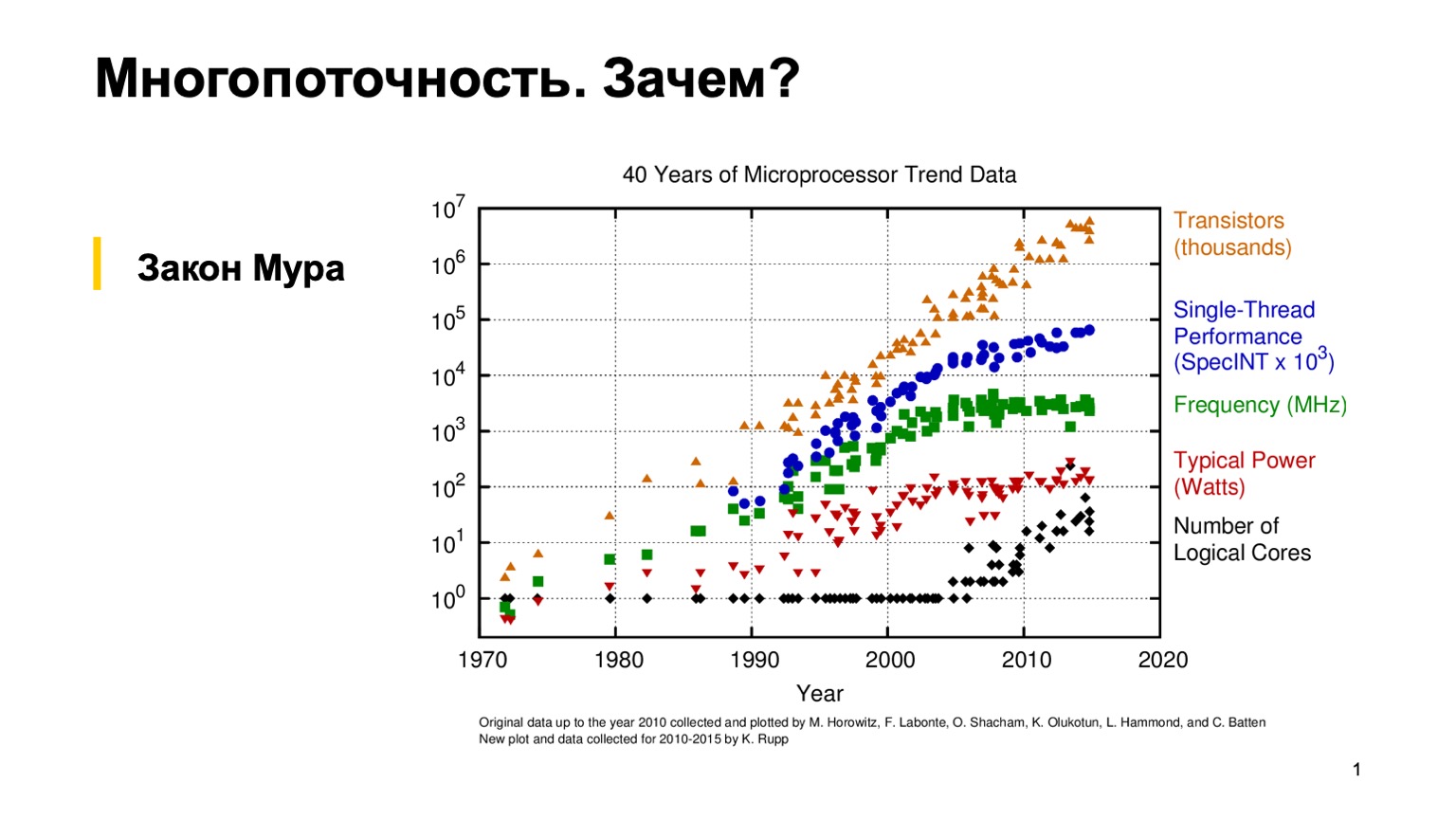
Schauen wir uns zunächst dieses interessante Diagramm an, das die Entwicklung der Eigenschaften von Mikroprozessoren in den letzten 40 Jahren zeigt. Vor ungefähr 10-15 Jahren, als das Gras grüner war und die Prozessoren Single-Threaded waren, konnte ein gewöhnlicher Programmierer einmal ein korrektes Single-Threaded-Programm schreiben und sich dann auf Moores empirisches Gesetz verlassen. Er sagt, dass Prozessoren alle zwei Jahre doppelt so schnell sind. Wie Sie sehen, haben die Hersteller von Mikroprozessoren aus verschiedenen Gründen irgendwann um 2005 auf die Multi-Core-Architektur umgestellt und damit begonnen, die Anzahl der logischen Kerne zu erhöhen. Und der Leistungszuwachs eines einzelnen Kerns hörte auf, Moores Gesetz zu befolgen, und die Verarbeitungsleistung eines Kerns begann langsamer zu wachsen. Dies war eine Revolution, und gewöhnliche Programmierer mussten parallel programmieren, um genau diesen Leistungsgewinn zu nutzen.
Da wir gerade üben, werden wir versuchen, ein einfaches Multithread-Programm zu schreiben und selbst zu sehen, wie es funktioniert.
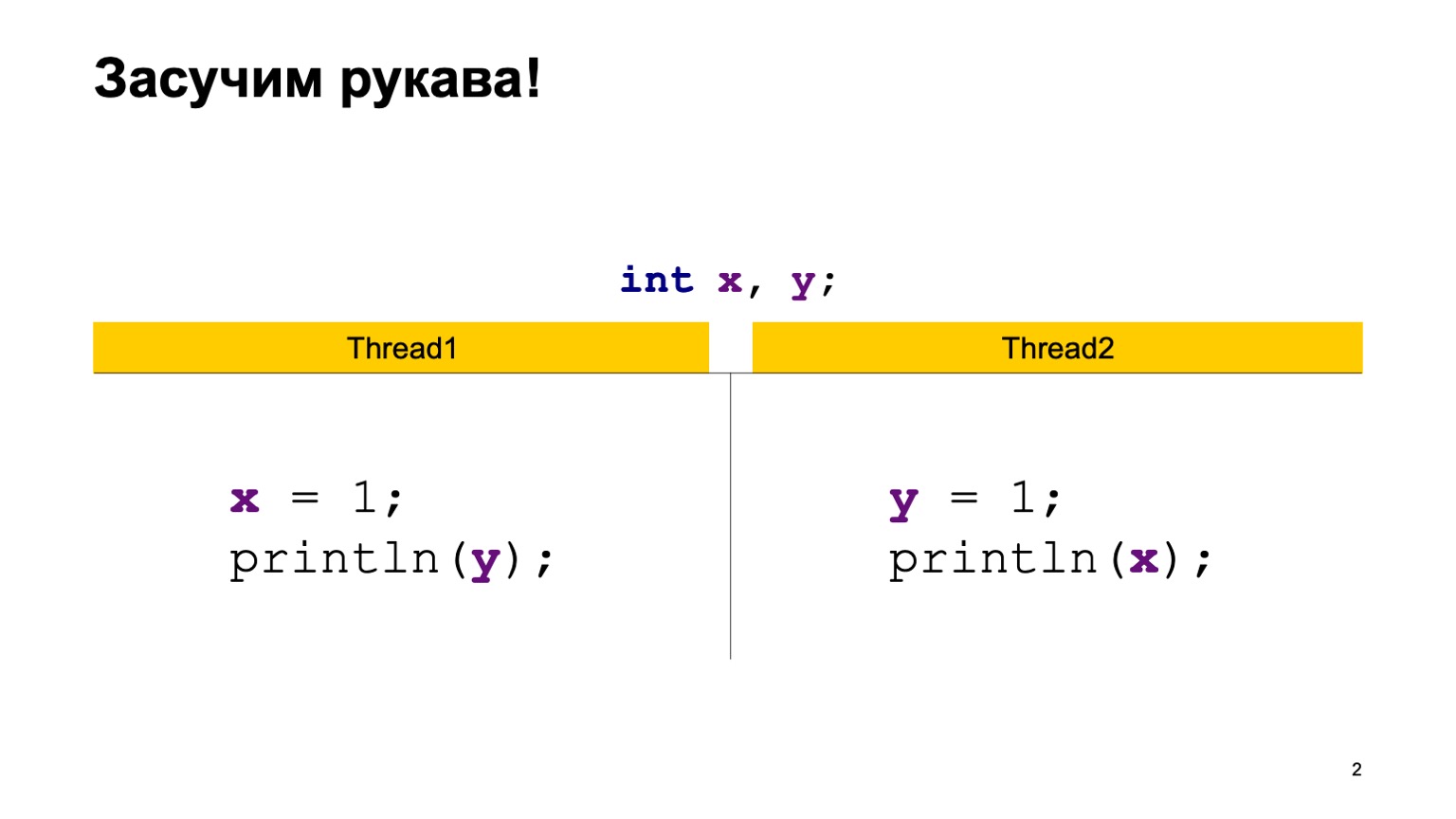
Nehmen wir als Beispiel eine ziemlich einfache Aufgabe zum Kreuzlesen von Datensätzen. Lassen Sie uns zwei gemeinsam genutzte Variablen X und Y, die zuerst mit dem Standardwert (Null) initialisiert wurden, und zwei Streams haben. Jeder Thread schreibt in eine Variable und liest eine andere. In diesem Fall schreibt Thread1 eine Einheit in X und liest Y. Der zweite Thread macht dasselbe, nur rückwärts.
Eine einfache Java-Implementierung könnte ungefähr so aussehen.

Wir werden die ReadWriteTest-Klasse schreiben, sie wird zwei statische Variablen X und Y haben. Direkt in der Hauptmethode konstruieren wir zwei Threads Thread1 und Thread2 und geben jedem von ihnen eine Lambda-Funktion ein, die ausgeführt wird, wenn der Thread ausgeführt wird. Setzen Sie den Code von der vorherigen Folie dort und starten Sie zwei Threads.
Die Reihenfolge, in der die Threads beginnen, ist in gewisser Weise unvorhersehbar. Dies hängt davon ab, wie das Betriebssystem Threads ausführt. Dementsprechend können wir unterschiedliche Versionen haben. Es scheint zu verstehen, wie das alles funktioniert, wir müssen dieses Programm viele Male ausführen, dann die Ausgabe aggregieren und sehen, wie oft diese oder jene Antwort im Programm gefunden wird.

Um das Rad nicht neu zu erfinden, können wir ein fertiges Werkzeug verwenden. Dies nennt sich jcstress, das Java Concurrency Stresstest-Dienstprogramm, das Teil des OpenJDK-Projekts ist.
Dieses Dienstprogramm bietet einen Rahmen für das Schreiben von Stresstests. In diesem Fall lässt sich der Code der vorherigen Folie leicht umschreiben. Zunächst hängen wir die Anmerkung jcstress Test an die Klasse, wodurch unsere Testskripte für das Dienstprogramm einfach sichtbar werden. Wir kennzeichnen es auch mit der State-Klasse, die besagt, dass die Klasse Daten enthält, die sich ändern können: Sie werden sowohl modifiziert als auch aus verschiedenen Streams gelesen. Wir deklarieren zwei Methoden, thread1 und thread2, und markieren sie mit der Annotation Actor. Actor Annotation bedeutet, dass die Methode in einem separaten Thread ausgeführt werden muss. jcstress garantiert, dass jede dieser Methoden in genau einer Instanz der State-Klasse in einem separaten Thread ausgeführt wird. Die Reihenfolge, in der sie gestartet werden, ist nicht speziell festgelegt. Das Ergebnis wird in ein II_Result-Objekt geschrieben, das auf der Folie angezeigt wird. Wir können davon ausgehen, dass es sich um ein Tupel von zwei numerischen Werten handelt, die nur durch die Abhängigkeitsinjektionsmethode dargestellt werden, über die Kirill in einem früheren Bericht gesprochen hat.
Bevor wir mit diesem Test beginnen, überlegen wir uns, welche Schlussfolgerungen die Befehle geben können und welche Werte wir in r1 und in r2 hinzufügen können.

Dazu verwenden wir das sogenannte Alternationsmodell. Die Operationen Lesen oder Schreiben werden auf die eine oder andere Weise in einer bestimmten Reihenfolge ausgeführt. Es reicht aus, alle diese Optionen zusammen durchzugehen und zu sehen, welche Ergebnisse wir erzielen werden.

Angenommen, eine der möglichen Varianten von Ereignissen ist, dass Thread eins vollständig vor Thread zwei ausgeführt wird. Zuerst haben wir Eins zu X hinzugefügt und Null von Y gelesen, da es keine Einträge gab. Dann schrieben sie eine in Y und lasen eine aus X, da der erste Stream dies bereits geschafft hatte.
Die erste Antwort ist null und eins.

Die zweite Variante der Ereignisentwicklung ist genau das Gegenteil: Stream zwei wurde vor Stream eins ausgeführt.

Dementsprechend erhalten wir ein Spiegelergebnis von Eins-Null.

Es gibt ungefähr vier weitere Optionen, die dasselbe Ergebnis liefern, wenn die Threadausführung völlig durcheinander ist. Zum Beispiel haben wir eine Einheit in einem Stream in X aufgezeichnet, in der zweiten haben wir es geschafft, eine Einheit in Y zu haben, und wir berechnen eins zu eins. Sie können dann sehen, welche anderen Optionen es als Heimübung gibt.

Es scheint, dass wir alle möglichen Optionen durchgegangen sind, mehr gibt es nicht. Lassen Sie uns das Dienstprogramm ausführen und sehen, welche Schlussfolgerungen es zieht.

Die Ausgabe sieht aus wie eine Tabelle. In der ersten Spalte werden die Ergebnisse aufgelistet, die wir in II_Result hinzugefügt haben - das Dienstprogramm führt diesen Code millionenfach aus - und die Anzahl der Fälle, in denen überhaupt ein bestimmtes Ergebnis festgestellt wurde. Aber wahrscheinlich wäre dieser Bericht nicht gewesen, wenn alles so einfach gewesen wäre.
Tatsächlich können wir in dieser Schlussfolgerung auch das Null-Null-Ergebnis sehen, das mit dem Alternationsmodell schwer zu erklären ist. Es scheint, dass eine der möglichen Optionen darin besteht, dass jemand direkt im Stream-Code die Zeilen übernommen und neu angeordnet hat.
Überlegen wir, warum es passiert ist und wie wir damit leben können. Ich bitte Sie auch, darauf zu achten, dass die One-One-Option nur äußerst selten speziell auf meinem Computer gefunden wurde. Von 130 Millionen Vorstellungen führten nur 154 Vorstellungen zum Ergebnis von eins zu eins. Und im Gegenteil, in fast 30% der Fälle tritt Null-Null sehr häufig auf.

Um ein Zwischenergebnis zusammenzufassen, das wir alle mit Ihnen gesehen haben. Zuallererst konnten wir verstehen, dass die Interaktion von Flüssen durch das Gedächtnis nicht trivial ist. Das von uns verwendete Rotationsmodell funktioniert nicht. Wir haben eine Umlagerung gesehen. Das kann viele Gründe haben.
Zum Beispiel konnten wir einige „relativistische Effekte“ von Eisen beobachten. Dies kann auf folgende Weise gedacht werden: In einem Taktzyklus eines 3-GHz-Prozessors bewegt sich das Licht im Vakuum etwa 10 cm. Das Protokoll zum Lesen und Schreiben in den Prozessorspeicher ist kompliziert und manchmal dauert es mehrere hundert Taktzyklen, um den Wert von einem Kern auf einen anderen zu übertragen. Dementsprechend kann ein Kern scheinen, die Vergangenheit zu sehen. Das Ergebnis nach dem Datensatz ist aufgetreten, aber wir sehen den alten Wert. Außerdem stehen Prozessoren auch nicht still und können Anweisungen stellenweise ändern.
Moderne Optimierungscompiler können zu derselben Permutation führen. Um eine maximale Single-Thread-Leistung zu erzielen, können sie auch Anweisungen austauschen, sodass die Richtigkeit eines Single-Thread-Programms nicht beeinträchtigt wird. Aber in Multithread-Programmen kann es zu interessanten Effekten kommen, die wir gesehen haben.
Und die zweite - wahrscheinlich die wichtigste Schlussfolgerung: Wir haben gesehen, dass Multithread-Programme grundsätzlich nicht festgelegt sind. Singlethread-Programme stützen sich hauptsächlich auf einige Invarianten bei der Eingabe und Ausgabe und sind deterministisch. vorausgesetzt, der Zufallszahlengenerator und die Benutzereingabe sind Eingabeparameter.
Dies macht die Dinge sehr kompliziert: Es ist schwierig zu verstehen, was das Programm tut, und es ist schwierig, es zu testen.
In Bezug auf die Komplexität der Tests können wir hinzufügen, dass dasselbe Ergebnis nur 154 Mal bei 130 Millionen Anrufen gefunden wurde. Die Eintrittswahrscheinlichkeit dieses Ergebnisses beträgt ein Millionstel. In der Produktion bedeutet dies, dass ein solcher Fehler nach Wochen reproduziert werden kann. Und es wird sicherlich irgendwo am Sonntagabend passieren, wenn Sie das überhaupt nicht erwartet haben.

Lassen Sie uns darüber nachdenken, wie wir sein sollten und was wir im Allgemeinen von unserer Zunge erwarten, um am Sonntagabend friedlich zu schlafen. Erstens benötigen wir ein Tool, mit dem wir das Verhalten des Programms vorhersagen und Beurteilungen über dessen Ausführung vornehmen können. Zweitens brauchen wir Sprachwerkzeuge, mit denen wir die Permutationen und Effekte beeinflussen können - sie können von der Hardware, dem Compiler usw. stammen. Ich möchte weniger darüber wissen, wie ein bestimmter Prozessor funktioniert, welche Optimierungen der Compiler ausführen kann und welche Abkürzung verwendet wird das kam aus der Java-Welt. Einmal schreiben, überall ausführen - Schreiben Sie einmal den richtigen Multithread-Code, damit er auf allen Plattformen funktioniert.

Diese Fragen und Anforderungen, die wir aufgelistet haben, stellten sich seit langem in den Köpfen von Entwicklern und Theoretikern und Praktikern. Wie jede komplexe Aufgabe mit einem hohen Grad an Komplexität wurde sie durch die Einführung des Konzepts einer abstrakten Maschine gelöst. Wir alle, Entwickler in höheren Programmiersprachen, schreiben nicht für eine bestimmte Hardware, nicht für ein solches Prozessormodell, sondern schreiben eine abstrakte Maschine. Und die Spezifikation der Sprache soll ihr Verhalten so beschreiben, dass diese drei Welten in Einklang gebracht werden. Einerseits lassen Sie Entwickler von Compilern und Prozessoren ihre Optimierungen vornehmen und uns Programmierern, die bereits in einer bestimmten Sprache schreiben, den Kopf in den Kopf sprengen.
Das Speichermodell nimmt in dieser abstrakten Maschine eine zentrale Position ein. Sie sollte eine Frage beantworten: Wenn ich eine Variable X in einem Stream lese, welches Ergebnis der letzten Einträge kann ich dort überhaupt sehen? Es wurde erstmals versucht, das Speichermodell in der Sprache Java zu formalisieren, alle anderen Speichermodelle erschienen später. Angenommen, C ++ 11 ist mit einigen Änderungen fast eine Kopie des Java-Speichermodells.
In Java gab es mehrere Speichermodelle. Ursprünglich wurde das sogenannte "glockenförmige" Speichermodell als erfolglos erkannt, da es die Arbeit von Programmierern behinderte, die in Java schreiben, und dem Compiler einige Optimierungen verbot, die für sich selbst durchaus angemessen sind. Dementsprechend wurde im Rahmen des Community-Prozesses JSR-133 ein modernes Speichermodell geschrieben.
Da wir die Schriftstelle in Form einer Spezifikation haben, versuchen wir, sie zu untersuchen und zu verstehen, was wirklich im Inneren vor sich geht.

Es gibt ein Problem. Heben Sie Ihre Hände, der die Spezifikation der Sprache öffnete und las, was dort geschah. Und wie viele von Ihnen haben das Speichermodell von Absatz 17.4 gelesen? Eine kleine Überraschung erwartet Sie. Die Sprachspezifikation wird grundsätzlich in einer verständlichen Sprache beschrieben. Aber das Speichermodell ist voller mathematischer Hardcore. Es gibt Einschlüsse in Griechisch, viele mathematische Begriffe aus der Reihe transitiver Abschlüsse, der Vereinigung zweier Ordnungen usw.
Leider gibt es keinen anderen Weg. Das einzige, worauf Sie sich beim Schreiben von Multithread-Programmen verlassen können, ist die Spezifikation. Sie muss lesen und verstehen. Ich kann Sie nur empfehlen. Außerdem hatte ich, als ich die Spezifikation zum ersten Mal las, solche Eindrücke.
Warum ist es so kompliziert? Ich bin den falschen Weg gegangen und ich warne Sie sehr, sich wie ich zu verhalten.
Ich habe es genommen, im Internet gesucht, was ein Speichermodell ist. Ich habe ein Buch namens JSR-133 Cookbook for Compiler Writers gefunden. Sie beschreibt, wie ein Compiler-Entwickler dieses Speichermodell auf einfache Weise implementieren kann. Das Problem ist, dass dies eine spezifische Implementierung ist und nicht zur Beurteilung des gesamten Speichermodells im Allgemeinen verwendet werden kann.
Versuchen wir auf jeden Fall, einen kleinen Versuch zu den wichtigsten Schlussfolgerungen zu machen, die sich aus dem Java-Speichermodell ergeben.

Möglicherweise gibt es viele Ausführungen Ihres Multithread-Programms. Das haben wir selbst am Beispiel unseres Programms gesehen. Im einfachsten Beispiel hatten wir bereits vier Ergebnisse seiner Implementierung. Und die Aufgabe des Java-Speichermodells besteht darin, zu sagen, welche dieser Ausführungen korrekt sind und welche davon verboten werden sollten. Und postuliert drei Dinge. Die erste ist, dass Ihre Aufgabe im Rahmen eines Threads pseudosequenziell ausgeführt wird. Dies impliziert, dass der Compiler Operationen austauschen kann, der Prozessor auch Anweisungen parallel ausführen kann, sie austauschen kann. Dies muss jedoch so erfolgen, dass die sichtbaren Auswirkungen der Ausführung Ihres Programms so sind, als ob es direkt nacheinander ausgeführt würde.
Zweitens sind die sogenannten aus dem Nichts stammenden Bedeutungen in der Sprache verboten. Leider haben wir keine Zeit, dies zu zeigen, aber es gibt Fälle, in denen der Compiler eine solche Konvertierung durchführen kann, dass in einem Single-Thread-Programm alles korrekt ist und Sie möglicherweise einen Datensatz in einem Multi-Thread-Programm haben, den Sie nicht ausgeführt haben.
Dementsprechend gibt das Speichermodell an, dass beim Lesen einer Variablen entweder der Standardwert oder einige der Ergebnisse der Aufzeichnung zurückgegeben werden, die einmal von einem anderen Befehl ausgeführt wurden. Und die restlichen Aktionen können als sequentiell interpretiert werden, wenn sie durch eine Teilordnungsbeziehung verbunden sind - bevor dies geschieht. Und dies ist jetzt der einzige Ort, an dem wir Mathe brauchen. Teilweise Beziehung, da nicht alle Lese- und Schreiboperationen von Variablen durch Relationen verbunden sind. Es hat die Eigenschaften Reflexivität, Transitivität und Antisymmetrie.

Lassen Sie uns detaillierter darüber sprechen, was vor sich geht. Die erste Regel ist, dass alle Operationen in einem einzigen Thread verknüpft werden. Wenn Sie in einem Thread geschrieben haben, dass X gleich eins ist, ist Y gleich eins; Es wird angegeben, dass die Schreiboperationen in X mit Vorgängen vor Y zusammenhängen. Das heißt, X geschieht vor Y. Außerdem werden einige spezielle Aktionen, die sogenannten Synchronisationsaktionen, gebunden. Lesen Sie mehr in der Spezifikation. Dies ist beispielsweise das Schreiben und Lesen einer flüchtigen Variablen, das Sperren / Entsperren auf einem Monitor, das Betreten des synchronisierten Blocks und das Verlassen des synchronisierten Blocks. Ein sehr wichtiger Punkt ist, dass alle Synchronisationsaktionen in Ihrem Programm Threads in genau derselben Reihenfolge sehen, als würden sie einzeln ausgeführt.
Und passiert, bevor einige Paare dieser Aktionen verknüpft werden. Es spielt keine Rolle, in welchem Thread Synchronisationsaktionen stattfinden. Es ist wichtig, dass sie zum Beispiel eine flüchtige Variable passieren. In der Spezifikation heißt es beispielsweise, dass in die flüchtige Variable geschrieben wird, bevor eine andere nachfolgende Aktion ausgeführt wird. Dies bezieht sich genau auf die Art und Weise, in der wir Synchronisationsaktionen hatten.
Und das Wichtigste dabei ist, dass die Regel vor der Konsistenz abläuft, die nur die wichtigste Frage zum Speichermodell beantwortet. Es kann wie folgt interpretiert werden. Wenn eine Variable eine Kette von Lese- / Schreibvorgängen enthält und diese durch eine Kette von Vorgängen vor Beziehungen verbunden sind, sollte beim Lesen auf jeden Fall der letzte Datensatz in dieser Kette angezeigt werden. Ist dies nicht der Fall, können Sie einen anderen Wert, einen anderen Datensatz oder einen Standardwert anzeigen. Jetzt können Sie ausatmen, mit den grundlegenden Definitionen sind wir fertig.
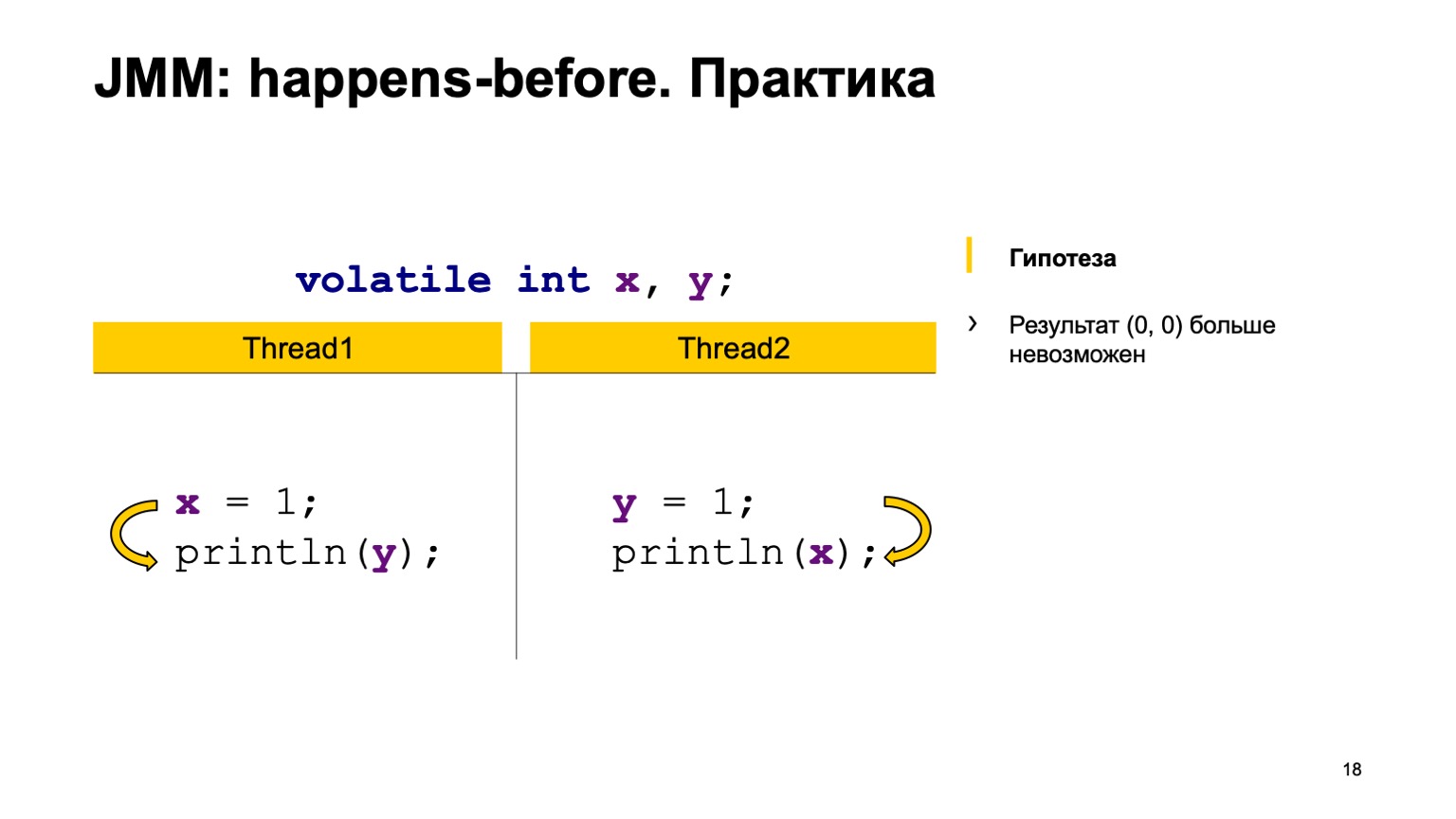
Versuchen wir die Theorie in der Praxis zu testen? Nehmen wir ein Beispiel mit einem Kreuzlesen von Datensätzen und fügen den flüchtigen Modifikator zu den Variablen X und Y hinzu. Versuchen wir zu beweisen, dass wir den Wert Null-Null nicht mehr sehen werden. Verwenden Sie dazu einfach die Regeln, die ich oben ausgesprochen habe.
Wir werden die Vorkommnisse in einem Thread arrangieren. Vor dem Lesen von Y und im zweiten Thread wird in X geschrieben. Schreiben an Y geschieht, bevor von X gelesen wird.
Und dann haben wir vier Synchronisationsaktionen: Schreiben in X, Schreiben in Y, Lesen aus X, Lesen aus Y. Sie können in einer bestimmten Reihenfolge auftreten, und ein Paar kann in zwei Fällen auftreten.
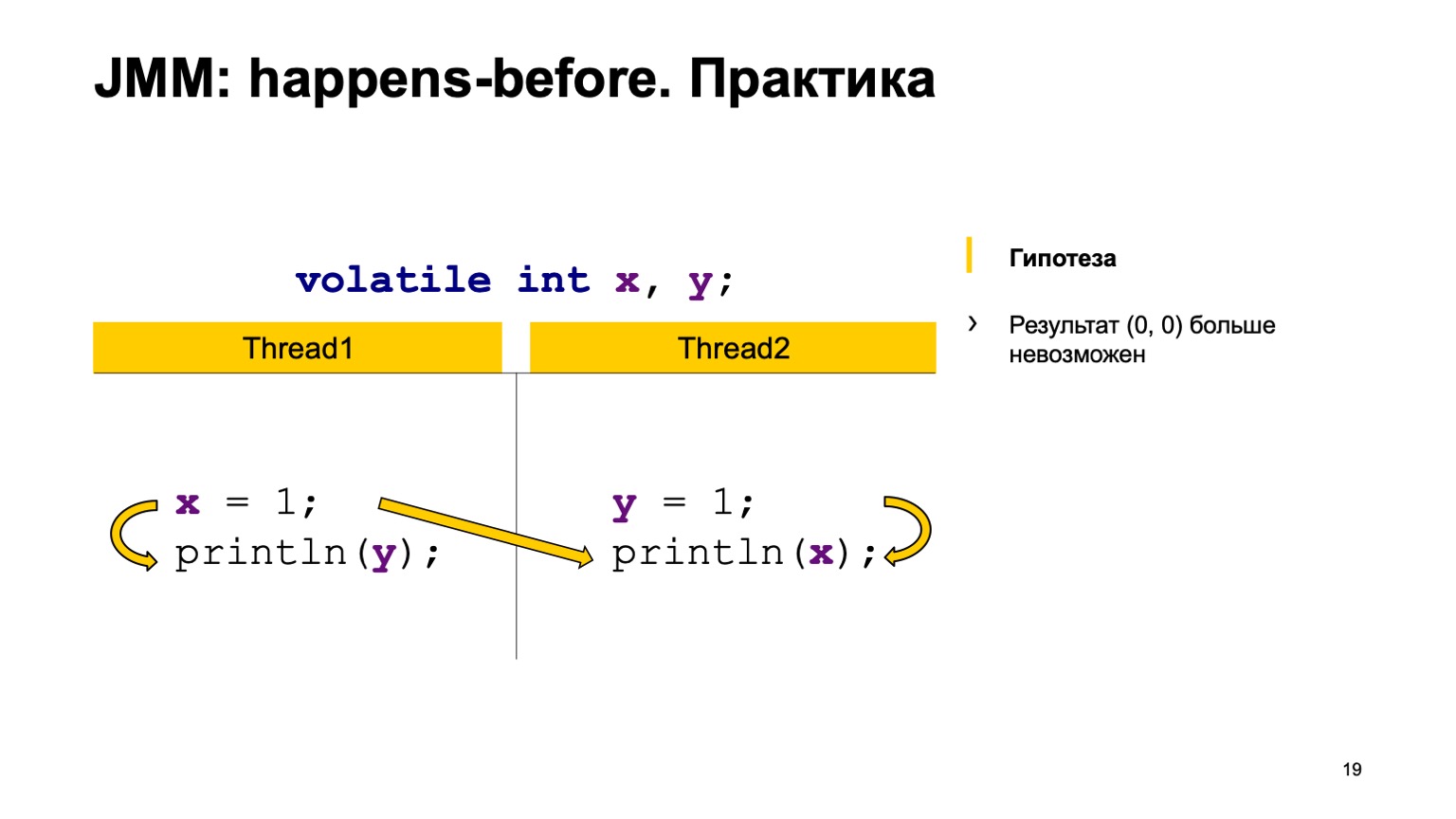
Das Schreiben in X in Stream 1 erfolgte beispielsweise früher als das Lesen aus X in Stream 2 ("happen-before"). Wie Sie hier sehen können, hängt die Beziehung nicht mit Y zusammen. Das Ergebnis des Lesens von Y kann entweder den Standardwert oder den Wert, den der zweite Stream aufgezeichnet hat, an uns zurückgeben. Ein Messwert von X muss immer eine Einheit enthalten. Dementsprechend können unsere Optionen null-eins, eins-eins sein.
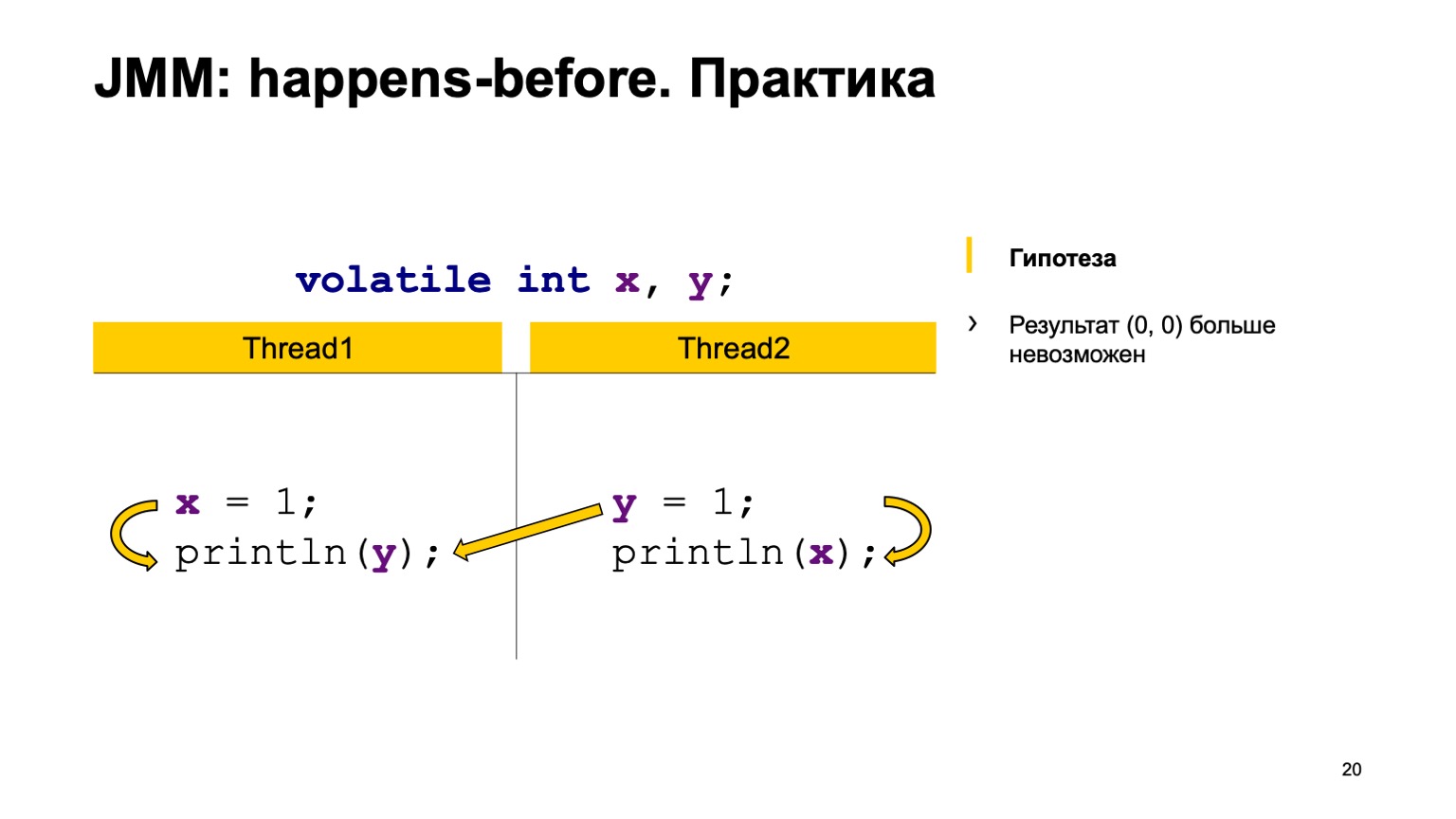
Der zweite Fall ist, wenn eine Verbindung entsteht. Dies ist dasselbe - das Schreiben in Y geschieht, bevor aus Y gelesen wird. Es gibt auch keine Verbindung zwischen X. Dementsprechend ist das Ergebnis dasselbe, nur dort erhalten Sie Eins-Null, Null-Eins. Theoretisch können wir unser neues Programmverhalten nachweisen.

Sie können es in der Praxis überprüfen. Nehmen Sie das flüchtige Schlüsselwort und fügen Sie es in unseren Test ein. Laufen Sie und sehen Sie, dass in der Tat in unserem Land dieser Wert nie reproduziert wird.
Also, happen-before ist ein sehr gutes Werkzeug, um die Korrektheit Ihrer Programme zu beweisen. Es hat eine weitere interessante und nützliche Eigenschaft. Nehmen wir an, wir haben noch so ein kleines Stück Code. Eine flüchtige Variable X und Variable Z sind nicht flüchtig, kein Unterschied. Es gibt einen Thread, der nur in die Variablen X und Z schreibt. und der zweite Thread, der wartet, wenn X den Wert eins annimmt und erst dann Z ausgibt. Auf die gleiche Weise können wir die Vor-Ereignis-Beziehung innerhalb desselben Threads und zwischen Threads aufbauen. Wir werden sehen, dass der Datensatz in Z im ersten Stream transitiv ist, sein Wert wird immer in Stream 2 gelesen. Dies ist tatsächlich ein ziemlich leistungsfähiger Mechanismus zum Veröffentlichen von Daten zwischen Threads.
Nehmen wir an, wir haben noch so ein kleines Stück Code. Eine flüchtige Variable X und Variable Z sind nicht flüchtig, kein Unterschied. Es gibt einen Thread, der nur in die Variablen X und Z schreibt. und der zweite Thread, der wartet, wenn X den Wert eins annimmt und erst dann Z ausgibt. Auf die gleiche Weise können wir die Vor-Ereignis-Beziehung innerhalb desselben Threads und zwischen Threads aufbauen. Wir werden sehen, dass der Datensatz in Z im ersten Stream transitiv ist, sein Wert wird immer in Stream 2 gelesen. Dies ist tatsächlich ein ziemlich leistungsfähiger Mechanismus zum Veröffentlichen von Daten zwischen Threads., , — put value. — get value . happens-before , , put value happens-before get value. , happens-before , volatile, . , , — put happens-before get.

, . -, . , , . , . , , . , . , , , , .
-, , jcstress. : , JVM . , .
, . — «The Art of Multiprocessor Programming» . , happens-before, , . . — «Java Concurrency in Practice» . , . , , . . .
, performance- Oracle, Red Hat. , Java- , . JMM.
. , -, . , , YouTube. , , . Danke an alle.